graph TD
V["Visual Input<br/>(Root)"]
V --> A1["Annotation 1<br/>(Branch 1)"]
V --> A2["Annotation 2<br/>(Branch 2)"]
V --> A3["Annotation 3<br/>(Branch 3)"]
V --> A4["Annotation 4<br/>(Branch 4)"]
style V fill:#e1f5ff,stroke:#2196F3,stroke-width:2px
style A1 fill:#fff4e1,stroke:#FF9800
style A2 fill:#fff4e1,stroke:#FF9800
style A3 fill:#fff4e1,stroke:#FF9800
style A4 fill:#fff4e1,stroke:#FF9800
Packing & Message Trees
What Is Packing?
Packing is a technique that merges multiple short training examples into a single long sequence to avoid wasteful padding during batch creation. The token counts of training examples vary widely, ranging from a few hundred tokens (pure text or small images) to over 16,000 tokens (videos with subtitles or long videos during long-context training).
Challenges in Vision-Language Models
Packing in Vision-Language Models (VLMs) presents non-trivial challenges for the following reasons:
- Dual packing requirements: Both Vision Transformer (ViT) crops and Large Language Model (LLM) tokens need to be efficiently packed
- Model diversity: Must support models with different approaches to converting images and video into tokens
Molmo2’s On-the-Fly Packing Algorithm
Molmo2 developed an on-the-fly packing algorithm that constructs maximally efficient packed sequences from a small in-memory pool of examples. This algorithm can be integrated into a standard PyTorch data loader.
What Are Message Trees?
Message Trees are a method for encoding videos or images that have multiple annotations. They enable efficient processing of multiple different annotations (question-answer pairs, captions, pointing, etc.) for a single visual input.
Structure of Message Trees
Message Trees represent data in a tree structure as follows:
Specifically:
- The visual input is encoded as the first message
- Each annotation becomes a different branch
- The tree structure is linearized as a single sequence
- Custom attention masks are used to prevent cross-attention between branches
Attention Mask Implementation
Message Trees use custom attention masks to maintain independence between branches. This prevents different annotations (branches) from attending to each other.
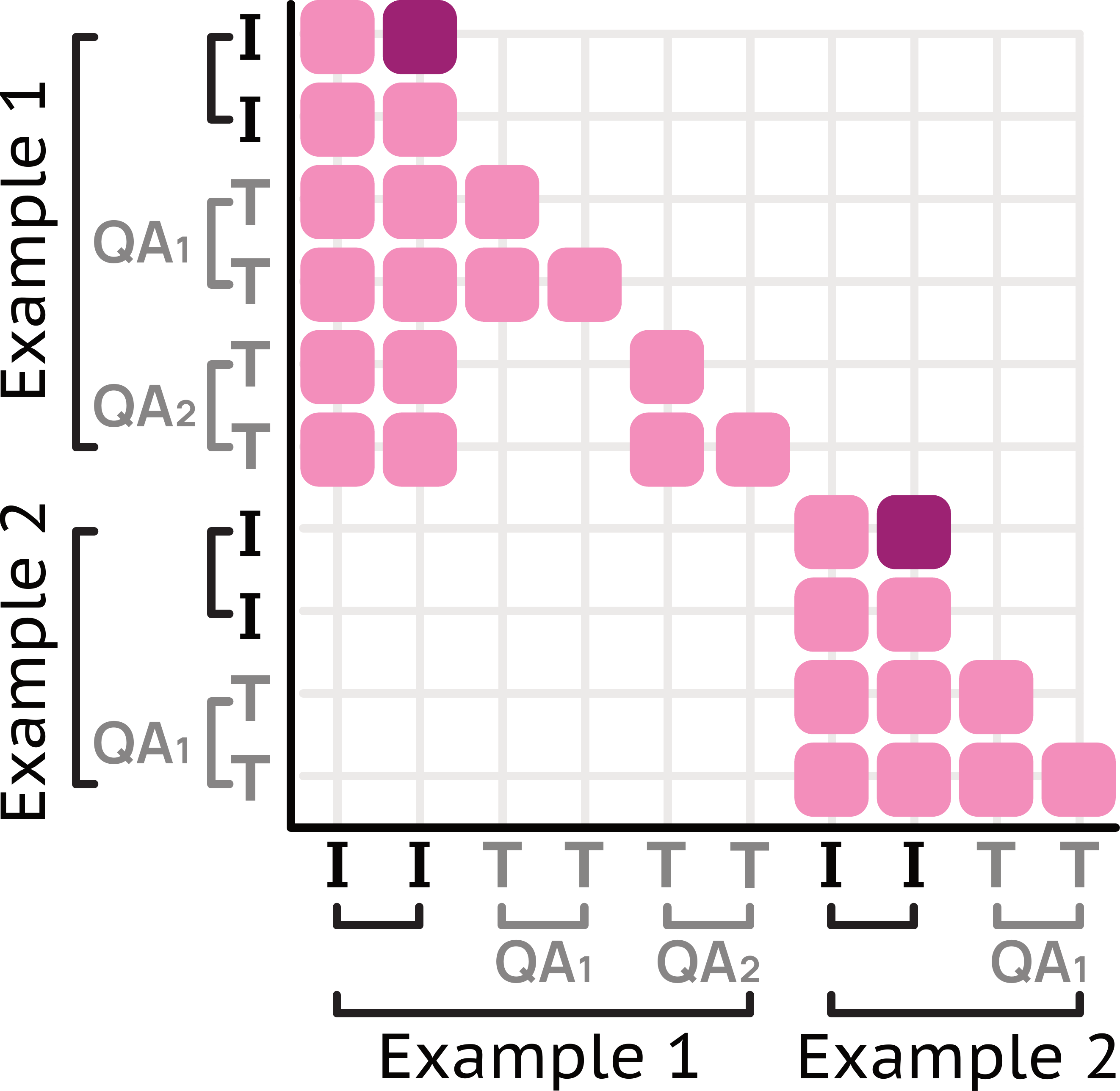
Each branch can attend to the visual input, but cannot cross-attend to other branches.
Synergy of Packing and Message Trees
By combining Packing and Message Trees, Molmo2 achieves the following:
- High-density training data utilization: Efficiently leverages multiple annotations for a single visual input
- Minimal padding: Efficiently packs examples of different lengths, making effective use of GPU memory
- Accelerated training: 15x efficiency improvement accelerates training on large-scale data
These two techniques form a critical foundation for Molmo2’s efficient training.
References
Clark, Christopher, Jieyu Zhang, Zixian Ma, et al. 2026. “Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding.” arXiv Preprint arXiv:2601.10611. https://arxiv.org/abs/2601.10611.