flowchart TD
D3PM["<b>D3PM</b> (2021)<br/>foundational<br/>遷移行列 Q_t の一般論"]
Abs["Absorbing transition<br/>に絞り込む"]
Gen["一般 transition を保持<br/>+ ratio matching"]
MDLM["<b>MDLM</b> (2024)<br/>x_0-prediction CE<br/>重み付き masked CE"]
SEDD["<b>SEDD</b> (2024)<br/>concrete score<br/>score entropy 損失"]
D3PM --> Abs
D3PM --> Gen
Abs --> MDLM
Gen --> SEDD
D3PM and SEDD
MDLM(Masked Diffusion Language Model)(Sahoo ほか 2024年) は「absorbing transition + \(x_0\)-prediction の cross-entropy」という極めて簡潔な選択をしたが、これは離散拡散の唯一の道ではない。D3PM (Austin ほか 2021年) はより一般的な遷移行列を扱う foundational な定式を提供し、SEDD(Score Entropy Discrete Diffusion) (Lou ほか 2024年)(ICML 2024 best paper)は確率比(concrete score)を直接学習する代替案を示している。両者を知ることで、MDLM の選択がなぜ「実装の簡潔さ」に集約されたのかが見える。
本章では D3PM の枠組み、SEDD の ratio matching、そして MDLM を含めた三者の比較を整理する。
D3PM: 離散拡散の foundational な数学
位置づけ
D3PM(Discrete Denoising Diffusion Probabilistic Models)(Austin ほか 2021年) は、現在の masked / discrete diffusion 系列における foundational な論文である。MDLM や SEDD もこの枠組みの上に立っており、連続拡散(Denoising Diffusion Probabilistic Models(DDPM))(Ho ほか 2020年) を「離散変数の場合に何が起こるか」と書き直したのが D3PM の出発点である。
DDPM は連続変数 \(x \in \mathbb{R}^d\) に Gaussian ノイズを徐々に加えていく forward 過程を考えるが、テキストのようなカテゴリカル変数では Gaussian は使えない。代わりに、各時刻で 遷移行列 \(Q_t\) を介してトークンを別のトークンに置き換える、というのが離散拡散の基本構造である。
Forward 過程と遷移行列
トークン \(x \in \{1, \dots, K\}\)(\(K\) は語彙サイズ)を one-hot で表現すると、forward 過程は次のように定義される。
\[ q(x_t \mid x_{t-1}) = \text{Cat}\bigl(x_t;\, Q_t x_{t-1}\bigr) \]
ここで \(Q_t \in \mathbb{R}^{K \times K}\) は遷移行列で、\((Q_t)_{ij}\) は時刻 \(t-1\) にトークン \(j\) だったものが時刻 \(t\) にトークン \(i\) になる確率を表す。複数ステップでの遷移は単純に行列積で書ける。
\[ q(x_t \mid x_0) = \text{Cat}\bigl(x_t;\, \bar{Q}_t x_0\bigr), \qquad \bar{Q}_t = Q_t Q_{t-1} \cdots Q_1 \]
reverse posterior \(q(x_{t-1} \mid x_t, x_0)\) も Bayes 則で閉形式に求まり、これがモデルが模倣すべき目標分布となる。
遷移行列の選び方
D3PM が示した最大の貢献は、\(Q_t\) の選び方によって複数の系列が得られるという点である。
Uniform transition: 各トークンが一様分布に向かって拡散する。最終状態は語彙上の一様分布。
\[ Q_t = (1 - \beta_t) I + \frac{\beta_t}{K} \mathbf{1}\mathbf{1}^\top \]
Absorbing transition: 各トークンが確率 \(\beta_t\) で吸収状態 [MASK] に遷移し、一度マスクされたら戻らない。これが MDLM が採用した 形式である。
\[ (Q_t)_{ij} = \begin{cases} 1 & i = j = \texttt{[MASK]} \\ \beta_t & i = \texttt{[MASK]},\, j \neq \texttt{[MASK]} \\ 1 - \beta_t & i = j \neq \texttt{[MASK]} \\ 0 & \text{otherwise} \end{cases} \]
Discretized Gaussian: 連続拡散に近い遷移。語彙が順序付き(例: 画素値)の場合、距離の近いトークンへの遷移を優先する。
Nearest-neighbor: 単語埋め込み空間で距離が近いトークンへ遷移する。テキストの局所構造を保つことを意図した設計。
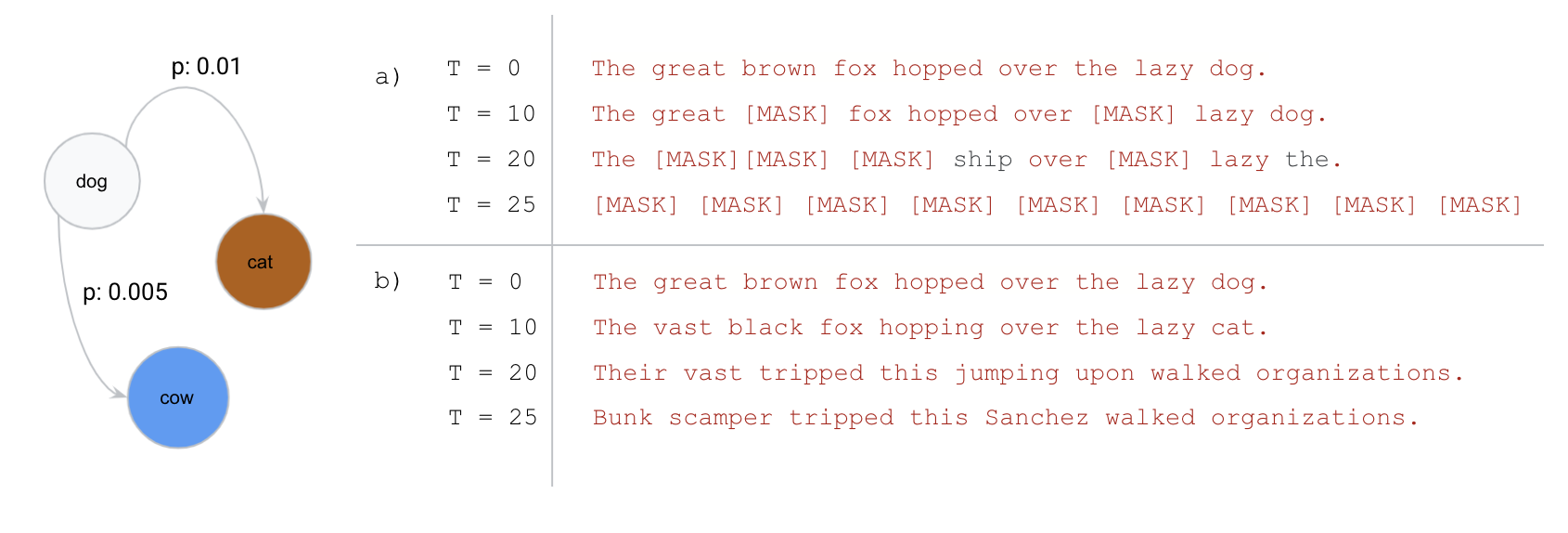
[MASK] に置換され、戻ることはない。(b) uniform transition: トークンが他のトークンに遷移し続け、最終的には一様分布のノイズになる。MDLM は (a) absorbing に絞ることで定式化を簡潔化した。出典: (Austin ほか 2021年)
図 1 の (a) と (b) の違いが、後の MDLM / SEDD で「どちらの方向に進むか」を分けるキーになる。
学習目標
D3PM の学習は ELBO の variational lower bound(VLB) をそのまま最適化する形を取る。reverse モデル \(p_\theta(x_{t-1} \mid x_t)\) を訓練する KL 項の総和が損失となる。
\[ \mathcal{L}_{\text{VLB}} = \mathbb{E}_q \Bigl[ \underbrace{D_{\text{KL}}\bigl(q(x_T \mid x_0) \,\|\, p(x_T)\bigr)}_{L_T} + \sum_{t > 1} \underbrace{D_{\text{KL}}\bigl(q(x_{t-1} \mid x_t, x_0) \,\|\, p_\theta(x_{t-1} \mid x_t)\bigr)}_{L_{t-1}} - \log p_\theta(x_0 \mid x_1) \Bigr] \]
実装上は、reverse posterior \(q(x_{t-1} \mid x_t, x_0)\) がカテゴリカル分布なので、各時刻で離散分布同士の KL を直接計算できる。
何を学べるか
D3PM の価値は次の 3 点に集約される。
- 離散変数の forward / reverse 過程 が連続版(DDPM)と同型に組めることを示した
- 遷移行列の選択がモデルの性質を決める ことを統一的フレームワークで示した
- MDLM が選んだ absorbing transition がなぜ簡潔な目的関数につながるかの背景を提供する
特に最後の点は重要である。absorbing transition では、\(x_t\) は [MASK] 化された位置と元のトークンが残った位置の混合になるため、reverse posterior が「マスク位置を \(x_0\) で埋める」という単純な構造に縮退する。この縮退が MDLM の重み付き masked CE 損失を導く。
SEDD: Score Entropy Discrete Diffusion
位置づけ
SEDD(Score Entropy Discrete Diffusion)(Lou ほか 2024年) は、masked / absorbing 以外の離散拡散の定式化として ratio matching(concrete score の学習)を提案した。連続拡散における score matching の離散版とみなせる枠組みである。
連続側では「スコア \(\nabla_x \log p(x)\) を学習する」という強力な抽象化が存在するが、離散変数には微分が定義できないためそのままでは使えない。SEDD はこの問題を「スコアの代わりに確率比を学習する」ことで解決した。
Concrete score(確率比)
離散変数 \(x\) について、SEDD は次の concrete score を学習対象とする。
\[ s_\theta(x)_y = \frac{p(y)}{p(x)} \quad (y \neq x) \]
これは「現在 \(x\) にいるとき、別のトークン \(y\) へ移る相対的な確率」を表す比であり、連続側の \(\nabla \log p\) の離散類似物に相当する。連続側でスコアが「方向」を表すのに対し、こちらは「どのトークンへ向かう確率が高いか」を表す。
Score entropy 損失
SEDD は denoising score matching(DSM)の離散版として、score entropy という新しい損失を提案した。
\[ \mathcal{L}_{\text{SE}} = \mathbb{E}_{t, x_t, x_0} \sum_{y \neq x_t} w_t(x_t, y) \Bigl[ s_\theta(x_t, t)_y - \frac{q_{t|0}(y \mid x_0)}{q_{t|0}(x_t \mid x_0)} \log s_\theta(x_t, y) \Bigr] \]
ここで \(w_t\) は遷移強度に応じた重み、第 2 項の比 \(q_{t|0}(y \mid x_0) / q_{t|0}(x_t \mid x_0)\) が学習の教師信号となる concrete score の真値である。DSM の Bregman divergence による導出に対応するもので、\(s_\theta \to p(y)/p(x)\) で最小化されることが示される。
何を学べるか
SEDD は次の点で価値がある。
- 離散拡散における 「スコア概念」の代替(ratio matching) を確立した
- absorbing に限定せず、uniform を含む任意の transition で動く 一般性を持つ
- MDLM の選択(スコアを諦めて \(x_0\)-prediction)と対比される定式を提示
- AR LLM の perplexity を 一部のベンチで上回る 結果を出し、離散拡散がスケールしうることを示した
ただし、損失の実装が MDLM の masked CE に比べて複雑であり、安定性のチューニングも必要となる点が大規模展開時のハードルとなる。
三者の比較
D3PM、MDLM、SEDD は同じ「離散拡散」という土俵に立ちつつ、異なる選択をしている。
| 項目 | D3PM | MDLM | SEDD |
|---|---|---|---|
| 時刻 | 離散 | 連続時間 | 連続時間 |
| Transition | 一般(uniform / absorbing / Gaussian / NN) | absorbing のみ | 一般 |
| 学習対象 | reverse posterior の Cat 分布 | \(x_0\)-prediction (CE) | concrete score / ratio |
| 損失 | ELBO の VLB 直接 | 重み付き masked CE(簡潔) | score entropy |
| 数学的位置づけ | foundational | absorbing の簡潔化 | ratio matching |
| 主な貢献 | 離散拡散の枠組み | 実装の簡潔さ | スコア類似物の確立 |
表 1 を眺めると、D3PM が「上位概念」として枠組みを提供し、MDLM がその中で absorbing に絞り込んで実装を単純化、SEDD は別軸で ratio matching に一般化 した、という構図が見える。
なぜ MDLM が「勝った」のか
ノートMDLM の優位性についての考察
MDLM が DLLM のスケールアップで主流になった主要因は次の 3 点である。
- 目的関数の単純さ: 損失が「マスク位置の cross-entropy に \(1/t\) の重みを乗せる」だけで、BERT 訓練とほぼ同じコードで動く。デバッグも訓練の挙動把握も容易である。
- 絞り込まれた選択: absorbing 限定で reverse posterior が「マスクを埋める」という単純な操作に縮退するため、実装が単純になり、スケールしやすい。
- 理論と実装の距離が近い: confidence-based unmasking(後述する MaskGIT 由来のサンプラ)が absorbing transition と相性が良い。「
[MASK]をどう埋めるか」という直感的な操作がそのまま reverse 過程になっている。
SEDD はより一般的だが、損失の実装の複雑さと数値安定性で大規模展開には不利である。score entropy の重み付けや、確率比の指数化に伴う数値処理は、masked CE のような「BERT そのまま」というレベルの単純さには到達しない。
D3PM は研究のフレームワークとしては今も価値がある。新しい遷移行列を試したり、離散拡散の理論的性質を分析したりする際の出発点として参照される。
他の DLLM 派生について
ノートDream: LLaDA の対抗モデル
Dream(Ye+ 2025)も masked diffusion を採用しているが、初期化や訓練レシピが LLaDA と異なる。具体的には、事前学習済み AR LLM の重みからの初期化や、独自のマスク schedule などが特徴となる。
LLaDA との比較は近年の DLLM 論文で頻出する。両者ともに MDLM の定式化(absorbing transition + 重み付き masked CE)の上に立っており、違いは「どう訓練するか」「どこから初期化するか」というレシピのレベルである。定式化が共有されているため、結果の比較がしやすい点も MDLM が主流になった理由のひとつである。
読み方の推奨
各論文を全部読むのは負担が大きいので、目的に応じた読み方を提案する。
- D3PM: §3 の forward 過程の定義と §4 の VLB は通読する価値がある。各 transition(uniform / absorbing / discretized Gaussian / nearest-neighbor)の表は参照用に手元に置いておくと良い。
- SEDD: §3 の concrete score の定義と §4 の score entropy 損失を中心に読む。実装はやや複雑なので、論文の付録の擬似コードと合わせて読むと理解しやすい。
- 時間がない場合: MDLM を理解した後にこれら 2 本を scan する読み方が最も効率的である。MDLM が「特殊化」、SEDD が「別軸の一般化」、D3PM が「上位概念」と位置づけが見えてから読むと、各論文の貢献が立体的に把握できる。
関連章へのリンク
- 主軸の定式化: MDLM
- 連続側との比較: 連続拡散と離散拡散の橋渡し
- 全体俯瞰: DLLM 全体像
参考文献
Austin, Jacob, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, と Rianne van den Berg. 2021年. 「Structured Denoising Diffusion Models in Discrete State-Spaces」. Advances in Neural Information Processing Systems. https://openreview.net/forum?id=h7-XixPCAL.
Ho, Jonathan, Ajay Jain, と Pieter Abbeel. 2020年. 「Denoising Diffusion Probabilistic Models」. Advances in Neural Information Processing Systems. https://arxiv.org/abs/2006.11239.
Lou, Aaron, Chenlin Meng, と Stefano Ermon. 2024年. 「Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution」. Proceedings of the 41st International Conference on Machine Learning. https://arxiv.org/abs/2310.16834.
Sahoo, Subham Sekhar, Marianne Arriola, Yair Schiff, ほか. 2024年. 「Simple and Effective Masked Diffusion Language Models」. Advances in Neural Information Processing Systems. https://openreview.net/forum?id=L4uaAR4ArM.