LLaDA
LLaDA(Large Language Diffusion with mAsking)(Nie ほか 2025年) は、masked diffusion language model(MDLM)(Sahoo ほか 2024年) の定式化を 8B パラメータにスケールし、自己回帰(Autoregressive, AR)LLM と同程度の性能を達成した最初の本格的な Diffusion Language Model(DLLM)である。MDLM が定式化の中核を提供したのに対し、LLaDA は「定式化を実装に落としたとき何が起こるか」を網羅的に示した報告であり、サンプリング戦略の具体的な実装と 指示追従(instruction-following)の Supervised Fine-Tuning(SFT) が論文の中心を占める。
なぜ LLaDA を読むべきか
MDLM は「重み付き BERT 訓練」という極めて簡潔な目的関数で DLLM の訓練を表現する。しかし、
- それを 8B 規模で訓練すると AR LLM と同等の scaling が得られるのか
- 訓練後の 推論ループはどう設計するか
- 指示追従は AR と同じやり方で SFT できるのか
という実装側の疑問は、MDLM の論文だけからは読み取れない。LLaDA はこれらに対する現時点で最も詳細な answer を提供している。本章では、特に推論ループとサンプリング戦略に焦点を当て、論文を読む際の道標を示す。
LLaDA は MDLM の定式化を継承しつつ、absorbing transition + \(x_0\)-prediction CE という極めて素直な選択をしている。新規の数学的貢献よりも、スケールと実装の選択が論文の主な貢献である。
押さえるべき要素
サンプリング手順の全体像
LLaDA の推論は、AR LLM の左から右へのループとは根本的に異なる。全位置を [MASK] で初期化し、各ステップで全位置に予測を出し、信頼度の高い位置から順次確定していく。
このループの 1 ステップを擬似コードで書くと次のようになる。
# x: 現在のトークン列(一部 [MASK]、一部確定済み)
# steps: 総ステップ数 T
# k_t: ステップ t で unmask する個数
for t in range(T, 0, -1):
# 1. forward pass: 全位置に対する分布を得る
logits = model(x) # [seq_len, vocab_size]
probs = softmax(logits)
# 2. masked 位置のみを対象に信頼度を計算
mask_positions = (x == MASK_ID)
pred_tokens = argmax(probs, dim=-1) # 各位置の予測
confidence = max(probs, dim=-1) # 各位置の信頼度
# 3. masked 位置の中で信頼度上位 k_t 個を unmask
masked_conf = confidence[mask_positions]
topk_idx = topk(masked_conf, k_t)
x[topk_idx] = pred_tokens[topk_idx]
# 4. 残った masked 位置はそのまま [MASK]
# (low-confidence remasking では確定済み位置も再マスク可)ポイントは次の 3 つである。
- forward pass をステップごとに毎回回す(AR の KV-cache の素朴な転用は効かない)
- 確定順序は左→右ではなく、信頼度の降順
- ステップごとの unmask 個数 \(k_t\) は schedule(線形、cosine 等)で決める
Unmask 個数 \(k_t\) の schedule
ステップ \(t\) で何個 unmask するかは事前に決められた schedule に従う。代表的な選択肢は以下の通りである。
- Linear schedule: \(k_t = L/T\) で一定。各ステップで同じ個数を確定
- Cosine schedule: 最初と最後を疎、中盤を密にする。MaskGIT 由来で画像生成では標準
- Exponential schedule: 後半ほど多く unmask。早期に確定した位置の品質を担保する設計
総ステップ数 \(T\) と系列長 \(L\) の関係は、\(T = L\)(毎ステップ 1 個)から \(T \ll L\)(毎ステップ多数)まで連続的に選べる。\(T\) を小さくするほど推論は速いが、誤り訂正の機会が減るため品質は低下する。
Low-confidence remasking
LLaDA の実装現場での核心は、low-confidence remasking と呼ばれる戦略である。一度 unmask した位置でも、その後のステップでより信頼度の低い位置として判定されれば、再度 [MASK] に戻す。
数学モデル上、absorbing transition の reverse 過程は「[MASK] から非 [MASK] への 1 方向遷移」しか定義されていない。理論的には一度 unmask した位置は戻らない。それにも関わらず実装では再マスクが行われるのはなぜか。
理論と実装のギャップが生まれる理由は以下の通りである。
- 誤り訂正の必要性: 早期ステップで低信頼度のまま確定した位置は、後段の文脈が見えるにつれて誤りが明らかになる。再マスクして他の位置の情報を取り込み直すことで訂正の機会が得られる
- 訓練時の分布との整合: 訓練時は任意の mask 率 \(t \in [0,1]\) で BERT 的に学習されているため、推論時に部分的にマスクされた状態を再度通すことは訓練分布の範疇に収まる
- mask schedule との分離: 数学的 schedule(時刻 \(t\))と実装的 schedule(実際にいくつ unmask するか)を分離することで、ステップ数と品質のトレードオフを実装側で調整できる
absorbing diffusion の定式化はあくまで 訓練目的関数を導出するための道具であり、推論時のサンプリング戦略は別物として扱える。MDLM の ELBO は「forward 過程に対する変分下界」であり、推論ループそのものを規定しない。LLaDA は ELBO 最適化と独立に推論ループを設計している、と理解すると見通しがよい。
Semi-autoregressive sampling
LLaDA はさらに semi-autoregressive sampling という戦略を提案している。これは系列全体を一度に並列生成するのではなく、ブロック単位で生成する方式である。
- 系列をブロック \(B_1, B_2, \dots, B_M\) に分割
- ブロック内は並列に DLLM 的な unmask
- ブロック間は AR 的に逐次(\(B_1\) を完成させてから \(B_2\) に進む)
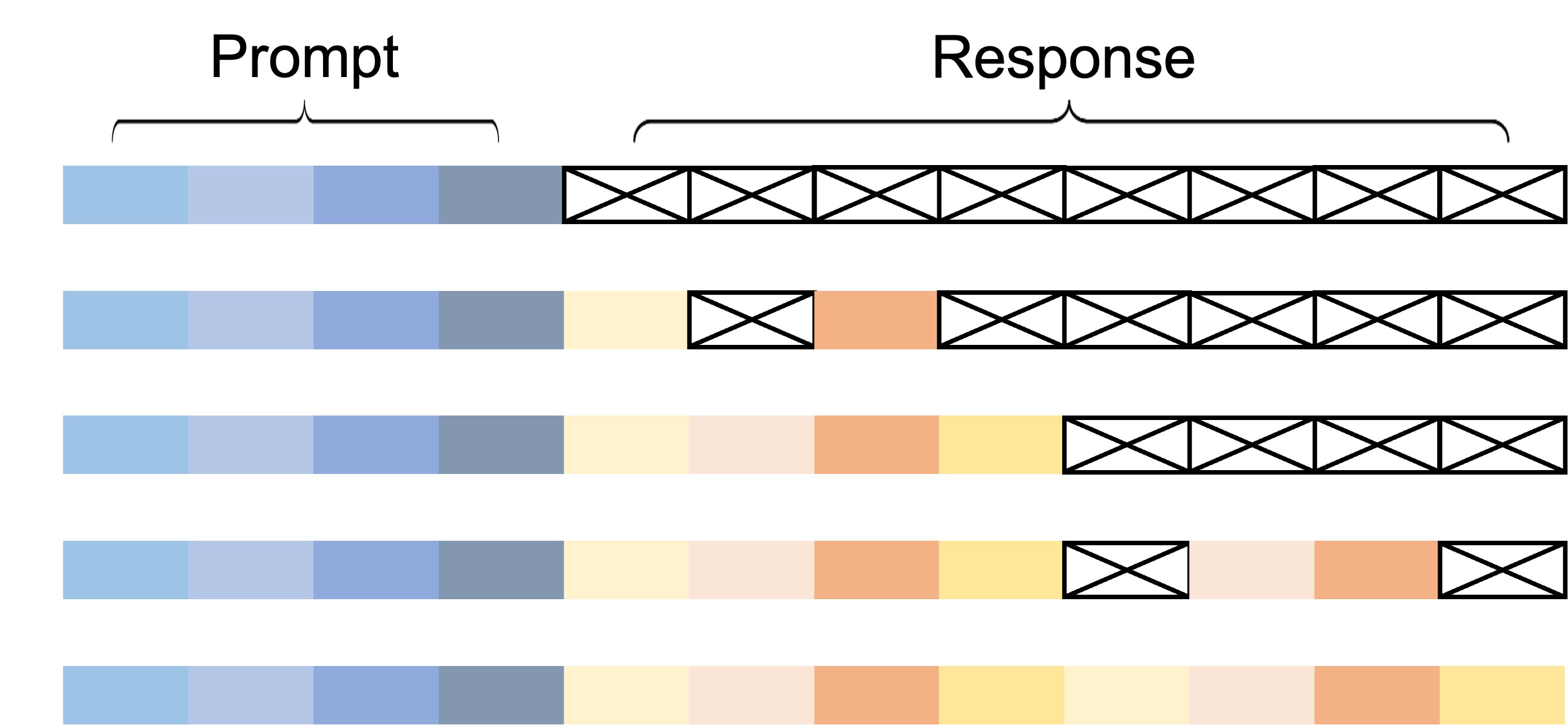
この設計の意図は次の通りである。
- AR LLM 的な趣の保持: 長い系列で発生しがちな大域的整合性の崩れを防ぎ、左から右への因果的な流れを保つ
- KV-cache の活用: 既に確定したブロックは KV-cache に入れられるため、後続ブロックの forward pass を高速化できる
- 品質と並列性のトレードオフ調整: ブロックサイズで AR 寄り(小ブロック)と並列寄り(大ブロック)の連続的な選択ができる
Scaling 曲線
LLaDA の論文の中盤は、8B モデルが AR LLM と同程度に scale するという事実の実証に充てられている。GSM8K、MATH、MMLU、HumanEval、BBH 等の標準的なベンチマークで、同程度の訓練計算量の AR LLM と並ぶスコアが得られている。
| 観点 | 観察 |
|---|---|
| スケーリング指数 | AR LLM とほぼ同等の指数で性能向上 |
| in-context learning | few-shot 性能も AR と同等に発現 |
| 推論タスク(数学等) | 同規模の AR LLM と互角の領域に到達 |
| 計算効率(推論時) | ステップ数 \(T\) に依存。\(T \ll L\) で並列性が活きる |
具体的な数値は論文に譲るが、ポイントは「DLLM は scaling law の点で AR LLM のオルタナティブとして成立する」という事実の確立にある。
指示追従の SFT
masked DLM をどう instruction-tune するかは、AR LLM の SFT と異なる工夫が必要である。LLaDA は次のような戦略を採用している。
- prompt-response 形式: 入力は
prompt + [MASK]*Lとして与え、response 部分のみを mask 対象にする - mask 率の schedule: 訓練時の mask 率 \(t\) は \([0,1]\) から一様にサンプル(事前学習と同じ)。応答全体が
[MASK]の状態(\(t=1\))も含む - 損失計算: cross-entropy の重み \(1/t\) も事前学習と同じで、追加の SFT 専用ロスは導入しない
つまり SFT は「事前学習の延長で、prompt を condition とする条件付き訓練」として実装される。AR LLM の SFT が「次トークン予測ロスを応答部分のみに限定する」のと構造的には対応している。
prompt は 常に観測済み(mask されない)として与え、response 部分のみが diffusion の対象になる。これは AR LLM で prompt を context として与え、response 部分のみで loss を取るのと同じ発想である。
読み方の優先順位(論文セクション)
論文は規模が大きいため、目的に応じて読む順を絞ると効率的である。
| セクション | 重要度 | 内容 |
|---|---|---|
| §2 formulation | 必読 | MDLM とほぼ同じ定式化であることを確認 |
| §3 sampling | 最重要(2 周以上) | 推論ループ・remasking・semi-AR の実装詳細 |
| §4 results | scan | スケール結果と他モデル比較 |
| §5 analyses | 興味次第 | mask 率の影響、ステップ数の効果等の詳細分析 |
§2 formulation(必読)
MDLM の定式化を踏襲していることを確認するだけでよい。新規の数学的貢献はほぼなく、LLaDA = MDLM at 8B + 実用サンプラという理解で問題ない。
§3 sampling(最重要)
論文の本質。次の点を 2 周以上読むことを推奨する。
- 基本ループの確認(forward → confidence sort → unmask top-k → repeat)
- low-confidence remasking の挙動と、なぜそれが効くかの説明
- semi-autoregressive sampling の動機とブロックサイズの選び方
- 温度・top-p などの確率的サンプリングと greedy unmask の関係
§4 results(scan)
性能比較表を眺めて、AR LLM と同程度に scale する事実を確認するだけで十分である。具体的なベンチマークスコアの暗記は不要。
§5 analyses(興味次第)
mask 率の schedule、ステップ数 \(T\) と品質の関係、ブロックサイズの影響などの ablation。実装する際に戻ってくる参照として読む。
この論文を読んだ後に分かること
LLaDA を読み終えると、次の 3 点が具体的なイメージで理解できるようになる。
- DLLM の推論が具体的にどんなループか: 「forward → confidence sort → unmask top-k → repeat」という構造の解像度が上がる。AR LLM の
for i in range(L): generate(x[:i])と対比して頭に入る - なぜ低温度で trajectory collapse するのか: confidence sort が argmax 的に高度に決定論的なため、温度を下げると毎回ほぼ同じ生成軌道になる。多様性を得るには confidence のサンプリング側に温度を乗せる必要がある、という感覚が掴める
- 推論時介入が乗る具体的な「段」が見える: forward pass の出力、confidence の計算、unmask 個数の決定、remask の選択など、ステップごとに介入できる「段」が複数あることが明確になる。AR LLM では「各位置の logit」しか介入点がないのと対照的
サンプリング戦略の比較
LLaDA 周辺で使われる主なサンプリング戦略は次の通り。それぞれ品質 / 多様性 / 計算量のトレードオフが異なる。
- Greedy unmask: 各ステップで信頼度上位 \(k\) を確定(決定論的)。最も素朴で高速だが、多様性に乏しく trajectory collapse しやすい
- Stochastic sampling: 信頼度を温度付きでサンプル(Gumbel-top-k 等)。多様性が出る代わりに 1 回あたりの品質はやや下がる
- Semi-autoregressive: ブロック内は並列、ブロック間は逐次。AR 的な大域整合性と DLLM の並列性を両立
- Remasking: 一度 unmask した位置を再マスクし戻す余地を残す。誤り訂正の機会を作るが、ステップ数が増える
実装では、これらを組み合わせて使う(例: semi-AR + remasking + stochastic)のが標準的である。
戦略の組み合わせの例
| 設定 | 用途 | 特徴 |
|---|---|---|
| Greedy + 並列 | 高速生成 | 速いが trajectory collapse のリスク |
| Stochastic + 並列 | 多様性重視 | サンプル間の違いを出したい場合 |
| Semi-AR + Greedy | 安定生成 | KV-cache 活用、長文の整合性確保 |
| Semi-AR + Remasking | 高品質生成 | 計算量と引き換えに品質を取りに行く |
実装上の注意点
LLaDA を実際に動かす際に陥りやすい落とし穴がいくつかある。
KV-cache の扱い
AR LLM の KV-cache は「直前のトークン位置の K/V を保持し、新しいトークン位置の attention 計算を高速化する」仕組みである。DLLM では各ステップで 系列全体の forward pass を回すため、素朴な KV-cache の流用は効かない。
- 基本ループでは KV-cache 不可: 各ステップで全位置の予測を更新するため
- Semi-AR では部分的に利用可能: 確定済みブロックは固定とみなして KV-cache できる
- prefix が固定の場合: prompt 部分は常に観測済みなので KV-cache の対象になる
ステップ数と品質のトレードオフ
ステップ数 \(T\) は推論コストを線形に支配する。\(T = L\)(毎ステップ 1 個 unmask)は AR LLM と同じコストに近づくが、AR と違って毎回全位置の forward を回すため実コストは高い。\(T \ll L\) にすると並列性が活きるが、誤り訂正の機会が減る。
| \(T\) の選び方 | 推論コスト | 品質 | 並列性 |
|---|---|---|---|
| \(T = L\) | 最大(AR より高い) | 最も高い | 低 |
| \(T = L/4\) | 1/4 | やや低下 | 中 |
| \(T = L/16\) | 1/16 | 明確に低下 | 高 |
| \(T = 1\) | 1(1 ステップ) | 大幅低下 | 最大 |
温度と多様性
confidence-based unmask は本質的に argmax 寄りの操作のため、AR LLM の temperature=0.7 程度の温度では十分な多様性が得られない。多様性を制御する箇所は次の 2 段ある。
- トークン予測の温度: 各位置で argmax ではなく softmax の温度サンプリング
- 位置選択の温度: confidence 上位 \(k\) を確定する際に Gumbel-top-k 等で確率的に選ぶ
後者の「位置選択の温度」は AR LLM には存在しない DLLM 固有の制御点である。
連続拡散モデルとの対比
LLaDA のサンプリングループは、連続拡散モデルの reverse SDE / probability flow ODE のサンプリングと構造的には対応するが、操作対象が異なる。
- 連続拡散: 連続値 \(x_t\) から \(x_{t-\Delta t}\) へノイズを除去
- LLaDA: 一部
[MASK]の系列から、より少ない[MASK]の系列へ離散的に遷移
連続拡散では「全座標が連続値として滑らかに更新される」のに対し、LLaDA では「一部の [MASK] 位置が離散的に確定する」という違いがある。confidence sort は、連続拡散における どの座標を先に更新するかという分散制御に対応する操作と見ることもできる。
詳細は 連続拡散と離散拡散の橋渡し を参照。
関連手法へのリンク
- 土台となる定式化: MDLM: Masked Diffusion Language Models
- confidence-based unmask の源流: MaskGIT: Confidence-based Iterative Unmasking の源流
- DLLM 分野の現状: DLLM 分野の現状と未解決問題
本章で言及した MaskGIT (Chang ほか 2022年) のサンプリング戦略については 5 章で詳述する。