MaskGIT
MaskGIT (Chang ほか 2022年) は画像生成の論文であるが、現在の Diffusion Language Model(DLLM)のサンプリング戦略の 直接的な起源 である。LLaDA (Nie ほか 2025年) や Dream に代表される「全位置 [MASK] で初期化し、信頼度の高い位置から段階的に確定していく」という反復生成のアルゴリズムは、形式上ほぼ MaskGIT そのものを言語に移植したものとみなせる。本章は MaskGIT の枠組みを概観し、現在の DLLM サンプリングとの繋がりを示す。
なぜ言語モデルの本で MaskGIT を扱うのか
DLLM のサンプラ(信頼度上位 \(k\) を unmask する反復生成)の核となるアイデアは、画像生成側で先に確立されていた。MaskGIT は「離散トークンに対する反復生成 + 信頼度ベースの段階的確定」という枠組みを画像生成で示し、これが言語側にそのまま輸入された。歴史的経緯と設計動機を理解するために、MaskGIT を一度押さえておく価値は大きい。
特に、現在の DLLM の論文を読む際には、次のような疑問が頻出する。
- なぜサンプリング時に「信頼度の高い位置から確定する」のか、別の順序ではダメなのか
- なぜステップ数を増やすと品質が上がるのか、1 ステップではダメなのか
- なぜスケジュール(各ステップで何個 unmask するか)が重要なのか
これらの設計判断の妥当性は、MaskGIT の論文中のアブレーション実験で 画像側で先に検証済み である。言語側の各論文では既知の前提として扱われがちなため、初出の文脈を確認しておくと理解が早い。
本章は画像生成の論文を扱うが、目的は 画像生成手法の解説ではなく、現在の DLLM サンプラ設計の起源とその設計判断の根拠を確認することである。Vector-Quantized GAN(VQ-GAN)による離散化や Fréchet Inception Distance(FID)評価の詳細には立ち入らず、サンプリングアルゴリズムに集中する。
MaskGIT の枠組み
全体構成を先に俯瞰しておく。MaskGIT は「離散トークン化 → bidirectional transformer の学習 → 反復サンプリング」という 3 段構成である。本節では設定、訓練、サンプリングの順に確認する。
設定
MaskGIT は次の 2 段階の構成を取る。
- 画像を VQ-GAN で離散トークン列に圧縮(例: \(16 \times 16\) のグリッドで合計 256 トークン)
- このトークン列に対して bidirectional transformer を学習
訓練は BERT 風の masked token prediction である。具体的には、各サンプルに対してマスク率 \(r \sim \text{Uniform}(0, 1)\) をサンプルし、トークン列の \(r\) の割合をランダムに [MASK] に置き換え、これを復元するクロスエントロピー(cross-entropy, CE)損失を取る。マスク率を「ランダムに広く取る」点が標準 BERT との違いであり、推論時に「序盤の高マスク率」と「終盤の低マスク率」の両方を経験させる狙いがある。
訓練の損失関数を式で書けば、
\[ \mathcal{L}_{\text{MaskGIT}} = - \mathbb{E}_{r \sim \mathcal{U}(0,1)} \mathbb{E}_{x, M_r} \sum_{i \in M_r} \log p_\theta(x_i \mid x_{\bar{M}_r}) \]
ここで \(M_r\) はマスク率 \(r\) でランダムに選ばれたマスク位置の集合、\(x_{\bar{M}_r}\) はマスクされていない位置のトークン列である。これは後に MDLM で示される masked diffusion の変分下限(Variational Lower Bound, VLB)と本質的に同じ形をしている。
サンプリング手順(核心)
MaskGIT のサンプリングは、全位置を [MASK] で初期化し、\(T\) ステップで全位置を確定していく反復ループである。
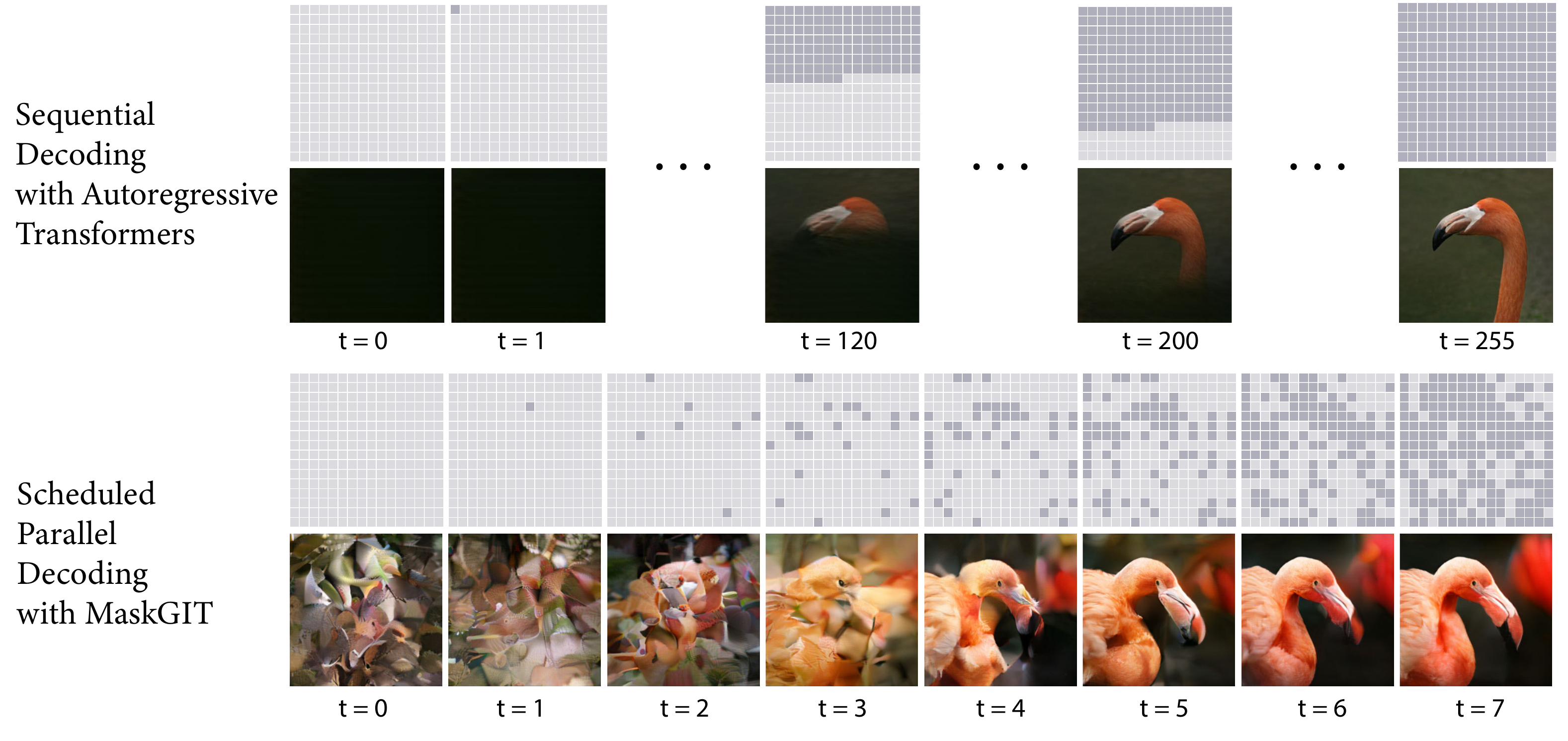
図 1 が MaskGIT の本質を端的に示している。並列に予測 → 信頼度の高い箇所を確定 → 残りを再帰的に埋める という DLLM サンプラと同型の構造が、画像生成で先に確立されていた。
擬似コードで書くと次のようになる。
# T: 総ステップ数(典型的に 8〜16)
# N: トークン列の長さ
# x: 現在のトークン列(初期は全て [MASK])
x = [MASK] * N
for t in range(1, T + 1):
# 1. forward: 全位置の分布を得る
logits = transformer(x) # [N, V]
probs = softmax(logits / temp, dim=-1)
# 2. 各位置で候補トークンを取る(argmax or sample)
pred = probs.argmax(dim=-1) # [N]
conf = probs.max(dim=-1) # [N]、各位置の信頼度
# 3. このステップで残しておくマスク数を決める
mask_ratio = cosine_schedule(t / T) # gamma(t/T) = cos(pi/2 * t/T)
n_mask = ceil(mask_ratio * N)
# 4. 信頼度の低い方から n_mask 個を [MASK] のままに、
# 残り(信頼度上位)は pred で確定
sorted_idx = argsort(conf) # 信頼度の低い順
keep_masked = sorted_idx[:n_mask]
x = pred.clone()
x[keep_masked] = MASKここで重要なのは「一度確定した位置は基本的に再度マスクされない」点である。スケジュールが単調減少なので、ステップ \(t\) で確定した位置は以降のステップでも確定済みのまま扱われる。後の Token-Critic ではこの制約を緩めるが、基本版の MaskGIT では確定後の再考は行われない。
鍵となる工夫
MaskGIT の品質を支えているのは、次の 3 つの相互に関連した設計判断である。
- Cosine masking schedule: 序盤は少しだけ unmask(多くを
[MASK]のまま残す)、終盤に多く unmask する。\(\gamma(t/T) = \cos(\frac{\pi}{2} \cdot t/T)\) のような単調減少関数で、「難しい位置を後回しにする」効果がある。 - Confidence-based selection: 何を unmask するかをモデル自身の信頼度(top-1 確率)で決める。AR の固定順序(左から右)とは違い、文脈が十分に固まった位置から順に確定する。
- Iterative refinement: 1 ステップで全部を決めずに、複数ステップに分けて段階的に確定する。各ステップで他位置の確定情報が増えるため、後のステップほど予測が容易になる。
これら 3 つは独立に有効なのではなく、組み合わさってはじめて品質が出る。論文中のアブレーションでも、いずれか 1 つを外すと品質が大きく劣化することが示されている。
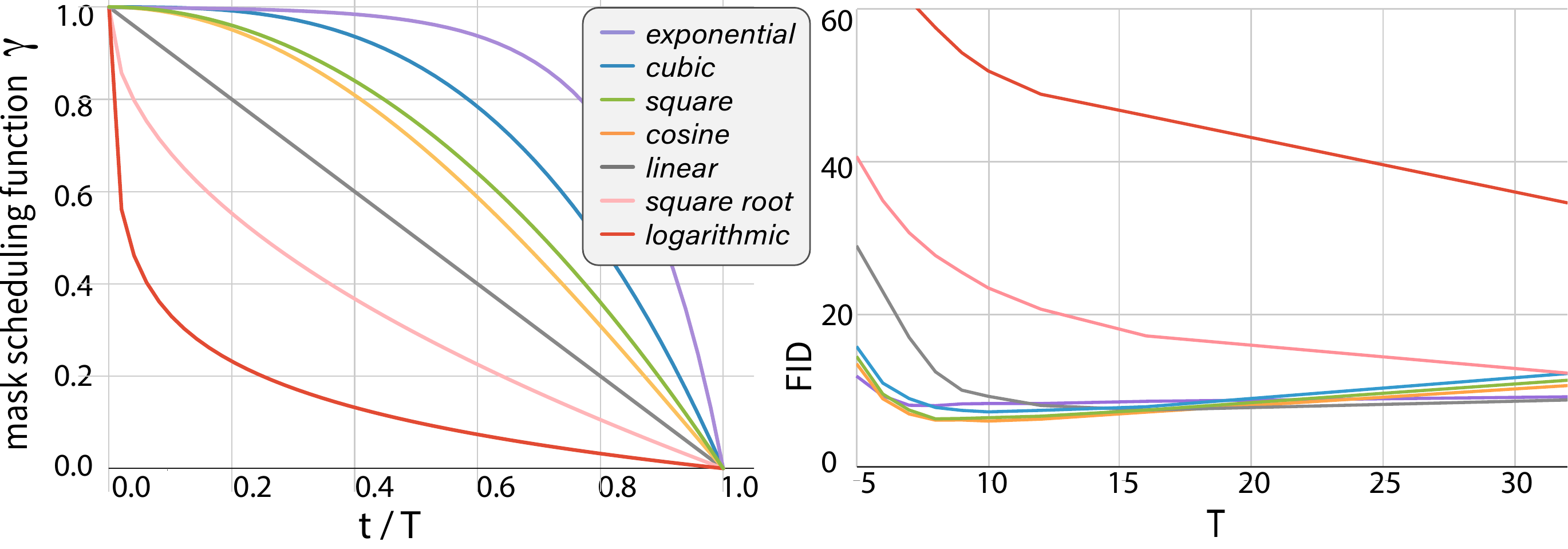
図 2 は、スケジュール関数の選択が品質に直接効くことを示している。「序盤は少しずつ、終盤に多く unmask」という単調減少の形状そのものが重要であり、形が極端だと品質が崩れる。「コサインスケジュールを線形スケジュールに置き換える」だけで FID が悪化すること、「信頼度上位を選ぶ」のではなく「ランダムに選ぶ」と AR 並みのステップ数を要するようになることも、3 要素が相互に支え合うことを示唆している。
DLLM サンプラとの対応
MaskGIT と LLaDA のサンプリングを並べると、ほぼ全ての要素が一対一に対応していることがわかる。
| 要素 | MaskGIT (画像) | LLaDA (言語) |
|---|---|---|
| トークン化 | VQ-GAN で離散化 | BPE 等で離散化(自然に離散) |
| Backbone | Bidirectional Transformer | Bidirectional Transformer |
| 訓練 | ランダムマスク予測 (BERT 風) | masked diffusion CE |
| サンプリング初期化 | 全位置 [MASK] |
全位置 [MASK] |
| Unmask 戦略 | 信頼度上位 \(k\)、コサインスケジュール | 信頼度上位 \(k\) |
| ステップ数 | 8〜16 程度 | 数十〜数百 |
| 確定後の扱い | 確定 (basic) / 再考あり (variant) | 確定 (absorbing) / 低信頼度位置を remask |
表 1 が示すとおり、両者は本質的に 同じアルゴリズムを異なるドメインに適用したもの である。違いは主に次の 2 点に集約される。
- トークン化の経路: 画像は VQ-GAN を介して離散化する必要があるが、テキストは元から離散である。これは MaskGIT 側の固有の制約であり、サンプリング戦略本体には影響しない。
- ステップ数の規模: MaskGIT は 8〜16 ステップで完結するが、LLaDA は典型的に数十〜数百ステップを使う。これはトークン列の長さ(256 vs. 数千)と要求される品質の違いによる。
さらに細かい違いを挙げれば、画像側は 位置間の局所的な空間相関(隣接ピクセル)が強く、確定の伝播が比較的容易なのに対し、言語側は 長距離の依存(数百トークン離れた共参照、構文的整合性)が頻出するため、ステップ数を多めに取って各位置を慎重に確定する必要がある。これは「ドメインの違いに起因する量的な差」であり、アルゴリズム本体の構造には変更を要求しない。
MaskGIT が示した重要な洞察
MaskGIT の論文は単にアルゴリズムを提示しただけでなく、設計判断それぞれが品質に効くことを実験で示した。具体的には、ImageNet \(256^2\) の class-conditional 画像生成において、当時の AR ベースラインを大きく上回る FID を、8 ステップという少ないステップ数で達成した。これは「ステップ数を増やせば品質が出る」というスケーリング側の主張だけでなく、「少ないステップ数でも適切な設計なら高品質が出る」という効率側の主張でもある。
ここから DLLM サンプラ設計に持ち越せる教訓を 3 つ抽出する。
信頼度ベースの順序付けは強力
「どの位置から確定するか」をモデルの信頼度で決めると、難しい位置を文脈が固まってから扱える。これは固定順序(左から右)の AR より柔軟であり、特に「中央が分かれば両端が決まる」ようなパターン(画像の場合は構造的な位置関係、言語の場合は構文的な依存関係)に強い。
別の見方をすれば、信頼度ベースの順序付けは モデル自身に確定順序を選ばせている とも言える。AR モデルは「左から右」という外部的に決められた順序に従うが、MaskGIT 系は確信のある位置を優先するため、データに含まれる依存構造に適応した順序を自然に取る。これは原理的には AR より柔軟だが、信頼度のキャリブレーションが悪いと逆効果(高信頼度な誤りを確定してしまう)になる弱点も持つ。
1 ステップでの全部決めはダメ
非自己回帰(NAR)の素朴な発想は「並列に全部を一気に予測する」ことだが、これでは品質が大きく劣化する。Bidirectional transformer は各位置の周辺文脈に依存して予測を出すため、「全位置が [MASK]」という初期状態からの 1 ステップ予測は実質的に 無条件サンプル に近く、出力がバラバラになる。iterative refinement は本質的に必要である。
これは確率モデル的に見れば自然である。\(p_\theta(x_i \mid x_{\bar{M}})\) は他位置 \(x_{\bar{M}}\) の条件付き分布として学習されているため、\(x_{\bar{M}}\) が空(全位置がマスク)のときの予測は、本質的に 周辺分布 に近い。各位置を独立に argmax / sample で取ると、位置間の同時整合性が崩れる。ステップ数を増やして「一部位置の確定を条件として残り位置の予測を見直す」のは、この同時整合性を取り戻す手続きである。
スケジュール設計が品質を決める
「ステップごとに何個 unmask するか」のスケジュールが品質に強く影響する。MaskGIT の論文は線形 / コサイン / quadratic / cubic などを比較し、コサイン(序盤少なく、終盤多く unmask)が最良であることを示している。これは「序盤は少数の確定で済ませて文脈を作り、終盤の確定は容易にする」という直観と一致する。
スケジュール関数 \(\gamma(\tau)\)(\(\tau = t/T \in [0, 1]\))が満たすべき条件は次のとおりである。
- \(\gamma(0) = 1\)(最初は全位置がマスク)
- \(\gamma(1) = 0\)(最後は全位置が確定)
- 単調減少
- 「序盤は緩やかに減少、終盤に急速に減少」という凹形状
コサイン関数 \(\gamma(\tau) = \cos(\frac{\pi}{2} \tau)\) はこれらを自然に満たす。線形関数 \(\gamma(\tau) = 1 - \tau\) は凹形状でないため、序盤に多くを確定しすぎてしまい品質が落ちる。
MaskGIT の経験から DLLM 設計に持ち越せること:
- コサインスケジュールは DLLM でも候補になる。実際 LLaDA を含む多くの DLLM サンプラが近い形状のスケジュールを採用している。
- 信頼度の温度付きサンプルで多様性を制御できる。argmax だと決定的すぎ、温度を上げすぎると品質が落ちる。MaskGIT は中庸の設定が良いと報告している。
- 複数ステップ間のフィードバック(中間で予測を見て次のステップの戦略を決める)の余地はまだ広く残されている。MaskGIT は固定スケジュールだが、動的な調整は今後の余地がある。
MaskGIT 以降の発展(短く)
MaskGIT 以降、画像側で関連手法がいくつか登場している。サンプリング戦略の改良という観点では言語側にも応用が利く。主要な発展を時系列で示す。
| 手法 | 年 | 主な貢献 |
|---|---|---|
| MaskGIT | 2022 | 信頼度ベース反復生成の確立 |
| Token-Critic | 2022 | 確定後の再考(remasking)を別モデルで判定 |
| MUSE | 2023 | テキスト条件付きへの拡張 |
| MAGVIT 系 | 2023〜 | 動画への拡張、トークン化の改良 |
| MaskBit | 2024 | ビット単位トークン化と組み合わせた効率化 |
このうち、DLLM 側に直接持ち越せる教訓を含むものを補足する。
- MUSE は条件付き生成への拡張で、cross-attention でテキスト条件を取り込む。DLLM の SFT(指示追従訓練)と類似の構造を持つ。
- Token-Critic は確定した位置の再考(remasking)を別モデルの判定で行う仕組みで、一度確定した位置を後で
[MASK]に戻す機構を初めて明示的に導入した。これは LLaDA や Dream で採用されている「低信頼度位置を remask する」戦略の直接的な原型である。 - MAGVIT 系 は動画への拡張だが、長系列に対するスケジュール設計のヒントを与える。
これらは画像側の発展だが、サンプリング戦略の改良という観点では言語側にも応用可能である。Token-Critic 的な remasking は実際に DLLM 文献でも独立に再発明されており、両ドメインの相互参照は今後も有用と考えられる。
MaskGIT と離散拡散の関係
MaskGIT は元々「離散拡散」として提案されてはおらず、masked transformer + iterative decoding の枠組みとして導入された。しかし後に MDLM 等が示したように、MaskGIT の訓練と推論はちょうど masked (absorbing) diffusion の特殊ケース として解釈できる。
具体的には、
- 訓練時の「ランダムマスク率 \(r\) でマスクして復元する CE」は、masked diffusion の variational lower bound を時間で離散化したものと等価
- 推論時の「全位置
[MASK]から段階的に unmask する」は、absorbing diffusion の reverse process と同じ動作
つまり、MaskGIT は「拡散モデルだと気づかずに離散拡散をやっていた」とも言える。この re-interpretation により、画像側の MaskGIT-like 手法と言語側の DLLM が同じ数学的枠組みの下で語れるようになった。
まとめ
本章では DLLM サンプラの起源として MaskGIT を概観した。要点は次のとおり。
- MaskGIT は 画像離散トークン列に対する反復マスク予測 を提案した
- サンプリングは 全位置
[MASK]→ 信頼度上位を段階的に unmask という構成で、現在の DLLM サンプラとほぼ同型 - コサインスケジュール・信頼度ベース選択・iterative refinement の 3 つが品質を支える
- 後の理論的解釈により、MaskGIT は masked diffusion の特殊ケース と位置付けられた
DLLM のサンプラを設計・実装する際には、MaskGIT 側の経験(特にスケジュール設計と remasking)を参考にできることが多い。逆に DLLM 側で得られた知見(長系列に対するステップ数の取り方、特定トークン語彙への対応)は画像側にも応用可能性がある。両ドメインを行き来して文献を読むことで、サンプリング戦略の本質的な部分と、ドメイン固有の細部とを切り分けて理解しやすくなる。