MDLM
MDLM(Masked Diffusion Language Model)は、Sahoo らが NeurIPS 2024 で発表した離散拡散言語モデルの定式化である (Sahoo ほか 2024年)。離散拡散の foundational な数学を提供した D3PM(Discrete Denoising Diffusion Probabilistic Models)(Austin ほか 2021年) から数年間にわたって蓄積されてきた masked diffusion の理論を、1 つの簡潔な目的関数に集約した点が最大の貢献である。後続の LLaDA (Nie ほか 2025年) や Dream は実質的にこの定式化の上に立っており、現代的な Diffusion Language Model(DLLM)を理解する出発点として最初に読むべき論文となっている。
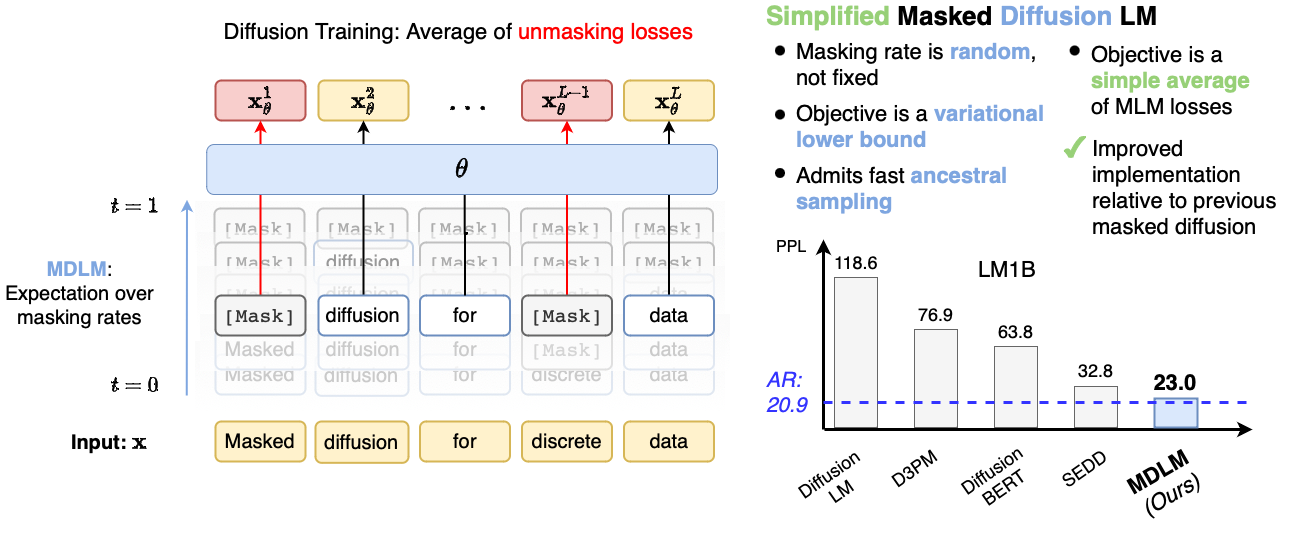
図 1 に示すように、訓練は「マスク率を確率変数として変動させた BERT」と読める。
なぜ MDLM を最初に読むべきか
D3PM が提示した離散拡散の枠組みは、uniform / absorbing / discretized Gaussian など多様な遷移行列を統一的に扱う一方、目的関数は KL(Kullback-Leibler)ダイバージェンスの和として書かれており、実装上の見通しが必ずしも良くなかった。その後 SEDD(Score Entropy Discrete Diffusion)(Lou ほか 2024年) は concrete score / ratio matching の観点から目的関数を再構築したが、score function を陽に扱うため離散領域特有の煩雑さが残っていた。
MDLM はこの状況に対し、absorbing transition([MASK] 状態への一方向遷移)に絞った上で連続時間極限を取ると、変分下限(Evidence Lower Bound, ELBO)が 重み \(1/t\) の masked cross-entropy に縮約することを示した。これにより、
- 訓練は BERT のランダムマスク予測の連続時間一般化として実装できる
- 推論は離散時刻でのサンプリングループとして書ける
- 連続拡散モデル(Denoising Diffusion Probabilistic Models(DDPM)等)の denoising score matching と構造的に対応する
という見通しの良い構図が得られる。「DLLM の訓練とは何をしているのか」を 1 本で掴むうえで、MDLM ほど良い入口は他にない。
MDLM と同年に Shi らも独立に類似の masked diffusion の定式化を提案している (Shi ほか 2024年)。両者は記法こそ異なるが、本質的に同じ「absorbing + 連続時間 ELBO → 重み付き masked CE」の構造に到達しており、現在は両論文を合わせて参照することが多い。
定式化の核
記法
語彙サイズを \(V\)、系列長を \(L\) とし、クリーンな系列を \(x_0 = (x_0^1, \dots, x_0^L)\) で表す。各トークンは \(V+1\) 状態を取り得る(通常の語彙 \(V\) 種類に加え、特殊トークン [MASK] を追加)。\(x_t^i\) は時刻 \(t \in [0,1]\) における位置 \(i\) のトークンを表す。
Forward 過程
各位置のトークンを独立に、確率 \(t\) で [MASK] に置換する。\(t = 0\) では \(x_0\) がそのまま残り、\(t = 1\) では全位置が [MASK] になる。各位置 \(i\) について、
\[ q(x_t^i \mid x_0^i) = \begin{cases} 1 - t & x_t^i = x_0^i \\ t & x_t^i = \texttt{[MASK]} \end{cases} \]
これは離散時刻の D3PM における absorbing transition の連続時間版に相当する。一度 [MASK] になった位置は、forward 過程の途中で元のトークンに戻ることはない(absorbing 性質)。
Reverse 過程
逆過程は、\(t\) から \(t - \mathrm{d}t\) への 1 ステップで、[MASK] 位置のうち一部を予測トークンで埋める過程として書ける。位置 \(i\) が時刻 \(t\) で [MASK] のとき、時刻 \(s < t\) における条件付き分布は
\[ q(x_s^i \mid x_t^i = \texttt{[MASK]}, x_0^i) = \begin{cases} \frac{t - s}{t} & x_s^i = x_0^i \\ \frac{s}{t} & x_s^i = \texttt{[MASK]} \end{cases} \]
となる。実装上はこの真の posterior に対して、\(x_0\) をニューラルネット \(p_\theta(x_0 \mid x_t)\) で予測することで近似する。すなわち \(x_0\)-prediction の精神で逆過程を学習する。
目的関数
連続時間 ELBO の積分を、上記の forward / reverse 過程の選択のもとで具体化すると、最終的に次の損失関数に縮約する。
定理 1 (MDLM の目的関数 (Sahoo ほか 2024年)) 連続時間 absorbing forward 過程の下で、MDLM の負の ELBO は次の損失と等価になる。
\[ \mathcal{L}_\text{MDLM} = \mathbb{E}_{t \sim \mathcal{U}(0,1)} \, \mathbb{E}_{x_t \sim q(\cdot \mid x_0)} \left[ \frac{1}{t} \sum_{i=1}^{L} \mathbf{1}[x_t^i = \texttt{[MASK]}] \, \log p_\theta(x_0^i \mid x_t) \right] \tag{1}\]
ここで本質的なポイントは次の 2 点である。
[MASK]位置でのみ評価される: \(\mathbf{1}[x_t^i = \texttt{[MASK]}]\) により、unmasked 位置の loss は寄与しない- 重み \(1/t\): 時刻 \(t\) が小さい(マスクが少ない)ほど 1 マスクあたりの寄与が大きい
定理 1 は、BERT のランダムマスク予測損失に対し「マスク率を \(t \in [0,1]\) で動かしながら、\(1/t\) で重み付ける」という拡張になっている。これが「MDLM は連続時間版 BERT である」と言われる所以である。
学習目的の導出の流れ
詳細な計算は原論文 §3 および Appendix A に譲るが、(式 1) に至る論理の骨格は次の通りである。
ELBO の離散時刻版
時刻を \(0 = t_0 < t_1 < \dots < t_N = 1\) と離散化すると、ELBO は
\[ \log p_\theta(x_0) \geq -\mathbb{E}_q \left[ \sum_{n=1}^{N} D_\text{KL}\left( q(x_{t_{n-1}} \mid x_{t_n}, x_0) \,\big\|\, p_\theta(x_{t_{n-1}} \mid x_{t_n}) \right) \right] + \text{const.} \]
と書ける。各 KL は位置ごとに分解できる(forward 過程が位置独立なため)。
各位置の KL の評価
位置 \(i\) における KL は、\(x_{t_n}^i\) が [MASK] か通常トークンかで場合分けされる。
- \(x_{t_n}^i \ne \texttt{[MASK]}\)(既に確定): absorbing 性質より \(x_{t_{n-1}}^i = x_{t_n}^i\) が確定的に分かるため、posterior と prior の両方が delta になり KL は 0
- \(x_{t_n}^i = \texttt{[MASK]}\): posterior は「\(x_0^i\) で埋まる確率 \((t_n - t_{n-1})/t_n\)、
[MASK]のまま残る確率 \(t_{n-1}/t_n\)」であり、ここでのみ非自明な KL が発生
unmasked 位置の loss が消えるのは、まさに absorbing 性質に由来する。情報が一度 forward 過程で「噴出」して [MASK] になったあと、それが時刻 \(t\) で残っていれば未確定(loss あり)、消えていれば既確定(loss なし)という単純な構造になる。
連続時間極限
\(N \to \infty\) の極限を取ると、ステップ幅 \(\Delta t = t_n - t_{n-1}\) が 0 に近づき、KL の主要項が
\[ \frac{\Delta t}{t_n} \cdot (- \log p_\theta(x_0^i \mid x_{t_n})) \]
の形に整理される。これを積分すると、時刻 \(t\) について \(1/t\) の重み付けが現れる。\(1/t\) という重みは、絶対時間ではなく「単位時間あたりに forward 過程で何個のトークンが [MASK] に吸収されるか」のレートから来ていると理解しておくと直感が掴みやすい。
推論時の denoising loop
訓練が終わった後、サンプリングは reverse 過程を離散時刻で辿ることで行う。基本形は次の擬似コードで表せる。
# x_T: 全位置 [MASK] で初期化(T はステップ数)
x = [MASK] * L
for t in linspace(1.0, 0.0, T+1)[:-1]:
s = t - 1.0 / T
# ニューラルネット p_theta による予測
logits = model(x)
# MASK 位置のみ予測サンプリング
for i in masked_positions(x):
if rand() < (t - s) / t:
x[i] = sample(softmax(logits[i]))
# else: MASK のまま残すこの基本形では「各 [MASK] 位置を独立に確率 \((t - s)/t\) で確定させる」ことになり、ステップ数 \(T\) を増やせば 1 ステップあたりの確定数が減って品質が上がる。逆に \(T\) を減らせば高速だが品質が落ちる。\(T\) は計算量と品質のトレードオフを支配するハイパーパラメータである。
実用上は「ランダムに確率で確定」ではなく、「予測 logit の信頼度が高い位置から順に確定」させる戦略がよく使われる。これは画像生成の MaskGIT に由来し、LLaDA など後続モデルが採用している。MDLM の理論的な reverse 過程はランダム確定だが、サンプラの選択は理論と独立に交換可能である。
absorbing transition の必然性
D3PM では uniform / absorbing / discretized Gaussian など複数の遷移を扱えたが、MDLM はあえて absorbing に絞る。なぜそれが自然な選択なのか。
「噴出した情報は戻ってこない」一方向性
absorbing 過程の本質は、情報の損失が一方向的であることだ。一度 [MASK] になった位置は、forward 過程の途中で別のトークンに戻ったり、別の通常トークンに変化したりしない。これにより、
- reverse 過程で「現在
[MASK]の位置は元が何であれ未知」「現在通常トークンの位置は元のまま」という単純な区別ができる - 学習目的の評価は
[MASK]位置のみで行えばよい - BERT のマスク予測タスクと直接対応する
uniform 遷移(任意のトークンに置換)の場合、reverse 過程で「現在トークン \(a\) にあるが、それが元の \(a\) なのか別の文字が変化したものなのか」を区別する必要があり、目的関数が複雑になる。absorbing が「単純な目的関数」と「BERT との接続」を同時に成立させる選択である。
言語データとの相性
言語データにおいて「特定のトークンが [MASK] に置換される」は、欠損・伏字・穴埋めという自然な操作と対応する。uniform 置換(別のランダムトークンに置換)よりも、テキスト処理の直感に合う。
実験結果と scaling
MDLM 論文では LM1B・OpenWebText を用いた実験により、次の点を示している。
| 比較対象 | MDLM の位置付け |
|---|---|
| D3PM (absorbing) | より良い perplexity を達成 |
| SEDD | 同等以上、かつ実装が簡潔 |
| AR (GPT-2 同規模) | わずかに劣るが同程度に scale する |
特に重要なのは、AR と同程度の scaling 則に従って性能が伸びることである。すなわち、計算量・データ量・モデルサイズを増やしたときの perplexity の減衰が AR と類似のパターンを示し、DLLM が「小規模でだけ動くオモチャ」ではないことを示唆している。この観察は後の LLaDA(8B スケール)の動機付けにもなっている。
読み方の優先順位
論文を読む際の各セクションの重要度を表にまとめておく。
| セクション | 重要度 | 内容 |
|---|---|---|
| §2 定式化 | 必読(2 周以上) | forward / reverse 過程の定義、記法 |
| §3.1 目的関数の導出 | 必読 | ELBO から \(1/t\) 重み付き CE への簡略化 |
| §3.2 SUBS パラメータ化 | 推奨 | \(x_0\) 予測のヘッド設計、[MASK] 出力を 0 にする工夫 |
| §4 sampling | 必読 | 推論ループ、ancestral / analytic samplers |
| §5 実験 | 概観で十分 | LM1B・OWT・zero-shot perplexity |
| Appendix A | scan で十分 | D3PM 等価性の証明、連続時間極限の厳密化 |
| Appendix B-C | リファレンス | 派生損失・実装詳細 |
特に §2 と §3.1 は、本書の他章を読む際の前提知識となるため、最低 2 周読んで「forward 過程の定義」「ELBO がなぜ [MASK] 位置のみの CE になるか」を自分の言葉で説明できる状態を目指したい。
この論文を読んだ後に分かること
MDLM を一通り読むと、以下の理解が得られる。
- DLLM の訓練の正体: 「ノイズスケジュール付きの BERT 訓練」だと割り切ってよい。マスク率 \(t\) を一様にサンプリングし、\(1/t\) で重み付ける以外、BERT との差は本質的にはない。
- 推論時の denoising step の意味: 離散時刻 \(t_n\) でのサンプリングであり、ステップ数 \(T\) は計算量と品質のトレードオフのハイパラ。理論上は \(T \to \infty\) で連続時間 reverse 過程に近づく。
- absorbing 性質の役割: 「unmask したら確定」という性質が、目的関数を
[MASK]位置のみで評価する形に簡略化する根本原因。 - AR との関係: AR は左から右への 1 方向 unmask(既存トークンの予測を順次行う)と見なせ、DLLM は順序自由な unmask に一般化したもの、と捉えられる。
連続拡散モデルとの対応
連続拡散(DDPM, VP-SDE 等)における denoising score matching(DSM)は、ノイズ強度 \(\sigma_t\) で重み付けされた L2 損失
\[ \mathcal{L}_\text{DSM} = \mathbb{E}_t \, \mathbb{E}_{x_t} \left[ w(t) \, \| s_\theta(x_t, t) - \nabla_{x_t} \log q(x_t \mid x_0) \|^2 \right] \]
の形を取る。MDLM の目的関数 (式 1) は、これと 構造的に同型 である。
| 連続拡散(DSM) | MDLM |
|---|---|
| L2 損失(スコア \(s_\theta\) 回帰) | masked cross-entropy(\(x_0\) 予測) |
| ノイズ強度依存の重み \(w(t)\) | 時刻依存の重み \(1/t\) |
| forward: ガウシアンノイズ付与 | forward: 確率 \(t\) で [MASK] 化 |
| reverse: SDE / ODE 積分 | reverse: 離散時刻 unmask |
両者とも「\(x_0\)-prediction の精神で逆過程を学習する」点で共通しており、損失の重み構造が「重み付き回帰 vs 重み付き分類」の差として現れている、と理解しておくと統一的に見える。
→ 詳細: 連続拡散と離散拡散の橋渡し
関連手法へのリンク
MDLM を起点に、次の章で派生・関連手法を扱う。
- 派生・スケール: LLaDA: 大規模 Masked DLM とサンプリング — MDLM の定式化を 8B パラメータにスケールし、実用的なサンプラを提示
- 別系統の離散拡散: D3PM と SEDD: 離散拡散の別の選択肢 — absorbing 以外の遷移行列、score-based な定式化
- サンプラの源流: MaskGIT: Confidence-based Iterative Unmasking の源流 — 画像生成における confidence-based unmasking