flowchart TD
D3PM["<b>D3PM</b> (2021)<br/>foundational<br/>General theory of transition matrix Q_t"]
Abs["Restrict to<br/>Absorbing transition"]
Gen["Keep general transition<br/>+ ratio matching"]
MDLM["<b>MDLM</b> (2024)<br/>x_0-prediction CE<br/>Weighted masked CE"]
SEDD["<b>SEDD</b> (2024)<br/>concrete score<br/>Score entropy loss"]
D3PM --> Abs
D3PM --> Gen
Abs --> MDLM
Gen --> SEDD
D3PM and SEDD: Alternative Formulations of Discrete Diffusion
Masked Diffusion Language Model (MDLM) (Sahoo et al. 2024) made an extremely concise choice of “absorbing transition + cross-entropy of \(x_0\)-prediction,” but this is not the only path for discrete diffusion. D3PM (Discrete Denoising Diffusion Probabilistic Models) (Austin et al. 2021) provides a foundational formulation that handles more general transition matrices, and SEDD (Score Entropy Discrete Diffusion) (Lou et al. 2024) (ICML 2024 best paper) presents an alternative that directly learns probability ratios (concrete scores). Knowing both reveals why MDLM’s choice converges on “simplicity of implementation.”
This chapter organizes the D3PM framework, SEDD’s ratio matching, and a comparison of all three including MDLM.
D3PM: Foundational Mathematics of Discrete Diffusion
Positioning
D3PM (Discrete Denoising Diffusion Probabilistic Models) (Austin et al. 2021) is a foundational paper in the current lineage of masked / discrete diffusion. Both MDLM and SEDD stand on this framework, and D3PM’s starting point was to rewrite continuous diffusion (Denoising Diffusion Probabilistic Models (DDPM)) (Ho et al. 2020) as “what happens in the case of discrete variables.”
DDPM considers a forward process that gradually adds Gaussian noise to a continuous variable \(x \in \mathbb{R}^d\), but for categorical variables such as text, Gaussian noise cannot be used. Instead, the basic structure of discrete diffusion is to replace a token with another token at each time step via a transition matrix \(Q_t\).
Forward Process and Transition Matrix
Representing a token \(x \in \{1, \dots, K\}\) (\(K\) is the vocabulary size) as a one-hot vector, the forward process is defined as follows.
\[ q(x_t \mid x_{t-1}) = \text{Cat}\bigl(x_t;\, Q_t x_{t-1}\bigr) \]
Here \(Q_t \in \mathbb{R}^{K \times K}\) is the transition matrix, and \((Q_t)_{ij}\) represents the probability that a token \(j\) at time \(t-1\) becomes token \(i\) at time \(t\). Multi-step transitions are simply written as matrix products.
\[ q(x_t \mid x_0) = \text{Cat}\bigl(x_t;\, \bar{Q}_t x_0\bigr), \qquad \bar{Q}_t = Q_t Q_{t-1} \cdots Q_1 \]
The reverse posterior \(q(x_{t-1} \mid x_t, x_0)\) can also be obtained in closed form via Bayes’ rule, and this becomes the target distribution that the model should imitate.
Choice of Transition Matrix
The greatest contribution of D3PM is to show that multiple variants can be obtained depending on the choice of \(Q_t\).
Uniform transition: Each token diffuses toward a uniform distribution. The final state is a uniform distribution over the vocabulary.
\[ Q_t = (1 - \beta_t) I + \frac{\beta_t}{K} \mathbf{1}\mathbf{1}^\top \]
Absorbing transition: Each token transitions to the absorbing state [MASK] with probability \(\beta_t\), and once masked, it never returns. This is the form adopted by MDLM.
\[ (Q_t)_{ij} = \begin{cases} 1 & i = j = \texttt{[MASK]} \\ \beta_t & i = \texttt{[MASK]},\, j \neq \texttt{[MASK]} \\ 1 - \beta_t & i = j \neq \texttt{[MASK]} \\ 0 & \text{otherwise} \end{cases} \]
Discretized Gaussian: A transition close to continuous diffusion. When the vocabulary is ordered (e.g., pixel values), it prioritizes transitions to nearby tokens.
Nearest-neighbor: Transitions to tokens that are close in the word embedding space. A design intended to preserve the local structure of text.
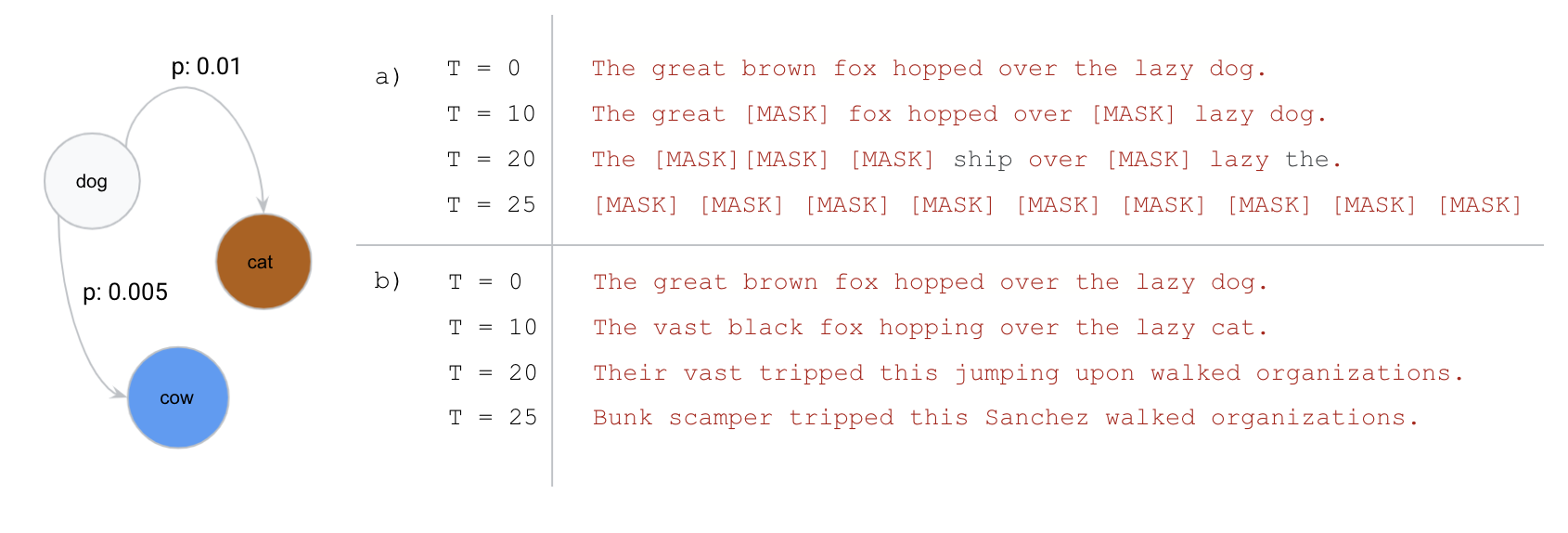
[MASK] and never return. (b) uniform transition: tokens keep transitioning to other tokens, eventually becoming uniformly distributed noise. MDLM simplified the formulation by restricting to (a) absorbing. Source: (Austin et al. 2021)
The difference between (a) and (b) in Figure 1 is the key that later splits MDLM and SEDD in terms of “which direction to take.”
Training Objective
D3PM training takes the form of directly optimizing the variational lower bound (VLB) of the evidence lower bound (ELBO). The sum of KL terms that train the reverse model \(p_\theta(x_{t-1} \mid x_t)\) becomes the loss.
\[ \mathcal{L}_{\text{VLB}} = \mathbb{E}_q \Bigl[ \underbrace{D_{\text{KL}}\bigl(q(x_T \mid x_0) \,\|\, p(x_T)\bigr)}_{L_T} + \sum_{t > 1} \underbrace{D_{\text{KL}}\bigl(q(x_{t-1} \mid x_t, x_0) \,\|\, p_\theta(x_{t-1} \mid x_t)\bigr)}_{L_{t-1}} - \log p_\theta(x_0 \mid x_1) \Bigr] \]
In implementation, since the reverse posterior \(q(x_{t-1} \mid x_t, x_0)\) is a categorical distribution, the KL between discrete distributions can be computed directly at each time step.
What Can Be Learned
The value of D3PM can be summarized in the following three points.
- It showed that the forward / reverse process for discrete variables can be built in the same form as the continuous version (DDPM)
- It demonstrated in a unified framework that the choice of transition matrix determines the properties of the model
- It provides the background for why the absorbing transition chosen by MDLM leads to a concise objective function
The last point is particularly important. In an absorbing transition, \(x_t\) becomes a mixture of [MASK]-ed positions and positions where the original token remains, so the reverse posterior degenerates into a simple structure of “fill mask positions with \(x_0\).” This degeneration leads to MDLM’s weighted masked CE loss.
SEDD: Score Entropy Discrete Diffusion
Positioning
SEDD (Score Entropy Discrete Diffusion) (Lou et al. 2024) proposed ratio matching (learning concrete scores) as a formulation of discrete diffusion outside masked / absorbing. It can be regarded as a discrete version of score matching in continuous diffusion.
On the continuous side, there exists a powerful abstraction of “learning the score \(\nabla_x \log p(x)\),” but since derivatives are not defined for discrete variables, it cannot be used directly. SEDD solved this problem by “learning probability ratios instead of the score.”
Concrete Score (Probability Ratio)
For a discrete variable \(x\), SEDD takes the following concrete score as the learning target.
\[ s_\theta(x)_y = \frac{p(y)}{p(x)} \quad (y \neq x) \]
This is the ratio representing “the relative probability of moving to another token \(y\) when currently at \(x\),” and corresponds to the discrete analog of \(\nabla \log p\) on the continuous side. While the score on the continuous side represents a “direction,” this represents “which token has a high probability of being moved to.”
Score Entropy Loss
As a discrete version of denoising score matching (DSM), SEDD proposed a new loss called score entropy.
\[ \mathcal{L}_{\text{SE}} = \mathbb{E}_{t, x_t, x_0} \sum_{y \neq x_t} w_t(x_t, y) \Bigl[ s_\theta(x_t, t)_y - \frac{q_{t|0}(y \mid x_0)}{q_{t|0}(x_t \mid x_0)} \log s_\theta(x_t, y) \Bigr] \]
Here \(w_t\) is a weight corresponding to the transition strength, and the ratio \(q_{t|0}(y \mid x_0) / q_{t|0}(x_t \mid x_0)\) in the second term is the true value of the concrete score that serves as the supervisory signal. This corresponds to the derivation of DSM via Bregman divergence, and it is shown to be minimized at \(s_\theta \to p(y)/p(x)\).
What Can Be Learned
SEDD is valuable in the following respects.
- It established an alternative to the “score concept” (ratio matching) in discrete diffusion
- It has the generality to work with any transition including uniform, not limited to absorbing
- It presents a formulation that contrasts with MDLM’s choice (giving up the score and using \(x_0\)-prediction)
- It produced results that surpass Autoregressive (AR) LLMs in perplexity on some benchmarks, showing that discrete diffusion can scale
However, the loss implementation is more complex than MDLM’s masked CE, and tuning for stability is required, which becomes a hurdle for large-scale deployment.
Comparison of the Three
D3PM, MDLM, and SEDD stand on the same ground of “discrete diffusion” but make different choices.
| Item | D3PM | MDLM | SEDD |
|---|---|---|---|
| Time | Discrete | Continuous time | Continuous time |
| Transition | General (uniform / absorbing / Gaussian / NN) | Absorbing only | General |
| Learning target | Cat distribution of reverse posterior | \(x_0\)-prediction (CE) | Concrete score / ratio |
| Loss | VLB of ELBO directly | Weighted masked CE (concise) | Score entropy |
| Mathematical positioning | Foundational | Simplification of absorbing | Ratio matching |
| Main contribution | Framework of discrete diffusion | Simplicity of implementation | Establishment of score analog |
Looking at Table 1, one can see the picture that D3PM provided the framework as the “upper-level concept,” MDLM narrowed it down to absorbing to simplify implementation within that framework, and SEDD generalized it along a different axis to ratio matching.
Why MDLM “Won”
NoteConsiderations on MDLM’s Advantages
The main reasons MDLM became the mainstream in DLLM scale-up are the following three points.
- Simplicity of the objective function: The loss is simply “cross-entropy at masked positions multiplied by a \(1/t\) weight,” and it runs on almost the same code as BERT training. Debugging and understanding training behavior are easy.
- A narrowed choice: By restricting to absorbing, the reverse posterior degenerates into the simple operation of “filling masks,” making implementation simple and scaling easier.
- Short distance between theory and implementation: Confidence-based unmasking (the sampler derived from MaskGIT, discussed later) is compatible with the absorbing transition. The intuitive operation of “how to fill
[MASK]” directly becomes the reverse process.
SEDD is more general, but is disadvantageous for large-scale deployment due to the complexity of loss implementation and numerical stability. The weighting of score entropy and the numerical handling associated with exponentiation of probability ratios do not reach the level of simplicity of masked CE that is “BERT as-is.”
D3PM still has value as a research framework. It is referenced as a starting point when trying new transition matrices or analyzing the theoretical properties of discrete diffusion.
Regarding Other DLLM Derivatives
NoteDream: A Counterpart Model to LLaDA
Dream (Ye+ 2025) also adopts masked diffusion, but its initialization and training recipe differ from LLaDA. Specifically, it features initialization from the weights of a pre-trained AR LLM and its own mask schedule.
Comparisons with LLaDA frequently appear in recent DLLM papers. Both stand on the MDLM formulation (absorbing transition + weighted masked CE), and the differences are at the recipe level of “how to train” and “where to initialize from.” The fact that the formulation is shared, making it easy to compare results, is also one of the reasons MDLM became mainstream.
Recommended Reading Approach
Reading each paper in full is a heavy burden, so we propose reading approaches according to purpose.
- D3PM: §3 on the definition of the forward process and §4 on the VLB are worth reading through. The table of each transition (uniform / absorbing / discretized Gaussian / nearest-neighbor) is useful to keep on hand for reference.
- SEDD: Read centered on §3 on the definition of concrete score and §4 on the score entropy loss. The implementation is somewhat complex, so reading it together with the pseudocode in the appendix of the paper makes it easier to understand.
- If time is limited: After understanding MDLM, scanning these two papers is the most efficient reading approach. Reading them after seeing that MDLM is a “specialization,” SEDD is a “generalization along a different axis,” and D3PM is the “upper-level concept” allows the contribution of each paper to be grasped in three dimensions.
References
Austin, Jacob, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. 2021. “Structured Denoising Diffusion Models in Discrete State-Spaces.” Advances in Neural Information Processing Systems. https://openreview.net/forum?id=h7-XixPCAL.
Ho, Jonathan, Ajay Jain, and Pieter Abbeel. 2020. “Denoising Diffusion Probabilistic Models.” Advances in Neural Information Processing Systems. https://arxiv.org/abs/2006.11239.
Lou, Aaron, Chenlin Meng, and Stefano Ermon. 2024. “Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution.” Proceedings of the 41st International Conference on Machine Learning. https://arxiv.org/abs/2310.16834.
Sahoo, Subham Sekhar, Marianne Arriola, Yair Schiff, et al. 2024. “Simple and Effective Masked Diffusion Language Models.” Advances in Neural Information Processing Systems. https://openreview.net/forum?id=L4uaAR4ArM.