MaskGIT: Masked Image Generation via Bidirectional Transformers
MaskGIT (Chang et al. 2022) is a paper on image generation, but it is the direct origin of the current Diffusion Language Model (DLLM) sampling strategy. The iterative generation algorithm represented by LLaDA (Nie et al. 2025) and Dream — “initialize all positions with [MASK], and progressively commit positions starting from those with the highest confidence” — can be regarded, formally, as essentially a port of MaskGIT to language. This chapter surveys the MaskGIT framework and clarifies its connection to current DLLM sampling.
Why Discuss MaskGIT in a Book on Language Models
The core idea of the DLLM sampler (iterative generation that unmasks the top-\(k\) positions by confidence) was established earlier on the image-generation side. MaskGIT demonstrated the framework of “iterative generation over discrete tokens + progressive commitment based on confidence” for image generation, and this was imported directly into language. To understand the historical context and design motivations, it is well worth covering MaskGIT once.
In particular, when reading current DLLM papers, the following questions arise frequently.
- Why does sampling commit “starting from positions with the highest confidence” — wouldn’t another order work?
- Why does quality improve as the number of steps increases — why doesn’t a single step suffice?
- Why is the schedule (how many positions to unmask at each step) important?
The validity of these design decisions was already verified on the image side by the ablation experiments in the MaskGIT paper. Since these are typically treated as known premises in language-side papers, checking the original context makes them easier to understand.
This chapter deals with an image generation paper, but the goal is not to explain image generation methods; it is to confirm the origins of current DLLM sampler designs and the rationale for their design decisions. We do not delve into the details of discretization via Vector Quantized GAN (VQ-GAN) or Fréchet Inception Distance (FID) evaluation, and concentrate on the sampling algorithm.
The MaskGIT Framework
Let us first survey the overall structure. MaskGIT has a three-stage structure: “discrete tokenization → training of a bidirectional transformer → iterative sampling.” This section examines the setup, training, and sampling in order.
Setup
MaskGIT adopts the following two-stage construction.
- Compress the image into a discrete token sequence with VQ-GAN (e.g., 256 tokens in total on a \(16 \times 16\) grid)
- Train a bidirectional transformer over this token sequence
Training is BERT-style masked token prediction. Specifically, for each sample we sample a mask ratio \(r \sim \text{Uniform}(0, 1)\), randomly replace a fraction \(r\) of the tokens in the sequence with [MASK], and take the CE loss for reconstructing them. The point of “drawing the mask ratio widely at random” differs from standard BERT, with the intent of having the model experience both “high mask ratios early on” and “low mask ratios late” at inference time.
Writing the training loss as a formula,
\[ \mathcal{L}_{\text{MaskGIT}} = - \mathbb{E}_{r \sim \mathcal{U}(0,1)} \mathbb{E}_{x, M_r} \sum_{i \in M_r} \log p_\theta(x_i \mid x_{\bar{M}_r}) \]
where \(M_r\) is the set of mask positions randomly chosen with mask ratio \(r\), and \(x_{\bar{M}_r}\) is the token sequence at the unmasked positions. This has essentially the same form as the variational lower bound (VLB) of masked diffusion that is later shown in MDLM.
Sampling Procedure (The Core)
MaskGIT sampling is an iterative loop that initializes all positions with [MASK] and commits all positions over \(T\) steps.
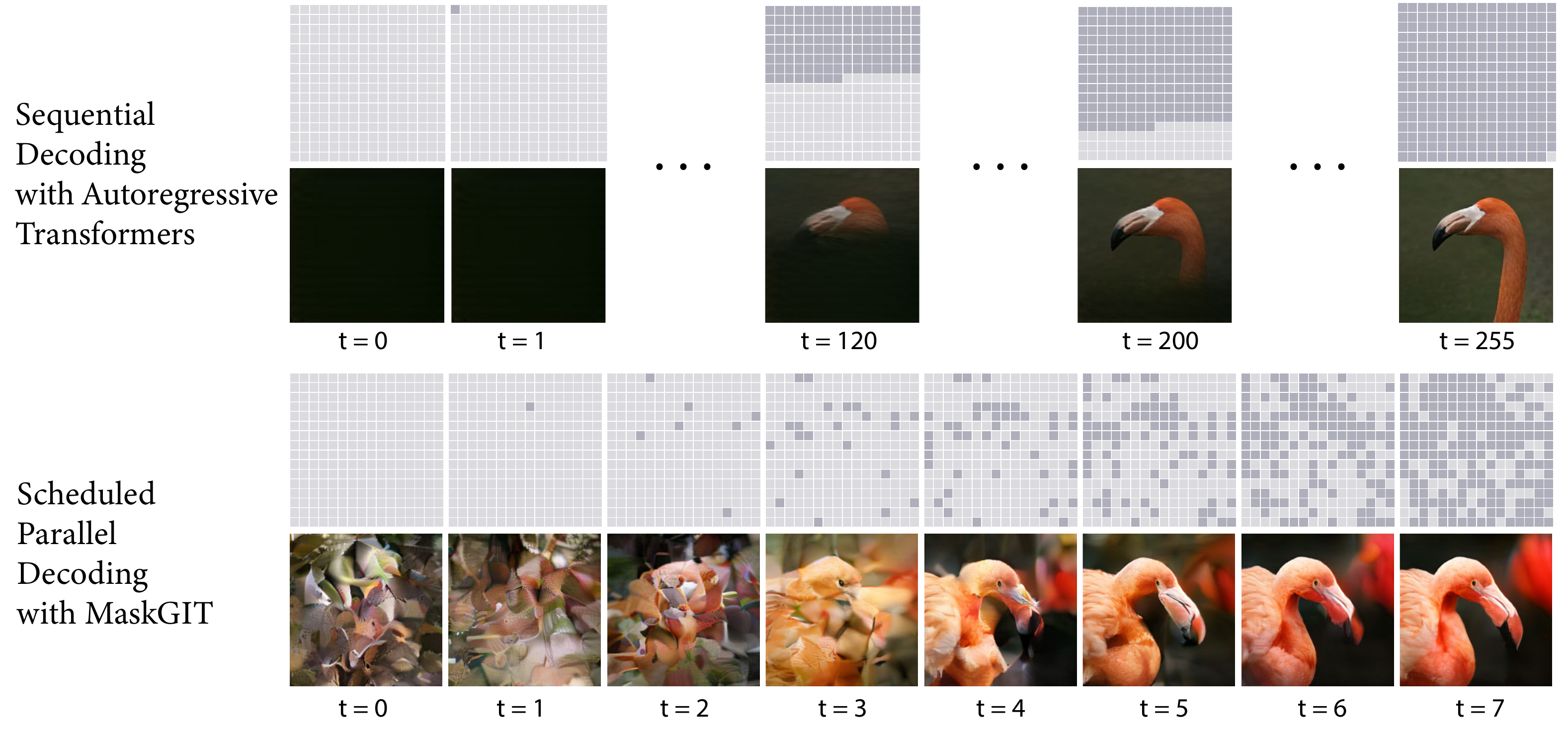
Figure 1 clearly illustrates the essence of MaskGIT. The structure of predict in parallel → commit the high-confidence positions → recursively fill the rest — isomorphic to the DLLM sampler — was established earlier in image generation.
In pseudocode this looks like the following.
# T: total number of steps (typically 8-16)
# N: length of the token sequence
# x: current token sequence (initially all [MASK])
x = [MASK] * N
for t in range(1, T + 1):
# 1. forward: obtain the distribution over all positions
logits = transformer(x) # [N, V]
probs = softmax(logits / temp, dim=-1)
# 2. take a candidate token at each position (argmax or sample)
pred = probs.argmax(dim=-1) # [N]
conf = probs.max(dim=-1) # [N], confidence at each position
# 3. determine how many positions to leave masked at this step
mask_ratio = cosine_schedule(t / T) # gamma(t/T) = cos(pi/2 * t/T)
n_mask = ceil(mask_ratio * N)
# 4. keep the n_mask lowest-confidence positions as [MASK],
# and commit the rest (top confidence) to pred
sorted_idx = argsort(conf) # in ascending order of confidence
keep_masked = sorted_idx[:n_mask]
x = pred.clone()
x[keep_masked] = MASKThe important point here is that “once a position is committed, it is basically not masked again.” Since the schedule is monotonically decreasing, a position committed at step \(t\) is treated as already committed in subsequent steps as well. Later, Token-Critic relaxes this constraint, but in the basic MaskGIT, post-commit reconsideration is not performed.
Key Design Ideas
The quality of MaskGIT is supported by the following three mutually related design decisions.
- Cosine masking schedule: Unmask only a few positions early on (leaving most as
[MASK]) and unmask many positions late. With a monotonically decreasing function such as \(\gamma(t/T) = \cos(\frac{\pi}{2} \cdot t/T)\), this has the effect of “putting difficult positions off until later.” - Confidence-based selection: What to unmask is decided by the model’s own confidence (the top-1 probability). Unlike the AR fixed order (left to right), positions whose context has been sufficiently fixed are committed first.
- Iterative refinement: Rather than deciding everything in one step, split into multiple steps and commit progressively. Since each step provides more commitment information about other positions, prediction becomes easier in later steps.
These three are not independently effective; quality emerges only when they are combined. The ablations in the paper also show that removing any one of them significantly degrades quality.
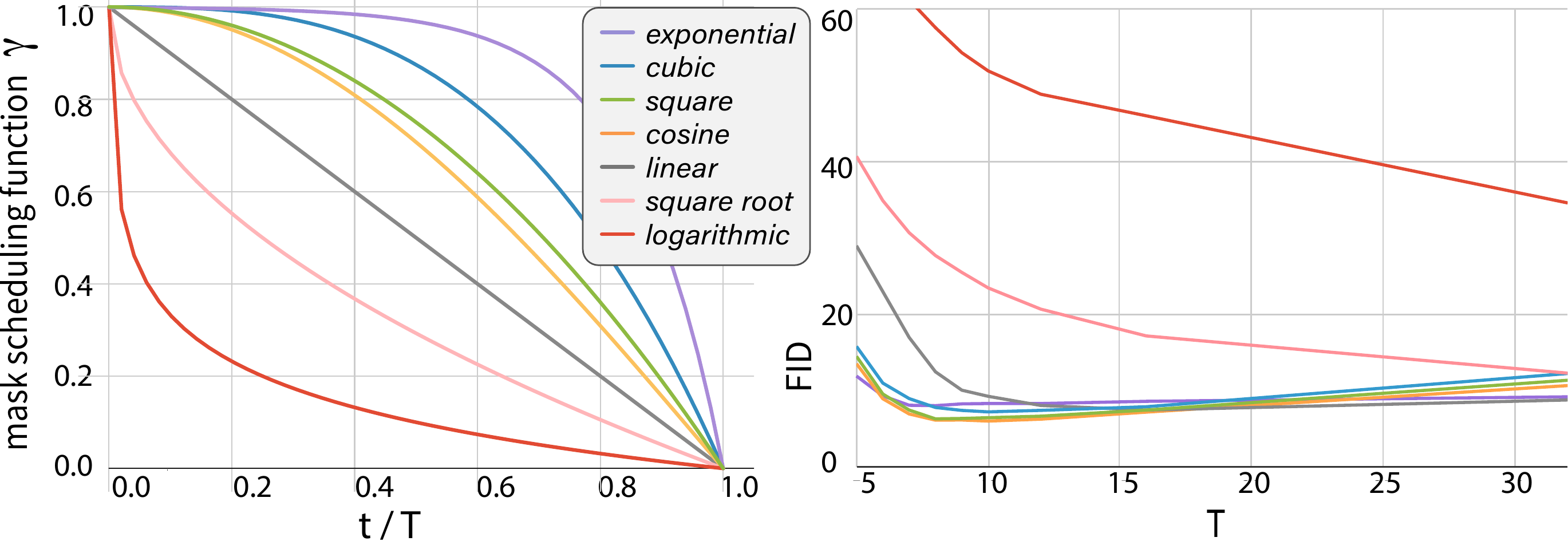
Figure 2 shows that the choice of schedule function directly affects quality. The very shape of “unmask a few early, many late” — that monotonically decreasing form — is what matters, and quality breaks down when the shape is extreme. The facts that “merely replacing the cosine schedule with a linear schedule” degrades FID, and that “selecting randomly” rather than “selecting the top confidence” requires AR-comparable numbers of steps, also suggest that the three elements mutually support each other.
Correspondence with DLLM Samplers
Lining up the sampling of MaskGIT and LLaDA side by side reveals that nearly every element corresponds one-to-one.
| Element | MaskGIT (image) | LLaDA (language) |
|---|---|---|
| Tokenization | Discretized via VQ-GAN | Discretized via BPE, etc. (naturally discrete) |
| Backbone | Bidirectional Transformer | Bidirectional Transformer |
| Training | Random mask prediction (BERT-style) | Masked diffusion CE |
| Sampling initialization | All positions [MASK] |
All positions [MASK] |
| Unmask strategy | Top-\(k\) confidence, cosine schedule | Top-\(k\) confidence |
| Number of steps | About 8-16 | Tens to hundreds |
| Treatment after commit | Committed (basic) / reconsidered (variant) | Committed (absorbing) / remask low-confidence positions |
As Table 1 shows, the two are essentially the same algorithm applied to different domains. The differences boil down to two main points.
- Path of tokenization: Images need to be discretized via VQ-GAN, while text is already discrete. This is a constraint specific to MaskGIT and does not affect the sampling strategy itself.
- Scale of the number of steps: MaskGIT completes in 8-16 steps, while LLaDA typically uses tens to hundreds. This is due to the difference in token sequence length (256 vs. several thousand) and the required quality.
For finer differences, the image side has strong local spatial correlation between positions (adjacent pixels), making the propagation of commitment relatively easy, whereas the language side frequently exhibits long-range dependencies (co-references hundreds of tokens apart, syntactic consistency), so more steps are needed to commit each position carefully. This is a “quantitative difference attributable to domain differences” and does not require changes to the structure of the algorithm itself.
Important Insights from MaskGIT
The MaskGIT paper did not merely present an algorithm — it experimentally demonstrated that each design decision contributes to quality. Specifically, on class-conditional image generation on ImageNet \(256^2\), it achieved FID significantly better than the contemporary AR baselines using just 8 steps. This is not only a scaling-side claim that “increasing the number of steps produces quality” but also an efficiency-side claim that “even with few steps, appropriate design produces high quality.”
We extract three lessons from this that carry over to DLLM sampler design.
Confidence-Based Ordering Is Powerful
Letting the model’s confidence decide “from which position to commit” allows difficult positions to be handled after their context has settled. This is more flexible than the AR fixed order (left to right), and is especially strong against patterns like “if the middle is known, both ends are determined” (structural positional relations in the image case, syntactic dependency relations in the language case).
From another perspective, confidence-based ordering can be said to let the model itself choose the commitment order. AR models follow an externally determined order of “left to right,” whereas MaskGIT-family models prioritize positions about which they are confident, and so naturally take an order adapted to the dependency structure inherent in the data. In principle this is more flexible than AR, but it has the weakness that poor confidence calibration is counterproductive (committing high-confidence errors).
Deciding Everything in One Step Does Not Work
The naive non-autoregressive (NAR) idea is to “predict everything in parallel at once,” but this significantly degrades quality. Because a bidirectional transformer outputs predictions that depend on the surrounding context of each position, a single-step prediction from the initial state “all positions are [MASK]” is essentially close to an unconditional sample, and the output ends up incoherent. Iterative refinement is essentially necessary.
This is natural from a probabilistic-model perspective. Since \(p_\theta(x_i \mid x_{\bar{M}})\) is trained as a conditional distribution on the other positions \(x_{\bar{M}}\), the prediction when \(x_{\bar{M}}\) is empty (all positions masked) is essentially close to the marginal distribution. Taking each position independently with argmax/sample breaks the joint consistency among positions. Increasing the number of steps and “revisiting predictions at the remaining positions conditional on commitments at some positions” is the procedure that recovers this joint consistency.
Schedule Design Determines Quality
The schedule for “how many positions to unmask per step” strongly affects quality. The MaskGIT paper compares linear / cosine / quadratic / cubic etc., and shows that cosine (unmask few early, many late) is the best. This is consistent with the intuition of “make do with a few commitments early to build context, and make late commitments easy.”
The conditions that the schedule function \(\gamma(\tau)\) (with \(\tau = t/T \in [0, 1]\)) should satisfy are as follows.
- \(\gamma(0) = 1\) (initially all positions are masked)
- \(\gamma(1) = 0\) (finally all positions are committed)
- Monotonically decreasing
- Concave shape, “slowly decreasing early on, rapidly decreasing late”
The cosine function \(\gamma(\tau) = \cos(\frac{\pi}{2} \tau)\) naturally satisfies these. The linear function \(\gamma(\tau) = 1 - \tau\) is not concave, so it commits too many positions early on and quality drops.
What carries over from the MaskGIT experience to DLLM design:
- The cosine schedule is also a candidate for DLLMs. In fact, many DLLM samplers including LLaDA adopt schedules of a similar shape.
- Temperature-controlled sampling on confidence can control diversity. argmax is too deterministic, and raising the temperature too much drops quality. MaskGIT reports that a moderate setting is good.
- There is still much room for feedback between multiple steps (looking at intermediate predictions to decide the strategy of the next step). MaskGIT uses a fixed schedule, but dynamic adjustment is room for future work.
Developments After MaskGIT (Briefly)
After MaskGIT, several related methods have appeared on the image side. From the perspective of improving the sampling strategy, they also have implications for the language side. Major developments are shown chronologically.
| Method | Year | Main contribution |
|---|---|---|
| MaskGIT | 2022 | Established confidence-based iterative generation |
| Token-Critic | 2022 | Post-commit reconsideration (remasking) judged by a separate model |
| MUSE | 2023 | Extension to text-conditional generation |
| MAGVIT family | 2023- | Extension to video, improved tokenization |
| MaskBit | 2024 | Efficiency improvements combined with bit-level tokenization |
Among these, we add notes on those that contain lessons directly transferable to DLLMs.
- MUSE is an extension to conditional generation that ingests text conditions via cross-attention. It has a structure similar to DLLM SFT (instruction-tuning).
- Token-Critic is a mechanism that judges the reconsideration of committed positions (remasking) using a separate model, and it was the first to explicitly introduce the mechanism of returning a once-committed position to
[MASK]. This is the direct prototype of the “remask low-confidence positions” strategy adopted in LLaDA and Dream. - MAGVIT family is an extension to video, but it provides hints on schedule design for long sequences.
These are developments on the image side, but from the perspective of improving the sampling strategy, they are also applicable on the language side. Token-Critic-like remasking has actually been independently reinvented in the DLLM literature, and cross-referencing between the two domains is expected to remain useful going forward.
Relation Between MaskGIT and Discrete Diffusion
MaskGIT was not originally proposed as “discrete diffusion” — it was introduced as a framework of masked transformer + iterative decoding. However, as later shown by MDLM and others, MaskGIT’s training and inference can be interpreted as exactly a special case of masked (absorbing) diffusion.
Specifically,
- The “CE for masking with random mask ratio \(r\) and reconstructing” at training time is equivalent to a time-discretization of the variational lower bound of masked diffusion
- The “progressively unmask from all positions
[MASK]” at inference time is the same behavior as the reverse process of absorbing diffusion
In other words, MaskGIT was, in effect, “doing discrete diffusion without realizing it was a diffusion model.” Through this re-interpretation, MaskGIT-like methods on the image side and DLLMs on the language side can now be discussed under the same mathematical framework.
Summary
This chapter surveyed MaskGIT as the origin of the DLLM sampler. The key points are as follows.
- MaskGIT proposed iterative mask prediction over discrete image token sequences
- Sampling has the structure “all positions
[MASK]→ progressively unmask the top-confidence positions,” which is nearly isomorphic to current DLLM samplers - The three elements — cosine schedule, confidence-based selection, and iterative refinement — support quality
- Through later theoretical reinterpretation, MaskGIT was positioned as a special case of masked diffusion
When designing and implementing a DLLM sampler, one can frequently draw on the experience from the MaskGIT side (especially schedule design and remasking). Conversely, insights obtained on the DLLM side (how to choose the number of steps for long sequences, handling of specific token vocabularies) are potentially applicable to the image side as well. Reading the literature back and forth across the two domains makes it easier to separate the essential parts of the sampling strategy from the domain-specific details.