flowchart TD
ACT["ACT<br/>(Graves 2016)<br/>halting & ponder cost"]
UT["Universal Transformer<br/>(Dehghani 2018)<br/>depth recurrence + ACT"]
IAI["Iterative Amortized<br/>Inference<br/>(Marino 2018)"]
ALBERT["ALBERT<br/>(Lan 2020)<br/>cross-layer sharing"]
DEQ["DEQ<br/>(Bai 2019)<br/>fixed point + IFT"]
PN["PonderNet<br/>(Banino 2021)<br/>probabilistic halting"]
LTC["Looped Transformers<br/>as Programmable<br/>Computers<br/>(Giannou 2023)"]
LTL["Looped TF for<br/>Learning Algorithms<br/>(Yang 2024)"]
LTG["Looped TF for<br/>Length Generalization<br/>(Fan 2025)"]
GEI["Recurrent Depth<br/>(Geiping 2025)<br/>3.5B LLM, test-time unroll"]
MOR["MoR<br/>(Bae 2025)<br/>token-level adaptive depth"]
HRM["HRM<br/>(Wang 2025)"]
TRM["TRM<br/>(Jolicoeur 2025)"]
SOT["Sotaku<br/>(Lou 2026)<br/>800K Sudoku 98.9%"]
PTRM["PTRM<br/>(Sghaier 2026)<br/>test-time stochastic"]
GRAM["GRAM<br/>(Baek 2026)<br/>train-time stochastic"]
LDT["LDT<br/>(Davis 2026)<br/>+lattice deduction"]
ACT --> UT
ACT --> PN
UT --> ALBERT
UT --> LTC
ALBERT --> LTC
DEQ -.-> HRM
PN -.-> HRM
UT --> LTL
LTC --> LTL
LTL --> LTG
LTG -.-> GEI
UT --> GEI
IAI -.-> DEQ
IAI -.-> HRM
UT --> HRM
GEI -.-> HRM
GEI -.-> MOR
HRM --> TRM
TRM --> PTRM
TRM --> GRAM
HRM --> GRAM
TRM -.-> SOT
SOT --> LDT
The Lineage of Depth Recurrence
To assess HRM’s claim of architectural novelty made at its debut, we need to pin down what had already been in place and when. In practice, the design philosophy of “reusing the same weights many times on top of a Recurrent Neural Network (RNN) or Transformer, and learning how many passes to take” has a prehistory of nearly a decade going back to Adaptive Computation Time (ACT) in 2016. This chapter traces that lineage through ten papers and shows that the genuine contribution of HRM, TRM, and GRAM lies not in “architectural parts” but in “empirical demonstration within a specific regime”.
Overall View of the Lineage
Arranging the ten key papers chronologically reveals roughly three thick branches: the ACT line (halting and adaptive computation), the DEQ line (fixed point and implicit gradient), and the Looped Transformer line (universality and test-time looping). HRM sits at the point where these three lines converge, and TRM and GRAM further simplify and probabilize that bundle.
Below we summarize each paper briefly in chronological order, focusing on which “part” each one contributed and where HRM, TRM, and GRAM cite it.
ACT: Varying Computation According to the Input (2016)
Adaptive Computation Time (ACT) (Graves 2016) was the first framework to give RNNs the ability to learn the number of computation steps per input. At each time step \(t\), the sigmoid output \(h_t \in [0,1]\) is read as a halting probability, and computation stops once the cumulative sum exceeds \(1-\varepsilon\). Adding the number of steps spent before halting (the ponder cost) to the loss makes the neural network learn to “think deeply on hard inputs and output quickly on easy ones”.
ACT bequeathed two genes to its descendants. One is weight-tied recurrence itself, that is, “running the same weights multiple times”, and the other is adaptive halting via a halting head. The Q-head of Universal Transformer, PonderNet, and HRM all reference this 2016 framework. When HRM says it “adjusts computation per input via adaptive halting”, the ancestor to recall is here.
Universal Transformer: Bringing Depth Recurrence into the Transformer (2018)
Universal Transformer (UT) (Dehghani et al. 2019) was the first major paper to bring ACT into the Transformer. It applies each layer of the standard Transformer multiple times along the time axis with tied weights, emitting a halting probability at each position so that each position can stop at “a different depth”. UT is the ancestor of depth recurrence (vertical recurrence) in the lineage of this book, and the HRM paper cites UT directly.
The key observation of UT is that, when discussing the expressive power of the Transformer, one can separate “the number of layers” from “how many times the same layer is applied”. The depth need not be fixed; it can be unrolled depending on the input. This becomes the common premise behind HRM’s \(NT\)-step unrolling, Geiping’s test-time looping for recurrent depth, and the universality proofs of Looped Transformers. In the context of this book, UT is most naturally read as “the Transformer version of ACT” rather than in isolation.
Iterative Amortized Inference: Viewing Inference as Iterative Optimization (2018)
Marino et al.’s Iterative Amortized Inference (Marino et al. 2018) implemented the inference network of a Variational Autoencoder (VAE) as “an optimizer that iteratively encodes gradients”. In a standard VAE, the encoder \(q_\phi(z \mid x)\) returns the approximate posterior in one forward pass, but here the encoder is given a recursive structure that “takes the current gradient of the Evidence Lower BOund (ELBO) as input and advances the approximate posterior one step in that direction”.
This paper had two effects on the lineage. One is the variational view that “inference is not 1-shot but iterative optimization”, which runs through the later fixed-point formulation of DEQ and the amortized variational inference of GRAM. The other is that it brought the design of “using the same neural network to refine the state step by step” into the variational context as a core motif of reasoning.
ALBERT: Justifying Weight Sharing as “Parameter Saving” (2019)
ALBERT (Lan et al. 2020) looks somewhat off the main line in this lineage, but it cannot be left out because it demonstrated at scale that “applying the same weights 12 times via cross-layer parameter sharing matches Bidirectional Encoder Representations from Transformers (BERT)”. Even after sharing the per-layer independent weights of BERT-Large (334M) down to 18M, it matched or exceeded BERT on several GLUE tasks.
To put ALBERT’s contribution simply, it empirically supported the finding that “the layers of a Transformer can be interpreted along the time axis”. While Universal Transformer introduced weight tying from the perspective of expressive power, ALBERT arrived at the same structure from the perspective of “parameter saving”. The confluence of these two lines establishes the premise in the later Looped Transformer series that “weight tying is in fact the standard”. The precondition for HRM and TRM’s claim that “we match large-scale models with a few million parameters” was demonstrated once here.
DEQ: Treating the Limit of Weight Tying as a Fixed Point (2019)
The Deep Equilibrium Model (DEQ) (Bai et al. 2019) treats the limit of stacking a weight-tied neural network infinitely as the fixed point \(z^* = f_\theta(z^*, x)\), and uses the Implicit Function Theorem (IFT) to compute gradients in \(O(1)\) memory. Whereas ordinary Backpropagation Through Time (BPTT) requires memory proportional to the number of unrolled steps, DEQ needs only the fixed point and the backward pass takes \(1\) step.
The direct influence DEQ had on HRM is “the mathematical basis for the 1-step gradient approximation”. HRM does not BPTT through all \(NT\) steps and instead takes the gradient only at the final step, and the justification borrows the implicit differentiation via IFT from DEQ. The argument that “if \(f_\theta\) is a contraction, the 1-step linearization is a good approximation” is lifted directly from the DEQ literature. As discussed later, TRM rejects this “contraction so 1-step is fine” argument via ablation and improves performance by reverting to full BPTT. Pinning down where one of HRM’s theoretical pillars came from in the lineage makes it clear what TRM is rejecting.
PonderNet: Rewriting Halting as a Bernoulli Process (2021)
PonderNet (Banino et al. 2021) probabilistically reformulated ACT’s halting as a Bernoulli process and stabilized it with KL regularization. ACT’s original formulation handles the halting probability via cumulative sums and is therefore prone to bias and unstable training. PonderNet makes “Bernoulli sampling of stop-or-continue at each step” explicit, and by adding the KL distance to a target distribution (such as a geometric prior) as a penalty, it organizes the framework so that the trade-off between computation and accuracy can be controlled by a temperature parameter.
HRM’s Q-learning based halting formally belongs to the PonderNet lineage. It replaces the “stop / continue” binary choice with reinforcement learning actions and uses task success as the reward, but the root idea (treating halting as a probabilistic decision and regularizing it externally) was established with PonderNet. In the lineage, a single line runs from ACT to PonderNet to HRM’s Q-head.
Looped Transformers as Programmable Computers: Building a Universal Machine in 13 Layers (2023)
Giannou et al.’s Looped Transformers as Programmable Computers (Giannou et al. 2023) constructively proves that looping a 13-layer Transformer can constitute a universal computer. The paper implements each instruction of a One Instruction Set Computer (OISC) as a Transformer block and represents registers via positional embeddings, showing that arbitrary computations can be realized just by controlling the number of loops.
The significance of this paper is that it provides a theoretical basis for the claim that “the expressive power of the Transformer should be measured by the number of loops, not the number of layers”. When HRM and TRM say that “8 layers looped 16 times is equivalent to 128 layers”, this Turing completeness proof stands behind them. Looped Transformers as Programmable Computers is also the foundation for the empirical work that followed (the next section).
Looped Transformers Are Better at Learning Learning Algorithms (2024)
Yang et al.’s ICLR 2024 paper (Yang et al. 2024) experimentally shows that looping outperforms standard Transformers in In-Context Learning (ICL). On ICL tasks such as linear regression, sparse regression, and decision tree learning, a smaller looped Transformer reaches higher accuracy than a standard Transformer with the same number of parameters, and it can express more complex “learning algorithms” via ICL.
This result is the first empirical evidence that “looping works in practical domains” and elevates the theory of Looped Transformers as Programmable Computers from “mere existence proof” to “practical candidate”. The strategy of the HRM and TRM line of “test-time looping a small weight-tied neural network deeply” is a continuation of this empirical observation.
Looped Transformers for Length Generalization (2025)
Fan et al.’s ICLR 2025 paper (Fan et al. 2025) shows that increasing the number of loops at inference time beyond what was used at training improves length generalization. On arithmetic tasks (addition, multiplication, Floor Operation (fop)), accuracy is maintained on inputs longer than the training length as long as the number of loops is increased proportionally to the input length.
This is the direct basis for HRM’s claim that “looping more at test time than during training gives test-time scaling”. Fan et al.’s experiments show that “recurrent depth generalizes on algorithmic tasks”, and they can be used to justify the HRM and TRM strategy of extending the recursion depth at test time on structured tasks such as ARC-AGI and Sudoku. In the lineage, a thick flow runs through Looped Transformers as Programmable Computers (2023), Looped TF for Learning Algorithms (2024), Looped TF for Length Generalization (2025), and HRM (2025).
Geiping Recurrent Depth: Depth Recurrence at the 3.5B LLM Scale (2025)
Geiping et al.’s Scaling up Test-Time Compute with Latent Reasoning (Geiping et al. 2025) presents a pretraining protocol in which a language model with 3.5B parameters can unroll its recurrent block as many times as desired at test time. By training with “unrolling at random depth” during pretraining, one obtains a model whose thinking budget can be continuously controlled at inference simply by changing the number of loops.
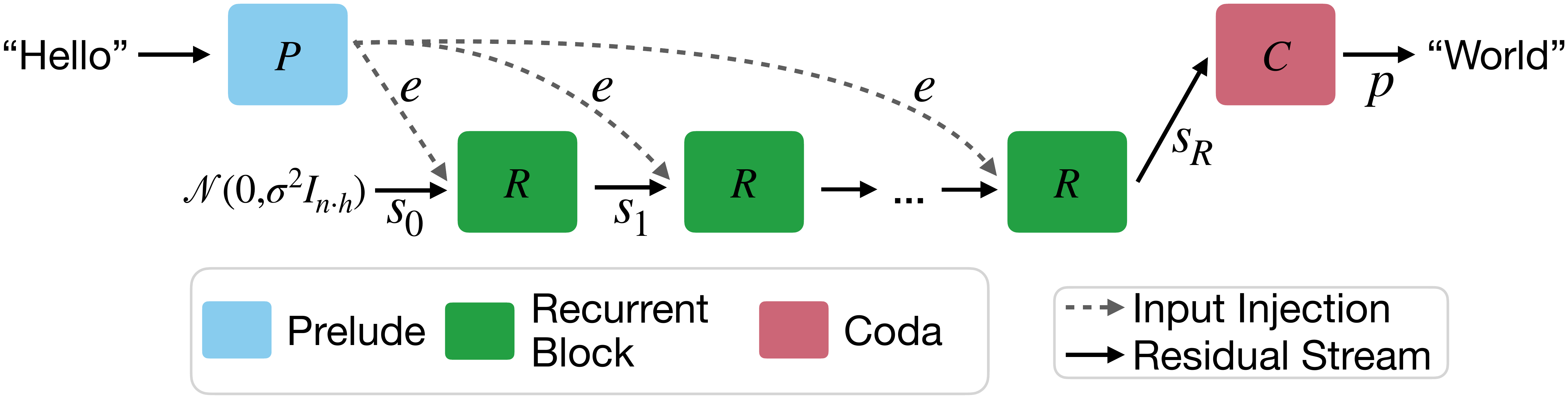
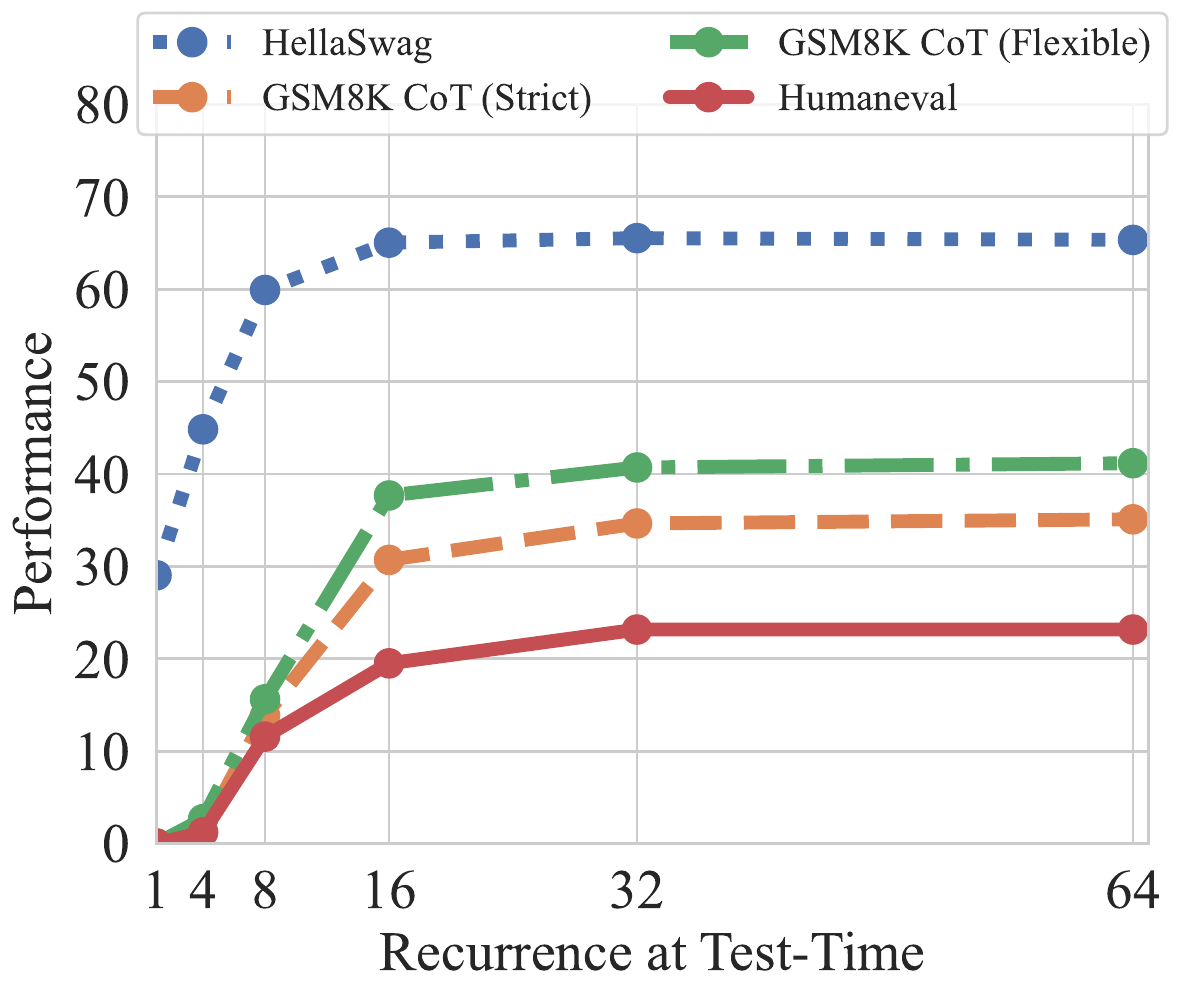
This paper is important for two reasons. First, it showed at LLM scale that “the property of test-time scaling emerges without using Chain-of-Thought (CoT) specific data”. Second, while HRM and TRM “do not go through a language model”, Geiping “does the same thing inside a language model”, taking a position that shows the recursive reasoning framework is continuous with the LLM community. To put HRM’s methodological innovation in perspective, we need to recognize that, at almost the same time, the depth recurrence strategy was independently being tried on the LLM side as well.
Mixture-of-Recursions: Varying Depth per Token (2025)
Bae et al.’s Mixture-of-Recursions (MoR) (Bae et al. 2025), a NeurIPS 2025 paper that appeared right after Geiping recurrent depth, reuses shared layers via recursion while assigning different recursion depths to individual tokens via a lightweight router. In other words, it reconstructs the adaptive halting of Universal Transformer as a routing mechanism appropriate for the LM era, allowing finer-grained depth allocation than Geiping’s “loop the whole model \(r\) times”. Across the 135M to 1.7B scale, it surpasses both vanilla Transformer and existing recursive baselines on the Pareto frontier at matched FLOPs.
MoR is significant in two ways. First, it modernizes the idea that ACT (Graves 2016) proposed in 2016, that “different tokens stop at different depths”, as a routing mechanism for the LM era. Second, whereas HRM and TRM use “a fixed deep supervision over the whole task”, MoR uses “token-level adaptive routing”, pushing the granularity of recursive depth scaling one notch finer. While all of this book’s main models stay with fixed depth, MoR offers a complementary axis of token-level adaptive depth.
Sotaku: An Individual Implementation Branching from the TRM Lineage (2026)
Sotaku (Lou 2026) by Cheng Lou is a from-scratch implementation that branched independently from the TRM lineage on GitHub. It is a roughly 800K-parameter neural network combining a 4-layer weight-shared Transformer with 2D Rotary Position Embedding (RoPE), and achieves 98.9 % (24728/25000) on Sudoku-Extreme via extreme test-time scaling that unrolls 16 iterations during training and up to 1024 iterations at inference. It is striking that the model reaches this accuracy while remaining Sudoku-agnostic (it does not embed row/col/box constraints and only assumes a 2D grid).
The position of Sotaku in the lineage is as an example of “pushing the TRM subtraction further”: independently achieving 11 points higher accuracy on Sudoku-Extreme at 1/10 the size of TRM (7M → 800K). Because it is an individual repository rather than a paper publication, it is rarely discussed as a formal comparison target, but the subsequent LDT inherits the Sotaku architecture almost as is and develops it by adding the lattice projection of abstract interpretation. As the starting point of a “more symbolic-deduction-leaning” lineage that runs alongside this book’s main models (HRM/TRM/PTRM/GRAM), Sotaku is an important link.
Summary: The Genuine Novelty of HRM, TRM, and GRAM
Organizing the ten papers above, we see that HRM’s technical components were essentially all in place from 2016 to 2021, and the Looped Transformer series together with Geiping’s recurrent depth had demonstrated empirical validity. Specifically,
- weight-tied recurrence: ACT (2016), Universal Transformer (2018), ALBERT (2019)
- fixed point and 1-step gradient: DEQ (2019)
- adaptive halting: ACT (2016), PonderNet (2021)
- looping deeply at test time: the Looped TF trilogy (2023 to 2025), Geiping (2025)
- the variational view of iterative inference: Marino (2018)
were each established independently before HRM. HRM’s contribution is that, by integrating these and showing that without CoT training data or large-scale pretraining, 27M parameters and 1000 samples can solve discrete reasoning benchmarks. TRM rejected “hierarchy” and “1-step gradient” from that integration via ablation and surpassed HRM with a simpler 2-layer single neural network trained with full BPTT. GRAM kept TRM’s efficiency while probabilistically extending the decoder, obtaining test-time scaling along the two axes of depth and width.
In other words, the true novelty of the three generations HRM, TRM, and GRAM lies not in “architectural parts” but in “a regime proof that the depth recurrence line can hold up on discrete reasoning benchmarks without CoT or large-scale data”. Conversely, part-level claims such as “hierarchy works” or “1-step gradient works” have already been refuted by TRM’s ablations. The reason this book places the lineage chapter near the beginning is to let readers distinguish from the start “which claims are essential to the architecture and which are decoration” as they read each chapter.
The two May 2026 additions, PTRM and LDT, can be read as the latest branching points of this lineage. PTRM is “stochastic exploration on a trained model” that adds Gaussian noise at test time to a TRM checkpoint without retraining, and LDT is the “sound deduction lineage” that inherits Sotaku’s architecture while adding the lattice projection of abstract interpretation. Both are design choices that directly attack what HRM and TRM had been keeping tacitly, namely “a single deterministic trajectory” and “the opacity of latent states”.
The Progression of Mechanistic Interpretation: The Attractor Landscape (2026)
While the part-level novelty in the lineage has reached a plateau, research that mechanistically opens up the interior of recurrent depth networks has advanced in 2025-26. This is progress along the axis of increasing the resolution of “what is happening” rather than “what is moving”, and it substantially changes the interpretive frame for reading this book’s main models.
First, Ren & Liu (Ren and Liu 2026) (this book’s HRM chapter) showed that HRM’s fixed-point property does not actually hold and mechanistically pointed out that HRM’s solving style is “closer to guessing than reasoning”. Second, Blayney et al. (Blayney et al. 2026) probed a looped reasoning language model (the recurrent depth LM in the Geiping style) and reported that (i) each layer converges to a distinct fixed point per iteration, and (ii) the model repeats feedforward-style inference stages once per iteration. Third, Efstathiou & Balwani (Efstathiou and Balwani 2026) (this book’s PTRM chapter) used sparse autoencoders to analyze the latent dynamics of TRM and conclude that “recursive reasoning is not incremental refinement but adaptive search over an attractor landscape”.
On the vision side, Jacobs et al. (Jacobs et al. 2026) showed that standard ViTs implicitly have a structure that repeats \(k \ll L\) distinct blocks along depth (Raptor recovers 96 % of DINOv2 with 2 blocks) and proposed a dynamical interpretation program with directional convergence into class-dependent angular basins, low-rank late-depth updates, and convergence to low-dimensional attractors.
What cuts across these is an integrated picture: the true nature of depth recurrence is not just “stacking layers to buy more compute” but a dynamical system that converges into a specific attractor basin for each input. This picture lets us re-read HRM and TRM’s “refining via depth” narrative, GRAM’s “diversifying attractors with multiple trajectories”, PTRM’s “escaping bad basins with noise”, and LDT’s “constraining attractors soundly with lattice projection” all as different engineering operations on the same attractor landscape. As scaffolding for reading this book’s five main models not just as “independent ideas from different schools” but as “complementary search strategies on the same landscape”, the progression of mechanistic interpretation is important.
References
Bae, Sangmin, Yujin Kim, Reza Bayat, et al. 2025. “Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation.” arXiv Preprint arXiv:2507.10524. https://arxiv.org/abs/2507.10524.
Bai, Shaojie, J. Zico Kolter, and Vladlen Koltun. 2019. “Deep Equilibrium Models.” Advances in Neural Information Processing Systems. https://arxiv.org/abs/1909.01377.
Banino, Andrea, Jan Balaguer, and Charles Blundell. 2021. “PonderNet: Learning to Ponder.” arXiv Preprint arXiv:2107.05407. https://arxiv.org/abs/2107.05407.
Blayney, Hugh, Álvaro Arroyo, Johan Obando-Ceron, et al. 2026. “A Mechanistic Analysis of Looped Reasoning Language Models.” arXiv Preprint arXiv:2604.11791. https://arxiv.org/abs/2604.11791.
Dehghani, Mostafa, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Lukasz Kaiser. 2019. “Universal Transformers.” International Conference on Learning Representations. https://openreview.net/forum?id=HyzdRiR9Y7.
Efstathiou, Andreas, and Aishwarya Balwani. 2026. “Recursive Reasoning as Attractor Landscape Search: Mechanistic Dynamics of the Tiny Recursive Model.” Workshop on Latent and Implicit Thinking – Going Beyond CoT Reasoning, ICLR 2026. https://openreview.net/forum?id=kKps9W1K7n.
Fan, Ying, Yilun Du, Kannan Ramchandran, and Kangwook Lee. 2025. “Looped Transformers for Length Generalization.” International Conference on Learning Representations. https://arxiv.org/abs/2409.15647.
Geiping, Jonas, Sean McLeish, Neel Jain, et al. 2025. “Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach.” arXiv Preprint arXiv:2502.05171. https://arxiv.org/abs/2502.05171.
Giannou, Angeliki, Shashank Rajput, Jy-yong Sohn, Kangwook Lee, Jason D. Lee, and Dimitris Papailiopoulos. 2023. “Looped Transformers as Programmable Computers.” arXiv Preprint arXiv:2301.13196. https://arxiv.org/abs/2301.13196.
Graves, Alex. 2016. “Adaptive Computation Time for Recurrent Neural Networks.” arXiv Preprint arXiv:1603.08983. https://arxiv.org/abs/1603.08983.
Jacobs, Mozes, Thomas Fel, Richard Hakim, Alessandra Brondetta, Demba Ba, and T. Andy Keller. 2026. “Block-Recurrent Dynamics in Vision Transformers.” arXiv Preprint arXiv:2512.19941. https://arxiv.org/abs/2512.19941.
Lan, Zhenzhong, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2020. “ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations.” International Conference on Learning Representations. https://openreview.net/forum?id=H1eA7AEtvS.
Lou, Cheng. 2026. Sotaku: From-Scratch Experiments on Iterative Neural Sudoku Solvers. Software, GitHub repository, commit 9e13341. https://github.com/chenglou/sotaku.
Marino, Joseph, Yisong Yue, and Stephan Mandt. 2018. “Iterative Amortized Inference.” International Conference on Machine Learning. https://arxiv.org/abs/1807.09356.
Ren, Zirui, and Ziming Liu. 2026. “Are Your Reasoning Models Reasoning or Guessing? A Mechanistic Analysis of Hierarchical Reasoning Models.” arXiv Preprint arXiv:2601.10679. https://arxiv.org/abs/2601.10679.
Yang, Liu, Kangwook Lee, Robert Nowak, and Dimitris Papailiopoulos. 2024. “Looped Transformers Are Better at Learning Learning Algorithms.” International Conference on Learning Representations. https://arxiv.org/abs/2311.12424.