Depth vs Token Scaling
The scaling law that “even a model of the same parameter count becomes smarter if more compute is invested at test time” has driven large language model (LLM) research since 2024. The Chain-of-Thought (CoT) line from OpenAI o1 to o3 and DeepSeek-R1 (DeepSeek-AI et al. 2025) pays this test-time compute by emitting long thinking tokens, while the recurrent depth line of the Hierarchical Reasoning Model (HRM) (Wang et al. 2025), the Tiny Recursive Model (TRM) (Jolicoeur-Martineau 2025), the Generative Recursive reAsoning Models (GRAM) (Baek et al. 2026), and Geiping et al. (Geiping et al. 2025) pays the same test-time compute by recursively unrolling the same layer many times. On the surface the two are completely different, but from a computational-complexity perspective they pursue the same goal through different media. This chapter contrasts the two paradigms and discusses their complementarity, integrability, and practical use cases.
Two Paradigms
The path to investing test-time compute splits into two main lines in modern reasoning research.
Sequential Token Scaling: CoT as an External Tape
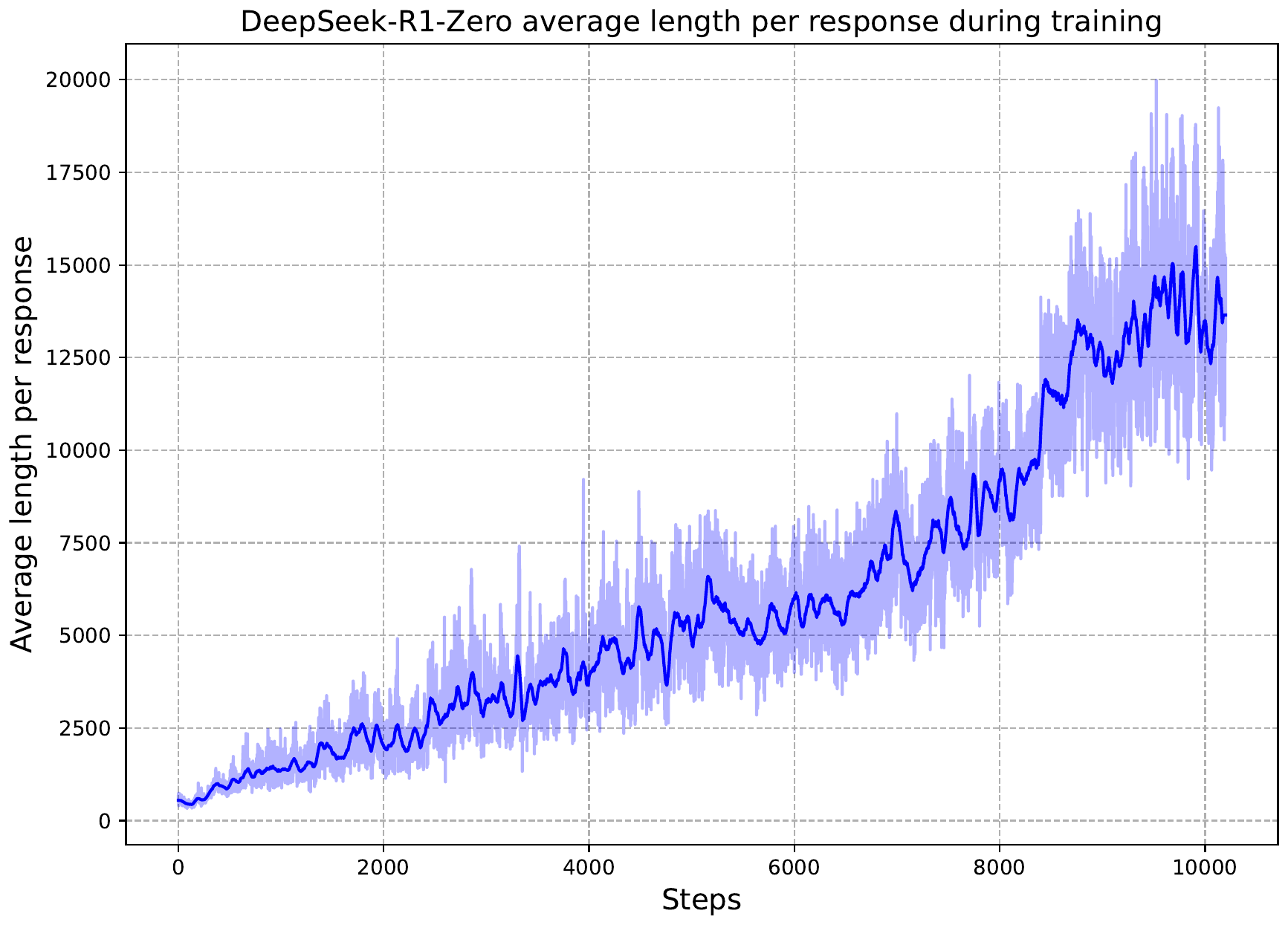
The strategy launched by OpenAI o1 (September 2024) and decisively demonstrated as an open model by DeepSeek-R1 (DeepSeek-AI et al. 2025) is to train an LLM with Reinforcement Learning from Verifiable Rewards (RLVR) and pay test-time compute by letting it generate a long CoT. In the training curves of R1-Zero, the average response length grows monotonically as Group Relative Policy Optimization (GRPO) progresses, providing a visual confirmation that the model spontaneously acquires “thinking time”.
The theoretical and empirical foundations of CoT scaling were established by three key papers.
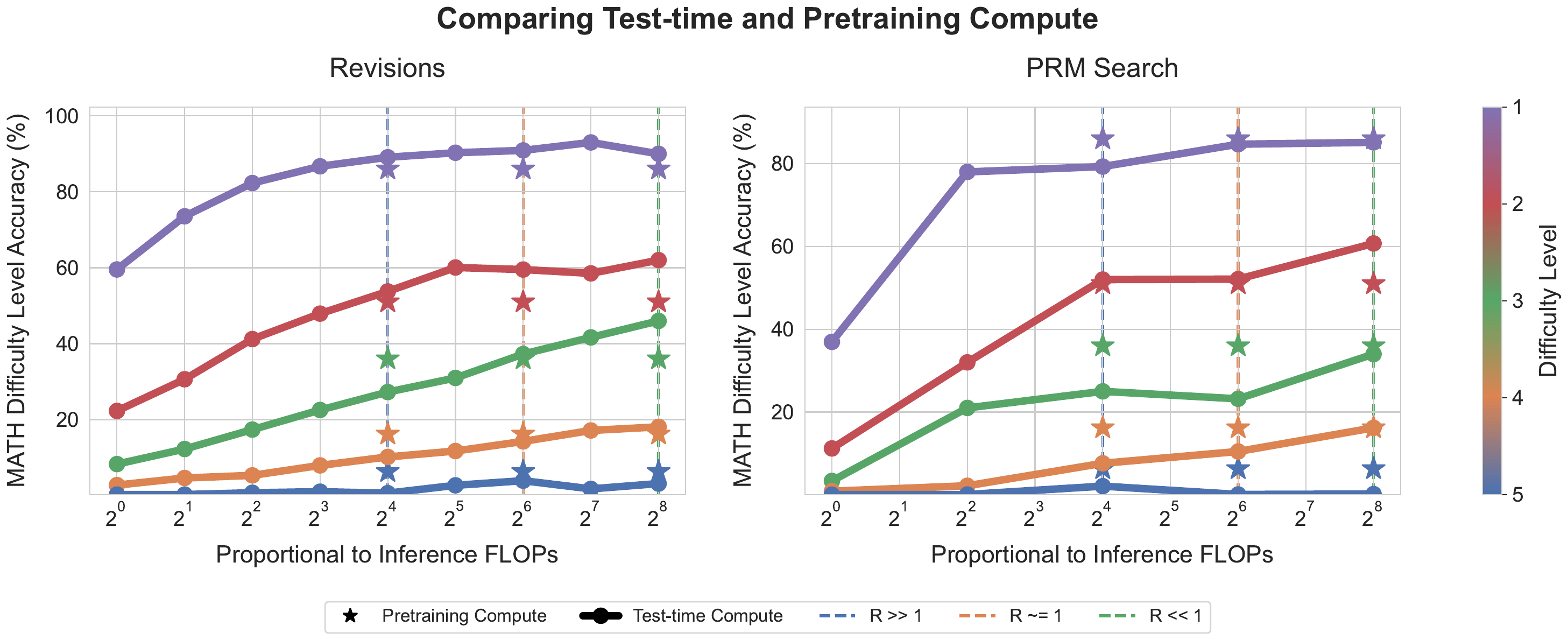
- Snell et al. (Snell et al. 2024) proposed a compute-optimal test-time allocation that switches between Best-of-N (BoN), revision, and Process Reward Model (PRM) search depending on prompt difficulty and inference budget, and showed on the MATH benchmark that with proper allocation a 14x smaller model can outperform a large model (Figure 2).
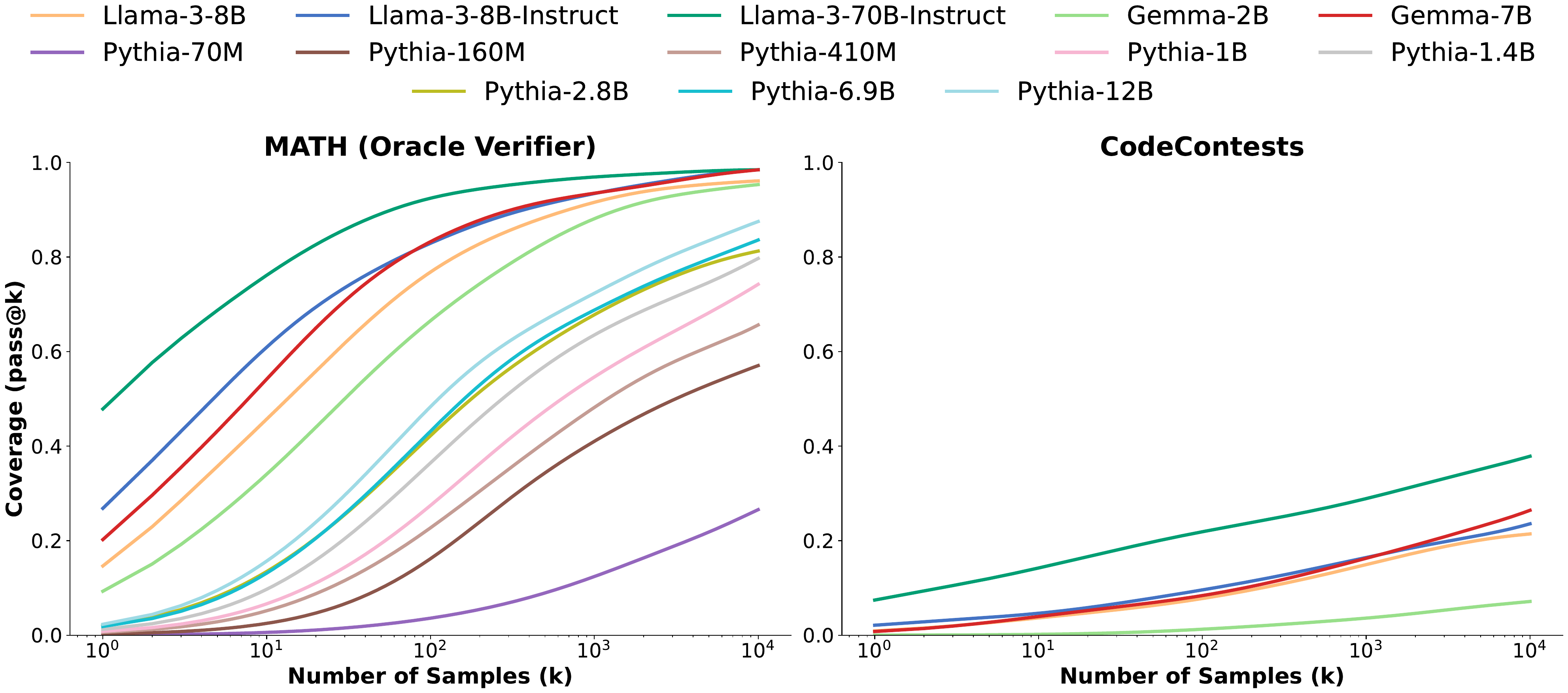
- “Large Language Monkeys” by Brown et al. (Brown et al. 2024) observed that the coverage (pass@k) of repeated sampling grows log-linearly across four orders of magnitude, showing that the number of samples is a brute-force but reliable scaling axis (Figure 3).
- Chen et al. (Chen et al. 2024) showed both theoretically and experimentally that performance can be non-monotonic in the number of LM calls, providing the foundation for why adaptive allocation matters.
This body of results, including not only “emit a long CoT” but also “draw many samples in parallel” and “verify and revise intermediate outputs”, forms the recipe book of sequential token scaling and constitutes the mainstream of current reasoning research.
Recurrent Depth Scaling: Latent Recurrence as an Internal Tape
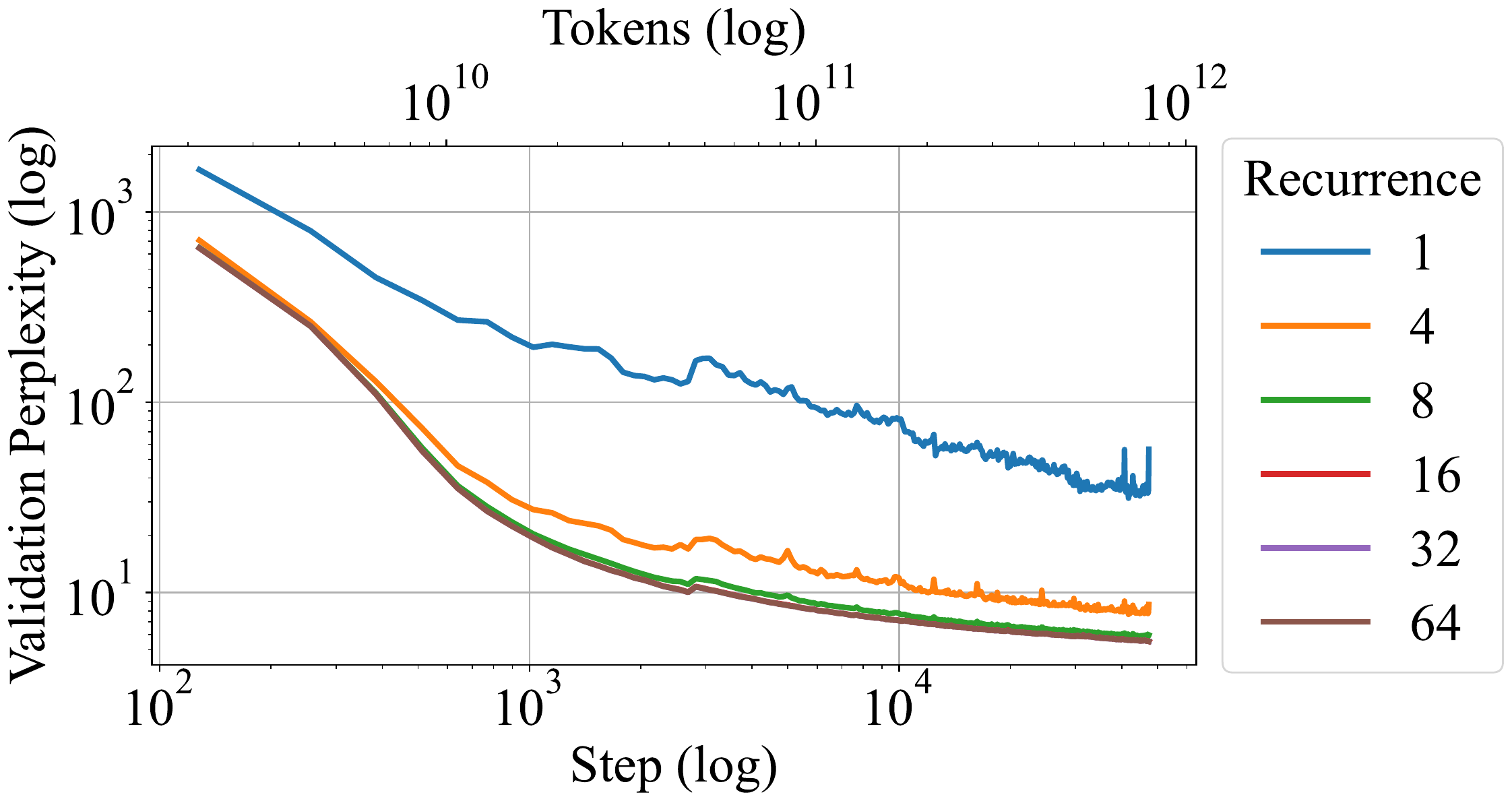
The other path is the strategy of recursively unrolling the same layer to greater depth at test time. The five main models of this book, HRM (Wang et al. 2025), TRM (Jolicoeur-Martineau 2025), PTRM (Sghaier et al. 2026), GRAM (Baek et al. 2026), and LDT (Davis et al. 2026), all belong to this line and run reasoning by unrolling a small network (800K–27M parameters) for \(NT\) or more steps. The same idea was carried to LLM scale by Geiping et al. (Geiping et al. 2025), who trained a 3.5B-parameter model with a recurrent block and showed that simply increasing the number of test-time recurrences monotonically improves perplexity and downstream performance.
The common claim of this line is clear: reasoning can be realized through internal hidden-state iteration without emitting any external tokens.
Comparison Table
The difference between the two can be summarized by a single metaphor. CoT re-injects tokens as an external tape, whereas recurrent depth re-injects the hidden state as an internal tape. This contrast is reflected consistently in the details of each recipe.
| Axis | CoT scaling | Recurrent depth scaling |
|---|---|---|
| Parameter scale | Hundreds of B (R1: 671B) | 7M–3.5B |
| Training data | Trillion tokens + Reinforcement Learning from Human Feedback (RLHF) / RLVR | 1,000 samples (HRM/TRM) |
| Generality | Open-domain | Task-specific (Sudoku / Maze / ARC-AGI) |
| Interpretability | Natural-language trace (human-readable) | Latent state (opaque) |
| Information bandwidth per step | 1 token via \(O(d_\text{vocab})\) softmax | \(\mathbb R^d\) passed through directly |
| Verifier integration | Easy on intermediate trace (PRM, SC, BoN) | Hard on intermediate latents |
| Recursion medium | Token tape (discrete, external) | Hidden state (continuous, internal) |
The axes in Table 1 are not independent: the final row, “recursion medium”, determines all the others. Choosing a token tape immediately implies that (i) training needs a vast amount of language data, (ii) traces are readable so generality and interpretability coexist, and (iii) the per-step information bandwidth is collapsed to a vocabulary-size softmax. Choosing a hidden-state tape immediately implies that (i) training can be done on a small number of samples without language data, (ii) traces are unreadable so the model becomes task-specific and verifiers are hard to interleave, but (iii) in exchange the per-step information bandwidth retains the continuous values in \(\mathbb R^d\).
Theoretical Point: Why the Two Can Be Equivalent
A single Transformer forward pass has fixed depth and, in the sense of circuit complexity, is confined to the neighborhood of \(TC^0\). As the series of analyses by Merrill and Sabharwal has shown, this means that polynomial-time planning or symbolic manipulation cannot be carried out end-to-end in a single forward pass. CoT and recurrent depth both introduce a recursive structure in order to push this fixed-depth limit further at test time, and in this sense they are the same.
The two can have equivalent computational power in theory. CoT re-injects tokens as an external tape and extends the effective depth proportionally to the length of the tape. Recurrent depth re-injects the hidden state as an internal tape and extends the effective depth proportionally to the number of recurrences. Both are means of scaling depth linearly at test time, and in the context of Turing-completeness arguments they belong to the same category.
The cost structure, however, is not symmetric. In terms of per-step information bandwidth, CoT maps the hidden state to a vocabulary probability distribution through softmax at each step and collapses it to one token by sampling. The information that a \(d\)-dimensional hidden state carries is compressed to \(\log_2 |\mathcal V|\) bits. Recurrent depth, in contrast, passes the hidden state directly to the next step, so the continuous values in \(\mathbb R^d\) themselves are fed into the next computation. Recurrent depth has per-step information bandwidth that is orders of magnitude wider, but in exchange it is not human-readable and verifiers are hard to interleave. The trade-off with interpretability has its root here.
“Equivalent” here means that in the limit of arbitrary precision and arbitrary depth the same class of functions can be expressed, not that the same performance is obtained under finite training conditions and a finite parameter budget. Empirically, CoT scaling and recurrent depth scaling have very different strengths (the former in open-domain, the latter on structured grid tasks). The equivalence argument is a starting point for thinking about a design space that integrates the two, not a claim that erases the current trade-offs.
Which Side Do HRM/TRM/GRAM Belong To
Explicitly, all three belong to (B) recurrent depth scaling. The design of increasing test-time performance by extending the inner recurrence of \(NT\) steps and the \(K\) deep supervision segments is a pure form of extending depth without emitting any tokens.
Looked at carefully, however, they smuggle in elements characteristic of (A) sequential token scaling.
- The outer refinement loop of HRM: As the independent reanalysis by the ARC Prize Foundation (Ge et al. 2025) showed, the real driver of HRM is not hierarchical convergence but outer-loop refinement (1 to 2 gives +13 pp, 1 to 8 roughly doubles performance), and this effectively functions as Best-of-K verifier-style inference. One can also read each segment as producing an independent “candidate” and the loss structure of deep supervision as performing implicit selection.
- PTRM’s test-time width scaling: PTRM (Sghaier et al. 2026) from May 2026 leaves the trained TRM checkpoint intact, adds Gaussian noise to the latent at each deep recursion step, runs \(K\) parallel rollouts, and uses TRM’s Q head as the verifier to pick the best trajectory. On PPBench, depth scaling (\(D=16 \to 48\)) gives +3.1 pp, while width scaling (\(K=1 \to 100\)) gives +13 pp, quantifying that width has better linearity than depth and is parallelizable. By requiring no training-time intervention, it establishes the axis of “retraining-free width scaling”.
- GRAM’s parallel trajectories: GRAM introduces stochastic latent transitions and acquires two-axis test-time scaling along depth and width \(N \times K\). The result on Sudoku-Extreme that aggregating \(N=20, K=16\) parallel trajectories outperforms a single deep decoder with \(K=320\) can be read as “Self-Consistency inside the latent space”, corresponding to Self-Consistency (SC) / Majority Voting. Whereas PTRM addresses the problem with test-time intervention alone, GRAM also obtains unconditional generation by embedding stochasticity at training time.
Seen through the lens of the “depth x width” axis, this is nothing other than the latent translation of “thinking-token length x Best-of-N” on the CoT side. The contribution of PTRM and GRAM can be organized as empirically demonstrating that the recipes of CoT scaling have essentially the same structure on the (B) side as well, and that it can be done either as a test-time top-down injection (PTRM) or as training-time embedding (GRAM).
As a third direction orthogonal to these, LDT (Davis et al. 2026) uses the trade-off between train compute and test compute in the reverse direction. The observation that increasing the number of training steps shrinks the median and upper percentiles of per-puzzle forward passes at inference by orders of magnitude on Sudoku-Extreme means that “once sound deduction can be learned, extra training takes over the role of inference-time search and makes it disappear”. Whereas CoT extends test-time compute by “thinking longer”, and HRM/TRM/PTRM/GRAM extend test-time compute by “unrolling the same layer deeper and in parallel”, LDT relies on the soundness guarantee of abstract interpretation to “internalize inference-time search through training”, thus reducing test-time compute. This serves as an example of bringing a “Train compute → Test compute substitution” axis to recursive reasoning, in addition to the three-axis Pareto of “Width × Depth × Token-length”.
Coconut as a Bridge: Continuously Interpolating Between the Two
The two paradigms are not completely disconnected. Coconut (Hao et al. 2025) removes the “hidden to token softmax” step at each CoT step and feeds the final hidden state directly back to the next step as a continuous thought. Formally, this is operationally equivalent to recurrent depth, and at the same time can be read as “a continuous version of CoT”. As a design space that enables continuous interpolation between CoT and recurrent depth, Coconut sits as a bridge between the two (in the group classification of Latent reasoning taxonomy, Coconut is placed at the center as “the first line to blur the boundary between discrete tokens and continuous hidden states”).
GRAM’s parallel trajectories can further be read as the probabilistic explicit form of the fact that Coconut’s continuous thought implicitly has Breadth-First Search (BFS)-like properties. Deterministic Coconut has only a single continuous trajectory, but GRAM handles a distribution over multiple trajectories through variational inference, thereby realizing the latent version of Self-Consistency.
Putting them together structurally, the picture is as follows. If we line up CoT’s stage as “discrete token tape”, Coconut’s stage as “continuous continuous-thought”, and HRM/TRM/GRAM’s stage as “task-specific latent recurrence”, a single axis emerges along which the degree of token compression and the connection to open-domain language vary continuously. The fact that methods such as Fractional Reasoning, which appeared in 2026, are starting to attempt continuous control of reasoning depth with a scalar \(\alpha\) also indicates that continuous interpolation in this design space is becoming a practical research topic.
Practical Use Cases
Even when theoretically equivalent, the asymmetric cost structure means that the choice depends on the deployment target.
- General-purpose / open domain / where humans want to read the trace: CoT scaling (DeepSeek-R1, o3, GPT-5 Pro, etc.). When the system needs to respond to diverse queries, when reasoning traces must be audited, or when verifiers or PRMs are needed to guarantee reliability, CoT has an overwhelming advantage.
- Narrow structured tasks / no large data / strict latency / on-device: The HRM/TRM family. Strong on Sudoku, ARC-AGI, combinatorial optimization, and domain-specific constraint satisfaction, where input-output structure is fixed and there is no room to emit many traces. Being able to run inference on-device at 7M parameters is a clear differentiator from the CoT line for edge-device applications. If a TRM checkpoint is already available and the goal is to raise test-time accuracy, the choice is PTRM; to train a stochastic model from scratch, GRAM; and for high-reliability use cases that prefer abstaining over emitting wrong answers, LDT.
- Next-generation foundation models: A hybrid of continuous thought and a language layer, in the style of Coconut (Hao et al. 2025) or Geiping (Geiping et al. 2025). The direction in which a single model switches between (A) and (B) adaptively per question is becoming realistic. Designs that dynamically switch to deep recurrence on hard problems and to CoT on open-ended dialogue are being studied.
Put briefly, CoT “buys compute by paying generality and interpretability”, and recurrent depth “buys compute efficiency by selling generality and interpretability”, a symmetric exchange. The choice is not decided by a head-to-head cost comparison, but by whether the deployment target tolerates that trade-off. This is the most practical axis when thinking about which to use.
On the CoT side, research on varying the inference budget per problem has begun with Chen et al.’s (Chen et al. 2024) adaptive optimization of the number of LM calls and Snell et al.’s (Snell et al. 2024) compute-optimal selection. On the recurrent depth side, the Q-head of HRM (Adaptive Computation Time, ACT) plays the same role, but a unified theory of adaptive allocation that handles the two lines together does not yet exist at the time of writing (May 2026). A framework that treats the three-axis Pareto of width x depth x token length is an important future research topic.
Chapter Summary
The points of this chapter are summarized as follows.
- Two paradigms: Sequential token scaling via CoT and recurrent depth scaling via HRM/TRM/GRAM/Geiping are two lines that differ in the medium through which test-time compute is paid (external token tape vs internal hidden tape).
- Theoretical equivalence: As means of extending depth at test time, the two can have equivalent computational power. The difference lies in the cost structure of the medium, especially in the per-step information bandwidth (\(\log_2 |\mathcal V|\) bits vs \(\mathbb R^d\)).
- Empirical trade-off: CoT gains generality, interpretability, and verifier integration, but collapses bandwidth to vocabulary size; recurrent depth preserves bandwidth, but loses generality, interpretability, and verifier integration.
- Position of HRM/TRM/GRAM: Nominally (B), but the outer refinement of HRM and the parallel trajectories of GRAM can be read as structures that translate Best-of-K / SC on the CoT side into the latent space. The “depth x width” axis is a design dimension shared by both paradigms.
- Coconut as a bridge: Coconut (Hao et al. 2025) is the first line that, by passing the hidden state directly to the next step without softmax, enables continuous interpolation between CoT and recurrent depth. It sits at the center of the design space that integrates the two.
- Use cases: The choice of paradigm should be based not on cost superiority but on whether the deployment target requires interpretability and generality, or efficiency and low latency. A unified framework including adaptive allocation is a future research topic.