GRAM
Generative Recursive reAsoning Models (GRAM) is a May 2026 paper by Baek, Jo, Kim, Ren, Bengio, and Ahn (Korea Advanced Institute of Science and Technology (KAIST), New York University, and Mila Québec AI Institute) that introduces stochastic multi-trajectory computation into the Recursive Reasoning Model (RRM) family (Baek et al. 2026). The paper was accepted at the ICLR 2026 Workshop on AI with Recursive Self-Improvement (RSI), is available as arXiv:2605.19376, and the code is not yet released at the time of writing (only a project site is public). This chapter first lays out the limitations of the “deterministic latent recursion” used by HRM and TRM, and then walks through how GRAM resolves them with Gaussian guidance plus amortized variational inference.
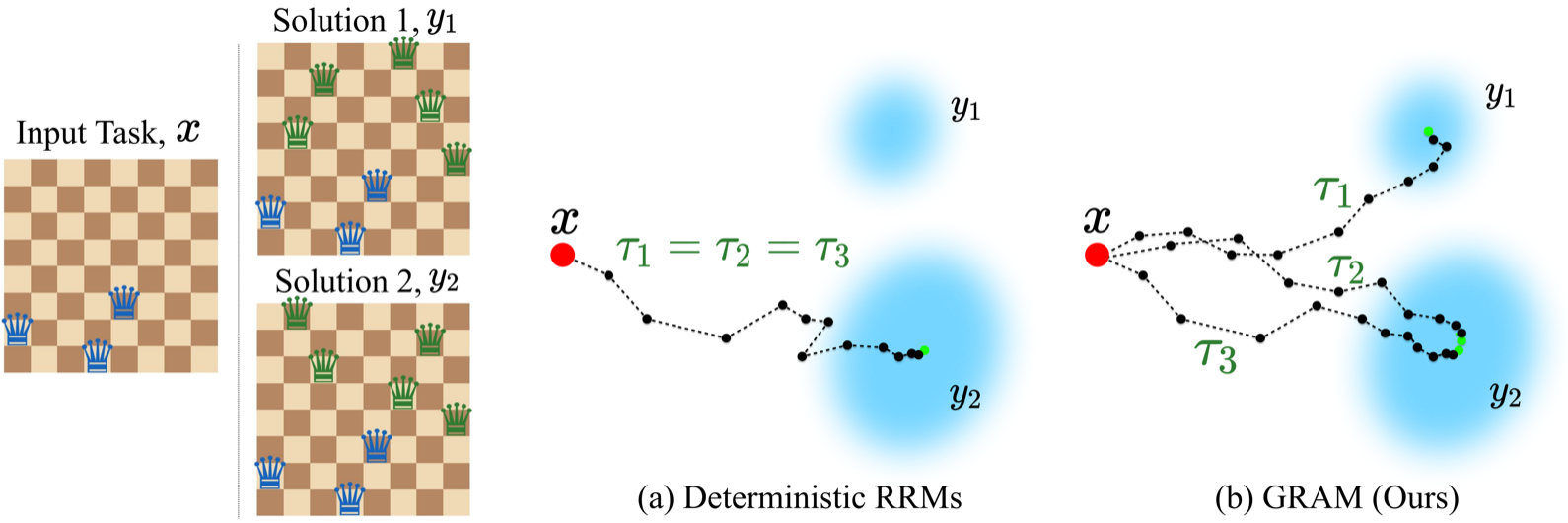
Motivation: Four Limitations of Deterministic RRMs
Both HRM and TRM always follow the same latent trajectory \(\tau = (z_0 \to z_1 \to \dots \to z_T)\) given an input \(x\) and an initial state \(z_0\). This simplicity, viewed as a reasoning model, comes with four tightly coupled constraints.
- Mode collapse: on Constraint Satisfaction Problems (CSPs) with multiple valid solutions, the model collapses onto a single attractor. On 8×8 N-Queens (12 essential solutions), coverage tops out at 36%.
- Single latent trajectory: multiple forward passes on the same input completely overlap. Test-time compute can only be spent along the single axis of “depth \(K\)”.
- No unconditional generation: because \(z_T = f(x)\) is a deterministic function, \(p(x)\) cannot be defined, so unconditional sampling such as generating a Sudoku from an empty board is structurally impossible.
- No multi-hypothesis reasoning: the model has no internal variable that carries uncertainty, so it cannot mechanically support System 2 style reasoning that maintains several hypotheses in parallel.
The authors place their conceptual roots in Kahneman’s System 1 / System 2 and Bengio’s consciousness prior (Baek et al. 2026). The motivation of GRAM is to bake the claim that “reasoning is not extending a single deterministic path but unfolding multiple hypotheses stochastically” directly into the RRM architecture.
Model Formulation
Stochastic Latent Transition
GRAM keeps the same hierarchical latent \(z = (h, l)\) as HRM/TRM, and preserves the one-step recursive structure of refining the low-level \(l\) for \(K\) steps before updating the high-level \(h\) once. The difference is that a learnable stochastic guidance \(\epsilon_t\) is injected as a residual at the end of the high-level update.
\[ \begin{aligned} l_{t,k} &= f_L(h_{t-1}, l_{t,k-1}, e_x; \theta), \quad k=1,\dots,K \\ u_t &= f_H(h_{t-1}, l_t; \theta) \\ \epsilon_t &\sim p_\theta(\epsilon_t \mid u_t) := \mathcal{N}\bigl(\mu_\theta(u_t),\, \sigma^2_\theta(u_t) I\bigr) \\ h_t &= u_t + \epsilon_t \end{aligned} \tag{1}\]
\(\mu_\theta(u_t)\) learns “the direction in which reasoning should proceed” and \(\sigma^2_\theta(u_t)\) learns “the width of exploration”, both conditioned on the current state. In the paper’s ablation, plain zero-mean Gaussian noise collapses to 50% on N-Queens, and only when both the mean and the variance are learned does the model reach the 99% range. The core empirical claim of GRAM is that neither stochasticity nor structured guidance can be dropped.
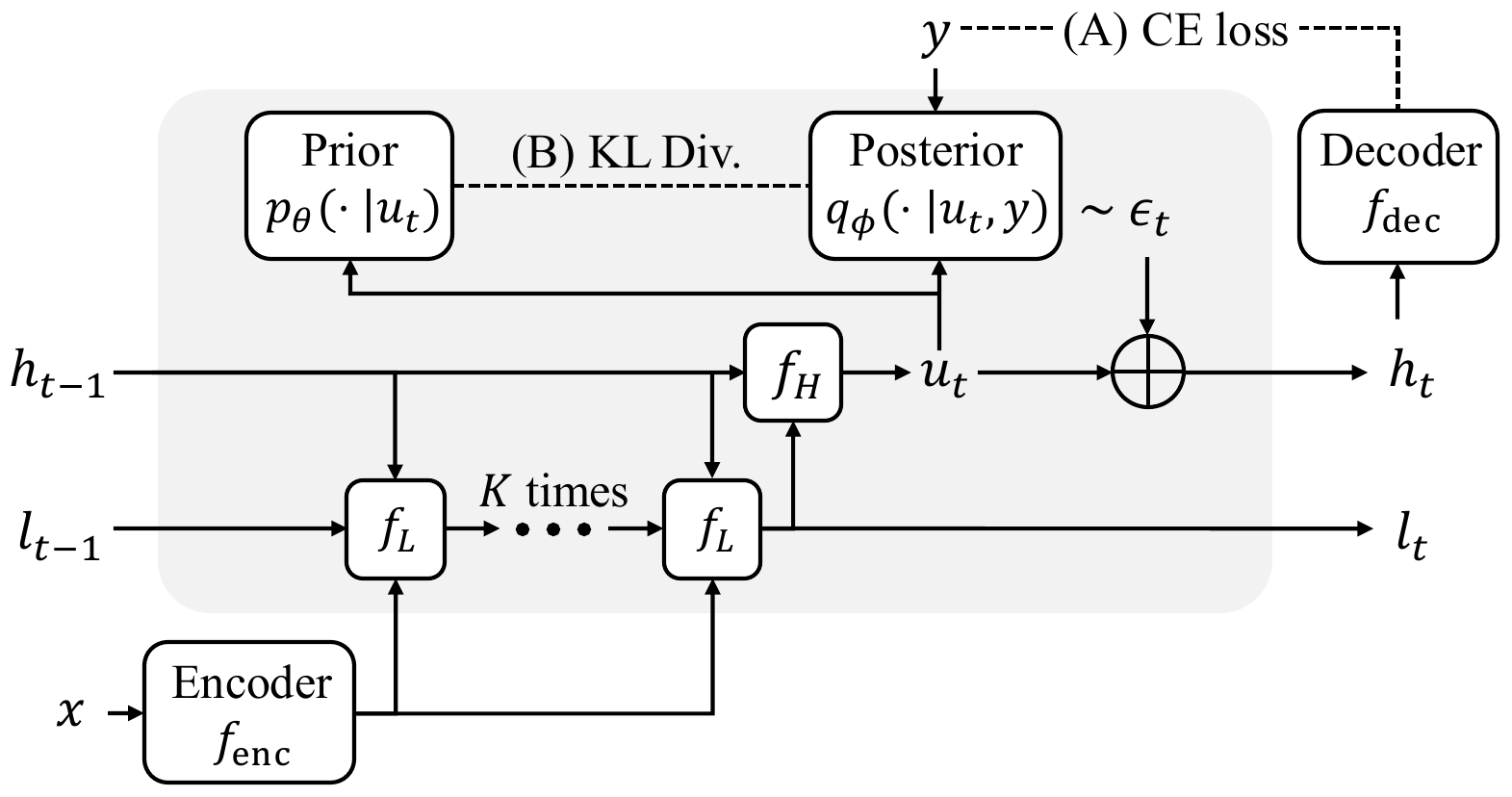
Restricting stochasticity to the high-level is a deliberate design choice. Ablations that inject noise on the low-level show no improvement. This maps the Kahneman-style division of labor “fast local computation deterministic, slow global planning stochastic” onto the computational mechanism.
A Generative Model over Trajectories
One supervision step stacks \(T\) transitions and the whole run stacks \(N_\text{sup}\) supervision steps, so a trajectory consists of \(T_\text{total} = T \times N_\text{sup}\) latents and the prediction is \(\hat y = \arg\max f_\text{dec}(z_{T_\text{total}})\) taken from the final latent. With this, GRAM becomes a latent-variable generative model over trajectories:
\[ p_\theta(y \mid x) = \int p_\theta(y \mid \tau, x)\, p_\theta(\tau \mid x)\, d\tau, \qquad p_\theta(\tau \mid x) = p(z_0) \prod_{t=1}^{T_\text{total}} p_\theta(z_t \mid z_{t-1}, x). \tag{2}\]
Replacing the input \(x\) with an empty embedding lets the same mechanism define \(p_\theta(x)\). In other words, the same model handles both conditional reasoning and unconditional generation. This realizes, in the recursive transformer family, the kind of reasoning that (LCM team et al. 2024) and (Ye et al. 2024) have been pursuing on sentence vectors or diffusion latents.
Training with Amortized Variational Inference
The marginalization over \(\tau\) in (Equation 2) has no closed form, so a variational posterior \(q_\phi(\tau \mid x, y)\) is introduced to maximize the Evidence Lower Bound (ELBO):
\[ \log p_\theta(y \mid x) \ge \mathbb{E}_{q_\phi(\tau \mid x, y)}\bigl[\log p_\theta(y \mid z_{T_\text{total}}, x)\bigr] - \mathrm{KL}\bigl(q_\phi(\tau \mid x, y)\,\|\, p_\theta(\tau \mid x)\bigr). \tag{3}\]
Prior and posterior both factor as Markov chains, and stochasticity enters only through the reparameterized Gaussian \(\epsilon_t\). The posterior \(q_\phi(\epsilon_t \mid u_t, y)\) draws guidance while observing the ground truth \(y\), whereas the prior \(p_\theta(\epsilon_t \mid u_t)\) does not see \(y\). At inference time, \(\epsilon_t\) is sampled from the prior.
Computing (Equation 3) exactly requires backpropagation through time (BPTT) over \(T_\text{total}\) steps, which blows up memory linearly. GRAM adopts a truncated surrogate that propagates gradients only through the final transition \(z_{T-1}^{(n)} \to z_T^{(n)}\) of each supervision step:
\[ \mathcal{L}_\text{GRAM}^{(n)} = \mathbb{E}_{q_\phi}\bigl[\log p_\theta(y \mid z_T^{(n)}, x)\bigr] - \mathrm{KL}\bigl(q_\phi(\epsilon_T^{(n)} \mid u_T^{(n)}, y)\,\|\, p_\theta(\epsilon_T^{(n)} \mid u_T^{(n)})\bigr). \tag{4}\]
This applies the same “localize BPTT” idea found in the 1-step gradient of HRM and the implicit differentiation of Deep Equilibrium Models (DEQ) (Bai et al. 2019), but to a trajectory-level KL. The appendix shows that on validation, the full ELBO and the surrogate decrease nearly in sync and monotonically, supporting the validity of the approximation.
The idea of updating the ELBO with a 1-step gradient has a precedent in Iterative Amortized Inference (Marino et al. 2018). GRAM can be read as transplanting its “recursively refine the posterior” idea onto the reasoning trajectory itself.
Inference-Time Scaling: Depth \(K\) Times Parallel Trajectories \(N\)
The most practical contribution of GRAM is that test-time compute can be invested along two separate axes. Depth \(K\) is the same supervision-step iteration as HRM/TRM, but in a deterministic RRM a single trajectory tends to get trapped in an attractor. Number of parallel trajectories \(N\) is a new axis: \(N\) trajectories are sampled independently from the prior \(p_\theta(\tau \mid x)\), and the terminal candidates \(\hat y^{(i)} = f_\text{dec}(z_T^{(i)})\) are aggregated. Aggregation uses either majority voting or best-of-N with a Latent Process Reward Model (LPRM).
LPRM trains a value head \(v_\psi(z_t)\) in parallel with the decoder using an auxiliary loss that regresses the final accuracy \(r \in [0,1]\) from the current latent:
\[ \mathcal{L}_\text{LPRM} = \sum_{t=1}^{T}\bigl(v_\psi(z_t) - r\bigr)^2. \tag{5}\]
At inference, the trajectory is selected as \(\arg\max_n v_\psi(z_T^{(n)})\). This is a transplant of the language-space Process Reward Model (PRM) onto latent trajectories, and amounts to a new category that could be called “verifier-guided latent search”.
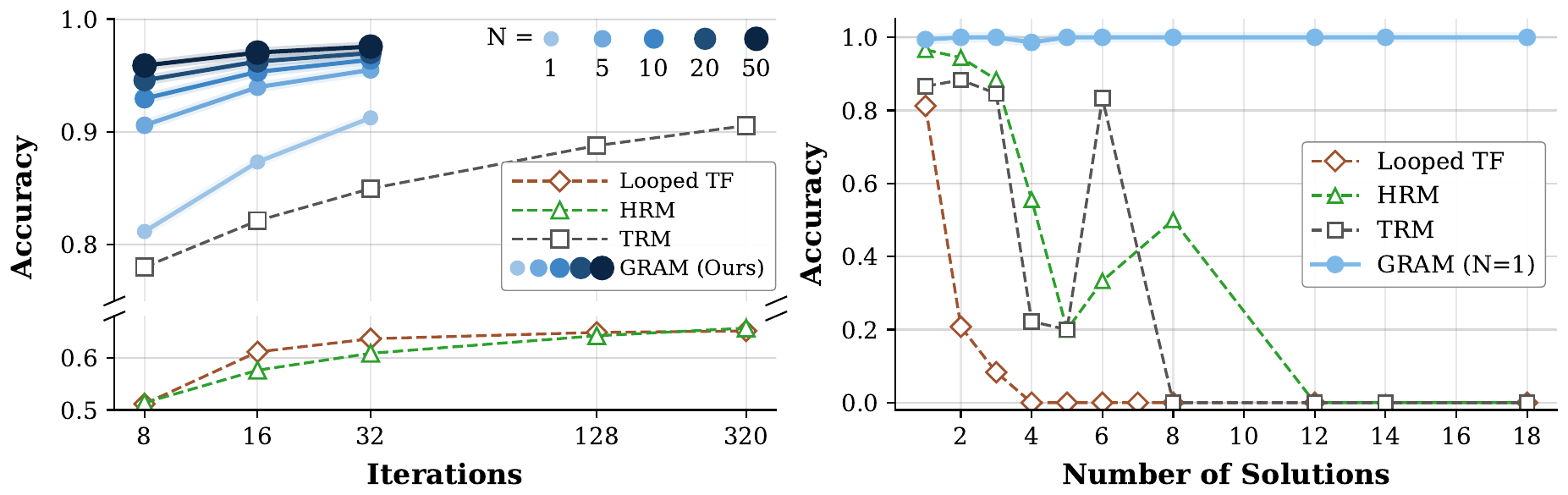
The left panel of Figure 3 shows that there is a regime where increasing the number of parallel trajectories is more efficient than spending the same compute on depth. GRAM with \(N=20\) and \(K=16\) reaches 97.0%, while TRM saturates at 90.5% even at \(K=320\). This quantitatively confirms that deterministic RRMs hit a structural ceiling from their “single trajectory” constraint that depth alone cannot lift. It is an observation that connects, from the recursion side, to Depth vs Token Scaling in this book.
Experimental Results
GRAM deliberately avoids direct comparison with frontier LLMs and restricts itself to same-condition comparisons against deterministic recurrent / recursive baselines (Looped Transformer, HRM, TRM). The paper’s claim is not “beat large LLMs” but rather to establish that stochasticization works within the RRM family.
| Task | Looped TF | HRM | TRM | GRAM |
|---|---|---|---|---|
| Sudoku-Extreme | 47.7 % | 55.0 % | 87.4 % | 97.0 % |
| ARC-AGI-1 | - | 40.3 % | 44.6 % | 52.0 % |
| ARC-AGI-2 | - | 5.0 % | 7.8 % | 11.1 % |
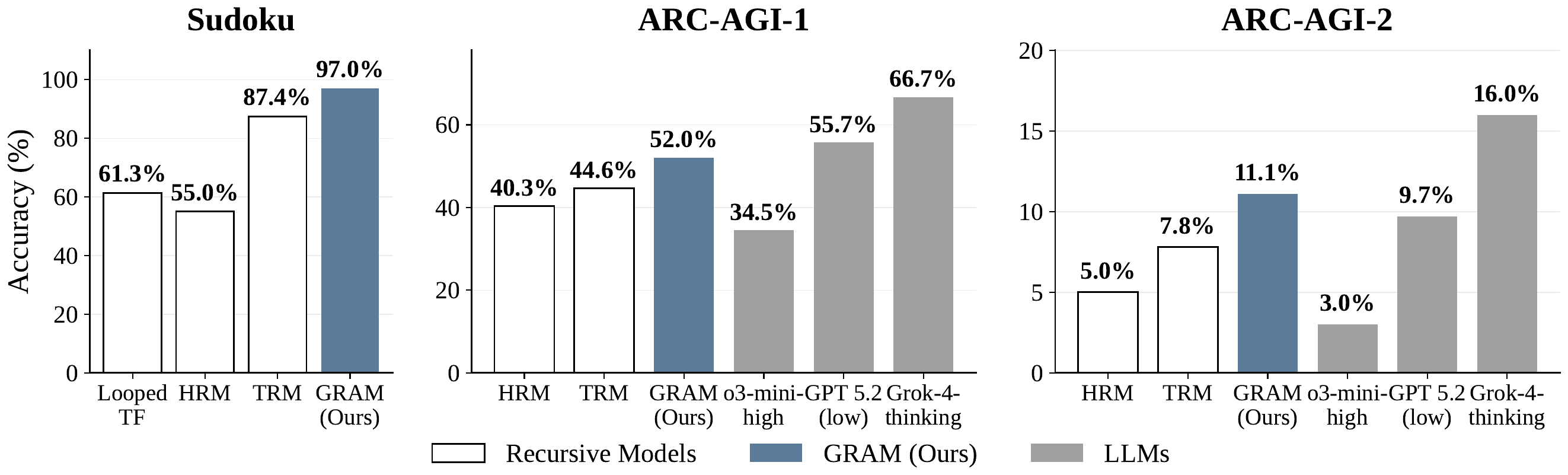
On multi-solution CSPs such as N-Queens and Graph Coloring, the limitations of deterministic RRMs become glaring (right panel of Figure 3). Single-shot accuracy on 8×8 N-Queens is 78.7% for HRM, 66.8% for TRM, 96.3% for AR, and 96.1% for Masked Diffusion Language Model (MDLM), against 99.7% for GRAM. Conflict edges on 10×10 Graph Coloring (lower is better) are 164.3 for HRM, 170.7 for TRM, 61.3 for AR, and 12.0 for MDLM, against 3.3 for GRAM. AR/MDLM offer high diversity but weak constraint satisfaction, while deterministic RRMs are strong on constraints but have zero diversity. GRAM resolves this dichotomy within a single model that combines “recursive refinement and generative diversity”.
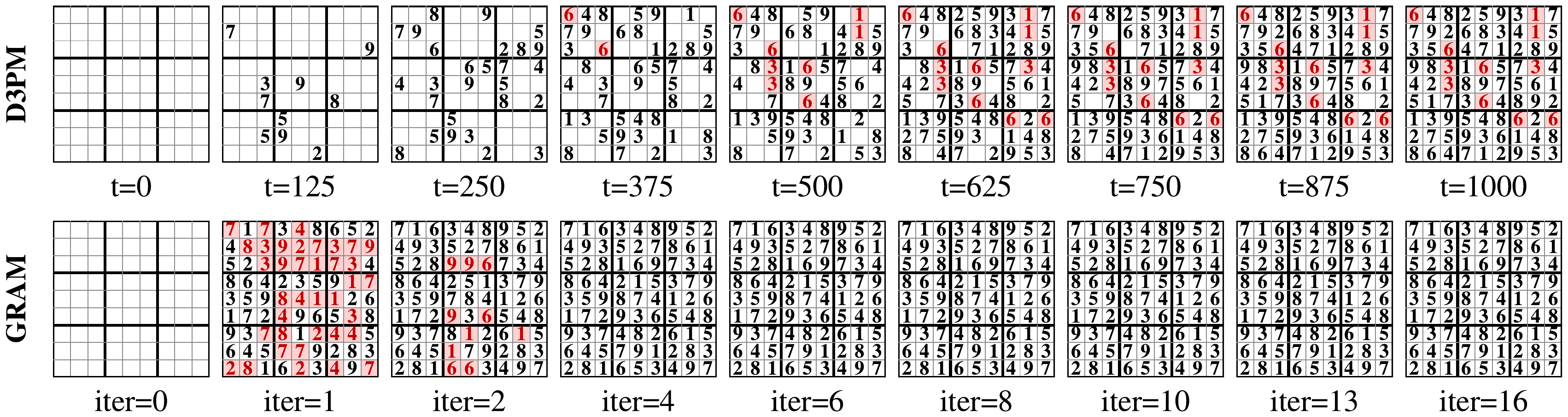
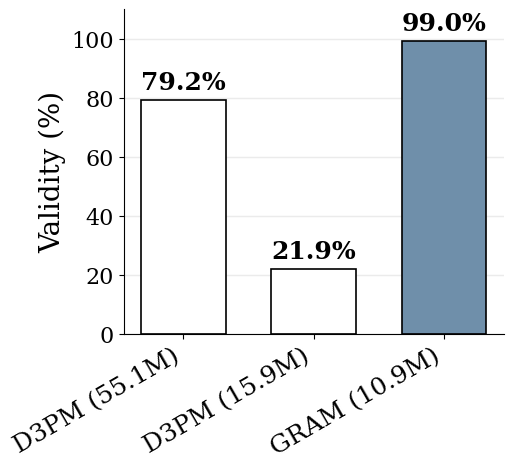
For unconditional generation, GRAM reaches 99.05% validity on Sudoku generation from an empty board with 10.9M parameters and 16 supervision steps, beating Discrete Denoising Diffusion Probabilistic Models (D3PM) which use 55.1M parameters and 1000 denoising steps.
On binarized MNIST, TRM completely mode-collapses (Inception Score (IS) 1.00 / Fréchet Inception Distance (FID) 303.29), while GRAM reaches IS 2.04 / FID 73.34 at 256 steps, comparable to D3PM. Even trained with 16 steps, performance improves monotonically up to 256 steps at inference, showing that inference-time scaling carries over to the generation side as well.
Positioning and Open Problems
Looking at the author list, three lines converge: Sungjin Ahn (KAIST/NYU) with the SCALOR/Genesis line of object-centric latent generative models, Yoshua Bengio (Mila) with the consciousness prior and GFlowNet, and Mengye Ren (NYU) with brain-inspired architecture research. Whereas HRM emphasized a neuroscience-flavored narrative and TRM peeled that narrative off through ablations, GRAM stands at a different position, rebuilding the RRM from another theoretical frame, namely “RRM as a generative model”.
The contributions in the context of this book can be summarized in three points. First, a demonstration of two-axis test-time scaling: an independent axis of depth \(K\) and parallel trajectories \(N\) exists, and there really is a regime where increasing \(N\) is more efficient than increasing \(K\). Second, the arrival of a latent verifier: LPRM is a latent counterpart of language-space PRM and opens a new category of verifier-guided latent search. Third, a bridge between reasoning models and generative models: since the same model handles both \(p_\theta(y \mid x)\) and \(p_\theta(x)\), the conventional split between the two has to be reconsidered.
Symmetry with PTRM: Train-Time vs Test-Time Stochasticization
Two weeks after GRAM’s release, Sghaier et al. (Sghaier et al. 2026) approached the same problem from a different route. PTRM (covered in this book’s PTRM chapter) leaves the trained TRM checkpoint intact and adds Gaussian noise to the latent at each deep recursion step as a test-time stochasticization, pushing TRM from 87.4 % to 98.75 % on Sudoku-Extreme without retraining or task-specific augmentation. Whereas GRAM learns a stochastic term during training and trains the model variationally, PTRM only injects noise at inference time and reuses TRM’s Q head as the verifier. The two implement the same “breaking TRM’s deterministic limit” from opposite sides.
Interestingly, the PTRM paper tries the simple ablation of “adding noise only to the initial latent \(z\) of TRM” and reports a negative result of no improvement on Sudoku. This is consistent with the same ablation GRAM itself ran, and the shared empirical rule stochasticity must be injected at each supervision step rather than only at the initial \(z\) has been confirmed independently by both papers. GRAM’s variational training and PTRM’s test-time noise injection can be read as two different engineering solutions to this shared diagnosis.
As organized at the end of the TRM chapter, PTRM and GRAM are complementary studies that add stochasticity back onto TRM’s minimal core in two ways, “flowing it in from above at inference time” and “embedding it during training”. Whereas PTRM gives up generation capability in exchange for keeping the existing TRM checkpoint usable, GRAM pays the cost of proposing a new model class in exchange for obtaining unconditional generation. In practice, the choice becomes PTRM when “a TRM checkpoint is already available”, and GRAM when “training a stochastic model from scratch is acceptable”.
Open Problems
The paper itself acknowledges that the sequential nature of deep supervision is a training-efficiency bottleneck that prevents scaling to foundation-model size. Whereas CoT scaled up by exploiting the parallelism of token sequences, no established way exists yet to parallelize recursive supervision steps. Like HRM and TRM, GRAM remains in the regime of “small models strong on structured tasks”, and generalization to open domains remains an open problem.
Independent of the PTRM/GRAM stochasticization route, Davis et al.’s Lattice Deduction Transformers (Davis et al. 2026) (this book’s LDT chapter) take a different path: they add not stochasticity but the lattice projection of abstract interpretation to obtain empirical soundness, that is, the property of either returning a solution or abstaining. After HRM and TRM, the small recursive reasoning model lineage can be summarized as branching into three orthogonal extension axes: PTRM (test-time stochastic), GRAM (train-time stochastic), and LDT (sound deduction).