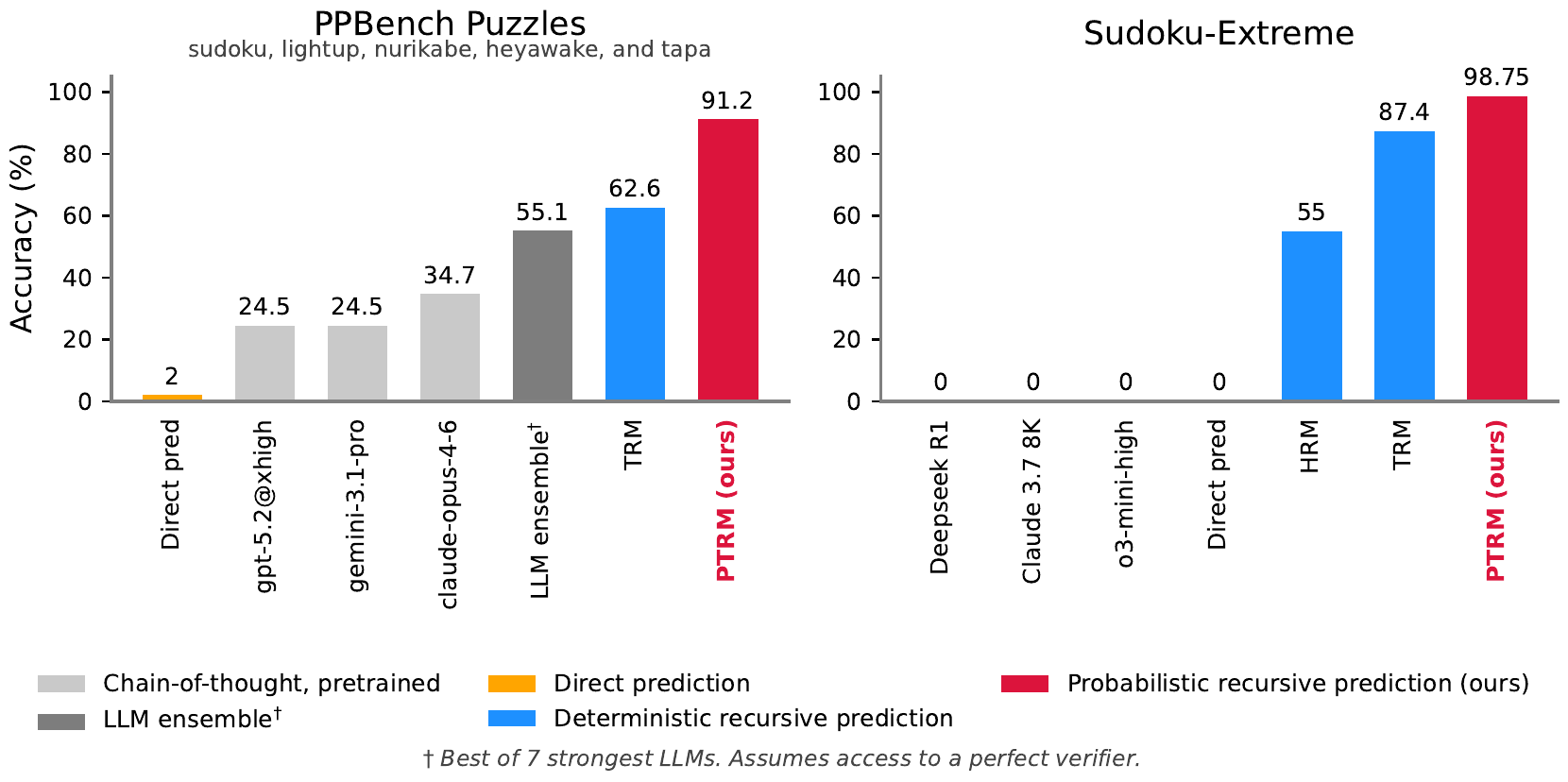
PTRM
Probabilistic Tiny Recursive Model (PTRM) is a test-time scaling framework released in May 2026 by Sghaier and Parviz at Mila Québec AI Institute / École de Technologie Supérieure (ETS), together with Jolicoeur-Martineau, the original author of Tiny Recursive Model (TRM) (Sghaier et al. 2026). In one sentence, PTRM lets TRM escape the bad latent basin that its deterministic recursion falls into, by adding Gaussian noise of scale \(\sigma\) to the latent at every deep recursion step and running \(K\) trajectories in parallel, and then reusing the Q head that TRM already learned for adaptive halting as a verifier to pick the best trajectory. No retraining and no task-specific augmentation are required, and it lifts TRM from 87.4 % to 98.75 % on Sudoku-Extreme and from 62.6 % to 91.2 % on Pencil Puzzle Bench (PPBench). Around the same time, a mechanistic analysis paper by Efstathiou & Balwani (Efstathiou and Balwani 2026), presented at the ICLR 2026 Workshop on Latent and Implicit Thinking, independently arrived at the same attractor hypothesis, and this chapter treats the two papers as a pair. As a test-time extension of TRM, the ARC Prize 2025 Paper Award winner, this book places PTRM as “the third strategy that puts a trained model directly to work as is”.
TRM Failure Modes: Trapped in a Bad Basin
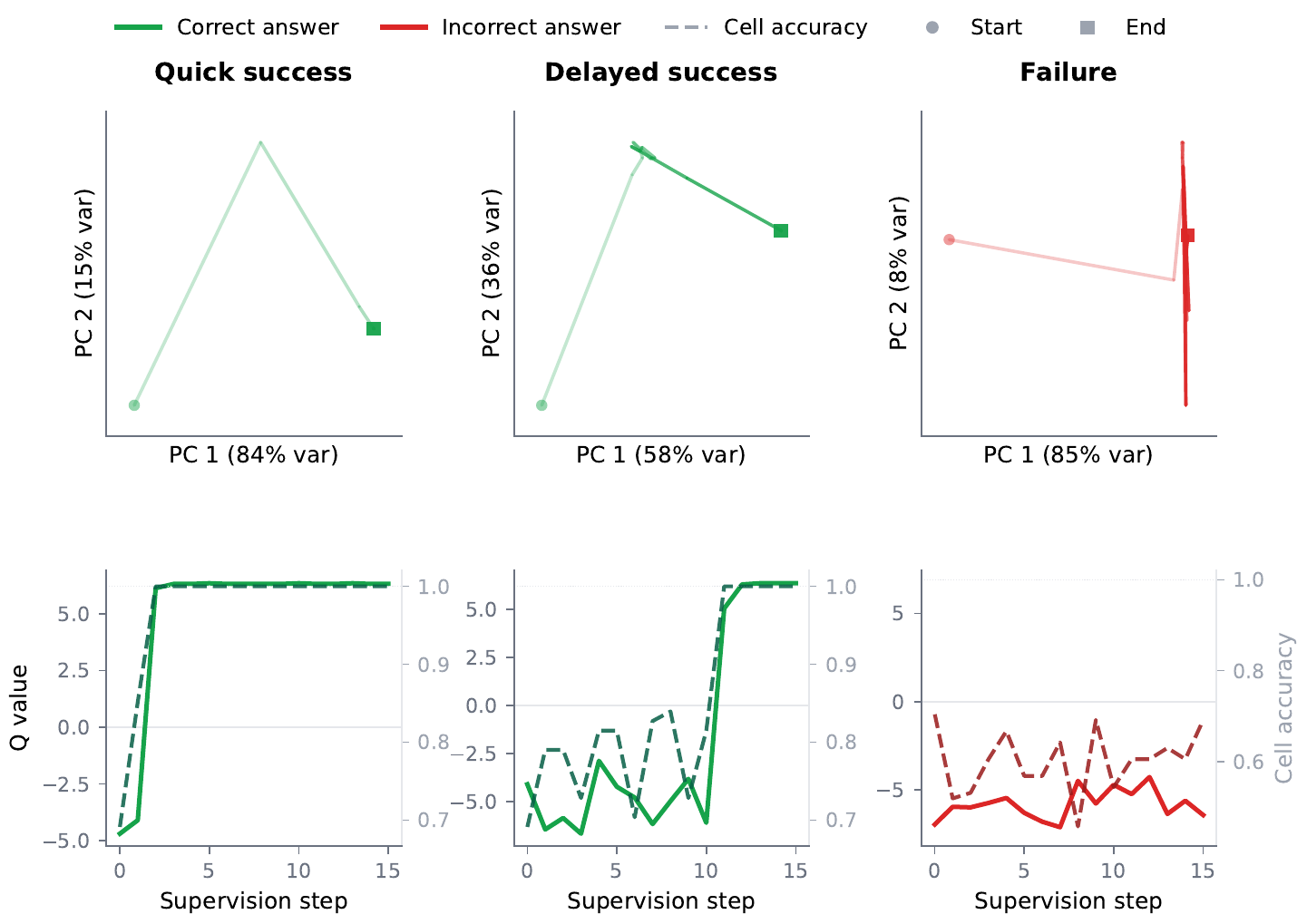
The mechanistic analysis in Section 3 of the PTRM paper is the starting point. The authors recorded TRM’s latent trajectories on PPBench, for 100 puzzles at a time and at the granularity of one supervision step, and projected them onto the principal plane via Principal Component Analysis (PCA). The trajectories fall into three qualitative modes.
- Quick success: within a few steps the trajectory moves into a convergent region and stays there. The Q value (halting logit) and the cell accuracy (the fraction of predicted cells that are correct) rise in sync and saturate at the same supervision step.
- Delayed success: the trajectory oscillates for many steps inside a bounded region, and then at some step suddenly escapes to a different region and converges. The Q value and the cell accuracy spike at the same moment of escape.
- Failure: the trajectory keeps oscillating in the bounded region, the Q value stays negative throughout (below 0.5 after sigmoid), and the cell accuracy never reaches 100 %.
From these observations, the authors introduce the vocabulary of good basin / bad basin. A good basin is a latent region in which the cell accuracy stays high, and a bad basin is one in which it does not. The key finding is that failure and delayed success behave identically in the early phase. Both are trapped in the same bad basin, and only the latter happens to escape through some stochastic fluctuation and reaches the correct answer. PTRM’s diagnosis is that “failure is not a lack of capability but a lack of an escape mechanism”.
The Q Head Tracks Trajectory Quality
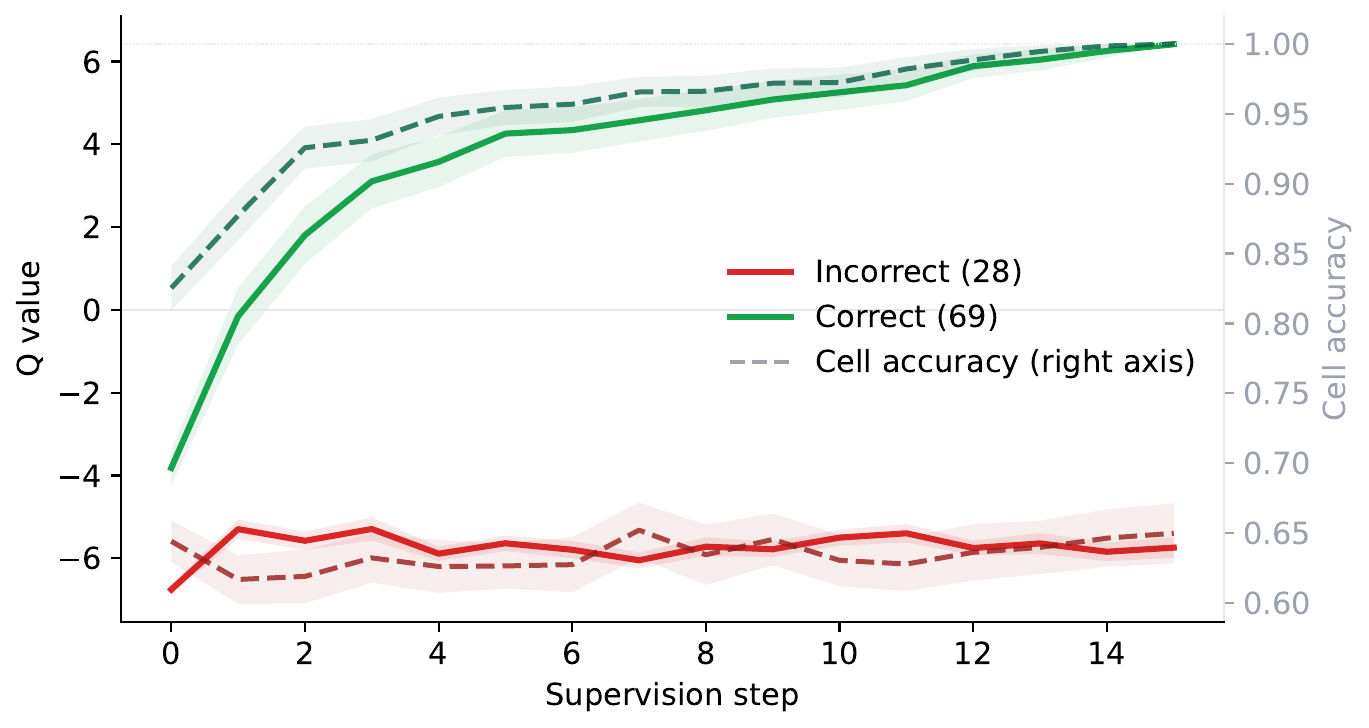
The second finding that anchors the PTRM design is in Section 3.2. TRM’s Q head was originally trained as the halting signal of Adaptive Computation Time (ACT) (Graves 2016), with a binary cross-entropy on whether “the current prediction matches the ground truth”. Aggregating over 100 PPBench validation puzzles, the authors find that the Q head’s logit \(\hat q\) tracks the cell accuracy almost perfectly at every supervision step.
At convergence, the two groups separate sharply, with \(\hat q \approx +6\) (sigmoid about 1) on correct trajectories and \(\hat q \approx -6\) (sigmoid about 0) on incorrect ones. The core interpretation of PTRM is that “as a by-product of the ACT auxiliary loss, TRM had effectively learned a verifier inside itself”. The downstream test-time procedure reuses this Q head as a rollout selector without any additional training.
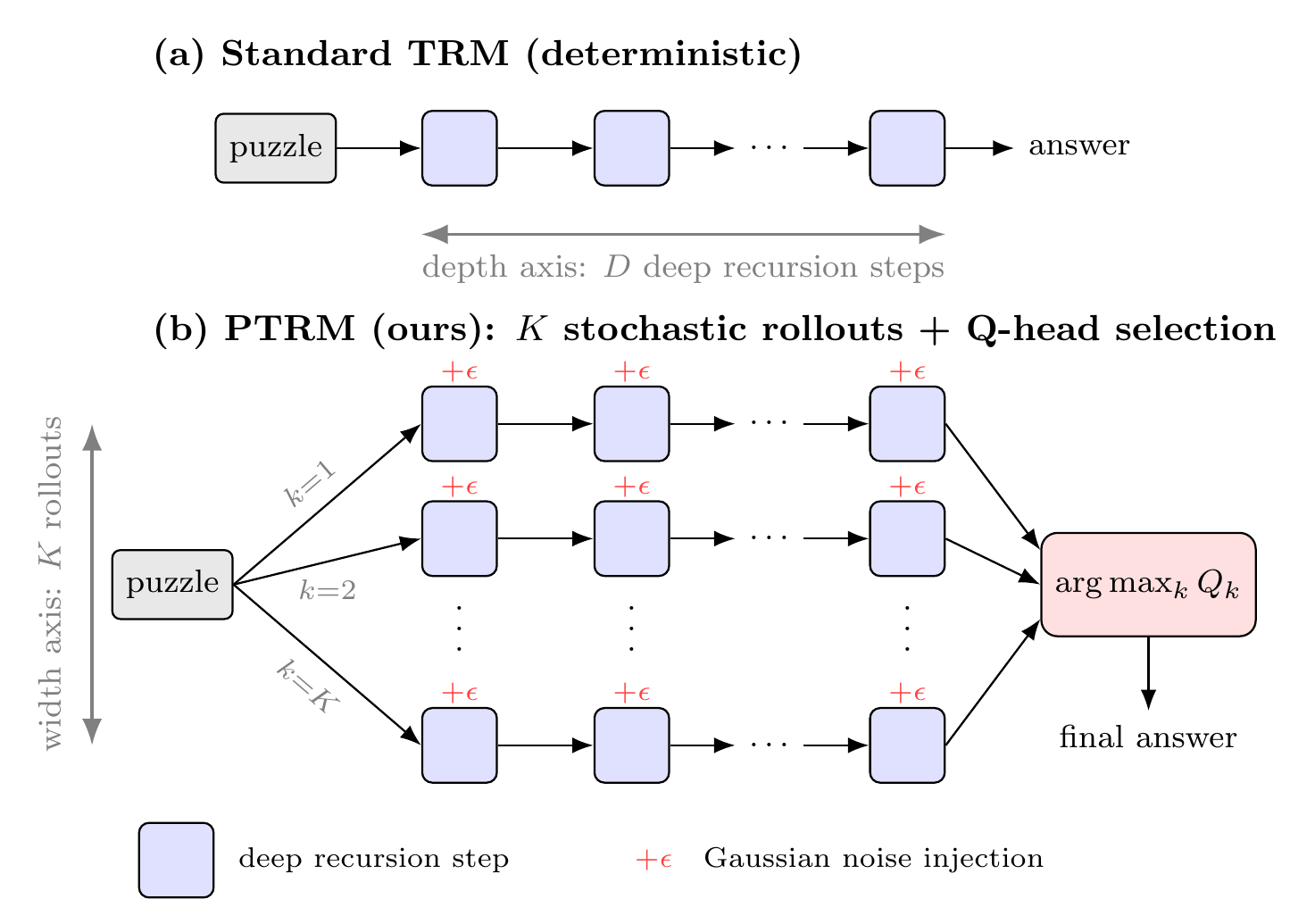
PTRM Method
PTRM assembles the two findings of the previous section into a single inference-time procedure. At every deep recursion step, Gaussian noise of scale \(\sigma\) is added to the latent \(z\). This is run as \(K\) parallel rollouts, and the best trajectory is chosen by the terminal Q value of each rollout. TRM’s architecture is left untouched, and the checkpoint is used as is. The intervention is purely at test time on a trained model.
Algorithm
We reproduce Algorithm 1 of the paper here. rec is TRM’s deep recursion step (one round of latent recursion), \(f_O\) is the output head, and \(f_Q\) is the Q head. \(D\) is the number of supervision steps.
def ptrm_inference(x, K, D, sigma, z0, y0):
candidates = []
for k in range(K): # K parallel rollouts
z, y = z0, y0
for t in range(D): # D deep recursion steps
eps = sigma * randn_like(z) # Gaussian noise
z = z + eps
z, y = rec(x, z, y) # standard TRM step
y_hat = argmax(f_O(y))
q_hat = f_Q(y)
candidates.append((y_hat, q_hat))
k_star = argmax([q for _, q in candidates])
return candidates[k_star][0]What deserves attention is that the noise injection happens at every supervision step, not only at the first one of a rollout. As discussed below, this is consistent with GRAM’s (Baek et al. 2026) ablation that “adding noise only to the initial \(z\) does not work”, and shows that independent stochasticity is needed at each step of the trajectory.
Empirical Demonstration of Bad-Basin Escape
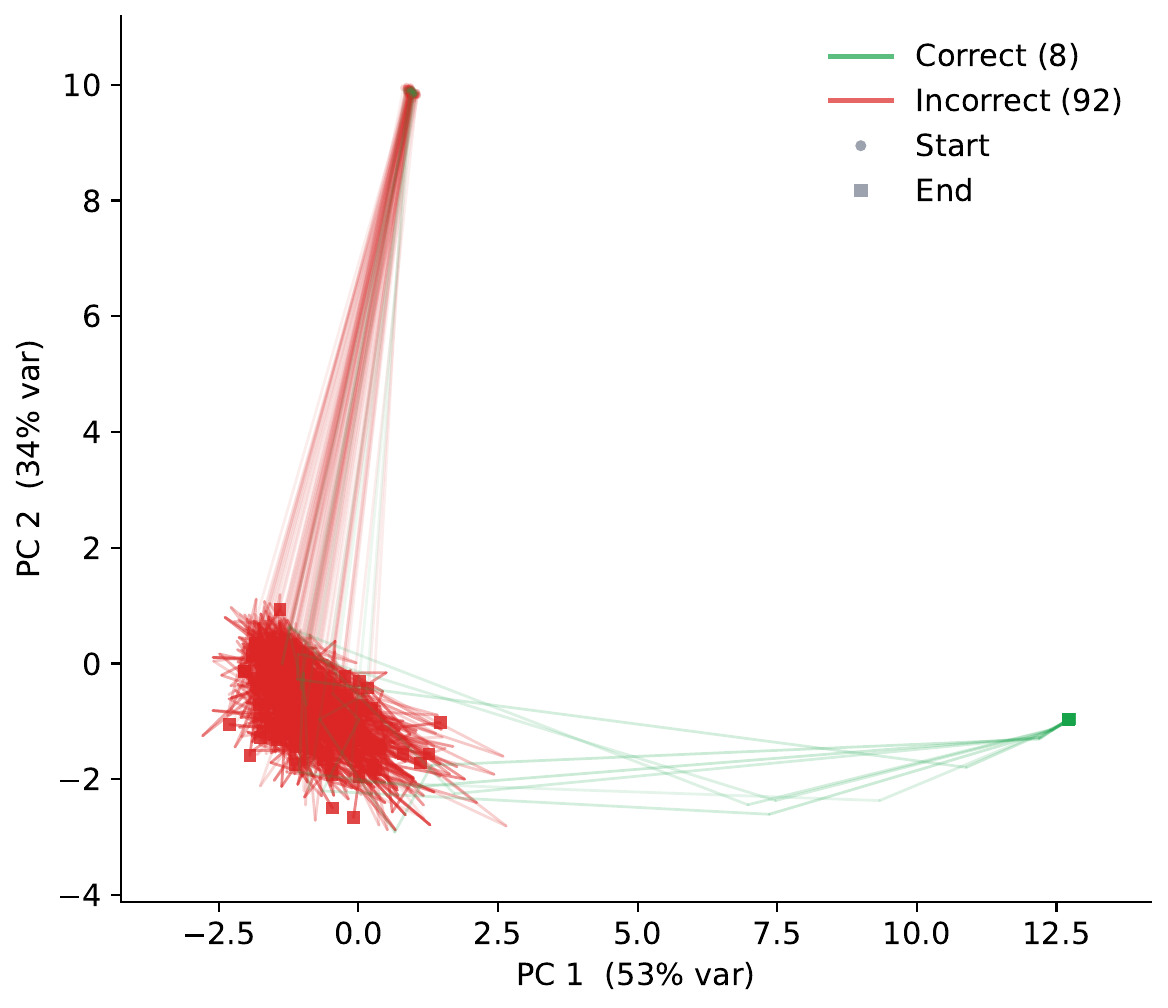
Section 4.1 takes a single failure puzzle from Figure 2 and runs \(K=100\) rollouts on it. Of the 100, 92 stay in the same bad basin, and only 8 escape to a distinct region and reach the correct answer. The number of escapes increases monotonically with \(K\), from 0 at \(K=5\), to 1 at \(K=25\), to 8 at \(K=100\). This quantitatively confirms that Gaussian noise generates a per-rollout escape probability.
Width Scaling and the Verifier Quality of the Q Head
Section 4.2 organizes PTRM’s most practical contribution. The authors distinguish three aggregation metrics.
- pass@\(K\): the probability that any of the \(K\) rollouts is correct (oracle upper bound)
- best-Q@\(K\): the probability that the rollout with the highest Q value is correct (the practical metric)
- mode@\(K\): the probability that the most frequent answer is correct (voting)
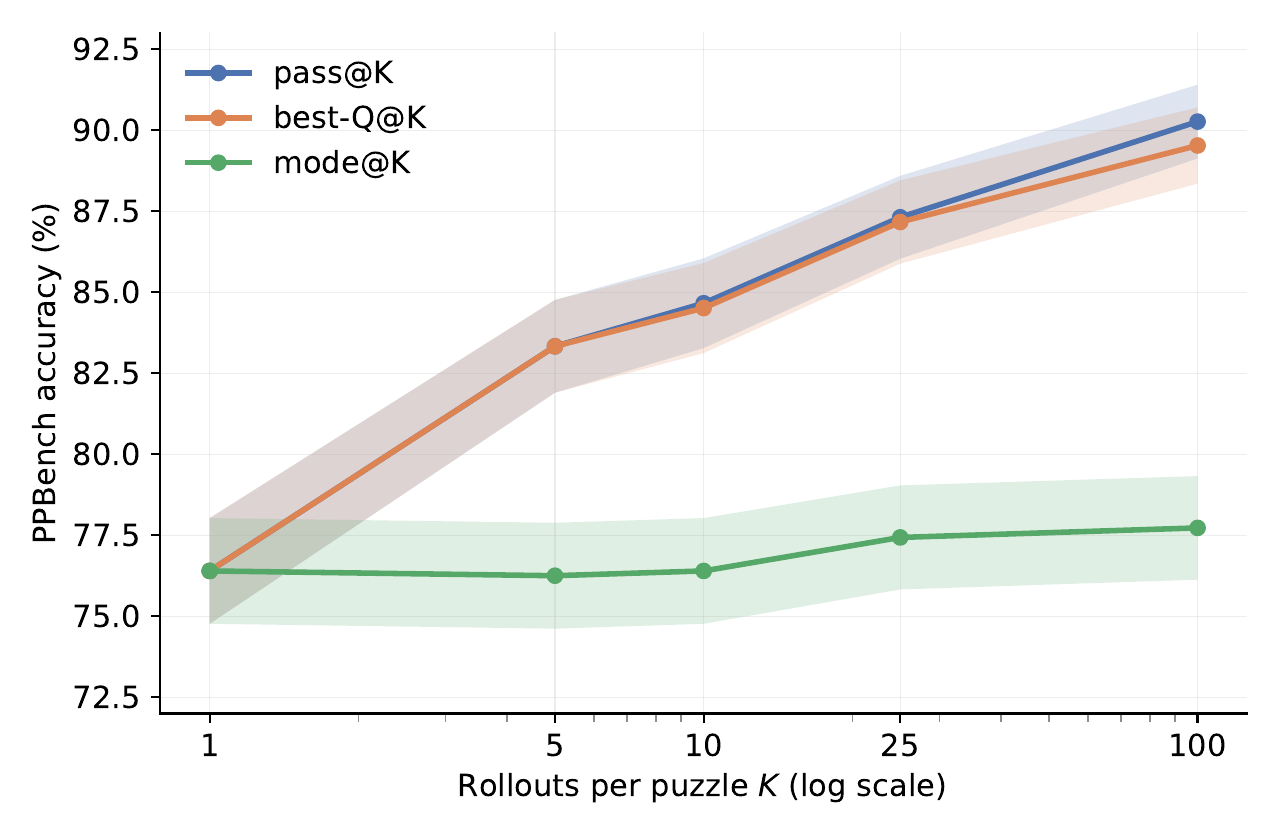
On PPBench validation, as \(K\) increases from 1 to 100, both pass@\(K\) and best-Q@\(K\) rise from 76.4 % to 89.5 %, and the gap between them stays below 1 pp throughout. This means that the Q head functions almost as well as an oracle verifier. By contrast, mode@\(K\) rises by only 1.3 pp. The gains from width scaling come from Q head selection, not from voting.
The comparison with the depth axis is also in Section 4.2. With \(K=1\) fixed, increasing depth \(D\) from 16 to 48 lifts PPBench validation from 76.4 % to only 79.5 % (+3.1 pp). With \(D=16\) fixed, increasing \(K\) from 1 to 100 lifts it by +13 pp. Combined with the computational property that rollouts are independent and parallelizable while depth is sequential, width becomes the primary test-time scaling axis.
Main Results
Section 5 of the paper evaluates PTRM on three benchmarks. The shared protocol is to “use the public TRM checkpoint as is and only change the inference settings \((K, D, \sigma)\)”.
PPBench
PPBench (Waugh 2026) is a constraint satisfaction puzzle collection with 62,231 puzzles across 94 puzzle types and is the main benchmark of PTRM. The authors focus on 6 types (sudoku, lightup, nurikabe, shakashaka, heyawake, tapa) and measure per-puzzle accuracy on the 300-puzzle golden set defined by Waugh et al. They aggregate over the 5 types that exclude shakashaka, which deterministic TRM already solves at 100 %.
The main result is that PTRM (\(K=100, D=48, \sigma=0.2\)) reaches an aggregate of 91.2 %, broken down as sudoku 97.8 %, lightup 100 %, nurikabe 88.9 %, heyawake 85.7 %, and tapa 80.0 %. This is +28.6 pp above deterministic TRM (\(K=1, D=16\)) at 62.6 %. TRM with depth alone increased (\(K=1, D=48\)) reaches only 66.0 % (+3.4 pp), confirming that most of the gain is from width.
The comparison with frontier LLMs is taken on the same golden set. With direct prompting, gemini-3.1-pro reaches 24.5 %, gpt-5.2@xhigh 24.5 %, and claude-opus-4-6@thinking 34.7 %. The ensemble of the top 7 LLMs with multi-step agentic prompting (assuming a perfect verifier) reaches 55.1 %. PTRM beats this by 36 pp at 91.2 %, and the cost per puzzle is $0.001, three orders of magnitude cheaper than the LLM ensemble at $2.66.
Sudoku-Extreme, Maze-Hard, ARC-AGI-2
Section 5.3 evaluates PTRM on the same three benchmarks used by the original TRM paper. On Sudoku-Extreme, TRM 87.28 % becomes PTRM 98.75 % (\(K=100, D=64, \sigma=0.3\), state-of-the-art). On Maze-Hard, 83.80 % becomes 86.73 % (\(K=100, D=16, \sigma=1.0\)). On ARC-AGI-2, pass@1 goes from 7.36 % to 8.47 % and pass@100 from 14.31 % to 15.97 % (\(K=25, D=16, \sigma=0.2\), with pass@2 at 9.72 %, roughly on par).
Sudoku-Extreme is the benchmark on which PTRM most dramatically eliminates the basin trap that was deterministic TRM’s weakness, and PTRM reaches state-of-the-art there. On ARC-AGI-2, however, it does not reach the large LLMs in the Grok-4 family, and on Maze-Hard best-Q@\(K\) falls well short of pass@\(K\) (see the ablation below). One of the limits of PTRM, acknowledged by the paper itself, is that there are tasks where “the verifier quality of the Q head becomes the ceiling”.
Noise Ablation
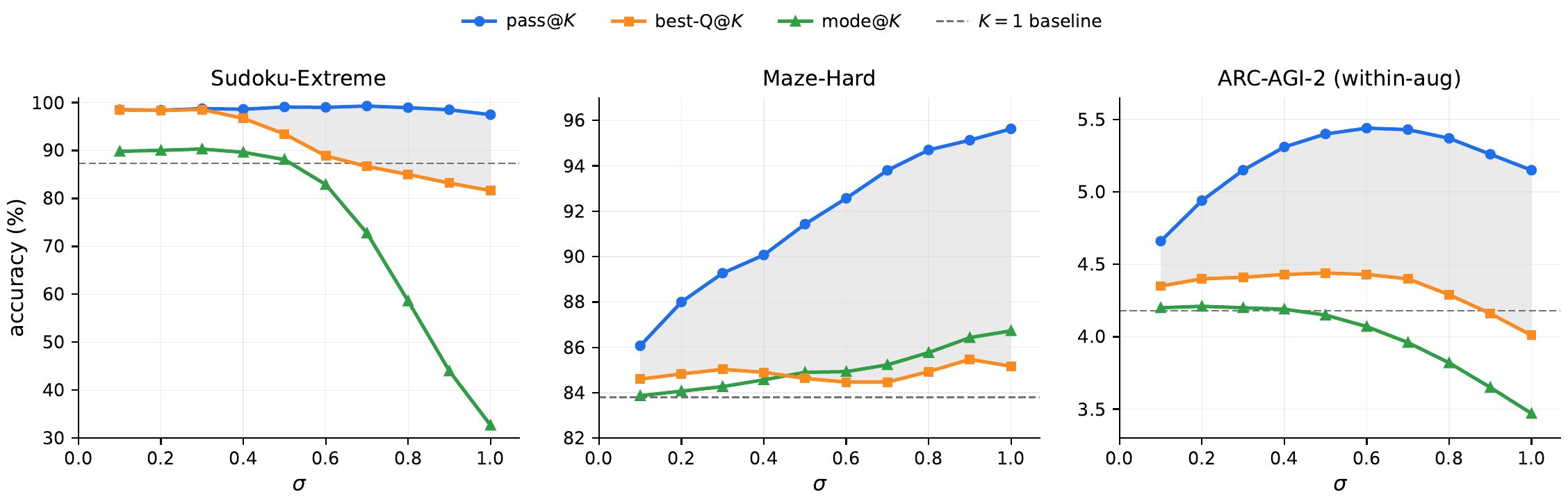
Section 5.4 and Appendix B sweep \(\sigma\) on the three benchmarks. The optimal \(\sigma\) is task-dependent.
- Sudoku-Extreme: hits the ceiling around \(\sigma \approx 0.1\) and stays roughly flat up to \(\sigma = 1.0\). best-Q@\(K\) is 98.5 %, within 1 pp of pass@\(K\) at 99.3 %.
- Maze-Hard: pass@\(K\) keeps rising up to \(\sigma \approx 1.0\), from 83.8 % to about 96 %. best-Q@\(K\) stays around 86 %, and the gap between the two opens to about 10 pp. A large verifier headroom remains.
- ARC-AGI-2: peaks around \(\sigma \approx 0.6\). The gap between best-Q@\(K\) and pass@\(K\) is also not negligible.
The wide gaps on Maze-Hard and ARC-AGI-2 show that what limits PTRM is not “search capability” but “verifier capability”. The central direction of the paper’s Future Work is that a stronger verifier, trained or attached, could pick up the rollouts that the current Q head is missing.
In Appendix C, the authors try a Langevin dynamics update that uses the Q head’s gradient to push the latent toward a high-Q region, \(z \leftarrow z - \eta \nabla_z E(z) + \sqrt{2\eta}\, \xi\) (with \(E(z) = -\log \mathrm{sigmoid}(f_Q(z))\) and \(\xi \sim \mathcal{N}(0, I)\)). On PCA plots, \(\nabla_z f_Q\) does point toward the good basin, so the idea looked promising, but the accuracy matched a noise-only ablation in which the gradient term was set to zero. All of the gain came from the noise term, and the gradient guidance added nothing. Based on this, the authors dropped the Langevin variant and converged to the simpler PTRM. This is a methodological finding that test-time gradient guidance on a trained model, at least through TRM’s Q head, did not work.
Limits and Contributions in This Book
Section 7 / Conclusion of the PTRM paper acknowledges three limits. First, the validation is mainly on grid-shaped puzzles, and the gains on ARC-AGI-2 and Heyawake are small. Second, the verification quality of the Q head is the ceiling, and on Maze-Hard a large gap between best-Q@\(K\) and pass@\(K\) remains. Third, the development of a stronger verifier is left as future work.
In the context of this book, PTRM’s contributions can be organized into three points.
First, it diagnoses “the deterministic limit of TRM” at the mechanism level. The vocabulary of three trajectory modes on the PCA plot, and of bad / good basins, becomes a shared language for talking about the behavior of the TRM lineage. Combined with Efstathiou & Balwani’s attractor hypothesis, the dynamics interpretation of small recursive models like HRM / TRM enters a new stage.
Second, it establishes width scaling as a test-time compute axis. Depth is sequential, cannot be parallelized, and from some point onward starts to incur overfitting cost (consistent with TRM’s Table 4, which already showed that “deeper is not always better”). Width does not have these properties, and gains rise linearly with the number of rollouts. As one answer to the question of “what to invest test-time compute in”, width scaling is now an established option.
Third, the finding that a trained Q head can be reused as a verifier is an observation that carries over to recursive reasoning models in general. A head trained as an auxiliary loss for adaptive halting actually works as a trajectory selector. If future RRM designs build in the assumption that halting signals can “double as a verifier”, the efficiency of test-time scaling becomes easier to raise.
In this book, as a continuation of the “subtraction” performed in TRM (peeling off the HRM story through ablations), PTRM presents the minimal intervention that puts a trained TRM directly to work at test time. Lined up with GRAM (the “addition” that introduces stochasticity at training time) and LDT (which “sounds up” the latent via lattice projection), the three form a series in which the intervention onto the TRM core grows progressively larger. PTRM is the lightest of the three, and by changing only the test-time procedure while keeping the checkpoint untouched, it sits at the position that first asks “what is gained and what is lost” relative to the heavier modifications that follow.