HRM
The Hierarchical Reasoning Model (HRM) (Wang et al. 2025) is a recursive reasoning model proposed in a paper that Sapient Intelligence (Singapore) and Sen Song’s group at Tsinghua University posted to arXiv in June 2025 and revised through v3 by August of the same year. The first author is Guan Wang, and the code is released at github.com/sapientinc/HRM. The paper drew large attention on X immediately after release, and subsequent independent verification by the ARC Prize Foundation (Ge et al. 2025) together with a mechanistic analysis (Ren and Liu 2026) sparked broad discussion of the gap between claims and evidence. This chapter separates the proposed method, its rationale, the experimental results, and the criticisms into three layers.
Problem Setting: Calling CoT an “Externalized Crutch”
Fixed-depth Transformers are confined to the neighborhood of AC⁰ / TC⁰ in the complexity-theoretic sense, and cannot execute polynomial-time planning or symbolic manipulation end-to-end. The paper takes this structural limitation as its starting point and argues that Chain-of-Thought (CoT) is an “externalized crutch” that offloads the limit onto an external token tape. CoT, it says, suffers from a triple burden: (i) step decomposition is hand-crafted and brittle, (ii) it requires large amounts of demonstrations, and (iii) decoding latency scales linearly. The paper takes the position that these should instead be addressed by iterative computation inside the latent space. The rhetorical motivation leans heavily on neuroscience, repeatedly emphasizing three points: (a) the cortical hierarchy processes information at different spatial and temporal scales, (b) frequency separation between theta waves (4–8 Hz) and gamma waves (30–100 Hz) enables stable high-level control, and (c) iterative refinement via recurrent connectivity avoids the deep credit assignment problem.
Architecture: Four Components and Dual Recursion
HRM consists of four learnable components: an input network \(f_I\), a low-level recurrent module \(f_L\), a high-level recurrent module \(f_H\), and an output head \(f_O\). One forward pass unrolls \(N\) high-level cycles times \(T\) low-level steps, for a total of \(NT\) timesteps. Indexing timesteps by \(i = 1, \ldots, NT\), the input \(x\) is first projected into a working representation \(\tilde x = f_I(x; \theta_I)\). The update rules at each timestep are as follows. L is updated at every step, while H is updated only at cycle boundaries (timesteps that are multiples of \(T\)):
\[ z_L^i = f_L(z_L^{i-1}, z_H^{i-1}, \tilde x; \theta_L) \tag{1}\]
\[ z_H^i = \begin{cases} f_H(z_H^{i-1}, z_L^{i-1}; \theta_H) & \text{if } i \equiv 0 \pmod T \\ z_H^{i-1} & \text{otherwise} \end{cases} \tag{2}\]
After \(N\) cycles, the final prediction is \(\hat y = f_O(z_H^{NT}; \theta_O)\). Both \(f_L\) and \(f_H\) are encoder-only Transformer blocks (hidden 512, 8 heads, 4 layers, SwiGLU, RMSNorm, Rotary Positional Encoding, Post-Norm), and their inputs are combined by element-wise addition.
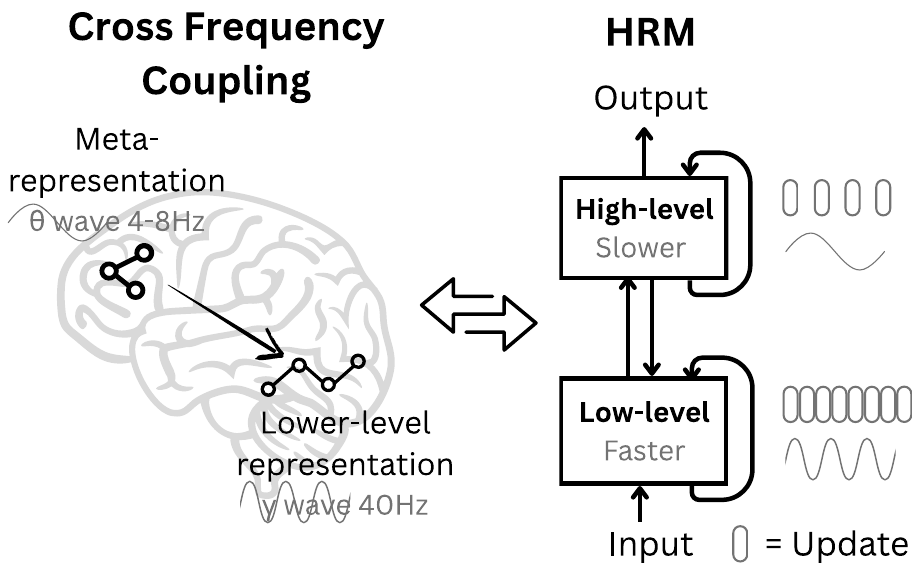
Hierarchical Convergence: Preventing Computational Exhaustion
A standard Recurrent Neural Network loses update magnitude once it converges early to a fixed point, after which subsequent steps are effectively dead. HRM claims to avoid this via a mechanism it calls hierarchical convergence. When L reaches a local equilibrium after \(T\) steps, H is updated once and injects a new \(z_H\) into L, periodically resetting L’s trajectory. As a result, the forward residual over the full \(NT\) steps (the norm of the difference between consecutive hidden states) shows periodic spikes at each cycle boundary. The figure below compares a standard RNN, a deep Transformer, and HRM, and shows that only HRM sustains computational activity.
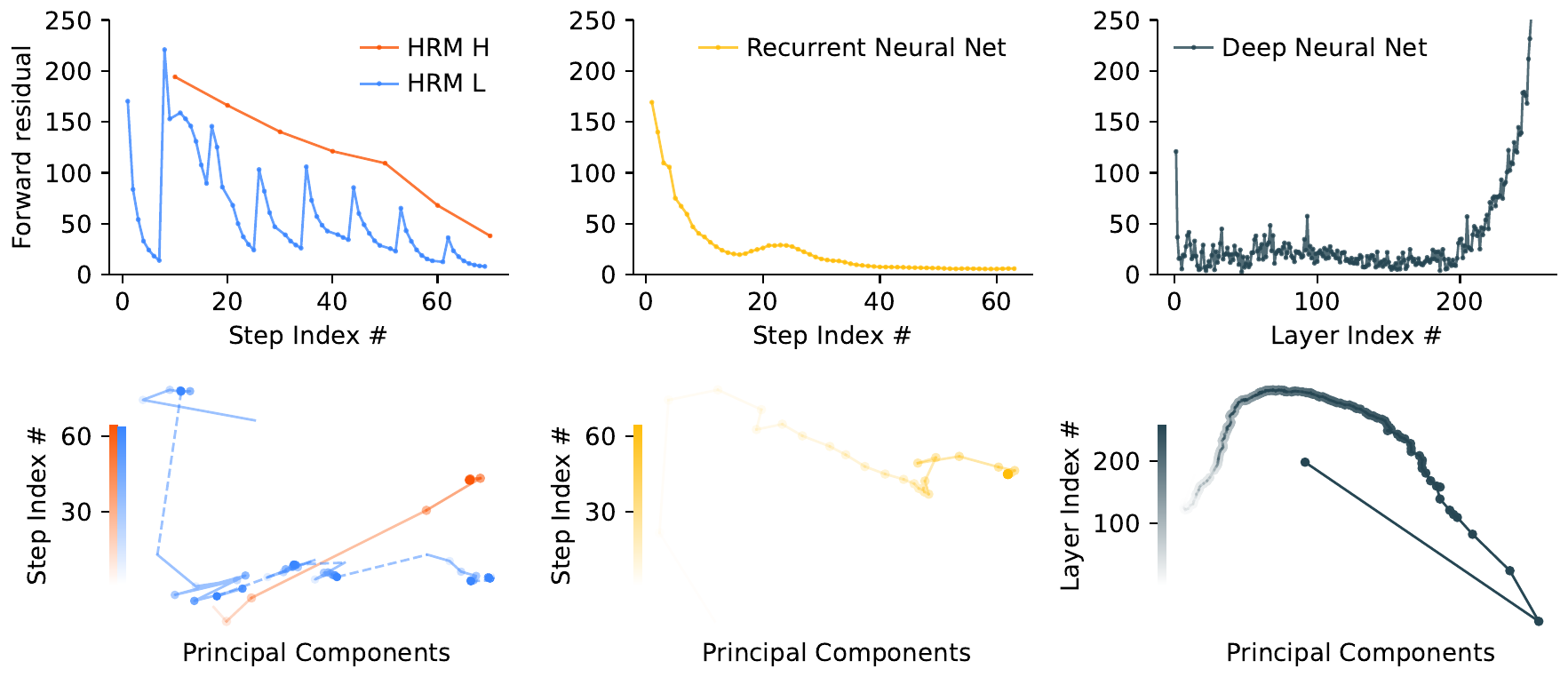
The paper shows that HRM outperforms a same-sized recurrent Transformer at any computational depth, and argues that hierarchical convergence is the essential mechanism that extends effective depth. This claim is revisited in the criticism section below.
1-Step Gradient Approximation: Local Backprop Derived from DEQ
Backpropagation Through Time (BPTT) needs to retain \(T\) steps of hidden state, with memory growing as \(O(T)\). HRM avoids this within the same framework as the Deep Equilibrium Model (DEQ) (Bai et al. 2019). Idealizing L as having converged to a fixed point \(z_L^\star = f_L(z_L^\star, z_H^{k-1}, \tilde x; \theta_L)\) and considering the H-side fixed point \(z_H^\star = \mathcal F(z_H^\star; \tilde x, \theta)\), the Implicit Function Theorem (IFT) gives the exact gradient as:
\[ \frac{\partial z_H^\star}{\partial \theta} = (I - J_{\mathcal F}\big|_{z_H^\star})^{-1} \frac{\partial \mathcal F}{\partial \theta}\bigg|_{z_H^\star} \tag{3}\]
where \(J_{\mathcal F} = \partial \mathcal F / \partial z_H\) is the Jacobian of the H-side update. Because the matrix inverse is expensive, HRM keeps only the first-order term of the Neumann expansion \((I - J_{\mathcal F})^{-1} = I + J_{\mathcal F} + J_{\mathcal F}^2 + \cdots\) and approximates \((I - J_{\mathcal F})^{-1} \approx I\). This contracts the gradient path to a three-step local backprop, “output head → final H state → final L state → input embedding”, and reduces memory to \(O(1)\). The paper justifies this biologically as “short-range, temporally local synaptic credit assignment” and connects it to the lineage of Equilibrium Propagation and Eligibility Propagation.
This approximation only holds when L has converged to a fixed point and \(I - J_{\mathcal F}\) is non-singular. The HRM implementation only runs \(N = T = 2\), so the \(z_H\) residual is not converged to zero to begin with. The Tiny Recursive Model (TRM) (Jolicoeur-Martineau 2025), covered in the next chapter, points out this broken assumption and shows that simply discarding the 1-step gradient and replacing it with full BPTT improves Sudoku accuracy by more than 30 points. The approximation that forms the theoretical core of HRM turned out to be empirically the biggest bottleneck.
Deep Supervision and Adaptive Computation Time
HRM calls one forward pass a segment and introduces deep supervision, in which the hidden state is detached at the end of each segment and passed as input to the next segment. It iterates for up to \(M\) segments, taking a loss and updating gradients per segment. This detach stops gradient propagation across segments, making the recursive deep supervision as a whole another 1-step approximation.
In addition, citing Daniel Kahneman’s System 1 / System 2, the paper introduces a Q-head and implements Adaptive Computation Time (ACT) (Graves 2016), which decides halt vs. continue per segment. The Q-head predicts action values from the final H state:
\[ \hat Q^m = \sigma(\theta_Q^\top z_H^{mNT}) \in \mathbb R^2 \tag{4}\]
where \(\hat Q^m = (\hat Q^m_\text{halt}, \hat Q^m_\text{continue})\). It is trained with standard Q-learning: the halt reward is the prediction correctness \(\mathbf 1\{\hat y^m = y\}\), the continue reward is 0, and the bootstrap target is the maximum Q value of the next segment. Neither a replay buffer nor a target network is used, but the paper argues that the combination of Post-Norm + RMSNorm + AdamW is equivalent to constrained optimization with an \(L^\infty\) constraint, which contributes to stability. At test time, simply setting \(M_{\max}\) larger than at training time yields inference-time scaling.
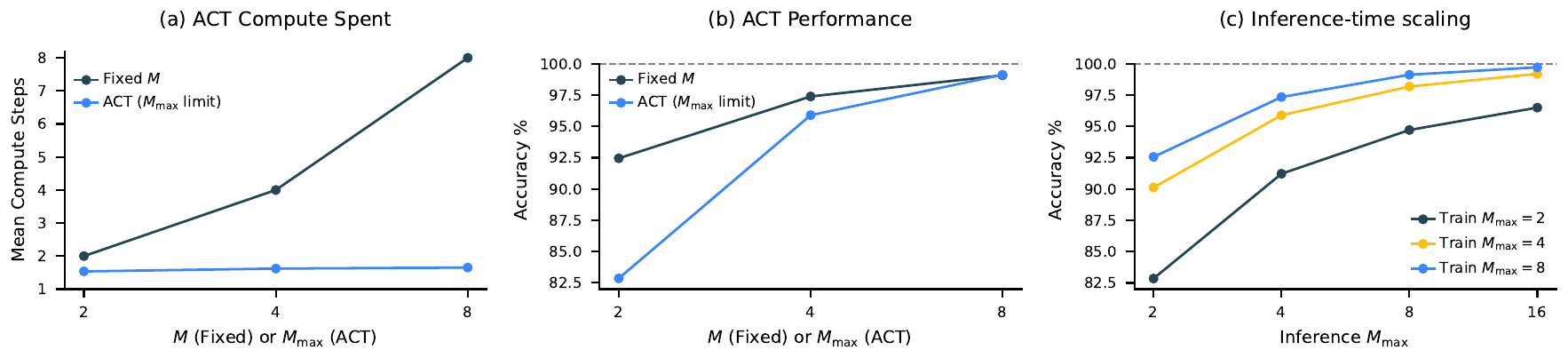
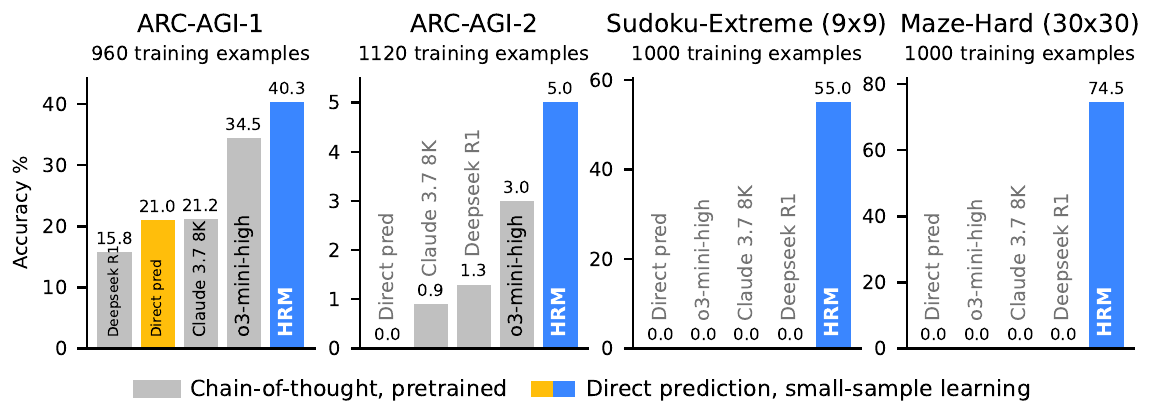
Experiments: The Claim of Beating Large LLMs from Scratch with 1000 Samples
The main HRM experiments use the following three benchmarks, all under the setting of about 1000 training samples, no pretraining, no CoT labels, and from-scratch training.
- ARC-AGI-1 / ARC-AGI-2: grid-based inductive reasoning puzzles
- Sudoku-Extreme: hard Sudoku requiring 22 backtracks on average
- Maze-Hard 30×30: shortest-path search (only path lengths of 110 or more)
| Benchmark | HRM (27M) | Direct pred (same-size Transformer) | CoT comparison |
|---|---|---|---|
| ARC-AGI-1 (~960) | 40.3 % | 15.8 % | o3-mini-high 34.5 %, Claude 3.7 8K 21.2 % |
| ARC-AGI-2 (1120) | 5.0 % | 0 % | Claude 3.7 0.9 %, DeepSeek-R1 1.3 %, o3-mini-high 3.0 % |
| Sudoku-Extreme (1000) | 55.0 % | 0 % | All CoT models including DeepSeek-R1 (DeepSeek-AI et al. 2025) at 0 % |
| Maze-Hard 30×30 | 74.5 % | 0 % | All CoT models at 0 % |
For ARC-AGI evaluation, 1000 augmentations from rotation, reflection, and color permutation are applied to the input, and a learnable puzzle identifier token is prepended per task. At test time, the top two from a majority vote over 1000 augmented inferences are taken as the final answer. This setup follows the ARC-AGI “2 attempts” rule, but as discussed below, the dependence on the puzzle identifier token becomes a major point of contention in the generalization argument.
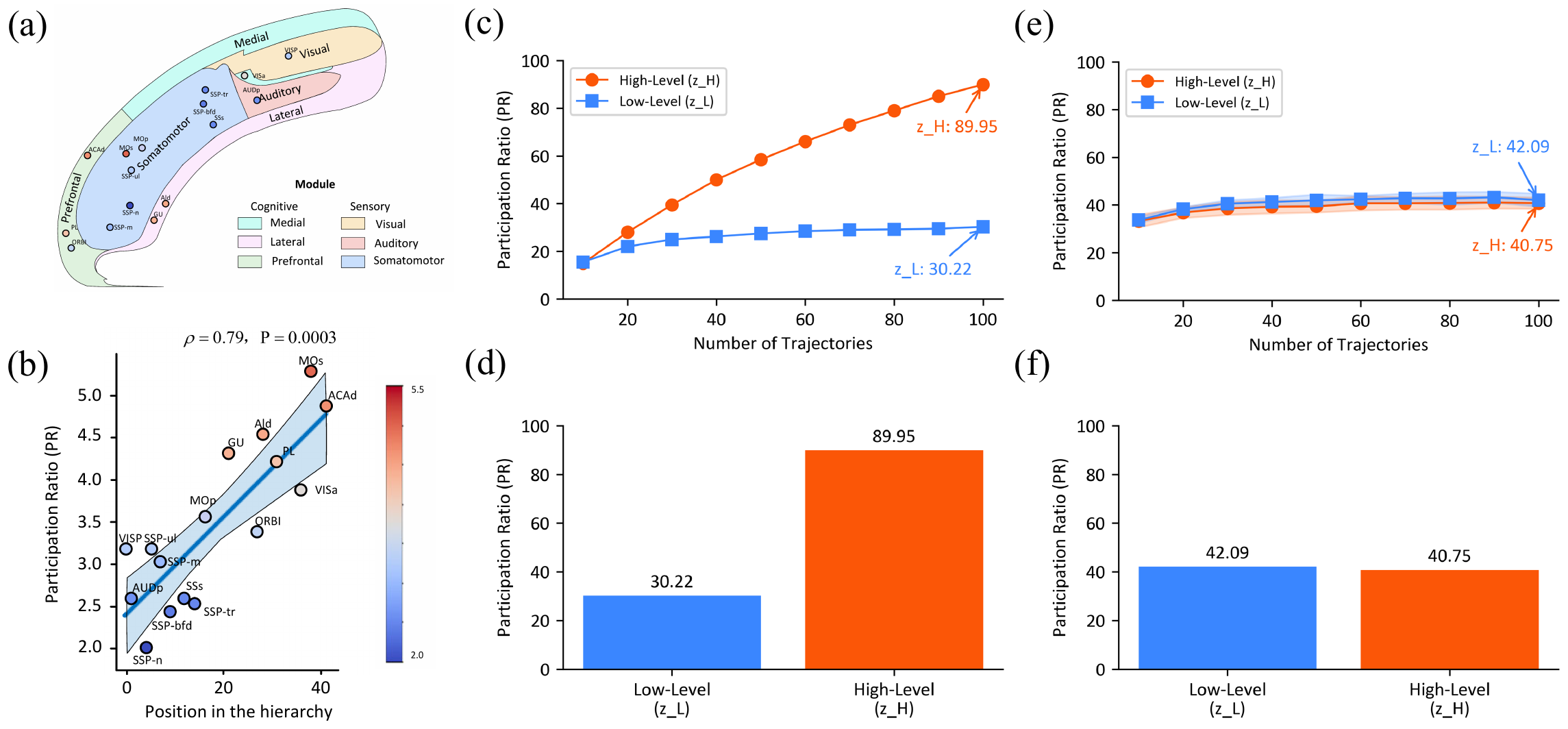
Brain Correspondence: Hierarchy in Participation Ratio
The closing section of the paper claims that HRM’s internal representations exhibit the same kind of dimensionality hierarchy as the mouse cortex. From the eigenvalues \(\{\lambda_i\}\) of the covariance matrix of each module’s hidden state, the Participation Ratio (PR) is computed as:
\[ \text{PR} = \frac{(\sum_i \lambda_i)^2}{\sum_i \lambda_i^2} \tag{5}\]
For trained HRM, the PR is \(z_L = 30.22\) and \(z_H = 89.95\), with the ratio \(z_H / z_L \approx 2.98\) reported to be similar to the mouse cortical hierarchy’s \(\approx 2.25\). When the same architecture is measured untrained, the PRs are 42.09 and 40.75 respectively and the hierarchical gap vanishes, so the paper concludes that the PR hierarchy is an emergent property gained through training. The authors themselves note, however, that this evidence is correlational rather than causal, and that an interventional experiment constraining the dimensionality of the H module would confound the entire training process and be hard to evaluate.
Independent Verification: Most of the Claims Peeled Off
About a month after HRM’s release, in August 2025, the ARC Prize Foundation published a systematic ablation in an independent verification (arcprize.org/blog/hrm-analysis). A perspectives paper by Tomaso Poggio et al. (Ge et al. 2025) and a mechanistic analysis paper (Ren and Liu 2026) followed, and the gap between the HRM narrative and the evidence was widely debated. The main points are as follows.
- Score drop on the semi-private set: HRM, which posted 40.3 % on the public evaluation set, drops to 32 % on the semi-private set (-9 pp). ARC-AGI-2 stays around 2 %.
- Architectural ablation: replacing it with a same-size vanilla Transformer only drops the score by ~5 pp. The H/L hierarchy is not the main factor.
- The real driver is the outer loop: increasing deep supervision iterations (outer-loop refinement) from 1 to 2 adds +13 pp, and from 1 to 8 nearly doubles the score. A component that is downplayed in the paper carries most of the performance.
- Saturation of augmentation: the claimed 1000 augmentations are unnecessary, and the score saturates at 300.
- Puzzle identifier token dependence: the
puzzle_idembedding seen during training is required, and generalization to new puzzles is structurally impossible. Even when training is restricted to the 400 evaluation tasks, the model still scores 31 % pass@2, so in practice this is closer to recognition and refinement of training templates than “generalization to unseen tasks”.
The mechanistic analysis paper (Ren and Liu 2026) goes further, showing that HRM does not actually satisfy the fixed-point property and fails even on the easiest Sudoku with a single unknown cell. The provocative title “Are Your Reasoning Models Reasoning or Guessing?” reflects the claim that HRM’s solving style is in fact closer to guessing than refinement. François Chollet himself summarized that “the HRM architecture is not what matters; the outer loop is the real body”.
Positioning: The True Novelty Is a Regime Proof
All of HRM’s technical components exist in prior work. Adaptive Computation Time originates in Graves 2016 (Graves 2016), weight-tied depth recurrence in Universal Transformer (Dehghani et al. 2019), implicit gradients via IFT in DEQ (Bai et al. 2019), and probabilistic halting in PonderNet (Banino et al. 2021). More recently, Geiping et al.’s recurrent depth approach (Geiping et al. 2025) has reintroduced the same kind of idea in the context of large-scale LLMs. What was genuinely novel about HRM is that it integrated these existing pieces and showed from scratch that discrete reasoning benchmarks can be handled with 27M parameters and 1000 samples, without CoT data or pretraining. The decorative claims that “hierarchy works”, “the 1-step gradient works”, and “the brain correspondence justifies the mechanism” were later all torn down by TRM’s ablation (Jolicoeur-Martineau 2025) and the ARC Prize Foundation’s verification (Ge et al. 2025; Ren and Liu 2026). What remains as the essence is the “regime proof that a depth-recurrent system can handle discrete reasoning without CoT or large-scale data”.
This conclusion is referenced repeatedly in later chapters. TRM is a “subtractive study” that strips away HRM’s decoration and extracts the core, while GRAM is an “additive study” that adds stochasticity back onto the subtracted minimal core and turns it into a generative model. When reading HRM as the starting point of these three generations, it is most productive to set aside the rhetoric for a moment and check, against the TRM ablation table (covered in the next chapter), what is empirically load-bearing and what is decoration.