A Taxonomy of Latent Reasoning
Hierarchical Reasoning Model (HRM), Tiny Recursive Model (TRM), and Generative Recursive reAsoning Models (GRAM) all advance reasoning through iterative computation over latent state without ever emitting a natural-language trace. Yet the research area called “latent reasoning” is not confined to these three. Pause Tokens (Goyal et al. 2024), Coconut (Hao et al. 2025), Quiet-STaR (Zelikman et al. 2024), Diffusion-of-Thoughts (DoT) (Ye et al. 2024), and Large Concept Model (LCM) (LCM team et al. 2024) run in parallel with different starting points and motivations. This chapter groups representative methods into 7 buckets and argues that group E (recurrent depth), where HRM/TRM/GRAM sit, has 4 properties that decisively separate it from every other group.
Seven Groups: Representative Methods and Test-Time Scaling Axes
Table 1 shows the taxonomy used in this chapter. It can be read as an extension of the activation-based / hidden-state-based split used in the Latent Reasoning Survey (LRS) (Zhu et al. 2025), with placeholder, distillation, diffusion, and concept buckets added.
| Group | Representative methods | Characteristic | Test-time scaling |
|---|---|---|---|
| A. Placeholder tokens | Pause (Goyal et al. 2024), Filler “dot by dot” (Pfau et al. 2024) | Insert meaningless tokens to add forward steps | Number of placeholders (width) |
| B. Continuous CoT (horizontal) | Coconut (Hao et al. 2025), Compressed CoT (CCoT) (Cheng and Durme 2024), Soft Thinking (Zhang et al. 2025) | Feed the last hidden state directly as next input | Number of continuous thoughts (width) |
| C. Implicit CoT distillation | Deng et al. (Deng et al. 2023, 2024) | Distill teacher CoT into the student’s hidden layers | Fixed in principle (student runs a normal forward) |
| D. Self-generated rationale | Quiet-STaR (Zelikman et al. 2024) | Generate internal rationales at each token position | Sampling average over multiple rationales |
| E. Recurrent depth (vertical) | HRM (Wang et al. 2025), TRM (Jolicoeur-Martineau 2025), PTRM (Sghaier et al. 2026), GRAM (Baek et al. 2026), LDT (Davis et al. 2026), Geiping et al. (Geiping et al. 2025) | Recurrently unroll the same layer in the depth direction | Number of recursions (depth); PTRM/GRAM also use parallel trajectories (width) |
| F. Diffusion-based | Diffusion-of-Thoughts (Ye et al. 2024), LaDiR (Kang et al. 2025) | Piggyback reasoning on denoising steps | Number of diffusion steps (infinite-depth limit) |
| G. Concept-level | LCM (LCM team et al. 2024) | Autoregress at the sentence-embedding level | Number of concepts generated |
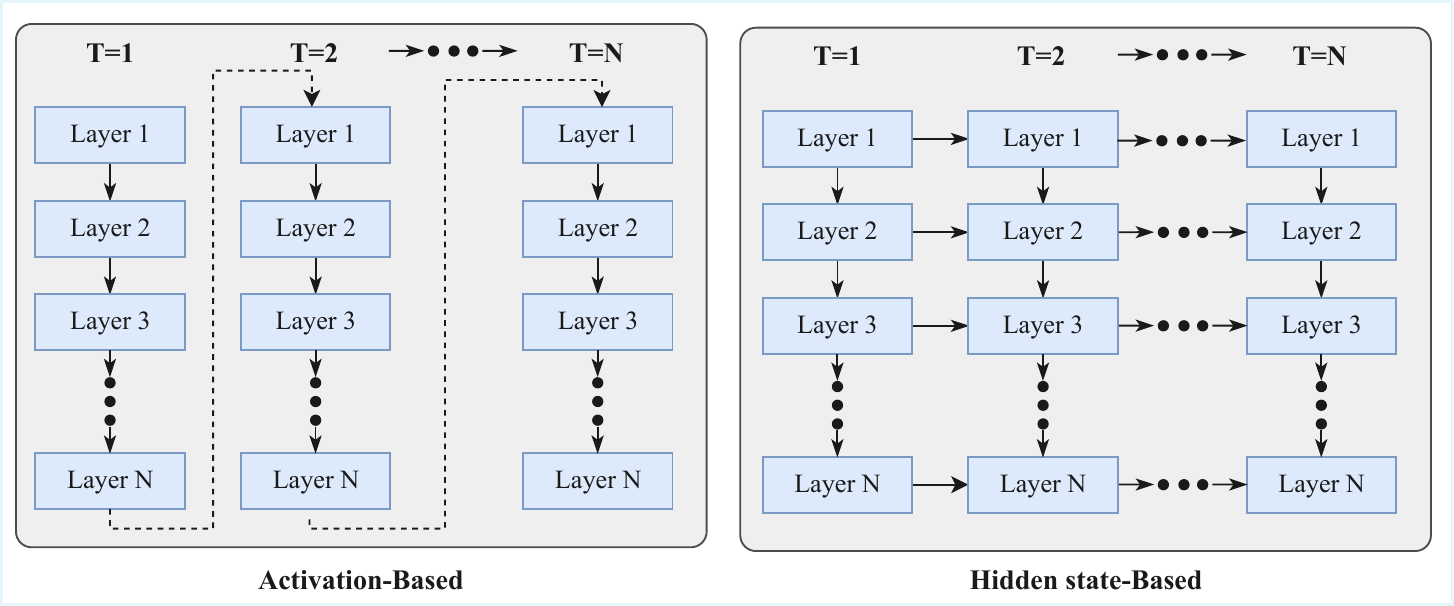
Viewed by LLM dependence, groups A, B, C, D, and G are extensions layered on top of an LLM; group F is partially LLM-dependent; only group E is self-contained and requires no LLM. Group E, the home of HRM/TRM/GRAM, sits at the far pole, passing through no natural language and depending on no LLM. In the vocabulary of LRS (Zhu et al. 2025), group B is horizontal recurrence (injecting hidden state along the temporal axis), and group E is vertical recurrence (recurring the same layer in the depth direction). The diffusion of group F does not lie on either axis and is placed in a separate lineage as a continuous-time limit of infinite depth. Figure 1 reproduces the LRS taxonomy diagram, where group B of this chapter roughly corresponds to “Hidden state-Based” (right side) and group E to “Activation-Based” (left side).
Group A: Padding the Depth with Placeholder Tokens
The simplest form of “latent reasoning” is to insert meaningless tokens into the input to increase the number of forward steps.
Pause Tokens (Goyal et al. 2024), presented at ICLR 2024, insert a learnable special token <pause> between the prefix and the output, and discard outputs until the last pause has been absorbed by attention. With pauses introduced in both pre-training and fine-tuning, a 1B-parameter model gained +18 % on SQuAD, +8 % on CommonsenseQA, and +1 % on GSM8k. The token itself carries no meaning; what grows is only the number of positions attention can operate over.
Filler Tokens / “Let’s Think Dot by Dot” (Pfau et al. 2024) pushes this further, showing that replacing pause tokens with fully meaningless characters such as ... still lifts accuracy from 66 % to 100 % on inductive tasks such as 3SUM. The provocative claim is that “the contents of a CoT can be meaningless; what is needed is only the added computation steps.” This result pours cold water on the interpretability of CoT and reinforces the motivation for groups B through E that follow.
Placeholders buy depth, but what is computed at that depth is not structurally determined. Filler can only solve tasks for which the “computation that leads to the answer” has been implicitly acquired during pre-training, and there is no guarantee that extra tokens help on unfamiliar problems. From group B onward, methods move toward making “what is computed” explicit through hidden-state design.
Group B: Continuous CoT That Bypasses the Language Layer
Group B is the lineage that feeds the last hidden state of an LLM directly back into the next-step input embedding without passing through softmax. As a formulation layered on top of an LLM, it is a continuation of group A, but it differs decisively in that each step carries “one real-valued vector” instead of “one discrete token.”
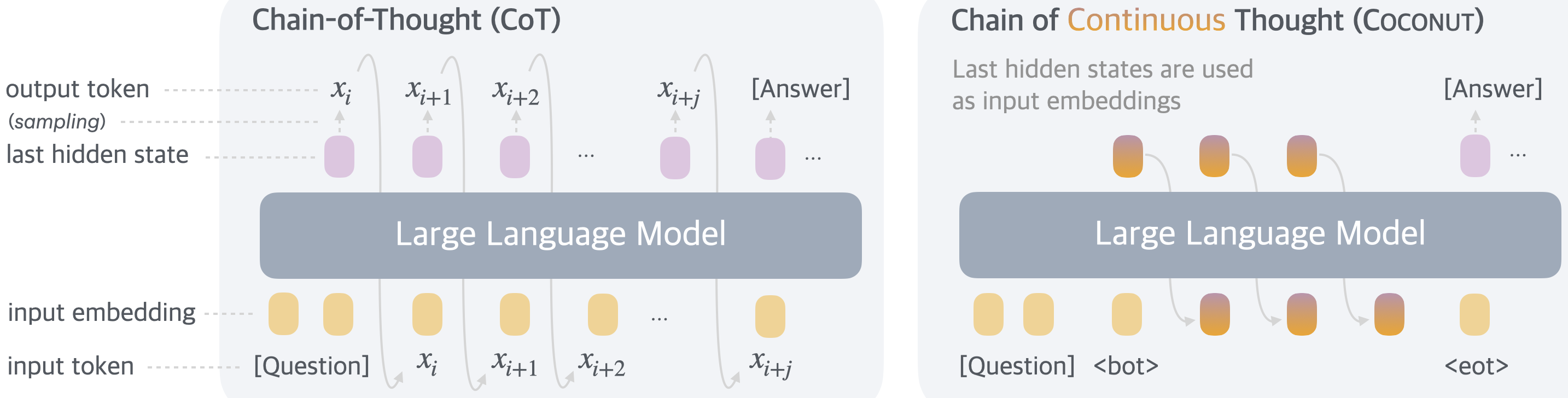
Coconut (Chain of Continuous Thought) (Hao et al. 2025) is the representative. As shown in Figure 2, whereas standard CoT routes each step through hidden → softmax → token → embedding, Coconut connects hidden → embedding directly. The authors argue that this continuous thought holds multiple reasoning paths as a superposition and performs implicit BFS. The implementation signals the switch to latent mode with special tokens <bot> and <eot>, and surpasses standard CoT on ProsQA and a small subset of GSM8k.
Compressed Chain of Thought (CCoT) (Cheng and Durme 2024) follows the same motivation by distilling an explicit reasoning chain into a variable-length sequence of contemplation tokens. It treats CoT as redundant and asks short sequences of continuous vectors to carry the same information. Soft Thinking (Zhang et al. 2025) uses a near-training-free approach: it multiplies the output distribution by the embedding matrix to obtain a “concept token” that becomes the next input. Setting temperature to 0 degenerates to standard CoT, so it can be implemented as a drop-in extension to existing models.
The shared design principle is “keep the language ability of the LLM, but remove the discretization bottleneck from its input-output path.” Outputs remain decodable into natural language, so downstream tooling such as verifiers and RLHF can be reused.
Group C: Implicit CoT Distillation
Group C is a distillation framework that internalizes the teacher’s explicit CoT into the student model’s hidden layers.
Implicit CoT via Knowledge Distillation (Deng et al. 2023) flies the banner “reasoning happens vertically inside hidden states” and distills the teacher’s CoT intermediate states into the student’s intermediate layers. Stepwise Internalization (Deng et al. 2024) is the successor and uses a curriculum that gradually removes CoT tokens during fine-tuning, eventually reducing them to zero. The finished student emits no CoT at all (a pure direct prediction even at test time), but reasoning steps are folded into its internal representations.
Group C differs from the others in that it offers no test-time scaling. The student aims to reach the answer in a single ordinary forward pass. While groups A and B explore “the path of investing extra computation at test time,” group C explores “the path of packing reasoning into train time.” The direction is opposite to the recursive reasoning that is the main theme of this book, but it is an adjacent area that shares the premise that “reasoning does not necessarily require a natural-language trace.”
Group D: Self-Generated Rationale
Quiet-STaR (Zelikman et al. 2024) generates an internal rationale at each token position and trains, in a REINFORCE-like manner, to reduce the loss of predicting the next token conditioned on that rationale. Whereas groups A through C presuppose a “teacher CoT” or a “placeholder,” Quiet-STaR has the model itself discover what it should think about. The generated rationales are sampled multiple times at test time and aggregated.
The improvements from 5.9 % to 10.9 % zero-shot on GSM8k and from 36.3 % to 47.2 % on CommonsenseQA were obtained with a setting that generates 8 rationales and takes a weighted sum through a mixing head. Group D stands on the border between natural-language traces and “latent” methods: the generated rationales are human-readable, yet they are treated functionally as a test-time computation source, which overlaps with the placeholders of group A.
Group E: Recurrent Depth, Home of HRM/TRM/GRAM
Group E is the lineage that recurrently unrolls the same layer parameters in the depth direction at test time, and the main models of this book, HRM, TRM, PTRM, GRAM, and LDT, all belong here. In addition, Geiping recurrent depth (Geiping et al. 2025) applies the same idea to a 3.5B-parameter LLM, looping r recurrent blocks an arbitrary number of times at test time. The lineage, as detailed in Depth Recurrence Lineage, runs from Adaptive Computation Time (ACT, 2016) through Deep Equilibrium Models (DEQ, 2019), Universal Transformer, PonderNet, and Looped Transformers.
As the most recent subdivision within group E, the lineage branches into three families by how stochasticity is introduced. Deterministic HRM/TRM return a single trajectory. Test-time stochastic PTRM injects Gaussian noise only at inference into a trained TRM checkpoint. Train-time stochastic GRAM variationally learns probabilistic latent transitions and handles parallel trajectories. Independent of these, LDT opens a different axis that adds not stochasticity but the lattice projection of abstract interpretation to obtain sound deduction. The details are covered in each chapter.
Group E has 4 attributes that decisively distinguish it from the other groups. This is the central observation of this book.
Four Attributes That Decisively Separate HRM/TRM/GRAM from Group B
Looking only at the vertical / horizontal split of LRS (Zhu et al. 2025), HRM/TRM/GRAM appear to differ from the Coconut family merely by belonging to group E rather than group B. But placing the two side by side reveals a deeper gap in design philosophy (Table 2).
| Attribute | Group B (Coconut family) | Group E (HRM/TRM/GRAM) |
|---|---|---|
| Base model | Layered on top of a large LLM (reusing hidden state) | Self-contained tiny network (no LLM) |
| Language bottleneck | No token in between at each step, but outputs are natural language | Maps from latent state directly to grid / structured output |
| Training data | Pre-training on hundreds of B tokens + tens of thousands of CoT fine-tuning examples | Thousands to tens of thousands of samples per task, from scratch |
| Test-time scaling | Number of continuous thoughts (width) | Recursion depth only; GRAM also has parallel trajectory width |
First, a self-contained tiny network, not layered on top of an LLM. Coconut and Geiping reuse an LLM’s hidden state, and as a result retain natural-language generation. HRM (27M), TRM (7M), and GRAM (10M) are task-specific small neural networks that completely give up language generation. The label “latent” is the same, but group B is the form obtained by stripping the final linear projection from an LLM, while group E is the form that never had a linear projection to begin with.
Second, the language bottleneck itself is removed. Group B also avoids discretization, but its outputs are still natural-language token sequences. Group E maps latent state directly to structured outputs such as ARC-AGI grids or Sudoku number boards. Precisely because the language layer is bypassed, there is room for small models to win on grid-shaped tasks where frontier LLMs struggle.
Third, the training data is smaller by orders of magnitude. The LLM family presupposes pre-training on hundreds of B tokens, but HRM and TRM can start training from 1,000 samples per task. This inverts the premise of group B: Coconut can only ride on the linguistic world knowledge held by an LLM, while group E discards world knowledge and acquires only structural computational capacity.
Fourth, test-time scaling is depth only (with GRAM also offering parallel trajectory width \(N\)). Coconut’s “superposing multiple paths in one vector” and GRAM’s “sampling \(N\) trajectories” overlap functionally, but while group B buys width through the number of continuous thoughts, the center of group E is the recursion count \(K\). Geiping’s recurrent depth shows that a 3.5B model can be extended from r=4 to r=32 at test time, and stands as a bridge between group E and group B.
The Coconut family starts from an efficiency motivation: “we want to speed up reasoning by bypassing the language layer of an LLM.” The LLM is given, and the goal is to trim the redundancy of its inference path.
HRM/TRM/GRAM start from an architecture-first motivation: “reasoning is from the start a computation unrelated to discrete language, and large LMs are not needed.” They question the LLM itself and claim there should be a different architecture for structured reasoning.
Even under the same “latent reasoning” umbrella, every design decision changes depending on whether the starting point is efficiency or architecture. When skimming the classification axes of surveys, take care not to miss this difference in the layer of problem framing.
Group F: Diffusion-Based Reasoning
Diffusion-of-Thoughts (Ye et al. 2024) piggybacks reasoning on the denoising steps of a diffusion LM. As shown in Figure 3, instead of autoregressively generating tokens from left to right, it polishes the entire reasoning chain in parallel as a denoising process from time \(t = T\) to \(t = 0\). It surpasses a base AR LM on GSM8k’s 4-digit multiplication, while exposing an accuracy / latency tradeoff through two sampling modes, Single-Pass and Multi-Pass.
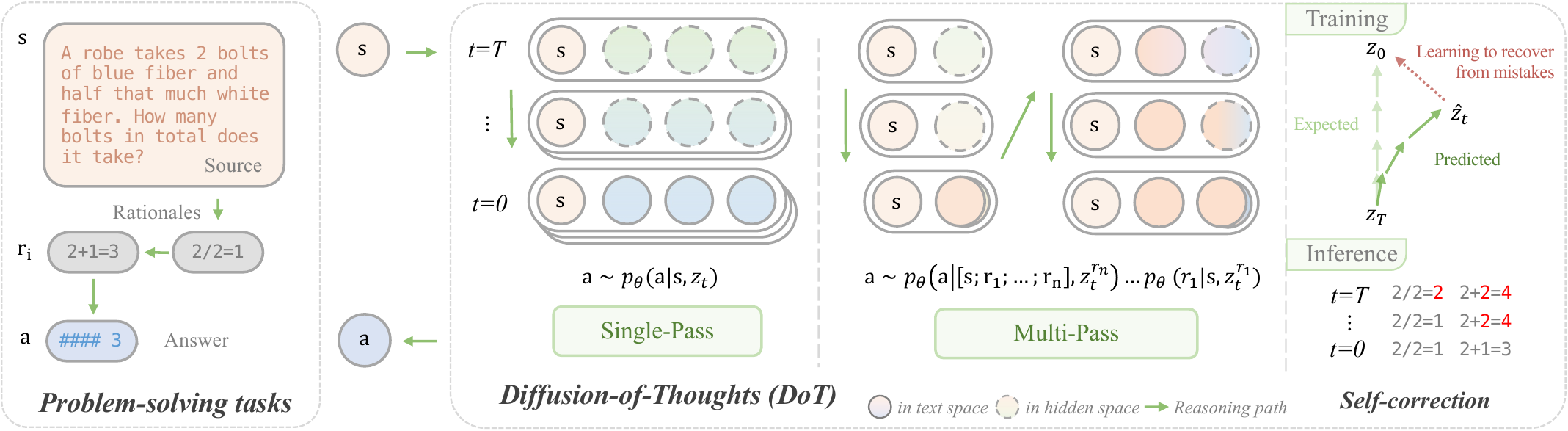
In the LRS (Zhu et al. 2025) taxonomy, diffusion is the third axis as a “continuous-time limit of infinite depth” that does not lie on the vertical / horizontal axes. Diffusion can be read as the limit of HRM/TRM/GRAM’s discrete depth \(K\) as \(K \to \infty\) with Gaussian noise injection added. Indeed, GRAM’s variational latent transition is mathematically akin to the forward process of diffusion.
LaDiR (Kang et al. 2025) from 2025 brings this diffusion line closer to the reasoning context. It encodes reasoning steps with a Variational Autoencoder (VAE), and a latent diffusion model refines them with blockwise bidirectional attention. The design, which generates diverse reasoning trajectories on math, code, and puzzles, sits in between the group-E-leaning GRAM (variational latent transition) and the group-F-leaning diffusion-of-thoughts. Read alongside this book’s GRAM variational design, it shows that the idea of “treating reasoning trajectories as a probability distribution” is being reached independently from different schools.
Group G: Concept-Level
Large Concept Model (LCM) (LCM team et al. 2024), announced by Meta in December 2024, is the lineage that performs autoregressive prediction on sentence embeddings rather than tokens. A fixed encoder called SONAR projects sentences into 1024-dimensional vectors, and a Transformer is trained to predict the next embedding from a sequence of sentence embeddings. Three loss types are tried, Mean Squared Error (MSE), diffusion, and quantized cross-entropy, all of which reason at a granularity different from token-level LLMs.
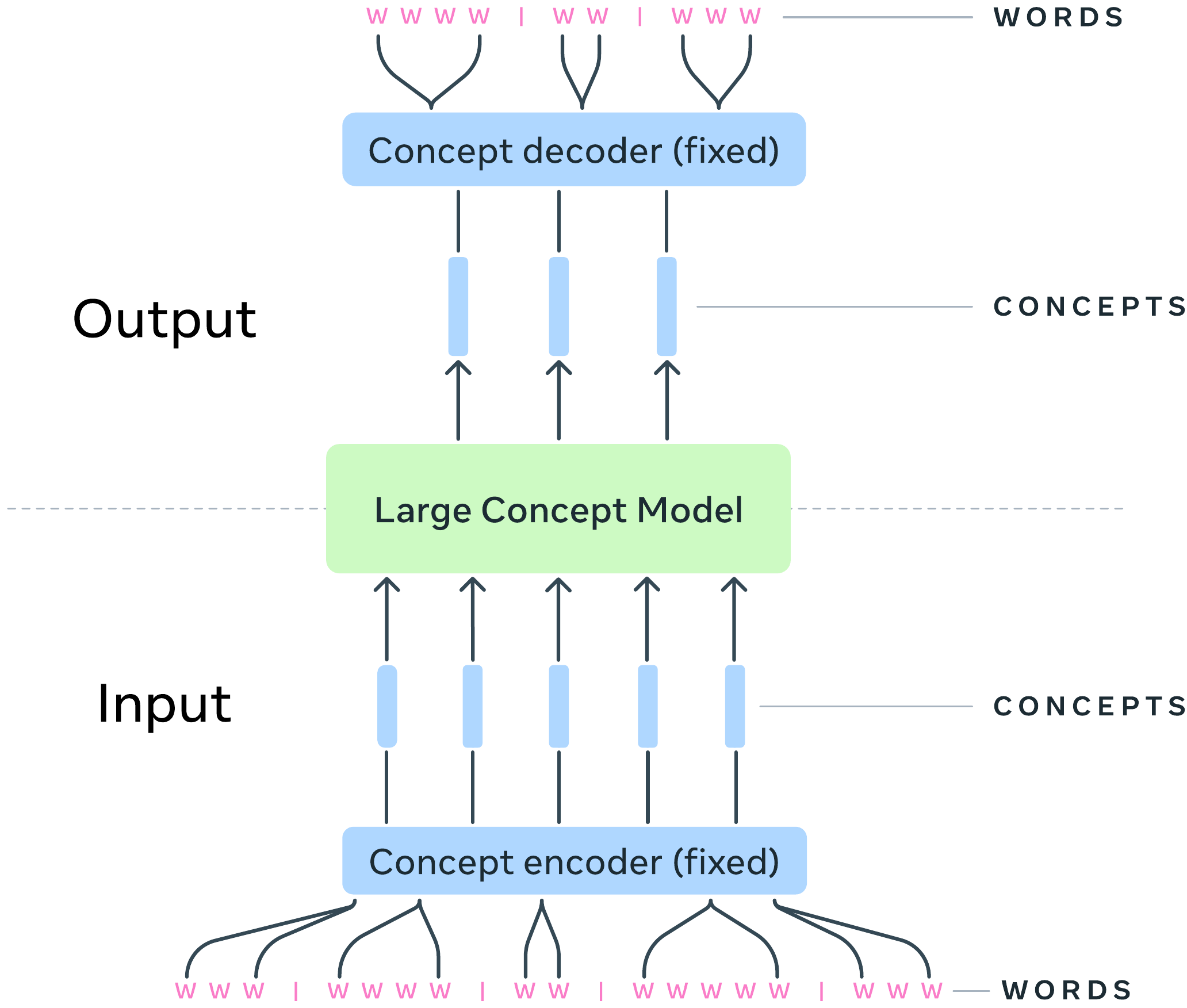
LCM is the most extreme implementation of the hypothesis that “the unit of reasoning should be at an abstraction layer above tokens.” Whereas groups B through E advance latent reasoning at the hidden-state level, LCM explicitly passes through a sentence-level semantic representation. Test-time scaling is measured by the number of concepts generated, and because each concept expands into multiple words, the token efficiency is high.
The Whole Picture of Latent Reasoning on Three Axes
Reorganizing the 7 groups of Table 1 along three orthogonal axes clarifies the position of HRM/TRM/GRAM even further.
- Language-channel axis: natural-language output (B, C, D, F, G) / structured output (E only; group A is dependent)
- Base-model axis: large LLM required (B, C, D, G) / partial LLM dependence (F, A) / no LLM needed (E)
- Test-time scaling axis: buy width (B, D) / buy depth (E) / infinite depth (F) / not provided (C)
HRM/TRM/GRAM sit at the “leftmost end” on all three axes (structured output / no LLM / depth). This is the most extreme contrast point when compared directly to Snell et al.’s (Snell et al. 2024) compute-optimal scaling and Brown et al.’s (Brown et al. 2024) log-linear coverage, treated in Depth vs Token Scaling.
Chapter Summary
Latent reasoning is not a single method but splits into 7 groups: placeholder (A), horizontal continuous CoT (B), distillation (C), self-generated rationale (D), vertical recurrent depth (E), diffusion (F), and concept-level (G). The vertical / horizontal split of LRS (Zhu et al. 2025) forms the skeleton of this classification, and this chapter has added 4 groups on top to capture the whole picture.
The main characters of this book, HRM/TRM/GRAM, sit in group E (recurrent depth), but they differ decisively from group B (the Coconut family) under the same latent reasoning umbrella on all 4 attributes (base model, language bottleneck, training data scale, test-time scaling axis). The motivation of the Coconut family is efficiency (speeding up an LLM), while the motivation of HRM/TRM/GRAM is architecture-first (no LLM needed), and the layer of problem framing differs by one step. With this contrast in mind, reading HRM/TRM/GRAM as “a development of Coconut” is a misreading, and they need to be evaluated independently as a separate research program.