flowchart LR
A1["<b>HRM claim 1</b><br/>1-step gradient via<br/>fixed-point approximation"] --> B1["TRM: replace with full BPTT<br/>+30.9 pp"]
A2["<b>HRM claim 2</b><br/>ACT / Q-head<br/>(2 forward passes)"] --> B2["TRM: drop continue loss<br/>1 forward, roughly equal"]
A3["<b>HRM claim 3</b><br/>Hierarchy (f_L / f_H split)<br/>+ brain correspondence"] --> B3["TRM: merge into a single net<br/>+5.0 pp"]
B1 --> C["<b>Conclusion</b><br/>The core of the HRM story<br/>does not explain the performance"]
B2 --> C
B3 --> C
TRM
Tiny Recursive Model (TRM) is a recursive reasoning model released in October 2025 as a sole-author paper by Alexia Jolicoeur-Martineau at Samsung SAIL Montréal (Jolicoeur-Martineau 2025). Among the three generations covered in this book, it is the sharpest piece of “subtractive research”: it takes the three-pillar story behind Hierarchical Reasoning Model (HRM) from June 2025, namely “brain-inspired hierarchy + 1-step gradient from Deep Equilibrium Models (DEQ) + Adaptive Computation Time (ACT)”, and dismantles each pillar through ablations while still outperforming HRM. With a single 2-layer neural network of roughly 7M parameters, it reaches 87.4 % on Sudoku-Extreme, 44.6 % on the ARC-AGI-1 public evaluation, and 7.8 % on the ARC-AGI-2 public evaluation, and won 1st place in the ARC Prize 2025 Paper Award. An official implementation is available on GitHub.
This chapter organizes the implications of the paper’s “Less is more” message in the following order: (1) critique of the HRM story, (2) the TRM construction, (3) main results, (4) ablations, and (5) community reproductions and criticisms. Claims and numbers from the HRM side are covered in detail in the HRM chapter of this book, and readers who want to compare directly may want to read both.
Three Critiques of the HRM Story
The paper takes issue with three core components of HRM. These directly motivate TRM’s architectural decisions and are later validated empirically in the ablations.
The Fixed-Point Theorem Does Not Apply
HRM lets gradients flow only through the last 2 of 6 function evaluations. The justification is the Implicit Function Theorem (IFT) and the 1-step gradient approximation (Bai et al. 2019), following the DEQ argument that “if the recursion has converged to a fixed point \(z^* = f(z^*)\), then a single back-propagation step at the equilibrium suffices.”
The TRM paper points out that this premise does not hold in HRM’s actual setup.
- All HRM experiments use \(n=2, T=2\), so the inner loop evaluates \(f_L\) only 4 times in total and \(f_H\) only once
- HRM Figure 3 shows that, in a \(n=7, T=7\) configuration, the forward residual decays over time, but the \(z_H\) residual still stays clearly away from 0
- In the actual \(n=2, T=2\) setting, the 1-step gradient is applied under the assumption that \(z_L\) “reached a fixed point in one \(f_L\) evaluation”, but convergence is nowhere near
From these observations, the paper concludes that “there is a motivation for invoking IFT, but the conditions the theorem requires are not actually met”. As discussed below, simply discarding this theoretical core yields a +30.9 pp improvement on Sudoku-Extreme, which is TRM’s biggest finding.
Inefficiency of ACT and the Q-Head
HRM learns the halt/continue decision via Q-learning and calls it ACT (Graves 2016; Banino et al. 2021). It consists of a halting loss and a continue loss, and although the paper itself does not mention it, the official implementation requires an additional forward pass for the continue loss. In other words, each optimization step runs the HRM-style forward pass twice, so even if sample efficiency looks good, the compute cost is effectively doubled.
TRM throws the continue loss away and simplifies the design to a halting head trained with Binary Cross Entropy on a single signal: “does the current prediction match the ground truth?” This brings the number of forward passes back to one and even slightly improves Sudoku-Extreme from 86.1 to 87.4 %.
Overclaim of Biological Interpretation
HRM’s interpretation of the slow \(f_H\) / fast \(f_L\) dual recursion is by analogy to different temporal-frequency hierarchies in the brain. Section 4 of the paper even brings in a Participation Ratio comparison with mouse cortex. The TRM paper criticizes this as “an explanation far removed from artificial neural networks that, if anything, obscures what is actually doing the work”. Combined with the absence of a systematic ablation table in the HRM paper, TRM’s stance is that the work needs to separate which components of the HRM construction are load-bearing and which are decoration.
TRM Architecture
The paper summarizes the entire implementation in Algorithm 2 (reproduced in the callout at the end of this section). Compared with HRM, the essential changes are: (i) consolidating the 4 modules \(\{f_I, f_L, f_H, f_O\}\) into a single 2-layer Transformer, (ii) reinterpreting the hierarchical pair \(z_L, z_H\) as a semantic pair “current solution \(y\)” and “latent reasoning feature \(z\)”, and (iii) running full Backpropagation Through Time (BPTT) over the entire inner recursion instead of a 1-step gradient.
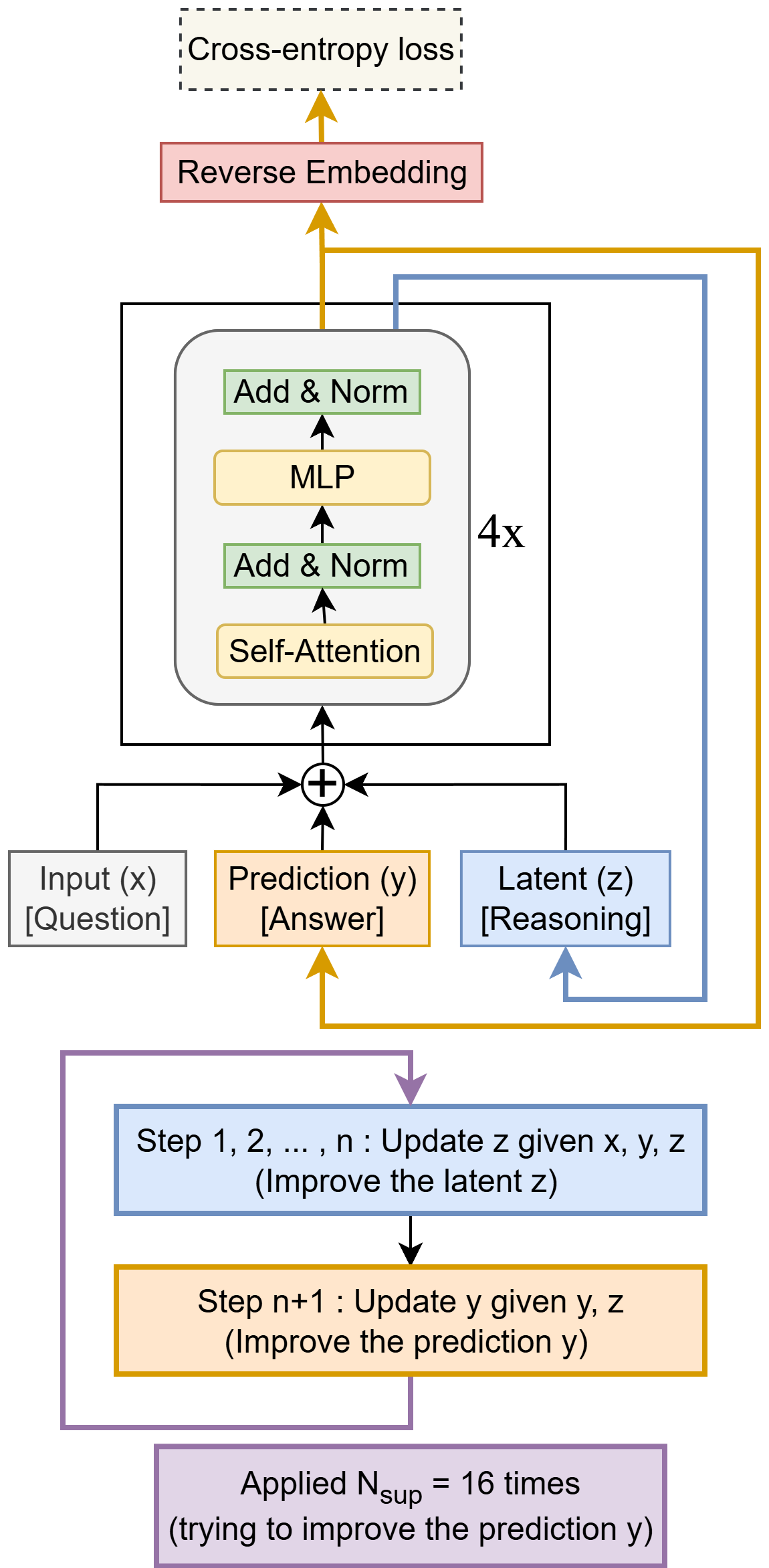
State and Recursion
TRM keeps three variables.
- \(x\): the embedded input problem (a 9x9 grid for Sudoku, up to 30x30 for ARC)
- \(y\): the current predicted solution, decoded into discrete tokens via the output head and argmax
- \(z\): a latent reasoning feature, an intermediate representation that does not directly correspond to \(y\) but is reflected in \(y\) through \(f_H\)
The inner loop consists of \(n\) rounds of latent reasoning and a single answer refinement:
\[ \begin{aligned} z &\leftarrow \text{net}(x, y, z) \quad (\text{repeated } n \text{ times}) \\ y &\leftarrow \text{net}(y, z) \end{aligned} \]
These \(n+1\) evaluations form one “full recursion process”. Outside, deep supervision runs the recursion no-grad for \(T-1\) rounds to improve \((y, z)\), and gradients flow only through the last round:
def deep_recursion(x, y, z, n=6, T=3):
with torch.no_grad():
for j in range(T - 1):
y, z = latent_recursion(x, y, z, n)
y, z = latent_recursion(x, y, z, n) # gradients on full recursion
return (y.detach(), z.detach()), output_head(y), Q_head(y)This outer update is stacked up to N_supervision times, with \((y, z)\) detached at every step. The standard setup is \(n=6, T=3\) and maximum \(N_\text{sup} = 16\).
Computing the Effective Depth
The effective depth per supervision step is measured as \(n_\text{layers} \times (n+1) \times T\). For HRM (\(n_\text{layers}=4, n=2, T=2\)) this is \(4 \times 3 \times 2 = 24\), and for TRM (\(n_\text{layers}=2, n=6, T=3\)) it is \(2 \times 7 \times 3 = 42\), so TRM halves the parameter count while increasing the effective depth. Paper Table 4 lines up this depth axis and reports that, at the same depth, TRM consistently beats HRM.
A New Interpretation of “Why Two Variables”
HRM used the two variables \(z_L, z_H\) in the name of “hierarchy”, but TRM offers a more straightforward explanation.
- \(z_H\) (= TRM’s \(y\)) is in fact the “current solution” itself and can be decoded with the output head and argmax
- \(z_L\) (= TRM’s \(z\)) is a latent feature that has no meaning when decoded, and is reflected into the solution only through \(f_H\)
Paper Figure 5 shows examples in which a trained HRM’s \(z_L\) and \(z_H\) are each argmax-decoded on Sudoku: \(z_H\) matches the correct grid, while \(z_L\) is just a meaningless string of digits. This visually backs up the claim. Under this view, the “one \(y\) and one \(z\)” construction is not about hierarchy but a simple division of labor in which the current answer and the workspace used to reach it are kept separately.
The paper further runs ablations that split \(z\) into \(n+1\) multi-scale pieces (77.6 %) and that drop \(z\) to a single feature (71.9 %), and confirms that both fall short of the two-variable construction (87.4 %).
flowchart TB
subgraph HRM["<b>HRM</b> (27M params, depth/sup=24)"]
direction LR
H1["f_I<br/>(input enc)"] --> H2["f_L<br/>4-layer TF<br/>(low-level)"]
H2 -.->|n times no-grad| H2
H2 --> H3["f_H<br/>4-layer TF<br/>(high-level)"]
H3 --> H4["f_O<br/>(output head)"]
H5["1-step gradient<br/>(only last f_L, f_H)"]
end
subgraph TRM["<b>TRM</b> (7M params, depth/sup=42)"]
direction LR
T1["embed(x)"] --> T2["net<br/>2-layer TF<br/>(shared)"]
T2 -->|update z<br/>n times| T2
T2 --> T3["net<br/>refine y"]
T3 --> T4["output head"]
T5["full BPTT<br/>(entire n+1 recursions)"]
end
NoteComparing the Pseudocode
The TRM pseudocode is as follows. Compared with the HRM pseudocode, three things stand out: (i) \(f_L\) and \(f_H\) are unified into a single net, (ii) the full recursion runs outside the with torch.no_grad() block and the 1-step gradient is gone, and (iii) the ACT continue loss is gone and the halting head is simplified to a single BCE.
def latent_recursion(x, y, z, n=6):
for i in range(n):
z = net(x, y, z) # latent reasoning update
y = net(y, z) # refine output answer
return y, z
def deep_recursion(x, y, z, n=6, T=3):
with torch.no_grad():
for j in range(T - 1):
y, z = latent_recursion(x, y, z, n)
y, z = latent_recursion(x, y, z, n)
return (y.detach(), z.detach()), output_head(y), Q_head(y)
for x_input, y_true in train_dataloader:
y, z = y_init, z_init
for step in range(N_supervision):
x = input_embedding(x_input)
(y, z), y_hat, q_hat = deep_recursion(x, y, z)
loss = softmax_cross_entropy(y_hat, y_true)
loss += binary_cross_entropy(q_hat, (y_hat == y_true))
loss.backward(); opt.step(); opt.zero_grad()
if q_hat > 0:
breakTraining Details
Training uses AdamW (\(\beta_1=0.9, \beta_2=0.95\)) with batch size 768, hidden size 512, and \(N_\text{sup}=16\). EMA is set to 0.999, and as the ablation in the paper shows, performance drops to 79.9 % without EMA (discussed later). Sudoku-Extreme and Maze-Hard are trained for 60K epochs and ARC-AGI for 100K epochs. Data augmentation follows the HRM setup: 1000 shufflings for Sudoku, and 1000 combinations of color permutation, dihedral, and translation for ARC. On ARC, each input puzzle has its own dedicated embedding, and at test time the most frequent prediction across 1000 augmentations is taken, which is a transductive setup inherited from HRM.
In terms of hardware, Sudoku-Extreme finishes in under 36 hours on a single L40S, and ARC-AGI takes about 3 days on 4 H100s, which is orders of magnitude cheaper than training a frontier LLM.
Main Results
The paper’s two main tables are reproduced here. Table 1 covers grid-structured puzzles, and Table 2 covers the ARC-AGI public evaluation sets (2 attempts). HRM numbers are quoted from the HRM paper, and LLM numbers come from the same source.
| Method | Parameters | Sudoku-Extreme | Maze-Hard |
|---|---|---|---|
| DeepSeek R1 (CoT) | 671B | 0.0 % | 0.0 % |
| Claude 3.7 8K (CoT) | ? | 0.0 % | 0.0 % |
| o3-mini-high (CoT) | ? | 0.0 % | 0.0 % |
| Direct prediction | 27M | 0.0 % | 0.0 % |
| HRM | 27M | 55.0 % | 74.5 % |
| TRM-Att | 7M | 74.7 % | 85.3 % |
| TRM-MLP | 5M / 19M | 87.4 % | 0.0 % |
| Method | Parameters | ARC-AGI-1 | ARC-AGI-2 |
|---|---|---|---|
| DeepSeek R1 (DeepSeek-AI et al. 2025) | 671B | 15.8 % | 1.3 % |
| Claude 3.7 16K | ? | 28.6 % | 0.7 % |
| o3-mini-high | ? | 34.5 % | 3.0 % |
| Gemini 2.5 Pro 32K | ? | 37.0 % | 4.9 % |
| Grok-4-thinking | 1.7T | 66.7 % | 16.0 % |
| Bespoke (Grok-4) | 1.7T | 79.6 % | 29.4 % |
| Direct prediction | 27M | 21.0 % | 0.0 % |
| HRM | 27M | 40.3 % | 5.0 % |
| TRM-Att | 7M | 44.6 % | 7.8 % |
| TRM-MLP | 19M | 29.6 % | 2.4 % |
What stands out is that on Sudoku-Extreme and Maze-Hard, every CoT-style frontier LLM (DeepSeek R1, Claude 3.7, o3-mini-high) scores 0 %. This is not a statement that frontier LLM reasoning is weak. It is a direct illustration of how test-time compute is allocated: the set of problems that a 7M neural net trained on 1000 examples can solve does not always overlap with the set of problems that a 671B model trained on trillions of tokens plus RL can solve. At the same time, on ARC-AGI, TRM does not reach Grok-4-thinking’s 66.7 % / 16.0 %, which confirms that “scale plus RL post-training works along a different axis”.
Implications of the Ablations
The systematic ablation on Sudoku-Extreme in paper Table 1 is directly relevant to this book’s broader argument (showing empirically where the HRM story falls apart), so it is reproduced in Table 3. The baseline is TRM (\(T=3, n=6\), 2 layers, EMA 0.999, MLP-Mixer) at 87.4 %.
| Setting | Accuracy (%) | Δ (pp) | Parameters | NFP |
|---|---|---|---|---|
| TRM (\(T=3, n=6\), MLP, baseline) | 87.4 | - | 5M | 1 |
| w/ ACT (continue loss restored) | 86.1 | \(-1.3\) | 5M | 2 |
| w/ separate \(f_H, f_L\) (HRM-style) | 82.4 | \(-5.0\) | 10M | 1 |
| no EMA | 79.9 | \(-7.5\) | 5M | 1 |
| w/ 4 layers, \(n=3\) | 79.5 | \(-7.9\) | 10M | 1 |
| w/ self-attention (MLP→Attn) | 74.7 | \(-12.7\) | 7M | 1 |
| w/ \(T=2, n=2\) (HRM-equivalent) | 73.7 | \(-13.7\) | 5M | 1 |
| w/ 1-step gradient (HRM-style) | 56.5 | \(-30.9\) | 5M | 1 |
| HRM (reference) | 55.0 | - | 27M | 2 |
The most important fact this table shows is that simply dropping the 1-step gradient approximation in favor of full BPTT gives a +30.9 pp improvement. The theoretical core of HRM does not function as an explanation of the performance, as also suggested by the fact that HRM’s own baseline (55.0 %) is roughly on par with the TRM variant that keeps the 1-step gradient (56.5 %). In the “Ideas that failed” appendix, the paper also reports that a version that actually runs fixed-point iteration via TorchDEQ (Bai et al. 2019) only slowed training and hurt generalization, reinforcing that “reaching the fixed point” is not the essential ingredient.
The other rows are also informative when read against the HRM story. Hierarchical separation (separate \(f_H, f_L\)) costs -5.0 pp and is indeed unnecessary. Reverting to \(T=2, n=2\) costs -13.7 pp, showing that HRM’s hyperparameter choice was simply too shallow. The self-attention → MLP-Mixer gap (-12.7 pp) suggests that “in short, fixed contexts like 9x9, the inductive bias of attention is actually a liability”, which questions HRM’s exclusive commitment to Transformers.
The -7.5 pp drop without EMA indicates that TRM operates right at the edge of overfitting. The paper imports EMA, which has become standard in GANs and diffusion (a context independent of (Bai et al. 2019)), and combines it with weight decay 1.0 to keep the model from collapsing.
Warning“Deeper Is Better” Does Not Hold
As an important empirical rule for TRM, paper Table 4 shows that performance drops if depth is increased too much. Before reaching \(k=T=n=6\) (effective depth 156, near the OOM limit), \(k=T=n=4\) already drops to 84.2 %, \(k=3, T=6\) gives 85.8 %, and \(k=6, T=3\) is OOM and cannot be measured. The “Less is more” message is not “abandon scale”, but the more limited claim that in a 1000-example supervised regime, depth becomes a source of overfitting cost. The paper’s Conclusion also leaves the question open, saying “we suspect why the recursion is so effective is related to overfitting, but we have no theory”.
Community Reproductions and Criticism
Right after the arXiv release, unofficial implementations such as lucidrains/tiny-recursive-model appeared, and TRM was also independently scored in the ARC Prize 2025 official evaluation.
Independent Verification by the ARC Prize Foundation
On the ARC Prize 2025 leaderboard, TRM’s semi-private evaluation is reported at roughly 40 % ($1.76/task) on ARC-AGI-1 and roughly 6.2 % ($2.10/task) on ARC-AGI-2. These are slightly below the paper numbers (44.6 %, 7.8 %), but compared with HRM, whose numbers dropped substantially under the ARC Prize independent ablation (see the HRM chapter), TRM is broadly within the range of reproducibility. The Paper Award 1st place, on the standalone paper, recognizes the methodological contribution of carefully dismantling the HRM story through ablations.
In the main ARC Prize 2025 competition, NVARC (NVIDIA KGMoN team, Sorokin & Puget) reached 24 % ($0.20/task) on ARC-AGI-2 using TRM-based components, setting an efficiency SOTA separate from the Paper track (Chollet et al. 2026). As of mid-2026, the trajectory is that TRM’s architecture is moving into practical use less as “a standalone reasoner” and more as “a piece to be combined with synthetic data generation and test-time training”.
TRM Direct Follow-Up Research
Within seven months of the paper’s release, follow-up research building on TRM has branched into several directions. In addition to the two papers this book treats as standalone chapters (PTRM and Lattice Deduction Transformers), progress is also visible along three axes: (i) training efficiency, (ii) implementation tricks for ARC Prize 2025, and (iii) operator design within the architecture.
- Training efficiency: Hakimi’s Recursive Stem Model (Hakimi 2026) combines detached hidden-state history during training, a loss applied only at the terminal step, and stochastic depth along the outer recursion to speed up TRM training by 20x or more, reaching 97.5 % on Sudoku-Extreme and around 80 % on Maze-Hard. While PTRM improves “test-time exploration”, RSM reads as an orthogonal axis improving “training efficiency”.
- ARC Prize 2025 implementation: McGovern’s Test-Time Adaptation of Tiny Recursive Models (McGovern 2025) is an independent reproduction that trains a 7M-parameter TRM on 1,280 public tasks for 48 hours and then applies 12,500 steps of test-time fine-tuning under the competition budget, reporting roughly 10 % on public eval and 6.67 % on semi-private. Whereas NVARC (covered in the ARC-AGI and Small Models chapter) integrates TRM components into a larger ensemble, this serves as a reference point for the “ceiling of plain TRM”.
- Operator replacement: Wang & Reid (Wang and Reid 2026) propose Tiny Recursive Reasoning with a Mamba-2 Hybrid, replacing Transformer blocks inside the recursive operator with Mamba-2 SSMs. The top-1 on ARC-AGI-1 is comparable, but pass@100 improves by +4.75 pp, suggesting that “TRM is not just a small Transformer, and the design space of the operator influences trajectory diversity”.
- Branching toward the sound deduction lineage: Cheng Lou’s Sotaku (Lou 2026) independently achieves 98.9 % on Sudoku-Extreme with 1/10 the size of TRM (800K parameters), and Lattice Deduction Transformers (Davis et al. 2026) (covered in this book’s LDT chapter) inherit Sotaku’s architecture while adding lattice projection from abstract interpretation to obtain empirical soundness. The HRM → TRM → Sotaku → LDT line runs alongside this book’s main models as a more “symbolic-deduction-leaning” lineage that is independent of them.
The paper’s own Conclusion notes that “TRM is only a supervised learner that returns a single deterministic solution, and cannot be used in settings where multiple solutions are allowed. Extending TRM into a generative model is left as future work”, and this is taken up directly by both PTRM (Sghaier et al. 2026) (this book’s PTRM chapter) and GRAM (Baek et al. 2026) (this book’s GRAM chapter) in May 2026. The former leaves the trained TRM checkpoint intact and adds stochasticity at test time through noise injection, while the latter stochasticizes the latent during training and requires retraining, forming complementary attacks that break TRM’s deterministic limit from the test-time and training-time sides respectively.
NoteAuthor’s retrospective in interview
In the ARC Prize 2025 official YouTube interview (ARC Prize 2025), Jolicoeur-Martineau discusses implementation realities and future directions not covered in the paper. The following summarizes statements that this book’s authors verified directly against the auto-generated English transcript; these are spoken remarks rather than paper claims.
- Ablations constrained by compute: “I was very limited in compute. So it was one run and it was this run, right? I didn’t [do] ablation.” This corroborates that each row of paper Table 1 is the result of a single run. The author also states that depth ablations on harder examples (such as ARC) were not feasible “because of course I didn’t have the computer”.
- Independent replication reaching 15 % on ARC-AGI-2 with longer training: The author mentions that a replication team retrained TRM for roughly twice as long and reached 15 % on ARC-AGI-2 public (versus the paper’s 7.8 %). Direct circumstantial evidence that the paper number is not a ceiling but is constrained by compute.
- Wanting to drop puzzle_id embedding in the future: “right now it’s a bit weird with the one embedding per per data point, like maybe you’d want some kind of in context learning so that you don’t need to retrain”. The puzzle_id dependence criticized in this book’s HRM chapter and Open Problems chapter is explicitly recognized by the author as a target for improvement.
- The ARC-AGI-2 bottleneck is context length: “RKGI 2 has this multiple example that can cause some issue. It makes the context length very big and you need some strategy.” The author identifies per-task example count blowing up context length as a structural reason TRM does not extend well on ARC-AGI-2.
Positioning
In the context of this book as a whole, TRM’s role is to serve as the clearest first-hand source for the “falling apart of the story” in the HRM lineage.
- Technically, it shows in a single ablation table that the three decorations of HRM (fixed point, ACT with 2 forward passes, hierarchy) can each be removed without losing performance, and that removing the biggest pillar (the 1-step gradient) actually improves performance by +30.9 pp
- In terms of awards, implementations, and community reproductions, it lands cleanly without the story collapsing the way HRM’s did (reproducible numbers, public code, the Paper Award)
- On the other hand, the narrative that “a small 7M model beats frontier LLMs” only holds in the closed setting of Sudoku/Maze, and on ARC-AGI it does not reach the Grok-4 family. The paper itself is explicit that it is a puzzle-specialized solver, not a substitute for an open-domain LLM
Which addition is grafted onto TRM’s deterministic minimal core has split the research program into multiple directions. PTRM leaves the trained TRM checkpoint untouched and adds a stochastic term at test time so that trajectories escape bad basins, the smallest possible intervention. GRAM adds a Gaussian stochastic term during training and obtains unconditional generation and multi-hypothesis reasoning as a larger architectural change. LDT branches off from the TRM lineage (HRM → TRM → Sotaku → LDT) and adds, instead of stochasticity, the lattice projection of abstract interpretation to obtain empirical soundness. After the HRM-to-TRM subtraction, this book covers these three branches alongside HRM and TRM as a total of five main models in five chapters.
References
ARC Prize. 2025. Interview with Alexia Jolicoeur-Martineau: ARC Prize 2025 Paper Award Winner. YouTube video interview. https://www.youtube.com/watch?v=P9zzUM0PrBM.
Baek, Junyeob, Mingyu Jo, Minsu Kim, Mengye Ren, Yoshua Bengio, and Sungjin Ahn. 2026. “Generative Recursive Reasoning.” arXiv Preprint arXiv:2605.19376. https://arxiv.org/abs/2605.19376.
Bai, Shaojie, J. Zico Kolter, and Vladlen Koltun. 2019. “Deep Equilibrium Models.” Advances in Neural Information Processing Systems. https://arxiv.org/abs/1909.01377.
Banino, Andrea, Jan Balaguer, and Charles Blundell. 2021. “PonderNet: Learning to Ponder.” arXiv Preprint arXiv:2107.05407. https://arxiv.org/abs/2107.05407.
Chollet, François, Mike Knoop, Gregory Kamradt, and Bryan Landers. 2026. “ARC Prize 2025: Technical Report.” arXiv Preprint arXiv:2601.10904. https://arxiv.org/abs/2601.10904.
Davis, Liam, Leopold Haller, Alberto Alfarano, and Mark Santolucito. 2026. “Lattice Deduction Transformers.” arXiv Preprint arXiv:2605.08605. https://arxiv.org/abs/2605.08605.
DeepSeek-AI, Daya Guo, Dejian Yang, et al. 2025. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” Nature 645: 633–38. https://arxiv.org/abs/2501.12948.
Efstathiou, Andreas, and Aishwarya Balwani. 2026. “Recursive Reasoning as Attractor Landscape Search: Mechanistic Dynamics of the Tiny Recursive Model.” Workshop on Latent and Implicit Thinking – Going Beyond CoT Reasoning, ICLR 2026. https://openreview.net/forum?id=kKps9W1K7n.
Ge, Renee, Qianli Liao, and Tomaso Poggio. 2025. “Hierarchical Reasoning Models: Perspectives and Misconceptions.” arXiv Preprint arXiv:2510.00355. https://arxiv.org/abs/2510.00355.
Graves, Alex. 2016. “Adaptive Computation Time for Recurrent Neural Networks.” arXiv Preprint arXiv:1603.08983. https://arxiv.org/abs/1603.08983.
Hakimi, Navid. 2026. “Form Follows Function: Recursive Stem Model.” arXiv Preprint arXiv:2603.15641. https://arxiv.org/abs/2603.15641.
Jolicoeur-Martineau, Alexia. 2025. “Less Is More: Recursive Reasoning with Tiny Networks.” arXiv Preprint arXiv:2510.04871. https://arxiv.org/abs/2510.04871.
Lou, Cheng. 2026. Sotaku: From-Scratch Experiments on Iterative Neural Sudoku Solvers. Software, GitHub repository, commit 9e13341. https://github.com/chenglou/sotaku.
McGovern, Ronan Killian. 2025. “Test-Time Adaptation of Tiny Recursive Models.” arXiv Preprint arXiv:2511.02886. https://arxiv.org/abs/2511.02886.
Ren, Zirui, and Ziming Liu. 2026. “Are Your Reasoning Models Reasoning or Guessing? A Mechanistic Analysis of Hierarchical Reasoning Models.” arXiv Preprint arXiv:2601.10679. https://arxiv.org/abs/2601.10679.
Roye-Azar, Antonio, Santiago Vargas-Naranjo, Dhruv Ghai, Nithin Balamurugan, and Rayan Amir. 2026. “Tiny Recursive Models on ARC-AGI-1: Inductive Biases, Identity Conditioning, and Test-Time Compute.” arXiv Preprint arXiv:2512.11847. https://arxiv.org/abs/2512.11847.
Sghaier, Amin, Ali Parviz, and Alexia Jolicoeur-Martineau. 2026. “Probabilistic Tiny Recursive Model.” arXiv Preprint arXiv:2605.19943. https://arxiv.org/abs/2605.19943.
Wang, Wenlong, and Fergal Reid. 2026. “Tiny Recursive Reasoning with Mamba-2 Attention Hybrid.” arXiv Preprint arXiv:2602.12078. https://arxiv.org/abs/2602.12078.