Confidence and Uncertainty
Given a reasoning trace produced by a Large Language Model (LLM), we want to estimate “does the model itself believe its answer is correct” without access to ground truth. This question sits at the entry point of every downstream application: selective prediction, abstention, Best-of-N weighting, and conformal prediction. This chapter first organizes the three main routes for estimators, then turns to the systematic miscalibration after Reinforcement Learning (RL) that was reported by multiple independent groups in 2026, and finally surveys the latest developments in sampling-based signals and their connection to downstream tasks.
Three Estimation Routes
Confidence estimators split into three families depending on what input they consume. logit-based methods use token log-likelihoods or entropy, verbalized methods directly ask the model to report its confidence, and sampling-based methods measure agreement or variance across multiple samples. Representative methods are summarized in Table 1.
| Route | Input | white/black box | Representative methods | Strengths | Weaknesses |
|---|---|---|---|---|---|
| logit-based | token logprob, predictive entropy | white-box | EAS (Zhu et al. 2025), Think Just Enough (Sharma and Chopra 2025) | Obtained from a single generation; lightweight | Unusable for APIs without logit access |
| verbalized | self-reported question to the model | black-box | “Are you sure?” family, DINCO (V. Wang and Stengel-Eskin 2025) | Works through APIs | Strong over-confidence after RL/RLHF |
| sampling-based | agreement / variance across many samples | black-box | semantic entropy, CISC (Taubenfeld et al. 2025), DiverseAgentEntropy (Feng et al. 2024) | No logits needed; directly tied to the answer | Cost of N samples |
TokUR (Zhang et al. 2025), accepted at ICLR 2026, is a white-box method that injects low-rank random weight perturbations at decoding time to separate aleatoric and epistemic uncertainty, sitting as an irregular case between the three routes. By aggregating token-level perturbations, it provides a framework where “the LLM self-evaluates the reliability of its own reasoning output”.
Miscalibration After RL
The largest empirical finding of 2026 is that “post-training to turn a model into a reasoning model severely degrades confidence calibration”. The same claim has been made independently by multiple groups.
Reasoning models trained with Reinforcement Learning with Verifiable Rewards (RLVR) or Reinforcement Learning from Human Feedback (RLHF) exhibit severe miscalibration, assigning extremely high probabilities to both correct and incorrect answers. Expected Calibration Error (ECE) becomes substantially worse than the base model, and verbalized confidence saturates above 85%.
Decoupling Reasoning and Confidence (Ma et al. 2026) shows that reasoning models trained via Group Relative Policy Optimization (GRPO) and similar algorithms suffer severe calibration degeneration, attributing the cause to “a gradient conflict between accuracy maximization and calibration error minimization”. The authors propose a DCPO (Decoupled Calibration Policy Optimization) loss that separates reasoning and calibration objectives, improving ECE while preserving accuracy.
Reasoning about Uncertainty (Mei et al. 2025) reports that when o1, o3-mini, DeepSeek-R1, Claude 3.7 Sonnet, and others are asked for verbalized confidence, extreme over-confidence is observed in which they assign 85% or higher confidence even to incorrect answers. The paper also shows a counterintuitive depth paradox: increasing the thinking budget worsens calibration. The effect of introspection prompts is model-dependent, improving things for o3-mini while degrading them for Claude 3.7.
Taming Overconfidence in LLMs (Leng et al. 2024) identifies the root cause of verbalized over-confidence after RLHF as the reward model being biased toward high-confidence expressions and returning higher rewards for them. The authors propose PPO-M (integrating confidence scores into reward model training) and PPO-C (re-adjusting the reward during PPO using a historical average), and improve calibration on Llama3-8B / Mistral-7B across six datasets. The shift in confidence distribution before and after RLHF appears clearly in Figure 1. Confidence that was broadly distributed across the 0.7-0.9 range at the SFT stage becomes concentrated near 1.0 after RLHF.
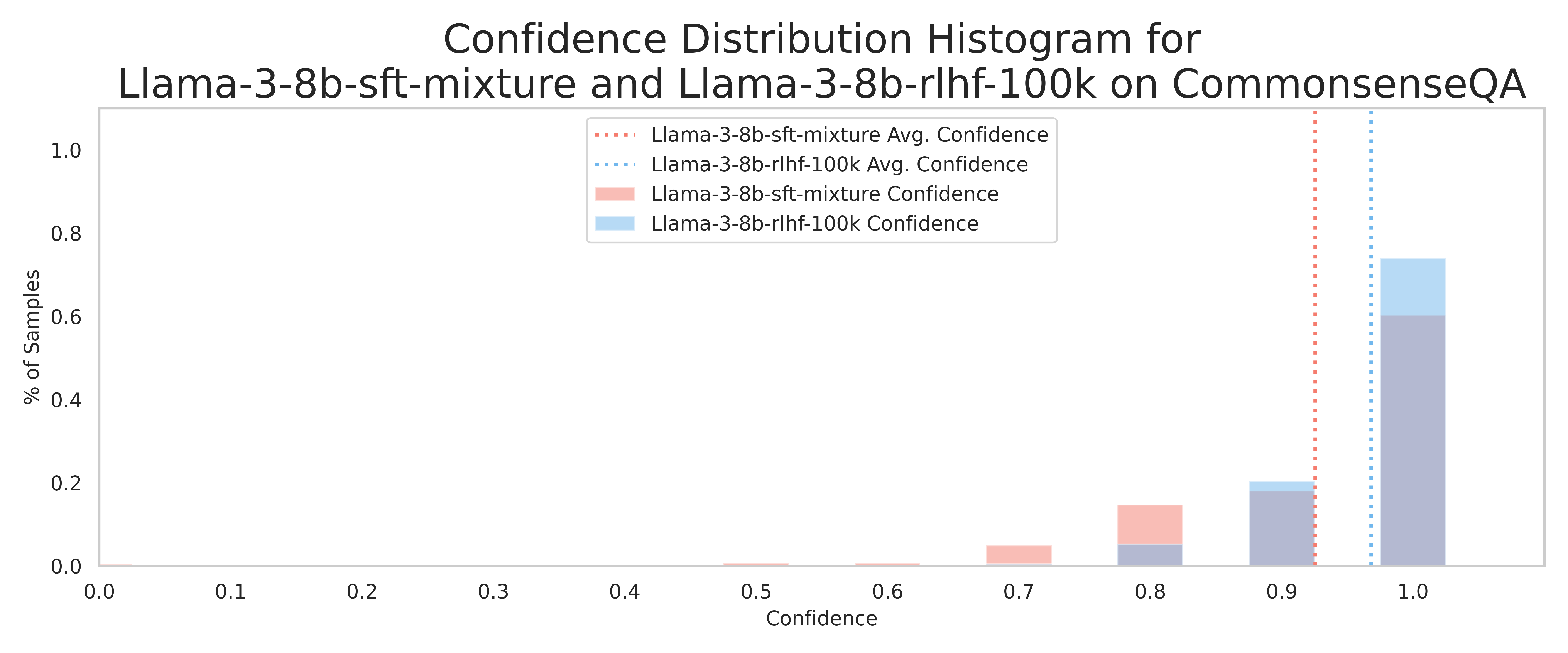
These findings provide fresh justification for why “sampling-based black-box signals” are necessary in modern reasoning models. They motivate investment in post-hoc external measurement under the assumption that logit-based and verbalized signals are broken.
The Collapse of Verbalized Confidence
For verbalized confidence, negative evidence accumulated in 2026 on three fronts: internal-circuit level, decision-theoretic perspective, and direct calibration comparison.
Wired for Overconfidence (T. Zhao et al. 2026) identifies the internal circuits that generate overconfidence using mechanistic interpretability. A compact set of mid-to-late layer MLP blocks and attention heads inflate confidence at the final token position, and targeted interventions there improve calibration. This is internal-circuit-level evidence that verbalized signals are “structurally inflated”.
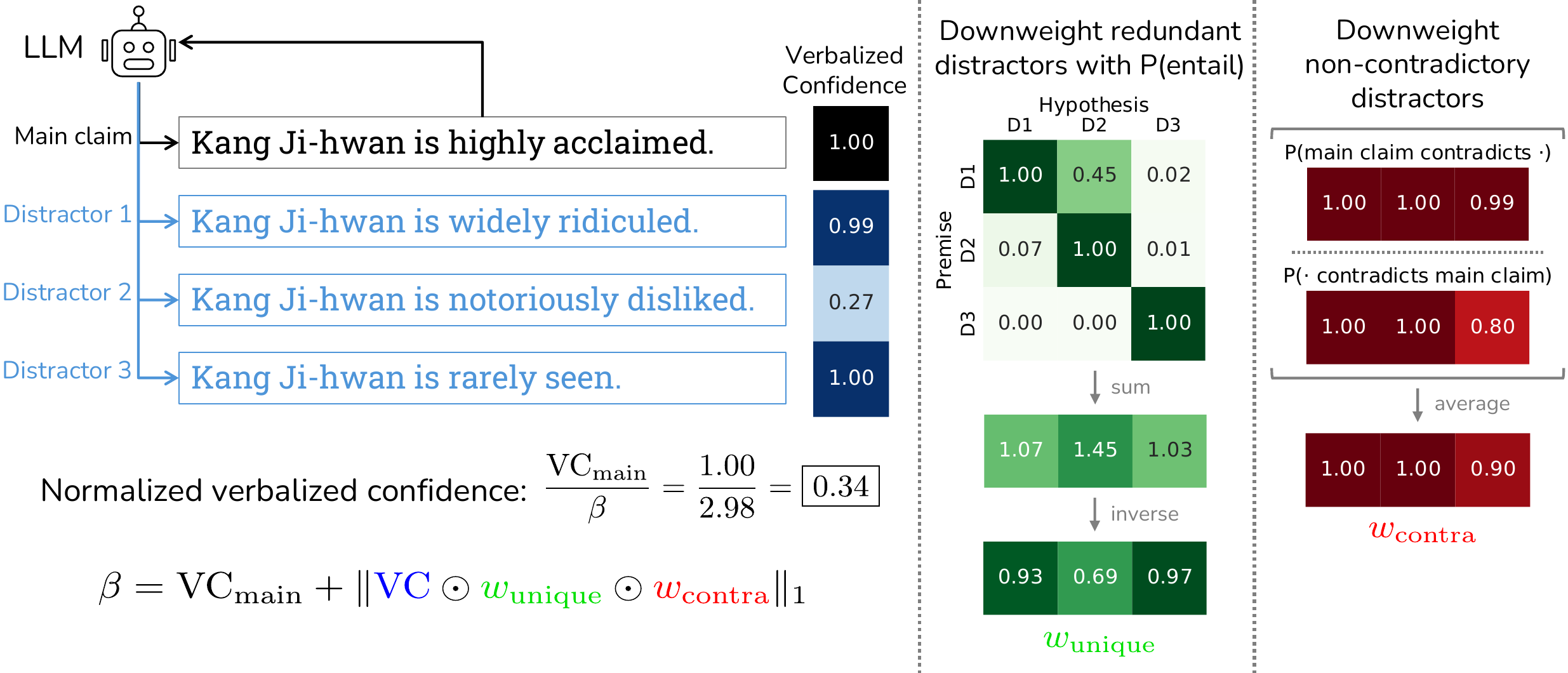
DINCO (V. Wang and Stengel-Eskin 2025) diagnoses that “verbalized confidence is over-confident because it exhibits suggestibility toward the claim presented”, and proposes a method in which the model itself generates multiple alternative claims as distractors, emits an independent verbalized confidence for each claim, and normalizes by the sum. DINCO with 10 generations operates efficiently enough to outperform self-consistency with 100 generations. The structure of the method is shown in Figure 2: the verbalized confidence of the main claim is normalized by the sum of verbalized confidences over the main claim and its distractors, with additional weighting by entailment and contradiction to suppress the “boost from suggestibility”.
Are LLM Decisions Faithful to Verbal Confidence? (J. Wang et al. 2026) introduces a benchmark called RiskEval and discovers a “utility collapse”: even under a setting that imposes high penalties on wrong answers, the model does not abstain even when it reports low verbalized confidence. Verbalized confidence comes out as a number, but it is not faithful to decision-making. This is a strong claim that calibration metrics alone are insufficient for trustworthiness.
- internal circuit: T. Zhao et al. (2026) explains the “why” mechanistically
- decision-theoretic: J. Wang et al. (2026) measures “whether it is acted on”
- direct calibration comparison: V. Wang and Stengel-Eskin (2025) shows “what improves when replaced with sampling-based”
Independently, they all support a shift to sampling-based signals.
Latest Developments in Sampling-Based Estimators
Sampling-based signals draw N reasoning traces and look at their agreement or entropy. Classically, self-consistency is the basic tool, and 2025–2026 has continued to extend it along the axes of “efficiency” and “diversity”. See Self-Consistency and Weighted Majority Voting for details.
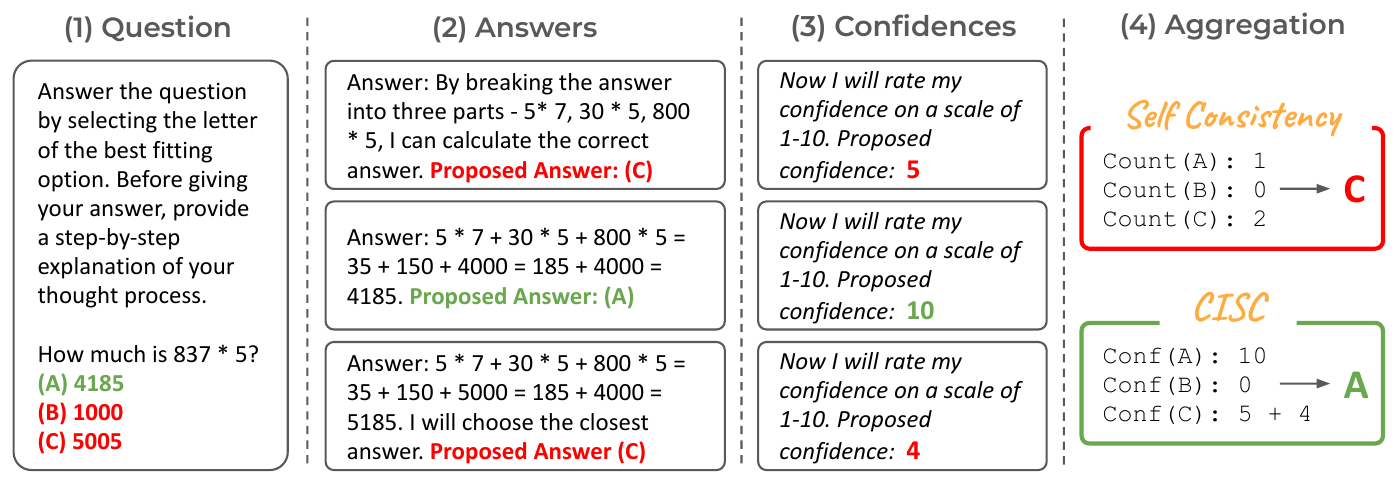
CISC (Taubenfeld et al. 2025) has the model itself emit a self-assessment score for each reasoning path and performs a weighted majority vote, reducing the required number of paths by over 40 percent on 9 models and 4 datasets. Figure 3 shows the contrast with self-consistency. Three reasoning paths are drawn for the same problem; self-consistency picks the wrong answer C by simple majority, while CISC weights paths by their self-assessment confidence and picks the answer A from the most confident path. An important finding is the report that “the most calibrated confidence method is the least effective in CISC”. This is the point that ECE-based calibration metrics can diverge from practical discrimination in some settings.
VecCISC (Petullo et al. 2026) addresses the high cost of CISC’s multi-call to a critic LLM by clustering reasoning traces by semantic similarity and filtering out redundant / degenerate / hallucinated traces in advance. It matches or exceeds CISC accuracy while reducing token usage by 47 percent.
DiverseAgentEntropy (Feng et al. 2024) computes entropy in a multi-agent setup that “asks the same knowledge with different query expressions”. Ordinary self-consistency only checks consistency across the same question and is therefore weak against cases where context bias drives the same incorrect answer repeatedly. The method captures genuine epistemic uncertainty rather than surface-level agreement, and achieves state-of-the-art for hallucination detection.
Unsupervised Confidence Calibration from a Single Generation (Zollo et al. 2026) proposes a pipeline that, as a replacement for N-time sampling, builds self-consistency-based signals offline on unlabeled data, distills them into a lightweight predictor, and emits confidence from a single generation at deployment time. It substantially outperforms baselines on 5 math and QA tasks and 9 reasoning models, and is robust to distribution shift.
Zollo et al. (2026) represents an important direction that became clear in 2026: use a high-quality sampling-based signal as a training-data generator, then distill it into a lightweight predictor that reproduces it in a single generation. Inference-time cost can be reduced by a factor of N, which fits low-latency applications such as selective generation.
Entropy Trajectory and Step-Wise Informativeness
Among logit-based signals, the family that treats token-level entropy as a “trajectory” has been rapidly consolidated since late 2025.
Entropy Trajectory Shape (X. Zhao 2026) measures per-step answer-distribution entropy across reasoning steps and finds that its shape predicts the final accuracy. Chains with monotonically decreasing trajectories have significantly higher accuracy than non-monotone chains. Trajectory shape, rather than a scalar entropy, functions as a cheap and nearly black-box indicator of correctness.
Stepwise Informativeness Assumption (Català et al. 2026) theorizes the empirical rule that “the lower the entropy in CoT, the more likely the answer is correct”. The Stepwise Informativeness Assumption (SIA) is the assumption that “autoregressive models accumulate information through answer-informative prefixes”, which is further reinforced by maximum likelihood training and RL. It is demonstrated across a wide range of models including Gemma-2, LLaMA-3.2, Qwen-2.5, DeepSeek, and Olmo on GSM8K, ARC, SVAMP, and others.
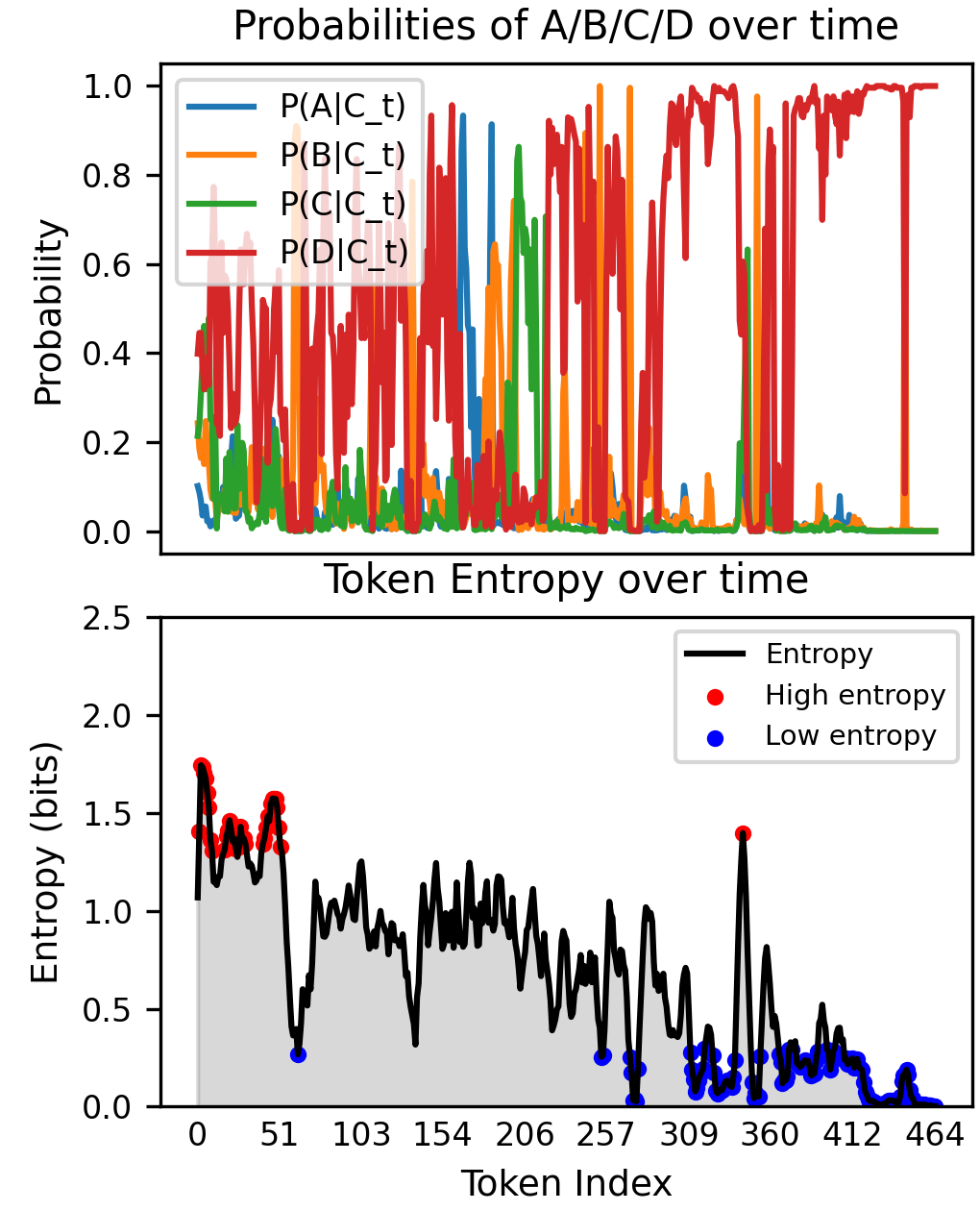
Entropy Area Score (EAS) (Zhu et al. 2025) integrates token-level predictive entropy during generation into a scalar. Requiring neither an external model nor re-sampling, it shows high correlation with answer entropy across benchmarks. It is also effective for training data selection, outperforming pass-rate-based filtering. Figure 4 is a typical example of the signal that EAS captures. The answer probabilities in the upper row oscillate violently in the first half of reasoning and converge to a single choice toward the latter half. The token-level entropy in the lower row correspondingly shows successive peaks above 1.5 bits in the first half, while consistently staying below 0.5 bits in the latter half where reasoning solidifies. EAS extracts the area under this curve as a single scalar.
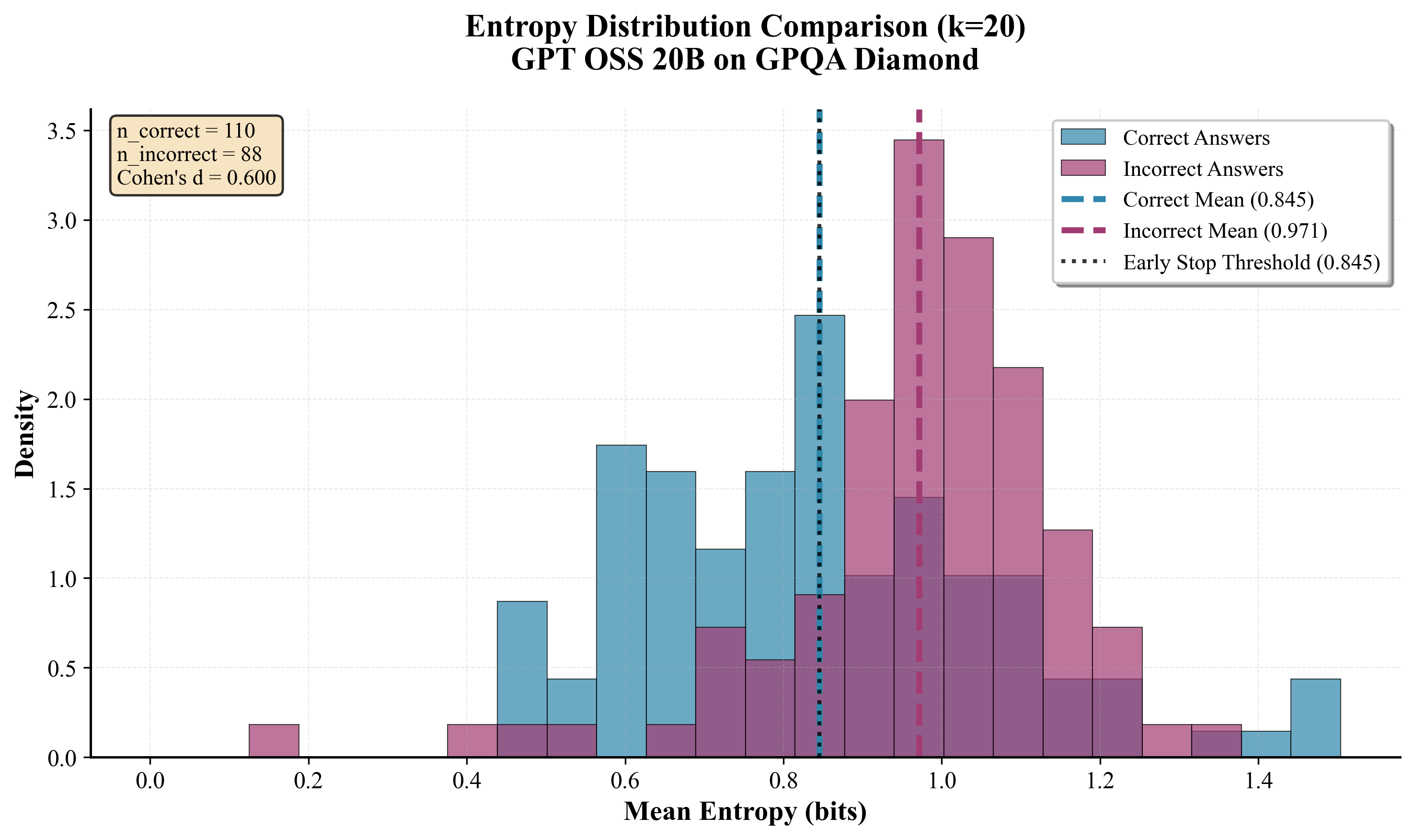
Think Just Enough (Sharma and Chopra 2025) uses Shannon entropy computed from token-level logprobs as an early-stopping signal, achieving 25–50 percent token reduction on reasoning models. An important observation is the report that this entropy-based emergent confidence appears in post-trained reasoning models (the DeepSeek-R1 family) but does not appear in standard instruction-tuned or pre-trained models (Llama 3.3 70B). Figure 5 shows how sequence-level entropy distributions separate between correct and incorrect answers on GPT-OSS 20B / GPQA Diamond. Incorrect answers consistently have higher entropy (mean 0.97 bits vs 0.85 bits, Cohen’s d = 0.6), and placing an early-stopping threshold at 0.845 bits practically discriminates correctness.
X. Zhao (2026), Català et al. (2026), Zhu et al. (2025), and Sharma and Chopra (2025) together show that “how entropy moves over time” carries more information than a single scalar entropy. This supports a design for downstream selective generation that decides when to stop based on “when entropy has settled”.
Downstream Applications
How the confidence signal is used is the final issue of this chapter. The representative downstream tasks can be organized into three: abstention, selective generation, and conformal prediction.
Abstention and Selective Generation
Knowing When to Quit (Davidov et al. 2026) proposes a principled framework that incorporates abstention as an “explicit action” inside RL during generation, halting when the value function drops below the abstention reward. It improves selective accuracy on both mathematical reasoning and toxicity avoidance, and provides a theoretical guarantee that “if value < reward then abstaining is strictly better than any other baseline” under general conditions. It is a natural foundation for plugging in confidence signals as input to abstention.
Conformal Prediction
Conformal prediction is a framework that returns a prediction set with the coverage guarantee that “the probability of containing the true answer is at least 1−α”. For LLMs, two ICLR 2026 papers have decisively established the setting.
Paraphrase-Robust Conformal Prediction (Xin et al. 2026) is a framework robust to surface variation in the prompt while preserving the conformal coverage guarantee. It expands the input via paraphrases, reinforces the predictive distribution with an auxiliary model, and aggregates the results across paraphrases. On Qwen2.5-7B, Llama-3.1-8B, and Phi-3-small, it produces compact prediction sets while preserving nominal coverage.
Online Reasoning Calibration (ORCA) (Zhou et al. 2026) is a meta-learning framework that performs conformal prediction dynamically at test time via test-time training. By performing dynamic calibration per input, it preserves the theoretical guarantee of conformal risk under distribution shift while achieving 47.5 percent efficiency improvement in-distribution and 67 percent on out-of-distribution MATH-500.
The paraphrase axis of Xin et al. (2026) and the diverse-agent axis of Feng et al. (2024) are siblings in the sense that both “ask the same knowledge with different expressions”. If a sampling-based signal is read as a nonconformity score, a confidence estimate with a coverage guarantee follows naturally.
The Opposite Pole: Learning Confidence at Training Time
As the opposite pole of post-hoc external measurement, there is an approach that internalizes confidence expression during training. Rewarding Doubt (Bani-Harouni et al. 2025) proposes an RL training scheme that seamlessly weaves confidence expression into the generation process. The reward is the logarithmic version of a proper scoring rule, penalizing both over-confidence and under-confidence. The trained model generalizes to unseen tasks. Like Leng et al. (2024)’s PPO-M / PPO-C, it represents the axis of “embedding calibration at training time” rather than “shaping inference-time signals”.
The route that measures externally at inference time (most of this chapter) and the route that builds it in at training time (Bani-Harouni et al. (2025), Leng et al. (2024), Ma et al. (2026)) are complementary rather than opposing. Training-time fixes raise the base level, and inference-time signals handle the residual uncertainty.
Chapter Summary
- Confidence estimators split broadly into three routes — logit-based, verbalized, and sampling-based — and in modern reasoning models the reliability of the logit and verbalized routes is systematically in doubt
- In 2026, multiple independent groups (Ma et al. (2026), Mei et al. (2025), Leng et al. (2024)) confirmed that “RL post-training breaks calibration”. This justifies the shift to sampling-based black-box signals
- For verbalized confidence, negative evidence has converged from three directions: internal circuits (T. Zhao et al. (2026)), decision-theoretic (J. Wang et al. (2026)), and direct comparison (V. Wang and Stengel-Eskin (2025))
- The sampling-based family is evolving along both efficiency and diversity axes; in particular Zollo et al. (2026)’s “distill N-time signals into one” trend and Feng et al. (2024)’s paraphrase axis are central
- Entropy trajectories (X. Zhao (2026), Català et al. (2026), Zhu et al. (2025), Sharma and Chopra (2025)) extend the logit-based family from “scalars” to “trajectories”, and SIA gives this a theoretical foundation
- For downstream applications, abstention (Davidov et al. (2026)), selective generation, and conformal prediction (Xin et al. (2026), Zhou et al. (2026)) are the main axes, and they are complementary to training-time calibration (Bani-Harouni et al. (2025))