Theory and Limits of RLVR
Since DeepSeek-R1, Reinforcement Learning with Verifiable Rewards (RLVR) has become the de facto standard, yet the basic question of what it is actually doing to LLMs became a major controversy in 2025–2026. Triggered by Yue et al.’s observation that “RLVR does not move outside the base distribution” (Yue et al. 2025a), counterarguments and refinements have proceeded in parallel from multiple angles, including evaluation metrics, optimization dynamics, and circuit-level intervention experiments. This chapter organizes the debate along three axes — the conflict between the expansion camp and the reweighting camp, the choice of evaluation metrics, and the mechanism behind what reweighting actually changes — and also surveys the adjacent line of work that re-evaluates the base model itself.
The Structure of the Debate
- Expansion camp: RLVR genuinely acquires reasoning traces that the base model did not have
- Reweighting camp: RLVR merely redistributes the probability mass over solution paths already present in the base distribution, acquiring no new capability
- Metric dependence: The conclusions of both camps flip easily depending on the choice of K in pass@K and on whether one evaluates only the final answer or the CoT as well
This conflict is not a mere difference of interpretation. It directly affects every practical decision, from where to invest test-time compute (longer CoT or more independent samples) to the design of downstream verifiers such as PRMs, to the choice of RL recipe. If the reweighting camp is right, inference-side tricks on the base model alone deserve a second look; if the expansion camp is right, continued RL training does yield genuinely new solving skills.
The Starting Point: Expansion or Reweighting
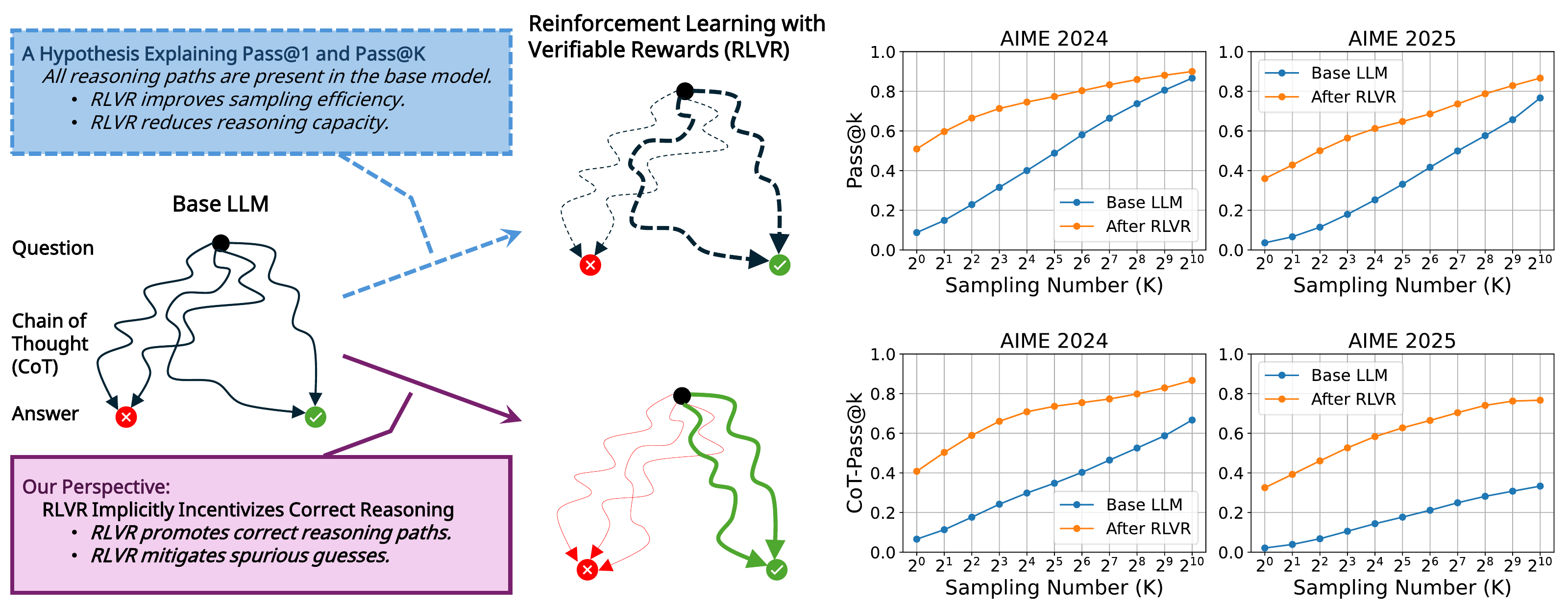
The debate was ignited by the pass@K analysis of Yue et al. at NeurIPS 2025 Oral (Yue et al. 2025a). Drawing K independent samples each from an RLVR fine-tuned model and the base model, and systematically sweeping K in pass@K (the probability that at least one sample is correct), they observed that the RL model surpasses the base for small K but that the base model overtakes the RL model once K is large enough. Furthermore, almost all generation traces of the RL model lie in the high-probability region of the base distribution in the sense of perplexity, with hardly any novel reasoning paths. From this observation they proposed the framework that “RLVR is a reweighting that improves sampling efficiency within the base distribution.”
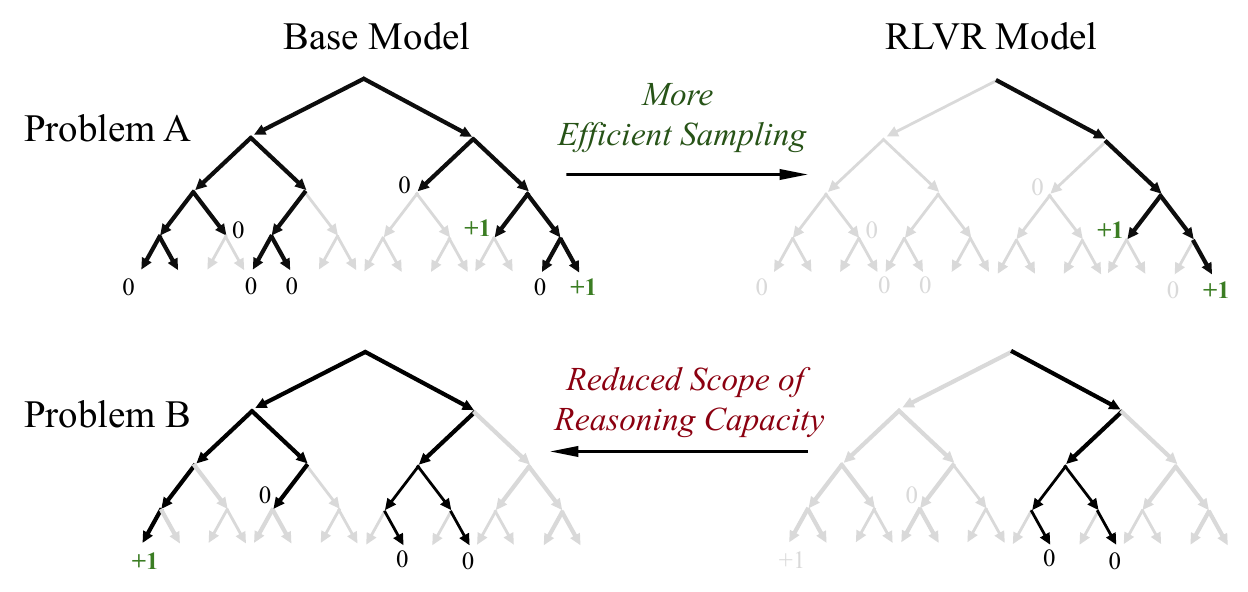
Figure 2 is the central piece of evidence in the same paper, showing that the pattern of the base overtaking the RL model at sufficiently large K is reproduced stably across four base models and four benchmarks.
This view was directly contested by the CoT-Pass@K study of Wen et al. (Wen et al. 2026). Because pass@K gives credit whenever only the final answer is correct, it cannot distinguish between paths that happened to arrive at the correct answer from incorrect reasoning traces and paths that contain a correct reasoning trace. When one switches to CoT-Pass@K, which gives credit only when both the entire CoT and the final answer are correct, the crossover that Yue et al. saw disappears and RLVR is above the base across the full range of K. The very fact that the same data leads to opposite conclusions under different metrics suggests that the heart of the debate lies in “how we measure” rather than in “mechanism.”
A view that bridges the two has since been proposed as the Two-Stage Dynamic View (Yue et al. 2025b). The behavior of RLVR can be described as a two-stage dynamic with respect to the number of training steps.
- Exploitation stage (early): high-probability tokens are further reinforced and the capability boundary shrinks
- Exploration stage (late): with sufficiently long training, the boundary genuinely expands
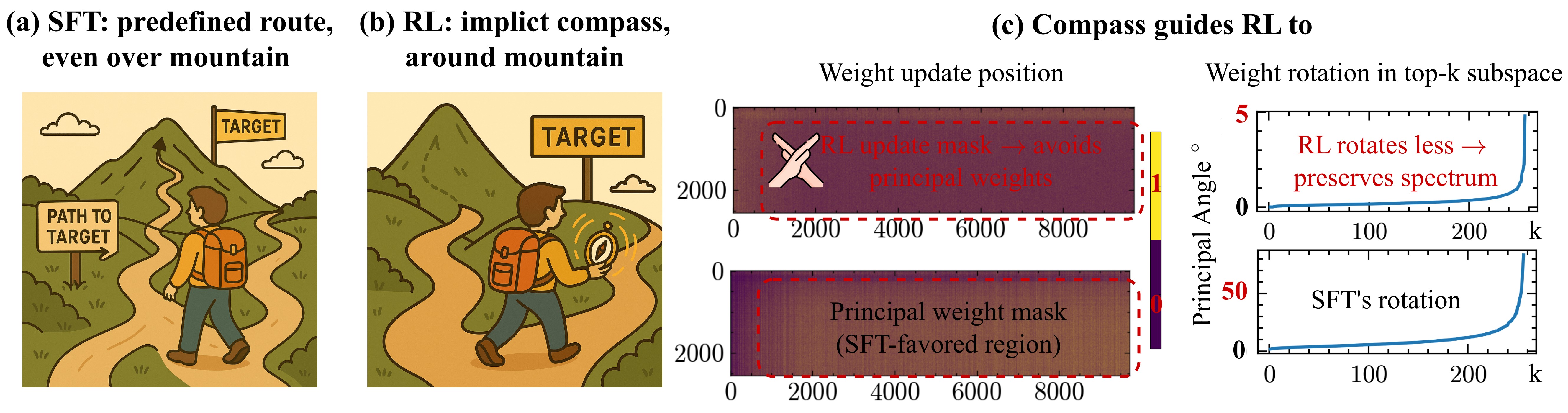
Experiments that look only at short training reach the shrinkage conclusion, while those that look at long training reach expansion, so the two camps were observing different cross-sections of the same dynamic. In a similar spirit, Path Not Taken (Hanqing et al. 2025) characterizes the training dynamic geometrically, proving via its Three-Gate Theory (KL Anchor / Model Geometry / Precision) that RLVR weight updates concentrate outside the principal directions of the pretrained model, providing theoretical backing for the reweighting view.
The Choice of Evaluation Metric
A second axis of the debate is the question of whether “measuring reasoning capability with pass@K” is appropriate at all.
Limits of pass@K
Pass@k as Diagnostic (Yu et al. 2025) decomposes the gradient of an RL objective that directly optimizes pass@K and shows that it is essentially nothing more than a per-example positive reweighting of pass@1. Moreover, the learning signal vanishes in low-success-rate regions where exploration is most needed. On this basis the authors argue that pass@K should remain as an inference-time diagnostic, while training objectives should be designed separately.
The Breadth-Depth metric (De et al. 2025) goes further, pointing out that for mathematical tasks with discrete answer spaces, pass@K at large K conflates the effect of “simply trying many times” with the reasoning boundary one actually wants to measure. As an alternative, the authors propose Cover@τ (the fraction of problems for which at least τ of the completions are correct), and the picture under Cover@τ differs from the RLVR-vs-base crossover seen under pass@K.
Table 1 summarizes the characteristics of the main metrics.
| Metric | What it measures | Behavior in RLVR vs base |
|---|---|---|
| pass@1 | Single-shot accuracy | RL consistently dominates |
| pass@K (small K) | Probability that one of K is correct | RL dominates |
| pass@K (large K) | Reachability under many attempts | Base overtakes (Yue et al. 2025a) |
| CoT-Pass@K | Probability that the whole trace is correct | RL dominates across all K (Wen et al. 2026) |
| Cover@τ | Fraction of reproducibly correct answers | Metric-specific picture (De et al. 2025) |
Taking seriously the fact that “changing how we measure flips the conclusion,” any attempt to summarize the effect of RLVR with a single number is in principle futile. The research on self-consistency and weighted majority voting covered in Self-Consistency and Weighted Majority Voting shares this concern for the same reason — how to bundle accuracy and reproducibility together.
Unpacking the Mechanism
When we say “RLVR is reweighting,” what is being reweighted with respect to what? In 2025–2026 several independent lines pushed into the mechanism.
Principal Directions and Sparse Updates
Path Not Taken (Hanqing et al. 2025), as mentioned above, shows that RLVR weight updates concentrate in low-curvature subspaces outside the principal directions of the pretrained model. This bias is invariant across datasets and RL recipes. A token-level observation in the same direction comes from Sparse but Critical (Meng et al. 2026), which shows that meaningful divergences between the RLVR fine-tuned policy and the base occur at only a tiny number of token positions, and demonstrates that a cross-sampling intervention that swaps the policies at only those critical positions reproduces most of the performance gain. The picture is that RLVR is a sparse and targeted refinement.
Small Vectors, Big Effects (Sinii et al. 2025) makes the intervention even lighter, showing that simply inserting per-layer steering vectors into the residual stream of the base model and training them with the RL objective reproduces most of the gain of full fine-tuning. The final-layer steering vector acts as a token substitution that biases the first generated token toward “To” or “Step,” while the penultimate layer up-weights process words and structural symbols. These transfer to other models in the same family.
Primitive and Pattern Selection
One answer to the question “then what is being reweighted?” is the sharpening of existing primitives. New Skills or Sharper Primitives (Wang et al. 2026) uses a synthetic task called Algebrarium (training only on single-step problems and evaluating on multi-step) to show that RLVR sharpens the probability of atomic steps, thereby suppressing the failure probability that compounds exponentially in composite tasks. The picture is that not new skills but the sharpening of already-existing atomic operations is what supports compositional reasoning.
Reshaping Reasoning (Chen et al. 2025) gives a theoretical analysis of RLVR convergence on a simplified question–reasoning–answer model and shows that RLVR does not create new reasoning patterns but rather acts as a pattern selector that picks the highest-success-rate pattern from among existing ones. Two regimes are derived: models with strong initial capability converge rapidly while weak ones converge slowly. On the Learning Dynamics of RLVR at the Edge of Competence (Huang et al. 2026) treats the same problem for compositional reasoning on Transformers and theorizes a relay regime in which a natural “easy-to-hard” curriculum emerges in difficulty-mixed data, together with grokking-like phase transitions that appear when there is a discontinuity in difficulty.
The Risk of Memorization Shortcuts
A particularly strong counterexample within the mechanism research is the Spurious Rewards Paradox (Yan et al. 2026). On models such as Qwen2.5, RL with random or even incorrect rewards can sometimes lead to substantial gains on downstream tasks. The authors analyze this puzzle via path patching and the logit lens, and discover an Anchor–Adapter circuit in which a Functional Anchor in middle layers L18–20 calls up memorized solutions from pretraining and a Structural Adapter at L21+ surfaces them. Part of the performance gain of RLVR may not be genuine reasoning enhancement but rather the activation of memorization shortcuts derived from contaminated data.
Consistent with this observation, Post-Training as Reweighting (Bu et al. 2025) formalizes the view that RLVR, outcome reward models, and process reward models all do not expand the tree-like set of reasoning paths but only reweight existing paths, casting it as a Multi-task Tree-structured Markov Chain. The division of labor is organized as “pretraining expands the tree, post-training reweights the CoT.”
Table 2 lines up the main mechanism hypotheses.
| Hypothesis | Central observation | Representative paper |
|---|---|---|
| Off-principal small updates | Weights move outside the principal directions of the pretrained model | (Hanqing et al. 2025) |
| Sparse token-level intervention | The policy changes only at a small number of critical positions | (Meng et al. 2026) |
| Steering bias | Lightweight per-layer vectors reproduce performance | (Sinii et al. 2025) |
| Primitive sharpening | Sharpening of atomic-step probabilities | (Wang et al. 2026) |
| Pattern selection | Selecting the best among existing patterns | (Chen et al. 2025) |
| Memorization shortcut | Middle-layer circuits invoke memorized solutions | (Yan et al. 2026) |
These hypotheses are not mutually exclusive and likely view the same phenomenon at different resolutions. Considering that middle-layer circuits such as the Functional Anchor are part of the weights updated outside the principal direction, and that this in turn concentrates at a few critical positions when viewed in the downstream token distribution, a consistent picture emerges.
Lines Returning to the Base Model
If RLVR is no more than reweighting, then manipulating the base model itself at inference time should achieve an equivalent effect — a line of work driven by this idea is proceeding in parallel.
Reasoning with Sampling (Karan and Du 2025) shows that an inference-only power sampling (a Metropolis–Hastings-based method that sharpens the likelihood of the base model) requiring no training, verifier, or dataset achieves reasoning performance comparable to or above RLVR on MATH500, HumanEval, and GPQA. As a side benefit, the diversity collapse frequently observed in RL post-training does not occur.
Can GRPO Transcend (Ni et al. 2025) theoretically explains the inconsistent out-of-distribution (OOD) generalization of GRPO — it works on math but not on medicine — and proves that GRPO is a conservative reweighting scheme bounded to the base distribution and cannot discover novel solutions. The paper redefines GRPO not as a “universal reasoning enhancer” but as a “sharpener of pretraining biases.”
RL vs Distillation (Kim et al. 2025) provides a careful comparison between RLVR and distillation. RLVR raises accuracy (pass@1) but not capability (pass@K), while distillation raises capability only when new knowledge is brought in. The observation that distilling only patterns falls into the same trade-off as RLVR offers a clue for organizing the division of labor among “base model + inference tricks,” “RLVR,” and “distillation.”
Chapter Summary
The state of the art in 2025–2026 on the question of what RLVR is doing can be summarized in the following four points.
- Reweighting is becoming the mainstream view. Starting from Yue et al.’s observation (Yue et al. 2025a), Path Not Taken (Hanqing et al. 2025), Sparse but Critical (Meng et al. 2026), Pattern Selection (Chen et al. 2025), GRPO Transcend (Ni et al. 2025), and Consistency (Bu et al. 2025) independently reached the conclusion of “redistribution of probability mass within the base distribution”
- The choice of evaluation metric dominates the conclusion. pass@K and CoT-Pass@K (Wen et al. 2026), Cover@τ (De et al. 2025) draw different conclusions from the same data and show that “no single metric can summarize it”
- A dynamic view is the key to reconciliation. The Two-Stage Dynamic View (Yue et al. 2025b) and Interplay (Zhang et al. 2025) show that the effectiveness of RL is a function of training stage and problem difficulty, suggesting that the claims of the expansion and reweighting camps may be different cross-sections of the same dynamic
- A re-evaluation of the base model is proceeding in parallel. Reasoning with Sampling (Karan and Du 2025) reaches RLVR-comparable performance using inference-only operations, leaving room for routes that do not go through RL
These are closely intertwined with the other signals on the training side (GRPO and reward design, PRMs) and the signals on the inference side (self-consistency, confidence, test-time compute scaling) treated in subsequent chapters. For example, recent remarks on the limitations of PRMs resonate precisely with the “resolution of reweighting” seen in this chapter, and the rise of self-consistency and prefix-based reranking systems likewise stems from the same question of how to extract the correct path from within the base distribution.