Tree Search and MCTS
Treating Chain-of-Thought (CoT) not as a single sequence but as a tree structure allows multiple continuations to be expanded and selected at each node. Research that brings classical search algorithms such as Monte Carlo Tree Search (MCTS), Tree-of-Thoughts (ToT), and beam search into Large Language Models (LLMs) inherits the lineage going back to AlphaGo, and went through another major update in 2025–2026.
This chapter organizes the tree-search methods that appeared in 2025–2026 along seven axes.
- Representative MCTS methods: the lineage of AlphaMath / rStar-Math
- Dynamic choice between wider vs deeper: the branching control opened up by AB-MCTS
- Verification granularity control: the continuous spectrum between beam search and Best-of-N shown by VG-Search
- Uncertainty-based branching: the shift from point estimates of the value function to distributional estimates, and on to policy entropy
- Verifier-free / lightweight verifier lines: self-evaluation approaches that reduce reliance on PRMs
- Faithfulness warnings: the gap between a “deep trace” and the “actual decision”
- Efficiency lines: implementation optimizations that are conscious of the compute budget
Finally, we also touch on the movement to recast tree search as probabilistic inference.
Treating CoT as a Tree
The motivation for treating LLM reasoning as a tree is simple. Even if we raise the sampling temperature and draw many single chains, traces that continue a redundant reasoning on top of a wrong premise cannot be rescued. With a tree structure, once an error is noticed, one can switch to a different branch.
LLM tree-search algorithms can be roughly described by three elements (Wei et al. 2025).
- Search Mechanism: which node to expand (MCTS’s UCB, beam search’s top-k, A*’s heuristic, etc.)
- Reward Formulation: how to assign value to each node or trajectory (PRM, self-evaluation, consistency, etc.)
- Transition Function: the unit of transition from a node to the next (token, step, thought type, etc.)
The survey (Wei et al. 2025) classifies existing methods along these three axes and provides a conceptual map that unifies test-time scaling and self-improvement.
Node Semantics Vary Across Papers
Among the three axes in the callout above, the Transition Function axis (the unit of transition from one node to the next) is actually the biggest source of confusion when reading LLM tree-search papers across the literature. Even when papers use the same words “tree” and “node,” what a node represents varies widely. The main methods covered in this book fall into the following seven systems.
| System | What a node represents | How boundaries are drawn | Representative examples |
|---|---|---|---|
| (α) Reasoning step | A single reasoning step (sentence or paragraph) | Newlines / step splitters | ToT (Yao et al. 2023), MITS (J. Li et al. 2025) |
| (β) Semantic marker | Chunk up to the next transition marker | Vocabulary like “Wait” / “Therefore” | Beyond the Last Answer (Hammoud et al. 2025) |
| (γ) Fixed-length window | \(L\) tokens or a fractional position \(\tau\) | Fixed length or ratio | Path-Consistency (Zhu et al. 2024), PoLR (Jindal et al. 2026), Prefix Consistency (Iwase et al. 2026) |
| (δ) MDP state | State in problem space | Domain-specific encoder | Reasoning via Planning (RAP) and other planning systems |
| (ε) Whole candidate solution | One full reasoning trace or one code candidate | Node = whole solution | AB-MCTS (Inoue et al. 2025) (Code Contest, etc.) |
| (ζ) Aggregator node | Virtual node that aggregates child statistics | Non-leaf itself carries meaning | The GEN node of AB-MCTS (Inoue et al. 2025) |
| (η) Question / sub-problem | A reformulation of the problem or a sub-question | LLM-emitted sub-question | Decomposed Prompting line |
When the meaning of a node differs, (i) the same “branching factor” or “depth” become incomparable, (ii) the granularity required by a verifier differs, and (iii) the unit of compute budget (LLM call count vs token count) changes, making fair comparison difficult. When reading each method in this chapter, paying attention to “what is a node here” greatly improves clarity. In particular, when comparing the prefix-based methods of Self-Consistency and Weighted Majority Voting (which sit in the γ system) with the (α) Reasoning step systems covered in this chapter, note that the referents of “node” differ between the two.
ToT and the Choice of Search Algorithm
The foundational LLM tree-search paper is Tree of Thoughts (ToT) (Yao et al. 2023), which most subsequent work inherits. ToT is described by four components.
- Thought decomposition: split the problem into units of “1 thought = 1 intermediate step”
- Thought generator \(G(p_\theta, s, k)\): sample \(k\) candidate thoughts from state \(s\)
- State evaluator \(V(p_\theta, S)\): ask the LLM itself “is this state promising?” and obtain a scalar
- Search algorithm: explore the tree with BFS / DFS / Beam Search
That is, ToT carries a self-evaluation structure where “LLM = policy + value function,” and an explicit LLM evaluator drives the search. The original paper switches search algorithm by task.
| Task | Search algorithm | Setting |
|---|---|---|
| Game of 24 | BFS with top-\(b\) keep | \(b = 5\) (effectively Beam Search) |
| Creative Writing | BFS | \(b = 1\) (nearly greedy) |
| 5×5 Mini Crosswords | DFS | with backtracking |
In other words, ToT is a framework rather than a single algorithm. Subsequent papers use compound names such as ToT-BS (Beam Search), ToT-DFS, and ToT-BFS to make the search algorithm explicit. When reading the literature, even if a paper simply writes “ToT,” one needs to check the experiment section to learn which search algorithm is actually being used.
MCTS vs ToT
ToT is not MCTS. The two are different families of search algorithms, and the methods covered in this chapter also split largely along this line. MCTS classically runs a 4-stage cycle.
- Selection: descend from existing nodes via UCB / Thompson sampling, etc.
- Expansion: when reaching a leaf, add a new child
- Simulation (rollout): random rollout from the new child until a final outcome
- Backpropagation: propagate the rollout outcome back to the root, updating all ancestors’ statistics
ToT has neither rollout nor backpropagation. It calls the LLM evaluator once at each node to obtain a scalar, then advances along the high-scoring branch via BFS / DFS / Beam. The differences are summarized below.
| Item | MCTS | ToT |
|---|---|---|
| Selection rule | UCB / Thompson sampling (statistical) | LLM evaluator scalar (heuristic) |
| Rollout | Yes (random simulation down to a leaf) | No (1 node = 1 LLM evaluation) |
| Backpropagation | Yes (rollout outcome propagates to all ancestors) | No (each node independent) |
| Value update | Iteratively update \(N(v), W(v)\), etc. | Single LLM evaluation only |
The LLM tree-search papers covered in this chapter split into these two camps.
- MCTS line: AlphaMath (G. Chen et al. 2024), rStar-Math (Guan et al. 2025), AB-MCTS (Inoue et al. 2025), SC-MCTS* (Gao et al. 2024)
- Non-MCTS heuristic line: the ToT line (Yao et al. 2023), Reasoning via Planning (RAP), MITS (J. Li et al. 2025) (PMI with beam search), CMCTS (Lin et al. 2025) (note that having “MCTS” in the name does not imply that the method runs the classical rollout-based MCTS)
When reading the discussions of VG-Search (H. M. Chen et al. 2025) or UATS (Song et al. 2026) / UVM (Yu et al. 2025) later, keeping track of which camp each method belongs to helps the picture come together.
That the way the reward is given dominates tree-search performance has become increasingly clear with the skepticism toward PRMs discussed later (Cinquin et al. 2025) and the rise of verifier-free lines (M. Wu et al. 2025; Rakhsha et al. 2025).
Representative MCTS Methods
A widely referenced starting point in the LLM × MCTS lineage is AlphaMath (G. Chen et al. 2024). It uses the ground-truth match rate of MCTS rollouts as value to learn an annotation-free Process Reward Model (PRM), and alternately improves the policy and the value. By bringing an AlphaGo-style self-play structure into math problems, it has become a reference point for subsequent MCTS-for-reasoning research. The overall pipeline is shown in Figure 1.
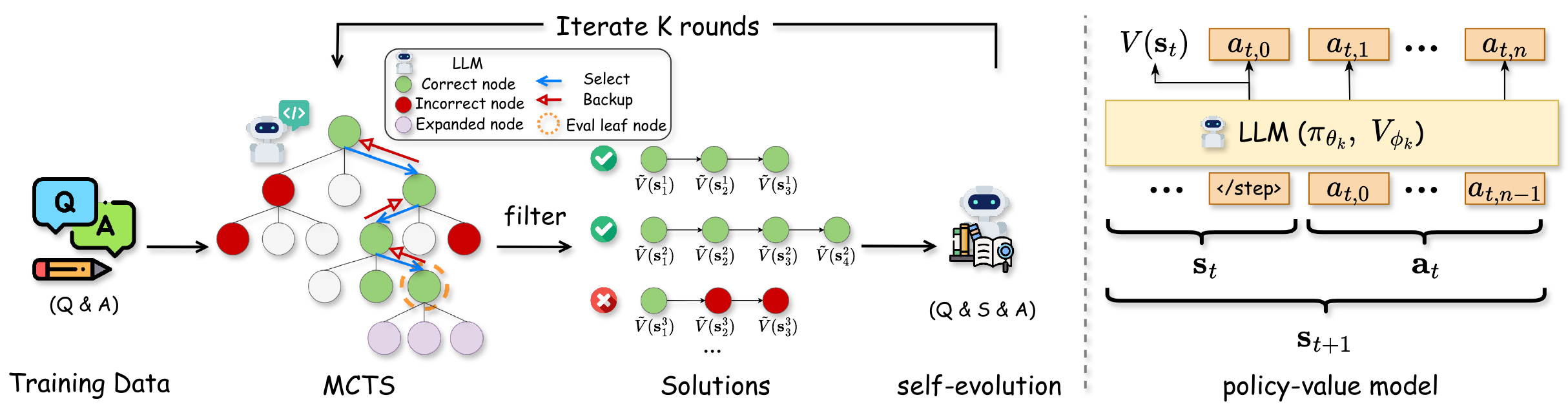
rStar-Math (Guan et al. 2025) pushes this lineage further at the scale of a 7B small language model (SLM), achieving 53.3% on AIME 2024 (8/15 problems correct, surpassing o1-preview). The method overview is shown in Figure 2.
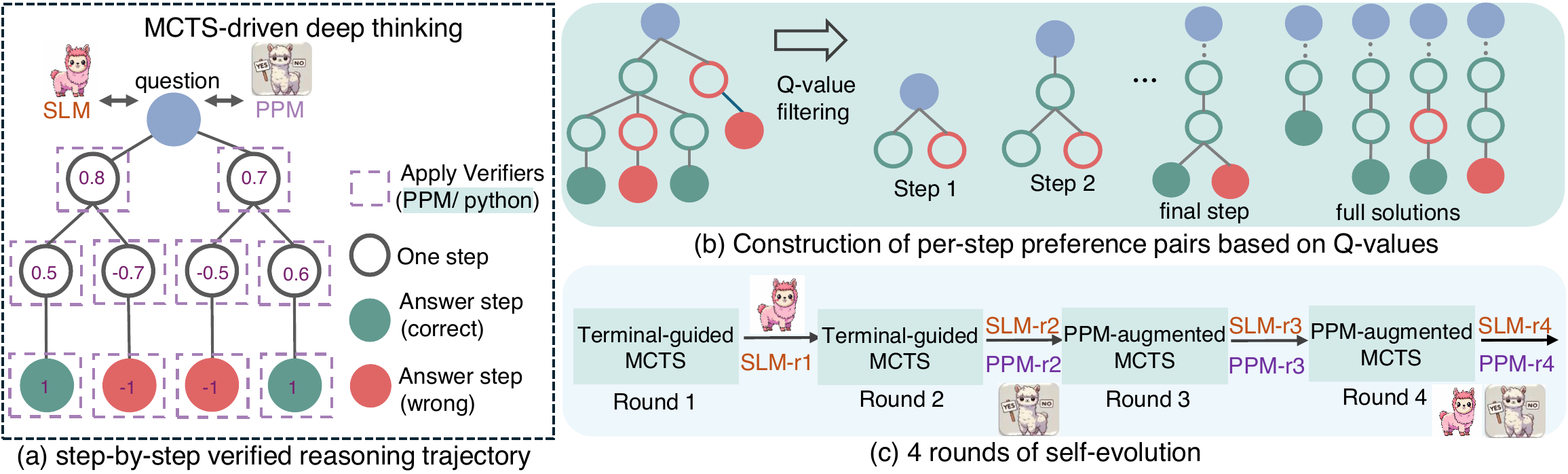
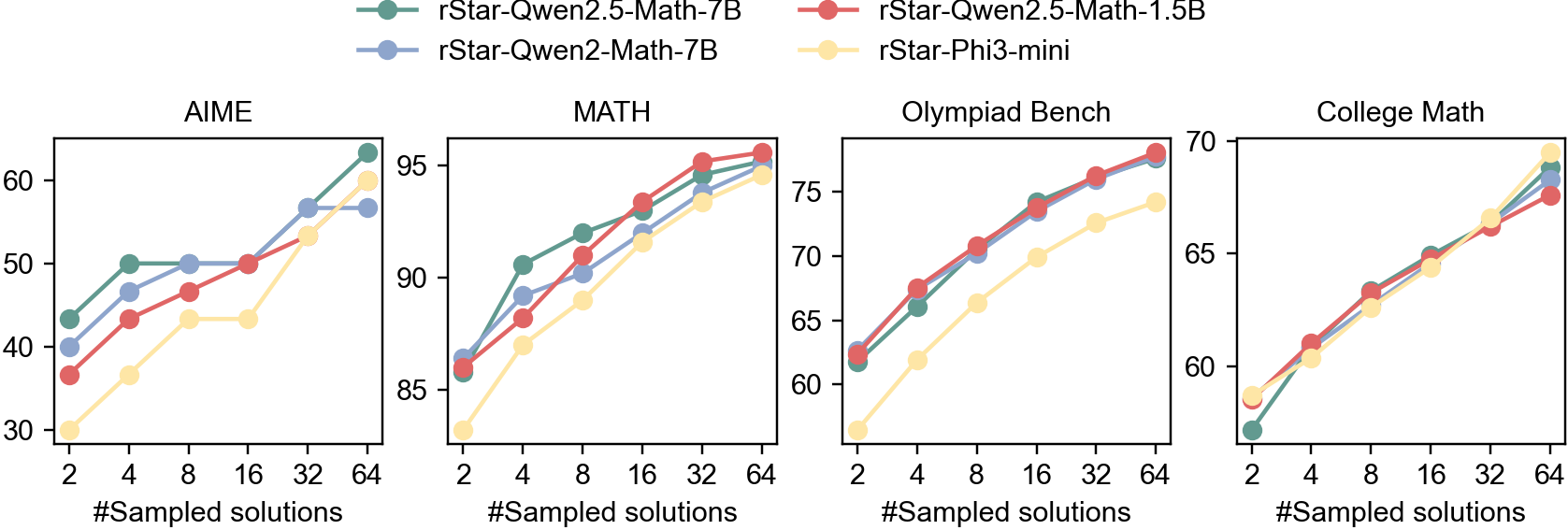
The self-evolution in Figure 2 can be read as extending AlphaMath’s policy-value alternating update (Figure 1) to both MCTS and PPM. Figure 3 shows the pass@K performance when increasing the number of MCTS samples. As the sample count grows, performance scales logarithmically across AIME / MATH / Olympiad / College Math, reaching over 60% on AIME with 64 samples.
The contributions of rStar-Math are threefold.
- Code-augmented CoT data synthesis: trajectories obtained from MCTS rollouts are verified by Python execution and used as training data
- Process Preference Model (PPM) training without score annotation: rather than numerical scores, the PPM is trained pairwise from the relative order of Q-values from rollouts
- Self-evolution of the policy and PPM: four rounds of iterative training lift performance
The result that a 7B SLM surpasses o1-preview shows that by embedding MCTS into the data generation pipeline, deep reasoning can be learned in an almost verifier-free manner, and directly influenced subsequent work such as DeepSearch (F. Wu et al. 2025).
SC-MCTS* (Gao et al. 2024) combines an interpretable reward model based on the principle of contrastive decoding with speculative decoding for speedup, reporting that Llama-3.1-70B + SC-MCTS* exceeds o1-mini by an average of +17.4% on the Blocksworld planning task. It is an example of simultaneously improving reward and inference speed, two of the three MCTS elements.
Dynamic Choice Between Wider vs Deeper
Determining the branching factor of MCTS has classically been a difficult problem. In the LLM context, one needs to decide online whether to “sample again from the same node (wider) or descend into a child node (deeper).”
AB-MCTS (Adaptive Branching MCTS) (Inoue et al. 2025) answers this question with Thompson sampling. For each node, an “expansion arm” that generates a new child and a “continuation arm” that selects an existing child are handled as a Bernoulli–Gaussian mixture Bayesian posterior, and the optimal branching is automatically determined per node. NeurIPS 2025 Spotlight. Figure 4 contrasts it with existing methods.
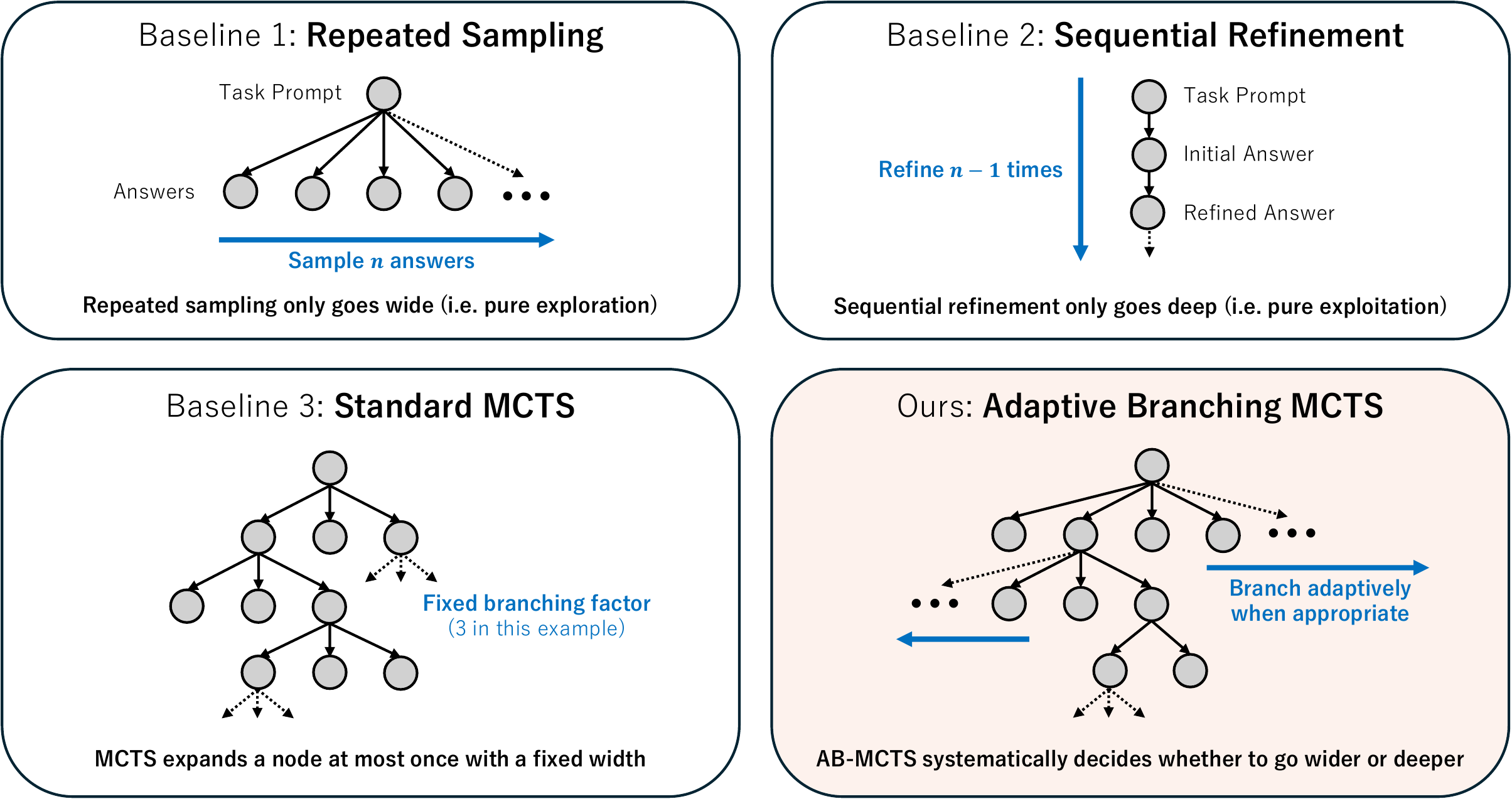
As the bottom right of Figure 4 shows, AB-MCTS switches per-node between “generating an additional child from the same node” and “deepening an existing child” through Thompson sampling on a Bayesian posterior.
AB-MCTS’s wider vs deeper control is a framework that decides “where to place the next sample” by uncertainty. UATS (Song et al. 2026) and UVM (Yu et al. 2025) discussed later can be interpreted as generalizing this idea by carrying it into the uncertainty of the value function itself.
Verification Granularity Control
If wider vs deeper is the problem of “where to place the sample,” then verification granularity is the problem of “how frequently to call the verifier.” Beam search verifies at every step, Best-of-N verifies only at the terminal. The two have been treated as separate algorithms, but in fact they are only the two ends of a continuous spectrum.
VG-Search (H. M. Chen et al. 2025) introduces a granularity parameter \(g\) and defines a general form in which the PRM screens candidates every \(g\) steps. With \(g=1\) we recover beam search, with \(g=L\) (the full length of the reasoning path) we recover Best-of-N, and \(1<g<L\) lies in between. Figure 5 shows an overview.
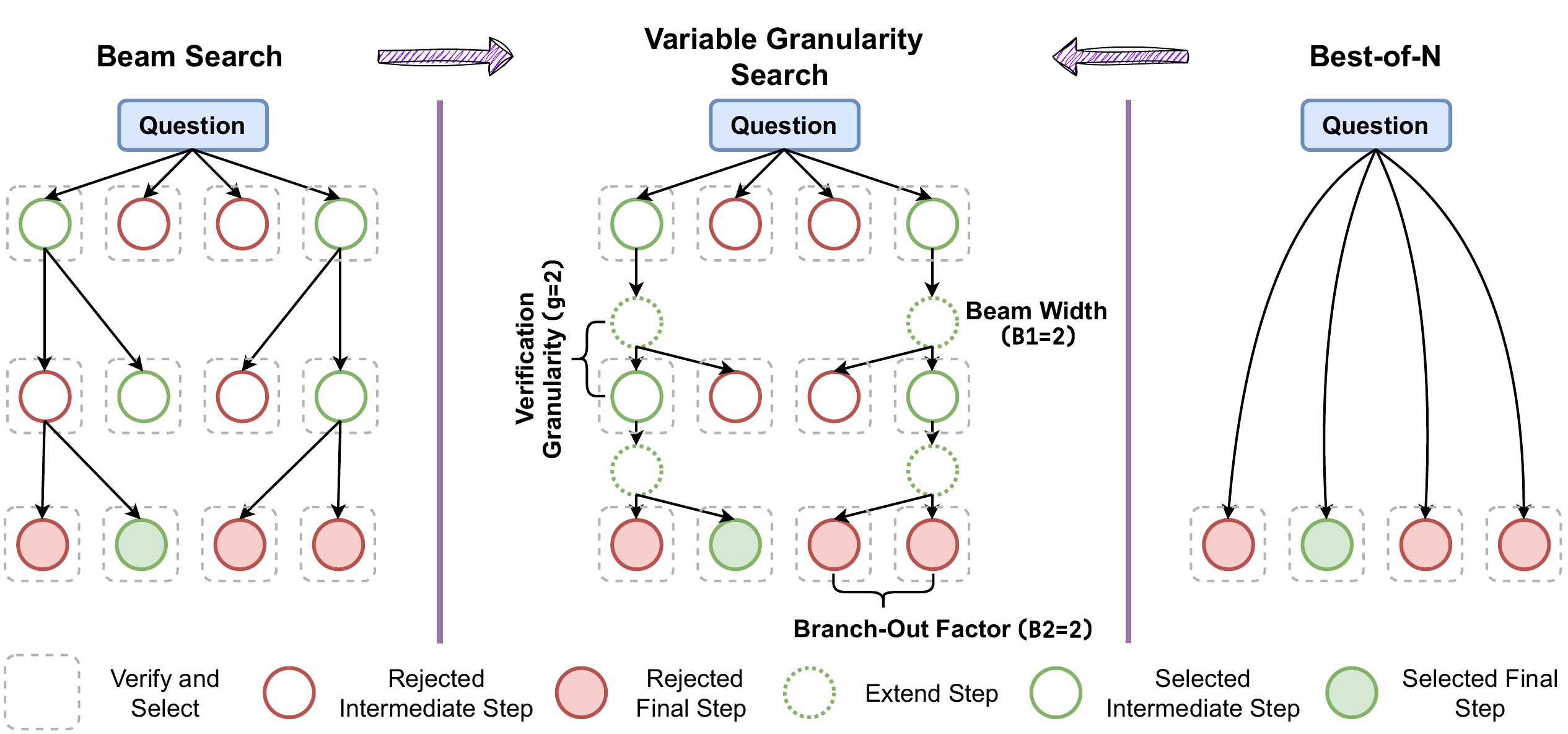
The key finding of VG-Search is that the optimal \(g\) varies with the task, the compute budget, and the model capability.
- Harder problems require denser verification (smaller \(g\)). The probability of erring at each step is high, so early trajectory correction is needed
- Larger compute budgets suffice with coarser verification (larger \(g\)). Even when verifier calls are reduced, accuracy is maintained
- Stronger generators match coarser verification. If the generator emits stable steps, frequent PRM calls are wasted
On MATH-500 (Qwen2.5-Math-7B + Skywork-o1-1.5B verifier), adaptive \(g\) selection achieves up to +3.1% accuracy improvement over beam search and +3.6% over Best-of-N, while at the same time reducing FLOPs by more than 52%. For instance, \(g=3\) reaches about \(2^{13}\) FLOPs / about 88% accuracy, whereas \(g=1\) (beam) requires about \(2^{15}\) FLOPs and stays around 87.5%. There exists a regime where lowering the verification frequency improves both accuracy and efficiency.
Uncertainty-Based Branching
The trend of replacing the point estimate of a PRM (a single numerical score) with an uncertainty distribution of the value function strengthened in 2025–2026.
UATS (Adaptive Uncertainty-Aware Tree Search) (Song et al. 2026) estimates the epistemic uncertainty of the PRM via Monte Carlo Dropout and dynamically allocates compute budget per node via a Reinforcement Learning (RL) controller. Theoretically, while standard search incurs linear regret, uncertainty-aware search can achieve sublinear regret. It is reported to mitigate PRM blow-ups on Out-Of-Distribution (OOD) reasoning paths. Figure 6 succinctly captures the motivation of UATS.
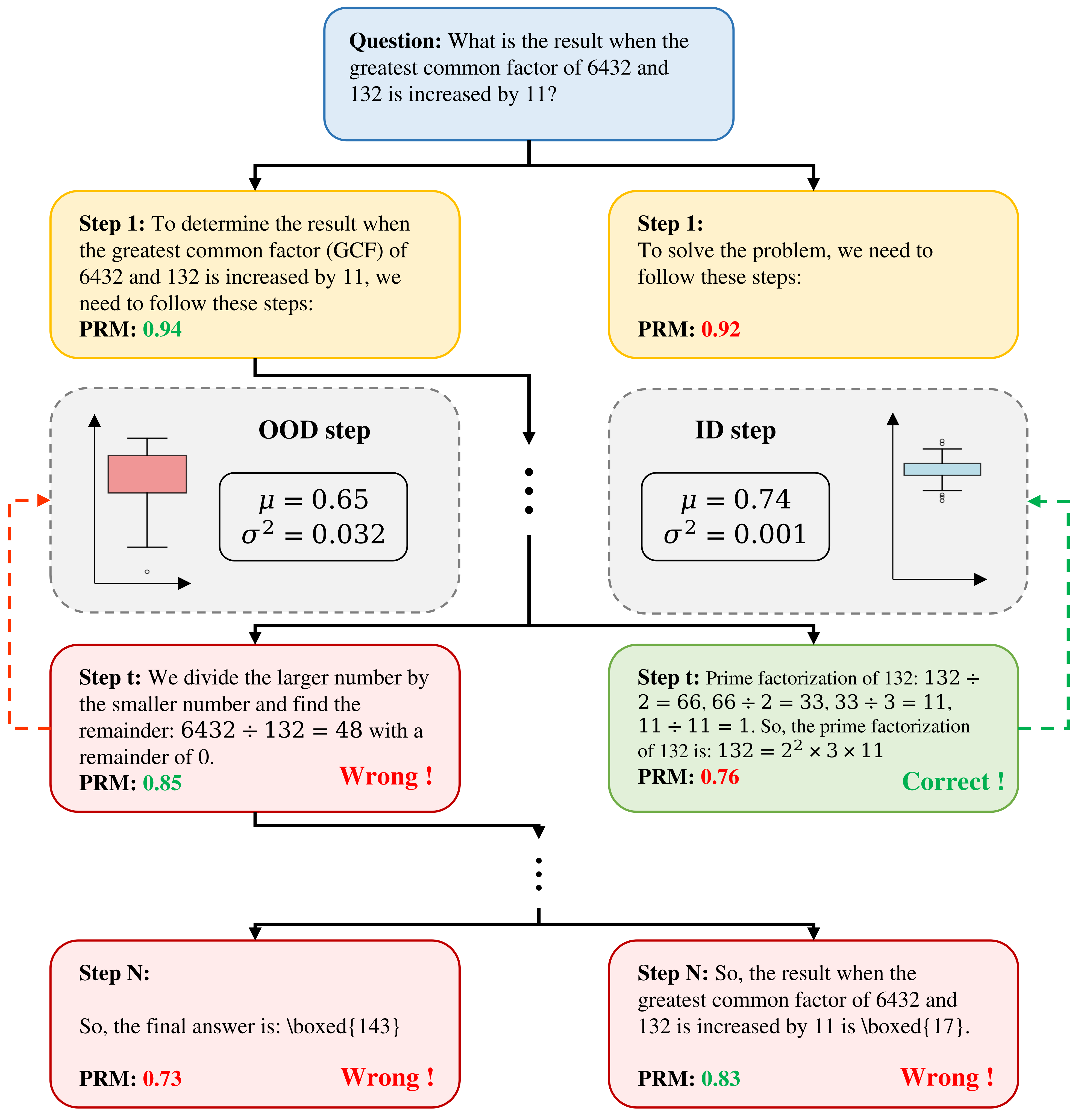
In the OOD step on the left of Figure 6, the PRM’s mean score is high at 0.85 but its variance \(\sigma^2=0.032\) is large, and as a result the wrong branch (Wrong) is taken. The ID step on the right, conversely, has a lower score of 0.76 but with \(\sigma^2=0.001\) can confidently select the correct branch (Correct). A typical case where the point-estimate PRM diverges from the node’s “true value.”
Robust Search with Uncertainty-aware Value Models (Yu et al. 2025) proposes the Uncertainty-aware Value Model (UVM), which replaces a single-point value estimate with a value distribution, together with Group Thompson Sampling that selects the optimal candidate from that distribution. In addition to in-distribution evaluation on GSM8K and MATH, it substantially mitigates verifier failure on OOD settings such as AIME25 and Minerva.
MITS (J. Li et al. 2025) adopts an entropy-based dynamic sampling design that “concentrates compute on uncertain steps,” and avoids expensive look-ahead simulation by using pointwise mutual information (PMI) as a step-wise score. The final prediction is a weighted majority vote of PMI and consensus.
Similarly using entropy as a branching gate, Entropy-Gated Branching (X. Li et al. 2025) uses the entropy of the next-token prediction distribution directly as a branching signal, instead of a value function. The design is to generate multiple continuations only at steps whose entropy exceeds a threshold, and to proceed along a single path otherwise: “branch only where the model is hesitant.” Figure 7 contrasts Normal decoding / Beam search / Entropy-Gated Branching.
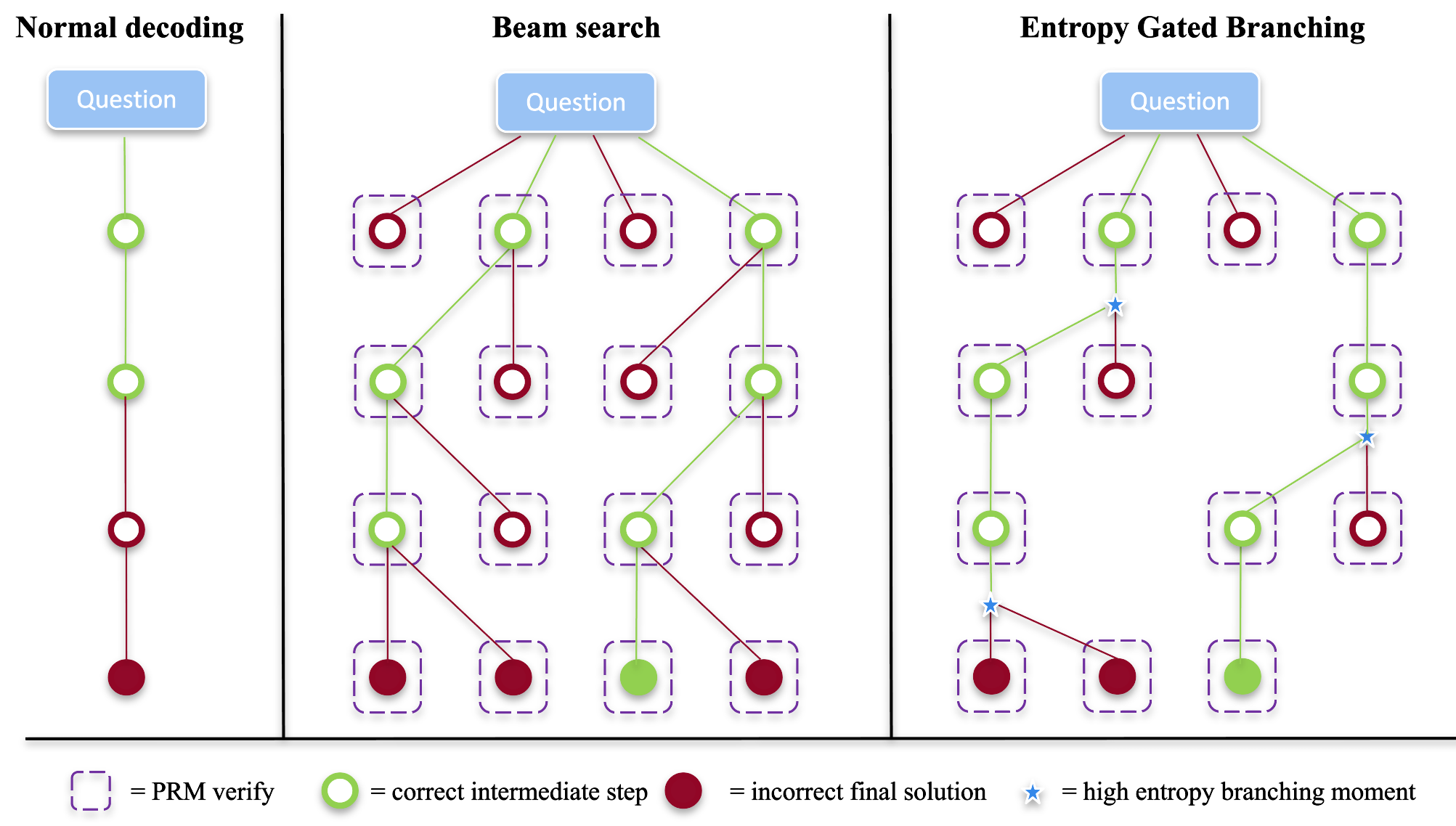
It reports +22.6% accuracy improvement over standard decoding and 31–75% speedup over uniform beam search on math reasoning benchmarks. The idea of concentrating compute on “uncertain steps” follows the same spirit as MITS’s entropy + PMI, but extracts uncertainty from the policy-side distribution rather than from the value side.
Representative approaches to uncertainty-based branching of the value function are summarized in Table 4.
| Method | Representation of uncertainty | Control target |
|---|---|---|
| AB-MCTS (Inoue et al. 2025) | Bayesian posterior over branching arms | wider vs deeper |
| UATS (Song et al. 2026) | PRM epistemic uncertainty via MC Dropout | per-node budget (RL) |
| UVM (Yu et al. 2025) | Value distribution + Group Thompson | candidate selection |
| MITS (J. Li et al. 2025) | Step entropy + PMI | sample count |
| Entropy-Gated (X. Li et al. 2025) | Entropy of next-token prediction distribution | whether to branch (gate) |
Verifier-Free / Lightweight Verifier Lines
As the limits of PRM-guided search (Cinquin et al. 2025) became recognized, methods that control search without an external reward model have been growing.
SELT (Self-Evaluation Tree Search) (M. Wu et al. 2025) is an MCTS that redefines UCB through the LLM’s intrinsic self-evaluation, without using any external reward model. It decomposes each node into atomic subtasks and applies semantic clustering. Improvements in robustness and suppression of hallucinations are reported on MMLU and Seal-Tools.
W2S-AlignTree (D. Zhang et al. 2026) proposes weak-to-strong inference-time alignment, using the step-level signal of a weak model as MCTS guidance for a strong model. With an Entropy-Aware PUCT, a UCB refinement, it secures trajectory diversity and lifts Llama3-8B summarization quality from 1.89 to 2.19 (+15.9%). AAAI 2026 Oral.
Majority of the Bests (MoB) (Rakhsha et al. 2025) is grounded in the observation that “even if the reward model is imperfect, the most frequent mode can be trusted.” It builds bootstrap subsets from a Best-of-N (BoN) candidate set, takes the argmax of each subset, and majority-votes them. Improvements on 25/30 settings out of 5 benchmarks × 3 LLMs × 2 RMs. NeurIPS 2025 Poster.
MoB’s stance that “even if the reward is unreliable, the most frequent mode is trustworthy” is essentially the same philosophy as self-consistency in Self-Consistency and Weighted Majority Voting (X. Wang et al. 2023). The idea of using “not individual scores but the collective mode” as a signal source is spreading as a main axis of verifier-free design in tree-search reward design as well.
CMCTS (Lin et al. 2025) restricts the action space to five disjoint kinds—understanding / planning / reflection / coding / summary—and prevents non-sensical transitions through a PRM and partial-order rules. Zero-shot, a 7B model is reported to surpass a 72B baseline by an average of +4.8%. Rather than making the verifier itself lightweight, this approach reduces dependence on the PRM by tightening the search space.
Limits of PRM-Guided Search
Limits of PRM-Guided Tree Search (Cinquin et al. 2025) scrutinizes Qwen2.5-Math-7B-Instruct paired with a pure PRM on 23 math problems, and shows that PRM-guided MCTS / beam search / A* / BoN do not statistically significantly outperform BoN despite their increased compute. The causes are the following two.
- PRMs are poor approximations of the state value: reliability degrades with depth
- PRMs are weak on OOD: they systematically mis-evaluate out-of-distribution problems
This negative result is less a rejection of tree search itself than an occasion to revise blind faith in PRMs. The verifier-free lines (M. Wu et al. 2025; Rakhsha et al. 2025) and uncertainty-aware lines (Song et al. 2026; Yu et al. 2025) covered in this chapter all sit as responses to this limitation.
See also Process Reward Models for details.
Probabilistic Inference Framing
The movement to recast tree search not as “search” but as “probabilistic inference” surfaced at COLM 2025.
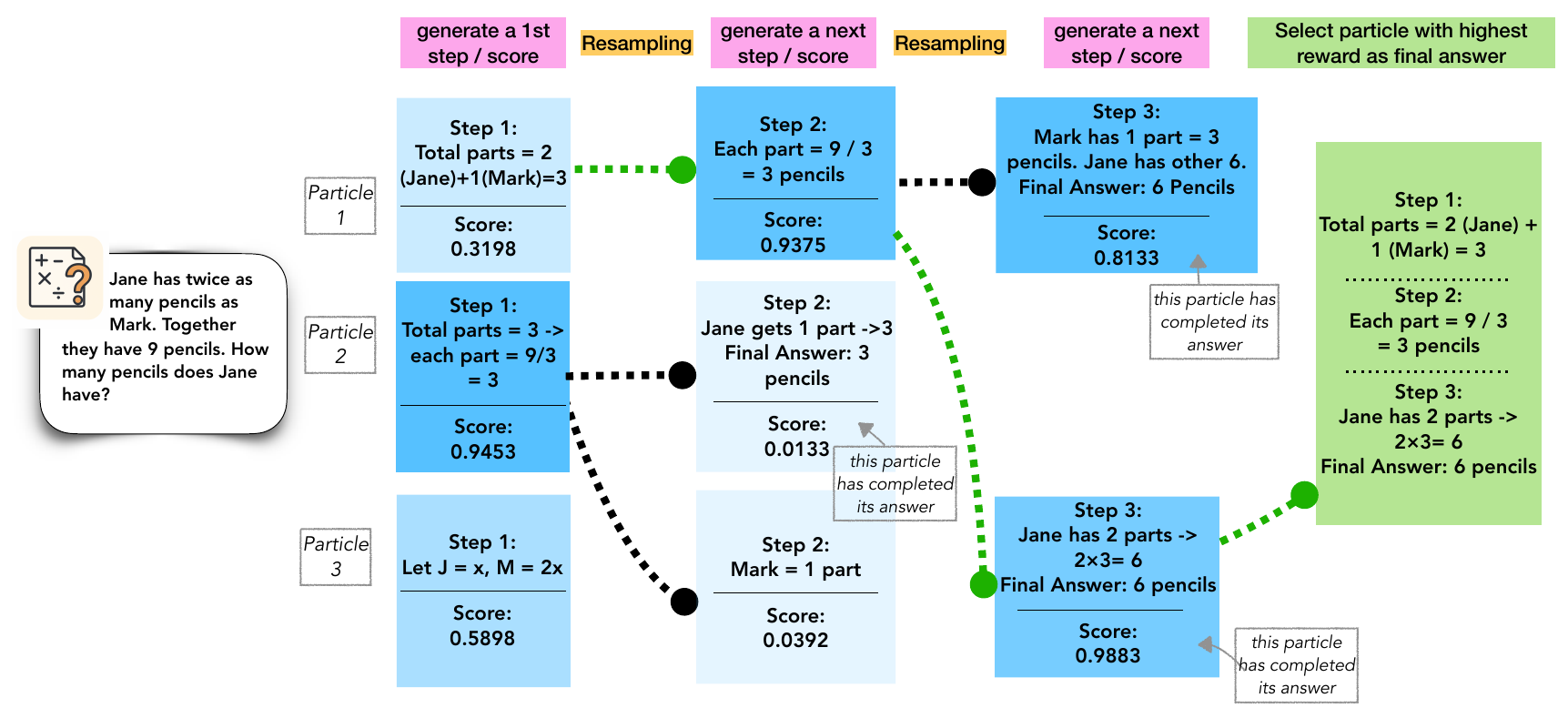
Particle-based Monte Carlo (Puri et al. 2025) views inference-time scaling as typical-set sampling of a state-space model and implements it with a particle filter (Sequential Monte Carlo, SMC). It has a side effect of avoiding reward hacking, and reports Qwen2.5-Math-1.5B surpassing GPT-4o with 4 rollouts and 7B reaching o1-class with 32 rollouts. Figure 8 visualizes each step of SMC.
PRM-guided GFlowNets (Younsi et al. 2025) automatically learns a PRM via MCTS and achieves reward-proportional diverse sampling via a GFlowNet. It complements the greediness of MCTS and raises path coverage with reward-proportional sampling. Reports generalization improvements of +2.59% on MATH Level 5 and +9.4% on SAT MATH.
From the perspective of Particle-based MC, MCTS’s operation of “rolling out and resampling by reward” corresponds to SMC’s proposal-likelihood-resample. Once tree search can be re-described as an inference algorithm, the tools of the Bayesian context (importance sampling, posterior approximation, the conflation issue between reward and likelihood) become directly applicable.
Faithfulness Warnings
A warning bell is starting to ring on whether the reasoning trace obtained from tree search really reflects “deep computation.”
An analytical paper that extracts a search tree from an LLM’s reasoning trace in the Four-in-a-row game. The findings are threefold.
- LLMs search more shallowly than humans
- Performance is predicted by breadth rather than depth
- Important: even when deep nodes are expanded in the trace, the actual move selection can be explained by a myopic model that ignores deep nodes
In other words, it has been quantitatively shown that LLMs may “pretend to do deep search while actually deciding shallowly.” This is an important observation in the lineage of the chain-of-thought faithfulness discussion (Lanham et al. 2023).
Figure 9 shows an ablation experiment that removes branches of a specific depth from the trace and feeds it back to the player.
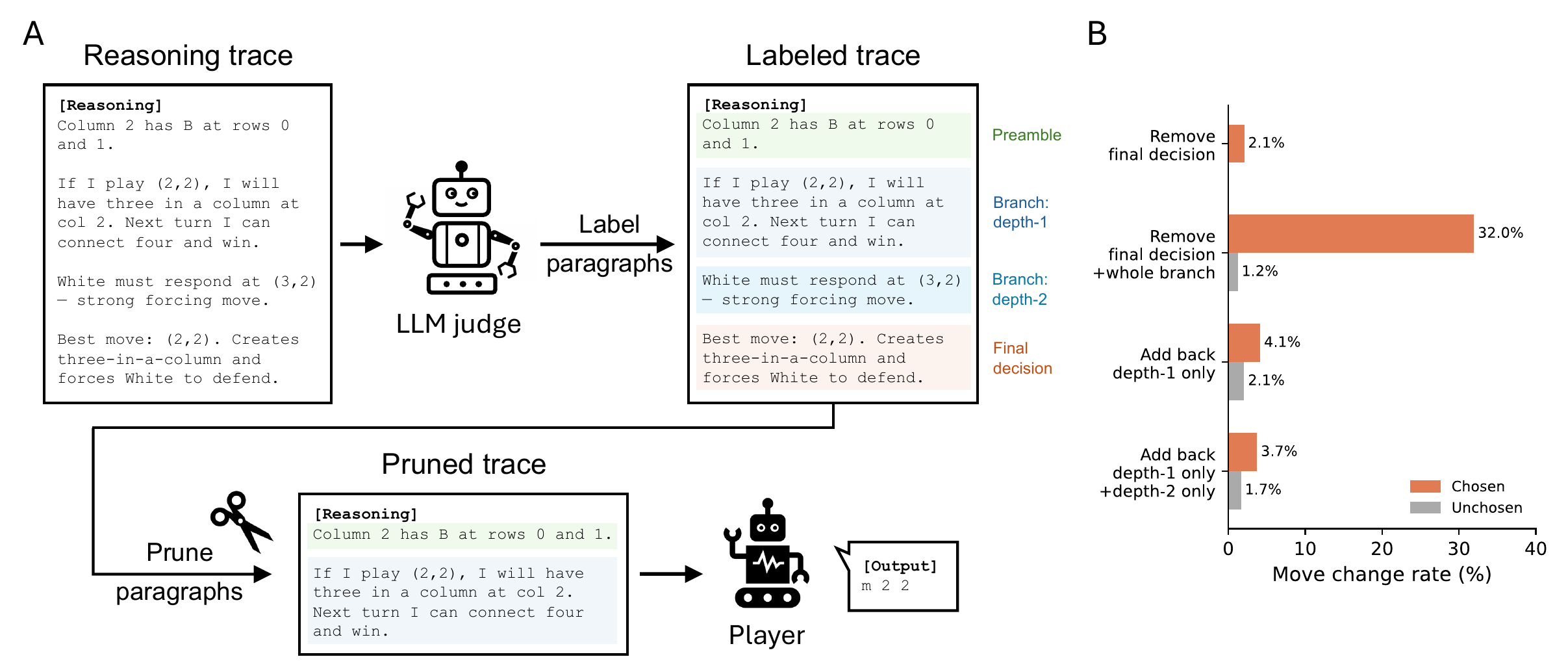
The right panel of Figure 9 is the quantitative evidence. While removing the final decision and the whole branch tied to it changes 32% of the moves, removing all depth-2 nodes while keeping only depth-1 changes the move rate by only 3.7% on the chosen branch side. That is, the LLM expands deep nodes but actually picks moves using only shallow information.
This finding implies that evaluation designs that depend on the apparent depth of tree search (designs that equate trace length or the number of expanded nodes with “amount of thought”) need to be reconsidered. The naive scaling view that “more rollouts is better” may also be invalid computation piled on top of shallow decisions.
The Lineage of Tree-of-Thoughts and Graph-of-Thoughts
Outside of pure MCTS, RL post-training of ToT, graph extensions, and a direction that analyzes existing long CoT post-hoc as a tree have also appeared.
LCoT2Tree (Jiang et al. 2025) is a framework that automatically converts long CoT into a hierarchical tree and extracts structural patterns with a Graph Neural Network (GNN). Figure 10 shows the conversion pipeline. The five stages—sketch extraction → step segmentation → assigning steps to sketch nodes → labeling each step’s function (exploration / verification / backtrack / continuation) → constructing the tree—yield a reasoning tree with node features (depth, out-degree, number of siblings) and edge features (four kinds of functions).
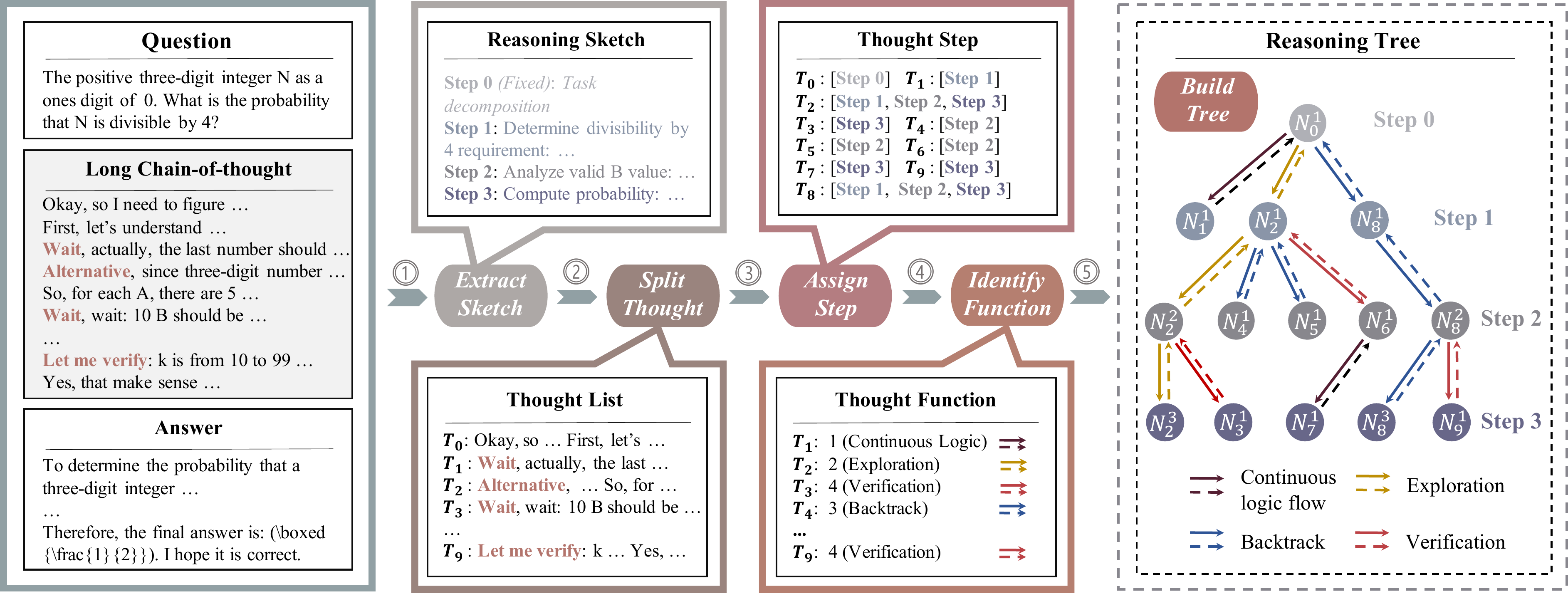
GNN-based analysis yields three observations: (1) exploration count, backtrack count, and verification count correlate strongly with answer accuracy, (2) tree-structural features predict accuracy better than simple token length, and (3) over-branching is identified as a typical failure pattern. This is a warning against the naive scaling view that “more branching is better,” and can be read as empirical support for the “branch only where the model is hesitant” designs of AB-MCTS (Inoue et al. 2025) and Entropy-Gated (X. Li et al. 2025) covered in this chapter.
ToTRL (H. Wu et al. 2025) is based on the observation that “long CoT tends to become redundant introspection and trial-and-error,” and learns ToT strategies from puzzle games via on-policy RL. ToTQwen3-8B is reported to improve both accuracy and efficiency on complex reasoning.
Adaptive Graph of Thoughts (AGoT) (Pandey et al. 2025) recursively decomposes a complex query into subproblems and builds, at test time, a dynamic directed acyclic graph (DAG) that expands only the necessary parts. It integrates the strengths of CoT / ToT / GoT and achieves +46.2% on GPQA training-free.
Forest-of-Thought (Bi et al. 2024) takes a forest structure that ensembles multiple independent ToTs, combining sparse activation for selecting relevant paths, dynamic self-correction, and consensus-guided decision. A design that balances tree-level diversity and consensus voting.
Policy Guided Tree Search (PGTS) (Y. Li 2025) is an RL-based tree search in which a learned policy dynamically selects among expand / branch / backtrack / terminate. It achieves state-of-the-art on math / logic / planning while significantly cutting cost.
Efficiency Lines
To bring the tree-search methods discussed in this chapter and the Self-Consistency lines from the previous chapter into production use, compute budget and efficiency are decisive.
FETCH (A. Wang et al. 2025) decomposes the failures of tree search into two pitfalls.
- Over-exploration: semantically equivalent states are redundantly expanded
- Under-exploration: high variance of verifier scoring causes frequent trajectory switching
As remedies, it merges equivalent states with agglomerative clustering on SimCSE embeddings, and suppresses variance with TD(λ) and a verifier ensemble. It simultaneously improved multiple tree-search algorithms on GSM8K / GSM-Plus / MATH (ACL 2025 long).
DPTS (Dynamic Parallel Tree Search) (Ding et al. 2025) decomposes the slowness of ToT into “frequent switching of reasoning focus” and “redundant suboptimal exploration,” and achieves 2–4x speedup with a Parallelism Streamline and a Search-and-Transition Mechanism. It improves throughput on Qwen-2.5 / Llama-3 while maintaining accuracy on MATH500 / GSM8K.
A*-Decoding (Chatziveroglou 2025) views language-model generation as a structural search over the state space of partial solutions and applies A*. It matches the performance of BoN and particle filtering with 1/3 the tokens and 30% fewer PRM passes, and shows an example where Llama-3.2-1B keeps up with the 70x larger Llama-3.1-70B on MATH500 / AIME24.
PRM-BAS (PRM-guided Beam Annealing Search) (Hu et al. 2025) combines an annealing schedule that shrinks beam width as the search depth grows with a PRM dense reward. It improves MathVista / MathVision / ChartQA and achieves the same quality as a large fixed beam at half the compute.
AdaSearch / AdaBeam (Quamar et al. 2025) is based on the hypothesis that “early tokens are decisive for alignment” and proposes a block-wise search that concentrates the compute budget upfront with a decaying schedule. Harmlessness +10%, sentiment +33%, math reasoning +24% (vs. BoN).
CATS (Cost-Augmented MCTS) (Z. Zhang et al. 2025) embeds explicit cost-awareness into MCTS for planning under a budget constraint, and uniformly compares DFS / BFS / MCTS / bidirectional. While a GPT-4.1 baseline fails under a tight budget, CATS balances accuracy and cost.
The main designs of the efficiency line are summarized in Table 5.
| Method | Main idea | Effect |
|---|---|---|
| FETCH (A. Wang et al. 2025) | Suppress over-exploration via semantic clustering | Simultaneously improves multiple tree searches |
| DPTS (Ding et al. 2025) | Parallel KV and transition mechanism | 2–4x speedup |
| A*-Decoding (Chatziveroglou 2025) | A* heuristic | 1/3 tokens, 30% fewer PRM passes |
| PRM-BAS (Hu et al. 2025) | Beam-width annealing | Same quality at half compute |
| AdaSearch (Quamar et al. 2025) | Concentrate budget on initial blocks | Large gains (math +24%) |
| CATS (Z. Zhang et al. 2025) | Explicit cost-awareness | Maintains accuracy under tight budget |
Extension to Self-Improvement
The movement of recycling tree-search results back into training is also notable. DeepSearch (F. Wu et al. 2025) identifies the cause of RLVR plateauing within a few thousand steps as sparse rollout exploration, and integrates MCTS into the training loop. With global frontier selection, entropy-based supervision, and a replay buffer with caching, it achieves an average accuracy of 62.95% and a 5.7x GPU-hour reduction.
Against the controversy of “can RLVR surpass the base” treated in RLVR Theory and Limits, DeepSearch shows that MCTS-augmented RLVR can break the plateau by supplying new exploration signals. Together with rStar-Math (Guan et al. 2025) covered in this chapter, it represents a direction that blurs the boundary between test-time search and training-time exploration.
Chapter Summary
Tree-search research in 2025–2026 advanced along five main axes.
- Skepticism toward PRMs drove the verifier-free / uncertainty-aware lines: starting from Limits of PRM-Guided (Cinquin et al. 2025), SELT (M. Wu et al. 2025), MoB (Rakhsha et al. 2025), UATS (Song et al. 2026), and UVM (Yu et al. 2025) independently presented designs that “reduce dependence on external verifiers”
- Dynamic control of wider vs deeper became standard: the Thompson sampling framework of AB-MCTS (Inoue et al. 2025) directly propagated into the subsequent uncertainty-based methods (Song et al. 2026; Yu et al. 2025)
- Verification granularity was organized as a continuous spectrum: VG-Search (H. M. Chen et al. 2025) connected beam search and Best-of-N through granularity \(g\) and showed that the optimal granularity varies with task, budget, and model
- Entropy-based branching spread: Entropy-Gated Branching (X. Li et al. 2025) and MITS (J. Li et al. 2025) established the design of “branching only at hesitant steps,” and LCoT2Tree (Jiang et al. 2025) provided empirical support by identifying over-branching as a failure pattern via GNN analysis
- Faithfulness warnings accumulated: from Lanham et al.’s Early Answering (Lanham et al. 2023) to Extracting Search Trees (S. Chen et al. 2026), observations that “the deep traces shown by LLMs can be explained by myopic decisions” and that “answers do not change much when the CoT is cut midway” urge a reconsideration of evaluation designs that naively read trace length or expansion count as “amount of thought”
In parallel, the movement to recast tree search as probabilistic inference (Puri et al. 2025) and the movement to embed it into self-improvement (Guan et al. 2025; F. Wu et al. 2025) are also accelerating. The three axes “Search Mechanism × Reward Formulation × Transition Function” shown by the survey (Wei et al. 2025) remain effective as a framework for coherently surveying the close-to-30 papers covered in this chapter.
See Process Reward Models for discussions of the PRM line, Self-Consistency and Weighted Majority Voting for self-consistency and verifier-free voting, and Test-Time Compute Scaling for the topic of compute-budget allocation.