Reasoning in Diffusion LLMs
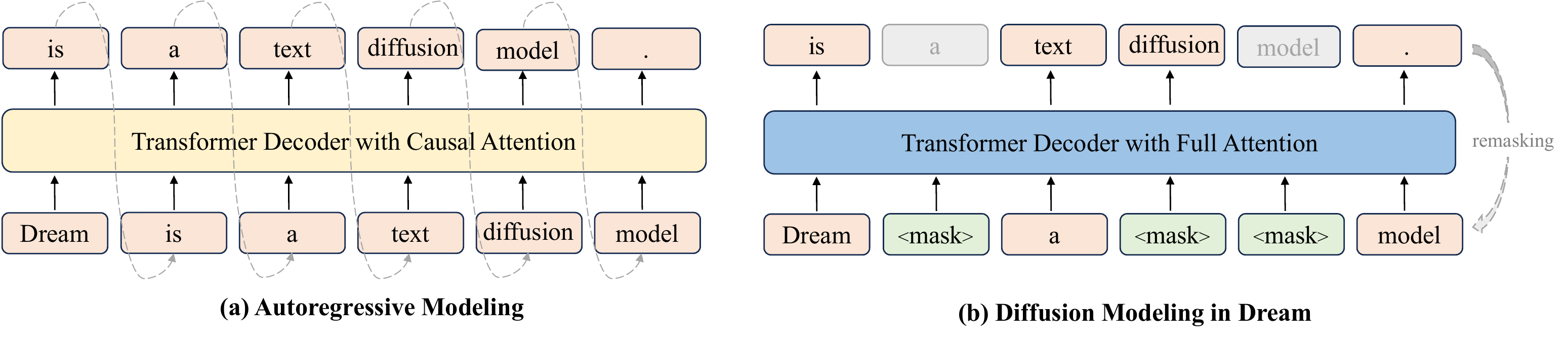
This chapter covers reasoning in masked diffusion-based large language models, also known as Diffusion Large Language Models (DLLMs). Whereas Autoregressive (AR) models generate sequences left-to-right in a single direction, DLLMs unmask in parallel from a fully masked sequence, so the generation order and the treatment of intermediate states differ fundamentally (Figure 1). The “inference-side signals” such as self-consistency and confidence covered in earlier chapters of this book have been developed under the AR assumption, but during 2025–2026 several methods derived from similar motivations have appeared independently for DLLMs as well.
This book focuses on reasoning in DLLMs. For the broader theoretical foundations, training methods, and derivative models of DLLMs, see the separate book Diffusion Language Models. Coverage of the underlying foundation models is kept minimal in this chapter.
Foundational DLLMs
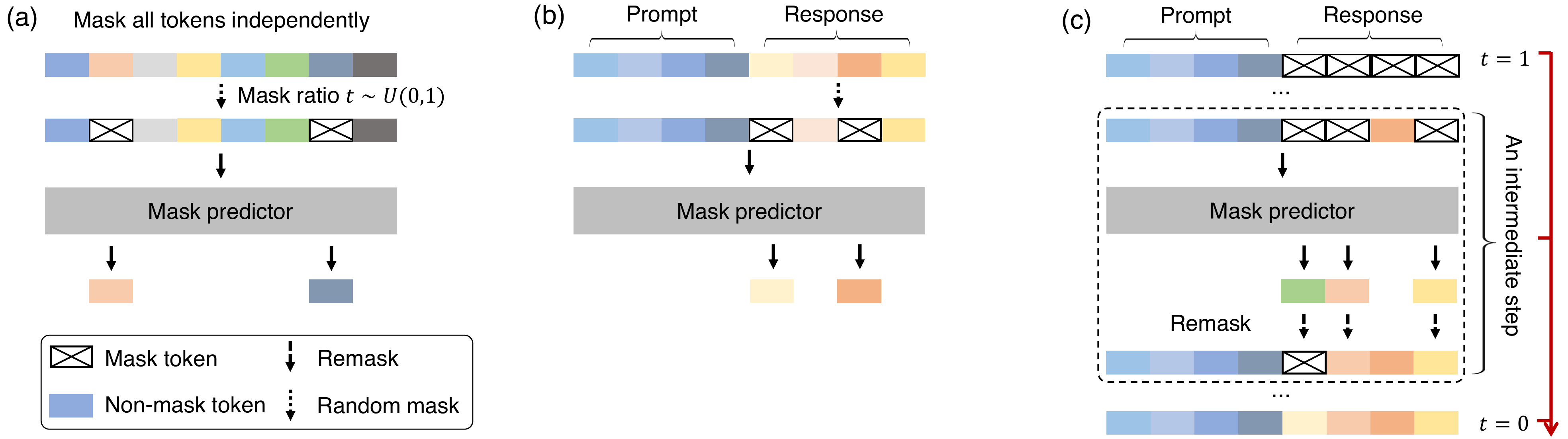
The starting point of DLLMs is the formulation of absorbing-state discrete diffusion in the Masked Diffusion Language Model (MDLM) (Sahoo et al. 2024). Figure 2 takes LLaDA as an example of a masked diffusion LM and shows (a) the forward process (random masking at ratio \(t \sim U(0,1)\)), (b) prompt-conditional mask-predictor training, and (c) the denoising trajectory at inference (gradually approaching the answer while remasking at intermediate steps). Several DLLMs reaching the 7B–8B scale have since appeared and serve as the experimental basis for reasoning research.
- LLaDA (Nie et al. 2025): The first DLLM at the 8B scale to achieve in-context learning performance on par with AR LLaMA3 8B. It adopts the standard masked diffusion design with a forward process that progressively masks tokens and a Transformer-based reverse denoising, and is distributed with open weights. It is the de facto base model for subsequent DLLM-RL research.
- Dream 7B (Ye et al. 2025): An open DLLM trained from an AR LLM initialization with context-adaptive noise rescheduling. It emphasizes arbitrary-order generation and infilling along with quality-speed tunability, and outperforms LLaDA on math/code and planning.
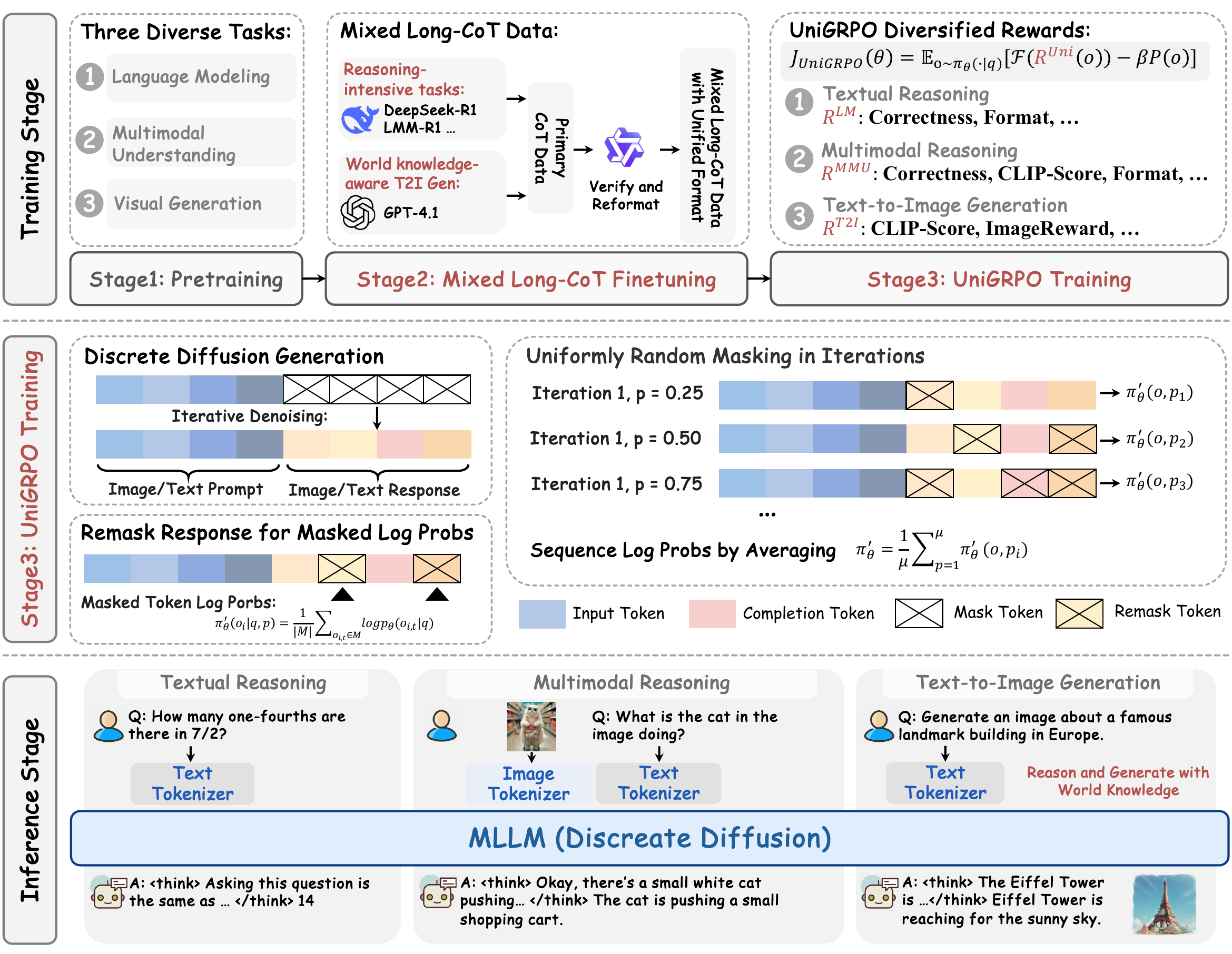
- MMaDA (L. Yang et al. 2025): A multimodal DLLM that integrates textual reasoning, multimodal understanding, and text-to-image generation into a single diffusion foundation model. As shown in Figure 3, it combines SFT on mixed long-CoT data with UniGRPO (unified cross-modality RL), and generates both text and images at inference through a single masked diffusion.
For commercial / large-scale industry use, Mercury (Inception Labs et al. 2025) (Inception Labs) and Seed Diffusion (ByteDance Seed et al. 2025) (ByteDance) have appeared and reached positions competitive with AR on the speed-quality Pareto frontier. Block diffusion (Arriola et al. 2025), which sits between AR and DLLM, is a hybrid design with intra-block diffusion and inter-block AR, continuously interpolating between AR and DLLM.
Against the problem that AR models are weak at planning, an observation that “discrete diffusion learns difficult subgoals better than AR” was reported in (Ye, Gao, et al. 2024). The strong results of 91.5% on Countdown and 100% on Sudoku (versus 45.8% and 20.7% for AR under the same conditions) suggest there are structural reasons why diffusion may be suited to reasoning (parallel prediction, flexibility in unmask order, and bidirectional context).
Inference-Time Techniques Specific to DLLMs
A motif similar to AR self-consistency and prefix-confidence — “aggregating intermediate states to predict the answer” — has been independently proposed for the denoising trajectory of DLLMs. The common core observation is that on the DLLM denoising trajectory, the answer is internally determined well before the final step. Table 1 summarizes the positioning of each method.
| Method | Operation | Time axis | Aggregation |
|---|---|---|---|
| Prophet | Early-stop and decode in bulk | Denoising step | Top-2 gap monitoring on a single trajectory |
| Time-is-a-Feature | Aggregate predictions of intermediate steps | Denoising step | Majority vote across steps of the same trajectory |
| I-DLM | Re-verify previous tokens within a single forward | Within a forward pass | Rejection sampling via self-verify |
Detecting When the Answer Is Fixed Within a Trajectory
Prophet (Li et al. 2025) observed in the DLLM denoising process that “the final answer is internally already determined by about halfway through refinement”, measuring this for 97% of GSM8K instances and 99% of MMLU instances. Concretely, it is a training-free scheme that decodes all remaining mask tokens in bulk once the confidence gap of the top-2 candidates exceeds a fixed threshold, achieving 3.4x speedup (Figure 4).
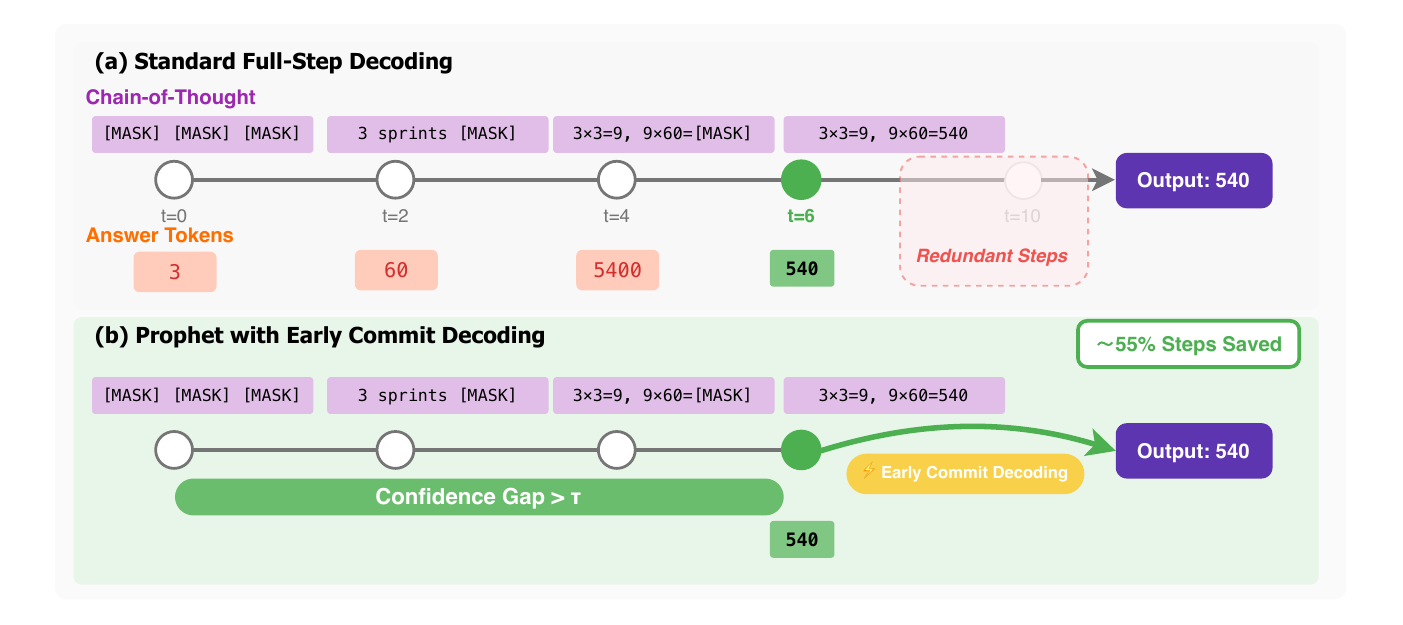
This observation completely parallels the way prefix-consistency-style methods in AR (see Self-Consistency and Weighted Majority Voting) exploit the fact that “the answer is determined partway through”. In AR the prefix length serves as the time axis, whereas in DLLMs the number of denoising steps serves as the time axis.
Self-Consistency by Aggregating Intermediate Steps
Time-is-a-Feature (W. Wang et al. 2025) observed the temporal oscillation phenomenon that “a correct answer surfaces once during denoising and is then overwritten later”, and proposed Temporal Self-Consistency Voting which aggregates predictions across intermediate steps (Figure 5). Furthermore, by post-training with Temporal Semantic Entropy (TSE) as a reward, it gains +24.7% on Countdown, +2.0% on GSM8K, and +4.3% on MATH500.
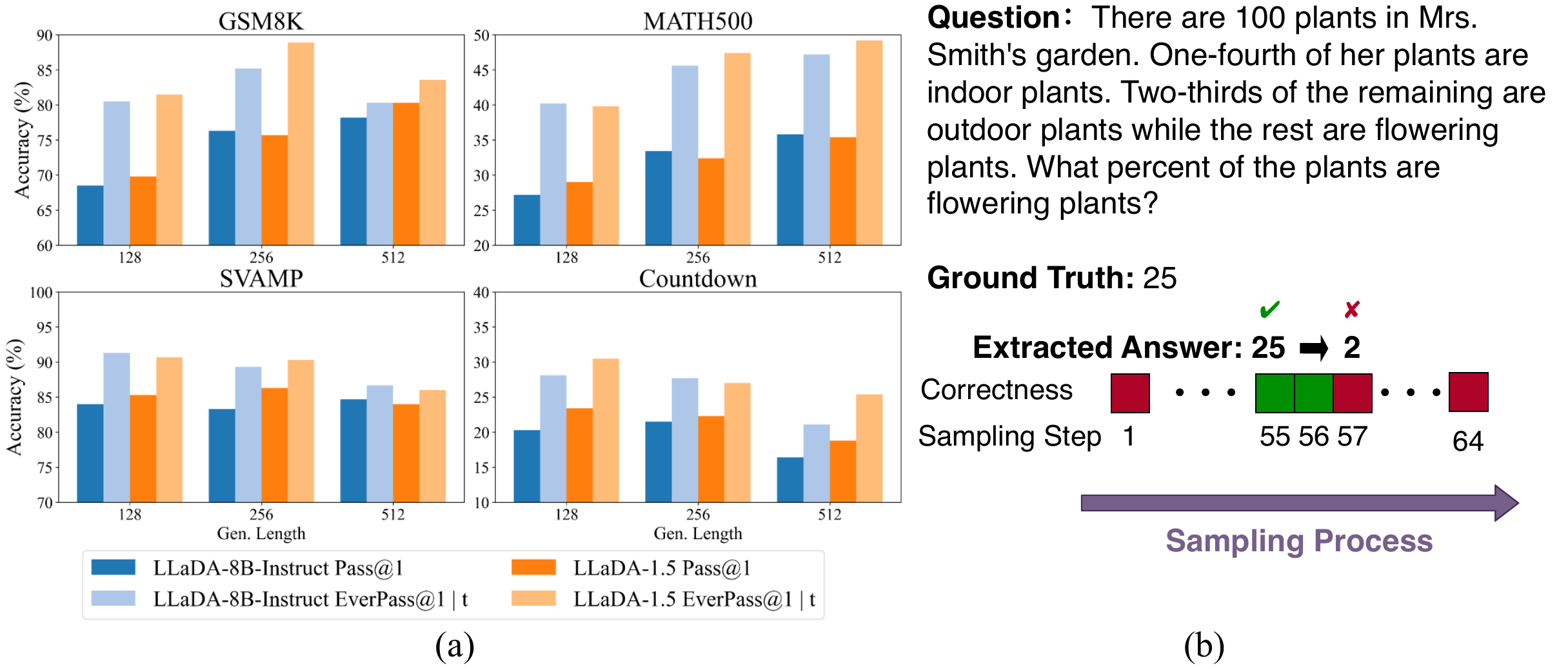
Whereas AR self-consistency runs multiple samples independently in parallel and takes a majority vote, this method treats different denoising steps on the same trajectory as samples, a different choice of time axis. Since the sampling cost is just a single denoising pass, it can be dramatically cheaper than AR self-consistency.
Self-Verify Within a Single Forward Pass
Introspective Diffusion Language Models (I-DLM) (Yu et al. 2026) identifies the lack of the AR property (consistency with one’s own past generations) as the main cause of the quality gap in DLLMs, and proposes Introspective Strided Decoding (ISD). The design advances new tokens while verifying previous tokens within the same forward pass, and an acceptance rule theoretically guarantees equivalence with the AR distribution. It achieves 69.6 on AIME-24 and 45.7 on LiveCodeBench, substantially surpassing LLaDA-2.1-mini while delivering 2.9–4.1x speedup relative to AR (Figure 6).
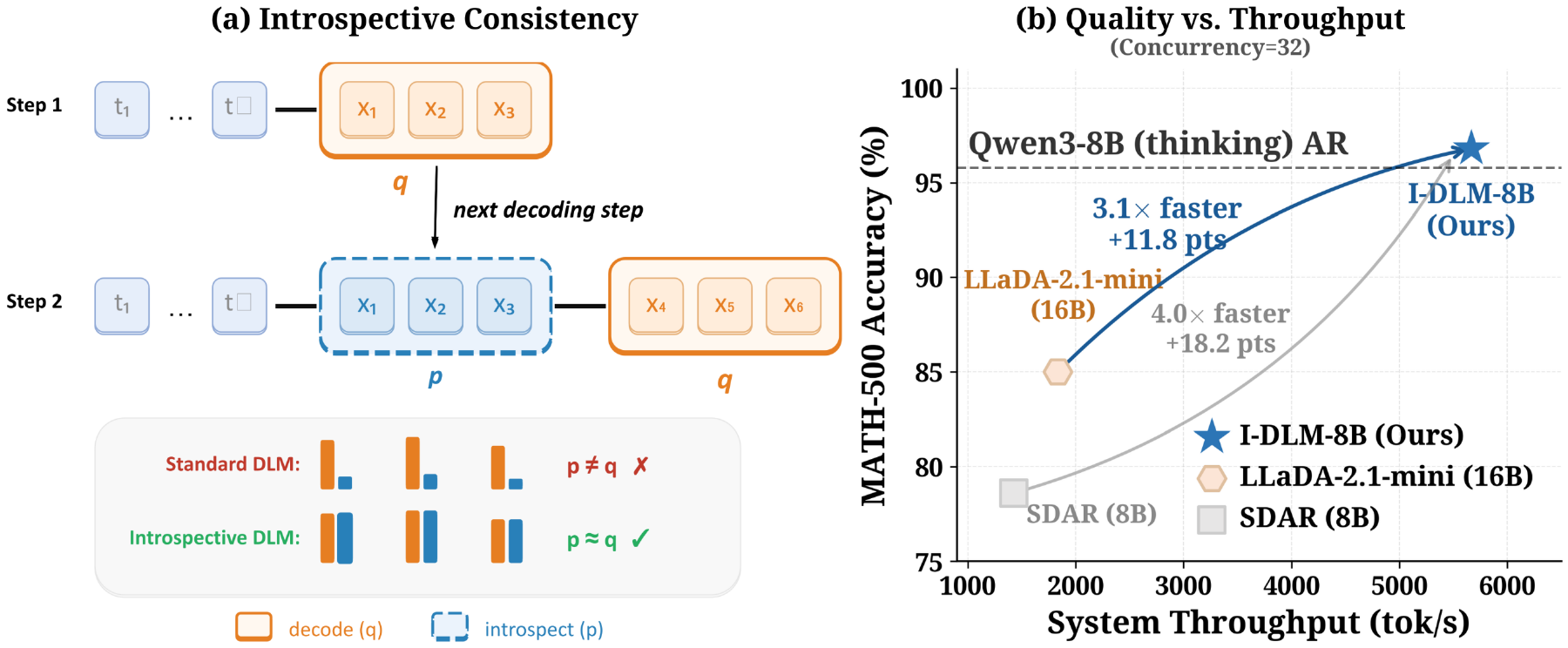
Rather than maintaining multiple trajectories externally, this design embeds self-verification within a single forward, with motivations close to speculative decoding and self-verification in AR.
Choice of Unmask Order
The essential degree of freedom of DLLMs lies in “in what order to fill the masks”. While AR is fixed left-to-right, DLLMs can unmask in arbitrary order, so how to determine this schedule becomes a major axis for test-time scaling.
The representative choices are summarized below.
- Confidence-based unmasking: A standard scheme that unmasks tokens in ascending order of model prediction entropy. Simple, but it triggers the flexibility trap discussed later.
- Block scheduling: Splits the sequence into blocks and proceeds block by block. Block size functions as a degree of freedom interpolating between AR and parallel diffusion (Arriola et al. 2025).
- Wavefront ordering (H. Yang et al. 2025): Unmasks following a “wavefront” that spreads outward from already-determined tokens. It avoids the premature EOS of global denoising and the semantic-unit fragmentation of block denoising, achieving SOTA on reasoning and code generation.
- Order search via tree search (Zheng Huang et al. 2025): Treats the unmask trajectory as a combinatorial search space and uses Monte Carlo Tree Search (MCTS) to guide early-stage trajectories with an information-gain reward, switching to a heuristic later on.
Using Schedule Multiplicity for Ensembling
HEX (Lee et al. 2025) shows that DLLMs implicitly learn a “mixture of semi-AR experts corresponding to different block schedules”, and observes that committing to a fixed schedule causes performance to collapse. The proposed method is a training-free scheme that generates with multiple schedules and takes a majority vote, reaching 88.10% on math reasoning.
Whereas AR self-consistency is a majority vote across trajectories from different sampling seeds, HEX is a majority vote across trajectories from different schedules, and its ensembling axis is orthogonal. Combining the two could yield bidirectional test-time scaling.
The Flexibility Trap and Confusion Zones
The order flexibility of DLLMs does not unconditionally improve reasoning; rather, several independent reports in 2025–2026 have identified pitfalls.
(Ni et al. 2026) reported the counterintuitive observation that “arbitrary-order generation narrows the reasoning boundary”. MDLMs, via confidence-based unmasking, tend to defer high-entropy tokens (logical connectors such as therefore, because, and so), which inhibits exploration at branching points. The fact that restricting to AR order expands the solution space suggests that AR’s fixed order may have functioned as an inductive bias for learning logical chains.
Relatedly, Confusion Zones (Chen et al. 2025) discovered “zones of confusion” on the DLLM trajectory where entropy spikes or sudden changes in confidence margin occur, and showed that these few steps strongly predict final accuracy. Adaptive Trajectory Policy Optimization (ATPO) improves performance without additional reward or compute by concentrating policy gradients on those steps.
These observations are consistent with other chapters of this book.
- The structure where high-entropy positions are branching points is the same “localization of important decision points” phenomenon as in the prefix-consensus methods covered in Self-Consistency and Weighted Majority Voting.
- The point that “the ability to overturn an early commit later” is needed is implemented by RemeDi (Huang et al. 2025) via self-reflective remasking (re-masking once-unmasked tokens based on per-token confidence), which substantially improves reasoning performance.
RL on DLLMs: Strengthening Reasoning via Post-Training
The line of work that strengthens DLLM reasoning from the training side, not just via inference-time techniques, is also maturing rapidly. Updates continue at a semiannual pace.
- d1 (S. Zhao et al. 2025): Applies SFT and a new RL algorithm
diffu-GRPOto a pretrained masked DLLM. It approximates the sequence likelihood with a mean-field approximation and regularizes with random prompt masking. Achieves a large boost over LLaDA-8B-Instruct on GSM8K and MATH500. - DCoLT (Zemin Huang et al. 2025): Treats each reverse diffusion step as a “thinking action” and optimizes the entire trajectory with outcome-based RL. Unlike linear/causal CoT, bidirectional lateral thinking is permitted at intermediate steps. When applied to LLaDA, it gains +9.8% on GSM8K, +5.7% on MATH, +11.4% on MBPP, and +19.5% on HumanEval.
- d2 (G. Wang et al. 2025): A successor to d1. It proposes d2-AnyOrder, which estimates the trajectory likelihood exactly with a single model pass, and an approximate version d2-StepMerge. It surpasses d1 on Countdown, Sudoku, GSM8K, and MATH500 without SFT, showing that the accuracy of likelihood estimation dominates RL performance.
- DiFFPO (H. Zhao et al. 2025): A framework that unifies RL for DLLMs. It trains a surrogate policy with off-policy RL and improves accuracy with two-stage likelihood approximation and importance sampling correction. It further enables joint training of the sampler and controller to dynamically determine the inference threshold per prompt.
The problem motivation of AR-oriented RLVR covered in Theory and Limits of RLVR (re-weighting of the base distribution versus acquisition of new abilities) can be discussed in the same form for DLLMs. The fact that trajectory-level credit assignment is more naturally defined than in AR is a structural advantage of DLLMs, but as observed in d2, the accuracy of likelihood estimation becomes the bottleneck.
Comparison and Connection with AR
Lining up DLLM reasoning characteristics against AR yields the correspondences shown in Table 2.
| Aspect | AR (auto-regressive) | DLLM (masked diffusion) |
|---|---|---|
| Generation order | Fixed left-to-right | Free unmask order |
| Intermediate state | Prefix (sequence of fixed left tokens) | Partial mask state (set of fixed tokens at arbitrary positions) |
| Early signal | Prefix consistency, prefix confidence | Answer convergence within trajectory (Prophet) |
| Ensembling axis | Independent samples (Self-Consistency) | Denoising step (Time-is-a-Feature), schedule (HEX) |
| Self-verify | Speculative decoding, internal consistency | Self-verify within a single forward (I-DLM) |
| Branching point | Step containing a logical connector | High-entropy position, confusion zone |
| Test-time RL | GRPO / DAPO family | diffu-GRPO (d1), DCoLT, d2, DiFFPO |
The two are structurally different but share the common problem motivation that runs through this book: “aggregate intermediate states to predict the answer”. Translating methods developed for AR onto DLLM denoising steps or schedules may yield new test-time scaling axes. Indeed, hybrid designs such as block diffusion (Arriola et al. 2025) could serve as the substrate for gradually bridging AR and DLLM methods.
Chapter Summary
DLLM reasoning has a different structure from AR reasoning, but its correspondence with the problem motivations running through this book is clear.
- Independent discoveries of the early-convergence phenomenon: Prophet, Time-is-a-Feature, and I-DLM are all separate teams that observed the phenomenon “the answer is determined at an intermediate state of the DLLM”, and each uses it for inference efficiency or quality improvement. They extract the same “intermediate-state signal” as in AR prefix-consistency methods, but on the time axis of denoising steps.
- The freedom of unmask order as a new test-time scaling axis: HEX, MEDAL, and WavefrontDiffusion exploit schedule diversity as a new ensembling axis. It is orthogonal to the sample-axis ensembling of AR, leaving considerable room for combination.
- Pitfalls of arbitrary order: Flexibility Trap and Confusion Zones show that the order flexibility of DLLMs is not necessarily advantageous for reasoning. AR’s fixed order may have functioned as an inductive bias for learning logical chains, and methods that preserve “AR-like prefix structure” may also be valuable on DLLMs.
- Rapid maturation of DLLM-oriented RL: With d1 → DCoLT → d2 → DiFFPO → ATPO updating at a semiannual pace, the field is approaching a level comparable to RLVR for AR. The more natural definition of trajectory-level credit assignment than in AR is a structural advantage, but the accuracy of likelihood estimation is the current bottleneck.
DLLM reasoning adds a parallel axis to the research landscape that had been dominated by AR, providing an opportunity to revisit the methods covered in each chapter of this book through the unified perspective of “how to define and aggregate intermediate states”. If hybrid designs such as block diffusion become widespread, AR and DLLM methods are likely to be connected continuously at the implementation level.