GRPO and Reward Design
Since the appearance of DeepSeek-R1 (Guo et al. 2025), Group Relative Policy Optimization (GRPO) (Z. Shao et al. 2024) has rapidly spread as the de facto standard algorithm for Reinforcement Learning with Verifiable Rewards (RLVR). This chapter first organizes GRPO itself and the major derivatives that emerged in 2025–2026 (DAPO, Dr. GRPO, GSPO, VAPO, REINFORCE++), and then addresses the question “is outcome reward alone enough?” through dense / process reward responses, particularly the line of work that repurposes the model’s own consistency or confidence as reward. Finally, we take up the fundamental skepticism posed by the “spurious reward phenomenon,” in which performance improves even with random reward.
GRPO and Its Derivatives
GRPO removes the value network (critic) from Proximal Policy Optimization (PPO) and uses a group-relative advantage in which the \(G\) samples drawn from the same prompt serve as baselines for one another. The structural difference from PPO is clear in Figure 1: whereas PPO maintains four models (policy, reward, reference, value), GRPO discards the value model and forms the advantage by normalizing, via group computation, the rewards of \(G\) rollouts \(\{o_1, \dots, o_G\}\) obtained from the same prompt \(q\).
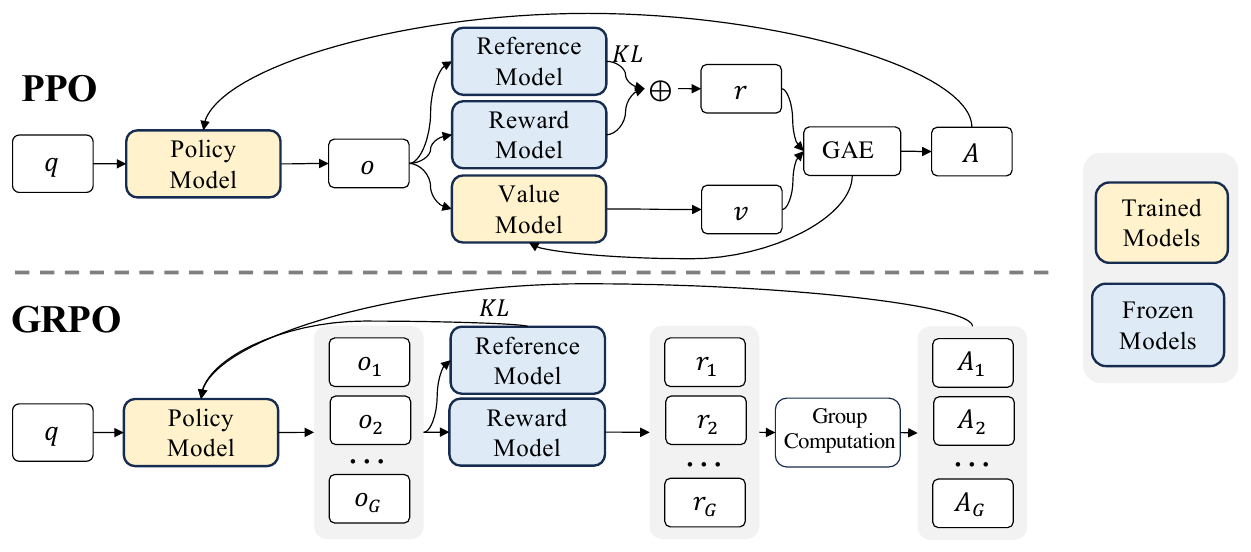
Formally, given rollouts \(\{o_1, \dots, o_G\}\) and outcome rewards \(\{r_1, \dots, r_G\}\) for a prompt \(q\), the advantage of each sample is defined by group-internal normalization as
\[ \hat{A}_i = \frac{r_i - \mathrm{mean}(\{r_j\})}{\mathrm{std}(\{r_j\})} \]
and is shared across all tokens. The fact that no critic needs to be trained is a major advantage for large-scale LLMs.
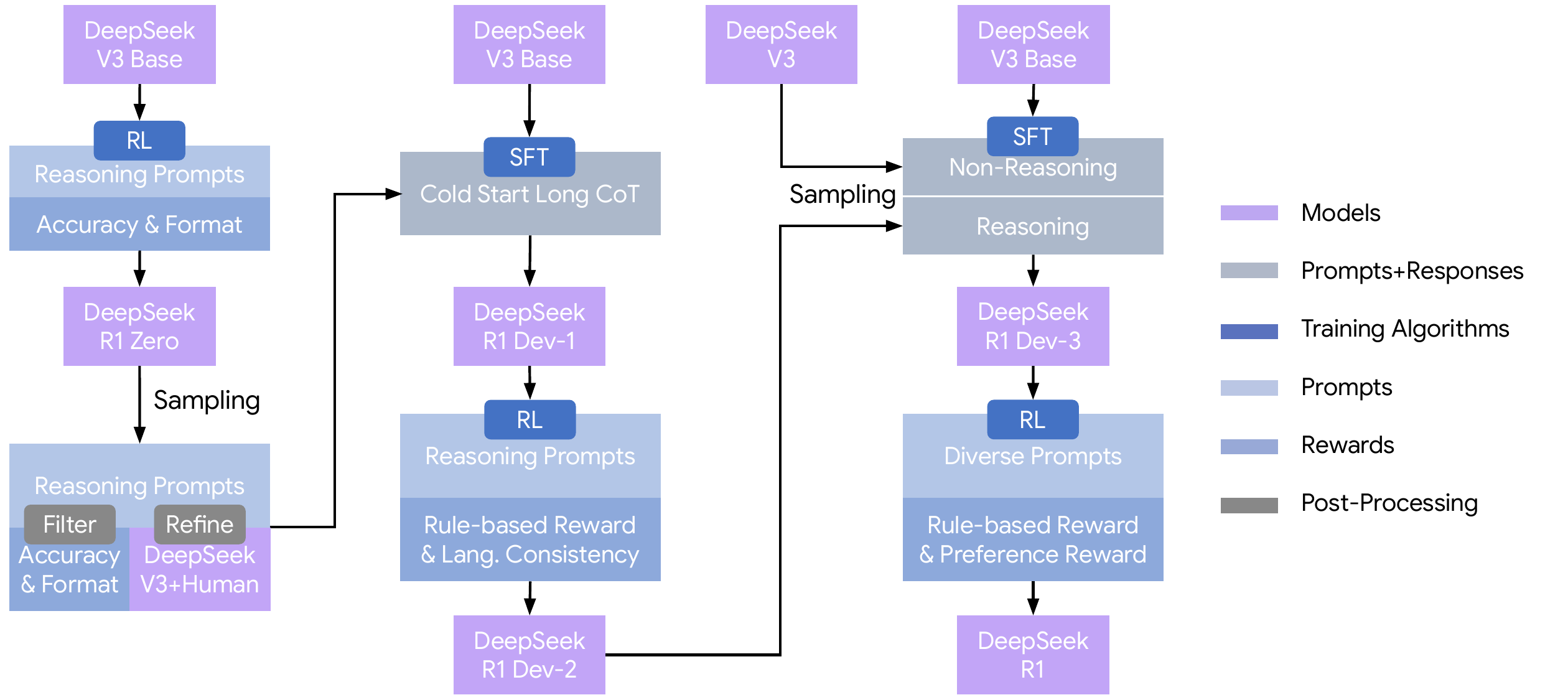
DeepSeek-R1 was built with a multi-stage pipeline centered on this GRPO (Figure 2). Starting from the base model, R1-Zero is first produced by pure RL alone; cold-start CoT is then sampled from it, and RL is run again. For reasoning prompts, accuracy + format reward is used, and the second stage for generalization combines rule-based reward with preference reward. Much of the subsequent research is positioned as an improvement of some part of this pipeline.
2025 was the year when derivatives of this basic form appeared in rapid succession.
- DAPO(Q. Yu et al. 2025): A production-scale GRPO implementation released by ByteDance Seed. It improves four points: Clip-Higher for suppressing entropy collapse, Dynamic Sampling for avoiding gradient-signal depletion, Token-level Policy Gradient Loss, and Overlong Reward Shaping. On AIME 2024 it surpassed DeepSeek-R1-Zero-Qwen-32B in half the steps and fully released both data and code
- Dr. GRPO(Liu et al. 2025): Points out two biases hidden in GRPO’s advantage computation. One is the Response Length Bias stemming from sequence-length normalization (longer wrong answers receive lighter penalties), and the other is the Question-Level Difficulty Bias stemming from dividing by the standard deviation (problems with small std are over-weighted). It proposes a prescription that eliminates both
- GSPO(Zheng et al. 2025): Discards the token-level importance ratio and performs clipping/optimization with sequence-level likelihood ratios. It resolves the instability that had become apparent in RL for Mixture-of-Experts (MoE) models and was used in practice in the Qwen3 training stack
- VAPO(Yu Yue et al. 2025): In contrast to the critic-free line of the GRPO family, it improves the value-based PPO line with seven modifications. It achieved AIME 2024 = 60.4 on Qwen2.5-32B and is characterized by zero crashes across multiple runs over 5000 steps
- REINFORCE++(Hu et al. 2025): Points out that the prompt-local advantage normalization of GRPO/RLOO is biased and changes it to normalize the advantage over the entire global batch. It handles complex reasoning while remaining critic-free
These can be positioned along three axes: “with or without a critic,” “normalization closed within the prompt or global,” and “importance ratio at token unit or sequence unit.”
DAPO raises the floor of vanilla GRPO with the four modifications above and showed the result of surpassing DeepSeek-R1-Zero-Qwen-32B on AIME 2024 in half the training steps (Figure 3). Three curves — avg@32 / pass@32 / cons@32 — are plotted simultaneously, and the fact that pass@32 rises to near saturation early on while avg@32 catches up later succinctly expresses the typical behavior of reasoning RL.
Dr. GRPO, in a different direction, modifies GRPO’s advantage formula itself. As shown on the left of Figure 4, vanilla GRPO multiplies the advantage by the response-length term \(1/|o_i|\) and the per-problem term \(1/\mathrm{std}(\mathbf{R})\), which produces the biases of “lighter punishment for longer wrong answers” and “extreme easy/hard problems being overvalued.” Dr. GRPO removes both, and as the right side of the figure shows, for the same training reward the output length is kept shorter, demonstrating a clear advantage in the sense of token efficiency.

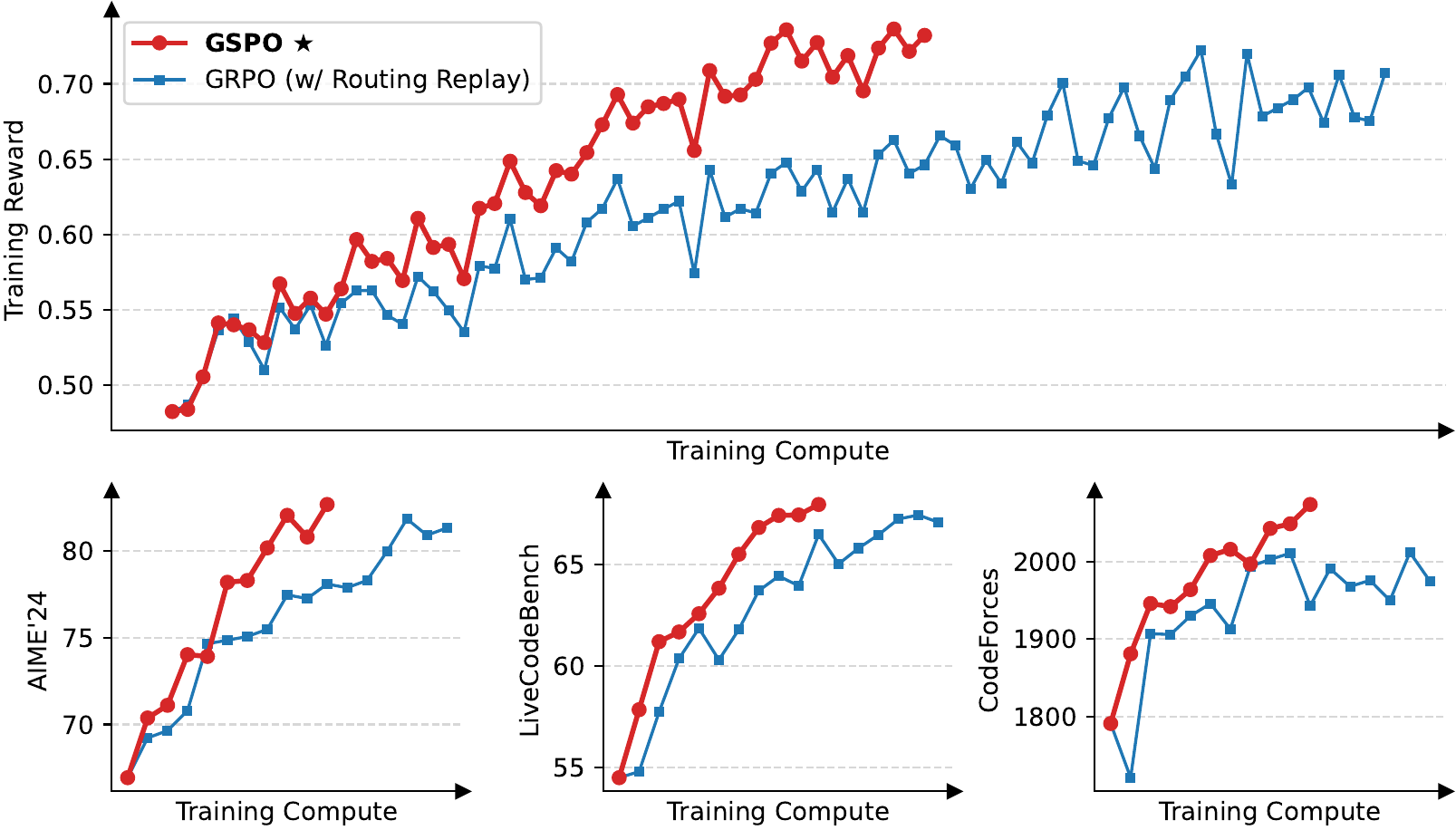
GSPO stabilizes training, especially for MoE models, by moving the unit of the importance ratio from token to sequence. As shown in Figure 5, the growth of training reward per unit of compute is consistently and stably larger for GSPO, and across the three benchmarks AIME’24 / LiveCodeBench / CodeForces it consistently outperforms GRPO + routing replay.
As of 2026, vanilla GRPO is already an old baseline, and it is common for new studies to assume some combination of derivatives.
From Outcome Reward to Process Reward
In parallel with the development of GRPO-family algorithms, research that increases the information content of the reward signal itself exploded.
- Outcome reward: Reward based only on whether the final answer is correct (a binary, or task completion degree). The standard form of RLVR
- Process reward: Reward given to each step of reasoning. It complements sparse outcome reward and localizes credit assignment
Obtaining process reward normally required step-level human annotation and was expensive. The main trend in 2025 concentrated on “how to construct process reward without human labels.”
The Discovery of Implicit Process Reward
PRIME(Cui et al. 2026) is a framework that online-estimates an implicit process reward from only the policy’s rollouts and outcome labels. It requires no explicit step annotations and works on top of any backbone among PPO / GRPO / RLOO / REINFORCE. Qwen2.5-Math-7B-Base + PRIME (= Eurus-2-7B-PRIME) surpassed Qwen2.5-Math-7B-Instruct with only 10% of the data.
A theoretical discovery that is two sides of the same coin is GRPO is Secretly a PRM(Sullivan and Koller 2025). They showed that GRPO with outcome reward is in fact equivalent to a Monte Carlo–based PRM-aware RL objective. When rollouts that share the same prefix exist within a group, a structure appears in which outcome reward is automatically converted to a process reward per sub-trajectory. This is a result that backs up, from the theoretical side, the legitimacy of “explicitly introducing process reward.”
VinePPO(Kazemnejad et al. 2025) points out that PPO’s value network fails to value intermediate states and directly estimates the value by independently running MC rollouts from each intermediate state. The idea of reinterpreting implicit reward as “the success rate of resampling from the prefix” is mechanically close to PRIME.
Consistency-Based / Self-Rewarding Rewards
The line of work that “extracts reward from the policy’s own behavior without using an external verifier” surged from late 2025 through 2026. The ideas are broadly split into two.
The first is the family that uses token / sample level confidence or entropy as reward.
- Intuitor(X. Zhao et al. 2026): Completely abolishes external reward and injects the model’s own self-certainty (logit entropy) into GRPO as the sole reward signal. It showed math performance comparable to supervised methods and out-of-distribution generalization to code generation
- LaSeR(Yang et al. 2026): Shows that the true reasoning reward can be directly estimated from the log-prob when a pre-specified token is inserted as the final token of the solution. No separate verifier needs to be called, and the self-rewarding score is co-trained inside RLVR, aligned with the verified reward
- Reasoning with Exploration(Cheng et al. 2026): Exploits the fact that token-level entropy correlates with pivotal tokens (logical branch points), self-verification tokens, and rare actions, and adds entropy as a shaping term for the advantage
The second is the family that turns the agreement between trajectories or between prefixes into reward.
- TTRL(Zuo et al. 2025): Creates pseudo-labels by majority voting for unlabeled test data and runs GRPO. Qwen-2.5-Math-7B’s AIME 2024 pass@1 improved by +211%. On the other hand, it has been reported that continued training falls into mode collapse due to overconfidence
- CoVo(Zhang et al. 2025): Aggregates, in vector space, how multiple reasoning trajectories at intermediate states “converge on the final answer (consistency) and do not waver toward other candidates (volatility),” and converts this into an intrinsic reward
- SCS(Jiahao Wang et al. 2025): Adds visual perturbations to the input image, applies truncation + resampling to the reasoning chain, and measures the agreement of the resulting answers. The obtained differentiable consistency score is used to down-weight each trace in policy update. +7.7pp in multimodal
- RESTRAIN(Z. Yu et al. 2025): To address the problem that TTRL relies excessively on majority voting and is fooled by spurious votes, it introduces self-penalization that looks at the model’s entire answer distribution and punishes “overconfident rollouts” and “low-consistency examples”
- COMPASS(Xing et al. 2025): A two-stage construction that creates pseudo-labels with Dual-Calibration Answer Reward and directly optimizes the quality of the reasoning path itself with Decisive Path Reward
The philosophy common to all of these is “make the policy’s own internal state the reward source.” While this avoids the collection cost and domain dependence of external verifiers, it carries the risk that systematic biases of the policy are directly mixed into the reward.
Rescuing the Negative Group
GRPO carries the negative group problem: when everyone in a group answers incorrectly, the variance of the advantage vanishes and the gradient becomes zero.
LENS(Feng et al. 2025) addresses this problem by extending the reward function to “a negative value depending on confidence.” It is a policy-gradient correction from the MLE perspective that punishes overconfident wrong answers more heavily, extracting an informative learning signal even from groups of wrong answers.
Prefix-Based Reward
The idea of “asking the model itself about the reasoning quality of intermediate states” has appeared independently in multiple papers as reward design based on prefixes.
GRPO-VPS(Jingyi Wang et al. 2026) probes the “conditional probability of the correct answer” per segment as the model advances its reasoning and adds the increment as a segment-wise process reward to the GRPO advantage. With no critic and no additional rollouts (only one forward pass), it achieves +2.6 acc / -13.7% length on math tasks.
PACR(Yoon et al. 2025) takes as an inductive bias the assumption that “in well-formed reasoning, the correct-answer probability should increase monotonically,” and directly incorporates the monotonicity of the correct-answer probability during reasoning into the reward. Like GRPO-VPS, it presupposes the existence of a ground-truth answer, but the form of the reward (increment vs. monotonicity) differs.
Whereas VinePPO and PRIME treat the “look at the continuation from the prefix” operation as a means of estimating implicit reward, PPPO(Sun et al. 2025) places this operation squarely on top of an MDP. It regards the prefix itself as the state, and incorporates the average accuracy from sampling \(N\) continuations from a fixed prefix as the Monte Carlo value of that prefix into the advantage. Furthermore, it combines this with Progressive Prefix Retention, which gradually expands the length \(\eta\) of the prefix to optimize (as a fraction of the generated tokens) from 15% to 35%, explicitly reflecting in the training algorithm the empirical observation that earlier tokens constrain the continuation more strongly (Figure 6).
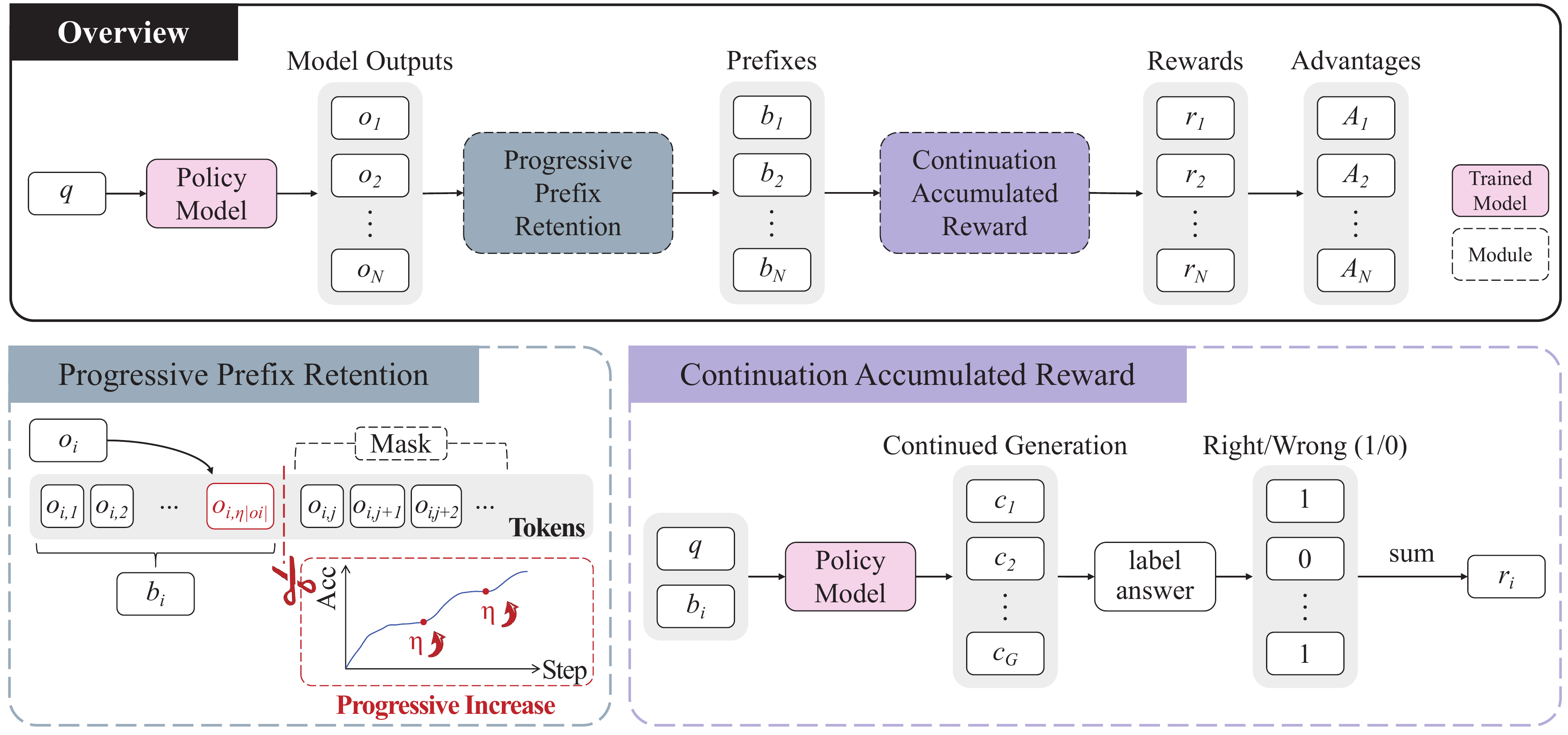
The paper reports up to +18.02pp and an average +14.64pp accuracy improvement on math benchmarks including AIME’25 with Qwen3-1.7B/4B/8B, at a training cost in which gradients flow through only the leading 26.17% of all generated tokens. The picture of “if RL starts from a good prefix, the remaining 65%–85% of tokens can be left frozen” can be seen as the most extreme expression, within the prefix-based reward lineage, of the claim that the prefix is the degree of freedom that RL should actually move.
These prefix-based rewards mechanically coincide with the inference-side methods such as Prefix-Confidence and Prefix Consistency treated in Self-Consistency and Weighted Majority Voting. Ranging from the implicit forms of GRPO-VPS / PACR to the explicit MDP formulation of PPPO, the fact that the same “look at the continuation from the prefix” operation is being independently reinvented on both the training side and the inference side strongly suggests that the prefix is a load-bearing unit of reasoning.
Pitfalls of Reward Hacking and Spurious Reward
When introducing dense / consistency-based reward, it is necessary to separate whether it is measuring “real reasoning quality” or merely amplifying quirks of the policy. The work that confronted this problem head-on is Spurious Rewards(R. Shao et al. 2025).
They showed that even with random reward or incorrect labels, GRPO improves Qwen2.5-Math-7B’s MATH-500 by +21.4pp, approaching the +29.1pp obtained when using ground truth (Figure 7). This is explained as the result of GRPO’s clipping bias amplifying behavior already acquired in pre-training (especially code reasoning patterns). Crucially, this phenomenon is specific to Qwen and does not reproduce on Llama3 or OLMo2. Looking at Figure 7, applying the same random/incorrect reward to Llama3.1-8B-Instruct or Olmo2-7B either decreases accuracy or almost completely eliminates gains under conditions without ground-truth-derived signal.
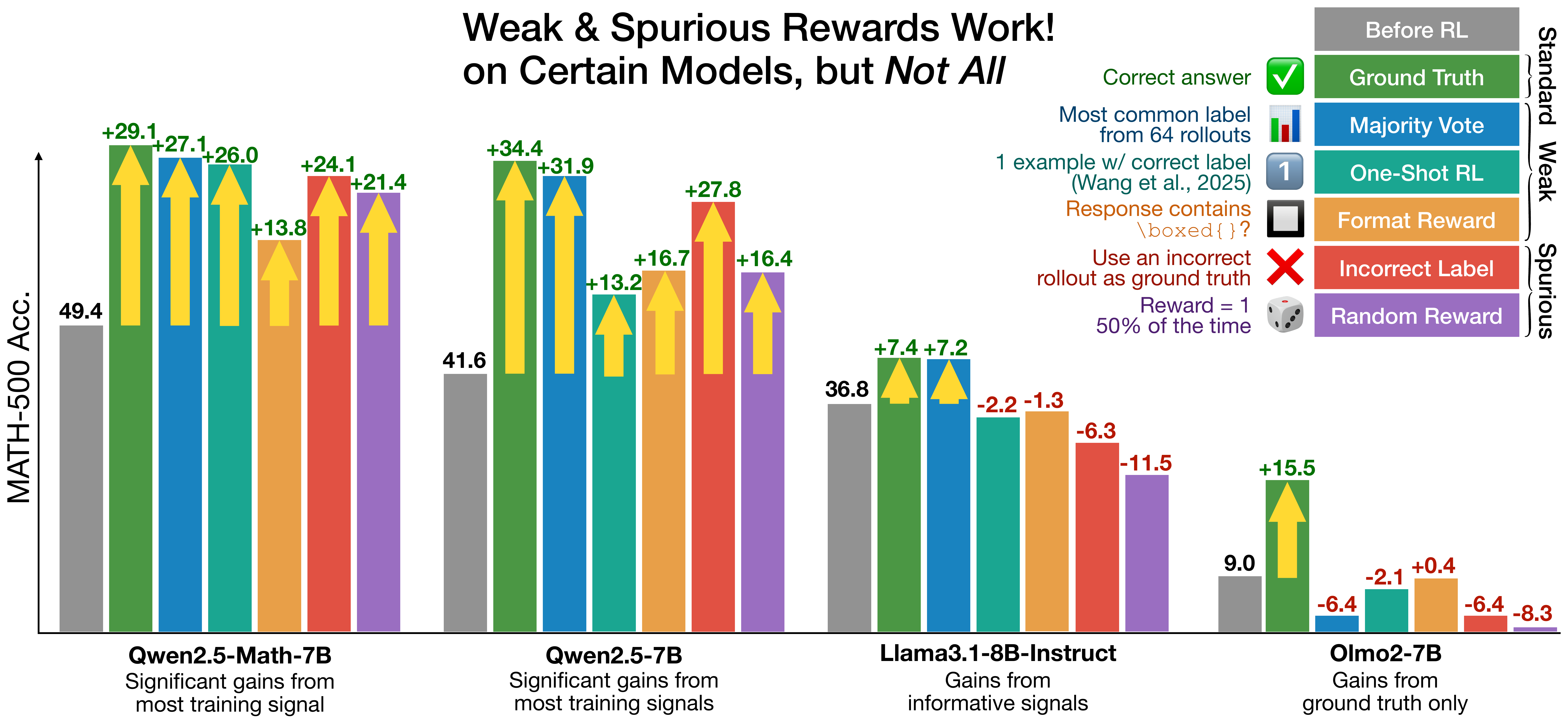
Research that proposes a new reward signal is now effectively required to demonstrate three things: (1) robustness against random / spurious reward (what happens if the same reward is randomized), (2) reproducibility across base models (does it work outside Qwen), and (3) the effect on large-K pass@K (is it narrowing the base distribution).
This cross-model robustness issue is directly connected to the question “does RLVR really expand the abilities of the base model” treated in Theory and Limits of RLVR. Does RLVR Really Incentivize Reasoning Beyond Base(Yang Yue et al. 2025) concluded that while RLVR raises pass@1, it is inferior to the base model at large-K pass@K — in other words, RLVR does not produce new reasoning patterns but merely narrows the base distribution. Whether dense reward can alleviate this fundamental ceiling is a challenge imposed on the entire process-reward family of research.
Self-Supervised RL: R-Zero and Absolute Zero
As research that completely eliminates external reward and trains reasoning models, two representative systems appeared in 2025.
R-Zero(Huang et al. 2026) adopts Challenger-Solver co-evolution. The Challenger is rewarded when it generates tasks near the Solver’s ability boundary, and the Solver is rewarded when it solves those difficult problems. With zero human curation, Qwen3-4B-Base showed improvements of +6.49 math / +7.54 general.
Absolute Zero Reasoner (AZR)(A. Zhao et al. 2025) is a configuration in which a single model proposes tasks that maximize its own learning progress and then solves them itself, using a code executor as both verifier and task validator. It achieved SOTA on code/math with zero external data.
These belong to a lineage that seeks “alternatives to ground-truth verifiers” alongside consistency-based reward; the code executor and self-play here use verifiability as a substitute for the verifier, while the consistency family uses the stability of the policy’s own behavior as the substitute.
Chapter Summary
GRPO became the de facto algorithm of RLVR in 2025, but the vanilla form has already receded to the position of a baseline, and discussion has entered a stage that presupposes the use of one of the derivatives — DAPO / Dr. GRPO / GSPO / VAPO / REINFORCE++. On the reward-design side, the shift from outcome reward to process / dense reward has become a major current, and in particular the family that “repurposes the policy’s own consistency or confidence as reward” (TTRL, CoVo, SCS, RESTRAIN, COMPASS, Intuitor, LaSeR, LENS, GRPO-VPS, PACR, PPPO) exploded. Behind these lie the theoretical and empirical findings of GRPO is Secretly a PRM(Sullivan and Koller 2025) and PRIME(Cui et al. 2026) that “process information is already embedded inside the outcome reward.”
On the other hand, Spurious Rewards(R. Shao et al. 2025) makes it imperative to verify the “realness” of reward signals through cross-model experiments. Studies that propose new rewards bear the responsibility of showing that they are not merely amplification of pre-trained behavior but really measure reasoning quality. In the next chapter (Process Reward Models), as the opposite pole of the implicit / consistency-based rewards treated in this chapter, we organize PRM-family methods that give explicit scores to each step of CoT.