Process Reward Models
A Process Reward Model (PRM) is a model that returns the correctness (or the probability of reaching a correct answer) for each step of a Chain-of-Thought (CoT). Until 2024, PRMs were widely used as intermediate signals for Best-of-N (BoN) selection and Reinforcement Learning (RL), but the high cost of collecting step labels by hand was the biggest barrier to adoption. Research in 2025–2026 is dismantling this barrier from two directions. One is label-free / weakly supervised training, and the other is the shift toward generative PRMs. In parallel, benchmarks demonstrating the inherent limitations of PRMs themselves, as well as studies skeptical of the effectiveness of PRM-guided search, have been accumulating. This chapter surveys roughly 24 major works around these four trends.
The Role of PRMs
Classically, PRMs have been used for the following three purposes.
- BoN selection: For \(N\) candidate trajectories, aggregate the per-step scores and select the best response. Compared to an Outcome Reward Model (ORM), which only scores the final answer, a PRM can identify trajectories that went wrong partway through
- Guiding RL training: Within Group Relative Policy Optimization (GRPO) or Direct Preference Optimization (DPO), incorporate step-level signals into the advantage in addition to the outcome reward
- Guiding search: Use the PRM for node scoring and pruning in Monte Carlo Tree Search (MCTS) or beam search
For a PRM to function in these applications, step labels of sufficient quality must be available. However, human annotation efforts like PRM800K only become viable at the scale of 800K steps, and real research settings must rely on either synthetic labels or weak supervision. The major technical advances of 2025–2026 are responses to this “scarcity of label supply.”
Figure 1 shows a typical annotation example from ProcessBench. label: 2 is the index of the “first incorrect step,” indicating that the minimum unit for PRM training and evaluation operates at this granularity.

steps array, an expert annotates the index of the “first incorrect step.” Source: (Zheng et al. 2024)
The Lineage of Label-Free PRMs
The mechanisms for eliminating the need for step labels fall broadly into four categories: MC rollout, log-likelihood ratios of the policy itself, pseudo labels back-propagated from outcomes, and next-token probabilities.
Math-Shepherd family (MC rollout-based): Math-Shepherd is a classical method that generates \(N\) rollouts from each intermediate step and uses the proportion that reaches the correct answer as a pseudo-score to label each step. OmegaPRM adds MCTS-based rollout efficiency improvements to lower generation cost. On the other hand, the practical report on Qwen2.5-Math-PRM (Zheng et al. 2024) shows that “step labels derived from MC rollout generalize more weakly than LLM-as-judge,” and proposes consensus filtering and hybrid annotation.
Implicit PRM (log-likelihood ratio-based): The core idea of Free Process Rewards (Cui et al. 2026) is that by simply parametrizing the outcome reward as a log-likelihood ratio between the policy and the reference, step-level rewards can be extracted “for free” after training. Because a PRM can be obtained using only response-level labels, the bottleneck of collecting step annotations is removed. PRIME (Cui et al. 2026) integrates this into online RL, eliminating the dedicated PRM training phase and updating the implicit PRM using only policy rollouts and outcome labels. It reports an average improvement of 15.1% from Qwen2.5-Math-7B-Base and the efficiency of surpassing Instruct with 10% of the training data.
FreePRM family (outcome → pseudo step label): FreePRM is a weakly supervised PRM that generates pseudo step labels from the correctness of the final outcome and mitigates label noise via Buffer Probability. It achieves F1=53.0 on ProcessBench, surpassing the fully supervised Math-Shepherd-based PRM by +24.1 points. It starts from the naive pseudo label of “if the outcome is correct, tentatively treat all steps as correct” and statistically squeezes out the noise.
uPRM family (next-token probability-based): Unsupervised PRM (uPRM, (Gadetsky et al. 2026)) is a scoring function derived from the LLM’s next-token probabilities that jointly evaluates “candidate positions of the first incorrect step” across a batch of trajectories. What is new is that the PRM can be trained fully unsupervised, using neither step labels nor outcome labels. It outperforms LLM-as-Judge by up to 15% on ProcessBench and also improves RL policy optimization.
Table 1 organizes the major label-free PRMs by their signal source.
| Method | Signal source | Labels used |
|---|---|---|
| Math-Shepherd / OmegaPRM | MC rollout agreement rate | None (generation only) |
| ImplicitPRM / PRIME (Cui et al. 2026) | \(\log \pi_\theta - \log \pi_\mathrm{ref}\) | Outcome only |
| FreePRM | outcome → pseudo step + buffer | Outcome only |
| Athena-PRM (Athena-PRM Team 2025) | Agreement between weak/strong completers | Outcome only |
| uPRM (Gadetsky et al. 2026) | Joint scoring of next-token probabilities | None |
| SPARK | Self-consistency and meta-critique | Outcome only |
What these share in common is the idea of “giving up on human step labels and instead extracting signal from elsewhere.” MC rollout, log-likelihood ratios, pseudo labels back-propagated from outcomes, next-token probabilities, and agreement among completers can all be viewed as proxy signals extracted from the policy’s implicit distribution.
The Lineage of Generative PRMs
Conventional PRMs were discriminative, returning a probability for each step via a scalar head. Generative PRMs replace this with “a verifier that verbalizes a CoT for each step and renders judgment.” Unlike discriminative PRMs, the essential advantage is that test-time compute can also be scaled on the verifier side.
ThinkPRM (Khalifa et al. 2025) is the earliest example of a long-CoT PRM against the discriminative type, fine-tuned with synthetic data of just 1% of PRM800K (8K step labels). It surpasses discriminative PRMs trained on full PRM800K by 8% / 4.5% out-of-domain in BoN and reward-guided search on ProcessBench / MATH-500 / AIME’24. GenPRM (Zhao et al. 2025) moves in the direction of combining explicit CoT with code verification, and proposes its own labeling method called Relative Progress Estimation (RPE). GenPRM-7B outperforms discriminative PRMs of the same size and, with test-time scaling, surpasses Qwen2.5-Math-PRM-72B.
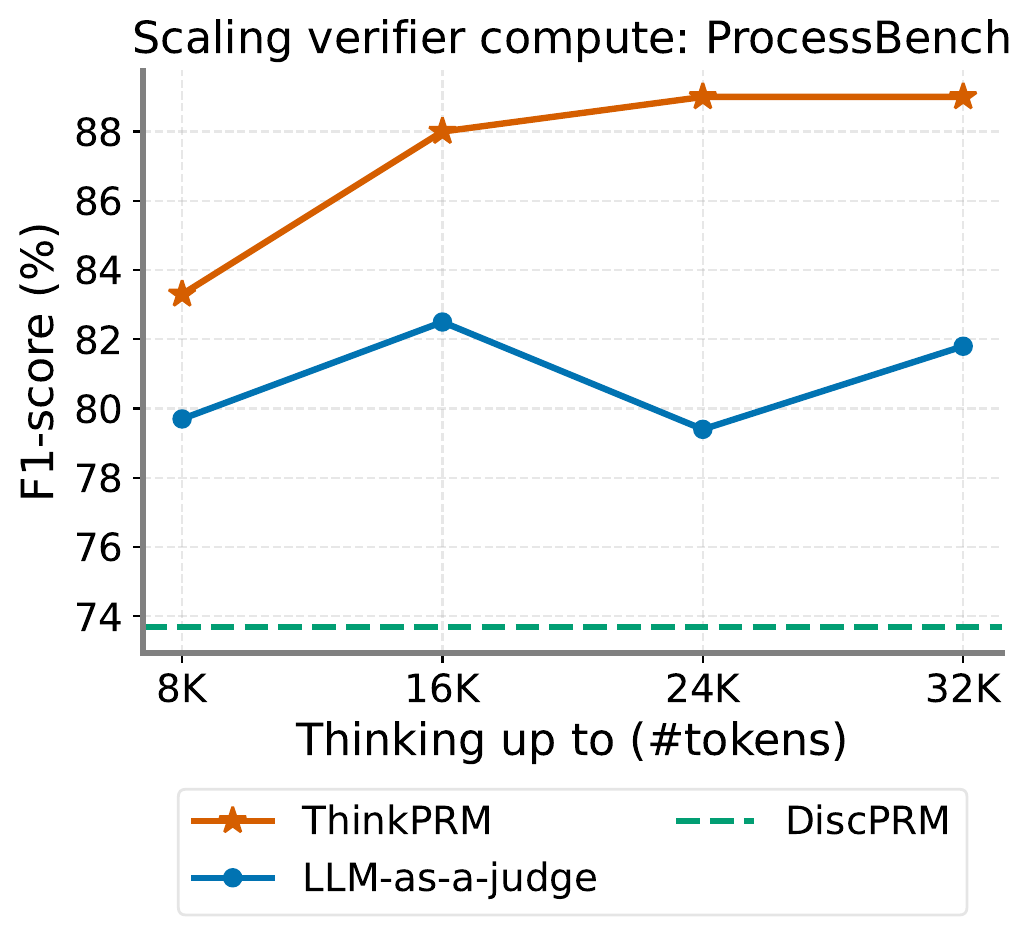
Figure 2 is a representative plot in which ThinkPRM demonstrated a “verifier-side scaling law.” Increasing the number of thinking tokens from 8K to 32K monotonically improves F1 from 83 to 89, substantially exceeding the plateau of the discriminative PRM (DiscPRM).
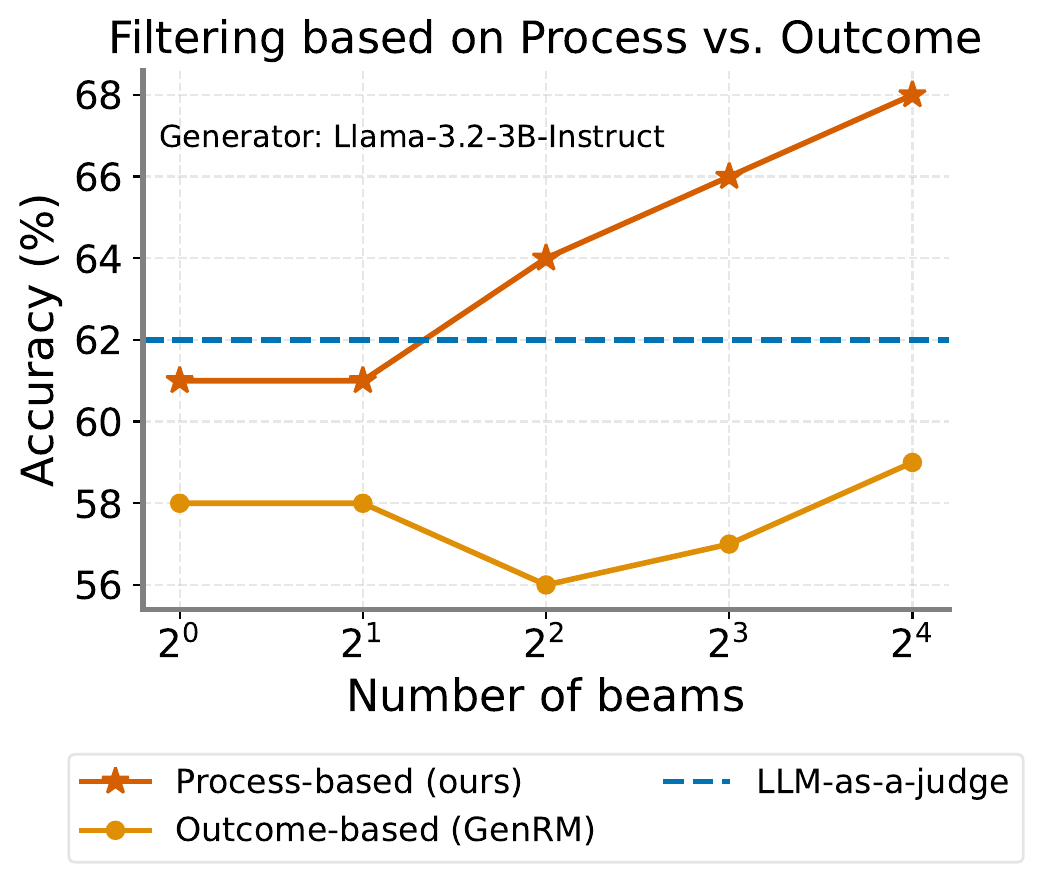
The advantage of generative PRMs is also pronounced in filtering. Figure 3 shows that ThinkPRM’s process-based filtering widens its margin over outcome-based filtering (equivalent to GenRM) as the beam size grows. This suggests that the original advantage of PRMs, “discarding trajectories that went wrong partway through,” scales with compute.
R-PRM is a generative PRM that improves performance via preference optimization without additional annotation. Reward Reasoning Model (RRM) deliberates with explicit CoT before returning a reward, and can flexibly invest test-time compute via ELO / knockout strategies. Uncertainty-Aware Step-wise Verification introduces a novel uncertainty metric called CoT Entropy for generative PRMs, reducing erroneous feedback by having the verifier itself detect steps it is uncertain about.
The advantage of generative PRMs is that they have a “verifier-side scaling law” where accuracy improves with more compute. The accuracy of discriminative PRMs is bounded by training data volume and expressive capacity, whereas generative PRMs can increase the reasoning budget at inference time. On the other hand, the cost grows superlinearly, so when to use generative PRMs depends on the downstream task’s compute budget.
Extensions to Specialized Domains
PRMs were concentrated in the math domain for a while, but from late 2025 they have rapidly broadened across domains.
- Multimodal: Athena-PRM (Athena-PRM Team 2025) uses the prediction agreement between a weak completer and a strong completer as a criterion for reliable labels, training a multimodal PRM with 5K samples. It achieves SOTA on VisualProcessBench at +3.9 F1, and with Qwen2.5-VL-7B as the policy, improves WeMath by +10.2 and MathVista by +7.1 points. Figure 4 shows an example of pseudo-label generation by Athena’s completer agreement
- Multi-domain: VersaPRM generates synthetic CoTs from MMLU-Pro and auto-labels them with a 70B model, extending PRM to domains such as law, medicine, and economics. It achieves +7.9% in weighted majority voting on the law category (substantially better than Qwen2.5-Math-PRM’s +1.3%)
- Long-CoT trajectories: ReasonFlux-PRM addresses the problem that existing PRMs do not fit the trajectory-response structure of DeepSeek-R1 / OpenAI-o1. By combining both step-level and trajectory-level supervision, it surpasses Qwen2.5-Math-PRM-72B in data selection quality with 10K high-quality trajectory-response data
- Structured reasoning (rule-based): VPRM (Verifiable PRM) avoids the opacity / bias / reward hacking vulnerabilities of neural judges by verifying each step with a deterministic rule-based verifier. It improves SOTA on risk-of-bias assessment for medical evidence synthesis by up to +20% F1

What these share in common is the direction of “incorporating domain-specific structure (multimodal completer diversity, medical rule-based verifiability, long-CoT trajectory structure) as a signal source for the PRM.” Rather than building a general-purpose PRM, building a domain-specialized one tends to yield more practical performance under a limited label budget.
Limitations of PRMs and Benchmarks
In parallel with PRM progress, skepticism toward PRMs themselves has also grown.
(Cinquin et al. 2025) showed that PRMs as guides for MCTS do not consistently outperform naive BoN, even with substantial compute. While the PRM score appears theoretically useful for narrowing the MCTS search space, empirically there are many cases where PRM noise distorts the search. How to use a PRM is an open question that depends on both the quality of the signal and the search algorithm.
An interesting point in the analysis of (Cinquin et al. 2025) is that the correlation changes significantly depending on the choice of aggregator that combines step scores into the whole trajectory. As shown in Figure 5, Last / Avg / Min / Prod maintain a moderate positive correlation, but Sum and Max degrade to nearly uncorrelated out-of-distribution. This suggests that when using PRM signals in downstream tasks, the choice of aggregation itself becomes an important hyperparameter.
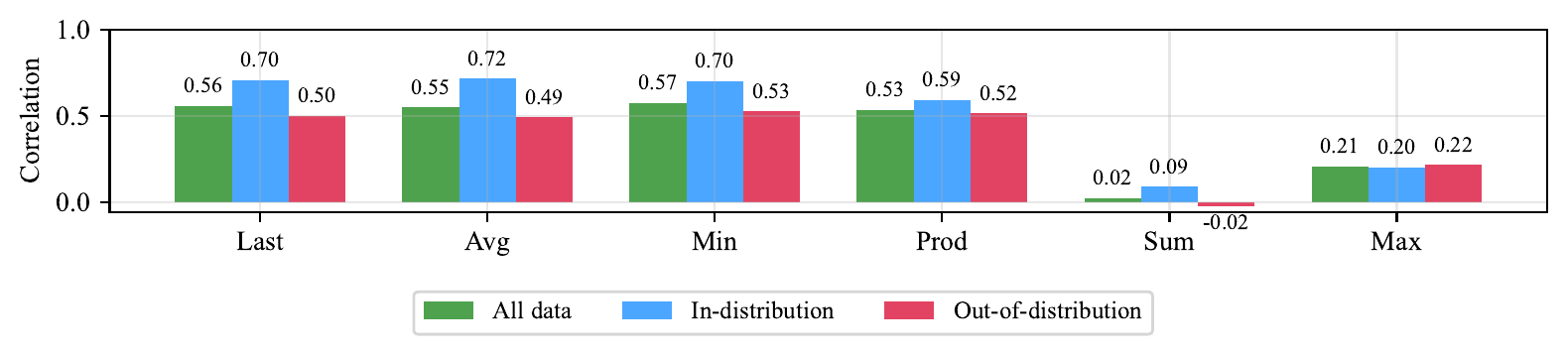
Last/Avg/Min/Prod are stable, but Sum/Max collapse. Source: (Cinquin et al. 2025)
On the benchmark side, difficulty and granularity have ratcheted up.
- ProcessBench (Zheng et al. 2024): A benchmark of 3,400 olympiad-level math problems where experts annotate the “first incorrect step.” It showed that existing PRMs degrade substantially in performance when going beyond the scope of GSM8K/MATH
- PRMBench: 6,216 problems / 83,456 step labels. Evaluates PRMs’ implicit error detection capabilities across 9 subcategories in 3 dimensions of simplicity / soundness / sensitivity. In the evaluation of 25 PRMs/LLMs, Gemini-2-Thinking is the best at 68.8 (humans achieve 83.8)
- Hard2Verify (Pandit et al. 2025): A step verification benchmark for frontier-level math (open-ended proofs such as IMO 2025) with over 500 hours of human annotation. 1,860 steps / 200 solutions. Qwen2.5-Math-PRM-72B drops substantially from 78.3 on ProcessBench to 37.3 on Hard2Verify, clearly demonstrating that existing PRMs are not usable at the frontier
Figure 6 shows a same-model comparison between Hard2Verify and ProcessBench. The horizontal axis is ProcessBench and the vertical axis is Hard2Verify, and the dedicated PRM Qwen2.5-Math-PRM-72B drops sharply from ProcessBench 78 to Hard2Verify 37. Only general-purpose large LLMs such as Gemini 2.5 Pro or GPT-5-High secure 50% or higher on Hard2Verify, succinctly demonstrating that the advantage of dedicated PRMs is lost at the frontier.
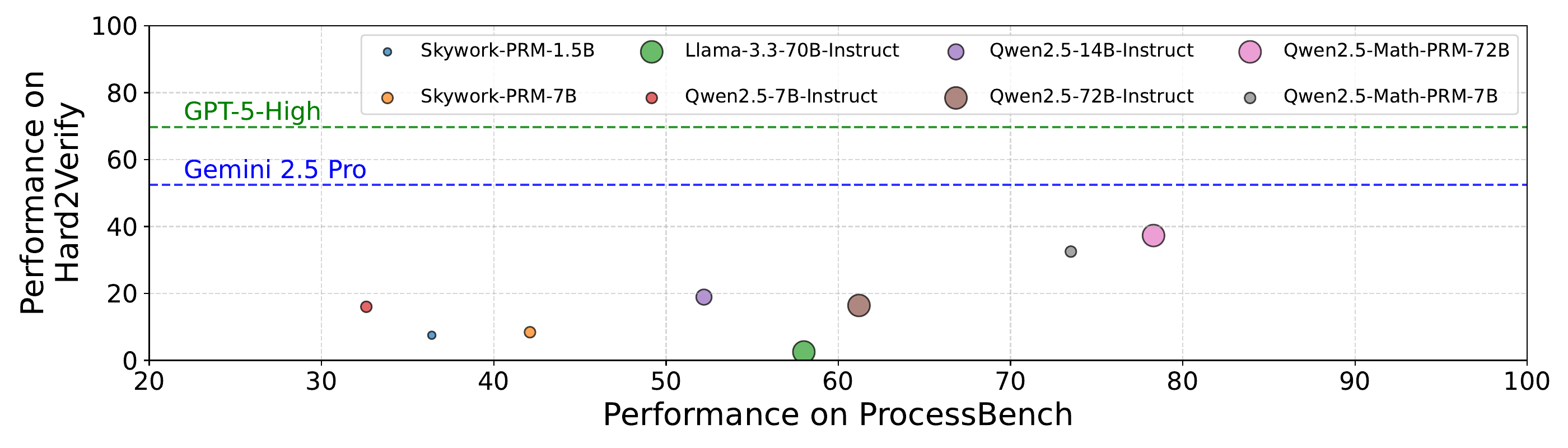
The Hard2Verify results send a strong message that “even within the math domain, PRM generalization is limited.”
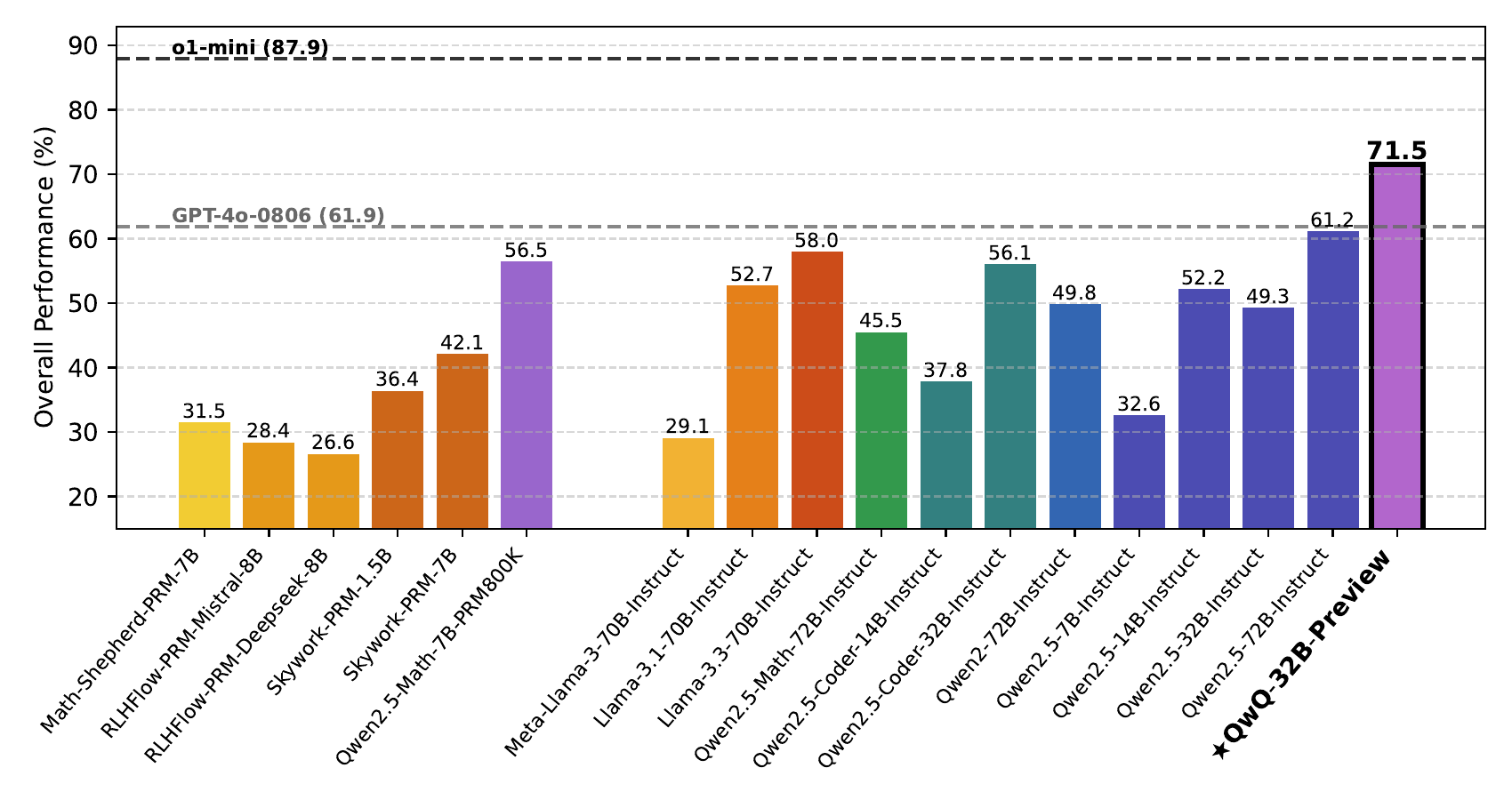
For reference, Figure 7 shows a comparison of major PRMs/LLMs on ProcessBench. Even within the same math benchmark, the gap between the best Qwen2.5-Math-7B-PRM800K (56.5) and the Skywork-PRM family (around 28-42) is large, showing that differences in PRM training recipes produce extreme performance gaps. Taken together with the Hard2Verify numbers, PRMs can be characterized as an unstable signal source that strongly depends on both benchmark selection and training recipe.
Calibration
PRM scores are often read as probabilities, but their calibration can be severely degraded.
A series of studies reported in parallel with (Khalifa et al. 2025) showed that PRMs are systematically overconfident. Know What You Don’t Know empirically shows that partial trajectories the PRM predicts at 90% actually succeed at a much lower rate, and proposes calibration of PRM outputs via quantile regression. By incorporating calibrated estimates into Instance-Adaptive Scaling (IAS), it substantially reduces calibration error on the MATH benchmark, combining reduced compute cost with maintained accuracy.
Distributional PRM pushes this direction further, correcting PRM miscalibration with conditional optimal transport. By learning a monotonic conditional quantile function on success probability conditioned on the PRM hidden states, it becomes possible to extract bounds at arbitrary confidence levels, significantly outperforming uncalibrated PRMs and quantile regression on MATH-500 / AIME.
The calibration discussion applies not only to PRMs but transversally to other signal sources such as self-consistency and verbalized confidence (see Confidence and Uncertainty).
Theoretical Connection with RL
The relationship between PRMs and RL has recently seen a deepening discussion of “equivalence.”
GRPO is Secretly a PRM theoretically proves that GRPO with outcome reward is equivalent to a Monte-Carlo PRM on subsets of trajectories sharing an identical prefix. The identical-prefix condition is nearly always met in real-world rollouts, demonstrating that a hidden step-level reward structure exists within GRPO. λ-GRPO, which corrects this defect, outperforms GRPO on reasoning benchmarks.
SPRO moves in the direction of intrinsically deriving the process reward from the policy model itself without training an additional PRM, and rigorously estimates step-wise advantage within shared-prompt sampling groups via Masked Step Advantage (MSA). It reports 3.4× training efficiency over vanilla GRPO and a 17.5% accuracy improvement.
ActPRM takes the reverse approach, proposing active learning PRM training in which only the samples that are most uncertain (aleatoric + epistemic) after the forward pass are labeled by a high-capability judge model. It achieves equivalent or better performance with 50% lower annotation cost, and SOTA at ProcessBench 75.0 / PRMBench 65.5.
These studies are establishing the view that “PRM training and RL training need not be considered as separate phases; an implicit PRM structure is already contained within RL.” This book treats the same perspective from a different angle in GRPO and Reward Design.
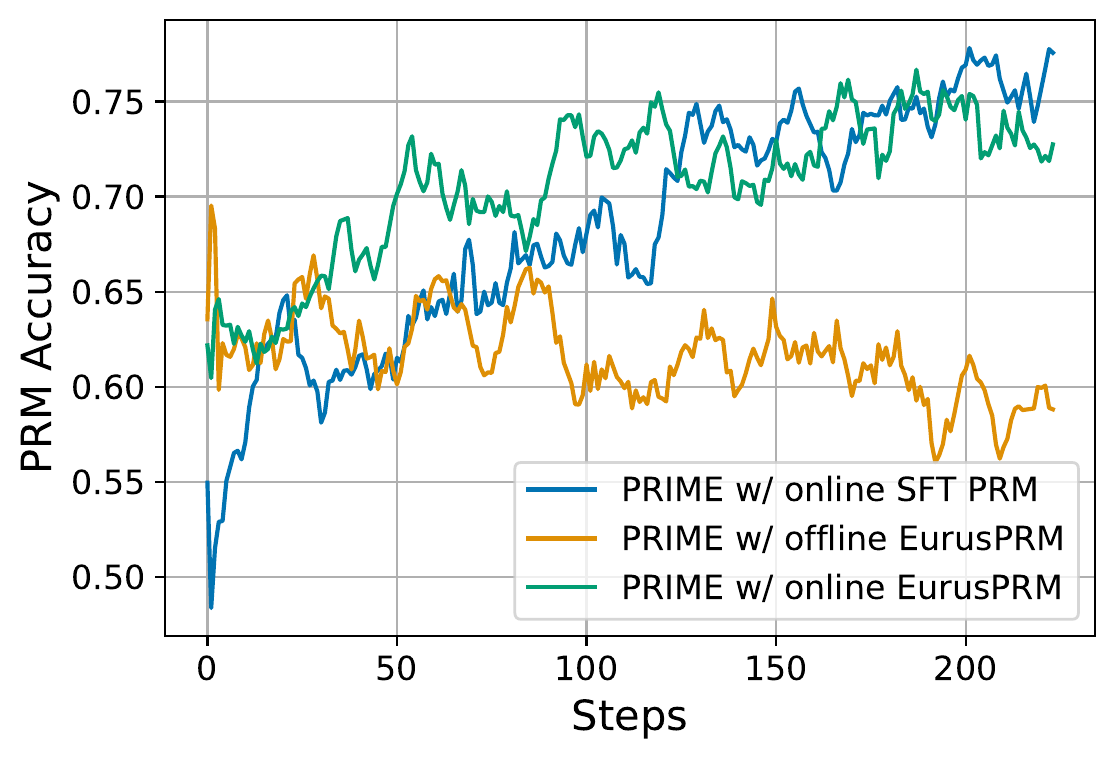
Figure 8 shows how much accuracy PRIME’s (Cui et al. 2026) online implicit PRM maintains during training. Whereas EurusPRM, fixed offline, degrades in accuracy partway through, the online-updated PRM (both the SFT version and the EurusPRM version) improves to around 75% accuracy as steps accumulate. This is a result that supports PRIME’s claim that implicit PRMs can maintain accuracy only by co-evolving with the policy.
Chapter Summary
The 2025–2026 movement in the PRM area can be summarized in the following five points.
- Convergence on “label-free step rewards”: Different signal sources (MC rollout, log-likelihood ratios, outcome-derived pseudo labels, next-token probabilities, completer agreement) are independently pursuing the same goal (eliminating step labels)
- Shift toward generative PRMs: The shift from scalar heads to CoT-verbalized verifiers makes it possible to scale test-time compute on the verifier side
- Theoretical identification with GRPO/RL: Studies such as PRIME, GRPO-is-secretly-a-PRM, and SPRO are showing that a PRM structure is implicitly contained within RL
- Exposure of the calibration problem: PRM overconfidence and the direction of correcting it via quantile regression / optimal transport have been established
- Harder benchmarks: Difficulty has expanded as ProcessBench → PRMBench → Hard2Verify, exposing the limits of existing PRMs
These appear to progress independently, but at the root they are answers to three questions: “the scarcity of step labels,” “where to invest verifier compute,” and “downstream signal utilization.” The next chapter, Self-Consistency and Weighted Majority Voting, treats self-consistency-based signals as a lightweight verifier that does not require a PRM. The boundary between these two lineages is rapidly blurring toward 2026.