Reasoning Structure Analysis
When we try to evaluate the quality of a Chain-of-Thought (CoT) at inference time, the easiest signals to reach for are “length” and “single-token confidence.” Yet these turn out to be weak predictors of correctness, as repeatedly noted in Self-Consistency and Weighted Majority Voting and Confidence and Uncertainty.
Where else should we look? Four papers that appeared independently in 2025–2026 converged on a shared answer: read the CoT as a structure. The causal influence of each reasoning step on the final answer, the fraction of abandoned branches, the attribution graph of internal circuits, the taxonomy of cognitive behaviors — the entry points differ, but all four rest on the same intuition that the predictive signal lives in structural features that a single length or confidence score cannot capture.
This chapter places these four works inside a unifying frame. The common motif is “measuring the structure of reasoning at inference time,” and the methods discussed here function as complements to the aggregation-side techniques covered in Self-Consistency and Weighted Majority Voting — the Self-Consistency line, the DeepConf family, and the prefix-based methods. Aggregation extracts signal from “the consensus across multiple traces,” while the methods in this chapter extract signal from “the structure of a single trace itself.”
Why Look at “Structure”
The following signals have been tried for CoT quality prediction.
- Length: the hypothesis that “longer CoT means more careful reasoning.” But the large-scale experiments of Feng et al. (Feng et al. 2025) show that within a single problem, shorter CoTs tend to be more accurate.
- Verbalized confidence: asking the model itself “rate your confidence from 0 to 10.” As DINCO (Wang and Stengel-Eskin 2025) and Wired for Overconfidence (T. Zhao et al. 2026) showed, models after Reinforcement Learning with Verifiable Rewards (RLVR) are severely miscalibrated.
- Token-level entropy: adopted by Self-Certainty (Kang et al. 2025) and Inverse-Entropy Voting (IEW) (Sharma and Chopra 2025), yet this too leans on the calibration of internal signals.
All of these limitations stem from treating the CoT as a homogeneous token sequence. The four works in this chapter recast the CoT as a structured object — a sequence with a temporal gradient, a graph with branches and abandonments, an internal circuit, a set of cognitive behaviors — and thereby pull out stronger predictive signal.
The prefix-based methods in Self-Consistency and Weighted Majority Voting (PoLR, Path-Consistency, Prefix-Confidence Scaling, ST-BoN, Beyond the Last Answer, Prefix Consistency) are structured along two axes: where to cut the CoT (cut position) and what to measure (confidence, frequency, regeneration agreement, etc.). The structural works examined in this chapter sit on the other side of these axes. Specifically, Reasoning Horizon gives a physical grounding for “where to cut,” and Failed-Step Fraction (FSF) restates structurally “what predicts correctness in a trace.”
Reasoning Horizon: The Trace’s Final Portion Is Causally Vacuous
Ye et al.’s Reasoning Horizon (Ye et al. 2026) measures the causal influence of each CoT step on the final answer by direct intervention. The method is simple. Deliberately corrupt a specific step in the CoT and observe how much the logit distribution over the final answer changes.
The corruption operation is designed per task.
- Dyck-nn (bracket matching): insert depth errors in stack tracking
- PrOntoQA (logical reasoning): substitute entities in logical rules
- GSM8K (arithmetic reasoning): inject errors into computation results
The effect of corruption is quantified by the Normalized Logit Difference Decay (NLDD). A positive NLDD means corruption lowers confidence in the correct answer (the step is causally active); a negative NLDD means corruption fails to lower it (the step is causally redundant).
The 70–85% Critical Point
The results are clean. In the early and middle portions of the CoT, NLDD is high; past a certain point, it drops sharply to near zero. The authors named this critical point the Reasoning Horizon \(k^*\). Across tasks and models, \(k^*\) lands in the 70–85% range of the full CoT.
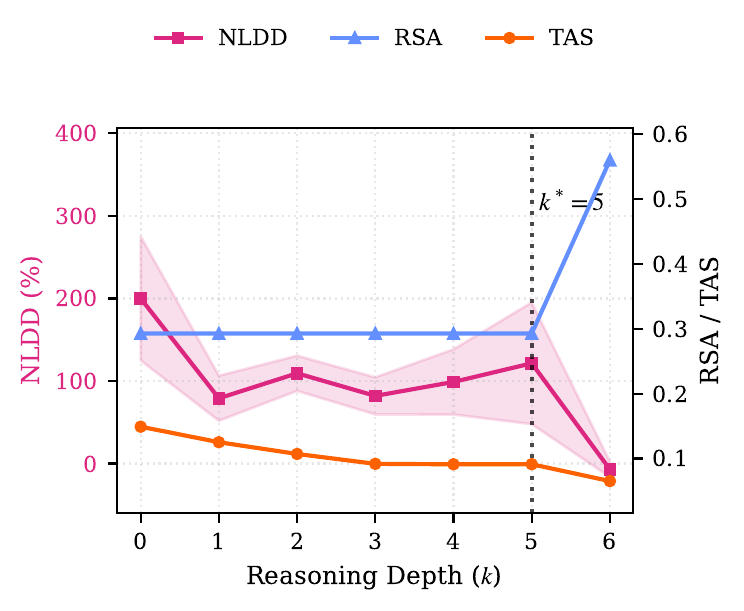
The concrete breakdown in Figure 1 is:
- GSM8K: step 5–6 out of 8 (about 85%)
- Dyck-nn: step 9–11 out of 12 (about 80%)
- PrOntoQA: step 11–16 out of 16 (about 70–100%)
Three model families were tested — DeepSeek-Coder-6.7B-Instruct, Llama-3.1-8B-Instruct, and Gemma-2-9B-Instruct — and the same pattern appeared despite architectural differences.
Faithful vs Anti-Faithful Regimes
Not every model is faithfully dependent on its CoT. Ye et al. distinguished two regimes.
- Faithful: Llama and DeepSeek show high positive NLDD. They are causally dependent on the early CoT steps, and corruption breaks the answer.
- Anti-Faithful: Gemma reaches 99% accuracy on logical reasoning while NLDD sits at −52.5%. Corrupting the CoT actually raises confidence in the correct answer. The verbalized CoT is causally disconnected from the internal representation.
The observation that accuracy alone cannot adjudicate the reasoning mechanism extends the CoT faithfulness discussion of Lanham et al. (2023).
Implications for Prefix-Based Methods
The Reasoning Horizon finding has physical implications for the shared “where to cut” question across the prefix-based methods in Self-Consistency and Weighted Majority Voting — PoLR, Path-Consistency, Prefix-Confidence Scaling, ST-BoN, Beyond the Last Answer, and Prefix Consistency.
These methods aggregate continuations from a prefix of the CoT, but the cut position has been chosen empirically. Borrowing the Reasoning Horizon result, cutting before \(k^* / L\) (where \(L\) is total CoT length and \(k^*\) is the 70–85% critical point identified in this chapter) preserves the causally important first portion of the trace, while reseeding regeneration or re-aggregation only from the answer-irrelevant tail.
The flip side: tokens past \(k^*\) are merely “along for the ride” with respect to answer generation, redundant trace that prefix-based methods should not use as the basis for confidence estimation or aggregation.
Failed-Step Fraction: Reading CoT as a Graph
Feng et al.’s Failed-Step Fraction (Feng et al. 2025) structurally analyzes the CoT not as a “text sequence” but as a “reasoning graph.” Each CoT is converted into Graphviz form by Claude 3.7 Sonnet (with a 100% compilation success rate), producing a directed graph in which nodes are individual reasoning steps and edges are the flow of information between them. Each node is labeled either a Success Step (blue) or a Failed Attempt (red).
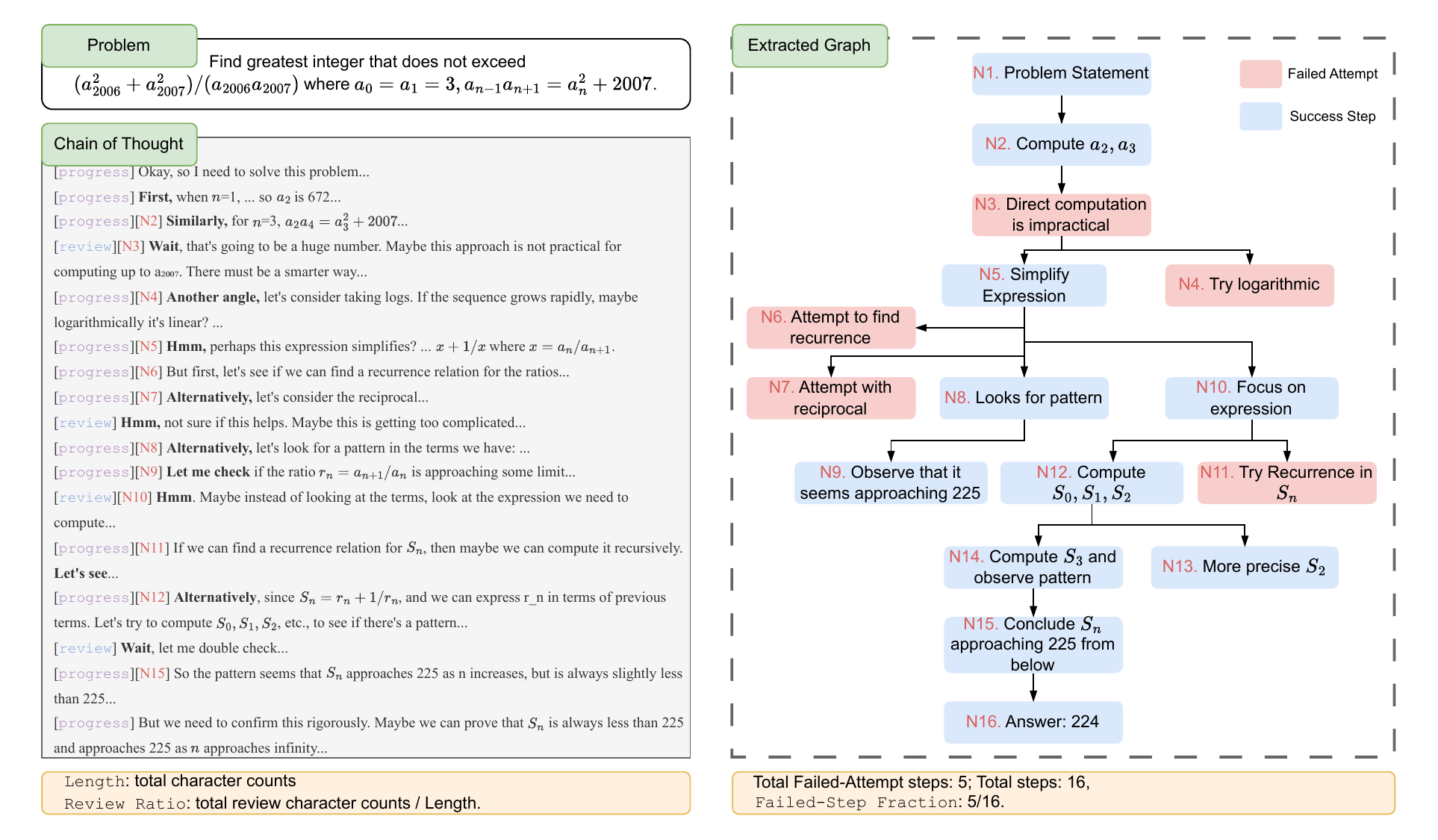
Definition of FSF
From this graph, FSF is defined as
\[ \text{FSF} = \frac{|\text{failed nodes}|}{|\text{total nodes}|} \tag{1}\]
FSF captures “the fraction of branches that were attempted and then abandoned during reasoning.” Crucially, this is a structural quantity computed locally per trace, and does not require any ground-truth correctness label.
FSF Is a Stronger Predictor Than Length or Review Ratio
Feng et al. analyzed roughly 4,800 math traces and 3,200 science traces across 10 models. The conditional correlation analysis contains some counterintuitive results.
- Length: within a problem, shorter CoTs are more accurate.
- Review Ratio (fraction of review behaviors): less review correlates with higher accuracy.
- FSF: fewer abandoned branches correlates with higher accuracy, consistently and significantly across all models and tasks.
The intuitions “long trace = careful thought” and “more review = self-verification” do not hold up in the data. Increased length and review are likely traces of repeatedly hitting dead ends, and FSF captures that directly.
FSF as a Test-Time Selector
Feng et al. also use FSF for test-time trace selection. Generate multiple traces per problem and pick the one with the minimum FSF.
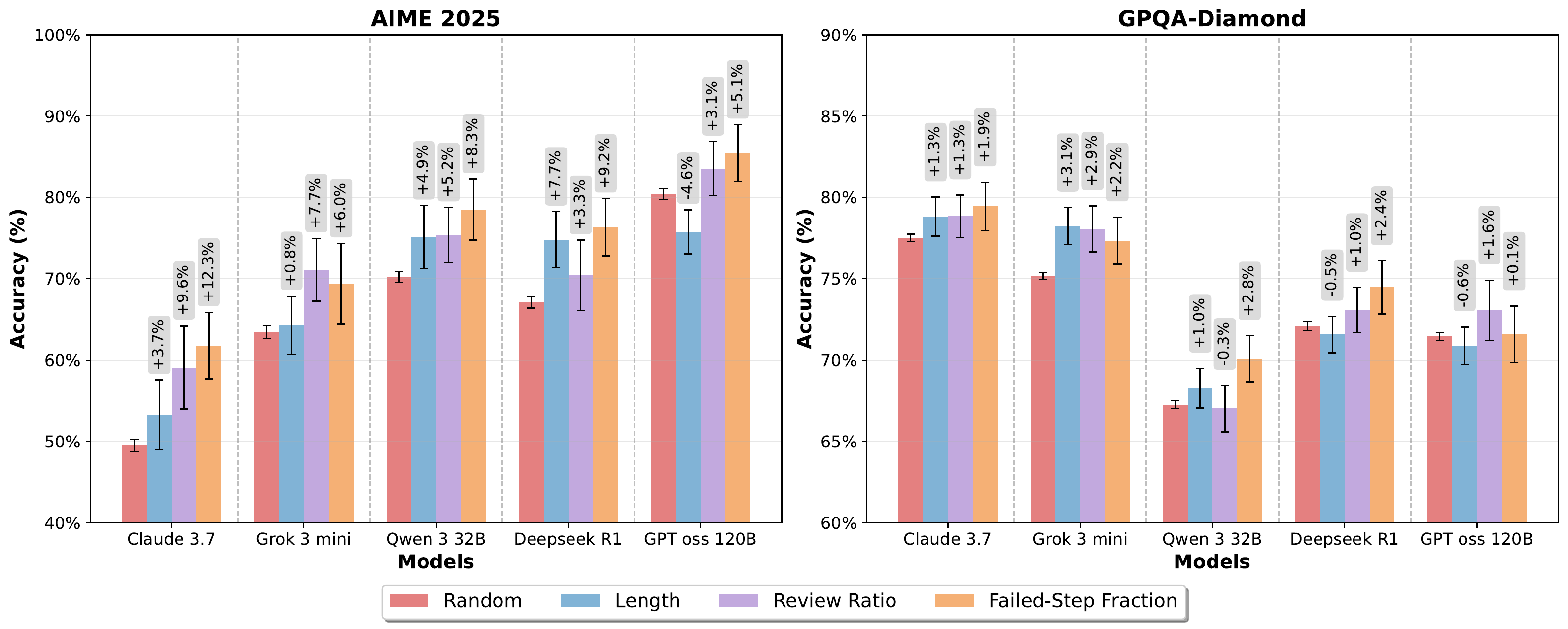
On AIME 2025 in Figure 3, FSF-based selection yields an average 5–13% accuracy improvement over Random and beats both Length and Review Ratio. On GPQA-Diamond, FSF is again the best in most cases, showing that the structural metric dominates the simple ones.
Removing Abandoned Branches: A Causal Test
To show that FSF is not merely a correlation but is causally load-bearing, Feng et al. ran an intervention that physically removes abandoned branches from the CoT.
- DeepSeek R1: 20.89% to 29.42%
- GPT oss 120B: 28.05% to 36.41%
Abandoned branches are not merely wasted — they bias the subsequent reasoning. The model cannot fully “forget” past failures, and the residual echo of abandoned attempts distorts the reasoning that follows. The result suggests it is possible to improve accuracy by rewriting the CoT structure at test time.
Relation to Regeneration-Based Methods
FSF reads CoT as a graph via an external LLM, but the same “trace stability” can plausibly be approximated as a black box by regeneration-based methods such as Beyond the Last Answer (Hammoud et al. 2025) or Prefix Consistency (Iwase et al. 2026) from Self-Consistency and Weighted Majority Voting. These methods regenerate the continuation from a prefix and measure the agreement among the regenerations; a trace with high FSF — many branches and abandonments — is unlikely to retrace the same branching pattern after regeneration, so the agreement is expected to be lower. A unified empirical comparison between FSF and regeneration-based methods is not yet available and remains an open question.
CRV: Structure from Internal Circuits
The two works above — Reasoning Horizon and FSF — use external observations of the CoT (text, post-intervention logits, extracted graphs) as their signal. Zhao et al.’s Circuit-based Reasoning Verification (CRV) (Z. Zhao et al. 2025) inverts this, extracting structural features from the model’s internal computation graph (attribution graph). It is the first attempt to apply Mechanistic Interpretability to reasoning verification.
The Four-Stage CRV Pipeline
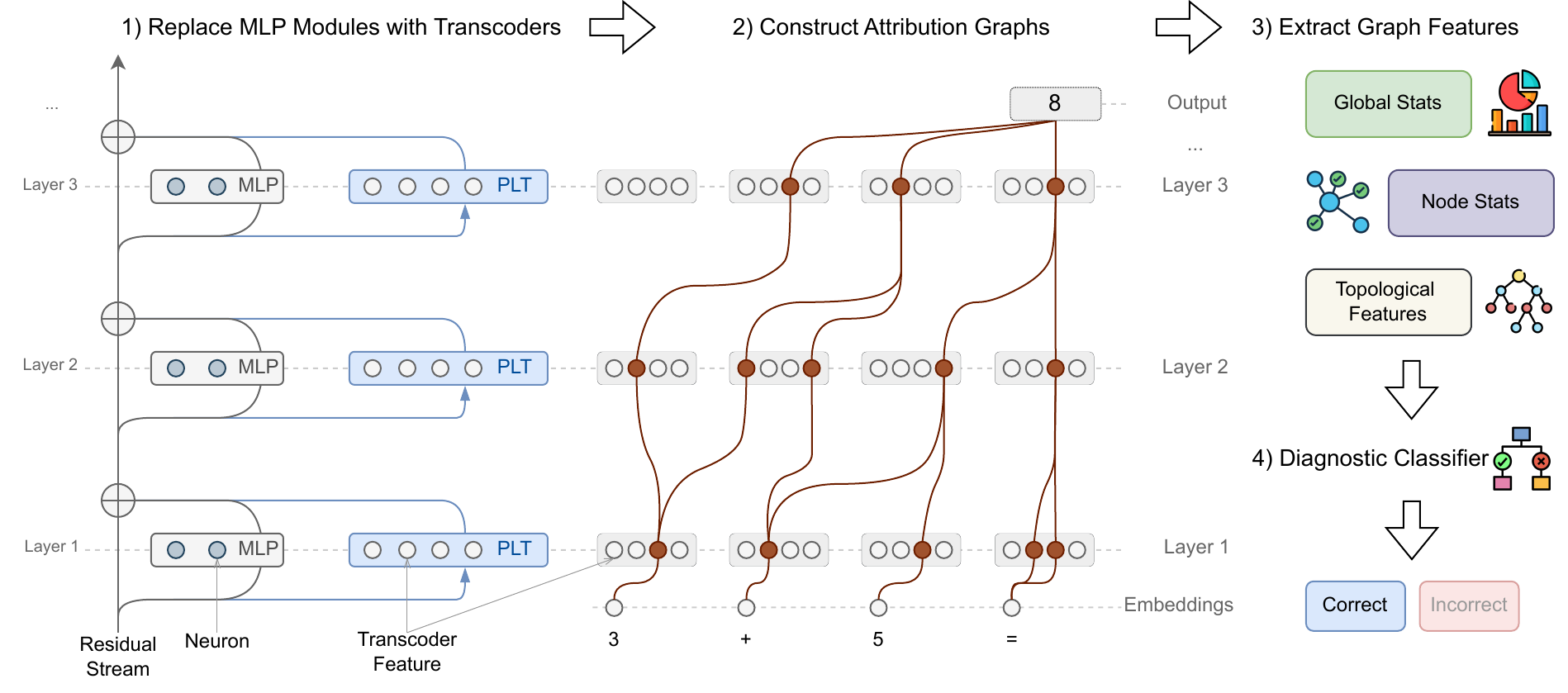
The CRV pipeline in Figure 4 runs as follows.
- Interpretabilizing the MLPs: replace each MLP module of Llama 3.1 8B Instruct with a per-layer transcoder (PLT). A PLT is a sparse autoencoder variant that approximates the MLP’s input-output function with sparse interpretable features.
- Building the attribution graph: for each reasoning step, construct a directed weighted graph whose nodes are input tokens, activated PLT features, and output logits, and whose edges are high-attribution causal paths between them.
- Extracting structural features: from the pruned graph, extract three families of features.
- Global stats: number of active nodes, final logit probability, entropy
- Node stats: mean / max / std of node activations and influence scores, per-layer histograms of active features
- Topological features: graph density, centrality (degree, betweenness), connectivity metrics
- Diagnostic classifier: a gradient boosting classifier takes the feature vector and predicts whether the step is correct.
AUROC That Clearly Exceeds Black-Box Methods
CRV beat existing black-box and grey-box methods across every dataset and every metric.
| Dataset | CRV (AUROC) | Strongest baseline (AUROC) | Gap |
|---|---|---|---|
| Synthetic Arithmetic | 92.47 | 76.45 (Energy) | +16.02 |
| Synthetic Boolean | 75.87 | 58.81 (MaxProb) | +17.06 |
| GSM8K | 70.17 | 62.55 (Energy) | +7.62 |
On Synthetic Arithmetic in particular, structured reasoning produces homogeneous computation traces, making the structural signature of errors easy to detect. On natural-language math like GSM8K, trace diversity grows and AUROC falls to 70.17, but CRV still clears the strongest baseline by 7.62 points.
Domain Specificity of Error Signatures
A central finding is that the structural pattern of errors depends strongly on the domain. When a CRV trained on arithmetic tasks is applied to GSM8K, AUROC drops to 57.04, falling below even the Energy baseline (62.55).
Reasoning errors in logical reasoning, arithmetic computation, and natural-language reasoning manifest as different computational patterns inside the model. Building a “universal internal verifier” faces a major obstacle, and per-domain retraining is required.
Causal Repair via Intervention
CRV’s most striking result is causal repair of the detected error.
In computing the arithmetic expression \(7 \times ((5+9)+7)\), the model miscalculated \(7 \times 14 = 98\) (the correct path is \(14+7=21\), then \(7 \times 21 = 147\)). After CRV flagged this step as incorrect, feature-importance analysis identified a late-layer PLT feature (multiplication-related, ID 91814) firing abnormally — a premature multiplication.
Inserting a forward hook that clamps this feature’s activation to 0 caused the model to correctly produce \(14+7=21\) and reach the right answer. Conversely, amplifying under-active features can also repair the error.
That is, the structural signatures CRV picks up are causally implicated in reasoning errors, not merely correlated with them.
Limitations
CRV has high value as a research tool, but is heavy as a practical verifier.
- Compute cost: training the PLT, building attribution graphs, and extracting features at each step is expensive — too costly as a drop-in verifier.
- Domain specificity: as noted above, retraining is required.
- Limited scope: it targets autoregressive CoT of standard instruction-tuned models and does not yet handle advanced reasoning models with explicit search or backtracking.
External and Internal Signals as Complements
CRV and the externally observed black-box methods (DeepConf-family logits, Self-Consistency-family trace agreement, FSF’s reasoning graph, prefix-regeneration agreement, etc.) are not in opposition — they are complementary.
- CRV shows from the inside that “correct and incorrect reasoning have different computational patterns within the model.”
- The external-observation methods capture that difference indirectly through different signal sources.
CRV gives a mechanistic background for “why external signals can work.” Correct reasoning may have internally stable computation patterns, so traces of that stability can plausibly leak into external observations (consensus across traces, logits, regeneration agreement, etc.).
In practice, the external-signal family that works through API access alone (see Self-Consistency and Weighted Majority Voting) is the realistic choice; CRV is best placed as a research tool that illuminates the internal mechanism behind those external signals.
FSF’s reasoning graph (Feng et al. 2025) and CRV’s attribution graph (Z. Zhao et al. 2025) are both called “graphs,” but operate at fundamentally different levels of abstraction.
- FSF’s reasoning graph: the CoT text is parsed by an external LLM and the logical dependencies between reasoning steps are turned into a graph. A text-level structure.
- CRV’s attribution graph: a visualization of neuron activations and information-propagation paths inside the model. A computation-level structure.
The former captures the structure of “what the model said,” the latter the structure of “how the model computed.” Combining the two opens substantial room for building higher-order aggregators.
Four Habits of Highly Effective STaRs: Classifying the Trace’s “Shape”
The three works so far measure structure with continuous-valued indicators (NLDD, FSF, AUROC). Gandhi et al.’s “Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs” (Gandhi et al. 2025) complements this qualitatively. It classifies the “shape” of a trace into four cognitive patterns and asks which patterns a self-improving reasoning model possesses.
The Qwen-vs-Llama Contrast
The starting point of the study is a simple observation. On the Countdown game (build a target number from given numbers and the four arithmetic operations), under identical Reinforcement Learning (RL) training conditions, Qwen-2.5-3B substantially outperforms Llama-3.2-3B.
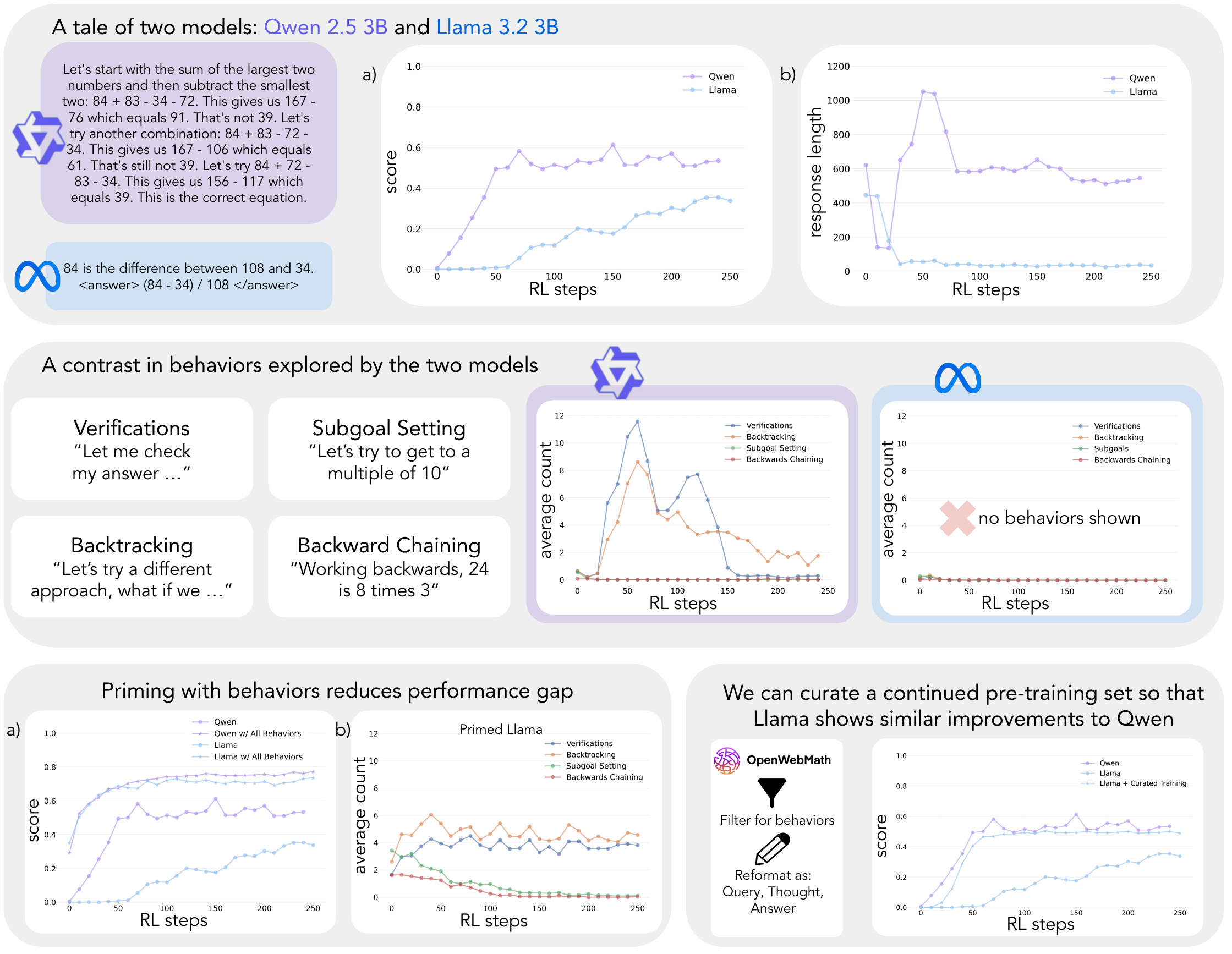
As the top row of Figure 5 shows, Qwen’s score rises steeply toward about 0.6, while Llama plateaus around 0.3 under the same RL. Response length tells the same story in mirror image: Qwen keeps stretching its traces as it improves, while Llama stays with short traces.
The Four Cognitive Patterns
The “contrast in behaviors” panel in the middle row pinpoints the cause. Qwen’s traces show four cognitive patterns frequently.
- Verification: a self-check that intermediate results are correct (e.g. “Let me check my answer…”)
- Backtracking: when stuck, going back a step and trying a different approach (e.g. “Let’s try a different approach, what if we …”)
- Subgoal setting: decomposing a large problem into smaller subproblems (e.g. “Let’s try to get to a multiple of 10”)
- Backward chaining: identifying intermediate results needed by working backward from the goal (e.g. “Working backwards, 24 is 8 times 3”)
Llama has essentially none of these. In the middle-right plot, all behavior counts on the Llama side hug zero.
Reasoning Behaviors Matter More Than “Correctness Itself”
The most surprising finding is that the presence of reasoning behaviors matters more than whether the answer is correct. Models trained on data that contains the four cognitive patterns but with incorrect final answers perform as well as or better than models trained on correct data that lacks those patterns.
That is, a model’s capacity for self-improvement depends not on memorizing correct answers but on acquiring “the way of doing reasoning effectively.”
Behavior Priming Closes the Gap
The bottom row of Figure 5 shows the priming experiment. Pre-training Llama on examples containing the four cognitive patterns (“Llama w/ All Behaviors”) starts the model on a trajectory close to Qwen’s. Continued pre-training on an OpenWebMath subset curated for these cognitive patterns (“Llama + Curated Training” on the bottom right) closes the score gap substantially.
This result shows that the four cognitive behaviors are learnable and a precondition for self-improvement via RL. The cognitive patterns the base model possesses end up setting the ceiling for downstream RL post-training.
Relation to Aggregation Methods
The Four Habits, with their qualitative classification of trace “shape,” sit alongside the quantitative indicators of Reasoning Horizon / FSF / CRV by providing a cognitive interpretation of what those indicators are measuring. Gandhi et al.’s four behaviors (verification, backtracking, subgoal setting, backward chaining) appear as cognitive patterns internalized inside the trace; the aggregation methods in Self-Consistency and Weighted Majority Voting can be read as measuring the extent to which these leak out as externally observable signals. A trace dominated by frequent backtracking, for example, tends to have high FSF and may also exhibit less stable behavior under prefix-based regeneration.
Synthesizing the 4 Perspectives
All four works in this chapter concretize the same motif — “measure the structure of reasoning at inference time” — through different entry points. Table 2 organizes them.
| Work | Object of analysis | Core finding | Implication for aggregation |
|---|---|---|---|
| Reasoning Horizon (Ye et al. 2026) | Causal influence decay | Tokens past \(k^*\) are causally vacuous | Physical grounding for the cut position of prefix-based methods |
| FSF (Feng et al. 2025) | Text-level reasoning graph | Abandoned-branch fraction is a stronger predictor than length or review | A black-box approximation candidate for regeneration-based methods |
| CRV (Z. Zhao et al. 2025) | Internal attribution graph | Correct/incorrect steps have different internal circuits (AUROC 92.47) | Mechanistic background for why external signals work |
| Four Habits (Gandhi et al. 2025) | Cognitive behavior patterns | The four behaviors matter more than correctness | Cognitive interpretation of aggregation-side signals |
Complementarity with Aggregation
The methods here are orthogonal to the aggregation methods in Self-Consistency and Weighted Majority Voting. Aggregation takes “consensus across multiple traces” as its signal; the methods in this chapter take “the structure of a single trace” as theirs. In principle they compose, and the following recipes emerge naturally.
- Structural selection + aggregation: compute FSF for each trace, then run weighted majority voting on the subset of traces with FSF below a threshold.
- Structural early stopping: stop at \(k^*\) following the Reasoning Horizon, and execute Self-Consistency on prefixes truncated at that point.
- Internal + external + cognitive: train a meta-aggregator on three inputs — CRV’s internal signal, the external signal from prefix-based methods, and the cognitive patterns from Four Habits.
Structural indicators and aggregation indicators leave plenty of room for higher-order signal fusion.
Open Questions
Each of the four works carries its own open question.
- Reasoning Horizon: in the Anti-Faithful regime (Gemma), does \(k^*\) retain the same meaning? If the CoT is causally disconnected from the internal representation, what is the \(k^*\) on the verbalized CoT actually measuring?
- FSF: it depends on graph extraction by an external LLM (Claude 3.7 Sonnet). The accuracy and consistency of the extractor cap the precision of FSF. Self-hosted lightweight extractors deserve study.
- CRV: compute cost and domain specificity. Value as a research tool is established, but its place as a practical verifier is unsettled.
- Four Habits: the definitions of cognitive patterns are heuristic. Are four enough? Could a coarser or finer taxonomy serve better? How universal are these patterns across domains?
Reading Reasoning at Inference Time
Together with aggregation (Self-Consistency and Weighted Majority Voting), confidence estimation (Confidence and Uncertainty), and test-time compute scaling (Test-Time Compute Scaling), the structural approach treated in this chapter is becoming the fourth pillar of the family that extracts signal from reasoning traces at inference time.
- Aggregation: measures the consensus of multiple traces.
- Confidence: measures the token distribution of a single trace.
- Compute scaling: decides the budget allocation for trace count and length.
- Structure (this chapter): measures the shape of a single trace.
The four lines independently attack the same problem — “how do we estimate the correctness of reasoning without ground truth?” — from different angles, and that is a defining feature of contemporary reliable-reasoning research. The structural approach in this chapter, by treating the CoT not as a homogeneous token sequence but as a structured object with a causal gradient, a branching structure, internal circuits, and cognitive patterns, opens a new axis of signal that length and confidence cannot reach.