Self-Consistency and Weighted Majority Voting
When a Large Language Model (LLM) is asked to solve problems with Chain-of-Thought (CoT), trusting a single reasoning trace is fragile. Stochastic decoding produces different intermediate steps for the same problem each time. Since Self-Consistency (X. Wang et al. 2023) was proposed, the framework of sampling N traces independently and aggregating them has become a basic tool for LLM reasoning.
Research in 2025–2026 has extended this framework in four major directions. The first is weighting at aggregation time: assign a confidence to each sample and replace simple majority voting with weighted majority voting. The second is leveraging prefixes: sample multiple continuations from a short prefix and predict the answer from agreement rate or confidence. The third is the theoretical foundation: the conditions under which weighted majority voting dominates simple majority voting, and its optimality, are being formalized. The fourth is adaptive sampling: dynamically determining the sample size N depending on the problem. This chapter organizes the related work along these four axes.
Basic Tools: Self-Consistency and Universal Self-Consistency
The idea of Self-Consistency (X. Wang et al. 2023) is simple. Sample N reasoning chains independently from the LLM for the same problem, collect the final answer \(a_i\) from each chain, and take the mode.
\[ \hat{a} = \arg\max_{a} \sum_{i=1}^{N} \mathbf{1}\{a_i = a\} \tag{1}\]
Wang et al. showed that this simple majority vote achieves substantially higher accuracy than greedy decoding on GSM8K and MultiArith. The intuition behind it is that “there are multiple reasoning paths that lead to the correct answer, but the paths that lead to wrong answers tend to vary.”
A naive extension of Self-Consistency is Universal Self-Consistency (USC). USC lets the LLM itself select “the most semantically majority answer” for free-form outputs that cannot be aggregated by exact match. This makes majority voting applicable to summarization and open-ended QA.
Equation 1 makes two strong assumptions: (i) each sample has equal weight, and (ii) agreement among answers is judged by exact match. Research in 2025–2026 has unfolded in directions that relax both.
Weighting Systems: Attaching Confidence Weights to Each Sample
A weighted majority vote (WMV) extracts a confidence signal \(s_i\) from each sample \(i\), passes it through a weighting function \(w(\cdot)\), and turns it into a voting weight:
\[ \hat{a} = \arg\max_{a} \sum_{i=1}^{N} w(s_i) \cdot \mathbf{1}\{a_i = a\} \tag{2}\]
The organizing axes are (1) where \(s_i\) comes from, (2) how the weighting function \(w\) is designed, and (3) whether weights are placed only on the sample’s own answer \(a_i\) (per-sample) or also on arbitrary answers that appear via regeneration (per-candidate). In this chapter we classify the methods primarily by the source of \(s_i\).
Token Logprob: A Family of Trace-Level Confidence Signals
Deep Think with Confidence (DeepConf) (Fu et al. 2025) is a family of trace-level confidence signals. Meta AI presented it as a Spotlight at the NeurIPS 2025 Efficient Reasoning Workshop. From the top-20 token log-probabilities \(\{P_{t,j}\}_{j \leq 20}\), the paper computes \(C_t = -\frac{1}{20}\sum_{j=1}^{20}\log P_{t,j}\) and then aggregates it into a trace score in five different ways:
| Name | Definition |
|---|---|
| First-token | KL divergence between the top-20 distribution at the first generated token position and the uniform distribution |
| Mean | \(\tfrac{1}{|y|}\sum_t C_t\) (simple average across the entire trace) |
| Bottom-10% | Average of the lowest 10% of sliding-window means of \(C_t\) (window 1024) |
| Block-min | Minimum among block averages, where blocks are split by double newlines |
| Tail | Average of \(C_t\) over the last 2,048 tokens |
The aggregation is a WMV with \(w(s) = s\) (identity), giving \(v_i(a) = s(y_i, \ell_i) \cdot \mathbf{1}\{a_i = a\}\). The paper further introduces a confidence filtering variant that keeps only the top \(\eta\)% of traces by signal before voting.
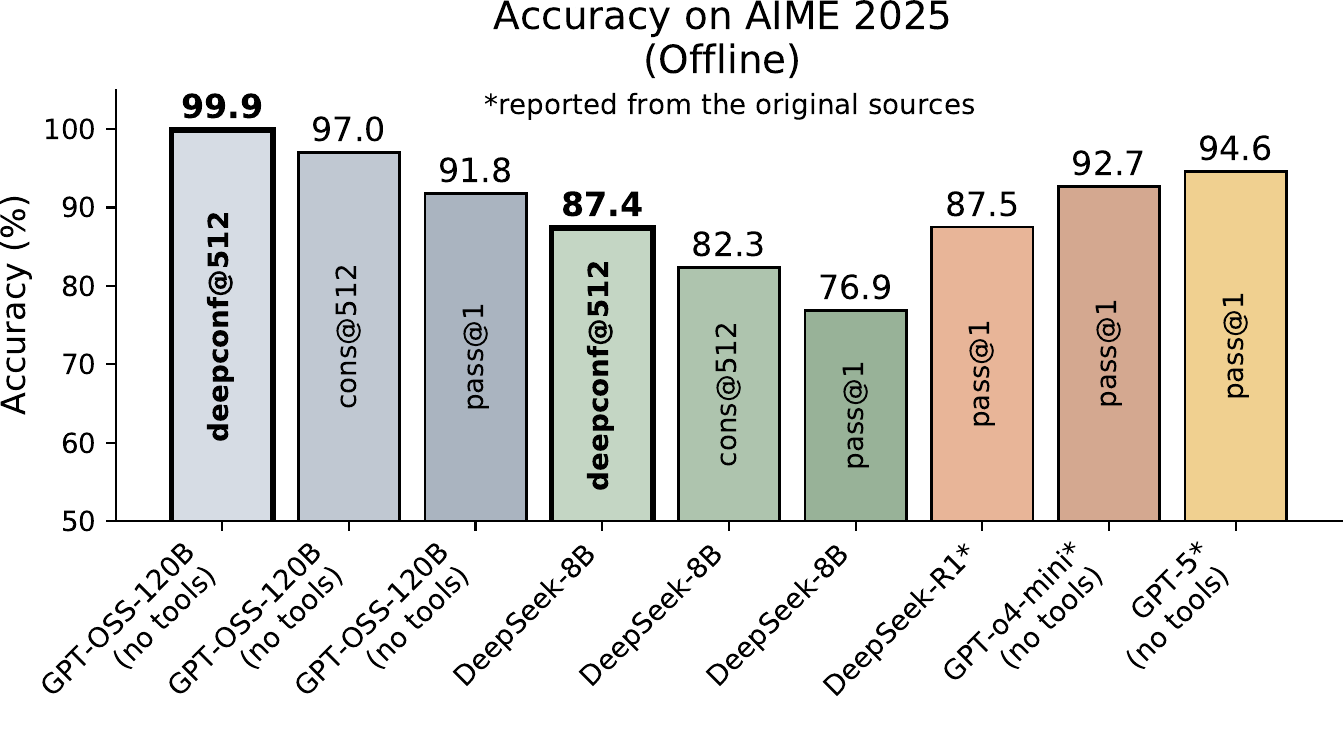
Figure 1 shows the overview. The headline result, AIME 2025 with GPT-OSS-120B, where DeepConf@512 reaches 99.9% accuracy, surpassing standard majority voting at 97.0% while reducing generated tokens by 84.7%, comes from a specific configuration that combines the bottom-10%/tail signals with confidence filtering and early termination — it is one particular variant in the family (Figure 2).
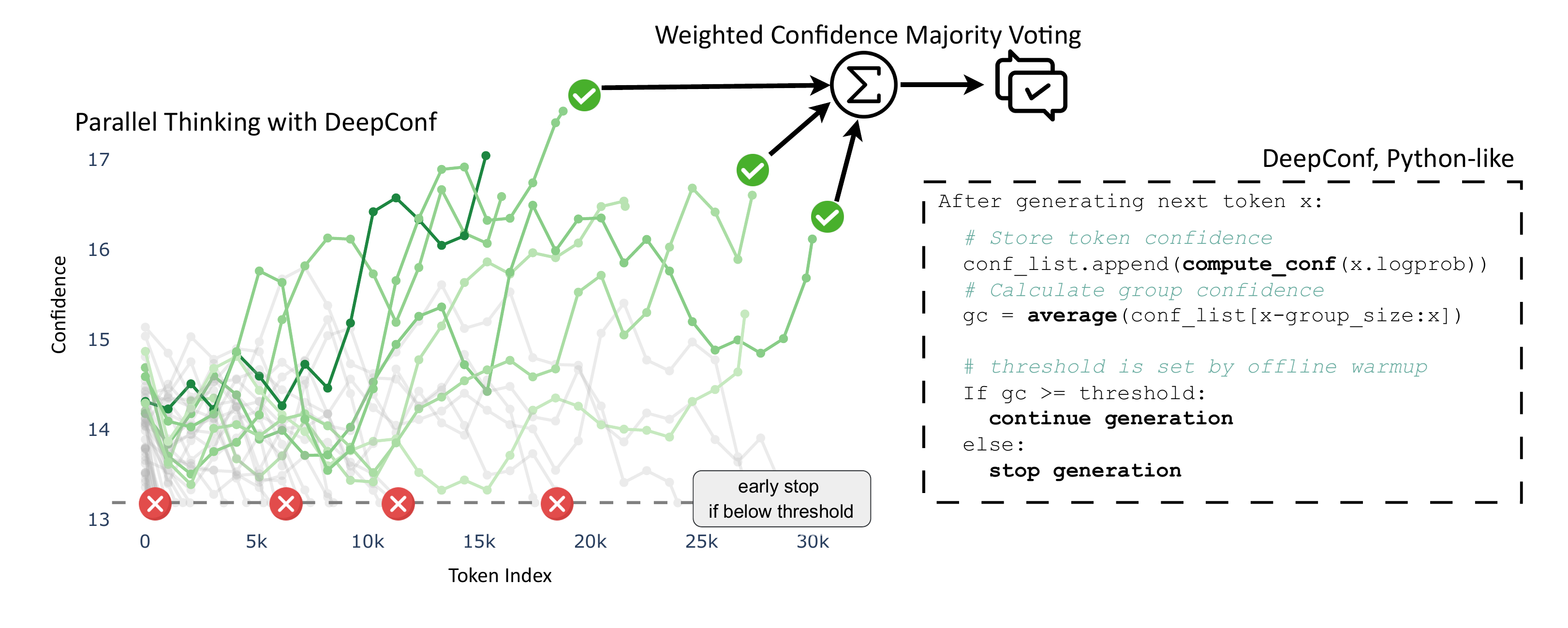
DeepConf assumes access to token log-probabilities (grey-box), so it is unusable on APIs that do not return log-probabilities. Independent reports also note that for hard problems with low Pass@1, the per-problem signal distributions of DeepConf’s variants largely overlap between correct and incorrect traces (Iwase et al. 2026), suggesting that the saturation of logit-based signals may set an upper bound for the entire weighting family.
Other Logit/Entropy Representatives: Self-Certainty, CER, IEW
DeepConf’s “Mean” variant corresponds to a top-20 approximation of Self-Certainty (Kang et al. 2025). Self-Certainty is defined as the trace-level mean of the Kullback–Leibler (KL) divergence between the full-vocabulary token distribution and the uniform distribution, and it was proposed as a reward-model-free Best-of-N signal (accepted at NeurIPS 2025). Combined with Borda voting, it surpasses SC and generalizes to open-ended generation. Figure 3 shows a typical failure case where SC votes for the wrong answer. Among six chains on the same problem, the majority answer 50 wins under SC, but measured by Self-Certainty, the chain with the correct answer 64 shows high certainty, and Borda voting reselects the correct answer.

CER (Razghandi et al. 2025) is a training-free weighting framework that, instead of averaging over the whole trace, focuses on critical decision points in the reasoning trace (numbers, proper nouns, etc.) and reads the logit-based confidence at those positions. It reports improvements of up to 7.4% on math and 5.8% on open-domain tasks.
IEW (Inverse-Entropy Voting) (Sharma and Chopra 2025) uses the reciprocal of each chain’s token-level Shannon entropy as the weight. Under the same token budget, IEW combined with sequential self-refinement outperforms parallel SC in 95.6% of configurations and achieves improvements of up to 46.7% on AIME-2024/25 and GPQA-Diamond.
DeepConf Mean, Self-Certainty, CER, and IEW differ along two axes: which logit positions to read (whole-trace mean, critical points, bottom-window, or tail) and what statistic to compute (KL, entropy, log-prob). Behind all of them lies the shared hypothesis that “correct chains differ internally on the logit side.”
Verbalized and Rating-Call Signals: The CISC Framework
CISC (Confidence-Informed Self-Consistency) (Taubenfeld et al. 2025) is not a single method but a framework that unifies existing per-sample confidence sources via softmax weighting. The original paper compares four raw-confidence sources:
| Source | Needs logprobs | Description |
|---|---|---|
| Response probability (X. Wang et al. 2023) | Yes | The length-normalized geometric mean of per-token probabilities across the trace. Already proposed as a weighted variant in the SC paper |
| Verbal binary (Lin et al. 2022) | No | A separate prompt asks the model for a {0, 1} self-rating |
| Verbal 0–100 (Lin et al. 2022) | No | A separate prompt asks the model for a 0–100 self-rating |
| P(True) (Kadavath et al. 2022) | Yes | Read the logits of “1” and “0” at the rating-call position and form a probability \(\exp(\ell_1)/(\exp(\ell_0)+\exp(\ell_1))\) |
CISC’s contributions are twofold: (a) a unified comparison of signal sources, and (b) a weighting design that turns raw confidences into sample-soft weights via a softmax with temperature \(T\). The signal sources themselves come from prior work. Figure 4 shows CISC’s aggregation procedure alongside SC.
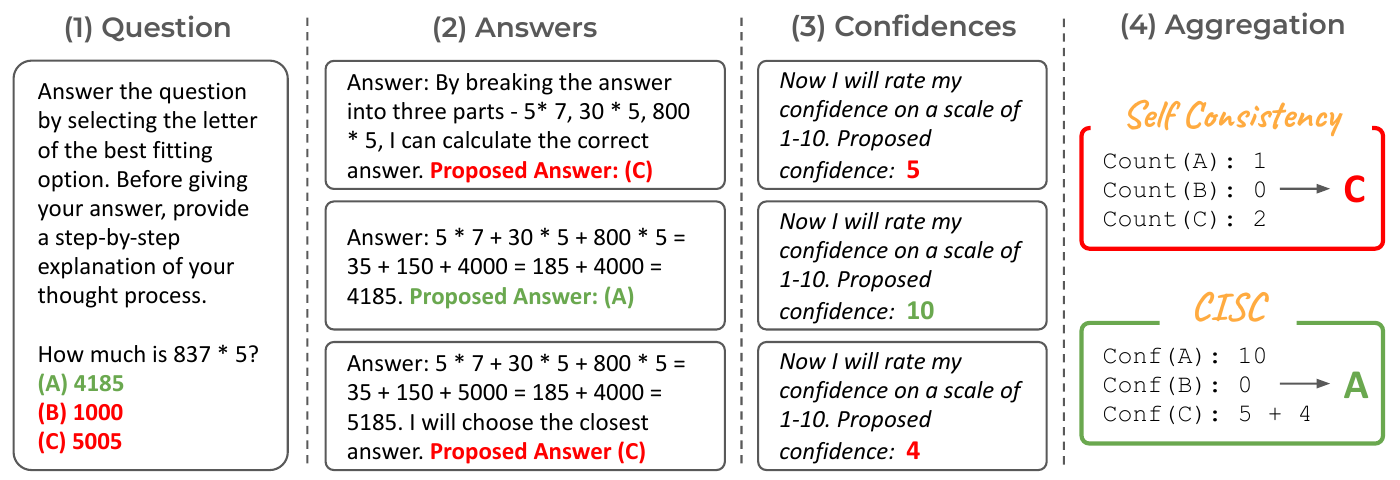
Multiple studies have independently reported that verbalized confidence is poorly calibrated. DINCO (V. Wang and Stengel-Eskin 2025), at ICLR 2026, empirically demonstrated that “LLMs’ verbalized confidence is overconfident” and proposed a method to normalize it with self-generated distractors. Within the CISC framework, Verbal binary and Verbal 0–100 frequently appear as the weakest sources, while stronger sources tend to be P(True) and Response probability.
External-Consistency-Based Signals: Confidence from Regeneration or Agreement
The methods above extract \(s_i\) from inside sample \(i\) (logits or verbalized rating). A different line constructs signals from the relations between samples or from regeneration behavior. Prefix Consistency (Iwase et al. 2026) truncates the CoT at a ratio \(\tau\), regenerates the continuation from the prefix, and aggregates the per-candidate rate at which the regenerations return to each candidate answer, feeding the result into WMV. We organize this method alongside others that share the same regeneration operation in the next section on prefix-based methods. NAD (Neuron Agreement Decoding) (Chen et al. 2025) is based on the finding that the neurons activated for correct answers are fewer and agree more strongly across multiple samples, and performs Best-of-N using only internal neuron agreement. External observation (regeneration agreement) and internal observation (neuron agreement) both measure the same hypothesis that “correct chains are structurally reproduced across samples” at different granularities.
Prefix-Based Methods: Predicting Continuations from Short Prefixes
The second direction is a line of work that uses the prefix of the reasoning trace as the starting point for aggregation. It is characterized by multiple independent groups arriving at this direction almost simultaneously, concretizing the common hypothesis that prefixes predict the answer through different operations: weight design, cluster selection, early truncation, and regeneration.
Prefix Clustering: Selecting Paths to Expand
PoLR (Path of Least Resistance) (Jindal et al. 2026) is an inference-time method that clusters short prefixes and fully expands only paths belonging to the most frequent cluster. It theorizes that “early reasoning steps predict final correctness” using mutual information and entropy, and on GSM8K, MATH500, AIME24/25, and GPQA-Diamond, it reduces tokens by up to 60% and wall-clock time by 50% while maintaining accuracy equal to or above SC. Accepted at ICLR 2026.
Prefix Confidence: Narrowing to One
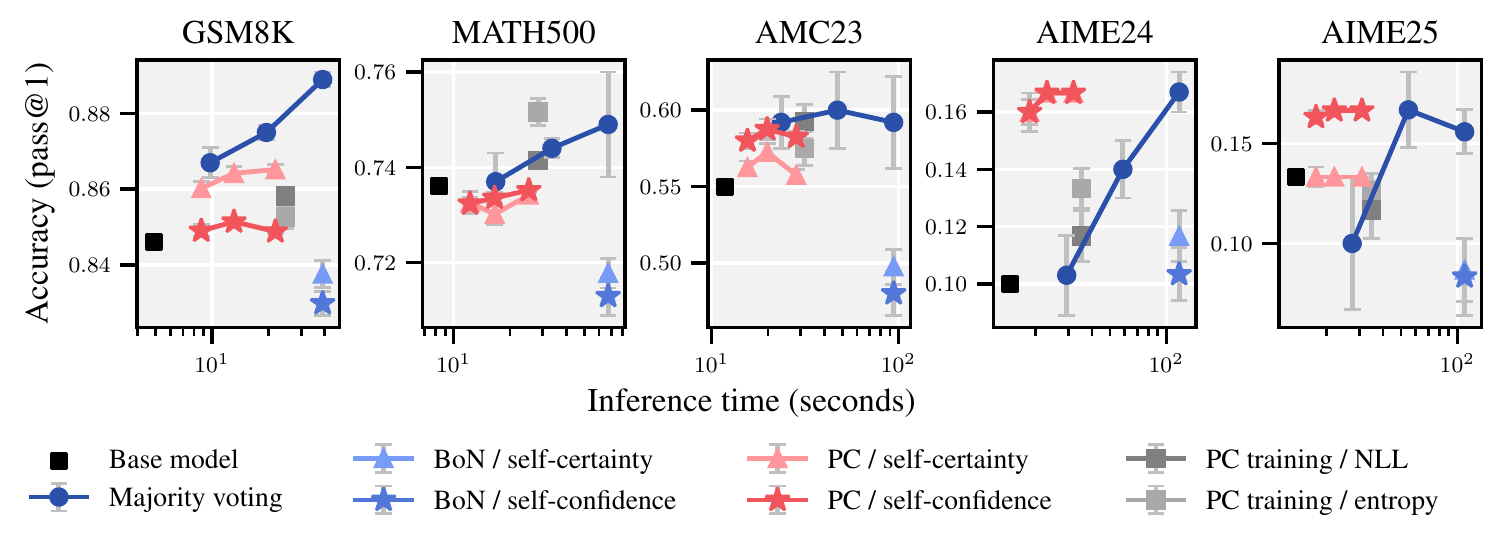
Prefix-Confidence Scaling (Otth et al. 2025) generates only 32-token short prefixes, measures the prefix-confidence of each candidate, and continues only the most promising one. It shows a better accuracy–compute tradeoff than majority voting on all of GSM8K, MATH, AMC, and AIME, and reports robustness to length bias. Figure 5 shows the inference time vs. accuracy curves on five math benchmarks. Each point corresponds to a different budget setting, and the configurations using prefix-confidence (red-tone markers) outperform majority voting (blue) at equivalent time or reach equivalent accuracy at less time.
Path-Consistency: Strengthening SC with Frequency
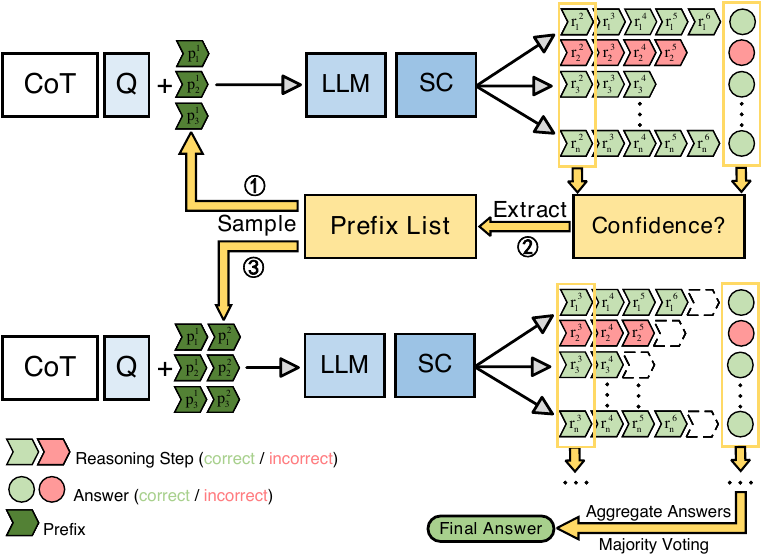
Path-Consistency (Zhu et al. 2024) strengthens SC by maintaining multiple promising prefixes in a Prefix List in parallel and growing each candidate as a starting point. The procedure in Figure 6 is staged: at each window boundary, when the majority-answer count exceeds the beta-confidence threshold, the optimal paths that reached that majority answer are inspected and their shared level-\(\ell\) prefix is added to the Prefix List as an entry. Each candidate’s level grows by one with each iteration. In later stages, only the continuation after any prefix in the Prefix List needs to be generated, so SC can be executed while reducing the token volume. The original paper formalizes the final-answer distribution as a marginalization over the Prefix List,
\[ P(a \mid q) \;=\; \sum_{R_{\mathrm{prefix}} \in \mathcal{P}} P(R_{\mathrm{prefix}} \mid q)\, P(a \mid q, R_{\mathrm{prefix}}) \tag{3}\]
which makes explicit that the Prefix List \(\mathcal{P}\) is a multi-candidate set rather than a single trunk. The \(p_1, p_2, p_3\) that appear stacked vertically in Figure 6 are distinct entries of \(\mathcal{P}\), and in the next iteration each candidate grows by one level independently (\(p_i^1 \to p_i^1 + p_i^2\)).
Speculative Truncation: Early Pruning
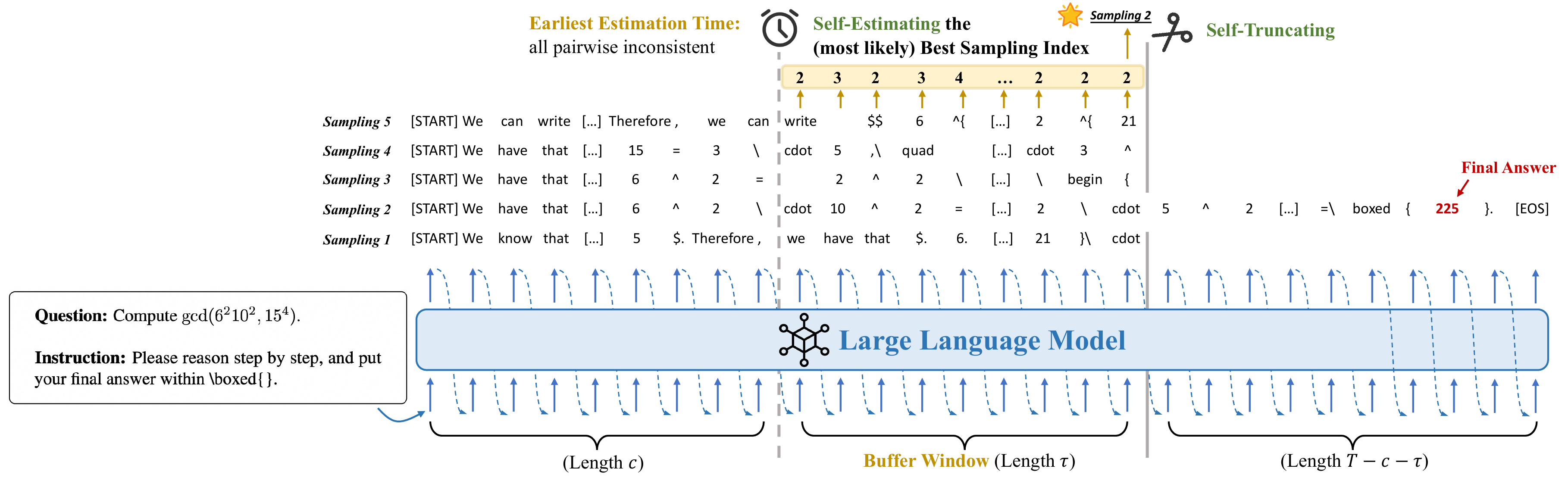
ST-BoN (Self-Truncation Best-of-N) (Y. Wang et al. 2025) measures “internal sampling consistency” at an early decoding stage and truncates unpromising candidates. It achieves reductions of 80% in GPU memory, 50% in latency, and 70–80% in compute. NeurIPS 2025 Spotlight. As shown in Figure 7, by examining inter-sample internal agreement at an early “earliest estimation time” and pruning all but the most promising sample (sampling 3 in the figure), it greatly saves subsequent generation cost.
Subthought-Based Decomposition and Regeneration: Mode Aggregation
Beyond the Last Answer (Hammoud et al. 2025) splits the reasoning trace into multiple subthoughts using linguistic markers, regenerates a continuation from each split point, and takes the mode of the resulting answers. It is a direct precursor to Prefix Consistency (Iwase et al. 2026) and shares the operation of regenerating from a prefix.
Concretely, the CoT is split into \(s_1, s_2, \dots, s_n\) at markers such as "Wait", "Hmm", "Alternatively", "Actually", "Therefore", "So", "First", "Next" — markers signaling reflection, alternative exploration, correction, or transition to a conclusion. From each prefix \(s_1 \oplus \cdots \oplus s_j\), a continuation is regenerated and an answer \(A_j\) is extracted. The final answer is
\[ A_{\text{mode}} = \arg\max_{A} \sum_{j=1}^{n} \mathbf{1}\{A_j = A\} \tag{4}\]
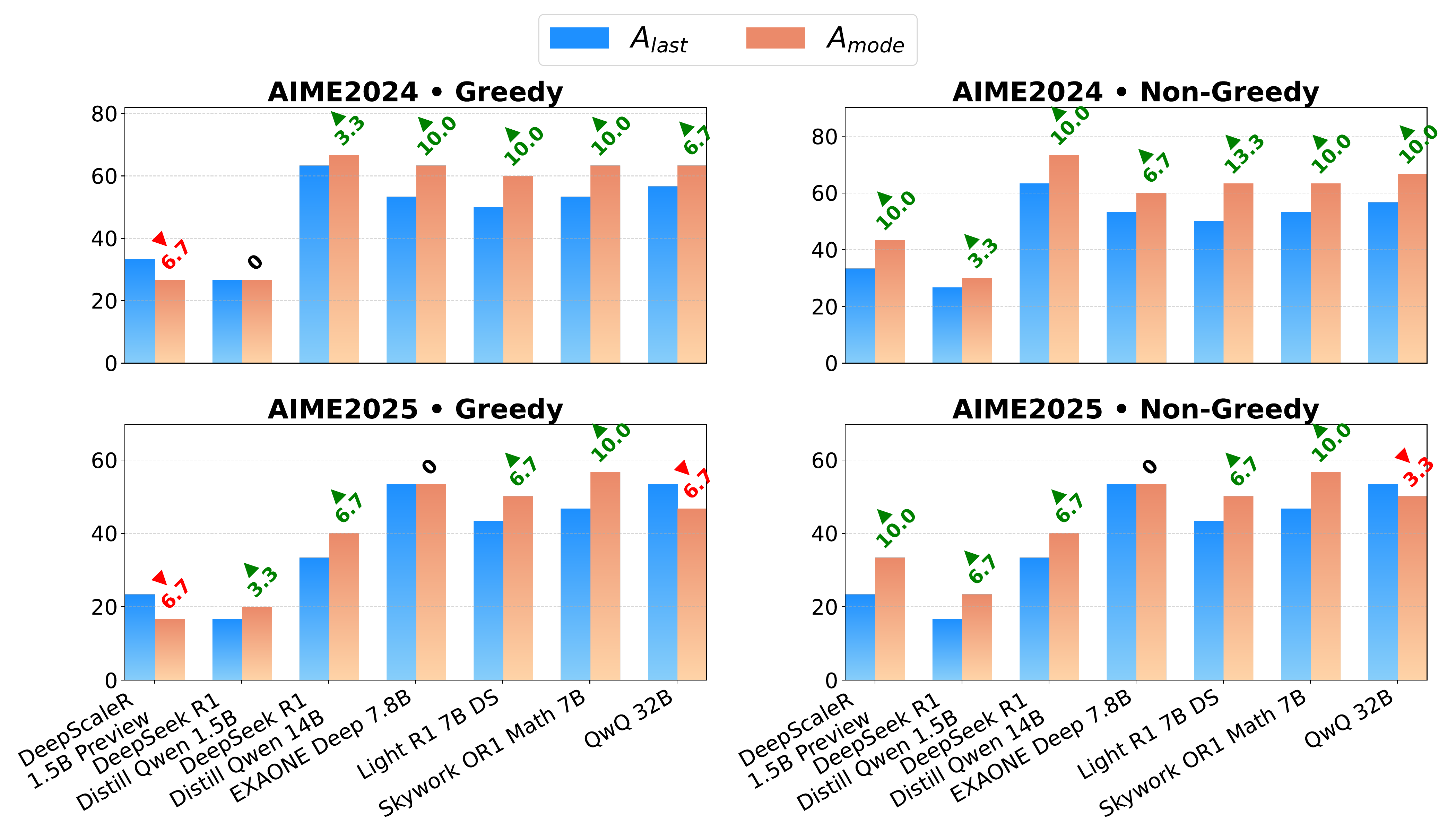
Figure 8 shows a typical case where the last subthought returns the incorrect answer 50, while the mode of answers regenerated from earlier subthoughts is the correct 96. The finding is that a reasoning trace carries information beyond just the final answer, and aggregating regenerations from intermediate stages can rescue a hidden majority.

The reported gains are substantial — up to +13% on AIME 2024 and +10% on AIME 2025 across multiple reasoning models (Figure 9). The paper also reports that the agreement pattern of answers across subthoughts correlates with both confidence and correctness.
Prefix Consistency (Iwase et al. 2026) differentiates from this work by replacing the aggregator over regenerations from mode to the rate of returning to the original answer, and using that rate as the weight source in WMV. The next subsection picks up that thread.
Prefix Consistency: Measuring Confidence via Regeneration
Prefix Consistency (Iwase et al. 2026) truncates the CoT at a ratio \(\tau\), regenerates the continuation from the prefix, and uses the rate of returning to the original answer as the voting weight. While riding on the weighting framework (Equation 2), it adopts prefix-regeneration consistency as the source of weights. Whereas Beyond the Last Answer (Hammoud et al. 2025) is a training-free aggregator that uses the mode as the final answer, Prefix Consistency turns the agreement rate itself into a continuous weight that flows into WMV — extracting a different signal from the same operation.
Same Hypothesis, Different Operations
Table 1 lists the methods that start from prefixes. The common hypothesis is that “short prefixes predict the correctness of the final answer,” and each method concretizes it through a different operation.
| Method | Use of prefix | Output |
|---|---|---|
| PoLR (Jindal et al. 2026) | Cluster and select the dominant cluster | Set of paths to expand |
| Prefix-Confidence Scaling (Otth et al. 2025) | Select top-1 by confidence | A single chain |
| Path-Consistency (Zhu et al. 2024) | Strengthen SC by occurrence frequency | Weighted majority vote |
| ST-BoN (Y. Wang et al. 2025) | Prune early | Set of surviving paths |
| Beyond the Last Answer (Hammoud et al. 2025) | Split by linguistic markers and regenerate from each point | Mode of regenerated answers |
| Prefix Consistency (Iwase et al. 2026) | Regenerate and measure return-to-original-answer rate | Weighted majority vote |
The fact that the observation “prefixes carry the answer” was obtained independently by multiple groups serves as supporting evidence for the hypothesis that prefixes are a load-bearing element in reasoning.
PoLR (Jindal et al. 2026) and Path-Consistency (Zhu et al. 2024) are isomorphic peers that both exploit a skew over the set of prefixes to make SC more efficient. Their names are also confusingly close — “Prefix Consensus” (PoLR), “Path-Consistency,” and “Prefix Consistency” (Iwase et al. 2026) — but structurally they form symmetric variants.
| Axis | Path-Consistency | PoLR |
|---|---|---|
| Signal | Exact prefix frequency \(\mathrm{count}(p) / N\) | Cluster size share under TF-IDF lexical similarity \(\lvert C^{*} \rvert / N\) |
| Expansion strategy | Sequential extract-and-sample (iteration per window) | One-shot (sample short prefixes → cluster → expand the dominant cluster) |
| Candidate extraction | Confidence-gated (beta-confidence above threshold) | Clustering-based (TF-IDF agglomerative + dominant cluster) |
| Main objective | Latency / token reduction | Token / latency reduction + orthogonal pre-filter for Adaptive Consistency (AC) / Early-Stopping SC (ESC) |
| Box-ness | Black-box | Black-box |
| Signal granularity | Prefix exact frequency | Cluster skew over the set of prefixes |
The two share the framework of “repurposing the skew over a prefix set into SC efficiency,” and differ symmetrically only in the measure (exact frequency vs lexical cluster) and the expansion strategy (sequential vs one-shot). In Related Work, the two can be treated as “twins inside the (5) trajectory agreement axis.”
Theoretical Foundation: Weighted Majority Voting Is MAP Optimal
That weighted majority voting dominates simple majority voting has recently been theoretically supported at ICLR 2026.
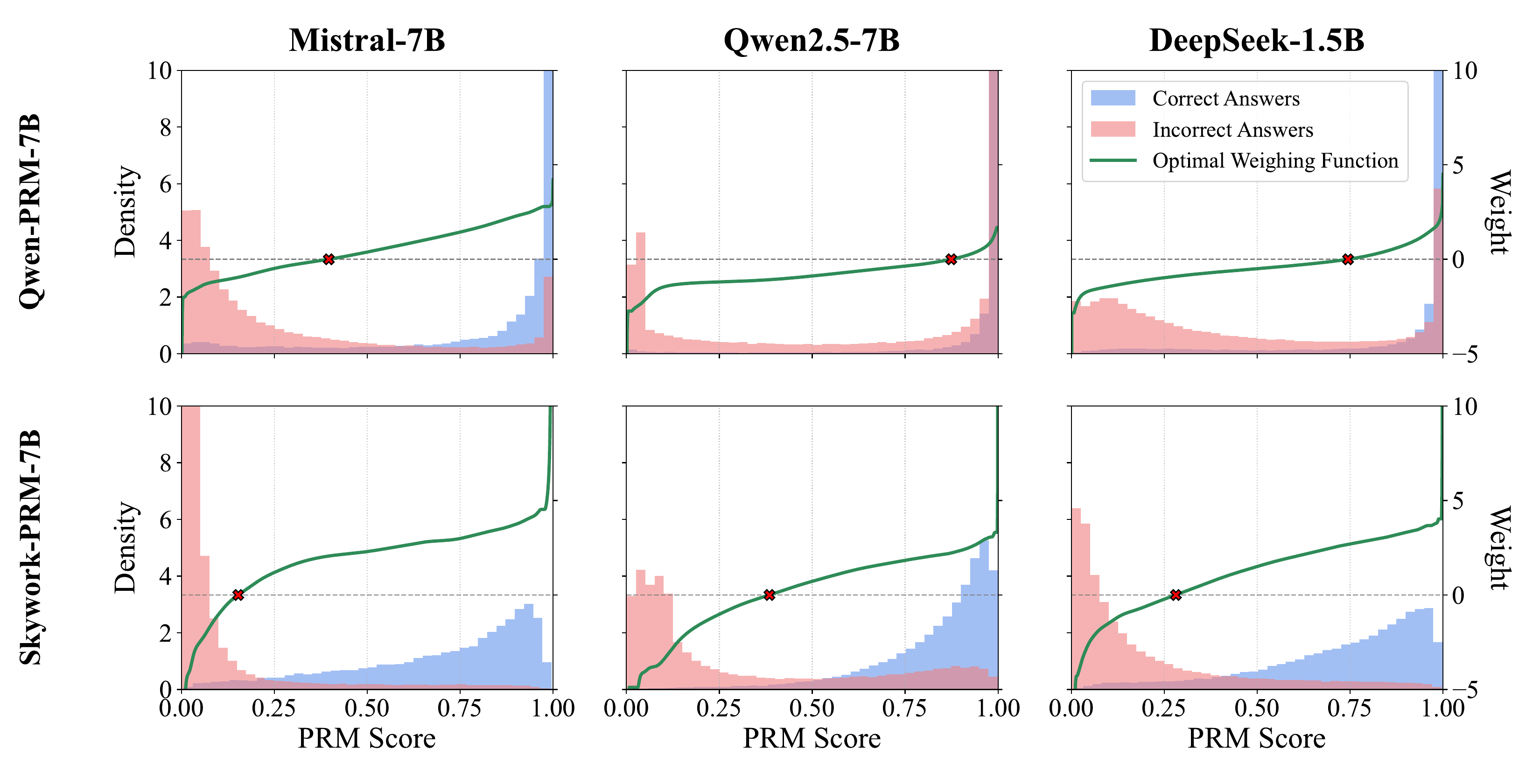
Kuang et al.’s work (Kuang et al. 2025) formulates the aggregation problem as MAP estimation that optimally combines the LLM signal and the Process Reward Model (PRM) signal. The result theoretically shows that calibrated weighted majority vote, rather than simple best-scoring selection, is optimal, and it reduces test-time compute by 37.1% / 21.3%. Figure 10 shows the shape of the derived optimal weight function. When the PRM score distributions for correct/incorrect differ, the optimal weights vary nonlinearly rather than linearly with the PRM score, rising sharply on the high-score side.
Ai et al.’s work (Ai et al. 2025) argues that “majority voting is only zero-order aggregation, and one should exploit each model’s expected accuracy (first order) and answer correlation (second order),” and proposes two algorithms, Optimal Weight (OW) and Inverse Surprising Popularity (ISP), with theoretical analyses. It outperforms majority voting by 1.16–3.36% on UltraFeedback, MMLU, and ARMMAN.
Best-of-∞ (Komiyama et al. 2026) analyzes the \(N \to \infty\) limit of majority-vote Best-of-N and proposes an adaptive generation scheme to deliver equivalent performance with a finite budget. It further extends to weighted ensembles of multiple LLMs and formulates the optimal weights as a mixed-integer linear program (MILP). Accepted at ICLR 2026.
In a different direction, AggLM (Zhao et al. 2025) takes the approach of “learning the voting function itself with RL.” It trains an aggregator LM that synthesizes the correct answer from multiple candidate solutions using verifiable rewards, and shows that it outperforms both majority voting and reward re-ranking. It can be positioned as an upper bound for training-free WMV methods.
Adaptive Sampling and Early Stopping: Dynamically Determining N
SC with a fixed N is simple but wasteful. Research that formalizes the intuition “easy problems need few N, hard problems need many N” surged in 2025–2026.
Bayesian / SPRT Methods
BEACON (Wan et al. 2025) is based on Sequential Search with Bayesian Learning. It sequentially updates the posterior belief over the reward distribution and “stops when the marginal utility of additional generation falls below the cost.” It reduces the average sample size by up to 80%.
ReASC (Reliability-Aware Adaptive Self-Consistency) (Kim et al. 2026) models the support rates of the top two candidates \(p\) with a Beta distribution, converts each sample’s reliability \(z(y_i)\) (a standardized bottom-10% confidence) into an “amount of evidence” via \(\max(1, \exp(\lambda z))\), and updates the posterior sequentially. When the posterior probability \(P(p_1 > p_2 \mid V)\) exceeds a threshold (typically 0.95), sampling stops, which scales the sampling cost to the difficulty of the problem. Across five models including Gemma-3-4B and Qwen-2.5-7B and four benchmarks including GSM8K, it reports a roughly 70% cost reduction while matching SC (k=16) accuracy. Figure 11 shows the framework. It is a two-stage design: Stage 1 decides immediately if the reliability of the very first sample exceeds the gate \(\tau_{\text{gate}}\); otherwise, Stage 2 runs a reliability-weighted Beta update.
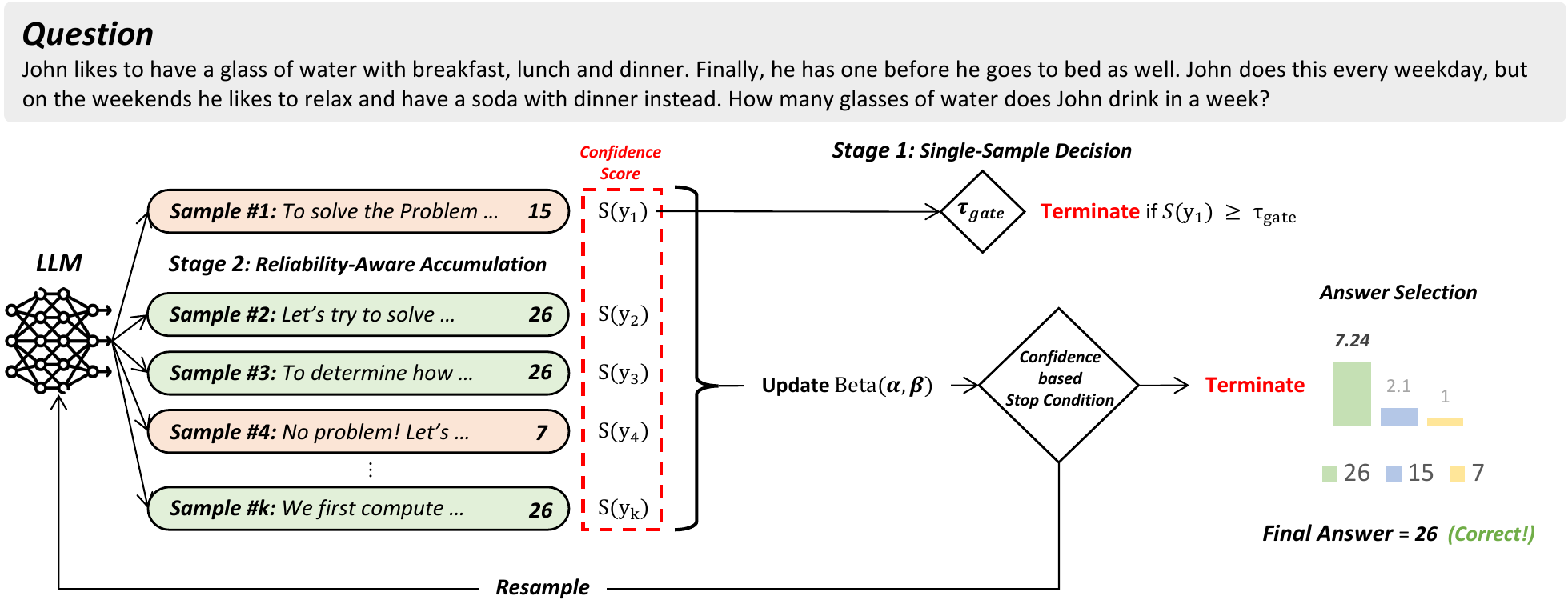
ReASC is conceptually close to Best-of-∞ (Komiyama et al. 2026). Both share the skeleton of “update a posterior belief over the answer distribution in a Bayesian manner, and stop once additional samples only contribute marginally.” Bo∞ uses the scalar reward from a reward model as evidence, while ReASC uses self-confidence derived from token logprobs. BEACON, CGES, ReASC, and Bo∞ converge on the structure signal sources differ, but the stopping rule is the same Bayesian update, indicating that the design space of weight × stopping rule combinations is still largely unexplored.
CGES (Aghazadeh et al. 2025) builds posterior distributions over each candidate answer using token probability or a PRM-derived scalar signal, and stops when the posterior mass exceeds a threshold. NeurIPS 2025 Workshop on Efficient Reasoning.
ConSol (Lee et al. 2025) calibrates the classical Sequential Probability Ratio Test (SPRT) for LLM self-consistency and stops the moment sufficient consistency is reached.
Verbal Confidence + Small Samples: A Withdrawn Claim
Two Samples Are Enough: Verbal Confidence Meets Self-Consistency in Reasoning LLMs (Del et al. 2026) was withdrawn after submission to ICLR 2026 (OpenReview ID: 66D3rZrNjV). The following is recorded as reference information, not as a peer-reviewed confirmed result.
The claim is simple: comparing six verbalized-confidence (VC) methods, SC, and a hybrid (VCSC) across nine scientific benchmarks and three reasoning models, the paper argues that two samples plus verbal confidence can match or exceed the reliability evaluation of 16–64 sample SC. If this holds, the number of inference samples could be cut by an order of magnitude, but verbalized confidence is well known to be poorly calibrated and prompt/model-dependent (see CISC (Taubenfeld et al. 2025) and DINCO (V. Wang and Stengel-Eskin 2025)). The calibration profile of reasoning models also differs from that of standard LLMs, so the claim should be treated as one requiring further replication and verification.
Budget Allocation Methods
SeerSC (Ji et al. 2025) uses System 1 to quickly compute answer entropy and pre-estimate the “required sample size” for each problem, and uses System 2 to generate that many in parallel. Unlike sequential ASC/ESC, it is compatible with parallel execution and reduces tokens by 47% and latency by 43%.
PETS (Liu et al. 2026) defines self-consistency rate as the “agreement rate with majority vote under an infinite budget” and optimizes trajectory allocation under a limited budget. It gives offline allocation based on crowdsourcing theory and an online allocation algorithm responsive to difficulty, reducing the budget by 75% on GPQA.
Pruning Methods
Token Set Cover (Sultan and Astudillo 2025) periodically prunes unnecessary hypotheses mid-SC via a weighted set cover that combines model confidence and lexical coverage. It reports 10–35% token reduction across 5 LLMs × 3 math benchmarks.
These adaptive sampling studies are orthogonal to studies of weighted majority voting. Weight design and stopping rules are composable, and a natural development is to “determine N dynamically with BEACON and aggregate with Prefix Consistency or IEW.”
Universal Self-Consistency and Semantic Aggregation
Tasks that cannot be aggregated by exact match (summarization, open-ended QA, long-form answers) require different mechanisms.
Latent Self-Consistency (LSC) (Oh and Lee 2025) appends a learnable summary token at the end of each response and detects the semantic majority by cosine similarity of its embeddings. With KV cache reuse, the computational overhead is below 0.9%. It handles both short and long answers.
Representation Consistency (RC) (Jiang et al. 2025) aggregates by taking into account not only answer frequency but also the consistency of internal activations (outputs of dense / sparse autoencoders) during generation. Accuracy improves by up to 4%. NeurIPS 2025.
Three layers — string-match voting (SC), embedding voting (LSC), and internal activation voting (RC) — are developing in parallel.
Internal-State Probing Methods: Alternative Signal Sources
The methods introduced so far basically use “external observations (output tokens, regeneration, agreement)” as signals, but a line of work that directly probes internal states is developing in parallel.
Hidden-state probing (Zhang et al. 2025) trains a binary classifier on the hidden state at the answer position and predicts the correctness of intermediate answers. It is used to decide “we can stop here,” reducing tokens by 24%.
ReProbe (Ni et al. 2025) predicts step-credibility from the internal state of a frozen LLM using a transformer probe with fewer than 10M parameters. It matches or exceeds a PRM up to 810× larger on MATH, Plan, and QA. Accepted at ACL 2026.
Calibrated Reasoning (Garg et al. 2025) has a pairwise Explanatory Verifier trained by Group Relative Policy Optimization (GRPO) emit calibrated confidence and a natural-language explanation, and it wins in situations where majority vote fails, such as when both solutions share the same error.
These are complementary to external signals (such as Self-Consistency and prefix-based methods), and there is substantial room for combining them to build higher-order aggregators.
Extensions to Agent Settings
Reasoning is needed not only for single-shot answers but also for multi-step agents.
TrACE (Sethi 2026) measures action agreement between small samples at each step of an LLM agent and proposes a training-free controller that decides immediately if agreement is high and takes additional samples if low. It achieves SC-4 equivalent accuracy with 33% fewer calls on GSM8K and 39% fewer on MiniHouse.
The approach of “using inter-rollout agreement as a free signal” is positioned as a bridge between the WMV of Equation 2 and the agent setting.
Chapter Summary
This chapter organized aggregation methods starting from SC along four axes.
- Weighting systems: branching by signal source — token logprob (Fu et al. 2025), verbalized (Taubenfeld et al. 2025), logit/entropy (Razghandi et al. 2025; Kang et al. 2025; Sharma and Chopra 2025), external consistency (Iwase et al. 2026; Chen et al. 2025)
- Prefix-based methods: PoLR (Jindal et al. 2026), Path-Consistency (Zhu et al. 2024), Prefix-Confidence Scaling (Otth et al. 2025), ST-BoN (Y. Wang et al. 2025), Beyond the Last Answer (Hammoud et al. 2025), Prefix Consistency (Iwase et al. 2026) independently arriving at the same hypothesis
- Theoretical foundation: weighted majority voting is MAP-optimal (Kuang et al. 2025), exploitation of higher-order information (Ai et al. 2025), the \(N \to \infty\) limit (Komiyama et al. 2026), learned aggregation (Zhao et al. 2025)
- Adaptive sampling: Bayesian/SPRT (Wan et al. 2025; Kim et al. 2026; Aghazadeh et al. 2025; Lee et al. 2025), budget allocation (Ji et al. 2025; Liu et al. 2026), pruning (Sultan and Astudillo 2025), verbal-confidence-driven small-sample variants (Del et al. 2026)
These four axes are orthogonal and can be combined in deployment. For example, the recipe “determine N dynamically with BEACON, build weights from prefixes, and aggregate with weighted majority voting” is in principle viable. Which combination dominates the accuracy–compute Pareto frontier in practice is an open question as of 2026.
In addition, external observations (regeneration, agreement) and internal observations (hidden state probes, neuron agreement, representation consistency) are positioned as complementary signal sources, and higher-order aggregators that integrate both are becoming the next frontier. The line of work on Process Reward Models (Process Reward Models) and the flow of this chapter are beginning to intersect in Kuang et al. (2025) and Zhao et al. (2025), and the very boundary between training-side signals and inference-side signals is dissolving — that is the recent trend.