Test-Time Compute Scaling
This chapter covers the family of methods that improve accuracy by spending additional compute at inference time of LLMs. Since the release of OpenAI o1, the fact that “spending more compute at inference time improves accuracy” has become common knowledge in the research community. The question has shifted from “does it improve?” to “where and how do we invest?” This chapter organizes the main streams of Test-time Compute Scaling (TTS): methods that control Chain-of-Thought (CoT) length, methods that allocate compute according to problem difficulty, system-side efficiency improvements, and even latent reasoning that leaves the language space behind.
The Landscape After OpenAI o1
The ways to use compute spent at test time can be broadly classified into the following four categories.
- Lengthening CoT: increase the thinking-token cap, or increase N in Best-of-N
- Aggregating multiple paths: Self-Consistency-style majority voting and weighted aggregation (Self-Consistency and Weighted Majority Voting)
- Searching: expand the thought space with tree search or Monte Carlo Tree Search (MCTS) (Tree Search and MCTS)
- Verifying: select among candidates with a Process Reward Model (PRM) or verifier (Process Reward Models)
(Snell et al. 2025), in an ICLR 2025 Oral, analyzed two test-time mechanisms — PRM-based search and prompt-adaptive update of the response distribution — and reported that, by adopting a “compute-optimal” strategy that adapts to difficulty, a 14x smaller model can match or exceed the performance of a much larger one. In the same year, 2024, (Brown et al. 2024) showed that “if the number of samples N is scaled by four orders of magnitude, coverage (the probability that at least one of them is correct) grows log-linearly,” and (Yangzhen Wu et al. 2024) empirically measured the trade-off between inference cost and model size from combinations of greedy / majority voting / tree search.
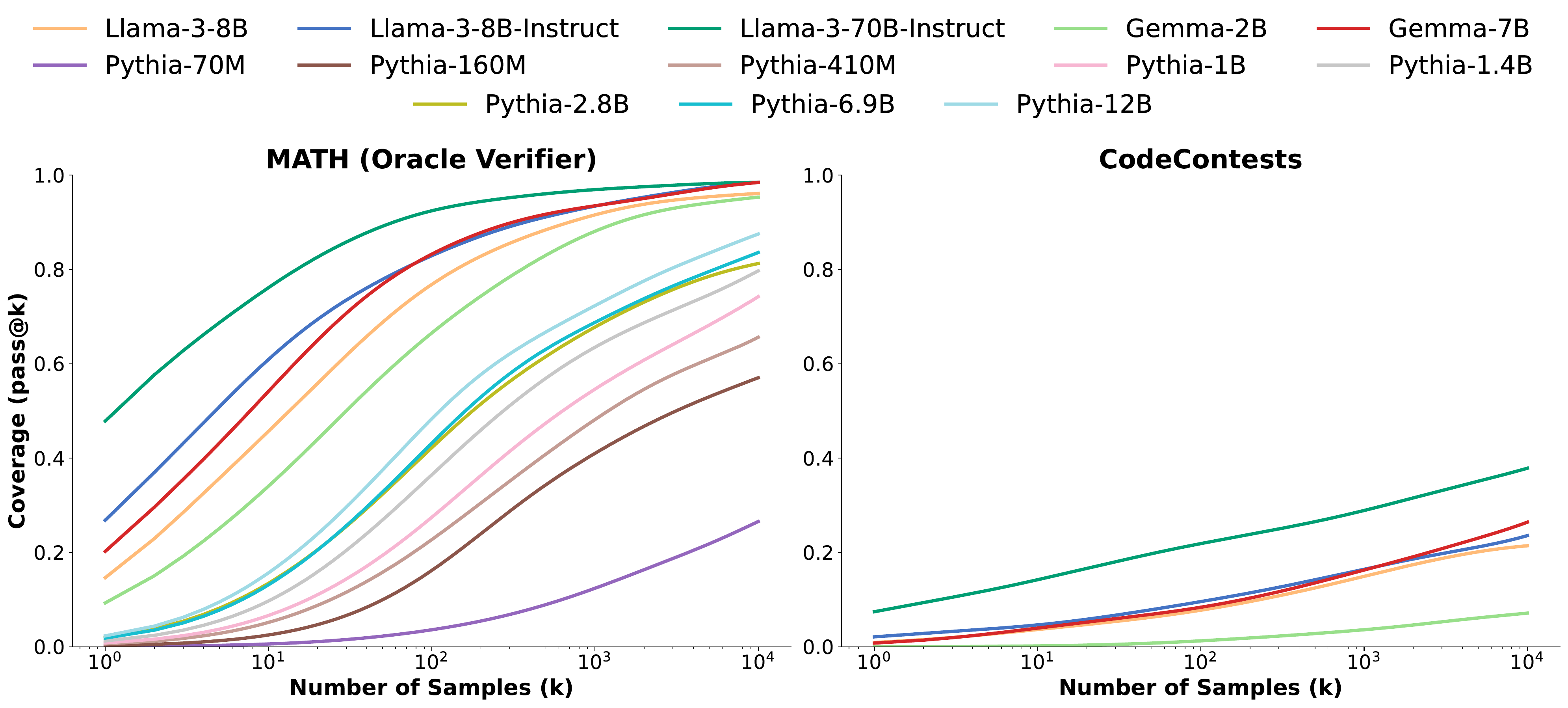
What Figure 1 shows is that Best-of-N-style repeated sampling has an extremely simple scaling structure: “the more we increase K, the higher the probability that at least one sample is correct, log-linearly.” The adaptive allocation methods discussed in later sections can be positioned as attempts to make this naive scaling more efficient by deciding “where to stop.”
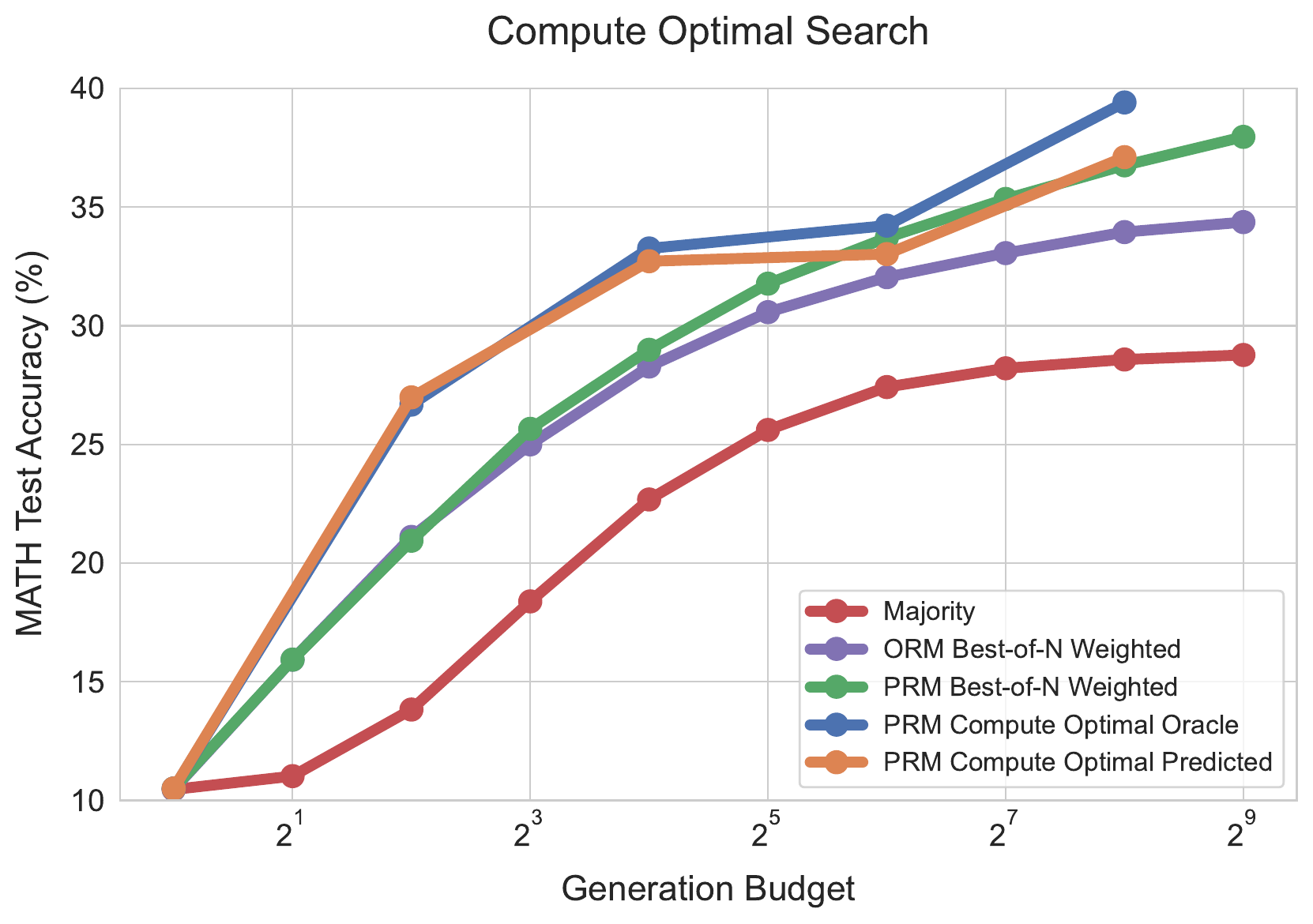
The point of Figure 2 is that there is room to optimize “how to spend compute” on a per-problem basis. While the curves for fixed strategies (Majority and Best-of-N) saturate early, the Compute Optimal scheme that switches methods according to difficulty keeps improving as the generation budget grows. The adaptive allocation methods in the second half of this chapter sit on the extension of this observation.
These works built the empirical foundation that “TTS indeed works.” On top of that, this chapter looks at research from 2025–2026 that addresses “how to make it work.”
Since OpenAI o1 Pro, frontier vendors have lined up “upper tiers that inject parallel test-time compute into the same reasoning model” as productized offerings (o1 Pro, GPT-5 Pro, GPT-5.5 Pro, xAI Grok 4 Heavy, etc.). OpenAI itself describes GPT-5 Pro as using “scaled but efficient parallel test-time compute,” explicitly stating that the Pro tier is not a different architecture but a deployment mode of the same model.
What can be confirmed publicly is that, at o1’s release, both pass@1 and majority vote @ 64 samples were shown in OpenAI’s benchmarks, which suggests the Pro tier can be read as a composite deployment of the aggregation discussed later in this chapter (Self-Consistency and Weighted Majority Voting) and verification (Process Reward Models). Recent work that exploits the asymmetry that verification is cheaper than generation (Zeng et al. 2025) is pushing on the efficiency limits of this style of deployment from the academic side.
Because the specifics of the aggregation / selection machinery are not public, this chapter does not address the internals of the Pro tier itself. Rather, the point to take here is that the academic methods discussed in this chapter share the same problem space as commercial deployments.
Budget Forcing and Thinking Control
The simplest and most widely used form of TTS is to explicitly control the length of thinking. s1(Muennighoff et al. 2025) is the representative example: it combines SFT on Qwen2.5-32B-Instruct using 1,000 curated reasoning traces (s1K) with “Budget Forcing,” which extends thinking by appending “Wait” during generation, or forces termination of thinking at a specified token count. With nothing more than this, it surpassed o1-preview on MATH by 27% and became the first paper to reproduce the test-time scaling curve shown by OpenAI in a minimal configuration.
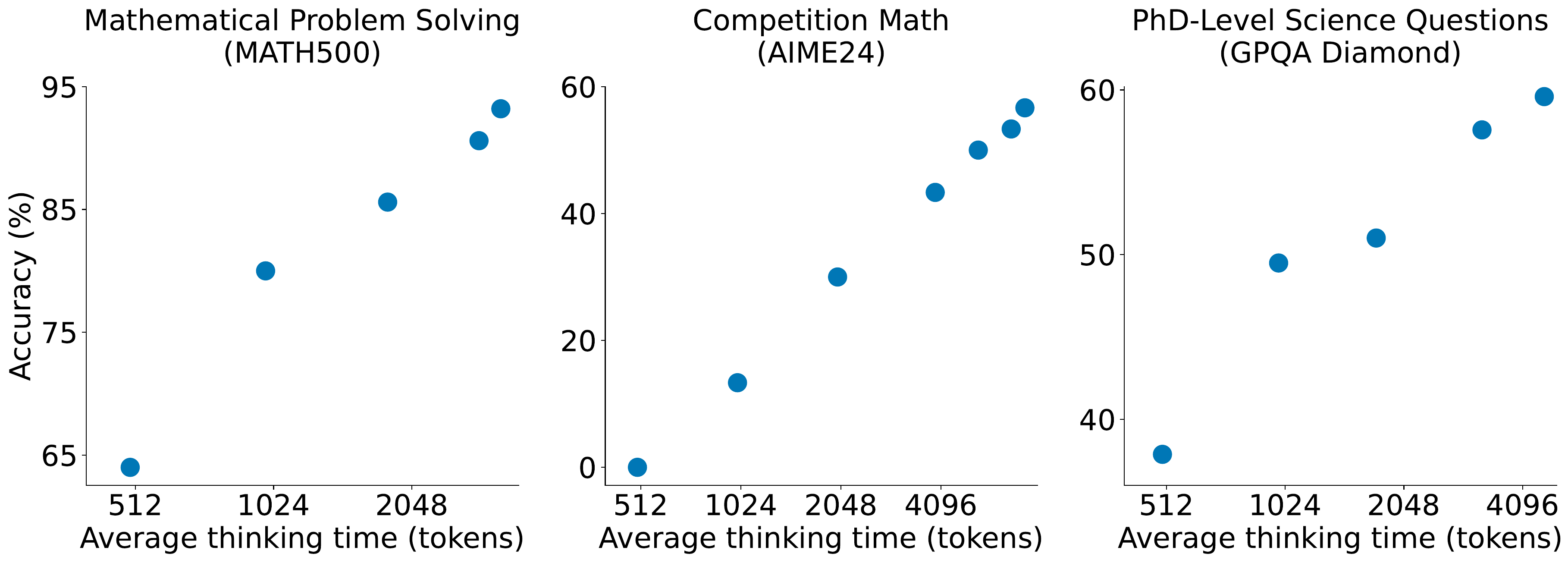
Figure 3 shows that, with the minimal recipe of SFT on just 1,000 examples plus Budget Forcing, monotonic performance improvement against a log-scale thinking budget is already reproducible. Many of the methods covered in this chapter take this basic curve as a starting point and aim for either “higher accuracy at the same thinking budget” or “the same accuracy at a smaller budget.”
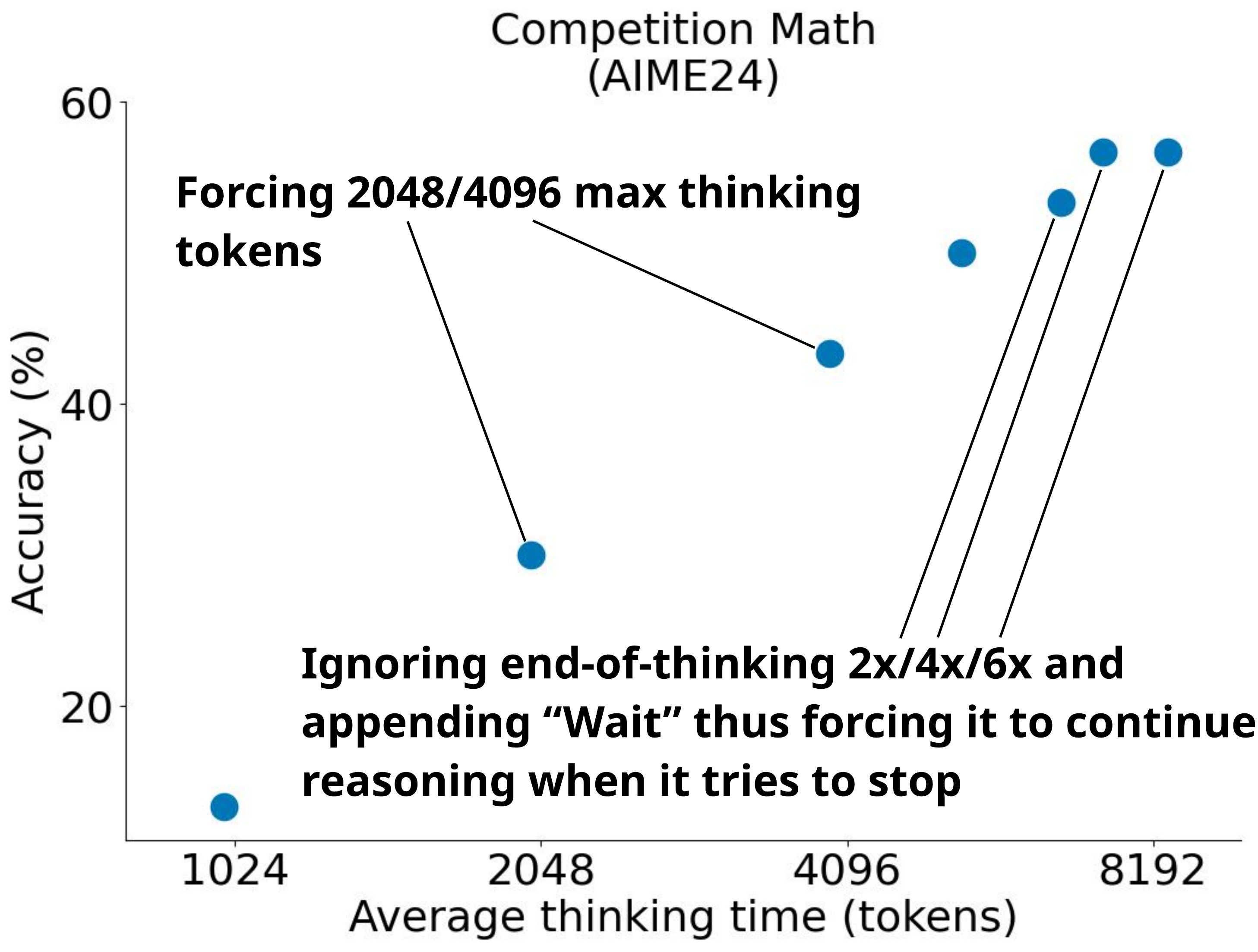
What Figure 4 demonstrates is that simply controlling “when to stop” and “when to continue” externally is enough to explicitly select an operating point on the scaling curve. This granularity of controllability is a prerequisite for the later adaptive allocation methods (CaTS, DEER, CGES, etc.).
What Budget Forcing in s1 demonstrated is the fact that test-time scaling can be achieved without any special reinforcement learning or massive data. What matters is decomposing “when to stop / when to continue” into a granularity that can be controlled externally to the model, and this becomes the premise for the adaptive allocation methods in the latter half of this chapter.
Budget Guidance(Li et al. 2025) softens the hard cut of s1. It assumes a Gamma distribution over the remaining thinking length and probabilistically guides next-token generation. With no fine-tuning, it achieved a 26% accuracy gain on MATH-500 under a tight budget and matched full-thinking accuracy at 63% of the tokens.
O1-Pruner(Luo et al. 2025) goes in the opposite direction — shortening overly long thinking — and achieves both length reduction and accuracy through RL-style fine-tuning with a length-harmonizing reward. It also proposes a metric called the Accuracy Efficiency Score (AES).
Chain of Draft(Xu et al. 2025) tries an extreme form of shortening. With the simple prompt Think step by step, but only keep a minimum draft for each thinking step, with 5 words at most, it compresses CoT to 7.6% of the tokens and achieves an 80% token reduction and a 76% latency reduction on GSM8k while matching or exceeding accuracy.
What these methods share is the stance of treating the length of CoT itself as an independent control variable.
Non-Monotonic Relationship Between CoT Length and Accuracy
Longer CoT is not always better. In 2025, several independent groups showed that the relationship between CoT length and accuracy is not monotonic.
(Yuyang Wu et al. 2025) showed, both through controlled experiments and a theoretical model, that the relationship between CoT length and accuracy is “inverse-U-shaped,” and reported that the optimal length increases with task difficulty but decreases with model capability (stronger models exhibit a “simplicity bias”). (W. Yang et al. 2025) empirically demonstrated that the optimal length distribution differs across domains, and lifted Qwen2.5-32B to the level of QwQ-32B-Preview via thinking-optimal scaling that self-selects shorter correct responses.
Accuracy drops when CoT is “too long” as well as “too short.” Papers pointing this out from both directions appeared at around the same time.
- Overthinking: (Hassid et al. 2025) reported that, among multiple chains generated for the same problem, shorter chains have up to 34.5% higher accuracy, and achieved a 40% token reduction with
short-m@k(generate k in parallel and take a majority vote over the first m to finish) - Underthinking: (Y. Wang et al. 2025) pointed out that o1-family models exhibit “underthinking,” abandoning promising thought trajectories prematurely to switch to another thought, and improved performance by introducing a “thought switching penalty” in decoding. This happens more often on harder problems and correlates strongly with incorrect answers
These observations imply that fixed-length / fixed-N TTS is in principle not optimal. This leads directly to the adaptive allocation discussed in the next section.
Adaptive Compute Allocation
The idea of dynamically allocating compute on a per-problem basis became mainstream from late 2025 through ICLR 2026. The main lineages are summarized in the table below.
| Method | Control signal | Control target | Source |
|---|---|---|---|
| CaTS (Self-Calibration) | self-distilled confidence | early stopping of Best-of-N | (C. Huang et al. 2025) |
| T1 | external tool (code, retrieval) | verification by a small LM | (Kang et al. 2025) |
| Fractional Reasoning | latent steering vector | reasoning depth (continuous) | (S. Liu et al. 2025) |
| DiffAdapt | token entropy patterns | Easy / Normal / Hard strategy switching | (X. Liu et al. 2025) |
| DEER | thought-switch detection | early exit of thinking | (C. Yang et al. 2025) |
| CGES | Bayesian update of scalar confidence | early stopping of sampling | (Aghazadeh et al. 2025) |
| Thought Calibration | hidden state probe | early stopping via plateau detection | (M. Wu et al. 2025) |
| Budget-aware | discriminative verifier + SC | optimizing verification cost | (Montgomery et al. 2025) |
| e1 | continuous effort parameter | proportional control of CoT length | (Kleinman et al. 2025) |
Looking at Table 1, one sees that multiple lineages try to determine “where to stop / how deeply to think” using different observed quantities. CaTS dynamically chooses N in Best-of-N, DEER chooses the length of thinking itself, and Fractional Reasoning chooses the depth in latent space.
The fact that CaTS, T1, Fractional Reasoning, ThinKV, and DiffAdapt were all accepted at ICLR 2026 simultaneously symbolizes the community sentiment that “fixed-K self-consistency and fixed-token-budget CoT are becoming old baselines.”
In particular, Fractional Reasoning goes beyond discrete-token CoT: it controls reasoning depth continuously by re-injecting a latent steering vector with a tunable scaling factor. The result that it can uniformly improve Best-of-N, majority voting, and self-reflection in a training-free manner suggests that reasoning depth has a linear structure.
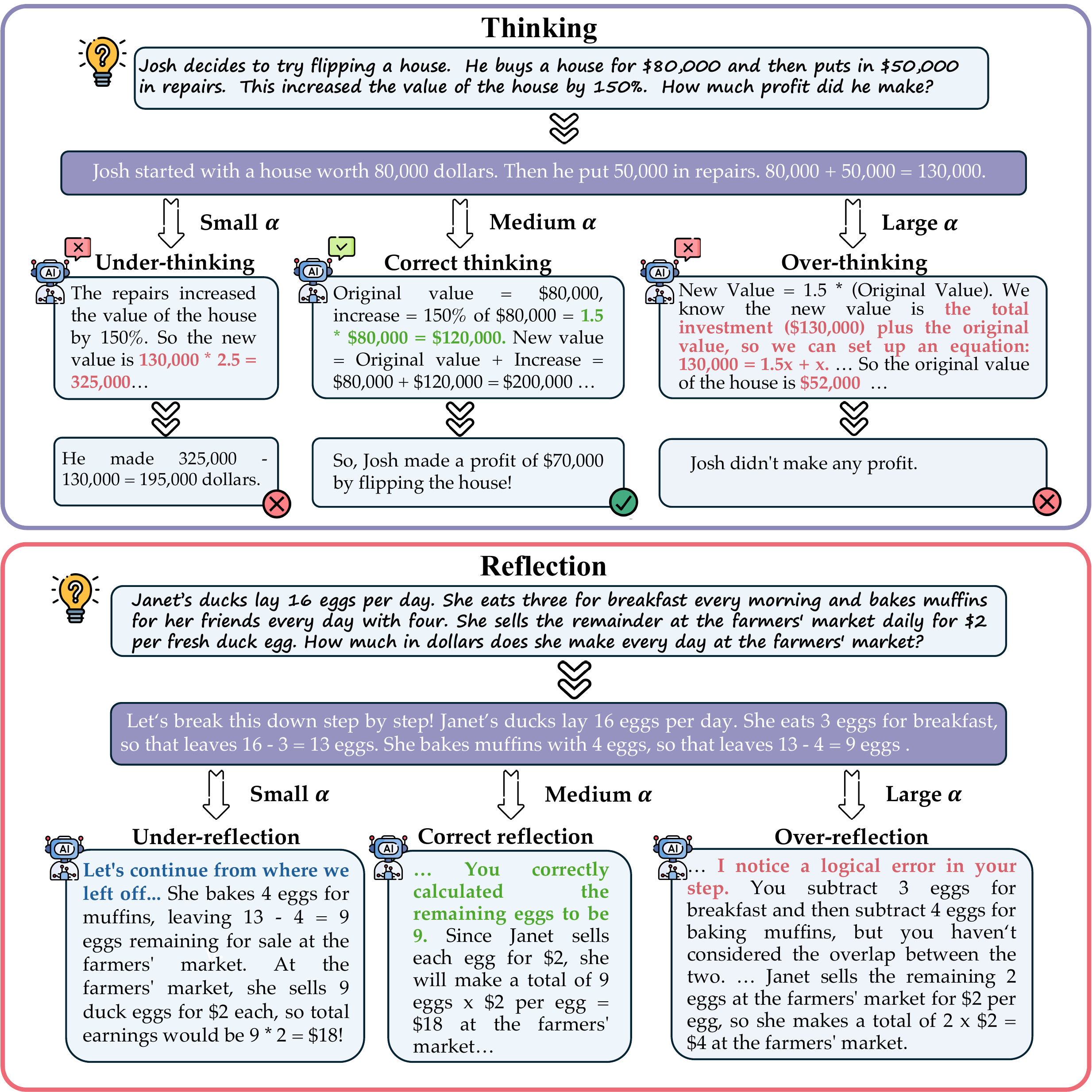
Figure 5 qualitatively shows that reasoning depth can be moved continuously by a single scalar α. The idea that one can specify the depth of thinking with a continuous value, rather than choosing between a fixed-length CoT or a discrete “think once more / stop” binary, connects naturally to the depth control of tree search covered in Tree Search and MCTS.
System-Side Optimization
A lineage that absorbs the “weight” of TTS on the software/hardware side is also rapidly emerging.
KV Cache Compression
Long CoT causes the KV cache to explode. ThinKV(Ramachandran et al. 2025) (ICLR 2026 Oral) quantizes / evicts based on per-thought importance and reuses freed slots with a kernel extending PagedAttention. It achieves near-lossless performance with less than 5% of the original KV cache and 5.8x throughput.
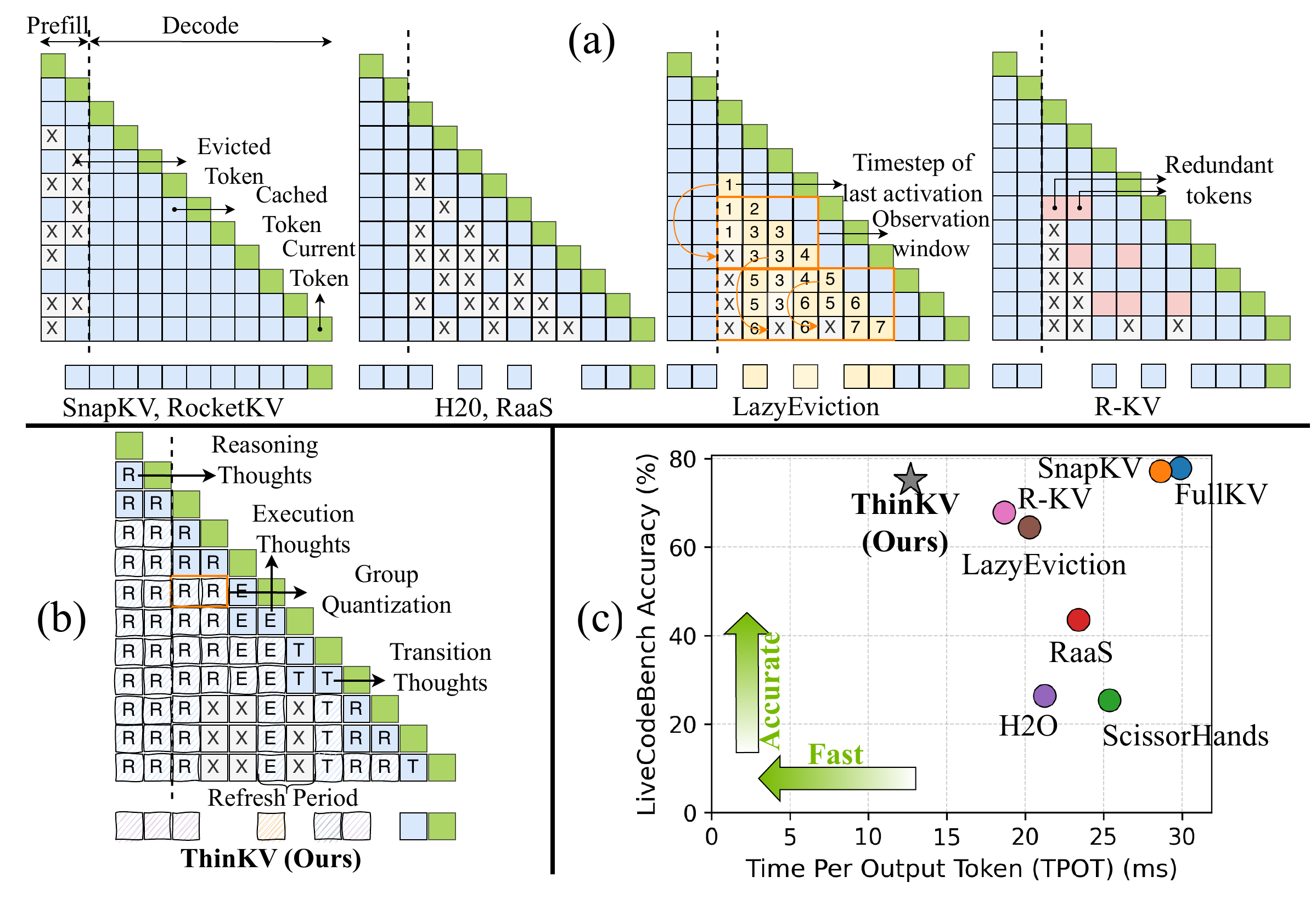
What Figure 6 shows is that, by raising the granularity of KV cache compression from “token” to “thought,” TPOT can be dramatically reduced with almost no accuracy loss. It is a result that symbolizes how the main battleground on the system side in the long-CoT era is shifting from generic token-level KV compression to compression that takes reasoning structure into account.
Speculative Reasoning
SpecReason(Pan et al. 2025) proposed a design that delegates intermediate reasoning steps to a lightweight model, while the base model focuses on verification. Because it judges based on semantic equivalence, it is not bound by exact token matching. The authors report a 1.4–3.0x speedup and a 0.4–9.0% accuracy improvement, and an 8.8–58.0% latency reduction when combined with speculative decoding. SCoT(J. Wang et al. 2025) uses a small draft model to produce thought-level proposals, which the target model accepts/modifies; this design reduced latency by 48–66% on math datasets.
Speculative decoding for long contexts is itself progressing: LongSpec(P. Yang et al. 2025) (ACL 2025) resolves the inefficiencies of memory, the training-inference gap, and tree attention, and achieved a 2.25x wall-clock reduction on long reasoning for AIME24 and a 3.26x speedup over Flash Attention.
Moving to Offline
Sleep-time Compute(Lin et al. 2025) pushes the test-time burden itself out to the idle period “before the user’s query.” By reasoning about the context in advance and passing that representation into the test-time prompt, it reduces test-time compute by about 5x while improving accuracy by 13–18%. Amortizing across groups of related questions yields a further 2.5x cost reduction.
Rethinking the Scaling Law
Kinetics(Sadhukhan et al. 2025) argued that existing test-time scaling laws ignore the memory-access bottleneck and therefore overestimate the effective efficiency of small models. From measurements on 0.6B–32B models, it showed that “attention is the new cost driver,” and obtained gains of more than 60 points on AIME via sparse attention.
TTS is not the simple story that “with the same compute budget, thinking longer is better”; it is a multi-dimensional trade-off where “compute budget = compute × memory × time.” With the appearance of ThinKV and Kinetics, the TTS scaling curve is being rewritten from the system side as well as the algorithm side.
Latent Reasoning
CoT is bound by the constraint of being a discrete token sequence. Coconut(Hao et al. 2024) (COLM 2025) removes this constraint by feeding the final hidden state back as a “continuous thought” directly into the embedding input, enabling latent reasoning unbound by the language space. Multiple reasoning paths can be explored simultaneously in a Breadth-First Search (BFS)-like manner, and it showed an accuracy-efficiency Pareto improvement over discrete CoT on logical tasks.
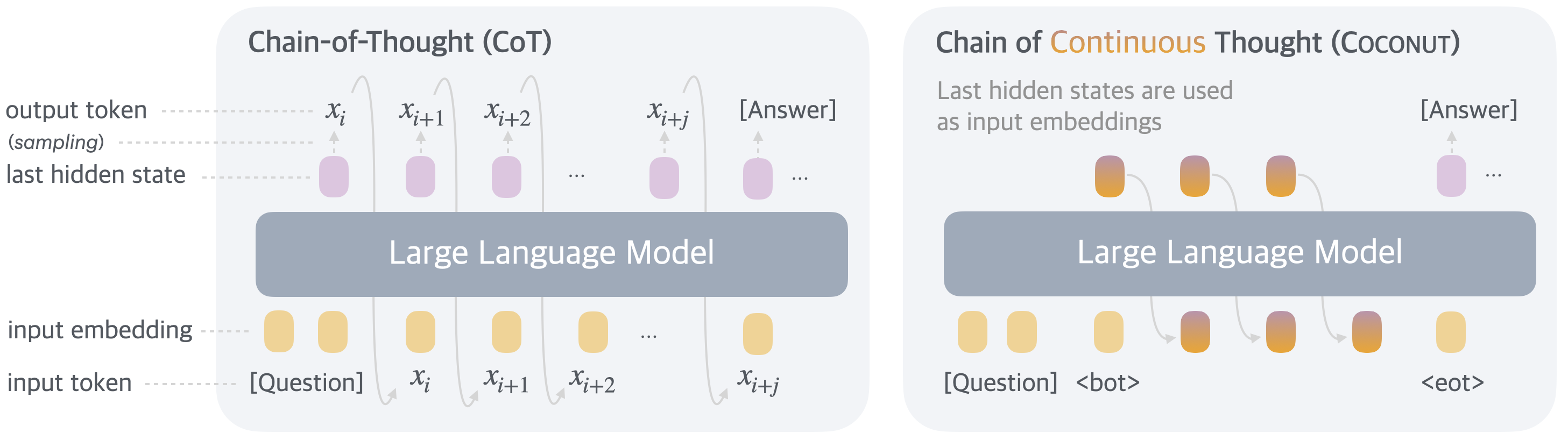
<bot> and <eot>. Source: (Hao et al. 2024)
What Figure 7 captures is the point that the necessity of “discretization” in reasoning is in fact only for external observers, and as far as the model’s internal reasoning is concerned, it can be completed in a continuous space. Discrete CoT has the interpretability advantage of being human-readable, but at the cost of collapsing the hidden state into a single-token vocabulary distribution at every word. Coconut allows one to choose whether or not to pay this cost depending on the task.
The lineage of Coconut extends in the following two directions.
- Expanding the representation space of continuous CoT: treating thoughts as vectors and making them manipulable by linear operations. Fractional Reasoning (S. Liu et al. 2025) can be positioned as an extension of this direction
- Compressed CoT: compressing long discrete CoT into a short latent representation, and decoding it when needed
The theoretical reach of latent reasoning is still expanding, and a natural next extension is the question of what counts as “the same thought” once prefix consistency from Self-Consistency and Weighted Majority Voting or the search from Tree Search and MCTS is moved into the latent space.
Parallelization, Asynchrony, and Markovian Thinking
Sequential thinking suffers from a pathology called “Tunnel Vision,” where suboptimal early choices constrain later stages. ParaThinker(Wen et al. 2025) proposed native parallel thinking that generates multiple reasoning paths in parallel and integrates them, achieving a 12.3% accuracy improvement at 1.5B and 7.5% at 7B with only about 7.1% additional latency. Whereas Self-Consistency parallelizes only the outer aggregation, ParaThinker parallelizes the thinking itself natively.
Markovian Thinker(Aghajohari et al. 2025) redesigns the RL training environment: it splits reasoning into fixed-size chunks and resets the context at the boundaries (i.e., enforces Markovian property). A 1.5B model can realize 24K thinking with 8K chunks, and for a length of 96K it reduces the H100-months from 27 to 7 while maintaining accuracy. It is drawing attention as a way to linearize the cost of long CoT.
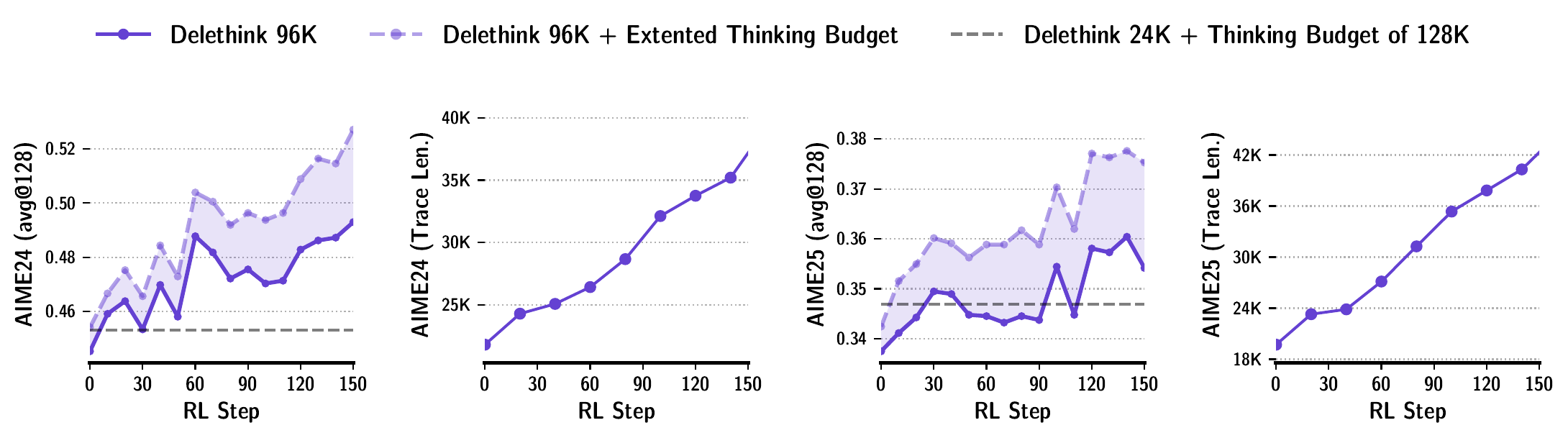
What Figure 8 shows is that even with RL training that enforces a context reset at chunk boundaries, accuracy continues to grow properly, and moreover the length scales with linear cost. It can be positioned as an approach that, from the training side, avoids the quadratic attention cost that becomes the saturating factor when extending long CoT.
Domain Dependency: From Math to Medicine
The discussion so far — budget forcing, optimal CoT length, adaptive allocation — has been built almost entirely on the implicit assumption of mathematical tasks. It is not by accident that AIME / MATH500 / GSM8k / AMC occupy most of the figures and tables in this chapter; test-time compute research itself is heavily biased toward math. How far do the conclusions reached here survive once the domain changes? Medical reasoning research in 2025 has begun to line up negative answers.
Decomposing Knowledge and Reasoning
(J. Wu et al. 2025) decomposed thinking trajectories into two components — knowledge and reasoning — and defined (1) a Knowledge Index (KI) that extracts the domain knowledge used at each step and matches it against an external database, and (2) an Information Gain (InfoGain) that measures how much each step reduces uncertainty about the final answer.
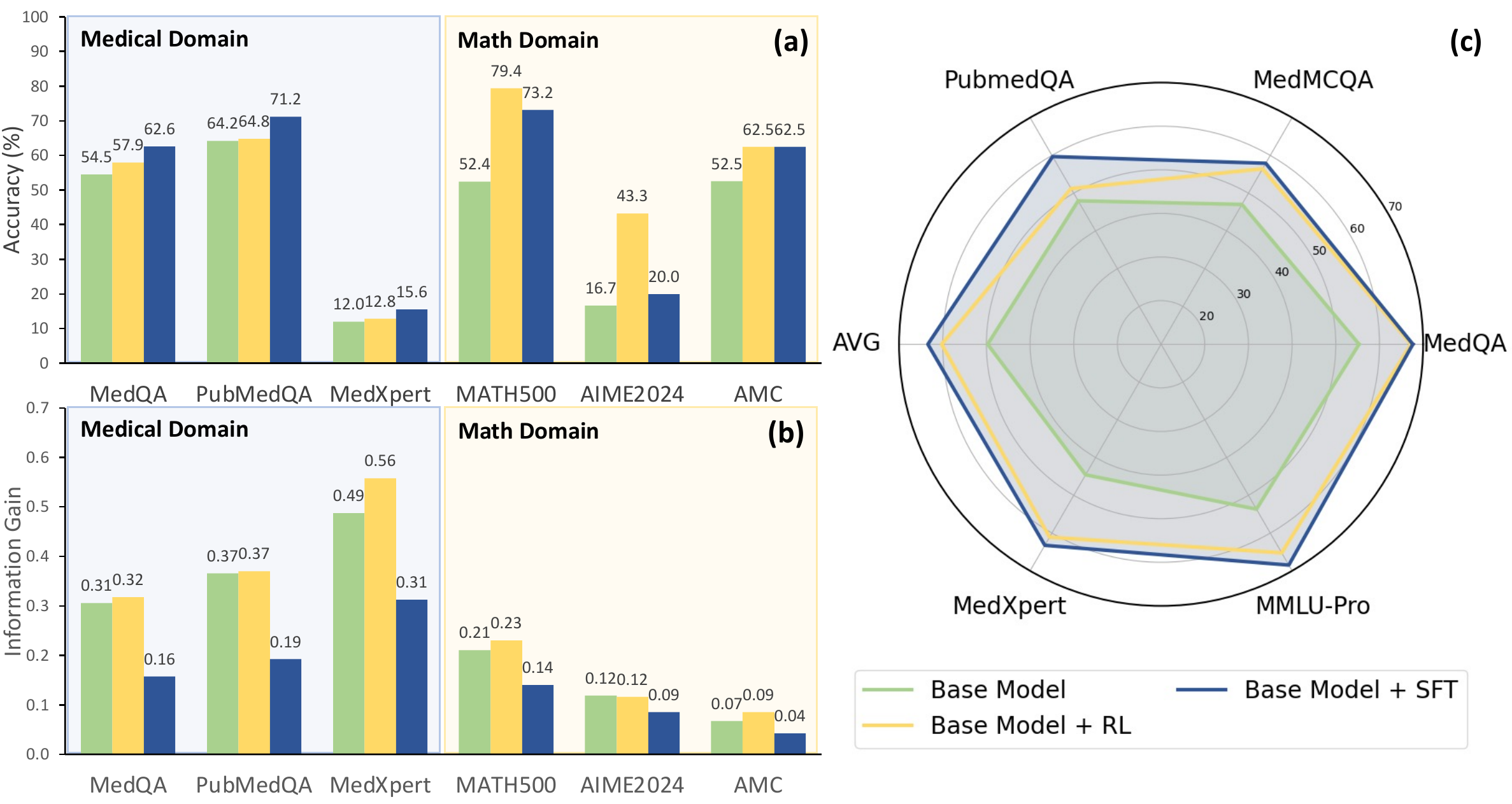
What Figure 9 shows is that the same training recipe has domain-dependent effects. In 4 out of 5 medical benchmarks, the KI–accuracy correlation exceeds the InfoGain–accuracy correlation. SFT raises accuracy while lowering InfoGain by an average of 38.9% (reasoning becomes more verbose), and in medicine it raises KI by an average of 6.2 points. RL raises medical KI by an average of 12.4 points, pruning reasoning trajectories that contain inaccurate knowledge. The paper also reports that reasoning distillation derived from R1 does not automatically transfer to medicine even when SFT/RL are appended downstream.
Medical Reasoning Has a Thinking-Budget Ceiling
(X. Huang et al. 2025) systematically studied test-time scaling on medical reasoning. Across 10 medical QA benchmarks, accuracy grows with the logarithm of the thinking budget but plateaus at around 4K tokens.
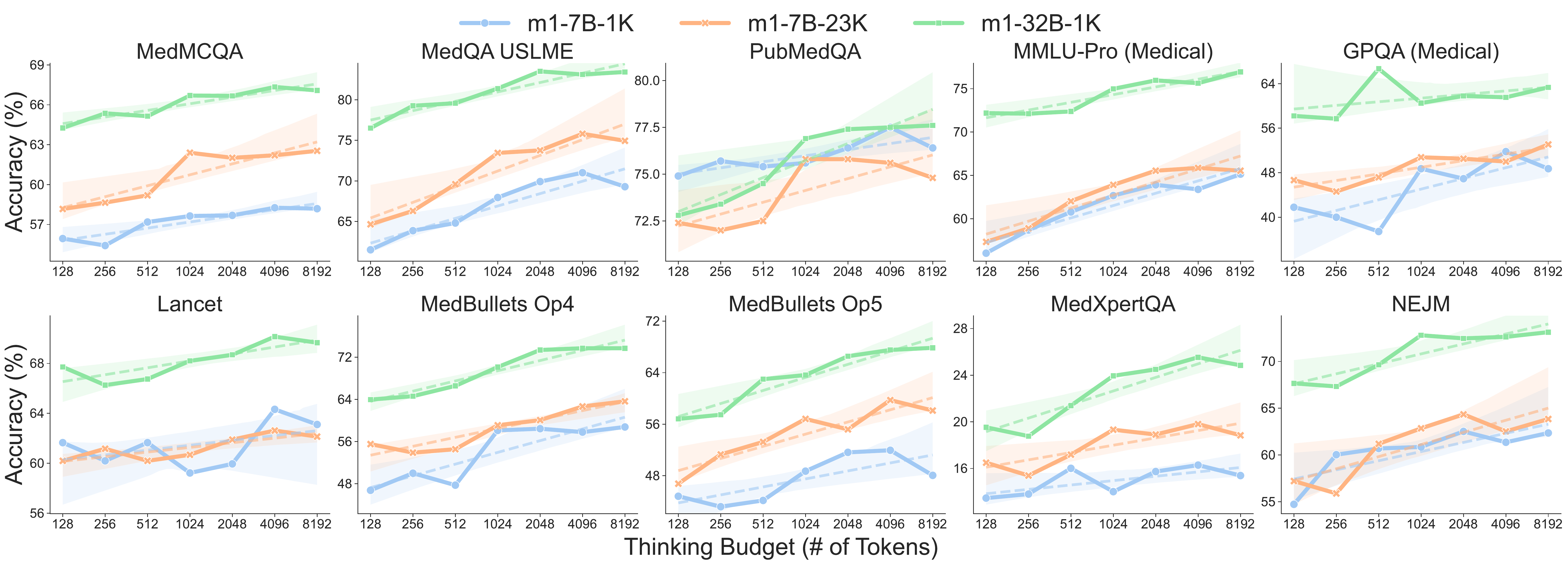
In addition, the “Wait”-insertion budget forcing introduced by s1 (Muennighoff et al. 2025) has only limited effect on medical QA, and in some cases overturns an initially correct answer into an incorrect one. The case analysis in the paper presents examples where a model with erroneous knowledge revisits a correct initial answer under additional thinking and arrives at an inaccurate conclusion. An operation that functions as iterative refinement in math acts in medicine to expose the knowledge bottleneck. The authors attribute the source of this bottleneck to “insufficient medical knowledge” and conclude that scaling data quality and model capacity is more effective than extending the thinking budget.
Medical Error Correction as an Evaluation Axis
Carrying inference-time signals from math over to medicine requires an evaluation counterpart on the medical side. MedRECT (Iwase et al. 2025) decomposes the problem on clinical text into three subtasks — error detection, error sentence extraction, and error correction — and constitutes a Japanese–English bilingual benchmark (Figure 11). MedRECT-ja contains 663 samples built via an automated pipeline from the Japanese Medical Licensing Examination (JMLE 2024–2025), and MedRECT-en contains 458 samples obtained by applying the same LLM-as-a-Judge screening to the MEDEC MS Subset Test. 11 LLMs (proprietary / open-weight / medical-specialized / reasoning-oriented) are evaluated.

The main results are threefold. First, comparing Qwen3-32B with and without thinking, turning reasoning on yields a relative improvement of +13.5% in error-detection F1 and +51.0% in sentence-extraction accuracy. Second, a general reasoning model outperforms medical-specialized models on sentence extraction: HuatuoGPT-o1-72B reaches 62.1%, while the smaller Qwen3-32B with thinking reaches 72.5%, suggesting that reasoning capability dominates over domain-specialized training. Third, LoRA fine-tuning raises accuracy in both languages, with relative improvements of +16.8% on MedRECT-ja and +19.6% on MedRECT-en. Because MedRECT-ja and MedRECT-en draw on different source materials, direct comparison of absolute numbers across languages is avoided; the benchmark is framed as a way to measure within-language model rankings and within-model en–ja gaps.
Takeaways
The conditions under which inference-time methods established on math transfer to other domains are not self-evident. At least the following two points have been confirmed.
- When the bottleneck of a domain lies in knowledge rather than reasoning, methods that extend reasoning depth produce limited accuracy gains, and budget forcing can act in the direction of overturning a correct answer (X. Huang et al. 2025)
- The optimal thinking budget is domain-dependent: the log-linear scaling observed in math plateaus around 4K tokens in medicine (X. Huang et al. 2025; J. Wu et al. 2025)
The budget forcing, adaptive allocation, and KV cache compression discussed in this chapter have merely reached an operating point optimized for math; knowledge-intensive domains call for a different operating point and different evaluation axes.
Chapter Summary
Table 2 reorganizes the main methods covered in this chapter along the axis of what is being optimized.
| Axis | Representative method | Effect (rough order of magnitude) |
|---|---|---|
| Hard length control | s1 (Budget Forcing) | o1-preview +27% on MATH |
| Soft length control | Budget Guidance | same accuracy at 63% of full-thinking tokens |
| Shortening priority | Chain of Draft | 7.6% of tokens, 80% reduction |
| Shortening priority (learned) | O1-Pruner | balancing length and accuracy |
| Inverse-U-shaped length | When More is Less | optimal length is problem-dependent |
| Adaptive early stopping | CaTS, DEER, CGES, Thought Calibration | 50–80% reduction in thinking tokens |
| Adaptive depth | Fractional Reasoning | uniform training-free improvement across multiple methods |
| KV cache compression | ThinKV | near-lossless with <5% KV, 5.8x throughput |
| Speculative | SpecReason, SCoT, LongSpec | 1.4–3.3x latency improvement |
| Offline migration | Sleep-time Compute | 5x reduction in test-time compute |
| Latent | Coconut, Fractional Reasoning | reasoning outside the language space |
| Parallelization | ParaThinker | 7.5% at 7B with 7% additional latency |
| Linear scaling | Markovian Thinker | 4x reduction in the cost of 96K thinking |
Cutting across all of this, four points stand out.
- “When to stop” is a shared question: the hard cut of Budget Forcing, the soft cut of Budget Guidance, the thought-switch exit of DEER, the Bayesian stopping of CGES, and the plateau detection of Thought Calibration all decide where to cut the reasoning prefix using different signals. This connects directly to the prefix-based aggregation methods covered in Self-Consistency and Weighted Majority Voting
- Non-monotonicity of length is now established: multiple independent studies reported overthinking and underthinking at around the same time. Fixed-length / fixed-N TTS will remain as a baseline going forward, but the optimal method must be decided dynamically and in a problem-dependent and capability-dependent manner
- The system side is catching up: ThinKV, SpecReason, Sleep-time Compute, and Kinetics provide counterarguments to the “N-times-cost” critique. Discussing TTS efficiency from the algorithm side alone is becoming inadequate
- Domain dependency surfaces: in knowledge-intensive domains such as medicine, budget forcing can act in the direction of overturning a correct initial answer, and the thinking budget plateaus around 4K tokens (X. Huang et al. 2025; J. Wu et al. 2025). Operating points optimized for math do not transfer automatically to other domains
Self-Consistency and Weighted Majority Voting revisits the compute allocation covered here from the perspective of “how to aggregate a set of samples.” CISC, CER, Path-Consistency, ST-BoN, and Prefix Consistency, which appeared as derivatives of Self-Consistency, are in a back-to-back relationship with the adaptive allocation in this chapter.