Inference Acceleration
Diffusion Language Model(DLM)の推論高速化は、近年最も活発に動いている分野のひとつである。Autoregressive(AR)な大規模言語モデル(Large Language Model, LLM)は系列長 \(L\) に対して本質的に \(O(L)\) 回の forward pass を逐次実行する必要があり、これを下回るのはハードウェア最適化と speculative decoding 程度の余地しかない。一方で DLM は並列に全位置を更新できる構造を持つため、原理的にはステップ数 \(T \ll L\) で推論が完結する。しかし素朴に並列度を上げると parallel decoding curse(後述)と呼ばれる品質崩壊が起きるため、「どうやって並列性と品質を両立させるか」という工学的問題が独立した研究領域として成立している。
本章は DLM 推論加速の survey (Li ほか 2025年) §4 を中核に、加速戦略を 5 つの軸で整理する。(1) Parallel Decoding、(2) Unmasking / Remasking、(3) Key-Value(KV)Cache、(4) Feature Cache、(5) Step Distillation の 5 つは互いに直交しており、組み合わせることで掛け算的な高速化が得られる。なお、Classifier-Free Guidance(CFG)に代表される推論時介入は加速というよりも品質制御の側面が強いため、Guidance 章で扱う。
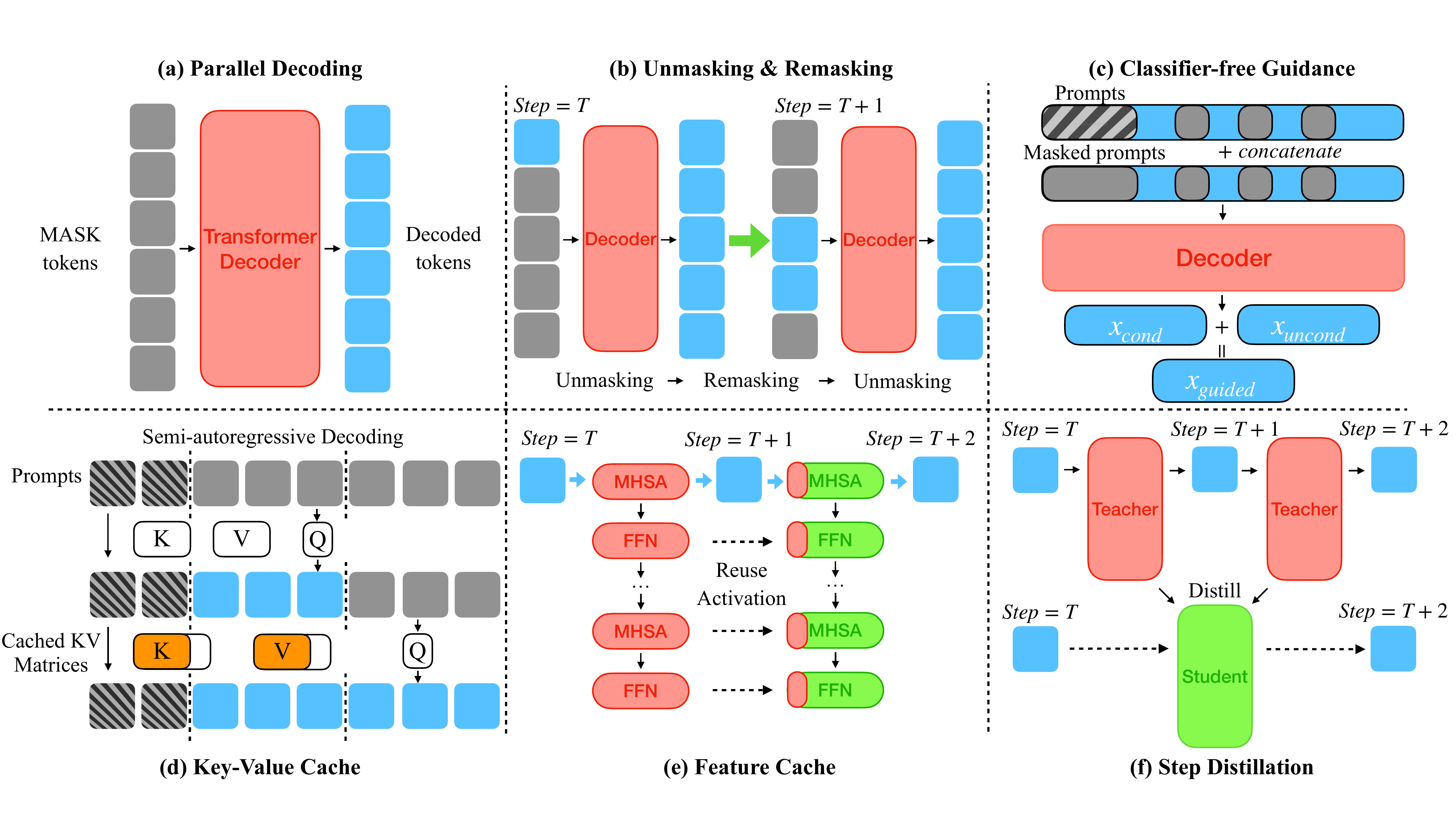
図 1 が本章の地図である。CFG は guidance 章で扱うため、本章では残り 5 戦略を順に深掘りする。各戦略は独立に機能するが、実用上は Fast-dLLM のように parallel decoding + KV cache を統合した実装が頻出する。最後の節では、これらを組み合わせた商用クラスの DLM(Mercury (Labs ほか 2025年)、Gemini Diffusion (Google DeepMind 2024年))が AR を上回る数千 token/sec を実現していること、そしてまだ open な課題群を整理する。
Parallel Decoding
並列復号の原理と崩壊
DLM の forward pass は系列全体に対する条件付き分布 \(p_\theta(x \mid x_t)\) を 1 回で出すため、masked 位置を 複数同時に確定 することが原理的に可能である。LLaDA (Nie ほか 2025年) の標準サンプラは「信頼度上位 \(k\) 個を unmask」する設計で、\(k\) を大きく取れば取るほど 1 ステップあたりの並列度が上がり、Number of Function Evaluations(NFE)が減る。
しかし、ここに固有の落とし穴がある。各位置 \(i\) の予測分布 \(p_\theta(x^i \mid x_t)\) は 他の masked 位置を周辺化した周辺分布であり、複数位置を独立に argmax / sample すると、得られる結合は条件付き分布の積ではなく 独立分布の積 に縮退する。データ分布 \(p(x)\) にトークン間の相関がある限り、この近似は系列が長くなるほど崩れる。
Parallel Decoding Curse
Fast-dLLM (Wu ほか 2025年) はこの現象を parallel decoding curse と呼び、典型例として ABABAB / BABABA の 2 モードしか含まないデータで訓練したモデルを挙げている。訓練分布上は両モードが等確率で現れるため、各位置の周辺分布は \(p(A) = p(B) = 0.5\) となる。並列に独立 sample すると AAABBB や ABABBA のような 訓練データに存在しない 系列が高確率で生成される。これは並列度を上げるほど顕在化する根本的な失敗モードである。
図 2 は、ステップ数を減らすと品質が落ちていく古典的な曲線である。素朴な並列化は曲線の左下(少ステップ・低品質)に張り付くが、後述の confidence-aware / adaptive な戦略はこの曲線そのものを上方シフトさせる。「ステップ数と品質のトレードオフは固定ではなく、サンプラ設計で動かせる」というのが parallel decoding 研究の核心メッセージである。
代表的な戦略
確率的に裏付けられた解決策は、「並列に確定して良いのは、位置間の依存が弱い箇所のみ」という直観に集約される。これをどう検出・近似するかで以下のような系統に分かれる。
| 手法 | アプローチ | 報告速度向上 | 訓練要否 |
|---|---|---|---|
| Fast-dLLM (Wu ほか 2025年) | confidence-aware: 閾値超えを全て unmask | 13× (LLaDA) / 27.6× (Dream, +cache) | training-free |
| APD (Israel ほか 2025年) | 軽量 AR auxiliary で並列度を動的調整 | quality 維持で大幅加速 | aux モデル要 |
| SlowFast Sampling (Wei ほか 2025年) | 2 段階: slow で安定 token 確定、fast で一括 finalize | 最大 34× (+cache) | training-free |
| SpecDiff (Christopher ほか 2025年) | DLM を AR の drafter として使う speculative decoding | AR 比 2× / 最大 7.2× | AR + DLM |
| Dimple (Yu ほか 2025年) | 高 confidence token を毎ステップ複数発見 | iteration を 1.5-7× 削減 | training-free |
| Learn2PD (Bao ほか 2025年) | どの token を unmask すべきかを学習した filter | 固定閾値を置換 | 学習要 |
| dParallel (Z. Chen ほか 2025年) | certainty-forcing distillation で並列性を高める | 並列性向上 | 蒸留要 |
Fast-dLLM の閾値方式は最も単純で再現性が高い。「全位置の予測確率が閾値 \(\tau\)(典型的に 0.9 等)を超えた箇所を一括で unmask する」だけの training-free 加速で、LLaDA / Dream にそのまま乗せて 10× オーダーの加速が得られる。閾値を高く取れば品質を保ったまま並列度を上げられ、低く取れば NFE を一気に減らせるという、品質-速度トレードオフが単一スカラーで制御できる利点が大きい。
APD はもう一歩踏み込み、AR auxiliary の予測と DLM の予測が一致する範囲でのみ並列確定する。これは speculative decoding の精神を DLM に持ち込んだ設計で、auxiliary の追加コストはあるが「並列度を出しても品質が落ちない」保証が強い。SlowFast は phase を 2 段に分けて、序盤に slow / 終盤に fast という MaskGIT 的なコサインスケジュールの再発見でもある。
SpecDiff は逆方向の発想で、AR を主役にしつつ DLM を drafter として使う。DLM の並列性で複数 token を一気に提案し、AR で検証する Speculative Decoding の流れは、Mercury 等の商用 DLM の登場以前から実用されており、AR と DLM が「敵対」ではなく「補完」しうることを示す事例である。
Learn2PD と dParallel は最近の流れで、固定 confidence 閾値を学習で置き換える方向に進化している。「どの位置の予測がいま信頼できるか」を別の軽量モデル(filter)で予測する Learn2PD、訓練時に複数位置の確信度を強制的に高める certainty-forcing distillation を行う dParallel と、両者とも「サンプラ側」ではなく「モデル側」に並列性を埋め込む。
Unmasking / Remasking 戦略
何を unmask し、何を再 mask するか
DLM のサンプリングループは「forward pass → 信頼度計算 → unmask/remask の選択 → 次のステップへ」という構造を持つ。Parallel decoding が「どれだけ並列に確定するか」を扱うのに対し、unmasking / remasking 戦略は「どの位置を、どの順序で確定/再考するか」を扱う。両者は直交しているが、実装上は一体になることが多い。
最も基本的な選択肢は次の 3 つである。
- Random remasking: 各ステップでランダムに \(k\) 個確定。最も素朴で品質も最低
- Confidence-ranked remasking: 信頼度(top-1 確率)上位 \(k\) 個を確定。MaskGIT (Chang ほか 2022年) 由来の標準
- Low-confidence remasking: 確定済み位置でも、相対的に信頼度が低ければ次ステップで
[MASK]に戻す
Masked DLM (Sahoo ほか 2024年) のオリジナル論文は、random と confidence-ranked を ablation で比較し、後者が無コストで品質を改善することを示した。これは MaskGIT の知見の言語側での再確認であり、現在の DLM 実装の de facto standard になっている。
Fast-dLLM の global threshold
Fast-dLLM (Wu ほか 2025年) は、信頼度 top-\(k\) という固定個数のヒューリスティクスを global threshold に置き換えた。各ステップで「閾値 \(\tau\) を超えた全位置を一括で unmask」する設計に切り替えると、
- 序盤は閾値を超える位置がほぼなく、\(T_{\text{step}}\) あたり 1〜数個しか確定しない
- 終盤は文脈が固まり、ほぼ全位置が閾値を超えるため一気に大量確定
という適応的な scheduling が自然に得られる。これは MaskGIT のコサインスケジュールを「データ駆動で導出した」ものとみなせる。閾値というスカラー一つで品質-速度を制御できる単純さは、実装と評価の両面で大きな利点である。
ReMDM: 再 mask による refinement
ReMDM (Wang ほか 2025年) は inference-time scaling の発想を DLM に持ち込んだ研究である。Absorbing diffusion の reverse 過程は数学的には「[MASK] から非 [MASK] への一方向遷移」しか定義しないが、ReMDM は「確定済みのトークンを意図的に再 mask する」サンプラを提案している。
直観的には、
- 1 度確定したトークンが、後から見ると低品質と判明することがある
- そのトークンを
[MASK]に戻して再度予測すれば、後段の文脈を取り込んで訂正できる - 再 mask の予算(budget)を増やせば品質が上がるという滑らかなトレードオフが得られる
ReMDM はこの「再 mask 予算」を inference compute の単位と捉え、AR LLM のステップ数増加に近い形で品質を改善できることを示した。同じ訓練済みモデルから、推論時の計算予算だけで品質を引き出すという考え方は、画像拡散の DDIM ステップ数調整に対応する DLM 版の自由度である。
サンプラ設計の探索空間
これらの組み合わせは爆発的に広い。確認すべき軸を列挙するだけでも次のようになる。
- 確定戦略(top-\(k\) / threshold / learned filter)
- 再 mask 戦略(なし / low-confidence / ReMDM 的予算)
- 温度(位置選択 / トークン予測の 2 段)
- Block 構造(fully parallel / semi-AR with block size \(K\))
- Schedule(線形 / cosine / 学習 / 適応)
各軸を independent に動かせるため、実装側で「どれを採用するか」の決定が研究そのものになる。後述の open challenges でも触れるが、サンプラ設計の探索空間が大きすぎる問題は DLM 推論加速の重要な open problem である。
Key-Value Cache
なぜ AR の KV cache は素朴には効かないか
AR LLM の KV cache は、Transformer の causal attention が「過去のトークンの K/V のみに依存する」という構造に乗っている。新しいトークンを 1 つ追加する際、過去の K/V は変わらないため再計算不要で、\(O(L)\) の memory と \(O(L)\) の computation per step で済む。
DLM はこの仮定が崩れる。
- 各ステップで 系列全体 の bidirectional attention を回す
- masked 位置の予測が確定すると、その K/V は次ステップで変わる
- 結果として、全位置の K/V を毎ステップ再計算するのが naive な実装
これでは AR の KV cache 由来の速度が得られない。dKV-Cache (Ma ほか 2025年) が指摘するように、conventional KV cache は strict autoregressive decoding pattern を前提とした最適化であり、DLM の双方向・多段推論にはそのままでは適用できない。
Block-level KV cache: BD3-LM
BD3-LM (Arriola ほか 2025年) は訓練時にブロック構造を埋め込む設計で、ブロック間に causal mask を入れる。これにより、
- 完成したブロック \(B_{<m}\) の K/V は固定で、それ以降のステップで再利用可能
- ブロック内は bidirectional だが、ブロックが完成すれば外向きには「拡張された 1 トークン」として振る舞う
- 可変長生成も自然に成立する
という訓練と推論の整合が取れた KV cache が成立する。LLaDA の semi-AR サンプリングが「訓練しないバージョン」の block KV cache なら、BD3-LM はそれを「訓練レベルで保証した」版である。
Training-free DualCache: Fast-dLLM
Fast-dLLM (Wu ほか 2025年) は block 構造を仮定しつつ、訓練し直さずに KV cache を導入する DualCache を提案する。観察は「連続する diffusion ステップ間で K/V がほぼ変わらない」ことで、これを利用して prefix(既に確定した左側)と suffix(まだ mask の右側)の両方を cache する。
具体的には、
- Prefix cache: prompt 部分や既に確定した位置の K/V を保存。一度計算したら再利用
- Suffix cache: 未確定 mask 位置の K/V も、近接ステップでの変化が小さいため近似的に reuse
このアプローチで LLaDA / Dream 上で 27× のスループット改善を < 1% の accuracy 低下で達成している。Fast-dLLM の貢献は「parallel decoding + DualCache」の組み合わせで、両者の効果が掛け算で乗ることを示した点にある。
dKV-Cache: 遅延条件付きキャッシュ
dKV-Cache (Ma ほか 2025年) は、token 表現は確定後に安定する という観察を出発点とする。masked 状態の K/V は次ステップで大きく変わるが、unmask されて確定したトークンの K/V は以降ほとんど変わらない。そこで、
- 確定した時点では即 cache せず、1 ステップ遅らせて から cache に追加
- 遅延 cache に入れた K/V は以降ステップで固定とみなす
この設計で 2-10× の加速を、品質ほぼ無劣化で実現している。dKV-Cache の知見は他の cache 系手法にも影響を与えており、「いつ cache に commit するか」の選択が品質-速度の重要な dial であることを示した。
Adaptive cache 系: d²Cache、Elastic-Cache
さらに細粒度の制御を入れる方向に研究が進んでいる。
- d²Cache (Jiang ほか 2025年): fine-grained dual adaptive caching。KV 状態を時間軸で「変化が速い/遅い」に分類し、速いものだけを refresh、遅いものは reuse する。最大 34× を報告
- Elastic-Cache (Nguyen-Tri ほか 2025年): attention/depth-aware adaptive refresh。深い層の attention drift を検出して、必要な層だけ refresh する。最大 45× を報告
- FreeCache (Hu ほか 2025年): クリーン token の KV / 特徴を cache、動的位置のみ refresh。AR verifier との組み合わせで guidance も統合(guidance 章にも関連)
これらの adaptive cache 系は、「cache の hit 率を最大化する」という単純な目的に対し、attention pattern や depth profile の解析を入れた洗練版である。報告 speedup は実装条件依存だが、サンプラ設計と組み合わせれば 30-45× 級の加速が現実的に届く水準になっている。
| 手法 | アプローチ | 報告速度向上 | 訓練要否 |
|---|---|---|---|
| BD3-LM block cache (Arriola ほか 2025年) | training-level の block causal 構造 | 構造的に成立 | block 訓練要 |
| Fast-dLLM DualCache (Wu ほか 2025年) | training-free, prefix + suffix の近似 cache | 27× (LLaDA/Dream) | training-free |
| dKV-Cache (Ma ほか 2025年) | 確定後の token を 1 step 遅らせて cache | 2-10× | training-free |
| d²Cache (Jiang ほか 2025年) | 変化速度別の dual adaptive cache | 最大 34× | training-free |
| Elastic-Cache (Nguyen-Tri ほか 2025年) | depth-aware adaptive refresh | 最大 45× | training-free |
| FreeCache (Hu ほか 2025年) | clean token cache + dynamic refresh | guidance との統合 | training-free |
Feature Cache
中間活性化の冗長性
Feature cache は KV cache のさらに先に位置する加速戦略で、Transformer 内部の中間活性化(attention 出力、MLP 出力、residual stream 等)を時間方向で再利用する。画像拡散の DeepCache (Ma, Fang, と Wang 2024年) が起源で、U-Net の中間特徴が連続する denoising step 間で強い相関を持つことを観察し、深い層の計算を skip して shallow 層だけ更新する設計を示した。
DiT (P. Chen ほか 2024年) や Learning-to-Cache (Ma, Fang, Mi, ほか 2024年) は同じ発想を Transformer 拡散に持ち込み、層単位での再計算スキップを実現した。動画拡散の FasterCache (Lv ほか 2025年) も同系統で、長系列・複数フレームに対する中間特徴の再利用を最適化している。
これらの画像・動画拡散側の知見が、DLM にもほぼそのまま転用できる。
dLLM-Cache: prompt と response の冗長性分離
dLLM-Cache (Z. Liu ほか 2025年) は DLM 特有の構造を活かした feature cache を提案する。観察は次の 2 点である。
- Prompt token は denoising 過程でほぼ静的: 観測済みのトークンなので予測は変わらず、その中間特徴も変化しない
- Response token は sparse に進化: 確定したトークンは安定するが、まだ mask の位置は徐々に変化する
そこで、
- Prompt 部分には long-interval cache を当てる(数十ステップに 1 度の更新で十分)
- Response 部分には short-interval adaptive cache を当て、軽量な V-verify(value 類似度チェック)で「実際に変わったか」を検出して必要な時だけ refresh する
この設計で LLaDA-8B / Dream-7B 上で 9× の end-to-end 加速を達成している。「prompt と response で異なる冗長性を持つ」という DLM 固有の構造に着目した点が、画像拡散の feature cache とは異なる貢献である。
d²Cache と Elastic-Cache の位置付け
セクション 1.3 で触れた d²Cache (Jiang ほか 2025年) と Elastic-Cache (Nguyen-Tri ほか 2025年) は、本来 KV cache の側にも feature cache の側にも分類可能な手法である。KV と中間特徴を統一的に「diffusion step 方向に変化する状態」として扱い、変化速度別に refresh policy を切り替える。
実用上、これらは KV cache と feature cache の融合形と見るのが正確で、survey (Li ほか 2025年) でも両者の橋渡しとして位置付けられている。
FreeCache: guidance との統合
FreeCache (Hu ほか 2025年) は、KV / feature cache に加えて、AR verifier を guidance として組み合わせる。
- 確定済み(clean)トークンの KV / feature を cache、再計算しない
- 動的位置の予測は DLM が行い、AR verifier が承認 or 否認
- guidance の役割(出力の coherence 担保)と cache(計算量削減)が同じ仕組みで成立
これは「cache と guidance は本質的に同じインフラの上に乗せられる」ことを示しており、guidance 章と本章をつなぐ事例である。
| 手法 | アプローチ | 報告速度向上 | 主な特徴 |
|---|---|---|---|
| DeepCache (Ma, Fang, と Wang 2024年) | U-Net 中間活性化の reuse | 画像拡散の原型 | training-free |
| Δ-DiT (P. Chen ほか 2024年) | DiT 向け training-free 加速 | DiT に転用 | training-free |
| Learning-to-Cache (Ma, Fang, Mi, ほか 2024年) | Transformer 拡散の層 cache | 学習で cache policy 決定 | 学習要 |
| FasterCache (Lv ほか 2025年) | 動画拡散の長系列 cache | 動画への展開 | training-free |
| dLLM-Cache (Z. Liu ほか 2025年) | prompt 静的 / response 進化の分離 cache | 9× (LLaDA/Dream) | training-free |
| FreeCache (Hu ほか 2025年) | clean token cache + guidance 統合 | guidance 章にも関連 | training-free |
Step Distillation
教師-生徒で diffusion step を圧縮する
ここまでの 4 軸(parallel decoding / unmask 戦略 / KV cache / feature cache)は基本的に training-free な加速で、訓練済みモデルにサンプラや実装を被せるだけで効く。Step distillation はこれと対照的で、追加の訓練コストを払って student モデルを作る方向の加速である。
連続拡散側では Progressive Distillation (Salimans と Ho 2022年) が古典で、\(N\) ステップの teacher を \(N/2\) ステップの student に蒸留することを繰り返し、最終的に 4-8 ステップで teacher 品質に到達する。ADD (Sauer, Lorenz, ほか 2024年) / LADD (Sauer, Boesel, ほか 2024年) は adversarial loss を加えて 1-2 ステップ生成まで到達した。これらの蒸留枠組みは原理的には DLM にも適用可能だが、離散変数特有の問題(離散的な argmax を通る勾配伝搬、token 間相関の保持)に注意が要る。
Di4C: 離散拡散向け蒸留
Di4C (Hayakawa ほか 2025年) は離散拡散向けに設計された蒸留枠組みで、inter-token correlation を明示的に蒸留する点が中核である。
連続拡散では teacher と student の出力分布を直接 KL で近づければ済むが、離散拡散では各位置の周辺分布を合わせても 位置間の同時分布 が崩れる(parallel decoding curse と同根の問題)。Di4C は次元方向の相関項を蒸留目的に加えることで、student が並列に多数位置を確定しても結合分布を保つよう訓練する。
報告では 4-10 ステップの student が teacher 品質に並び、追加で ~2× の加速が得られる。Di4C の貢献は「離散拡散の蒸留では何を保つべきか」を明確化した点にあり、後続の蒸留研究の標準設計になっている。
DLM-One: 1-step generation
DLM-One (T. Chen ほか 2025年) は連続 DLM(embedding-space diffusion)向けの蒸留で、score-based distillation + adversarial regularization を組み合わせて 1 forward pass で系列全体を生成する。報告速度向上は 500× と桁外れで、AR LLM の枠を完全に超える領域に踏み込んでいる。
ただし注意点として、
- DLM-One は連続 DLM 側の手法で、masked DLM(離散)には直接適用できない
- 1-step 生成の品質は teacher に比べてやや劣化する場合があり、「速さ全振り」のオプション
- 蒸留コストが大きく、再現には大規模な計算資源を要する
それでも 500× という数字は印象的で、step distillation が「最後の桁を取りに行く」加速軸であることを示している。
| 手法 | アプローチ | 報告速度向上 | 対象 |
|---|---|---|---|
| Progressive Distillation (Salimans と Ho 2022年) | \(N \to N/2\) を反復 | 連続拡散の古典 | 連続 |
| ADD (Sauer, Lorenz, ほか 2024年) / LADD (Sauer, Boesel, ほか 2024年) | adversarial diffusion distillation | 1-2 step まで | 連続 |
| Di4C (Hayakawa ほか 2025年) | inter-token correlation を明示的に蒸留 | 4-10 step, ~2× | 離散 (DLM) |
| DLM-One (T. Chen ほか 2025年) | score-based + adversarial、1 forward | 500× | 連続 DLM |
5 軸の組み合わせと商用クラス DLM
加速軸は独立に乗る
冒頭で述べたとおり、5 つの加速軸は 互いに独立で、組み合わせると掛け算的に効く。実装上頻出する組み合わせは次のパターンである。
- Fast-dLLM + KV cache + Feature cache: parallel decoding (10×) × DualCache (3×) × feature cache (2-3×) で 30-100× オーダー
- BD3-LM + block cache + adaptive feature cache: 訓練時に block 構造を入れた上で、cache 戦略を重ねる
- Di4C 蒸留後の student + parallel decoding + cache: 蒸留で base NFE を削減し、その上に training-free 加速を被せる
Fast-dLLM 自身が parallel decoding と KV cache の組み合わせで 13× / 27.6× を達成しているように、サンプリング設定の単純な変更だけで 5-10× は届く。さらに distillation を被せれば 100× 級の加速も視野に入る。
Mercury と Gemini Diffusion
商用クラスの DLM はこれらの加速を統合的に実装している。
- Mercury (Labs ほか 2025年): Inception Labs による商用 DLM。診断・コード生成等で 数千 token/sec を実現と報告しており、同等品質の AR LLM を上回るスループット
- Gemini Diffusion (Google DeepMind 2024年): Google DeepMind の DLM 製品。並列生成と低レイテンシを売りにする
これらは「DLM が AR を上回る速度域に達した」という事実の最も具体的な証拠である。AR LLM のスループットはハードウェアと最適化で頭打ちになる傾向があるが、DLM は並列度というアルゴリズム側の dial を持つため、まだ伸びしろが大きい。
AR vs DLM のレイテンシ位置関係
ベンチマーク条件の標準化は未確立だが、現時点での粗いレイテンシ位置関係は次のようになる。
| クラス | 代表 | スループット (token/sec) |
|---|---|---|
| AR LLM (vanilla) | Llama-3 8B | ~50-100 |
| AR LLM (optimized) | vLLM / TensorRT-LLM | ~100-500 |
| DLM (naive sampler) | LLaDA-8B 標準 | ~10-50 |
| DLM (Fast-dLLM 系) | LLaDA + parallel + cache | ~500-1500 |
| DLM (商用) | Mercury / Gemini Diffusion | 数千 |
表 5 の数値は実装と評価条件で大きく変動するため絶対視は避けるべきだが、最適化された DLM が AR を上回りうるという質的な傾向は確立されつつある。
Open Challenges
これらの加速技術はまだ発展途上で、いくつもの未解決問題が残っている。
評価軸の標準化
サンプラと cache の組み合わせが爆発的に多いため、「どの設定で速度を測るか」が論文ごとに異なる。同じモデルでも、
- 評価ベンチマーク(GSM8K / MATH / HumanEval / MMLU)
- 系列長(短答 vs 長文)
- 並列度 / 閾値 / cache hit 率の設定
- ハードウェア(GPU 種別、batch size)
によって 10× 単位で結果が変わる。quality-NFE 曲線 を統一フォーマットで報告することが期待されるが、現状では各論文が独自の軸を採っており直接比較が難しい。
長文での性能維持
報告されている加速の多くは、数百〜千トークン程度の中程度の系列長での測定である。長文(数千〜数万トークン)では、
- 並列化したときの parallel decoding curse の影響が拡大
- cache hit 率が下がる(位置 i と位置 j の遠距離依存)
- semi-AR にしても block 数が増えて KV 効率が劣化
という問題が顕在化する。LongLLaDA (X. Liu ほか 2025年)、UltraLLaDA (He ほか 2025年) などの長 context 対応研究は始まっているが、加速技術と長文性能の両立は open である。
蒸留後の guidance 互換性
Step distillation で得られた student は、teacher と異なる出力分布を持つ。これに対し、
- CFG の guidance scale はそのまま使えるか
- 蒸留後に guidance を効かせると品質が落ちないか
- guidance を取り込んだ蒸留を最初から行うべきか
といった問いは未整理である。連続拡散側では guidance distillation の研究があるが、離散 DLM 向けの体系的な検討はこれからの領域である。
Block KV cache と guidance の干渉
BD3-LM のように block 構造を持つモデルで guidance を当てる場合、
- block 境界をまたぐ classifier-free guidance はどう設計するか
- 完成済み block の K/V を cache したまま guidance を効かせると、guidance signal が伝わらない位置が出る
- block 内 guidance と block 間 guidance を分離する必要があるか
といった構造的な問題がある。これは guidance 章とも密接に関わる。
サンプラ設計の探索空間
セクション 1.2 で挙げたように、サンプラの dial が多すぎる。
- 確定戦略(top-\(k\) / threshold / learned filter)
- 再 mask 戦略の有無と予算
- 温度(位置選択 / トークン予測)
- Block 幅
- Cache の refresh policy
- 蒸留 student の使用有無
これらの組み合わせ最適化は手作業では覆い切れず、AutoML 的な探索が必要になる規模である。「サンプラそのものを学習する」方向(Learn2PD、dParallel)は端緒だが、本格的な研究はこれからである。
→ 詳細: DLLM 分野の現状と未解決問題
まとめ
DLM の推論加速は、独立に機能する 5 つの軸 — Parallel Decoding / Unmasking & Remasking / KV Cache / Feature Cache / Step Distillation — が掛け算的に組み合わさる多次元の設計空間である。Parallel decoding curse という DLM 固有の落とし穴を回避しつつ並列性を引き出す confidence-aware / adaptive 系の手法(Fast-dLLM、APD、SlowFast)が training-free で 10-30× の加速を実現し、これに dLLM-Cache や Elastic-Cache を重ねれば 30-50× オーダー、さらに Di4C / DLM-One の蒸留を被せれば 100-500× 級の加速に届く。
商用クラスの Mercury や Gemini Diffusion は既に AR LLM を上回るスループットを実現しており、「DLM は遅い」という素朴な印象は現状の最先端には当てはまらない。一方で、評価軸の標準化、長文性能の維持、guidance との干渉、サンプラ設計の探索空間など、open な問題群は数多く残っている。本章で扱った 5 軸を「独立に組み合わせ可能な道具」として把握しておくと、論文を読む際にも新手法の位置付けが素早く見える。