Survey: Li et al. 2025
本書は MDLM・LLaDA・MaskGIT・Block Diffusion といった主要文献を一本ずつ縦に深掘りすることで、拡散言語モデル(Diffusion Language Model, DLM)の定式化と実装の最先端を読み解く構成になっている。一方で Li らのサーベイ “A Survey on Diffusion Language Models” (Li ほか 2025年) は、同じ分野を横方向に俯瞰し、論文数の急増・主要モデルの時系列・タスク別の応用までを 1 本でまとめている。本章はこのサーベイそのものを 1 章として整理し、本書全体への地図として機能させる。サーベイを直接読まなくても、(1) どの領域がカバーされているか、(2) 既存章でどこを深掘りしているか、(3) サーベイでしか触れられていない領域はどこか、を一気に把握できる構成にしている。
サーベイの基本情報
| 項目 | 内容 |
|---|---|
| タイトル | A Survey on Diffusion Language Models |
| 著者 | Tianyi Li, Mingda Chen, Bowei Guo, Zhiqiang Shen |
| 公開 | arXiv:2508.10875 (2025 年 8 月) |
| GitHub | Awesome-DLMs |
サーベイの本文は 8 セクション構成で、§2 で分類体系、§3 で訓練、§4 で推論、§5 でマルチモーダル、§6 で性能比較、§7 で応用、§8 で課題と将来方向を扱う。GitHub レポジトリには対応する論文リストが整理されており、新規論文のキャッチアップにも有用である。
研究分野の規模感
サーベイの導入で強調されているのは、DLM 研究の急増である。離散拡散の foundational paper である D3PM を引用する論文のうち、タイトル / アブストラクトに “language” を含むものを「離散 DLM 関連論文」として集計すると、2024 年から 2025 年にかけて発表数が指数的に増えている。連続埋め込み拡散(continuous DLM)は早期から研究されてきたが、2024 年以降は離散拡散の方が圧倒的に活発である。
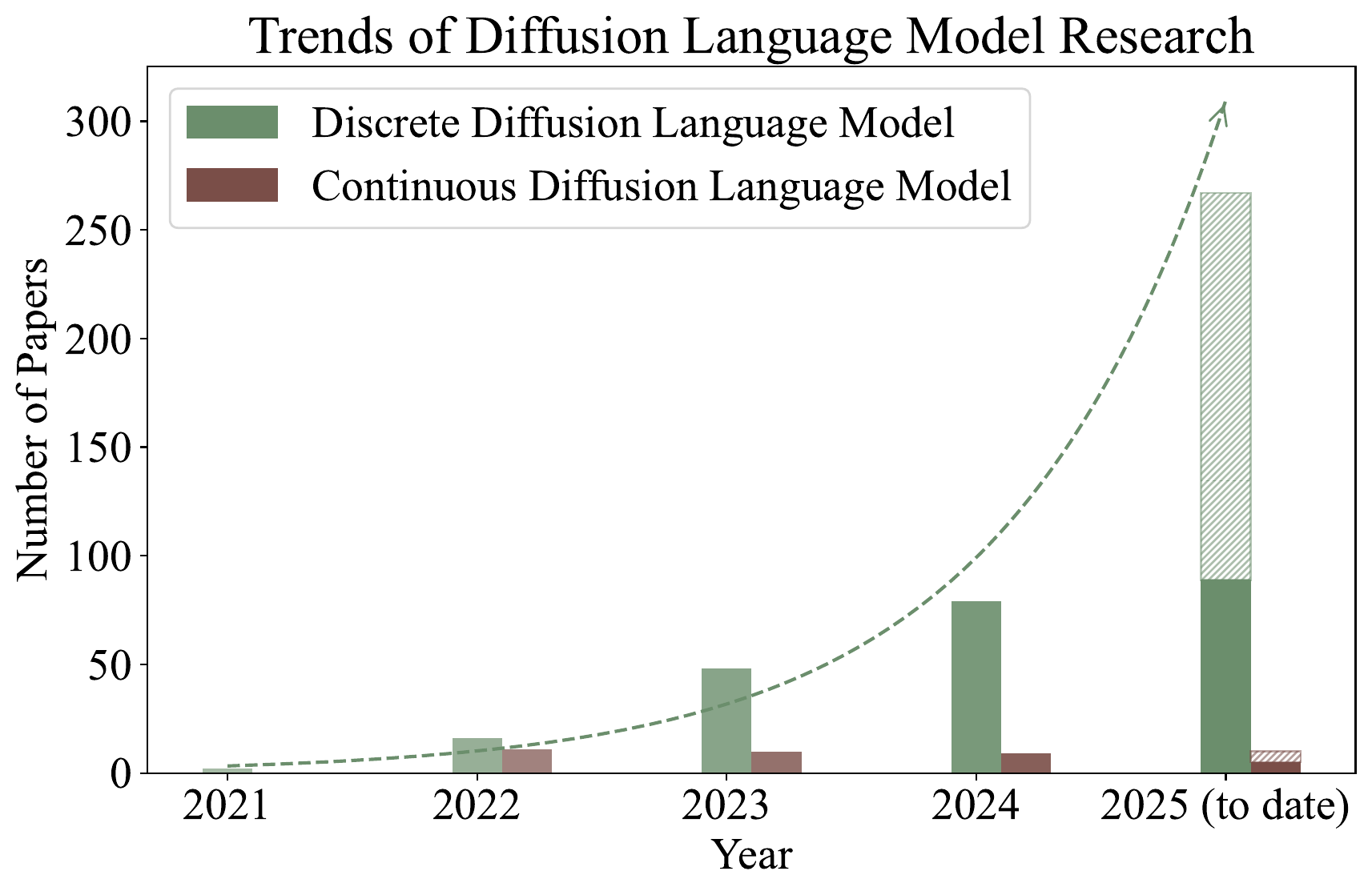
図 1 を見れば、なぜ本書が MDLM・LLaDA など離散拡散側に章を厚く配置しているかが分かる。研究の重心が離散側に移った理由はいくつかある。第一に、MDLM が「重み付き BERT 訓練」という極めて簡潔な目的関数に集約されたこと。第二に、LLaDA が 8B スケールで AR 同サイズと同等性能を示したこと。第三に、商用クラスの Mercury や Gemini Diffusion が登場し、実用性が見えてきたことである。
主要モデルの時系列地図
サーベイは DLM のタイムラインを 3 色に分けて整理している: 連続埋め込み(continuous)、離散(discrete)、マルチモーダル(multimodal)の 3 系統である。
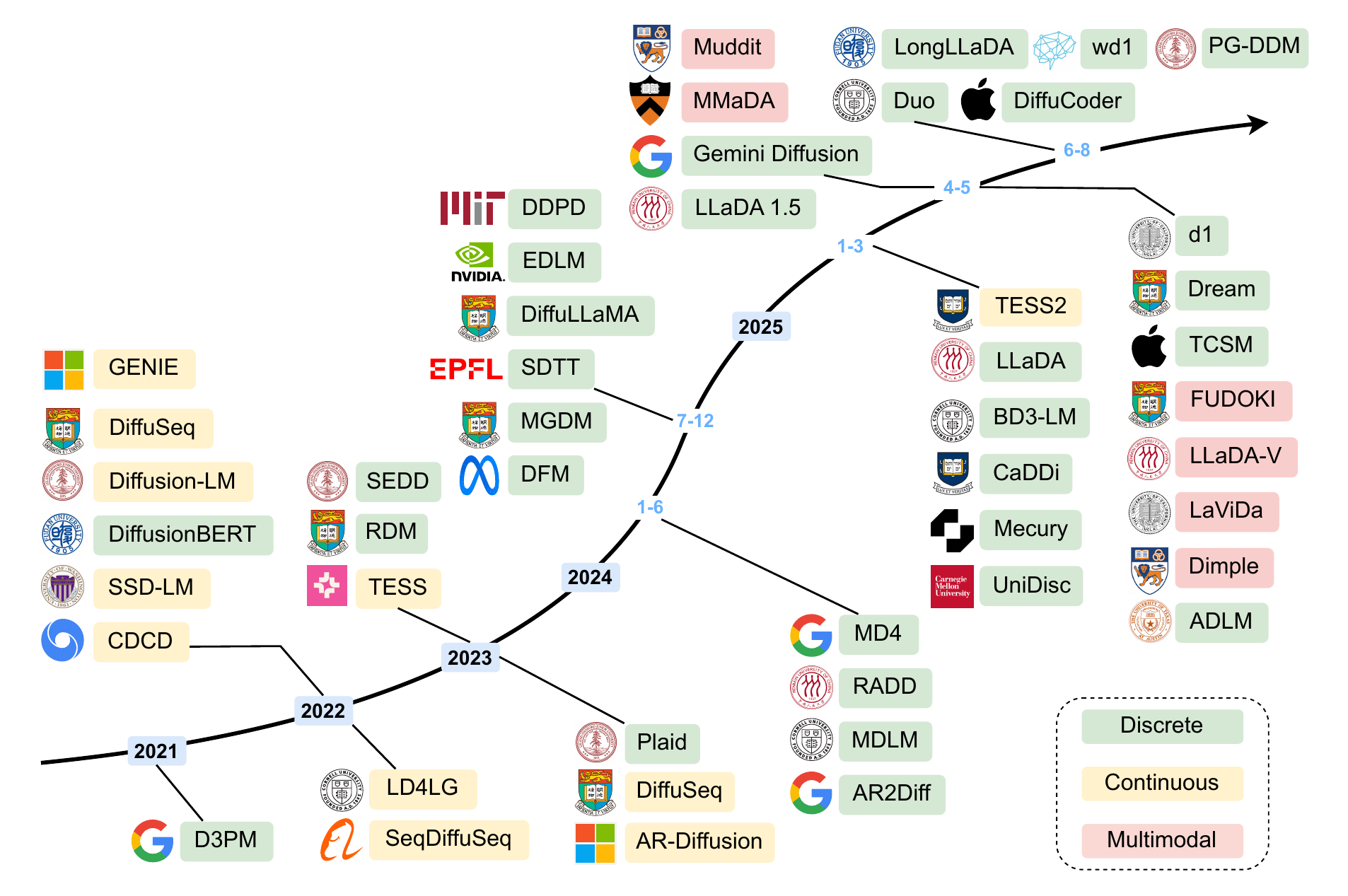
図 2 から読み取れる主要な流れは次のとおりである。
- 2022 年以前: Diffusion-LM, SED, CDCD など連続埋め込み拡散が中心。画像拡散の枠組みを直接テキストに持ち込もうとした時代
- 2023-2024 年: D3PM (2021) を起点に、SEDD, MDLM, MD4, RADD などの離散拡散の定式化が一気に成熟。
[MASK]トークンを使う absorbing diffusion が事実上の標準に - 2025 年: LLaDA-8B が from-scratch で AR 同等性能を示し、Dream-7B が AR からの adaptation で competitive な結果を出す。さらに LLaDA-V / MMaDA / Dimple などマルチモーダル化が一気に進む
- 商用化: Mercury (Inception Labs) と Gemini Diffusion (DeepMind) が実用速度(数千 tokens/秒)で出てくる
→ 詳細: Recent Discrete DLMs
→ 詳細: Multimodal DLM
サーベイの分類体系(taxonomy)
サーベイの中核は次の 4 軸での taxonomy である。
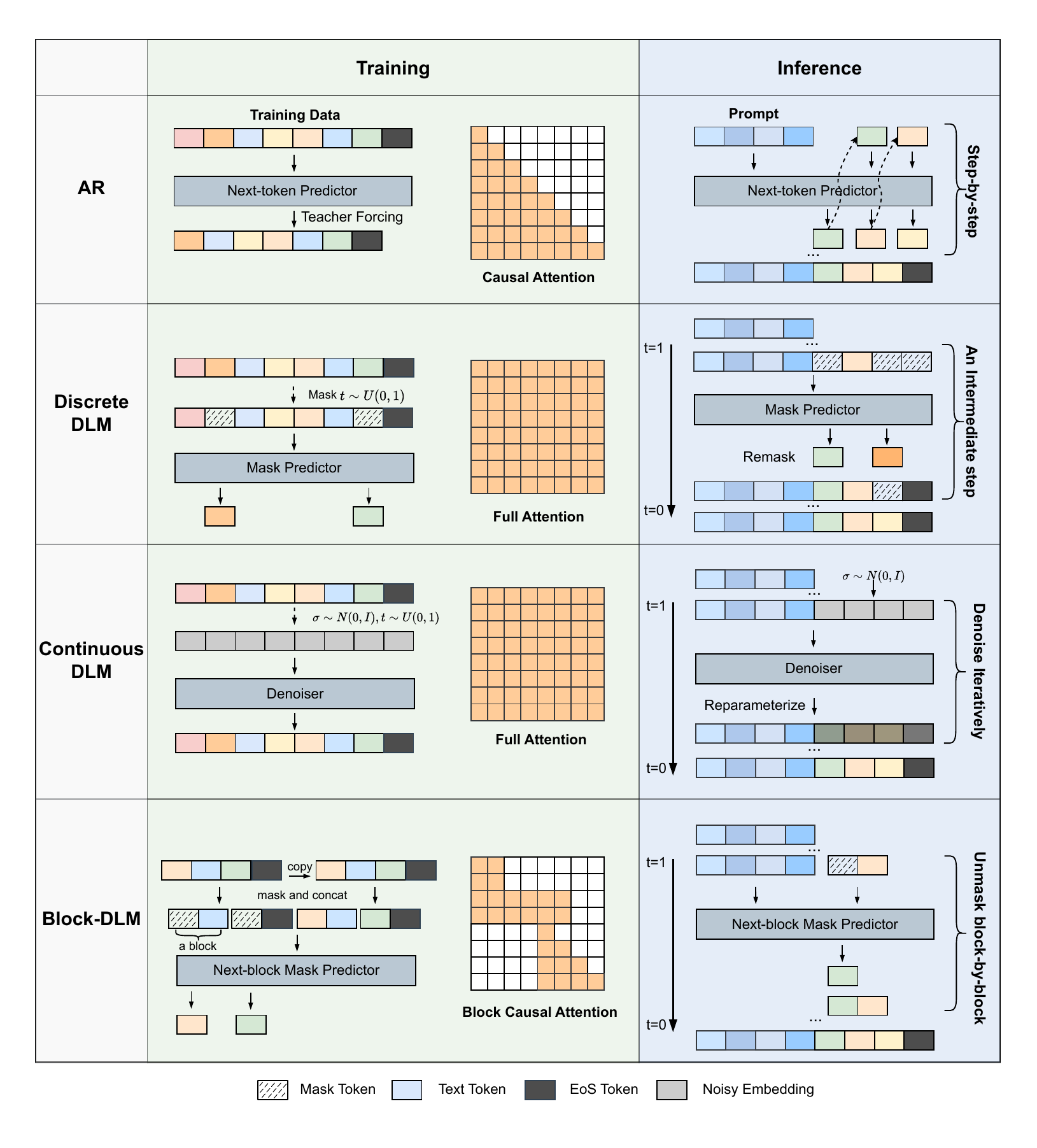
図 3 の 4 軸を簡潔に整理する。
- Paradigms (§2): 拡散がどの空間で起きるか。連続 / 離散 / ハイブリッド AR-Diffusion の 3 分類
- Training Strategies (§3): pre-training(from scratch / AR adaptation / image-diffusion adaptation)と post-training(SFT, GRPO 系 RL, preference optimization)の 2 軸
- Inference & Optimization (§4): parallel decoding, unmasking/remasking, guidance, efficiency(KV cache, feature cache, step distillation)
- Multimodal & Applications (§5, §7): マルチモーダル DLM、conventional NLP, code generation, computational biology, robotics
本書はこの taxonomy のうち、Paradigms と Training の Pre-training を縦に深掘り(MDLM / LLaDA など)、残りを補完する形で新規章を追加している。
本書とサーベイの対応表
サーベイの各サブセクションと本書の対応章を 表 1 に示す。本書を読む際の入口として、また「サーベイを読みながら本書の深掘りに飛ぶ」ための索引として使ってほしい。
| サーベイのセクション | 主要トピック | 本書の対応章 | カバレッジ |
|---|---|---|---|
| §2.1 Continuous DLMs | Diffusion-LM, SED, CDCD, Plaid, TESS | Embedding-Space Diffusion | 既存章でカバー |
| §2.2 Discrete DLMs | D3PM, SEDD, MDLM, LLaDA, Dream, RADD, DFM, GIDD | MDLM / LLaDA / D3PM and SEDD / Recent Discrete DLMs | 既存 + 新章 |
| §2.3 Hybrid AR-Diffusion | SSD-LM, AR-Diffusion, BD3-LM, CtrlDiff, SpecDiff, SDAR, TiDAR, SDLM | Block Diffusion / Hybrid AR-Diffusion | 既存 + 新章 |
| §3.1 Pre-training | from scratch / AR adaptation / image-diffusion adaptation | LLaDA / AR→DLM Adaptation | 既存 + 新章 |
| §3.2 Post-training | DoT, DCoLT, diffu-GRPO, UniGRPO, VRPO 系 | Post-Training (RL) | 新章 |
| §4 Inference | parallel decoding / KV cache / feature cache / step distillation | Inference Acceleration | 新章 |
| §4.3 Guidance | A-CFG, Freecache, DINGO | Guidance | 新章 |
| §5 Multimodal DLMs | LLaDA-V, MMaDA, Dimple, LaViDa, Fudoki, Muddit | Multimodal DLM | 新章 |
| §6 Performance Study | ベンチマーク横断比較 | — | サーベイの図 6 を直接参照 |
| §7 Applications | Code, Bio, Robotics, NLP タスク群 | Applications | 新章 |
| §8 Challenges | parallelism trade-off, infrastructure, long-context, scalability | Open Problems | 既存章でカバー |
リンク先のファイルはすべて本書内に存在する章である。サーベイで興味を持った領域があれば、対応章に飛ぶことで定式化や実装の細部まで踏み込める。
パラダイム 3 分類の意義
サーベイは拡散がどの空間で起きるかに基づき、連続 / 離散 / ハイブリッド AR-Diffusion の 3 分類を採用している。これは本書の 概要 で採用していた「絶対量子化された離散拡散」と「連続埋め込み拡散」の 2 項対立よりも、ハイブリッドという第三軸を加えている点に意義がある。
本書の overview では、現代的な DLM の中核として MDLM 起源の「[MASK] を埋める iterative refinement」を強調し、Diffusion-LM 系の連続埋め込み拡散を別系統として位置づけていた。これは MDLM/LLaDA を理解するための導入としては適切である。しかし、サーベイの 3 分類を加えることで、より広い構造が見える。
具体的には、AR と DLM は連続体として捉えるべきである、という見方が立つ。完全な AR は「ブロック長 1 で因果的」な極端ケース、完全な DLM は「全位置を同時に並列生成」する反対の極端ケースであり、Block Diffusion(BD3-LM)や SDAR, TiDAR などのハイブリッド AR-Diffusion は、その中間でブロック単位の半自己回帰を実現する。サーベイがこの 3 分類を明示することで、本書の Block Diffusion 章が単発の派生形ではなく、AR と DLM の連続体の中の一点として自然に位置づけられる。
このハイブリッド軸を意識すると、SpecDiff(speculative decoding に DLM を組み込む)や TiDAR(DLM で並列生成しつつ AR で出力)など、AR の利点と DLM の利点を組み合わせる工夫が今後増えると予想できる。サーベイで関連論文がまとまった節を持っているのはこのためである。
→ 詳細: Block Diffusion
→ 詳細: Hybrid AR-Diffusion
サーベイで強調されている重要な事実
サーベイを読み進めると繰り返し言及される、重要な観察事実を以下にまとめる。各項目は本書の対応章で詳しく扱われるが、まずサーベイの俯瞰として頭に入れておくと、個別論文を読むときの位置づけが鮮明になる。
1. 離散 DLM の方が連続 DLM より圧倒的に多い (2025 年時点)
連続埋め込み拡散は 2022 年頃の Diffusion-LM, SED から始まる初期の主流であったが、[MASK] を使う離散拡散の方が定式化が簡潔で(MDLM の重み付き BERT 損失)、かつスケールしやすい(LLaDA-8B)ことが判明し、研究の重心は離散側に移った。図 1 の傾向はこれを反映している。
2. LLaDA-8B が「from-scratch で AR 同サイズと同等」を初めて示した
それまでの DLM はベンチマークで AR に劣っていたが、LLaDA-8B (Nie ほか 2025年) が同等の事前訓練データで LLaMA3-8B と互角の性能を出した。これは「DLM は本質的に AR より弱い」という当時の暗黙の仮定を覆すマイルストーンであった。サーベイは LLaDA を分岐点として位置づけている。
3. マルチモーダル DLM が新しいフロンティア
LLaDA-V, MMaDA, Dimple, LaViDa などが 2025 年に集中して登場した。AR 系の VLM(LLaVA など)と異なり、DLM の双方向 context は cross-modal 推論や統一的な「理解 + 生成」モデルに自然に向く。サーベイの §5 が独立した章として扱われているのはこのためである。
4. 商用クラス(Mercury, Gemini Diffusion)の登場
Inception Labs の Mercury (Labs ほか 2025年) と Google DeepMind の Gemini Diffusion (Google DeepMind 2024年) が 2024-2025 年に登場し、数千 tokens/秒の推論速度を実現している。学術界の DLM がスケール 8B 程度に留まる中、商用側ではすでに実用速度のサービスが動いている点が示唆的である。
5. データ効率が AR より高い可能性
サーベイは複数の論文を引用し、DLM が multi-epoch 訓練で AR より効果的にデータを活用できる傾向を指摘している。これは ELBO の重み付け項 \(1/t\) が同じデータを異なるマスク率で繰り返し見せる効果と関係している。データが律速になりつつある現代の LLM 訓練において、これは無視できない利点である。
サーベイで言及されているが本書では深掘りしない領域
地図として機能させるため、本書が「サーベイに任せる」領域も明示しておく。
Performance Study (§6)
サーベイは GSM8K, HumanEval, MMLU など主要ベンチマークで DLM を AR と横並びで比較する図を提供している。本書ではこの種の網羅的なベンチマーク再現は扱わない(章ごとに代表的な数値は引用するが、横並び比較はサーベイの図を直接見るのが速い)。
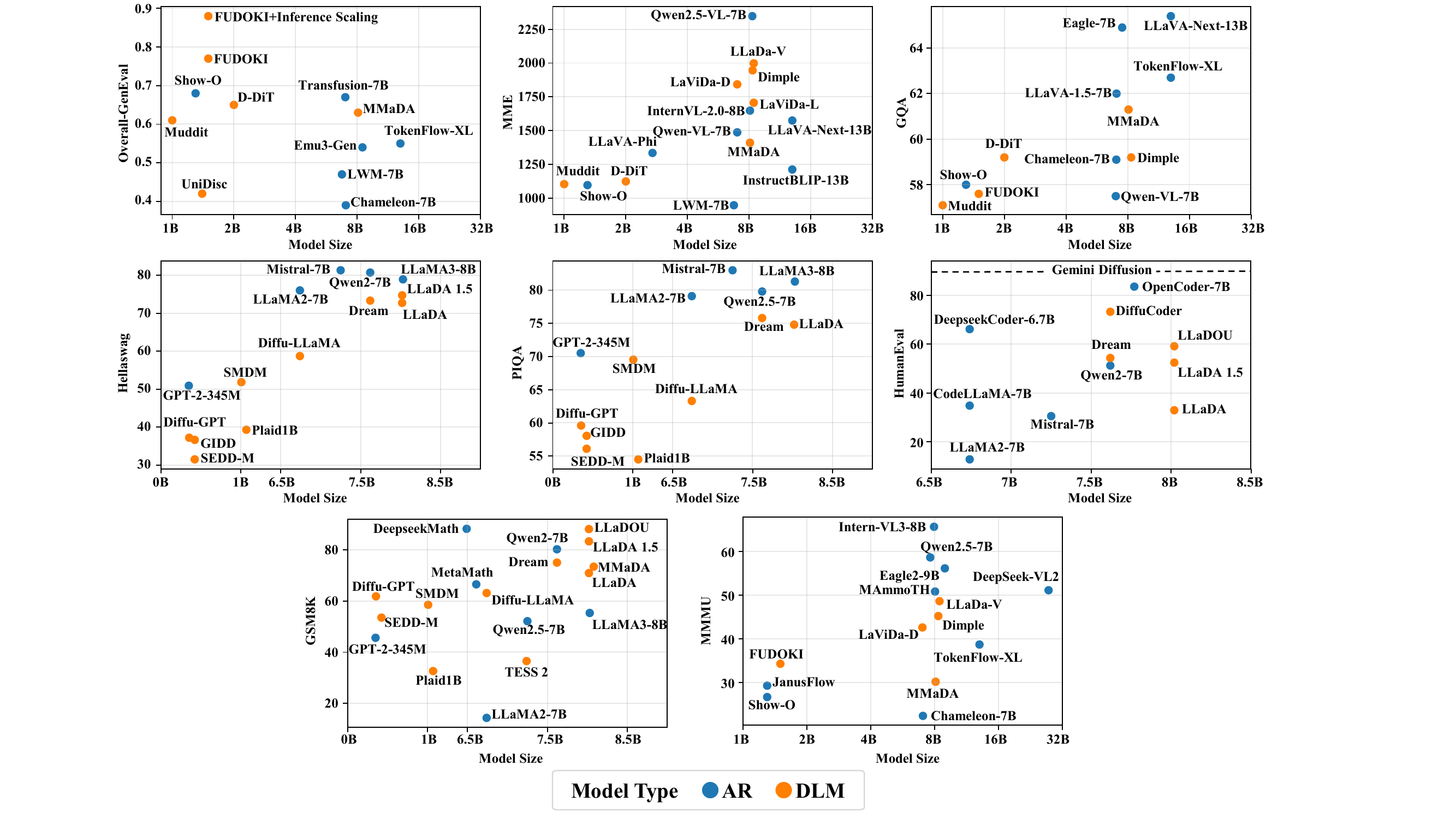
図 4 のような横断比較は、サーベイの図 6 を直接参照するのが効率的である。本書の各章では個別モデルの性能を扱うが、ベンチマーク横並びの全体像はサーベイ側に任せる。
Conventional NLP の細かいタスク群
サーベイは §7 で DiffusionNER, DiffuSum, EdiText, PoetryDiffusion, XDLM などを応用例として列挙している。本書の Applications 章では Code / Biology / Robotics を中心に扱い、conventional NLP の個別タスクへの応用は概観のみとする。タスク固有の論文を網羅したい場合はサーベイの §7 を参照されたい。
読書順の推奨
本書とサーベイをどちらから読むかで、推奨される順序が変わる。
サーベイから入る読者向け
サーベイで全体像をつかんでから、各論を本書で深掘りするパターン。
- サーベイの §1 (Intro), §2 (Paradigms), §8 (Challenges) を流し読み
- 本書の overview で本書の構成を確認
- 本書の MDLM → LLaDA で離散拡散の定式化と最先端を理解
- 興味に応じて Recent Discrete DLMs, Block Diffusion, Hybrid AR-Diffusion, Multimodal DLM などに分岐
- サーベイの §6 (Performance) で全体性能を確認
既存章から入る読者向け
本書のメイン文献を読みながら、サーベイで周辺を補強するパターン。
- 本書の MDLM と LLaDA で核となる定式化を押さえる
- 本書の 連続-離散橋渡し で連続拡散との対応関係を理解
- ここで本章に戻り、表 1 で「自分が読みたい領域がサーベイのどこにあるか」を確認
- 興味のあるサーベイの節 (§3 Training, §4 Inference, §5 Multimodal など) を読む
- 本書の対応章(Post-Training (RL), Inference Acceleration, Multimodal DLM など)で深掘り
- 最後に Open Problems と サーベイの §8 で未解決問題を確認
サーベイは幅優先(広く浅く)、本書は深さ優先(狭く深く)の役割分担になっている。サーベイ単体では各定式化の数式の意味まで踏み込まないし、本書単体では分野全体の論文網羅性は持たない。両方を併読することで、立体的に DLM 研究の全体像が見える。
サーベイは 2025 年 8 月時点での網羅を目指しているが、DLM 分野は月単位で新規論文が出ているため、最新の preprint は GitHub レポジトリ (Awesome-DLMs) で追うのが現実的である。また、サーベイは「何があるか」のリスト化に重点があり、「なぜそうなるか」の数理的説明は最小限である。MDLM の ELBO 導出や LLaDA のサンプリング戦略の細部は、本書の該当章を参照するか、原論文に当たる必要がある。