Inference Acceleration: Speeding Up DLM Generation
Accelerating the inference of Diffusion Language Models (DLMs) is one of the most actively moving areas in recent research. Autoregressive (AR) Large Language Models (LLMs) intrinsically need to execute \(O(L)\) forward passes sequentially for a sequence of length \(L\), and the only room to do better is essentially hardware optimization and speculative decoding. DLMs, in contrast, have a structure that allows all positions to be updated in parallel, so in principle inference can complete in \(T \ll L\) steps. However, naively pushing parallelism causes a quality collapse known as the parallel decoding curse (discussed below), so “how to reconcile parallelism with quality” has emerged as an engineering problem with its own research area.
This chapter organizes acceleration strategies along five axes, centered on §4 of the DLM acceleration survey (Li et al. 2025): (1) Parallel Decoding, (2) Unmasking / Remasking, (3) Key-Value (KV) Cache, (4) Feature Cache, and (5) Step Distillation. The five axes are mutually orthogonal, and combining them yields multiplicative speedups. Inference-time interventions represented by Classifier-Free Guidance (CFG) are more about quality control than acceleration, so they are treated in the Guidance chapter.
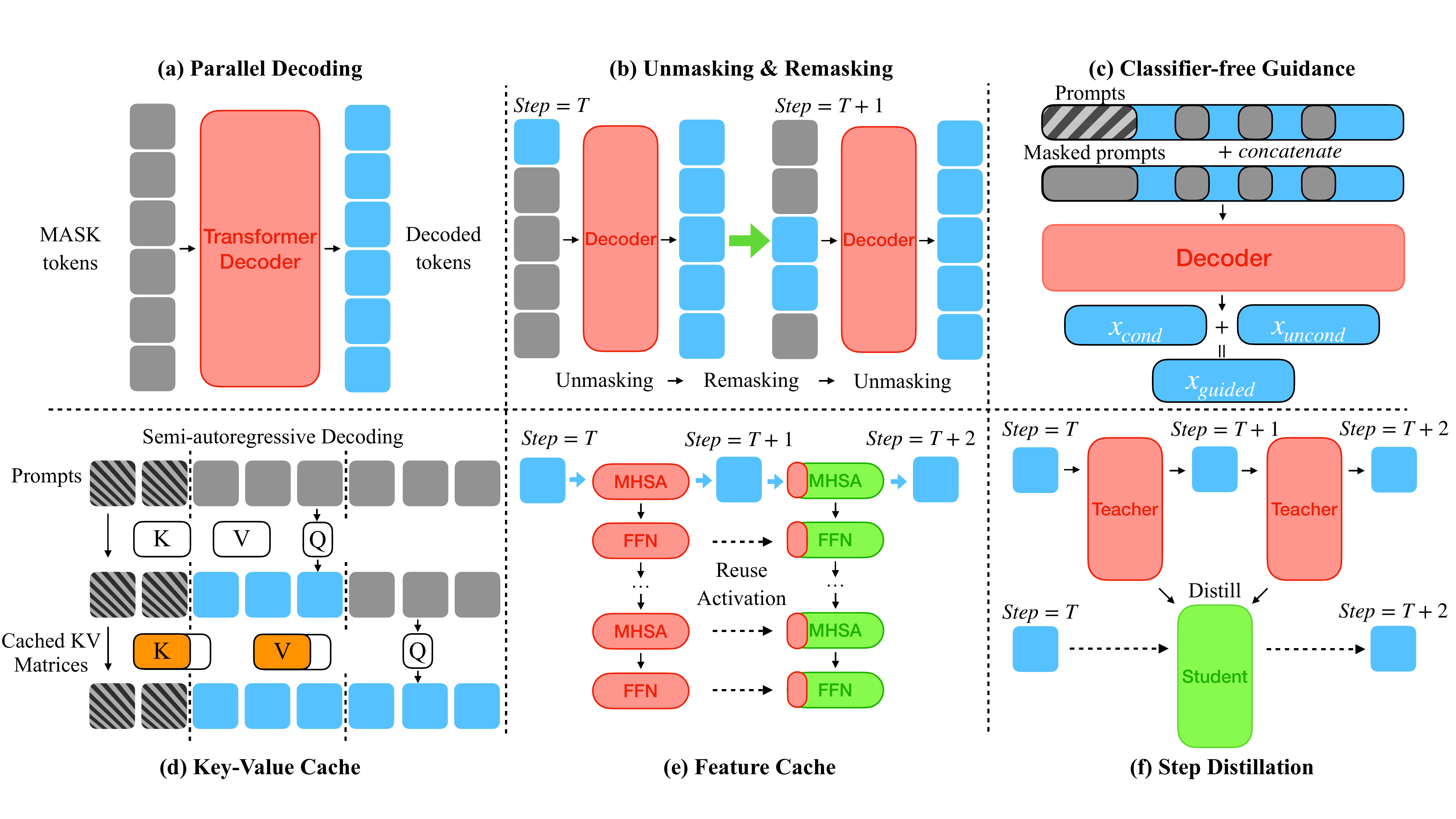
Figure 1 is the map of this chapter. Since CFG is covered in the guidance chapter, the remaining five strategies are explored here in order. Each strategy works independently, but in practice integrated implementations like Fast-dLLM that combine parallel decoding with the KV cache appear frequently. The final section organizes how commercial-class DLMs that combine these techniques (Mercury (Labs et al. 2025), Gemini Diffusion (Google DeepMind 2024)) achieve thousands of tokens per second, surpassing AR LLMs, along with the open challenges that remain.
Parallel Decoding
The Principle of Parallel Decoding and Its Breakdown
A DLM’s forward pass produces the conditional distribution \(p_\theta(x \mid x_t)\) over the entire sequence in a single shot, so it is in principle possible to commit multiple masked positions simultaneously. LLaDA’s (Nie et al. 2025) standard sampler is designed to “unmask the top-\(k\) positions by confidence,” and the larger \(k\) is, the higher the per-step parallelism and the lower the Number of Function Evaluations (NFE).
There is, however, an inherent pitfall here. The prediction distribution \(p_\theta(x^i \mid x_t)\) at each position \(i\) is a marginal distribution that marginalizes out the other masked positions, and when multiple positions are independently argmaxed or sampled, the resulting joint reduces not to a product of conditionals but to a product of independent distributions. As long as the data distribution \(p(x)\) has correlations among tokens, this approximation breaks down more severely as the sequence grows.
Parallel Decoding Curse
Fast-dLLM (Wu et al. 2025) calls this phenomenon the parallel decoding curse, and gives as a canonical example a model trained on data that contains only the two modes ABABAB and BABABA. Since both modes appear with equal probability on the training distribution, the marginal at each position becomes \(p(A) = p(B) = 0.5\). Sampling each position independently in parallel produces sequences such as AAABBB or ABABBA — sequences that do not exist in the training data — with high probability. This is a fundamental failure mode that becomes more pronounced the more parallelism is pushed.
Figure 2 shows the classical curve along which quality drops as the number of steps decreases. Naive parallelization sticks to the lower-left of the curve (few steps, low quality), but the confidence-aware / adaptive strategies discussed below shift the curve itself upward. The core message of parallel decoding research is that “the trade-off between step count and quality is not fixed; it can be moved by sampler design.”
Representative Strategies
Probabilistically grounded solutions converge to the intuition that “only positions whose inter-position dependence is weak should be committed in parallel.” Detecting or approximating this gives rise to the following families.
| Method | Approach | Reported speedup | Training required |
|---|---|---|---|
| Fast-dLLM (Wu et al. 2025) | confidence-aware: unmask everything above a threshold | 13× (LLaDA) / 27.6× (Dream, +cache) | training-free |
| APD (Israel et al. 2025) | A lightweight AR auxiliary dynamically adjusts parallelism | Substantial speedup at preserved quality | aux model required |
| SlowFast Sampling (Wei et al. 2025) | Two-phase: slow stage commits stable tokens, fast stage finalizes in bulk | Up to 34× (+cache) | training-free |
| SpecDiff (Christopher et al. 2025) | Speculative decoding using the DLM as the drafter for AR | 2× over AR / up to 7.2× | AR + DLM |
| Dimple (Yu et al. 2025) | Finds multiple high-confidence tokens at every step | 1.5-7× fewer iterations | training-free |
| Learn2PD (Bao et al. 2025) | A learned filter that predicts which tokens to unmask | Replaces fixed thresholds | learning required |
| dParallel (Z. Chen et al. 2025) | Certainty-forcing distillation that enhances parallelism | Higher parallelism | distillation required |
Fast-dLLM’s threshold method is the simplest and most reproducible. It is a training-free acceleration that “unmasks every position whose predicted probability exceeds a threshold \(\tau\) (typically around 0.9) in one shot,” and it can be dropped onto LLaDA / Dream as-is for order-of-magnitude (10×) speedups. The major advantage is that the quality-speed trade-off is controlled by a single scalar: setting the threshold higher raises parallelism without sacrificing quality, and lowering it drastically reduces NFE.
APD goes one step further and commits in parallel only over the range where the AR auxiliary’s prediction agrees with the DLM’s. This brings the spirit of speculative decoding into DLMs, and although it incurs the cost of an auxiliary model, the guarantee that “parallelism can be pushed without losing quality” is strong. SlowFast splits the procedure into two phases — slow early, fast late — and is also a rediscovery of the MaskGIT-style cosine schedule.
SpecDiff takes the inverse perspective and uses the DLM as a drafter while keeping AR as the protagonist. The pattern of “proposing multiple tokens in parallel with the DLM and verifying with AR” through speculative decoding has been used in practice even before the appearance of commercial DLMs like Mercury, illustrating that AR and DLMs can be “complementary” rather than “adversarial.”
Learn2PD and dParallel represent a recent direction that replaces a fixed confidence threshold with learning. Learn2PD predicts “which position’s prediction is currently trustworthy” with a separate lightweight filter, while dParallel performs certainty-forcing distillation at training time to forcibly raise the confidence at multiple positions. Both embed parallelism on the model side rather than the sampler side.
Unmasking / Remasking Strategies
What to Unmask, What to Remask
The DLM sampling loop has the structure “forward pass → confidence computation → choice of unmask/remask → next step.” Whereas parallel decoding deals with “how much to commit in parallel,” unmasking / remasking strategies deal with “which positions, and in what order, to commit or reconsider.” The two are orthogonal, but in implementations they often come together.
The most basic options are the following three.
- Random remasking: Commit \(k\) random positions at each step. The most naive option, and the lowest quality
- Confidence-ranked remasking: Commit the top-\(k\) positions by confidence (top-1 probability). The standard inherited from MaskGIT (Chang et al. 2022)
- Low-confidence remasking: Even already-committed positions are returned to
[MASK]in the next step if their relative confidence is low
The original Masked DLM paper (Sahoo et al. 2024) compared random and confidence-ranked in ablations and showed that the latter improves quality at no extra cost. This was a language-side reconfirmation of MaskGIT’s findings and is now the de facto standard in DLM implementations.
Fast-dLLM’s Global Threshold
Fast-dLLM (Wu et al. 2025) replaced the fixed-count top-\(k\) heuristic with a global threshold. By switching to a design that “unmasks every position whose confidence exceeds threshold \(\tau\) in one shot at each step,”
- Early on, almost no positions exceed the threshold, so only one or a few positions are committed per step \(T_{\text{step}}\)
- Late on, the context has solidified and nearly all positions exceed the threshold, so a large number are committed at once
an adaptive scheduling emerges naturally. This can be regarded as a “data-driven derivation” of the MaskGIT cosine schedule. The simplicity of controlling the quality-speed trade-off with a single scalar threshold is a major advantage in both implementation and evaluation.
ReMDM: Refinement via Remasking
ReMDM (Wang et al. 2025) brings the idea of inference-time scaling into DLMs. Mathematically, the reverse process of absorbing diffusion only defines a “one-way transition from [MASK] to non-[MASK],” but ReMDM proposes a sampler that “intentionally remasks already-committed tokens.”
Intuitively,
- A token committed once may, in hindsight, turn out to be of low quality
- Returning the token to
[MASK]and re-predicting allows incorporating downstream context for correction - Increasing the remasking budget gives a smooth trade-off in which quality improves
ReMDM treats this “remasking budget” as a unit of inference compute, and shows that quality can be improved from the same trained model in a manner analogous to increasing the number of steps in an AR LLM. The idea of squeezing quality out by inference-time compute alone from the same trained model is the DLM-side counterpart of DDIM step-count tuning in image diffusion.
The Design Space of Samplers
The combinations explode into a vast space. Even just enumerating axes one should check yields the following.
- Commit strategy (top-\(k\) / threshold / learned filter)
- Remask strategy (none / low-confidence / ReMDM-style budget)
- Temperature (two stages: position selection / token prediction)
- Block structure (fully parallel / semi-AR with block size \(K\))
- Schedule (linear / cosine / learned / adaptive)
Each axis can be moved independently, so the decision of “which to adopt” on the implementation side becomes a research topic in itself. As noted in the open challenges below, the sheer size of the sampler design space is an important open problem in DLM inference acceleration.
→ More: MaskGIT: Origin of Confidence-based Iterative Unmasking
Key-Value Cache
Why the AR KV Cache Does Not Work Naively
The KV cache in AR LLMs rides on the structure of Transformer causal attention that “depends only on the K/V of past tokens.” When a single new token is appended, the past K/V do not change and need not be recomputed, so memory is \(O(L)\) and computation per step is \(O(L)\).
DLMs violate this assumption.
- Each step runs bidirectional attention over the entire sequence
- When a masked position’s prediction is committed, its K/V change in the next step
- As a result, naively, the K/V at all positions are recomputed every step
This forgoes the speed gains that AR’s KV cache provides. As dKV-Cache (Ma et al. 2025) points out, conventional KV caches are optimizations that assume a strict autoregressive decoding pattern, and they do not apply as-is to the bidirectional, multi-stage inference of DLMs.
Block-Level KV Cache: BD3-LM
BD3-LM (Arriola et al. 2025) is a design that embeds block structure at training time, inserting a causal mask between blocks. Consequently,
- The K/V of completed blocks \(B_{<m}\) are fixed and reusable in subsequent steps
- Within a block, attention is bidirectional, but once the block is complete it behaves outward as a “single extended token”
- Variable-length generation also arises naturally
a KV cache that is consistent between training and inference is established. If LLaDA’s semi-AR sampling is “an untrained version” of a block KV cache, BD3-LM is the version “guaranteed at the training level.”
Training-Free DualCache: Fast-dLLM
Fast-dLLM (Wu et al. 2025) assumes block structure but proposes DualCache, which introduces a KV cache without retraining. The observation is that “K/V change very little between consecutive diffusion steps,” and DualCache leverages this to cache both the prefix (the left side already committed) and the suffix (the right side still masked).
Specifically,
- Prefix cache: Save K/V for the prompt portion and for already-committed positions. Once computed, reuse
- Suffix cache: K/V for unfixed mask positions are approximately reused, because changes between nearby steps are small
This approach achieves a 27× throughput improvement on LLaDA / Dream with < 1% accuracy degradation. Fast-dLLM’s contribution lies in showing that the combination of “parallel decoding + DualCache” multiplies the effects of the two components.
dKV-Cache: Delayed Conditional Cache
dKV-Cache (Ma et al. 2025) starts from the observation that token representations stabilize after commitment. While the K/V of masked states change substantially at the next step, the K/V of already-unmasked, committed tokens hardly change thereafter. Hence,
- At the moment a token is committed, do not cache it immediately; add it to the cache one step later
- K/V entered into the delayed cache are treated as fixed in subsequent steps
This design achieves 2-10× speedups with virtually no loss of quality. The insight of dKV-Cache has also influenced other cache-based methods, showing that the choice of “when to commit to the cache” is a crucial dial in the quality-speed trade-off.
Adaptive Cache Families: d²Cache, Elastic-Cache
Research is progressing toward more fine-grained control.
- d²Cache (Jiang et al. 2025): fine-grained dual adaptive caching. Classifies KV states along the time axis into “fast-changing / slow-changing,” refreshes only the fast ones, and reuses the slow ones. Reports up to 34×
- Elastic-Cache (Nguyen-Tri et al. 2025): attention/depth-aware adaptive refresh. Detects attention drift in deep layers and refreshes only the layers that need refreshing. Reports up to 45×
- FreeCache (Hu et al. 2025): Caches KV / features of clean tokens, refreshes only dynamic positions. Combined with an AR verifier, also integrates guidance (related to the guidance chapter)
These adaptive cache families are refined versions in which analyses of attention patterns and depth profiles are added to the simple objective of “maximizing the cache hit rate.” Reported speedups depend on implementation conditions, but combined with sampler design, 30-45× acceleration is realistically within reach.
| Method | Approach | Reported speedup | Training required |
|---|---|---|---|
| BD3-LM block cache (Arriola et al. 2025) | Training-level block-causal structure | Holds structurally | block training required |
| Fast-dLLM DualCache (Wu et al. 2025) | Training-free approximate prefix + suffix cache | 27× (LLaDA/Dream) | training-free |
| dKV-Cache (Ma et al. 2025) | Cache committed tokens one step later | 2-10× | training-free |
| d²Cache (Jiang et al. 2025) | Dual adaptive cache separated by change speed | Up to 34× | training-free |
| Elastic-Cache (Nguyen-Tri et al. 2025) | Depth-aware adaptive refresh | Up to 45× | training-free |
| FreeCache (Hu et al. 2025) | Clean-token cache + dynamic refresh | Integration with guidance | training-free |
Feature Cache
Redundancy in Intermediate Activations
The feature cache is an acceleration strategy that goes one step beyond the KV cache, reusing intermediate activations inside the Transformer (attention outputs, MLP outputs, residual streams, etc.) along the time axis. It originated in image diffusion with DeepCache (Ma, Fang, and Wang 2024), which observed that the intermediate features of a U-Net have strong correlations between consecutive denoising steps, and showed a design that skips computation in deep layers and updates only shallow layers.
DiT (P. Chen et al. 2024) and Learning-to-Cache (Ma, Fang, Mi, et al. 2024) carried the same idea into Transformer diffusion, realizing per-layer recomputation skipping. Video diffusion’s FasterCache (Lv et al. 2025) belongs to the same line, optimizing reuse of intermediate features over long sequences and multiple frames.
These image- and video-diffusion-side findings transfer to DLMs almost as-is.
dLLM-Cache: Separating Prompt and Response Redundancies
dLLM-Cache (Z. Liu et al. 2025) proposes a feature cache that leverages DLM-specific structure. The observations are the following two.
- Prompt tokens are nearly static through the denoising process: As observed tokens, their predictions do not change and their intermediate features do not change either
- Response tokens evolve sparsely: Committed tokens are stable, but positions still masked gradually change
Hence,
- The prompt portion is given a long-interval cache (a refresh once every several tens of steps is sufficient)
- The response portion is given a short-interval adaptive cache, and a lightweight V-verify (value-similarity check) detects “whether it actually changed” and refreshes only when needed
This design achieves a 9× end-to-end speedup on LLaDA-8B / Dream-7B. The contribution differs from the feature cache of image diffusion in that it focuses on the DLM-specific structure of “prompt and response carrying different redundancies.”
Positioning of d²Cache and Elastic-Cache
d²Cache (Jiang et al. 2025) and Elastic-Cache (Nguyen-Tri et al. 2025), discussed in Section 1.3, are methods that can be classified on either the KV-cache side or the feature-cache side. They treat KV and intermediate features uniformly as “states that change along the diffusion-step axis” and switch refresh policies based on change speed.
In practice, these are most accurately viewed as a fusion of KV cache and feature cache, and the survey (Li et al. 2025) also positions them as the bridge between the two.
FreeCache: Integration with Guidance
FreeCache (Hu et al. 2025) combines an AR verifier as guidance on top of KV / feature caches.
- KV / features of committed (clean) tokens are cached and not recomputed
- Predictions for dynamic positions are made by the DLM and approved or rejected by the AR verifier
- The role of guidance (ensuring output coherence) and that of the cache (reducing compute) are realized by the same mechanism
This shows that “the cache and guidance can essentially be placed on top of the same infrastructure” — an example bridging this chapter and the guidance chapter.
| Method | Approach | Reported speedup | Main features |
|---|---|---|---|
| DeepCache (Ma, Fang, and Wang 2024) | Reuse of U-Net intermediate activations | Image diffusion prototype | training-free |
| Δ-DiT (P. Chen et al. 2024) | Training-free acceleration for DiT | Carried over to DiT | training-free |
| Learning-to-Cache (Ma, Fang, Mi, et al. 2024) | Layer cache for Transformer diffusion | Cache policy by learning | learning required |
| FasterCache (Lv et al. 2025) | Long-sequence cache for video diffusion | Extension to video | training-free |
| dLLM-Cache (Z. Liu et al. 2025) | Separated cache for static prompt / evolving response | 9× (LLaDA/Dream) | training-free |
| FreeCache (Hu et al. 2025) | Clean-token cache + guidance integration | Related to guidance chapter | training-free |
Step Distillation
Teacher-Student Compression of Diffusion Steps
The four axes covered so far (parallel decoding / unmask strategy / KV cache / feature cache) are fundamentally training-free accelerations that just overlay a sampler or implementation on top of a trained model. Step distillation contrasts with this, being an acceleration that pays additional training cost to build a student model.
On the continuous-diffusion side, Progressive Distillation (Salimans and Ho 2022) is the classic, repeatedly distilling an \(N\)-step teacher into an \(N/2\)-step student and eventually reaching teacher quality in 4-8 steps. ADD (Sauer, Lorenz, et al. 2024) / LADD (Sauer, Boesel, et al. 2024) added adversarial losses and reached 1-2 step generation. In principle these distillation frameworks are applicable to DLMs too, but issues specific to discrete variables (gradient propagation through discrete argmax, preservation of inter-token correlations) need attention.
Di4C: Distillation for Discrete Diffusion
Di4C (Hayakawa et al. 2025) is a distillation framework designed for discrete diffusion, whose core is to explicitly distill inter-token correlations.
In continuous diffusion, matching the output distributions of teacher and student directly under KL suffices, but in discrete diffusion, matching the marginals at each position can break the joint distribution across positions (the same root cause as the parallel decoding curse). Di4C adds a dimensional-correlation term to the distillation objective, training the student to preserve the joint distribution even when many positions are committed in parallel.
Reports show that 4-10 step students reach teacher quality and yield an additional ~2× speedup. Di4C’s contribution is in clarifying “what should be preserved in distilling discrete diffusion,” and it has become the standard design of follow-up distillation research.
DLM-One: 1-Step Generation
DLM-One (T. Chen et al. 2025) is distillation for continuous DLMs (embedding-space diffusion) that combines score-based distillation + adversarial regularization to generate an entire sequence in 1 forward pass. The reported speedup is 500×, an extreme figure that steps fully beyond the regime of AR LLMs.
There are, however, caveats.
- DLM-One is a method on the continuous DLM side and does not apply directly to masked DLMs (discrete)
- The quality of 1-step generation can be somewhat degraded relative to the teacher; it is the “all-in on speed” option
- Distillation cost is large, and reproduction requires substantial compute resources
Even so, the 500× number is impressive and demonstrates that step distillation is the acceleration axis “for going after the last digit.”
| Method | Approach | Reported speedup | Target |
|---|---|---|---|
| Progressive Distillation (Salimans and Ho 2022) | Iterates \(N \to N/2\) | Classic for continuous diffusion | continuous |
| ADD (Sauer, Lorenz, et al. 2024) / LADD (Sauer, Boesel, et al. 2024) | adversarial diffusion distillation | Down to 1-2 steps | continuous |
| Di4C (Hayakawa et al. 2025) | Explicit distillation of inter-token correlations | 4-10 steps, ~2× | discrete (DLM) |
| DLM-One (T. Chen et al. 2025) | Score-based + adversarial, 1 forward | 500× | continuous DLM |
Combination of the 5 Axes and Commercial-Class DLMs
The Acceleration Axes Stack Independently
As noted at the start, the five acceleration axes are mutually independent and combine multiplicatively. The combinations that appear most often in implementations are the following patterns.
- Fast-dLLM + KV cache + Feature cache: parallel decoding (10×) × DualCache (3×) × feature cache (2-3×) on the order of 30-100×
- BD3-LM + block cache + adaptive feature cache: After embedding block structure at training time, layer cache strategies on top
- Di4C-distilled student + parallel decoding + cache: Reduce base NFE by distillation and overlay training-free acceleration on top
As Fast-dLLM itself achieves 13× / 27.6× with the combination of parallel decoding and KV cache, simple changes to sampling settings alone are enough to reach 5-10×. Adding distillation on top brings 100×-class acceleration into view.
Mercury and Gemini Diffusion
Commercial-class DLMs integrate these accelerations holistically.
- Mercury (Labs et al. 2025): A commercial DLM by Inception Labs. Reports realizing thousands of tokens per second in diagnostics and code generation, surpassing the throughput of AR LLMs of comparable quality
- Gemini Diffusion (Google DeepMind 2024): Google DeepMind’s DLM product. Markets parallel generation and low latency
These are the most concrete evidence of the fact that “DLMs have reached the speed regime in which they outperform AR.” AR LLM throughput tends to hit a ceiling at hardware and optimization, while DLMs hold the algorithmic-side dial of parallelism, so there is still much headroom.
Latency Positioning of AR vs DLM
Benchmark conditions are not yet standardized, but a rough current picture of latency positioning is as follows.
| Class | Representative | Throughput (token/sec) |
|---|---|---|
| AR LLM (vanilla) | Llama-3 8B | ~50-100 |
| AR LLM (optimized) | vLLM / TensorRT-LLM | ~100-500 |
| DLM (naive sampler) | LLaDA-8B standard | ~10-50 |
| DLM (Fast-dLLM family) | LLaDA + parallel + cache | ~500-1500 |
| DLM (commercial) | Mercury / Gemini Diffusion | Thousands |
The numbers in Table 5 vary substantially with implementation and evaluation conditions and should not be taken as absolute, but the qualitative trend that optimized DLMs can surpass AR is being established.
Open Challenges
These acceleration techniques are still under development, and many unresolved problems remain.
Standardization of Evaluation Axes
Because the combinations of sampler and cache are explosively many, “which setting to measure speed under” differs from paper to paper. Even for the same model,
- Evaluation benchmark (GSM8K / MATH / HumanEval / MMLU)
- Sequence length (short answer vs long form)
- Settings of parallelism / threshold / cache hit rate
- Hardware (GPU type, batch size)
can change results by 10× units. Reporting quality-NFE curves in a unified format is desirable, but currently each paper takes its own axes and direct comparison is difficult.
Maintaining Performance on Long Sequences
Many of the reported accelerations are measured on moderately long sequences of hundreds to a thousand tokens. On long-form text (thousands to tens of thousands of tokens),
- The impact of the parallel decoding curse increases when parallelism is pushed
- Cache hit rate drops (long-range dependencies between positions \(i\) and \(j\))
- Even with semi-AR, the number of blocks grows and KV efficiency degrades
these issues become salient. Long-context research such as LongLLaDA (X. Liu et al. 2025) and UltraLLaDA (He et al. 2025) has begun, but reconciling acceleration techniques with long-text performance remains open.
Compatibility of Guidance After Distillation
A student obtained by step distillation has a different output distribution from the teacher. Concerning this,
- Can the CFG guidance scale be used as-is?
- Does applying guidance after distillation reduce quality?
- Should distillation that incorporates guidance be performed from the start?
these questions are unorganized. On the continuous-diffusion side there is work on guidance distillation, but systematic study for discrete DLMs is an area still to come.
Interference Between Block KV Cache and Guidance
When applying guidance to a model with block structure such as BD3-LM,
- How should classifier-free guidance crossing block boundaries be designed?
- If the K/V of completed blocks are cached and guidance is then applied, there will be positions to which the guidance signal does not propagate
- Is it necessary to separate intra-block guidance and inter-block guidance?
these are structural issues. They are closely related to the guidance chapter.
The Sampler Design Space
As listed in Section 1.2, samplers have too many dials.
- Commit strategy (top-\(k\) / threshold / learned filter)
- Presence and budget of remasking strategy
- Temperature (position selection / token prediction)
- Block width
- Cache refresh policy
- Whether to use a distilled student
Combinatorial optimization over these cannot be covered by hand and reaches a scale that calls for AutoML-style exploration. The direction of “learning the sampler itself” (Learn2PD, dParallel) is a beginning, but full-fledged research is still ahead.
→ More: Open Problems in the DLLM Field
Summary
DLM inference acceleration is a multi-dimensional design space in which the five independently functional axes — Parallel Decoding / Unmasking & Remasking / KV Cache / Feature Cache / Step Distillation — combine multiplicatively. Confidence-aware / adaptive methods (Fast-dLLM, APD, SlowFast) that draw out parallelism while avoiding the DLM-specific pitfall of the parallel decoding curse realize 10-30× acceleration training-free; layering dLLM-Cache or Elastic-Cache on top reaches the 30-50× range; and adding Di4C / DLM-One distillation reaches 100-500×-class acceleration.
Commercial-class DLMs such as Mercury and Gemini Diffusion already realize throughput surpassing AR LLMs, and the naive impression that “DLMs are slow” does not apply to the current state of the art. Meanwhile, open problems remain — standardization of evaluation axes, maintaining long-text performance, interference with guidance, the sampler design space, and so on. Keeping the five axes covered in this chapter in mind as “independently combinable tools” makes it easier to quickly locate the positioning of new methods when reading papers.