A Survey on Diffusion Language Models: A Map of Li et al. 2025
This book is structured to read the state of the art in the formulation and implementation of Diffusion Language Models (DLMs) by drilling down vertically into one major reference at a time — MDLM, LLaDA, MaskGIT, Block Diffusion, and so on. In contrast, the survey by Li et al., “A Survey on Diffusion Language Models” (Li et al. 2025), scans the same field horizontally and consolidates in a single article the explosive growth in paper counts, the timeline of leading models, and task-by-task applications. This chapter organizes the survey itself as a single chapter and makes it function as a map of the entire book. Even without reading the survey directly, the chapter is laid out so that you can rapidly grasp (1) which areas are covered, (2) which areas are drilled into in the existing chapters of this book, and (3) which areas are touched on only by the survey.
Basic Information on the Survey
| Item | Content |
|---|---|
| Title | A Survey on Diffusion Language Models |
| Authors | Tianyi Li, Mingda Chen, Bowei Guo, Zhiqiang Shen |
| Publication | arXiv:2508.10875 (August 2025) |
| GitHub | Awesome-DLMs |
The body of the survey is organized into 8 sections: §2 covers the taxonomy, §3 training, §4 inference, §5 multimodal, §6 performance comparisons, §7 applications, and §8 challenges and future directions. The GitHub repository maintains a corresponding paper list, which is also useful for catching up on new papers.
The Scale of the Research Field
What the survey’s introduction emphasizes is the explosive growth of DLM research. If one counts, among papers citing D3PM — the foundational paper on discrete diffusion — those that contain “language” in the title or abstract as “discrete-DLM-related papers,” the number of publications grows exponentially from 2024 into 2025. Continuous-embedding diffusion (continuous DLM) has been studied since early on, but from 2024 onwards, discrete diffusion is overwhelmingly more active.
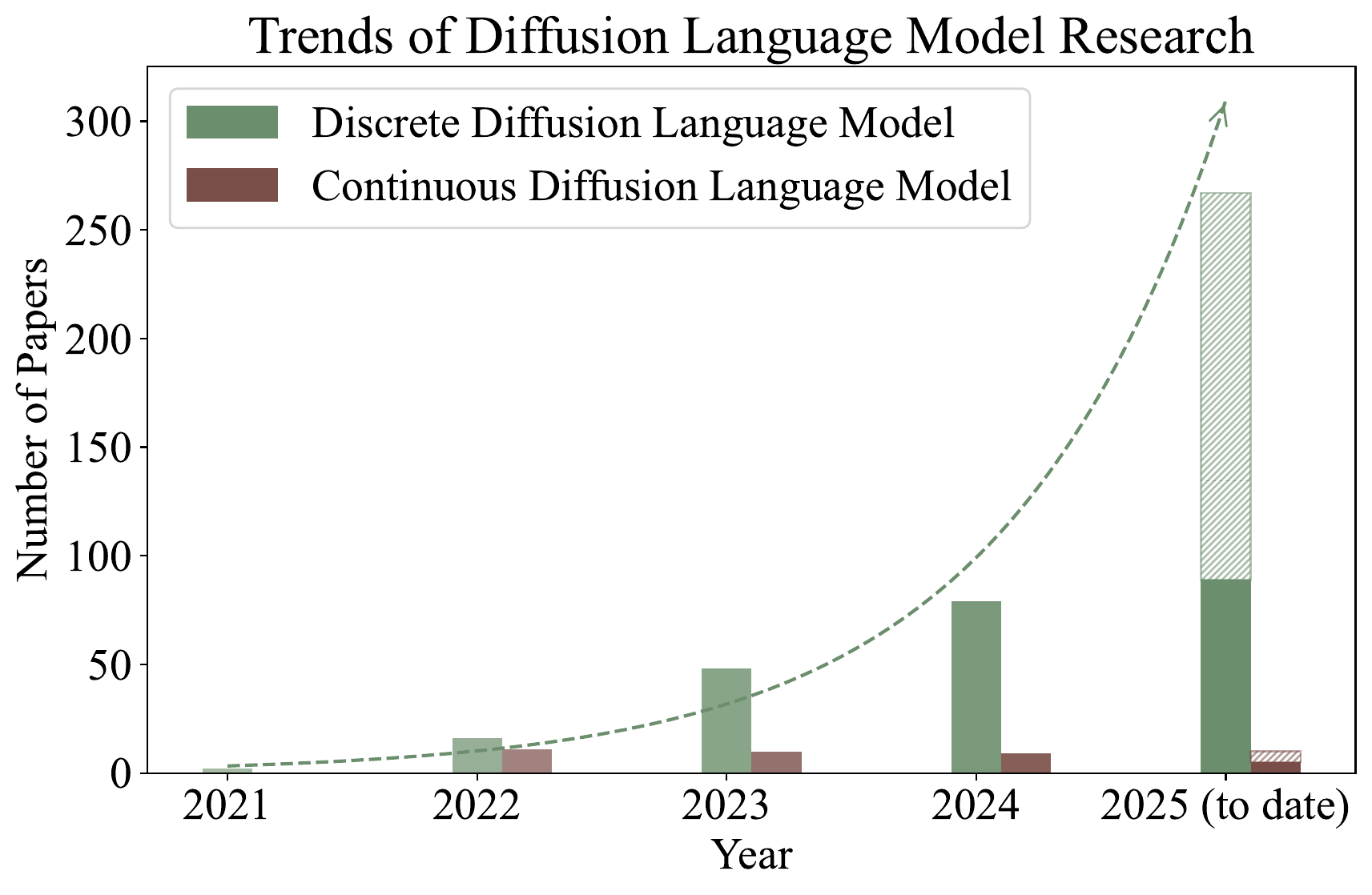
Figure 1 explains why this book devotes more chapters to the discrete-diffusion side, including MDLM and LLaDA. There are several reasons the center of gravity of research shifted to the discrete side. First, MDLM distilled the formulation into the extremely concise objective of a “weighted BERT training.” Second, LLaDA showed at the 8B scale performance on par with AR LLMs of comparable size. Third, commercial-grade systems such as Mercury and Gemini Diffusion appeared, making practical utility visible.
A Timeline Map of the Leading Models
The survey organizes the DLM timeline by color into three lineages: continuous embedding (continuous), discrete, and multimodal.
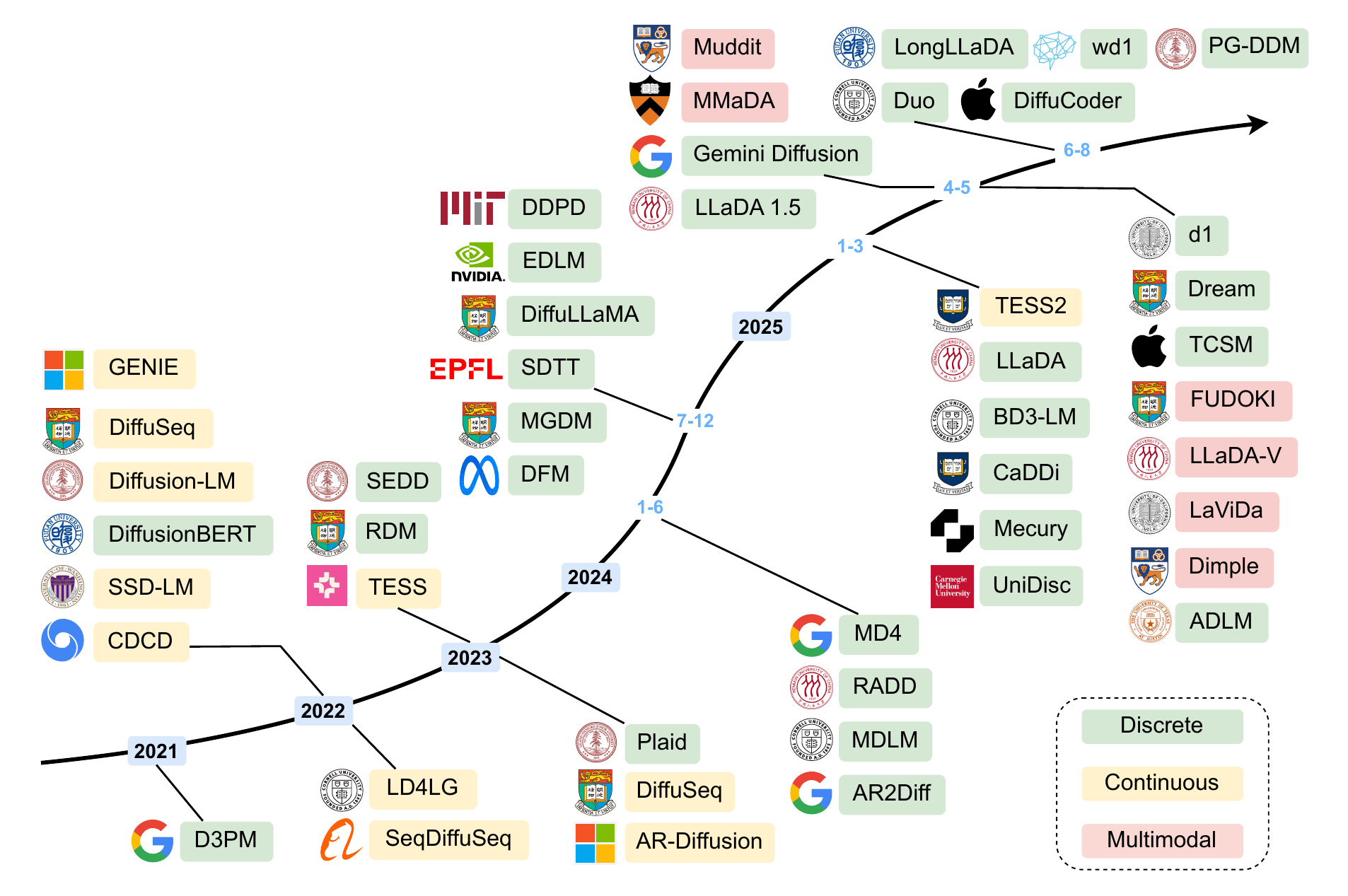
The main currents readable from Figure 2 are as follows.
- Pre-2022: Continuous-embedding diffusion such as Diffusion-LM, SED, and CDCD dominated. An era of trying to import the image-diffusion framework directly into text
- 2023–2024: Starting from D3PM (2021), the formulations of discrete diffusion — SEDD, MDLM, MD4, RADD, etc. — matured rapidly. Absorbing diffusion using the
[MASK]token became the de facto standard - 2025: LLaDA-8B shows AR-equivalent performance from scratch, and Dream-7B obtains competitive results via adaptation from an AR model. Multimodal extensions such as LLaDA-V / MMaDA / Dimple also advance at once
- Commercialization: Mercury (Inception Labs) and Gemini Diffusion (DeepMind) appear with practical speeds (thousands of tokens per second)
→ More: Recent Discrete DLMs
→ More: Multimodal DLM
The Survey’s Taxonomy
At the core of the survey is a four-axis taxonomy.
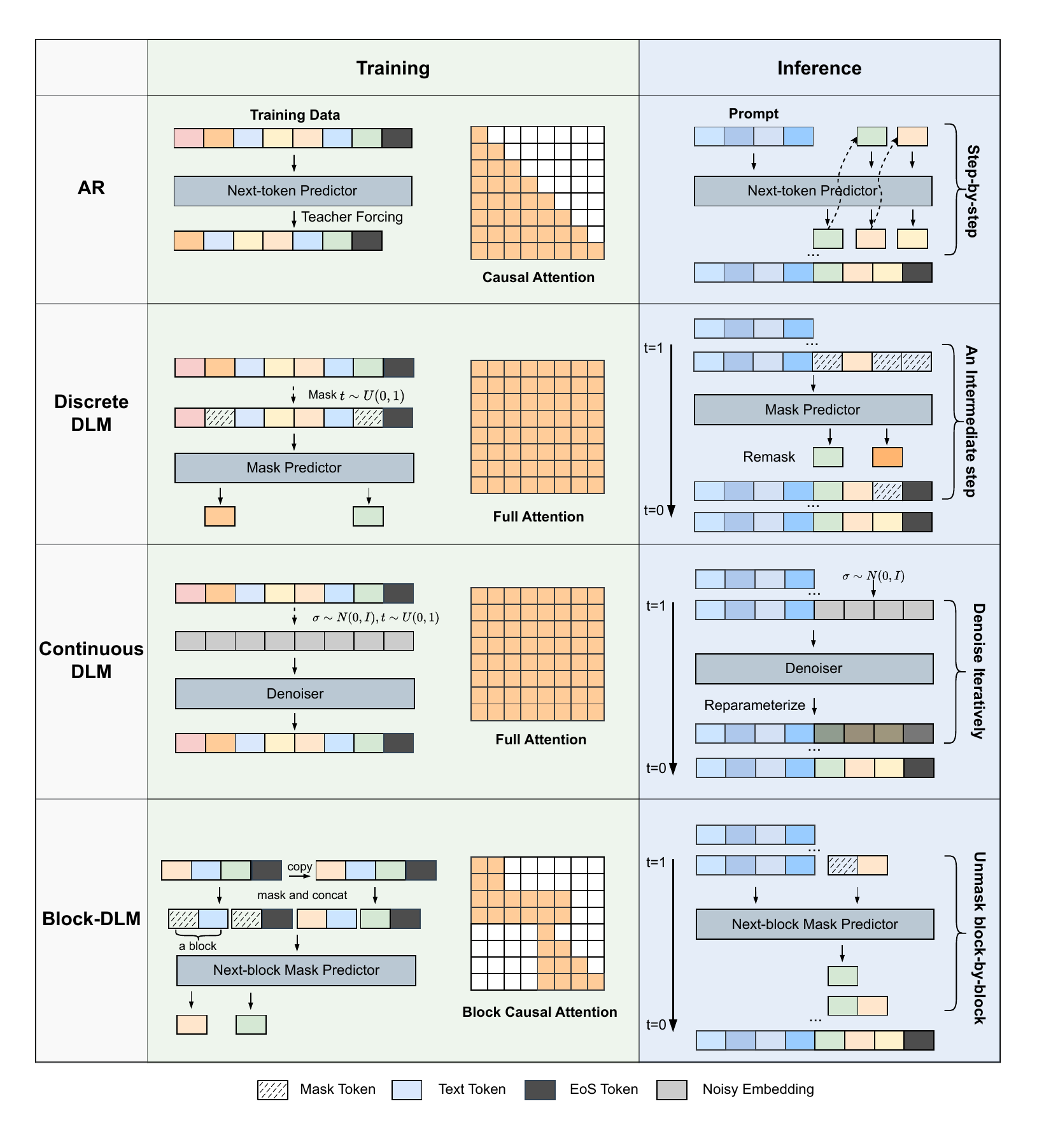
The four axes of Figure 3 are summarized below.
- Paradigms (§2): Where the diffusion takes place. A three-way split into continuous / discrete / hybrid AR-Diffusion
- Training Strategies (§3): Pre-training (from scratch / AR adaptation / image-diffusion adaptation) and post-training (SFT, GRPO-family RL, preference optimization) along two axes
- Inference & Optimization (§4): Parallel decoding, unmasking/remasking, guidance, efficiency (KV cache, feature cache, step distillation)
- Multimodal & Applications (§5, §7): Multimodal DLMs, conventional NLP, code generation, computational biology, robotics
Within this taxonomy, this book drills down vertically into Paradigms and the Pre-training portion of Training (MDLM, LLaDA, etc.), and adds new chapters to complement the rest.
A Correspondence Table Between This Book and the Survey
The subsections of the survey and their corresponding chapters in this book are shown in Table 1. Use it as an entry point when reading this book, and as an index for “jumping from the survey into the deep dives of this book.”
| Survey section | Main topics | Corresponding chapter | Coverage |
|---|---|---|---|
| §2.1 Continuous DLMs | Diffusion-LM, SED, CDCD, Plaid, TESS | Embedding-Space Diffusion | Covered in existing chapter |
| §2.2 Discrete DLMs | D3PM, SEDD, MDLM, LLaDA, Dream, RADD, DFM, GIDD | MDLM / LLaDA / D3PM and SEDD / Recent Discrete DLMs | Existing + new chapters |
| §2.3 Hybrid AR-Diffusion | SSD-LM, AR-Diffusion, BD3-LM, CtrlDiff, SpecDiff, SDAR, TiDAR, SDLM | Block Diffusion / Hybrid AR-Diffusion | Existing + new chapters |
| §3.1 Pre-training | from scratch / AR adaptation / image-diffusion adaptation | LLaDA / AR→DLM Adaptation | Existing + new chapters |
| §3.2 Post-training | DoT, DCoLT, diffu-GRPO, UniGRPO, VRPO family | Post-Training (RL) | New chapter |
| §4 Inference | parallel decoding / KV cache / feature cache / step distillation | Inference Acceleration | New chapter |
| §4.3 Guidance | A-CFG, Freecache, DINGO | Guidance | New chapter |
| §5 Multimodal DLMs | LLaDA-V, MMaDA, Dimple, LaViDa, Fudoki, Muddit | Multimodal DLM | New chapter |
| §6 Performance Study | Cross-benchmark comparisons | — | Refer directly to Figure 6 of the survey |
| §7 Applications | Code, Bio, Robotics, NLP task families | Applications | New chapter |
| §8 Challenges | parallelism trade-off, infrastructure, long-context, scalability | Open Problems | Covered in existing chapter |
All linked targets are chapters that exist in this book. If a region of the survey catches your interest, jumping to the corresponding chapter lets you dig into the details of formulation and implementation.
The Significance of the Three-Paradigm Split
The survey adopts the three-way split — continuous / discrete / hybrid AR-Diffusion — based on the space in which the diffusion takes place. This carries meaning by adding a third axis — hybrid — to the binary “absolutely-quantized discrete diffusion vs. continuous-embedding diffusion” used in this book’s Overview.
In this book’s overview, we emphasized the MDLM-rooted “iterative refinement that fills [MASK]” as the core of modern DLMs and positioned the Diffusion-LM lineage of continuous-embedding diffusion as a separate stream. This is an appropriate introduction for understanding MDLM/LLaDA. However, adding the survey’s three-way split reveals a wider structure.
Concretely, the view emerges that AR and DLMs should be understood as a continuum. Pure AR is the extreme case of “block length 1 and causal,” pure DLM is the opposite extreme of “generating all positions in parallel simultaneously,” and hybrid AR-Diffusion such as Block Diffusion (BD3-LM), SDAR, and TiDAR realizes block-wise semi-autoregression in between. By explicitly drawing this three-way split, the survey naturally positions this book’s Block Diffusion chapter not as a one-off derivative but as a single point inside the AR–DLM continuum.
Once aware of this hybrid axis, one can predict that work combining AR’s advantages with DLM’s advantages — such as SpecDiff (incorporating DLM into speculative decoding) and TiDAR (parallel generation by DLM while outputting AR-style) — will continue to grow. This is why the survey dedicates a section to the related papers.
→ More: Block Diffusion
→ More: Hybrid AR-Diffusion
Key Facts Emphasized in the Survey
The important observations repeatedly highlighted throughout the survey are summarized below. Each is treated in detail in the corresponding chapter of this book, but having them in mind as a survey-level overview sharpens the positioning of individual papers as you read them.
1. Discrete DLMs vastly outnumber continuous DLMs (as of 2025)
Continuous-embedding diffusion was the early mainstream from around 2022 with Diffusion-LM and SED, but it turned out that discrete diffusion using [MASK] is more concise in formulation (MDLM’s weighted BERT loss) and scales more easily (LLaDA-8B), and the center of research shifted to the discrete side. The trend in Figure 1 reflects this.
2. LLaDA-8B was the first to show “AR-equivalent at comparable scale from scratch”
Prior DLMs lagged behind AR on benchmarks, but LLaDA-8B (Nie et al. 2025) reached parity with LLaMA3-8B given equivalent pre-training data. This was a milestone that overturned the then-implicit assumption that “DLMs are essentially weaker than AR.” The survey positions LLaDA as a turning point.
3. Multimodal DLMs are a new frontier
LLaDA-V, MMaDA, Dimple, LaViDa, and others appeared in concentrated fashion in 2025. Unlike AR-family VLMs (LLaVA, etc.), DLMs’ bidirectional context is naturally suited to cross-modal reasoning and to unified “understanding + generation” models. This is why §5 of the survey is treated as a standalone chapter.
4. The arrival of commercial-grade systems (Mercury, Gemini Diffusion)
Inception Labs’ Mercury (Labs et al. 2025) and Google DeepMind’s Gemini Diffusion (Google DeepMind 2024) arrived in 2024–2025, achieving inference speeds of thousands of tokens per second. While academic DLMs remain around the 8B scale, on the commercial side, services running at practical speeds are already in operation — a suggestive contrast.
5. Possibly higher data efficiency than AR
Citing multiple papers, the survey points out a tendency for DLMs to use data more effectively than AR under multi-epoch training. This is related to the effect of the ELBO’s weighting term \(1/t\), which repeatedly exposes the same data at different mask rates. In an era when data is becoming the bottleneck for LLM training, this is a non-negligible advantage.
Regions Mentioned in the Survey but Not Drilled into in This Book
To make this chapter function as a map, we explicitly mark the regions that this book “leaves to the survey.”
Performance Study (§6)
The survey provides figures comparing DLMs and AR side by side on major benchmarks such as GSM8K, HumanEval, and MMLU. This book does not attempt comprehensive benchmark reproduction of this kind (representative numbers are cited in each chapter, but for side-by-side comparison, viewing Figure 6 of the survey directly is faster).
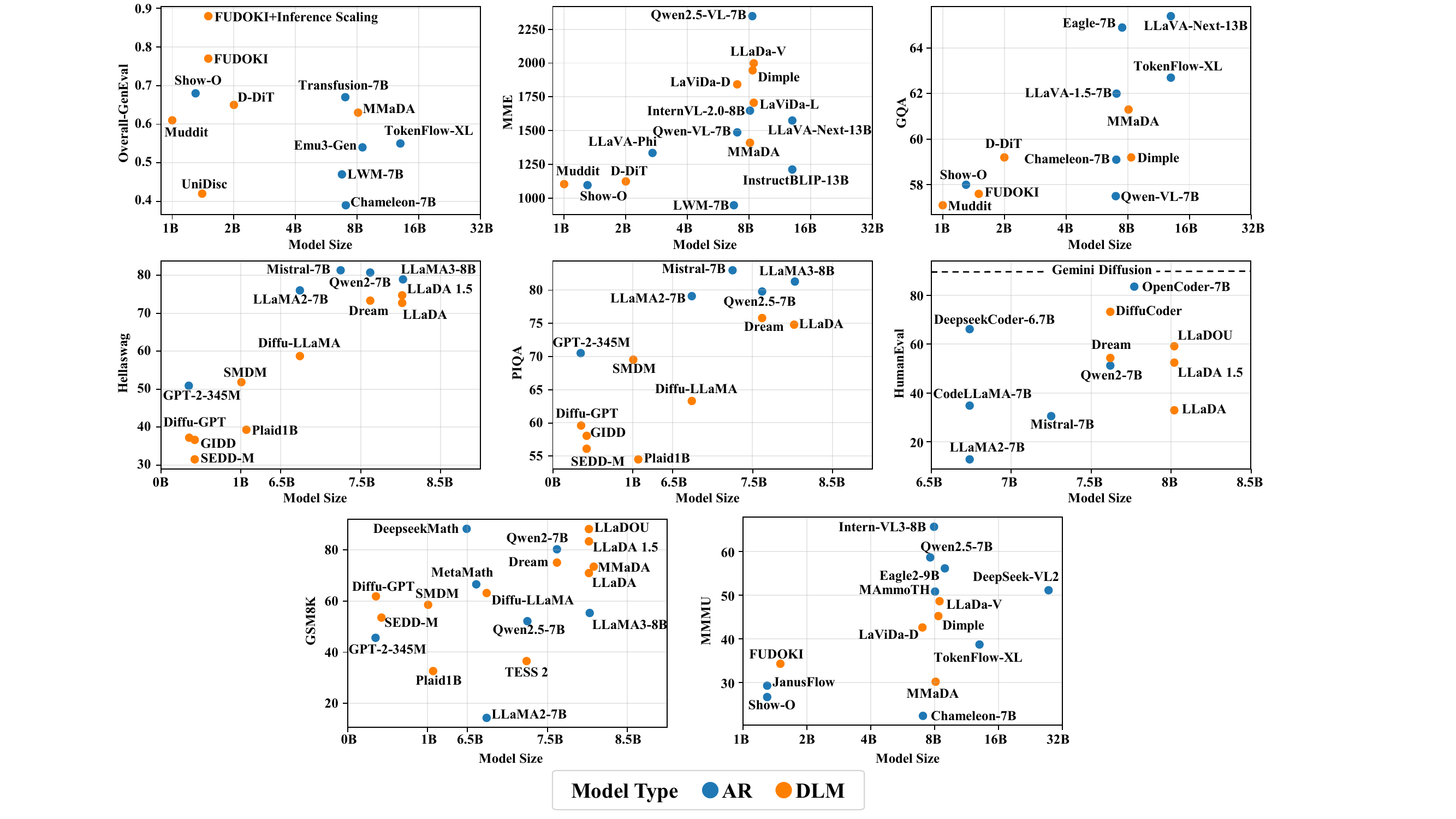
Cross-cutting comparisons like Figure 4 are best consulted directly in Figure 6 of the survey. Each chapter of this book treats the performance of individual models, but the overall side-by-side picture is left to the survey side.
Fine-grained tasks in conventional NLP
§7 of the survey enumerates applications such as DiffusionNER, DiffuSum, EdiText, PoetryDiffusion, and XDLM. The Applications chapter of this book focuses on Code / Biology / Robotics, and only outlines applications to individual conventional-NLP tasks. For exhaustive coverage of task-specific papers, refer to §7 of the survey.
Recommended Reading Order
The recommended order changes depending on whether you read this book or the survey first.
For readers entering from the survey
A pattern of grasping the overall picture from the survey and then drilling into specifics in this book.
- Skim §1 (Intro), §2 (Paradigms), and §8 (Challenges) of the survey
- Check this book’s structure in the overview
- Understand the formulation and current state of discrete diffusion via this book’s MDLM → LLaDA
- Branch out as your interests dictate to Recent Discrete DLMs, Block Diffusion, Hybrid AR-Diffusion, Multimodal DLM, etc.
- Check overall performance in §6 (Performance) of the survey
For readers entering from the existing chapters
A pattern of reading this book’s central references and reinforcing the surroundings via the survey.
- Anchor the core formulation in this book’s MDLM and LLaDA
- Understand the correspondence with continuous diffusion via this book’s Continuous–Discrete Bridge
- Return to this chapter and use Table 1 to find “where in the survey the region you want to read lives”
- Read the sections of the survey you find interesting (§3 Training, §4 Inference, §5 Multimodal, etc.)
- Drill down in the corresponding chapter of this book (Post-Training (RL), Inference Acceleration, Multimodal DLM, etc.)
- Finally, check open problems in Open Problems and §8 of the survey
The survey is breadth-first (wide and shallow), while this book is depth-first (narrow and deep). The survey alone does not get into the meaning of each formulation’s mathematics, and this book alone does not have field-wide paper coverage. Reading both gives a three-dimensional view of the DLM research landscape.
The survey aims at comprehensive coverage as of August 2025, but the DLM field produces new papers on a monthly cadence, so the realistic way to follow the latest preprints is the GitHub repository (Awesome-DLMs). Moreover, the survey weights “what exists” as a listing and gives minimal mathematical explanation of “why it is so.” The ELBO derivation of MDLM and the details of LLaDA’s sampling strategies must be sought in the corresponding chapters of this book or in the original papers.