flowchart TD
A["ARC-AGI-1<br/>(2019)"] --> B["TTT 系 50%台前半"]
A --> C["LLM + program synthesis<br/>40-55%"]
A --> D["HRM / TRM<br/>41-45%"]
A --> E["Frontier LLM + scaffold<br/>85%以上 (saturate)"]
F["ARC-AGI-2<br/>(2025-03)"] --> G["TTT 系 15-24%"]
F --> H["NVARC 24%<br/>(合成データ + small TTT)"]
F --> I["Frontier LLM + heavy CoT<br/>77-85%"]
F --> J["HRM / TRM 5-8%"]
K["ARC-AGI-3<br/>(2026-03)"] --> L["Frontier LLM 全て < 1%"]
K --> M["人間 100%"]
ARC-AGI と小規模モデル
本書が主軸に置く HRM や TRM は、ベンチマークとして ARC-AGI を選んだことが性能ナラティブの大半を支えている。一方で ARC-AGI 自体は 2025 年に第 2 世代、2026 年に第 3 世代が公開されて状況が大きく変わり、Frontier の Large Language Model(LLM)側の追い上げも著しい。本章では HRM/TRM 系の「小規模モデル路線」を競合するアプローチ群と並置し、最新ベンチマークでの相対位置を整理する。

ベンチマーク現状: 1, 2, 3 の三世代
ARC-AGI は 2026 年 5 月時点で 3 つの世代が併存する。
ARC-AGI-1(2019 年公開)は事実上 saturate した。Frontier model と scaffold(test-time augmentation や repeated sampling のような外殻処理)の組み合わせで 85 % 超、Test-Time Training(TTT)系のオープン手法でも 50 % 台前半に達する。
ARC-AGI-2(2025 年 3 月公開)は当初 Frontier LLM を 0–9 % に押し戻したが、2026 年前半までに急速に攻略が進み、5 月時点で GPT-5.5 が 85 %、GPT-5.4 Pro が 83.3 %、Gemini 3.1 Pro が 77.1 % を記録している。いずれも平均的な人間(66 %)を上回り、TTT 系の小規模モデルアプローチは 5–24 % のレンジに留まる。9 ヶ月で 8 % から 85 % へ急上昇したのは、Reinforcement Learning(RL)post-training と莫大な thinking budget を備えた Frontier reasoning LLM の威力を示している。
ARC-AGI-3(2026 年 3 月 25 日公開)は turn-based の対話型タスクで、ルールも目標も明示されない環境を試行錯誤で解読する必要がある。全 Frontier model が 1 % 未満に押し戻されている一方、人間は 100 % を達成しており、新たなギャップが開いた。ARC Prize 2026(賞金総額 200 万ドル超)は ARC-AGI-2 と ARC-AGI-3 の双方が対象である。
ARC-AGI と並走する verifier 装備の constraint reasoning benchmark として、Pencil Puzzle Bench(PPBench)(Waugh 2026年) が 2026 年 3 月に公開された。20 種・300 問のペンシルパズル(Sudoku、Light Up、Nurikabe、Heyawake、Tapa、Shakashaka 等)を step-level verifier 付きで評価するもので、ARC のように「ルール自体を推論する」設定とは対照的に「ルールは既知でその下での探索能力を測る」設定にあたる。本書の PTRM 章はこの PPBench を主実験 benchmark として採用しており、PTRM-best-Q@100 が 91.2 % で Frontier LLM ensemble の 55.1 % を大きく上回るという結果を、ARC-AGI と並ぶ「Frontier LLM が苦手な閉じた reasoning」の実例として読むことができる。
ARC Prize 2024・2025 総括
ARC Prize は毎年 ARC-AGI を巡るオープンコンペティションとして開催され、上位手法は技術レポート (Chollet ほか 2024年, 2026年) と Paper Award で公表される。
2024(ARC-AGI-1 が主戦場) では、ARChitects チーム(Franzen と Disselhoff)が TTT で private set 53.5 % を達成して 1 位、MindsAI が TTT パイオニアとして public eval 55.5 %、Ryan Greenblatt が GPT-4o + program synthesis verifier の組み合わせで 42 % を出した。Paper 賞は Akyürek らの TTT 論文 (Akyürek ほか 2024年) に与えられた。
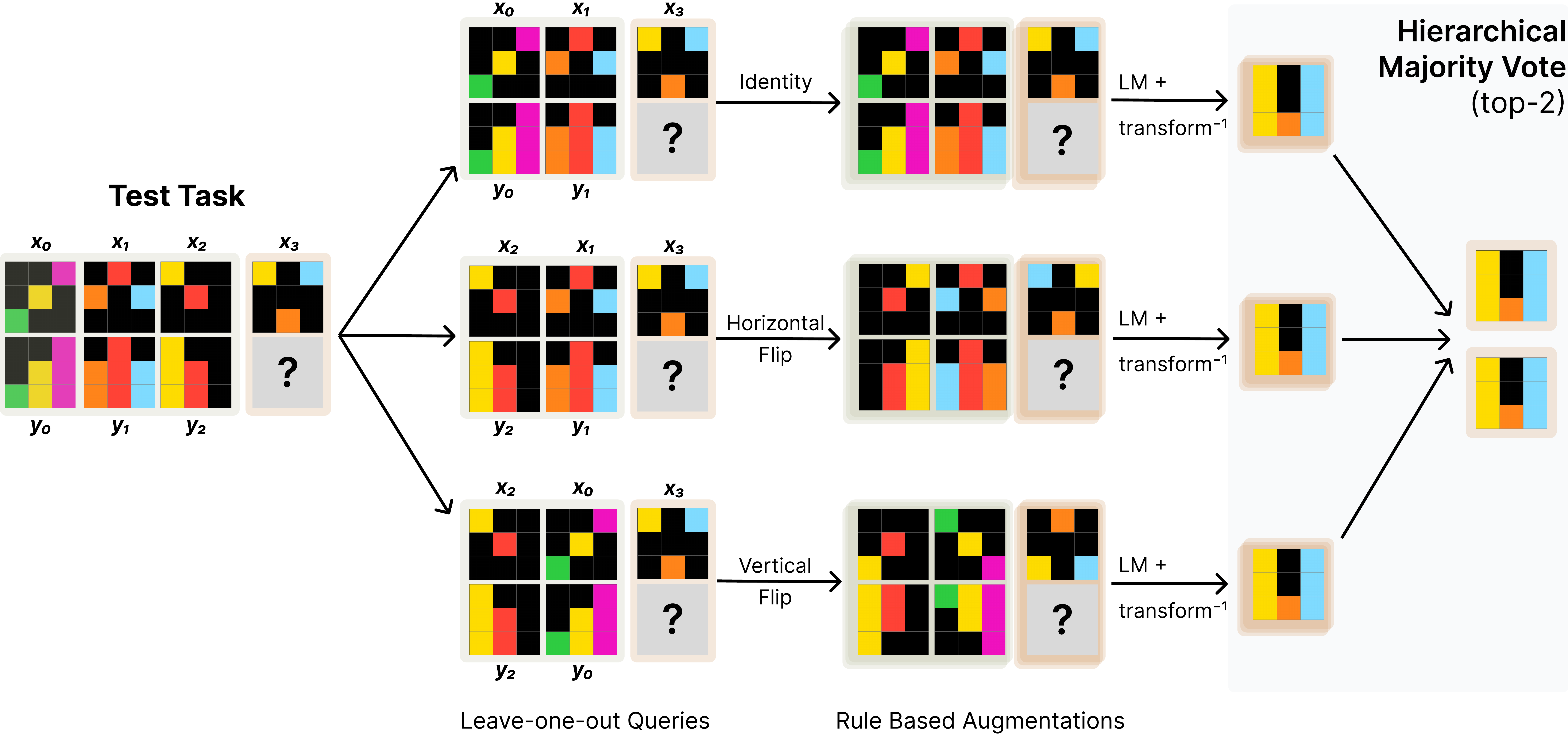
2025(ARC-AGI-2 が主戦場、Grand Prize 未獲得) では構成が大きく入れ替わった。1 位の NVARC(NVIDIA KGMoN, Sorokin と Puget)は ARChitects 系の TTT モデルに TRM ベースの components と 103,000 件の合成パズルを組み合わせ、ARC-AGI-2 で 24 % を達成し、コストは 1 タスクあたり 0.20 ドルに抑えた。2 位の ARChitects は 2D-aware の masked diffusion LLM と recursive self-refinement、3 位の MindsAI は 15.42 %。Paper 賞 1 位は Alexia Jolicoeur-Martineau の TRM 論文 (Jolicoeur-Martineau 2025年) に贈られた。HRM の独立検証 (Ge ほか 2025年) や ARC-AGI-1 における TRM 挙動を精査した後続研究 (Roye-Azar ほか 2026年) も同時期に公開され、small-net 路線の解像度が一段上がった。
NVARC が ensemble の中で TRM components を採用したのに対し、素の TRM だけを ARC Prize 規定下で評価した独立追試 として McGovern の Test-Time Adaptation of Tiny Recursive Models (McGovern 2025年) がある。7M parameters の TRM を public 1,280 タスクで 4×H100・48 時間訓練し、コンペ予算下で 12,500 ステップの test-time fine-tuning を施す構成で、public eval 約 10 %、semi-private 6.67 % を報告した。NVARC の 24 % との差は ensemble・合成データ・TTT 統合の効きの大きさを示しており、「TRM 単体の上限と、それを ensemble に組み込んだときの上限」の比較対照点として読める。
operator 設計の余地を探る方向では、Wang & Reid の Tiny Recursive Reasoning with Mamba-2 Hybrid (Wang と Reid 2026年) が再帰 operator 内の Transformer block を Mamba-2 SSM に置き換え、ARC-AGI-1 の top-1 は同等のまま pass@100 が +4.75 pp 改善することを示した。「TRM = 単に小さな Transformer」という見方が、operator 内部の architectural choice が trajectory 多様性に影響するという機構的観察によって相対化された。
有効アプローチ 5 系統の比較
ARC-AGI を攻略する手法は 2026 年中盤までに 5 つの グループ に整理できる。
| アプローチ | 代表 | ARC-AGI-1 | ARC-AGI-2 | 中核技法 |
|---|---|---|---|---|
| Test-Time Training | ARChitects, MindsAI, Akyürek | 47–55 % | 15–24 % | per-task LoRA fine-tuning |
| LLM + program synthesis | Greenblatt, Ndea (Chollet) | 42–55 % | 中程度 | 大量プログラム生成 + execution check |
| Frontier LLM + heavy CoT | GPT-5.5, Gemini 3.1 Pro | 85 % 超 | 77–85 % | RL post-training + 莫大な thinking budget |
| Inductive-biased small net | HRM, TRM | 41–45 % | 5–8 % | 再帰的 refinement + augmentation |
| 合成データ + small TTT | NVARC(TRM components) | - | 24 %(efficient SOTA) | 合成 puzzle + 4B TTT |
表 1 を一枚で見ると、ARC-AGI-2 における Frontier LLM と small-net 路線の差が一桁台 vs 七・八割という極端な対比になっていると分かる。
HRM / TRM のポジションと構造的制約
表 1 で見るように、本書の主要モデルのうち HRM と TRM は明確に「inductive-biased small net」グループ に属する。
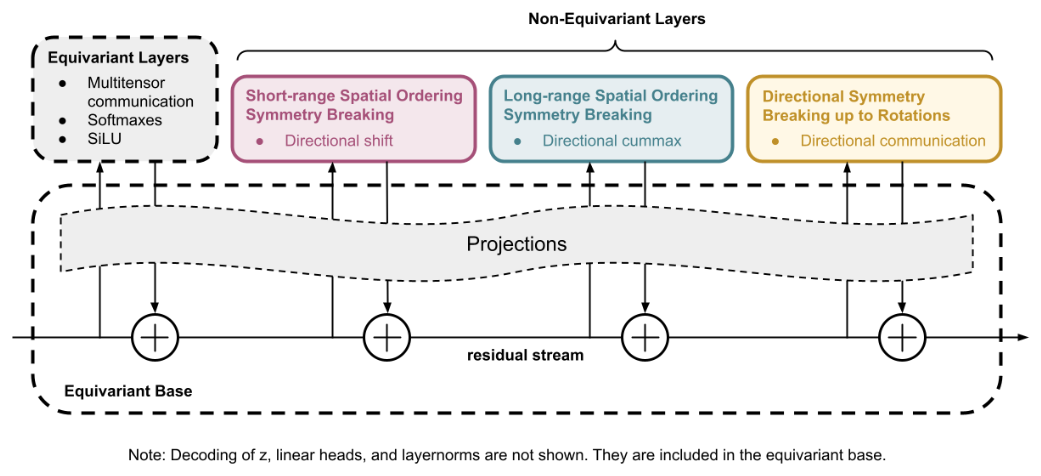
第一に、性能の主因は宣伝された hierarchical planner/worker 構造ではなく、外側の iterative refinement ループとデータ augmentation に集中している。ARC Prize Foundation の HRM 解析 (Ge ほか 2025年) が示すように、hierarchy を取り除いても性能はおよそ 5 pp しか落ちない。
第二に、HRM および TRM は puzzle_id embedding に依存する transductive な設計で、学習時に見た puzzle_id にしか適用できない。新規 task への few-shot 汎化は原理的に難しく、TTT 系全般に共通する問題が HRM/TRM ではさらに顕著に現れる。
第三に、絶対値で見ると TRM の ARC-AGI-1 = 44.6 %、ARC-AGI-2 = 7.8 % は、Frontier LLM の 77 % 超や NVARC の 24 %(efficient SOTA)に大きく劣る。2025 年 12 月の TRM 続編 (Roye-Azar ほか 2026年) は inductive bias、identity conditioning、test-time compute の役割を改めて分析し、ARC-AGI-1 での挙動が augmentation 量と inductive bias の組み合わせに強く依存することを定量化している。
ノートARC-AGI-2 で旧テクニックは通じない
ARC-AGI-2 は adversarial 構成で compositional depth も高い。2024 年に有効だった TTT-only 構成は 24 % あたりで頭打ちになり、HRM/TRM の puzzle_id 依存型は一桁台に留まる。突破に寄与したのは次の 2 つに集約された:
- 合成データで TTT を強化した小規模モデルの ensemble(NVARC のような構成)
- RL post-training と莫大な thinking budget を備えた Frontier reasoning LLM
9 ヶ月で 8 % から 85 % まで詰まったのは、後者の scaffold + thinking compute の効きの大きさを示している。
Chollet と Ndea、そして「ARC ≒ AGI」か
ベンチマーク提唱者 François Chollet は 2025 年 1 月に Mike Knoop と Ndea を共同設立し、ARC-AGI を巡る研究プログラムを企業ベースで再起動した。Ndea の中核思想は 「deep learning-guided program synthesis」、すなわち perception と program 空間の intuition を deep learning(DL)に任せ、reasoning 自体は discrete な program search に委ねるという分担である。Chollet は AGI を「人間のような skill acquisition efficiency」と再定義し、「現在の LLM は memorize と recombine に留まり、program synthesis としての learning が欠落している」と一貫して批判している。
「ベンチマーク高得点 ≒ AGI 達成」と見なすかについて、2026 年中盤のコミュニティ主流見解は No に収束している。論点は次の 4 つに整理できる。
- ARC-AGI-1 の saturate は test-time compute と TTT の勝利であり、本質的な一般化ではない(Chollet 自身が技術レポートで認めている)
- ARC-AGI-2 を 85 % で解く GPT-5.5 でも ARC-AGI-3 では 1 % 未満に落ちる
- HRM 解析が示すように、small-net 路線も「ARC の inductive bias をうまく突くトリック」の側面が強い
- NVARC の「合成データ + 小規模モデル TTT で Frontier LLM のコストを 1/100 程度に抑える」路線は efficient reasoning 研究の有望な方向として広く支持されているが、「AGI へのショートカット」というより「scaling 一辺倒への有意義な反証」として評価されている
系譜の俯瞰
HRM が ARC-AGI-1 に対して打ち出された 2025 年 6 月時点と、ARC-AGI-2 が標準ベンチマークになった 2026 年中盤とでは、議論のフレーム自体が変わっている。本章を補助章として独立させたのは、HRM/TRM/GRAM の絶対値を読むときにベンチマーク世代差を意識しなければ、論文同士の比較がそもそも成立しないからである。
参考文献
Akyürek, Ekin, Mehul Damani, Adam Zweiger, ほか. 2024年. 「The Surprising Effectiveness of Test-Time Training for Few-Shot Learning」. arXiv preprint arXiv:2411.07279. https://arxiv.org/abs/2411.07279.
Chollet, François, Mike Knoop, Gregory Kamradt, と Bryan Landers. 2024年. 「ARC Prize 2024: Technical Report」. arXiv preprint arXiv:2412.04604. https://arxiv.org/abs/2412.04604.
Chollet, François, Mike Knoop, Gregory Kamradt, と Bryan Landers. 2026年. 「ARC Prize 2025: Technical Report」. arXiv preprint arXiv:2601.10904. https://arxiv.org/abs/2601.10904.
Ge, Renee, Qianli Liao, と Tomaso Poggio. 2025年. 「Hierarchical Reasoning Models: Perspectives and Misconceptions」. arXiv preprint arXiv:2510.00355. https://arxiv.org/abs/2510.00355.
Jolicoeur-Martineau, Alexia. 2025年. 「Less is More: Recursive Reasoning with Tiny Networks」. arXiv preprint arXiv:2510.04871. https://arxiv.org/abs/2510.04871.
McGovern, Ronan Killian. 2025年. 「Test-time Adaptation of Tiny Recursive Models」. arXiv preprint arXiv:2511.02886. https://arxiv.org/abs/2511.02886.
Roye-Azar, Antonio, Santiago Vargas-Naranjo, Dhruv Ghai, Nithin Balamurugan, と Rayan Amir. 2026年. 「Tiny Recursive Models on ARC-AGI-1: Inductive Biases, Identity Conditioning, and Test-Time Compute」. arXiv preprint arXiv:2512.11847. https://arxiv.org/abs/2512.11847.
Wang, Wenlong, と Fergal Reid. 2026年. 「Tiny Recursive Reasoning with Mamba-2 Attention Hybrid」. arXiv preprint arXiv:2602.12078. https://arxiv.org/abs/2602.12078.
Waugh, Justin. 2026年. 「Pencil Puzzle Bench: A Benchmark for Multi-Step Verifiable Reasoning」. arXiv preprint arXiv:2603.02119. https://arxiv.org/abs/2603.02119.