flowchart TB
HRM["HRM (27M)<br/>approximate refinement"] --> TRM["TRM (7M)<br/>approximate refinement"]
TRM --> Sotaku["Sotaku (800K)<br/>approximate refinement"]
TRM --> PTRM["PTRM<br/>approximate +<br/>test-time noise"]
TRM --> GRAM["GRAM<br/>approximate +<br/>generative"]
Sotaku --> LDT["<b>LDT (800K)</b><br/><b>sound deduction</b>"]
LDT
Lattice Deduction Transformer(LDT)は、Amherst College の Liam Davis、Axiom の Leopold Haller と Alberto Alfarano、Barnard College / Columbia University の Mark Santolucito による 2026 年 5 月の論文で提案された再帰型 reasoning model である (Davis ほか 2026年)。要点は一行で書ける。再帰型 transformer の latent state を毎 forward pass のあとで abstract interpretation の lattice に投影することで、近似的な精錬ではなく sound な deduction(正解を返すか, さもなくば abstain する挙動)を獲得する。800K parameters の LDT が Sudoku-Extreme と Snowflake Sudoku を 100 % / 100 %、1.8M parameters の variant が Maze-Hard を 99.9 % で解く一方、Claude Opus 4.6、DeepSeek V4-Pro 1.6T、GPT-5.4 という Frontier 大規模言語モデル(Large Language Model, LLM)はいずれも 0 % である。本書が扱う HRM・TRM・PTRM・GRAM の「approximate refinement」系統に対して、LDT は「sound deduction」系統という独立した立ち位置を取る。系譜としては HRM → TRM → Sotaku → LDT という流れの末端に位置し、Sotaku のアーキテクチャを継承したうえで lattice projection を追加することで approximation を sound 化したものとして読める。
系譜: Sotaku を経由した独立進化
LDT の直接の前駆は Cheng Lou が個人で実装した Sotaku(2026, (Lou 2026年))である。Sotaku は 4 層 weight-shared transformer に 2D 回転位置埋め込み(Rotary Position Embedding, RoPE)(Su ほか 2024年) を組み合わせた約 800K parameters のニューラルネット(Neural Network, NN)で、訓練時 16 内部反復・推論時 1024 反復という test-time scaling のもとで Sudoku-Extreme 98.9 %(24728/25000)を達成した。重要な特徴は Sudoku-agnostic である点で、row / col / box の制約埋め込みを使わず純粋に 2D グリッドのみを仮定する。Samsung TinyRecursiveModels の TRM が 7M parameters で 87.4 % という結果と比較すると、1/10 のサイズで 11 ポイント高い精度を独立に達成したことになる。
LDT はこの Sotaku の base architecture(looped transformer + 2D RoPE)をほぼそのまま継承する。継承したうえで abstract interpretation の lattice projection を追加することで、Sotaku の approximation を sound 化した。本書 TRM 章で扱った TRM 系統からの分岐点として読めば、Sotaku が「サイズ削減と単純化の極北」、LDT が「そこに sound 性保証を足した拡張」という位置関係になる。
Abstract interpretation の lattice
Abstract interpretation は Cousot と Cousot が 1977 年に program analysis のために導入した枠組み (Cousot と Cousot 1977年) で、計算が高価な具体ドメイン \(C\) 上の性質を、扱いやすい抽象ドメイン \(A\) 上で sound に over-approximate するための一般理論である。LDT が必要とする最小限の語彙だけを整理する。
二つのドメインは Galois connection \((\alpha, \gamma)\) で結ばれる。\(\alpha : C \to A\) は abstraction(情報の落とし方)、\(\gamma : A \to C\) は concretization(抽象点が表す具体の集合)で、\(S \subseteq \gamma(\alpha(S))\) と \(\alpha(\gamma(a)) \sqsubseteq a\) という二条件を満たす。順序 \(\sqsubseteq\) は precision として読み、\(\top\) は何も分かっていない状態(全候補が生き残っている)、\(\bot\) は矛盾の状態(解なし)に対応する。Deduction は \(\top\) から下降して情報を絞る単調な作業で、\(\bot\) に潰れたら矛盾検出となる。Sound であるとは「抽象上で導出された主張は具体でも真である」ことで、その代償として completeness が落ちる(具体上の真な性質が抽象上では導けないことがある)。
LDT が Sudoku に対して取る具体化は次の通りである。具体ドメインは完全解の集合 \(G = \{1,\dots,9\}^{81}\) の powerset、抽象ドメインは grid powerset lattice
\[ A = (\{1,\dots,9\}^2 \to 2^{\{1,\dots,9\}}) \]
すなわち各セルに「まだ生きている候補集合」を持たせるものである。解は one-hot、\(\alpha\) は集合の bit-level OR、\(\gamma\) は「各セルの候補集合に整合する完全解全体」となる。論文の付録 A が示すように、grid powerset lattice はセル間相関を捨てるので、\(\gamma(\alpha(S))\) は元の \(S\) より広い集合になることが普通である。それでもこの抽象上で deduction(候補の単調な削除)を回すと、必ず sound な情報だけが残る。
最も精密な sound deduction は
\[ \mathrm{ded}_p(a) = \alpha\bigl(\gamma(a) \cap \|p\|\bigr) \]
で、\(\|p\|\) は puzzle \(p\) の解集合である。LDT はこの \(\mathrm{ded}_p\) を transformer で近似する。Naked single や hidden single は弱い手作りの sound abstract deduction の例であり、\(\mathrm{ded}_p\) そのものを学習するのが LDT の目標になる。
flowchart LR
C["<b>具体ドメイン C</b><br/>完全解の集合<br/>powerset of grids"] -- "α (abstraction)" --> A["<b>抽象ドメイン A</b><br/>grid powerset lattice<br/>per-cell 候補集合"]
A -- "γ (concretization)" --> C
A -.-> Top["⊤: 全候補生存"]
A -.-> Bot["⊥: 矛盾"]
ノートProgram analysis から logical deduction への横移動
Abstract interpretation はもともと program analysis(プログラム解析)の理論として開発された枠組みで、program の states に対する monotone な transformer の固定点を抽象上で計算するのが本来の用途である。LDT が示したのは、同じ理論が 論理的 deduction にも自然に当てはまる という観察である。program analysis では least fixed point を取り、LDT では greatest fixed point を取るという慣習の違いはあるが、論文付録 A の終盤で著者らも述べる通り「abstract interpretation は inferential computation 全般の sound approximation の理論であり、program-semantics framing はその一応用にすぎない」。本章で扱う Sudoku は logical deduction、constraint satisfaction、puzzle solving というその別の応用面に当たる。
アーキテクチャ
Lattice encoding
LDT は grid powerset lattice をテンソルとして transformer の入力にエンコードする(論文 Section 4.1)。9×9 Sudoku の場合、\(9 \times 9 \times 9 = 729\) 個のバイナリ sigmoid を持ち、各 sigmoid が「そのセルでその候補がまだ生きている信頼度」を表す。解は one-hot(セルごとに 1 つだけ alive)、\(\alpha\) はセルごとの bit-level OR である。これに加えて、CLS sigmoid を 1 つ「矛盾検出ヘッド」として配置する。閾値 \(\theta_{\mathrm{CLS}}\) を超えた時点で「現在の lattice 状態は具体化不能(\(\bot\))」と判定し、backtracking のトリガーとする。
可変トポロジー問題である Snowflake Sudoku では、\(15 \times 10\) の固定 covering グリッドを用意し、cell ごとに read-only in-puzzle mask channel を追加する。これにより \(n=3\) から \(n=7\) までの異なる hexagonal トポロジー(18 から 90 セル)を、アーキテクチャを変えずに同一モデルで処理できる。
Recurrent transformer(Sotaku 流)
NN 部分は Sotaku をほぼそのまま踏襲する。4 層 attention block を 16 内部反復(internal iteration)にわたって unroll し、各反復の出力を次反復の入力にする。入力 lattice encoding は毎反復 residual として再注入される。位置情報は learned 2D positional embedding を入力に加えるだけで、Maze の \(30 \times 30\) グリッドでは attention 内に 2D RoPE (Su ほか 2024年) を追加する。各反復は candidate logits と CLS logit を独立に出力し、訓練時は 16 反復すべてに loss を当てる(deep supervision)、推論時は最終反復のみを読む。
ノートTRM / HRM / Sotaku との対比
HRM は 4 部品(入力ニューラルネット、低レベル再帰モジュール、高レベル再帰モジュール、出力ヘッド)と二重再帰を持ち、TRM は 2 層単一ニューラルネットを weight-tied に深く展開する。Sotaku は TRM 系統をさらに削って 4 層 weight-shared + 2D RoPE に集約した。LDT はこの Sotaku のアーキテクチャをほぼ完全に継承したうえで、forward pass の 間 に lattice projection を挟むことで sound 化する。すなわち NN の表現力ではなく、NN を出た state を毎回 lattice に写すことが sound 性を担保する。
Solve loop: 訓練と推論を同じ手続きで回す
LDT の中心的設計は Section 4.2 の Solve loop にある。訓練時も推論時も同一の手続きで lattice state を進める。1 つの step は次の擬似コードでまとめられる。
# Algorithm 1: Solve (used for both training and inference)
def solve(x_0, Y): # Y: ground-truth solutions, empty at inference
x = x_0
while True:
x_new, conflict, solved, loss = step(x, Y)
if Y: # training only
optimizer_step(loss)
x = x_new
if conflict or solved:
return x, conflict, solved
# Algorithm 2: step operator
def step(x, Y):
# (i) 4-layer transformer x 16 internal iterations on lattice state x
b, c = transformer_forward(x)
# (ii) eliminate candidates with confidence below theta_elim
x_new = eliminate(x, sigmoid(b) < theta_elim)
conflict = (sigmoid(c) > theta_CLS) or has_empty_cell(x_new)
solved = all_cells_singleton(x_new) and not conflict
if Y:
target = x_new & alpha({y for y in Y if consistent(y, x_new)})
loss = bce_asym(b, target) + lambda_cls * bce(c, conflict) + lambda_ce * ce(b, target)
# (iii) if neither conflict nor solved, randomly pick a multi-candidate cell
# and pin one digit sampled from softmax of its candidate confidences
if not conflict and not solved:
x_new = sample_branch(x_new, tau_decide)
return x_new, conflict, solved, lossstep 操作は (i) 16 内部反復の transformer forward で candidate と CLS logit を出す、(ii) 確信度が \(\theta_{\mathrm{elim}}\) を下回った候補を eliminate する、(iii) どちらの終端でもなければ複数候補の残るセルを 1 つ一様乱択し、softmax から 1 桁を pin する分岐を行う、の 3 段から成る。終端は conflict もしくは solved で、lattice 集合が有限で各 step が必ず候補を減らすため停止性は保証される。
訓練と推論で同じ手続きを使う点が、Solve loop の最大の設計判断である。これは「モデルが訓練時に見る lattice 状態の分布」と「推論時に出会う状態の分布」を一致させるための工夫で、論文中でも「on-policy distillation (Agarwal ほか 2024年) と standard supervised fine-tuning の中間」と位置付けられている。teacher 信号は alpha operator が現在状態 \(x\) と整合する正解集合に当たる形で state-conditional に供給される。HRM / TRM / PTRM / GRAM が latent embedding を segment 間で持ち回すのと対照的に、LDT は lattice 自体が state を運ぶので、step 間で勾配は流さない。Cross-step latent を組み合わせる方向は future work として明記されている。
損失設計
deep supervision の各反復で 3 つの損失を合成する。
\[ \mathcal{L} = \frac{1}{L} \sum_{\ell=1}^{L} \Bigl[ \mathcal{L}_{\mathrm{BCE}}^{(\ell)} + \lambda_{\mathrm{cls}} \mathcal{L}_{\mathrm{CLS}}^{(\ell)} + \lambda_{\mathrm{ce}} \mathcal{L}_{\mathrm{CE}}^{(\ell)} \Bigr] \]
第一項は candidate sigmoid に対する 非対称 Binary Cross Entropy(BCE)で、正クラスの重み \(w^+\) と負クラスの重み \(w^-\) が \(w^+ / w^- = 8\) に設定される。これは「正候補を誤って消す」損失を「偽候補を残す」損失より 8 倍重く罰することを意味し、soundness を completeness より優先する工学判断を直接体現している。論文は Sudoku で \(w^+ / w^- = 8, \lambda_{\mathrm{cls}} = 0.1, \lambda_{\mathrm{ce}} = 0.2, \theta_{\mathrm{elim}} \approx 0.1, \tau_{\mathrm{decide}} = 1.5\) を採用し、他ドメインへも修正なく転用する。第二項は CLS sigmoid と「現状態が \(\bot\) に潰れたか」の指示関数の対称 BCE、第三項は唯一候補となったセルに対する softmax CE で、これは収束の加速のためだけに導入されている。
複数解への対応: alpha operator
Maze のように複数の最短経路が同一 puzzle に許される場合、単一の ground truth を固定すると等価な正解を罰してしまう。LDT は alpha operator を介してこれを自然に扱う。\(K\) 個の有効解を puzzle ごとに事前サンプリングし、現状態 \(x\) と整合する部分集合に \(\alpha\) を当てたものを supervision target にする:
\[ \hat{y} = x \sqcap \alpha\bigl(\{y \in Y \mid y \text{ is consistent with } x\}\bigr) \]
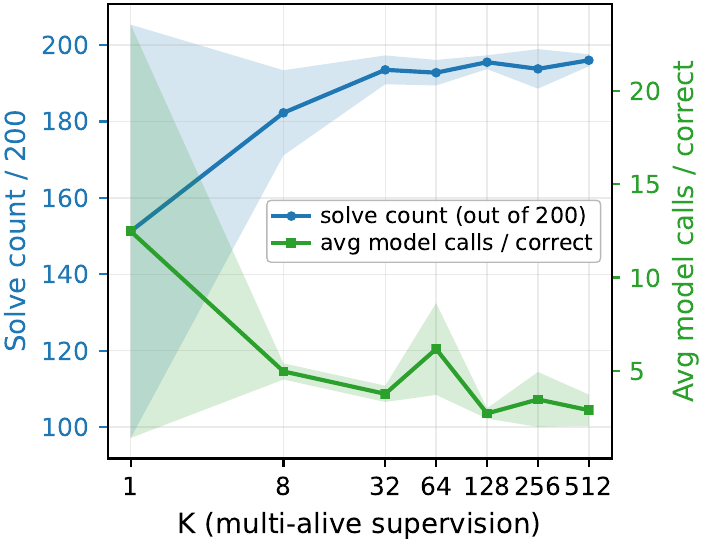
\(K=1\) の場合は通常の単一目標 supervised learning に帰着する。\(K > 1\) で残った正解集合が複数ある間は \(\hat y\) は multi-alive のままで、状態が単一の解のパスにコミットしてからは one-hot に潰れる。これは abstract interpretation 上で考えれば、解集合の “join” を抽象上で取ることに対応する。
主結果
Sudoku-Extreme: 800K で 100 % soundness
論文 Table 1 の Sudoku-Extreme は HRM 論文と同じ benchmark で、平均 22 backtracks 相当の難 puzzle を集めた集合である。LDT 800K parameters を 1K puzzle の train split で 4K steps(B200 GPU 1 枚で 15 分)訓練すると、soundness と accuracy の両方が 100 / 100 に到達する。比較対象は次の通りである。
| 手法 | パラメータ | Train | Soundness / Accuracy (%) | Train cost |
|---|---|---|---|---|
| Claude Opus 4.6 | ? | - | 0.0 / 0.0 | - |
| DeepSeek V4-Pro | 1.6T | - | 0.0 / 0.0 | - |
| GPT-5.4 | ? | - | 0.0 / 0.0 | - |
| HRM | 27M | 1K | 55.0 / 55.0 | - |
| TRM | 5M | 1K | 87.4 / 87.4 | 36h (4x L40S) |
| Sotaku | 800K | 2.7M | 98.9 / 98.9 | 2h40m (1x H100) |
| LDT, 4K steps | 800K | 1K | 100 / 100 | 15min (1x B200) |
| LDT, 4K steps (no-aug) | 800K | 1K (no-aug) | 100 / 99.7 | 13min (1x B200) |
注目すべき点が 4 つある。第一に、3 つの Frontier LLM がすべて 0 / 0 である事実は、これらの benchmark が「scale で解ける問題」と「small recurrent reasoner で解ける問題」が重ならないことを再確認させる(HRM / TRM 章と同じ観察)。第二に、LDT は TRM / HRM のパラメータ数を桁レベルで下回る。第三に、Sotaku が 2.7M puzzle の訓練を必要としたのに対し、LDT は同じ 800K のサイズで 1K puzzle しか使わない。第四に、puzzle augmentation を完全に外しても accuracy は 99.7 % に保たれ、soundness は 100 % を維持する。TRM は augmentation を 1000 通り適用しなければ Sudoku で発散したが、LDT は abstract interpretation の sound 性が augmentation の役割を肩代わりしている。
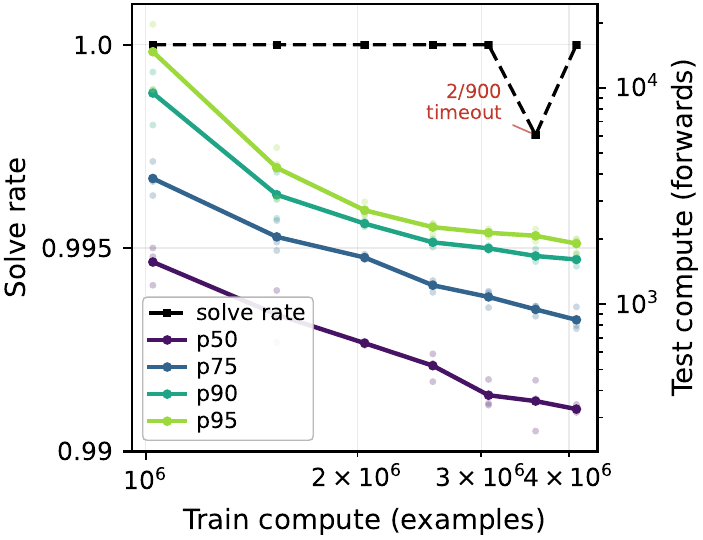
Snowflake Sudoku: 可変トポロジーへの汎化
論文 Section 5.2 は六角形 Sudoku 変種 Snowflake Sudoku への汎化を検証する。\(n=3\) から \(n=7\)(18 から 90 セル)まで異なるトポロジーを持つ puzzle 群を、SMT solver の cvc5 (Barbosa ほか 2022年) で 30,000 個合成し、500 を train、1000 を test に使う(LLM は計算コストの都合で 200 puzzle のみ評価)。LDT 800K は 500 puzzle 学習で 100 / 100 を達成し、Claude Opus 4.6 / DeepSeek V4-Pro / GPT-5.4 はやはり全滅する。単一モデルが \(15 \times 10\) covering グリッドと per-cell mask channel だけで \(n=4 \dots 7\) の全サイズを処理する点が、可変トポロジーへの sound deduction の汎化として注目に値する。
Maze-Hard: 複数解への適用
論文 Section 5.3 は \(30 \times 30\) の Maze-Hard(最短経路長 \(\geq 110\))で、多解 supervision を検証する。LDT 1.8M(埋め込み次元 \(d = 192\))が \(K=1\) で 99.3 / 99.3、\(K=512\) で 99.9 / 99.9 を達成する一方、HRM は 74.5、TRM は 85.3 にとどまる。注意点として、Maze では LDT も完全な sound ではない。失敗 1 / 1000 では abstain せず「正しいが最短ではない経路」を返してしまう。これは valid path を出している意味では誤りではないが、benchmark の「最短経路」基準では誤りで、論文も率直にそれを限界として記述している。

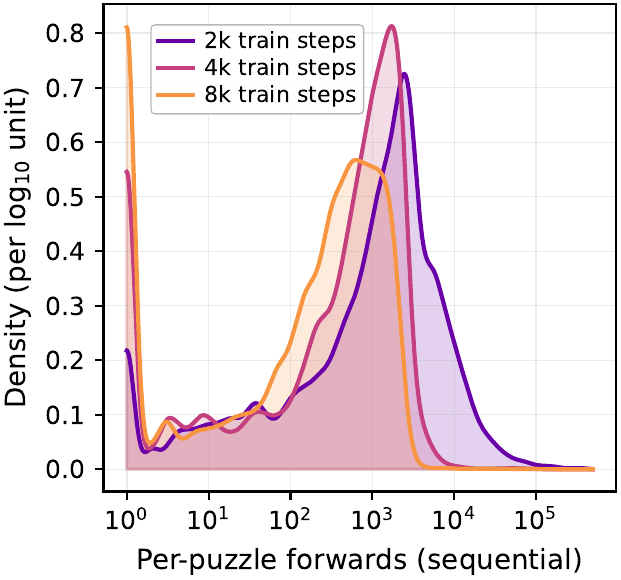
Train / test compute トレードオフの意味
図 3 は本書全体の文脈で再評価すべき結果を含んでいる。「訓練 compute を増やすほど、推論時の forward 数の中央値・上位 percentile がともに桁単位で減少する」というのは、CoT による sequential token scaling や、HRM / TRM / GRAM が示した recurrent depth scaling とは方向が逆の主張である。Frontier LLM の OpenAI o1 / DeepSeek-R1 (DeepSeek-AI ほか 2025年) は「より長く考える(=より多くの token を生成する)」ことで難問を解こうとし、HRM / TRM はテスト時の再帰深さを増やすことで効果的深さを得ようとする。LDT が示すのは、sound deduction を学習できれば、追加の学習が推論時 search を肩代わりして消す方向に働く という新しい trade-off である。
なぜそれが可能か。lattice projection は sound 性を保証するので、モデルが「正確な deduction を学ぶ」ことに集中できる。逆に approximate refinement 系では、学習がうまく進んでも解が正しい保証はなく、その分を test-time search や denoising step 数で補う必要がある。図 4 の bimodal な分布が示す通り、訓練を進めると質量は「lattice projection だけで解ける deduction mode」に移り、「branching を要する search mode」のピーク自体も短い forward 数の方向にシフトする。これは Depth vs Token Scaling で扱う test-time compute 配分論に、「sound deduction なら学習で search を内在化できる」という新しい軸を加える観察として整理できる。
関連研究
Haller の前作: 著者連続性
LDT の共著者 Leopold Haller は、D’Silva・Haller・Kroening が 2013 年に POPL で発表した Abstract Conflict Driven Learning(ACDL)(D’Silva ほか 2013年) の共著者そのものである。ACDL は modern SAT solver の標準技法である Conflict-Driven Clause Learning(CDCL)(Marques-Silva ほか 2009年) を、Boolean lattice 上の distributive transformer 判定問題として lattice-theoretic に持ち上げた研究で、conflict が起きるたびに「失敗を排除する learned clause」を生成する CDCL の動作原理を abstract interpretation の語彙で再構成したものである。
ここから見ると、LDT の CLS conflict head は事実上 ACDL の learned 版 として読める。Boolean Satisfiability(SAT)solver が矛盾を検出して branch を切り戻す機構を、neural network に学習させて等価な役割を持たせる試みである。論文の中では明示的に「LDT は ACDL の neural 化である」とは書かれていないが、共著者連続性とアーキテクチャ上の対応の両方から、これは中長期的な lineage として読むのが自然である。
Neuro-symbolic logical reasoning
LDT に近い研究系統は 2 つある。第一に、厳密 solver を network 層として組み込む流れである。SATNet (P.-W. Wang ほか 2019年) は MAX-SAT solver の differentiable 緩和を、Learning Modulo Theories (Fredrikson ほか 2023年) は Satisfiability Modulo Theories(SMT)solver を、それぞれ NN の layer として埋め込む。LDT との違いは、SATNet / LMT が 可微分 solver を NN の中に置く のに対し、LDT は lattice projection という非可微分な構造的制約だけで sound 性を保証 し、NN は自由に学習させる点にある。設計思想として対照的である。
第二に、Singh ラボを中心とする「abstract interpretation × ML」の系統がある。Neural Abstract Interpretation(NAI)(Gomber と Singh 2025年) が思想的に最も近い直前研究で、neural net を abstract transformer として学習する frame を提案する。違いは、NAI が program analysis 向けに transformer 単体を訓練する のに対し、LDT は iterative deduction 全体を looped transformer + lattice projection で統合する 統合度にある。LAIT (He ほか 2020年) や SAIL (Gu ほか 2026年) も同系統で、SAIL は LLM を abstract interpreter 学習に使う方向で動いている。
Diffusion との類縁
論文 Section 1 と 2 は、lattice projection と discrete diffusion の構造的類縁を強調する。D3PM (Austin ほか 2021年) は absorbing 状態への transition matrix を持つ forward process を学習し、逆 process で partial information を iterative にコミットしていく。LDT の lattice projection は「現在の候補集合を縮める」操作で、transition matrix を lattice-respecting なものに制限した D3PM として読める。ReMDM (G. Wang ほか 2025年) は generated token を inference time に re-mask できるようにする discrete diffusion で、LDT における branching と backtracking に対応する。論文は LDT を diffusion の方法論として展開してはいないが、「lattice projection は denoising と同型」という観察を future work の足がかりとして残している。
同時期の研究としては、Constraints-Guided Diffusion Reasoner(CGDR)(Zhang ほか 2025年) が同じ Sudoku / Maze で discrete diffusion + 強化学習の proximal policy optimization(PPO)による neuro-symbolic 学習を実現している。LDT が abstract interpretation で sound 性を保証するのに対し、CGDR は diffusion + PPO で制約遵守を獲得するという、同じ目標へのアプローチの違いとして対比できる。
HRM / TRM / PTRM / GRAM 系統との独立性
本書のこれまでの 4 章と LDT の根本的相違は、latent state の解釈と保証にある。HRM / TRM / PTRM / GRAM は latent state を不透明な hidden state として扱い、その上で approximate refinement を実行する。解は出るが、その解が正しい保証はない。一方 LDT は latent state を lattice の元として解釈可能に扱い、sound deduction を実行する。解は出るか abstain するかのいずれかで、誤った解は出さない(経験的に)。
両者は同じ「small recurrent transformer」というアーキテクチャ族に属するが、設計思想が根本的に違う。PTRM のように TRM に test-time noise を加えて bad basin から escape させる方向と、LDT のように latent を lattice に投影して sound 化する方向は、直交する 2 つの「TRM 系統の限界突破戦略」 として並読すべきである。前者は approximate refinement の枠内で test-time exploration を強化し、後者はそもそも approximate 性を sound 性に置き換える。
限界
論文 Section 6 は限界を 3 つ明示する。
明確な logical structure を持つタスクに限定される。 Abstraction and Reasoning Corpus(ARC)-AGI のように「task ごとに rule を少数の demonstration から推論する」設定では、LDT を naive port すると約 36 % の pass rate で plateau し、test-time search の gain も消える。conflict head が信頼できなくなり、branching が「良い枝」と「悪い枝」を区別できなくなるためで、論文は ARC-AGI を「LDT が直接適用できない代表的設定」と述べる。
lattice 設計が task-dependent である。 Sudoku の grid powerset lattice は人手で設計されており、Snowflake への拡張も手作業で行われた。任意タスクへの汎化のためには、domain-specific な abstract domain 設計が要請される。これは abstract interpretation 一般の課題でもある。
cross-step gradient が流れない。 Solve loop の step 間で勾配は流れず、lattice 自体が state を運ぶ。TRM-style の deep supervision を step 間にも入れる組み合わせは未試行で、将来方向として残されている。
ARC のように demonstration から rule を推論する設定では、「解の集合」ではなく「解を生成する program の集合」の上に abstract domain を構築する必要があるかもしれない、と論文は最後に示唆する。本書の文脈で位置付けるなら、LDT は HRM / TRM 系統が暗黙に避けてきた「どんな答えを返したのか保証できるか」という工学的問いに正面から答えた最初の論文として読める。性能の絶対値(Sudoku-Extreme 100 %)よりも、soundness 保証という新しい評価軸を recursive reasoning model の議論に持ち込んだ点が、中長期的には本論文の最も重要な貢献だと考えられる。
参考文献
Agarwal, Rishabh, Nino Vieillard, Yongchao Zhou, ほか. 2024年. 「On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes」. International Conference on Learning Representations (ICLR). https://arxiv.org/abs/2306.13649.
Austin, Jacob, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, と Rianne van den Berg. 2021年. 「Structured Denoising Diffusion Models in Discrete State-Spaces」. Advances in Neural Information Processing Systems (NeurIPS). https://arxiv.org/abs/2107.03006.
Barbosa, Haniel, Clark W. Barrett, Martin Brain, ほか. 2022年. 「cvc5: A Versatile and Industrial-Strength SMT Solver」. Tools and Algorithms for the Construction and Analysis of Systems (TACAS), Lecture Notes in Computer Science, vol. 13243: 415–42. https://doi.org/10.1007/978-3-030-99524-9_24.
Cousot, Patrick, と Radhia Cousot. 1977年. 「Abstract Interpretation: A Unified Lattice Model for Static Analysis of Programs by Construction or Approximation of Fixpoints」. Conference Record of the Fourth Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages (POPL) (Los Angeles, California), 238–52. https://doi.org/10.1145/512950.512973.
D’Silva, Vijay, Leopold Haller, と Daniel Kroening. 2013年. 「Abstract Conflict Driven Learning」. Proceedings of the 40th Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages (POPL), 143–54. https://doi.org/10.1145/2429069.2429087.
Davis, Liam, Leopold Haller, Alberto Alfarano, と Mark Santolucito. 2026年. 「Lattice Deduction Transformers」. arXiv preprint arXiv:2605.08605. https://arxiv.org/abs/2605.08605.
DeepSeek-AI, Daya Guo, Dejian Yang, ほか. 2025年. 「DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning」. Nature 645: 633–38. https://arxiv.org/abs/2501.12948.
Fredrikson, Matt, Kaiji Lu, Saranya Vijayakumar, Somesh Jha, Vijay Ganesh, と Zifan Wang. 2023年. 「Learning Modulo Theories」. arXiv preprint arXiv:2301.11435. https://arxiv.org/abs/2301.11435.
Gomber, Shaurya, と Gagandeep Singh. 2025年. 「Neural Abstract Interpretation」. ICLR 2025 Workshop: VerifAI: AI Verification in the Wild. https://openreview.net/forum?id=WTyyhWhp4m.
Gu, Qiuhan, Avaljot Singh, と Gagandeep Singh. 2026年. 「SAIL: Sound Abstract Interpreters with LLMs」. Proceedings of the ACM on Programming Languages 10 (PLDI).
He, Jingxuan, Gagandeep Singh, Markus Püschel, と Martin Vechev. 2020年. 「Learning Fast and Precise Numerical Analysis」. Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 1112–27. https://doi.org/10.1145/3385412.3386016.
Lou, Cheng. 2026年. Sotaku: From-scratch Experiments on Iterative Neural Sudoku Solvers. Software, GitHub repository, commit 9e13341. https://github.com/chenglou/sotaku.
Marques-Silva, João P., Inês Lynce, と Sharad Malik. 2009年. 「Conflict-Driven Clause Learning SAT Solvers」. Handbook of Satisfiability, 編集者: Armin Biere, Marijn Heule, Hans van Maaren, と Toby Walsh, vol. 185. Frontiers in Artificial Intelligence and Applications. IOS Press. https://doi.org/10.3233/978-1-58603-929-5-131.
Su, Jianlin, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, と Yunfeng Liu. 2024年. 「RoFormer: Enhanced Transformer with Rotary Position Embedding」. Neurocomputing 568: 127063. https://arxiv.org/abs/2104.09864.
Wang, Guanghan, Yair Schiff, Subham Sekhar Sahoo, と Volodymyr Kuleshov. 2025年. 「Remasking Discrete Diffusion Models with Inference-Time Scaling」. Advances in Neural Information Processing Systems (NeurIPS). https://arxiv.org/abs/2503.00307.
Wang, Po-Wei, Priya L. Donti, Bryan Wilder, と J. Zico Kolter. 2019年. 「SATNet: Bridging Deep Learning and Logical Reasoning Using a Differentiable Satisfiability Solver」. Proceedings of the 36th International Conference on Machine Learning (ICML), Proceedings of Machine Learning Research, vol. 97: 6545–54. https://arxiv.org/abs/1905.12149.
Zhang, Xuan, Zhijian Zhou, Weidi Xu, Yanting Miao, Chao Qu, と Yuan Qi. 2025年. 「Constraints-Guided Diffusion Reasoner for Neuro-Symbolic Learning」. arXiv preprint arXiv:2508.16524. https://arxiv.org/abs/2508.16524.