Latent reasoning の分類
Hierarchical Reasoning Model(HRM)、Tiny Recursive Model(TRM)、Generative Recursive reAsoning Models(GRAM)は、いずれも自然言語 trace を生成せず、latent state 上の反復計算で reasoning を進める。だが「latent reasoning」と呼ばれる研究領域はこの三世代に閉じない。Pause Tokens (Goyal ほか 2024年)、Coconut (Hao ほか 2025年)、Quiet-STaR (Zelikman ほか 2024年)、Diffusion-of-Thoughts(DoT)(Ye ほか 2024年)、Large Concept Model(LCM)(LCM team ほか 2024年) など、出発点も動機も異なる手法群が並走している。本章は 代表手法を 7 つのグループ に分け、HRM/TRM/GRAM が位置する グループ E(recurrent depth)が他のどの グループ とも決定的に異なる 4 つの性質を持つ ことを論じる。
7 つのグループ: 代表手法と test-time scaling の方法
表 1 は本章で用いる分類である。LRS (Zhu ほか 2025年) が用いる活性化ベース/隠れ状態ベースの 2 区分に、placeholder と distillation、diffusion、concept を加えた拡張版と捉えてよい。
| グループ | 代表手法 | 特徴 | test-time scaling |
|---|---|---|---|
| A. Placeholder tokens | Pause (Goyal ほか 2024年), Filler “dot by dot” (Pfau ほか 2024年) | 無意味トークンで処理段数を稼ぐ | 挿入する placeholder の本数(横幅) |
| B. Continuous CoT (horizontal) | Coconut (Hao ほか 2025年), Compressed CoT (CCoT) (Cheng と Durme 2024年), Soft Thinking (Zhang ほか 2025年) | last hidden state を次入力に直接 feed | 連続 thought の本数(横幅) |
| C. Implicit CoT distillation | Deng et al. (Deng ほか 2023年, 2024年) | 教師の CoT を生徒の hidden 層に蒸留・内在化 | 原則固定(生徒は通常 forward) |
| D. Self-generated rationale | Quiet-STaR (Zelikman ほか 2024年) | 各 token 位置で内部 rationale を生成 | rationale 本数の sampling 平均 |
| E. Recurrent depth (vertical) | HRM (Wang ほか 2025年), TRM (Jolicoeur-Martineau 2025年), PTRM (Sghaier ほか 2026年), GRAM (Baek ほか 2026年), LDT (Davis ほか 2026年), Geiping et al. (Geiping ほか 2025年) | 同じ層を深さ方向に再帰展開 | 再帰回数(深さ)、PTRM/GRAM では並列軌道(横幅)も |
| F. Diffusion-based | Diffusion-of-Thoughts (Ye ほか 2024年), LaDiR (Kang ほか 2025年) | denoising step に reasoning を相乗り | 拡散 step 数(無限深度近似) |
| G. Concept-level | LCM (LCM team ほか 2024年) | sentence embedding 単位の autoregressive | 生成する concept 数 |
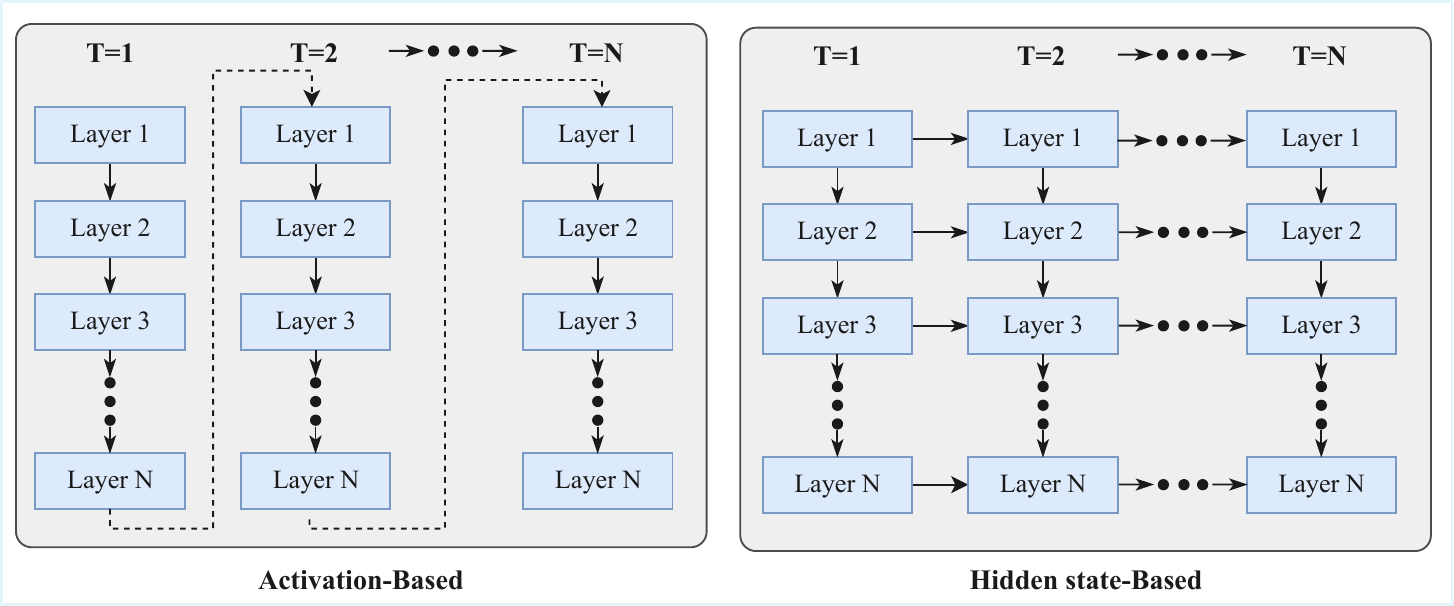
LLM 依存度で見ると、グループ A・B・C・D・G は LLM の上に被せる継承形、グループ F は LLM 部分依存、グループ E のみが LLM 不要の self-contained 系統である。HRM/TRM/GRAM が位置する グループ E は、natural language を一切経由せず LLM にも依存しない極北に立っている。LRS (Zhu ほか 2025年) の語彙では グループ B は horizontal recurrence(hidden state を時系列方向に注入)、グループ E は vertical recurrence(同じ層を深さ方向に再帰)と呼ばれる。グループ F の diffusion はこの両軸に乗らず、無限深度の連続時間極限として別系統に置かれる。図 1 は LRS による分類図で、本章の グループ B が「Hidden state-Based(右側)」、グループ E が「Activation-Based(左側)」に概ね対応する。
グループ A: Placeholder tokens で深さを稼ぐ
最も素朴な「latent reasoning」は、入力に無意味なトークンを挟むことで forward の処理段数を増やす手法である。
Pause Tokens (Goyal ほか 2024年) は ICLR 2024 で発表された。<pause> という学習可能な特殊トークンを prefix と出力の間に挿入し、最後の pause が attention に取り込まれるまで出力を捨てる。Pause を pre-train と fine-tune の両方で導入した 1B parameters モデルは、SQuAD で正解率 +18 %、CommonsenseQA で +8 %、GSM8k で +1 % を達成した。トークン自体は意味を持たず、増えるのは attention にかけられる位置の数だけである。
Filler Tokens / “Let’s Think Dot by Dot” (Pfau ほか 2024年) はさらに踏み込み、Pause を ... のような完全に無意味な文字に置き換えても 3SUM のような帰納的タスクで精度が 66 % から 100 % まで伸びることを示した。「CoT の中身は無意味でよく、必要なのは追加の計算段数だけ」という挑発的な主張である。この結果は CoT の解釈性に冷水を浴びせ、後の グループ B–E の動機を強化した。
Placeholder は深さを稼ぐが、その深さで何を計算するかは構造的に決まらない。Filler が解けるのは事前学習で「答えに至る計算」が暗黙に獲得されているタスクに限られ、未知の問題で追加 token が役立つ保証はない。グループ B 以降はこの「何を計算するか」を hidden state 設計で明示する方向に進む。
グループ B: Continuous CoT で言語層をバイパス
グループ B は LLM の last hidden state を softmax を経由せずに次ステップの input embedding に直接戻す 系統である。LLM の上に被せる formulation という点では グループ A の延長線にあるが、各ステップで運ぶ情報量が「離散 token 1 つ」ではなく「実数ベクトル 1 つ」となる点が決定的に異なる。
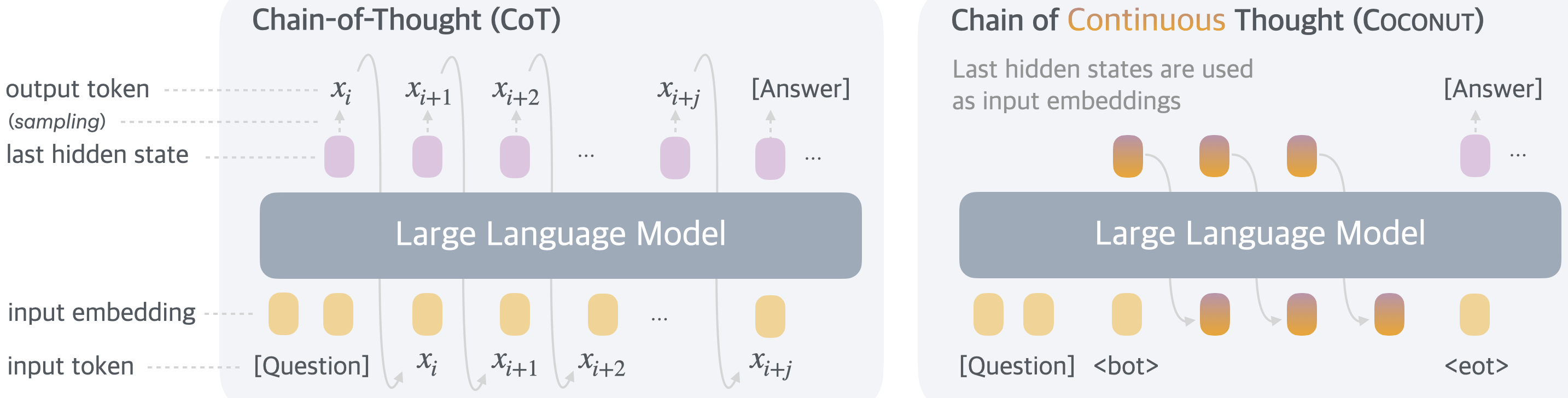
Coconut(Chain of Continuous Thought)(Hao ほか 2025年) が代表である。図 図 2 のとおり、通常の CoT が各ステップで hidden → softmax → token → embedding を経由するのに対し、Coconut は hidden → embedding を直接つなぐ。著者らは、この continuous thought が複数の reasoning path を 重ね合わせ として保持し、暗黙の BFS を実行していると主張する。実装上は <bot> <eot> という特殊トークンで latent モードへの切り替えを示し、ProsQA や GSM8k の small subset で標準 CoT を上回る精度を達成した。
Compressed Chain of Thought(CCoT) (Cheng と Durme 2024年) は explicit reasoning chain を可変長の contemplation token に蒸留圧縮する方向で同じ動機を追う。CoT を冗長と捉え、短い連続ベクトル列で同等の情報を運ばせる。Soft Thinking (Zhang ほか 2025年) は training-free に近い形で、出力分布を embedding 行列に掛けて得られる “concept token” を次入力にする。temperature を 0 にすれば通常 CoT に退化するため、既存モデルへの drop-in な拡張として実装できる点が特徴である。
これらに共通する設計思想は「LLM の言語能力は残したまま、その入出力経路から離散化のボトルネックを取り除く」ことである。出力は依然として natural language に decode 可能であり、verifier や RLHF など下流の道具立てを流用できる。
グループ C: Implicit CoT distillation
グループ C は教師の explicit CoT を生徒モデルの hidden 層に内在化する蒸留枠組みである。
Implicit CoT via Knowledge Distillation (Deng ほか 2023年) は「reasoning は hidden states の中で vertically に起こる」というスローガンを掲げ、教師の CoT 中間状態を生徒の中間 layer に蒸留する。Stepwise Internalization (Deng ほか 2024年) はその後継で、fine-tune 中に CoT トークンを段階的に削除し最終的にゼロまで持っていく curriculum を採る。完成した生徒は CoT を一切出力しない(test-time でも純粋な直接予測)が、内部表現に reasoning step が畳み込まれている。
グループ C は test-time scaling を提供しない点で他と異なる。生徒は通常の forward を 1 回流すだけで答えに到達することを目指す。グループ A–B が「test-time に追加計算を投資する道」を探るのに対し、グループ C は「reasoning を train-time に詰め込む道」を探る。本書の主題である recursive reasoning とは方向が逆だが、「reasoning は必ずしも自然言語 trace を必要としない」という前提を共有する隣接領域である。
グループ D: Self-generated rationale
Quiet-STaR (Zelikman ほか 2024年) は各 token 位置で内部 rationale を生成させ、その rationale 込みで次 token を予測したときの loss を下げる方向に REINFORCE 的に学習する。グループ A–C が「教師の CoT」や「placeholder」を前提にするのに対し、Quiet-STaR は モデル自身が「考えるべき内容」を発見する。生成された rationale は test-time に複数 sample されて aggregate される。
GSM8k で zero-shot 5.9 % から 10.9 %、CommonsenseQA で 36.3 % から 47.2 % という改善は、rationale を 8 本生成して mixing head で重み付き和を取る設定で得られた。グループ D は自然言語 trace と「latent」の境界に立つ手法群で、生成される rationale は人間が読める一方、それを test-time の追加計算源として扱う点で グループ A の placeholder と機能的に重なる。
グループ E: Recurrent depth: HRM/TRM/GRAM の本拠地
グループ E は 同じ層パラメータを test-time に深さ方向で再帰展開する 系統で、本書の主要 5 論文である HRM、TRM、PTRM、GRAM、LDT はここに属する。さらに Geiping recurrent depth (Geiping ほか 2025年) は同じ思想を 3.5B parameters の LLM に適用したもので、r 個の recurrent block を test-time に任意回ループさせる。系譜上の前史は Depth recurrence の系譜 で詳説するとおり、Adaptive Computation Time(ACT, 2016)から Deep Equilibrium Models(DEQ, 2019)、Universal Transformer、PonderNet、Looped Transformers と長く続いてきた。
グループ E 内部の最近の細分化として、確率性の入れ方で 3 系統に分かれる。決定論的な HRM/TRM は単一 trajectory を返す。test-time stochastic な PTRM は学習済 TRM checkpoint に推論時のみ Gaussian noise を加える。train-time stochastic な GRAM は variational に確率的 latent transition を学習し並列軌道を扱う。これらと独立に、LDT は確率性ではなく abstract interpretation の lattice projection を加えて sound deduction を獲得する別軸を切り開いた。詳細は各章で扱う。
グループ E は他の グループ と決定的に異なる 4 つの属性を持つ。これが本書の中心的観察である。
HRM/TRM/GRAM が グループ B と決定的に異なる 4 属性
LRS (Zhu ほか 2025年) の vertical / horizontal 区分だけ見れば、HRM/TRM/GRAM は グループ E、Coconut 系は グループ B というだけの違いに見える。だが両者を並べると、設計思想に一段の差があることが分かる(表 2)。
| 属性 | グループ B(Coconut 系) | グループ E(HRM/TRM/GRAM) |
|---|---|---|
| ベースモデル | 大規模 LLM の上に被せる(hidden 再利用) | 自己完結の tiny network(LLM 不使用) |
| 言語ボトルネック | 各ステップで token を経由しないが、出力は natural language | latent state から直接 grid/構造化出力にマップ |
| 訓練データ | 数百 B token の pre-train + 数万件の CoT fine-tune | task ごとに千〜数万サンプル、from scratch |
| test-time scaling | 連続 thought の本数(横幅) | 再帰深さ一択、GRAM のみ並列軌道幅も |
第一に、LLM の上に被せない、自己完結の tiny network である。Coconut や Geiping は LLM の hidden state を再利用し、結果として natural language 生成能力を残す。HRM(27M)、TRM(7M)、GRAM(10M)は task-specific な小さなニューラルネットで、言語 generation を完全に捨てている。「latent」という呼称は同じでも、グループ B では LLM の最後の linear projection を抜き取った形、グループ E では最初から linear projection を持たない形である。
第二に、言語ボトルネックそのものを排除 している。グループ B も離散化は回避するが、出力は依然として natural language の token 列である。グループ E は ARC-AGI のグリッドや Sudoku の数字盤のような構造化出力に latent state を直接マップする。言語層を経由しないからこそ、Frontier LLM が苦戦する格子状タスクで小規模モデルが勝利する余地が生まれる。
第三に、訓練データ規模が桁違いに小さい。LLM 系は数百 B token の pre-train を前提とするが、HRM/TRM は task ごとに 1,000 サンプルから訓練を始められる。これは グループ B の前提を真逆にする条件で、Coconut は LLM が持つ言語的世界知識の上にしか乗らないのに対し、グループ E は世界知識を捨てて構造的な計算能力だけを獲得する。
第四に、test-time scaling は深さ一択(GRAM のみ並列軌道幅 \(N\) も)である。Coconut の「1 vector に複数 path を重ねる」と GRAM の「\(N\) 軌道を sample」は機能的に重なるが、グループ B が連続 thought の本数で width を稼ぐのに対し、グループ E の中心は再帰回数 \(K\) である。Geiping の recurrent depth は 3.5B モデルで r=4 から r=32 まで test-time に伸ばせることを示し、グループ E と グループ B の中間に立つ橋となっている。
Coconut 系は 「LLM の言語層をバイパスして reasoning を高速化したい」 という efficiency 動機から出発する。LLM は所与で、その推論経路の冗長性を削るのが目標である。
HRM/TRM/GRAM は 「reasoning は最初から離散言語と無関係な計算で、大規模 LM は要らない」 という architecture-first 動機から出発する。LLM そのものを問題視し、構造化推論には別のアーキテクチャがあるはずだという主張である。
同じ “latent reasoning” の傘の下でも、出発点が efficiency か architecture かで設計判断のすべてが変わる。サーベイの分類軸を表面的に見るときには、この問題意識のレイヤ差を見落とさないよう注意してほしい。
グループ F: Diffusion-based reasoning
Diffusion-of-Thoughts (Ye ほか 2024年) は diffusion LM の denoising step に reasoning を相乗りさせる。図 図 3 のとおり、左から右に token を生成する autoregressive ではなく、時間 \(t = T\) から \(t = 0\) への denoising 過程として reasoning chain 全体を並列に磨く。GSM8k の 4-digit multiplication でベース AR LM を上回る一方、Single-Pass と Multi-Pass という 2 種類の sampling を提供して accuracy / latency のトレードオフを露出させた。
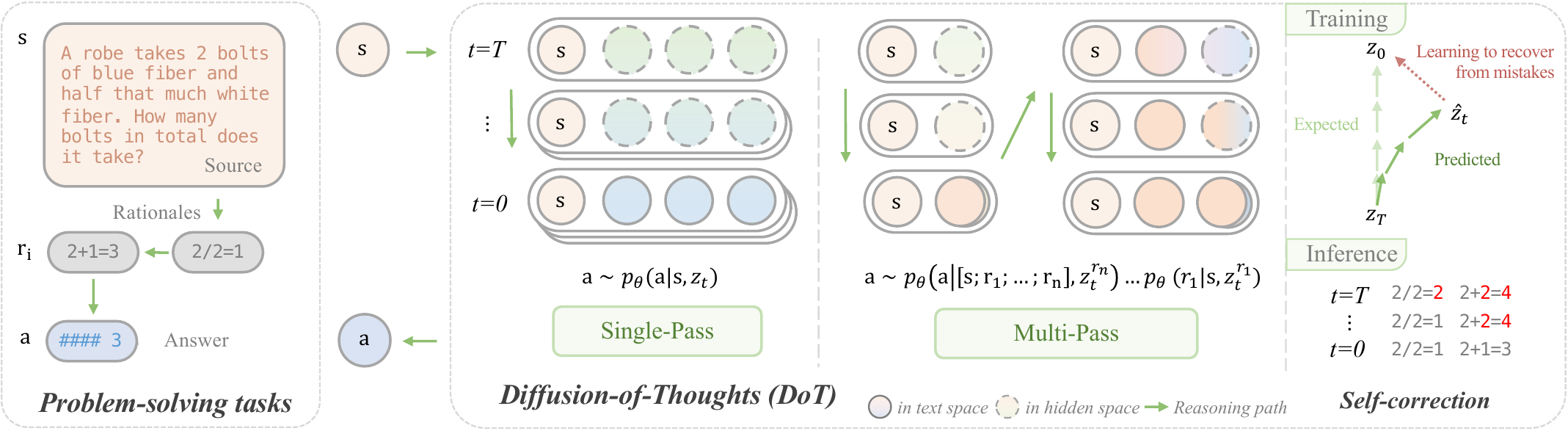
LRS (Zhu ほか 2025年) の分類では diffusion は「無限深度の連続時間極限」として vertical / horizontal の 2 軸に乗らない第三の軸を構成する。HRM/TRM/GRAM の離散深さ \(K\) を \(K \to \infty\) かつ Gaussian noise injection ありに極限化したものが diffusion と読める。事実、GRAM の variational latent transition は diffusion の forward process と数学的に類縁である。
2025 年の LaDiR (Kang ほか 2025年) はこの diffusion 系を reasoning 文脈にさらに近づけた研究で、Variational Autoencoder(VAE)で reasoning ステップを encode し、latent diffusion model が blockwise bidirectional attention でそれを refine する。数学・コード・パズルで多様な reasoning trajectory を生成する設計は、グループ E 寄りの GRAM(variational latent transition)とグループ F 寄りの diffusion-of-thoughts の中間に位置する。本書 GRAM の variational 設計と並べて読むと、「reasoning の trajectory を確率分布として扱う」発想が異なる学派から独立に到達されつつあることが見える。
グループ G: Concept-level
Large Concept Model(LCM) (LCM team ほか 2024年) は Meta が 2024 年 12 月に発表した、token ではなく sentence embedding 単位で autoregressive prediction する系統である。SONAR という固定 encoder で文を 1024 次元のベクトルに射影し、Transformer がこの sentence embedding 列から次の embedding を予測する形で学習する。loss は Mean Squared Error(MSE)、diffusion、または quantized cross-entropy の 3 種が試され、いずれも token-level LLM とは異なる粒度で reasoning する。
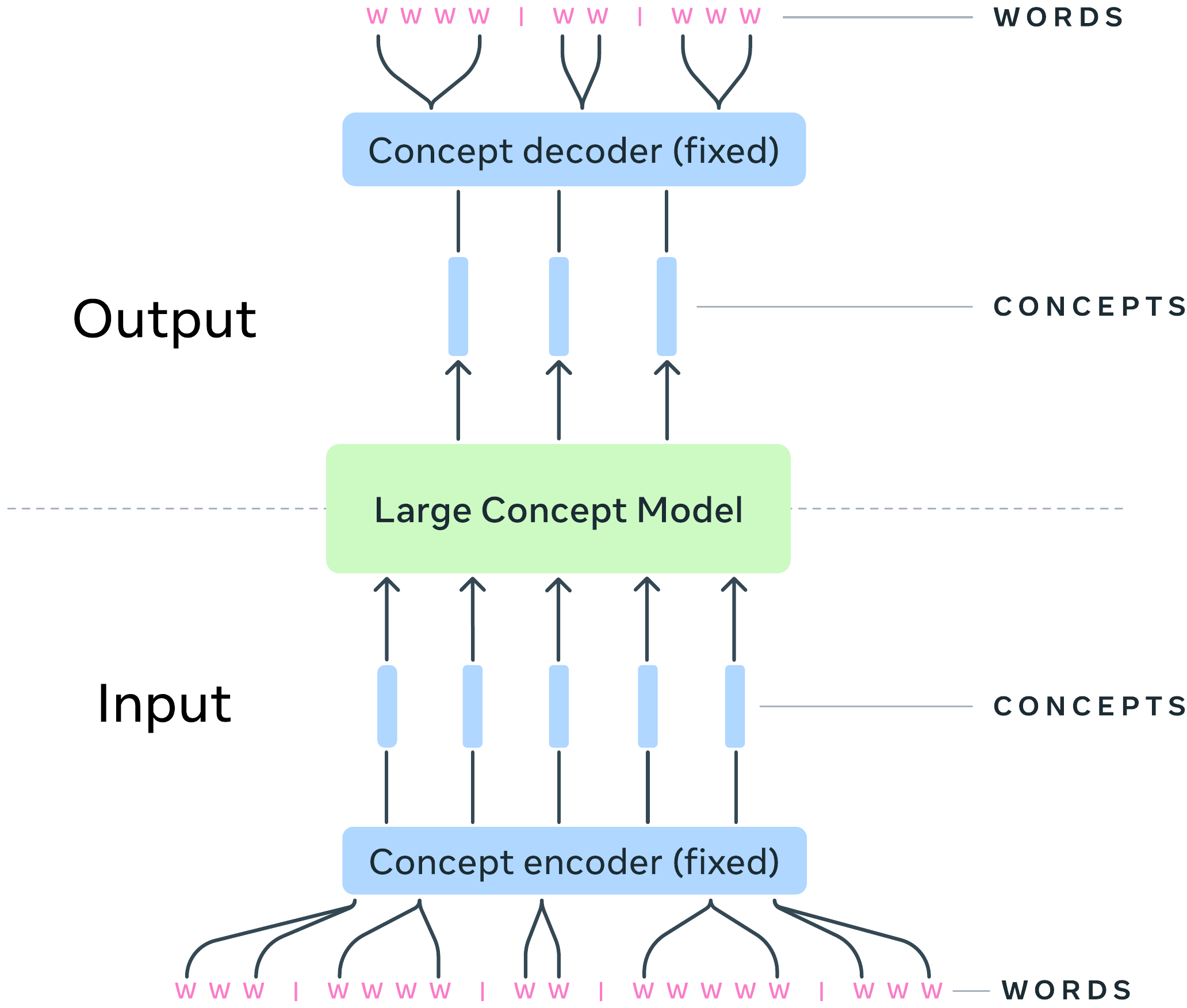
LCM は「reasoning の単位は token より上の抽象層にあるべき」という仮説の最も極端な実装で、グループ B–E が hidden state レベルで latent reasoning を進めるのに対し、明示的に sentence 単位の意味表現を経由する。test-time scaling は生成 concept 数で測られ、各 concept が複数 word に展開されるため token 効率が高い。
3 軸で見る latent reasoning の全体像
表 1 の 7 グループ を、3 つの直交軸で整理し直すと、HRM/TRM/GRAM の立ち位置がさらに明確になる。
- 言語チャネル軸: 出力が natural language か(B, C, D, F, G)/構造化出力か(E のみ、グループ A は依存)
- ベースモデル軸: 大規模 LLM 必須か(B, C, D, G)/LLM 部分依存(F, A)/LLM 不要(E)
- test-time scaling 軸: 横幅で稼ぐ(B, D)/深さで稼ぐ(E)/無限深度(F)/提供しない(C)
HRM/TRM/GRAM は 3 軸の交点でいずれも「左端」(構造化出力/LLM 不要/深さ)に位置する。これは Depth vs Token Scaling で扱う Snell ら (Snell ほか 2024年) の compute-optimal scaling や Brown ら (Brown ほか 2024年) の log-linear coverage と直接比較するとき、最も極端な対照点を提供する位置取りである。
本章のまとめ
Latent reasoning は単一の手法ではなく、placeholder(A)/horizontal continuous CoT(B)/distillation(C)/self-generated rationale(D)/vertical recurrent depth(E)/diffusion(F)/concept-level(G)の 7 つのグループ に分かれる。LRS (Zhu ほか 2025年) の vertical / horizontal 区分はこの分類の骨格を成すが、本章はそこに 4 つの グループ を加えて全体像を捉えた。
本書の主役である HRM/TRM/GRAM は グループ E(recurrent depth)に位置するが、同じ latent reasoning 傘下の グループ B(Coconut 系)とは 4 属性(ベースモデル、言語ボトルネック、訓練データ規模、test-time scaling 軸)のすべてで決定的に異なる。Coconut 系の動機が efficiency(LLM を高速化)であるのに対し、HRM/TRM/GRAM の動機は architecture-first(LLM 不要)であり、問題意識のレイヤが一段違う。この対比を踏まえると、HRM/TRM/GRAM を「Coconut の発展形」として読むのは誤読であり、別系統の研究プログラムとして独立に評価する必要があることが分かる。