Depth vs Token Scaling
「同じパラメータ数のモデルでも、test-time に計算を多く投じれば賢くなる」というスケーリング則は、2024 年以降の大規模言語モデル(Large Language Model, LLM)研究を駆動してきた前提である。OpenAI o1 から o3、DeepSeek-R1 (DeepSeek-AI ほか 2025年) に至る Chain-of-Thought(CoT)系列は、thinking token を長く吐くことでこの test-time compute を支払い、Hierarchical Reasoning Model(HRM)(Wang ほか 2025年) / Tiny Recursive Model(TRM)(Jolicoeur-Martineau 2025年) / Generative Recursive reAsoning Models(GRAM)(Baek ほか 2026年) / Geiping ら (Geiping ほか 2025年) の recurrent depth 系列は、同じ層を何度も再帰展開することでこの test-time compute を支払う。両者は表面的にはまったく異なるが、計算複雑性の観点では同じ目的を別の媒体で達成しようとしている。本章では二つの paradigm を対比し、補完性・統合可能性・実用的使い分けを論じる。
二つの paradigm
test-time compute を投資する道は、現代の reasoning research において大きく二系列に分かれる。
Sequential token scaling: 外部 tape としての CoT
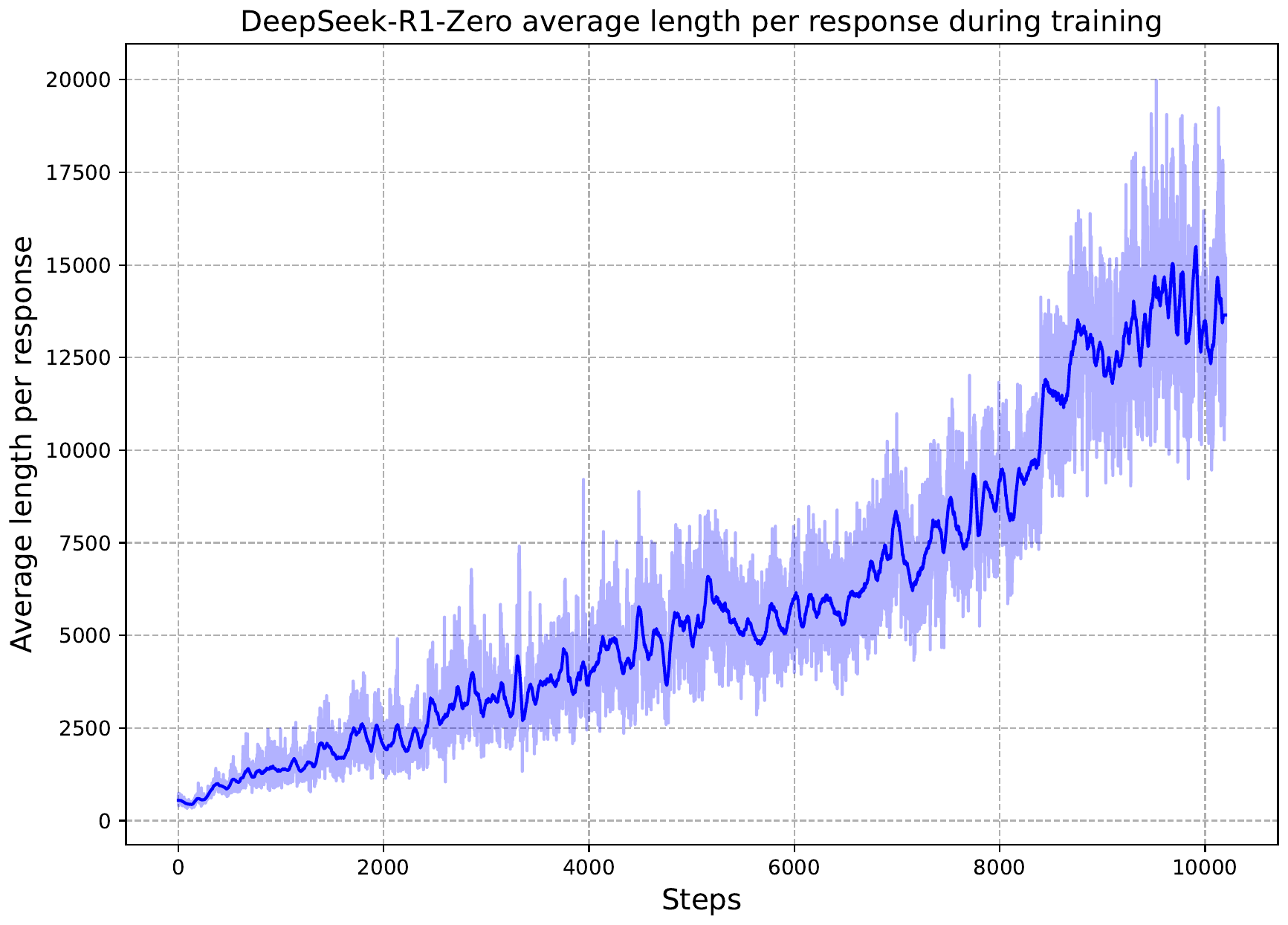
OpenAI o1(2024 年 9 月)が立ち上げ、DeepSeek-R1 (DeepSeek-AI ほか 2025年) が公開モデルとして決定的に証明したのが、Reinforcement Learning from Verifiable Rewards(RLVR)で訓練した LLM に、長い CoT を生成させて test-time compute を支払う戦略である。R1-Zero の訓練曲線では、Group Relative Policy Optimization(GRPO)の最適化が進むにつれて平均応答長が単調に伸びていき、モデルが自発的に「考える時間」を獲得していく様子が視覚的に確認できる。
CoT scaling の理論的・実証的基盤は、3 本の鍵論文で固められた。
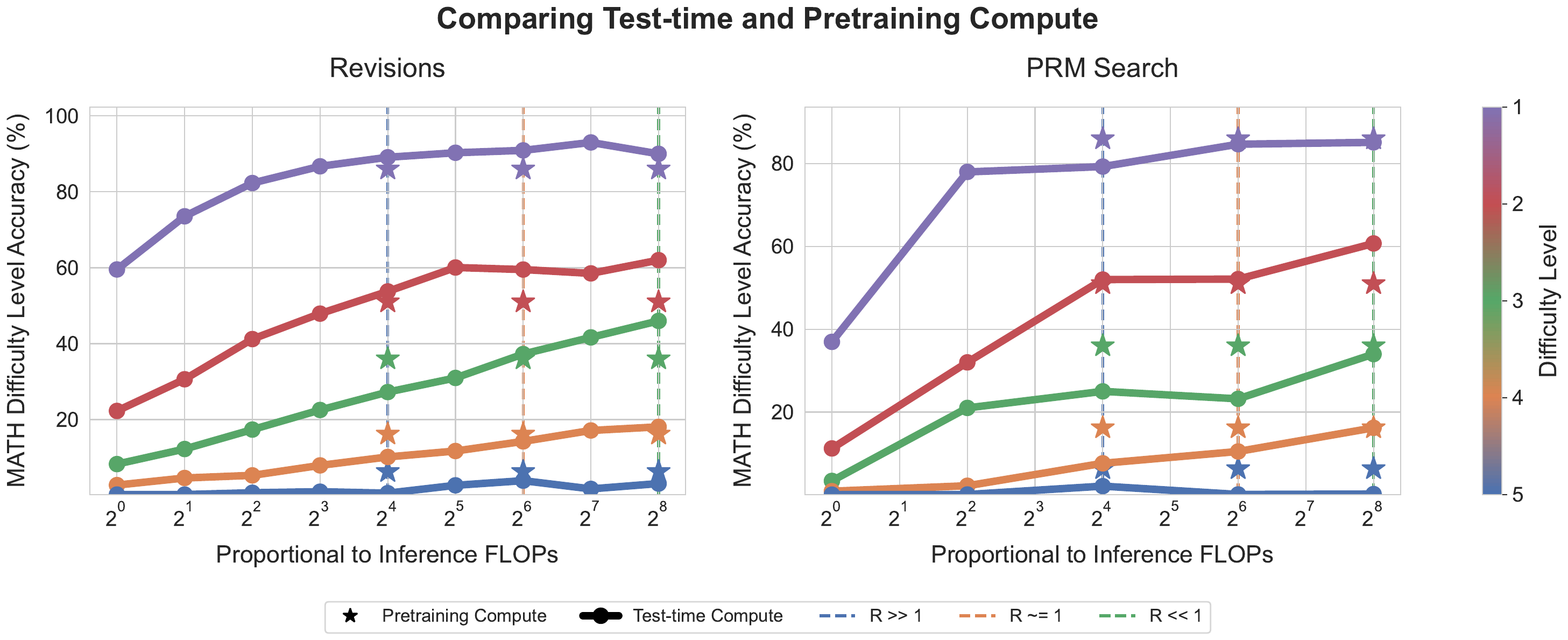
- Snell ら (Snell ほか 2024年) は、prompt の難易度と inference 予算に応じて Best-of-N(BoN)/ revision / Process Reward Model(PRM)検索を切り替える compute-optimal な test-time 分配 を提示し、適切に配分すれば 14 倍小さなモデルでも大規模モデルを上回れることを MATH ベンチマークで示した(図 2)。
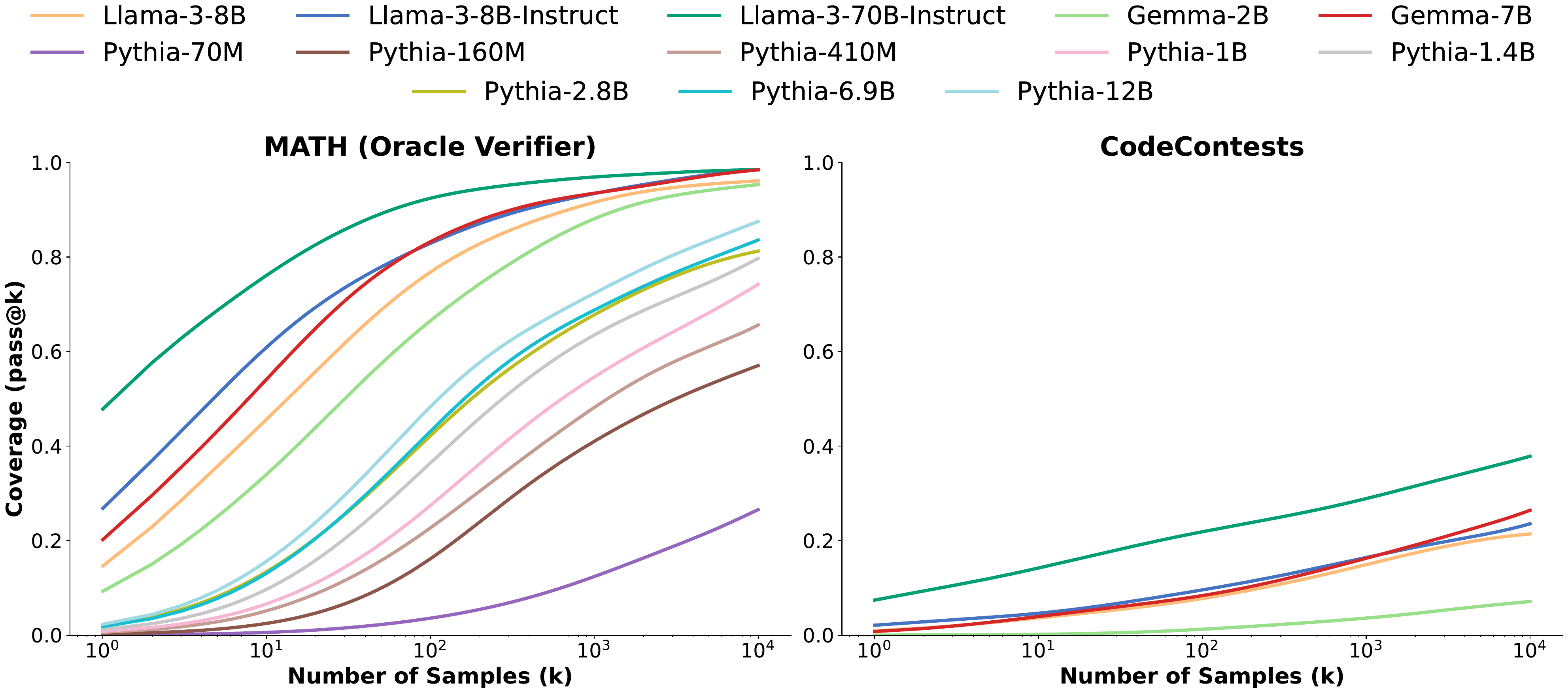
- Brown ら (Brown ほか 2024年) の “Large Language Monkeys” は、repeated sampling の coverage(pass@k)が 4 桁にわたって log-linear に伸びることを観測し、サンプリング回数こそが暴力的だが信頼できる scaling 軸であることを示した(図 3)。
- Chen ら (Chen ほか 2024年) は LM call 数に対し性能が非単調になる場合があることを理論と実験で示し、adaptive allocation がなぜ重要かの土台を与えた。
これら一連の知見は、「CoT を長く吐く」だけでなく「並列に多数サンプルを引く」「中間出力を検証して revision する」までを含めた sequential token scaling のレシピ集として、現代の reasoning research の主流を形成している。
Recurrent depth scaling: 内部 tape としての潜在再帰
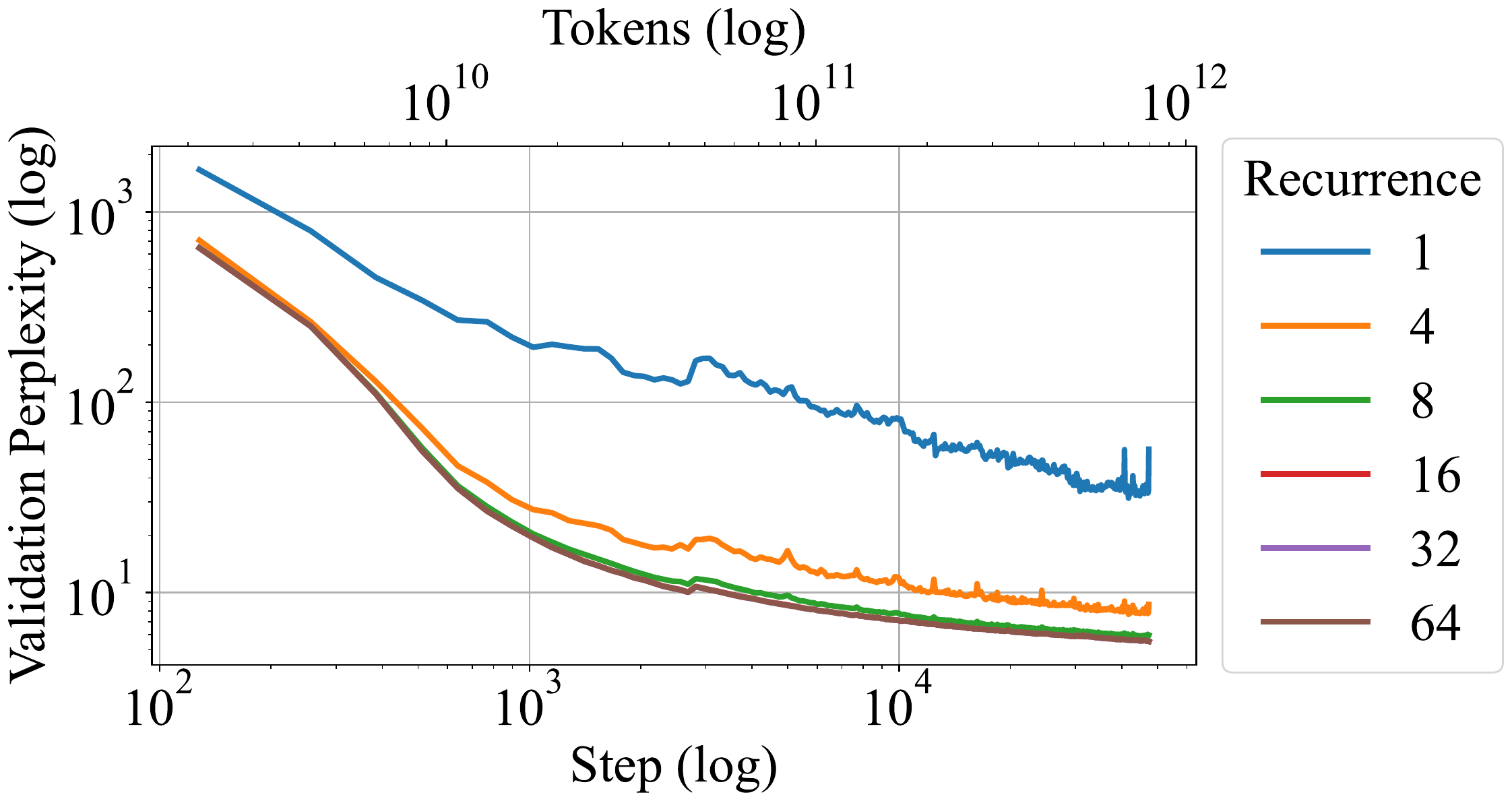
もう一つの道は、同じ層を test-time に深く再帰展開する戦略である。本書の主要 5 論文である HRM (Wang ほか 2025年)、TRM (Jolicoeur-Martineau 2025年)、PTRM (Sghaier ほか 2026年)、GRAM (Baek ほか 2026年)、LDT (Davis ほか 2026年) はいずれもこの系列に属し、small net(800K–27M parameters)を \(NT\) ステップ以上展開して reasoning を実行する。同じ思想を LLM スケールに持ち込んだのが Geiping ら (Geiping ほか 2025年) で、3.5B parameters のモデルを recurrent block で訓練し、test-time の recurrence 回数を増やすだけで perplexity と downstream 性能が単調改善することを示した。
この系列の共通主張は明確で、「外部に token を吐かなくても、内部 hidden state の反復で reasoning は実現できる」というものである。
比較表
両者の差は単一の比喩で要約できる。CoT が token を外部 tape として再注入 するのに対し、recurrent depth は hidden state を内部 tape として再注入 する。違いはレシピの細部にも一貫して現れる。
| 軸 | CoT scaling | Recurrent depth scaling |
|---|---|---|
| パラメータ規模 | 数百 B(R1: 671B) | 7M–3.5B |
| 学習データ | trillion tokens + Reinforcement Learning from Human Feedback(RLHF)/ RLVR | 1,000 サンプル(HRM/TRM) |
| 汎用性 | open-domain | task-specific(Sudoku / Maze / ARC-AGI) |
| 解釈性 | 自然言語 trace(人間可読) | latent state(不可視) |
| 1 step の情報帯域 | \(O(d_\text{vocab})\) softmax 経由 1 token | \(\mathbb R^d\) をそのまま流す |
| Verifier 統合 | 中間 trace に対し容易(PRM、SC、BoN) | 中間 latent に対し困難 |
| 再帰の媒体 | token tape(離散・外在) | hidden state(連続・内在) |
表 1 の各軸は独立ではなく、最後の「再帰の媒体」が他のすべてを規定している。token tape を選んだ瞬間に、(i) 学習には大量の言語データが必要になり、(ii) trace が読めるので汎用性と解釈性が両立し、(iii) 1 step あたりの情報帯域は語彙サイズの softmax に潰される。hidden state tape を選んだ瞬間に、(i) 言語データを介さず少数サンプルで訓練でき、(ii) trace が読めないので task-specific になり verifier も挟みにくくなるが、(iii) その代わり 1 step あたりの情報帯域は \(\mathbb R^d\) の連続値をそのまま保てる。
理論的論点: なぜ二者は等価でありうるか
Transformer の単一 forward は depth が固定で、circuit complexity の意味で \(TC^0\) 近傍に閉じ込められる。Merrill と Sabharwal らの一連の解析が示したように、これは多項式時間の planning や symbolic manipulation を end-to-end の単一 forward では実行できないことを意味する。CoT も recurrent depth も、この fixed-depth 限界を test-time に押し広げるために再帰の構造を導入する点では同じである。
両者は理論的には等価な計算能力を持ち得る。CoT は token を外部 tape として再注入し、tape の長さに比例して effective depth を伸ばす。Recurrent depth は hidden state を内部 tape として再注入し、recurrence 回数に比例して effective depth を伸ばす。いずれも depth を test-time に線形にスケールさせる手段であり、Turing-completeness 議論の文脈でも両者は同じカテゴリに属する。
しかしコスト構造は対称ではない。1 ステップあたりの情報帯域で見ると、CoT は各ステップで hidden state を語彙確率分布に softmax で写像し、サンプリングで 1 token に潰す。\(d\) 次元の hidden state が持つ情報量は \(\log_2 |\mathcal V|\) bit にまで圧縮される。一方 recurrent depth は hidden state を直接次ステップへ流すため、\(\mathbb R^d\) の連続値そのままが次の計算に投入される。Recurrent depth は 1 ステップあたりの情報帯域が桁違いに広い代わりに、人間が読めず、verifier も挟みにくい。解釈性とのトレードオフはここに根本の源がある。
ここで言う「等価」は 任意精度・任意深さの極限で同じ class の関数を表現できるという意味であり、有限の訓練条件・パラメータ予算で同じ性能が出るという意味ではない。実証的には CoT scaling と recurrent depth scaling は得意分野が大きく異なる(前者は open-domain、後者は structured grid task)。等価性の議論は両者を統合する設計空間を考えるための出発点であって、現状の trade-off を消すものではない。
HRM/TRM/GRAM はどちらに属するか
明示的には三者とも (B) recurrent depth scaling に属する。\(NT\) ステップの inner recurrence と \(K\) 回の deep supervision segment を test-time に増やすことで性能を伸ばす設計は、token を一切吐かずに depth を伸ばす純粋な形式である。
ただし注意深く見ると、内部に (A) sequential token scaling 的な要素を密輸入している。
- HRM の outer refinement loop: ARC Prize Foundation の独立検証 (Ge ほか 2025年) が示したように、HRM の真のドライバは hierarchical convergence ではなく outer-loop refinement(1 → 2 で +13 pp、1 → 8 で性能ほぼ倍増)であり、これは事実上 Best-of-K 的な verifier 型 inference として機能している。各 segment が独立な「候補」を出し、deep supervision の損失構造が暗黙の selection を担うとも読める。
- PTRM の test-time width scaling: 2026 年 5 月の PTRM (Sghaier ほか 2026年) は学習済 TRM checkpoint をそのまま使い、各 deep recursion step で latent に Gaussian noise を加えた \(K\) 並列 rollout を走らせ、TRM の Q head を verifier として最良軌道を選ぶ。PPBench で depth scaling(\(D=16 \to 48\))が +3.1 pp なのに対し width scaling(\(K=1 \to 100\))が +13 pp と、depth より width の方が線形性が良く並列化も可能であることを定量化した。学習段階の介入が要らない「再学習不要の width scaling」軸を確立している。
- GRAM の parallel trajectory: GRAM は確率的 latent transition を導入し、\(N \times K\) の depth × width 2 軸 test-time scaling を獲得した。Sudoku-Extreme で \(N=20, K=16\) の並列軌道集約が \(K=320\) の単一深い decoder を上回るという結果は、Self-Consistency(SC)/ Majority Voting に対応する 「latent 空間内の Self-Consistency」と読める。PTRM が test-time 介入だけで対処したのに対し、GRAM は学習段階に確率項を組み込むことで unconditional generation も同時に獲得する。
「depth × width」軸という概念で見ると、CoT 側でいう「thinking token 長 × Best-of-N」の latent 翻訳に他ならない。PTRM と GRAM の貢献は、CoT scaling のレシピが (B) 側でも基本的に同じ構造を持ち、しかも PTRM のように test-time に上から流すことも GRAM のように学習時に組み込むこともできることを実証した点にある。
これと直交する第 3 の方向として、LDT (Davis ほか 2026年) は train compute と test compute のトレードオフを逆向きに使う。Sudoku-Extreme で訓練ステップを増やすほど推論時の per-puzzle forward 数の中央値・上位 percentile が桁単位で短縮するという観察は、「sound deduction を学習できれば、追加の学習が推論時 search を肩代わりして消す方向に働く」ことを意味する。CoT が「より長く考える」ことで test-time compute を伸ばし、HRM/TRM/PTRM/GRAM が「同じ層を深く・並列に展開する」ことで test-time compute を伸ばすのに対し、LDT は abstract interpretation 由来の sound 性保証を頼りに「学習で推論探索を内在化する」ことで test-time compute を減らす方向に進む。「Width × Depth × Token-length」の三軸 Pareto に加えて、「Train compute → Test compute substitution」という独立軸を recursive reasoning に持ち込んだ事例として読める。
Coconut という橋: 両者を連続補間する
二つの paradigm は完全に断絶しているわけではない。Coconut (Hao ほか 2025年) は CoT の各ステップで行われる「hidden → token softmax」を取り除き、最終 hidden state をそのまま次ステップに戻す continuous thought を提案した。形式的にはこれは recurrent depth と等価な操作であり、同時に 「CoT を連続化したもの」と読める。CoT と recurrent depth の連続補間が可能な設計空間として、Coconut は二者の橋として位置付けられる(Latent reasoning の分類 の グループ 分類でも、Coconut は「離散 token と連続 hidden の境界を曖昧にした最初の系」として中心に置かれる)。
GRAM の parallel trajectory はさらに、Coconut の continuous thought が暗黙の幅優先探索(Breadth-First Search, BFS)的性質を持つことの確率的明示化と読める。決定論的な Coconut は単一の continuous trajectory しか持たないが、GRAM は変分推論で複数 trajectory の分布を扱うことで、Self-Consistency の latent 版を実現している。
両者を構造的にまとめると次のようになる。CoT の段階を「離散 token tape」、Coconut の段階を「連続 continuous thought」、HRM/TRM/GRAM の段階を「task-specific latent recurrence」と並べると、token 圧縮の度合いと open-domain 言語との結びつきが連続的に変化していく一本の軸が現れる。Fractional Reasoning など 2026 年に登場した手法が reasoning depth をスカラー \(\alpha\) で連続制御する試みを始めているのも、この設計空間の連続補間が現実的な研究課題になりつつあることを示している。
実用上の使い分け
理論的に等価でも、コスト構造の非対称性が大きいため、デプロイ先によって使い分けが必要になる。
- General-purpose / open domain / 人間が trace を読みたい: CoT scaling(DeepSeek-R1、o3、GPT-5 Pro 等)。多様なクエリに汎用的に応答する必要がある、reasoning trace の監査が必要、verifier や PRM を挟んで信頼性を担保したい場合は CoT が圧倒的に有利。
- 狭い structured task / 大量データなし / latency 厳しい / オンデバイス: HRM/TRM 系。Sudoku、ARC-AGI、組合せ最適化、特定ドメインの constraint satisfaction など、入出力構造が固定的で大量 trace を吐く余裕がない場合に強い。7M parameters でオンデバイス推論可能という規模感は、エッジデバイス用途において CoT 系列との明確な差別化要因になる。既存の TRM checkpoint があり test-time の精度を上げたい場合は PTRM、最初から確率モデルを訓練するなら GRAM、誤答を出す代わりに abstain させたい高信頼性用途では LDT という選択になる。
- 次世代の基盤モデル: Coconut (Hao ほか 2025年) や Geiping (Geiping ほか 2025年) 型の continuous thought + 言語層の hybrid。同一モデルが question ごとに (A)/(B) を切り替える adaptive allocation が現実的になる方向である。難しい problem には deep recurrence を、open-ended な dialogue には CoT を、それぞれ動的に切り替える設計が研究されつつある。
短く言えば、CoT は「汎用性と解釈性を払って計算を買う」、recurrent depth は「汎用性と解釈性を売って計算効率を買う」という対称な交換になっている。コスト比較で勝負が決まるのではなく、デプロイ先がそのトレードオフを許すかどうかで選択肢が決まる。これが両者の使い分けを考える際の最も実用的な軸である。
CoT 側では Chen ら (Chen ほか 2024年) の adaptive LM call 数最適化や Snell ら (Snell ほか 2024年) の compute-optimal selection で、問題ごとに inference 予算を変える研究が始まっている。Recurrent depth 側では HRM の Q-head(Adaptive Computation Time, ACT)が同じ役割を担うが、この二系列を統一的に扱う adaptive allocation 理論は本書執筆時点(2026 年 5 月)ではまだ存在しない。Width × Depth × Token-length の三軸 Pareto を扱う framework は今後の重要な研究課題である。
章のまとめ
本章の論点を整理する。
- 二つの paradigm: CoT による sequential token scaling と HRM/TRM/GRAM/Geiping による recurrent depth scaling は、test-time compute を支払う媒体(外部 token tape vs 内部 hidden tape)が異なる二系列である。
- 理論的等価性: 両者は depth を test-time に伸ばす手段としては等価な計算能力を持ち得る。違いは媒体のコスト構造、特に 1 ステップあたりの情報帯域(\(\log_2 |\mathcal V|\) bit vs \(\mathbb R^d\))にある。
- 実証上の trade-off: CoT は汎用性・解釈性・verifier 統合性を得る代わりに帯域を語彙サイズに潰し、recurrent depth は帯域を保つ代わりに汎用性・解釈性・verifier 統合性を失う。
- HRM/TRM/GRAM の位置: 表向き (B) だが、HRM の outer refinement や GRAM の parallel trajectory は CoT 側の Best-of-K / SC を latent 空間に翻訳した構造として読める。「depth × width」軸は両 paradigm で共通する設計次元である。
- Coconut という橋: Coconut (Hao ほか 2025年) は softmax を介さず hidden state を直接次ステップへ流すことで、CoT と recurrent depth の連続補間を可能にした最初の系である。両者を統合する設計空間の中心に位置する。
- 使い分け: コストの優劣ではなく、デプロイ先が解釈性・汎用性を要求するか、効率・低 latency を要求するかで paradigm を選ぶべき。adaptive allocation を含む統一 framework は今後の研究課題。