flowchart TD
ACT["ACT<br/>(Graves 2016)<br/>halting & ponder cost"]
UT["Universal Transformer<br/>(Dehghani 2018)<br/>depth recurrence + ACT"]
IAI["Iterative Amortized<br/>Inference<br/>(Marino 2018)"]
ALBERT["ALBERT<br/>(Lan 2020)<br/>cross-layer sharing"]
DEQ["DEQ<br/>(Bai 2019)<br/>fixed point + IFT"]
PN["PonderNet<br/>(Banino 2021)<br/>probabilistic halting"]
LTC["Looped Transformers<br/>as Programmable<br/>Computers<br/>(Giannou 2023)"]
LTL["Looped TF for<br/>Learning Algorithms<br/>(Yang 2024)"]
LTG["Looped TF for<br/>Length Generalization<br/>(Fan 2025)"]
GEI["Recurrent Depth<br/>(Geiping 2025)<br/>3.5B LLM, test-time unroll"]
MOR["MoR<br/>(Bae 2025)<br/>token-level adaptive depth"]
HRM["HRM<br/>(Wang 2025)"]
TRM["TRM<br/>(Jolicoeur 2025)"]
SOT["Sotaku<br/>(Lou 2026)<br/>800K Sudoku 98.9%"]
PTRM["PTRM<br/>(Sghaier 2026)<br/>test-time stochastic"]
GRAM["GRAM<br/>(Baek 2026)<br/>train-time stochastic"]
LDT["LDT<br/>(Davis 2026)<br/>+lattice deduction"]
ACT --> UT
ACT --> PN
UT --> ALBERT
UT --> LTC
ALBERT --> LTC
DEQ -.-> HRM
PN -.-> HRM
UT --> LTL
LTC --> LTL
LTL --> LTG
LTG -.-> GEI
UT --> GEI
IAI -.-> DEQ
IAI -.-> HRM
UT --> HRM
GEI -.-> HRM
GEI -.-> MOR
HRM --> TRM
TRM --> PTRM
TRM --> GRAM
HRM --> GRAM
TRM -.-> SOT
SOT --> LDT
Depth recurrence の系譜
HRM の登場時に強調された「アーキテクチャとして novel である」という主張を評価するには、何がいつ既に揃っていたかを正確に押さえる必要がある。実際には、Recurrent Neural Network(RNN)/ Transformer の上で「同じ重みを何度も使い、何回通すかを学習で決める」という設計思想は、2016 年の Adaptive Computation Time(ACT)から 10 年近い前史を持つ。本章はその系譜を 10 本の論文で辿り、HRM/TRM/GRAM の真の貢献が「アーキテクチャ部品」ではなく「特定レジームでの実証」にあることを示す。
系譜の全体像
主要 10 本を時系列で並べると、おおむね三つの太い枝が見える。ACT 系(halting と adaptive computation)、DEQ 系(fixed point と implicit gradient)、Looped Transformer 系(universality と test-time looping)の三系統である。HRM はこの三系統が同時に収束する場所に立っており、TRM/GRAM がさらにその束を簡約・確率化する。
以下、各論文を年代順に短く整理する。一本一本がどの「部品」を提供したか、HRM/TRM/GRAM がどこを引用しているかに焦点を絞る。
ACT: 計算量を入力に合わせて変える (2016)
Adaptive Computation Time(ACT)(Graves 2016年) は、RNN が 入力ごとに計算ステップ数を学習する 枠組みを最初に与えた。各時刻 \(t\) で sigmoid 出力 \(h_t \in [0,1]\) を halting probability として読み、累積和が \(1-\varepsilon\) を超えた時点で計算を打ち切る。打ち切るまでに費やしたステップ数(ponder cost)を損失に加えると、ニューラルネットは「難しい入力には深く考え、簡単な入力は早く出力する」挙動を学習する。
ACT が後世に残した遺伝子は二つある。一つは「同じ重みを複数回走らせる」という weight-tied recurrence そのもの、もう一つは halting head による adaptive halting である。Universal Transformer・PonderNet・HRM の Q-head はいずれもこの 2016 年の枠組みを参照している。HRM が「adaptive halting で計算量を入力ごとに調整する」と語るとき、想起すべき祖はここにある。
Universal Transformer: Transformer に depth recurrence を入れる (2018)
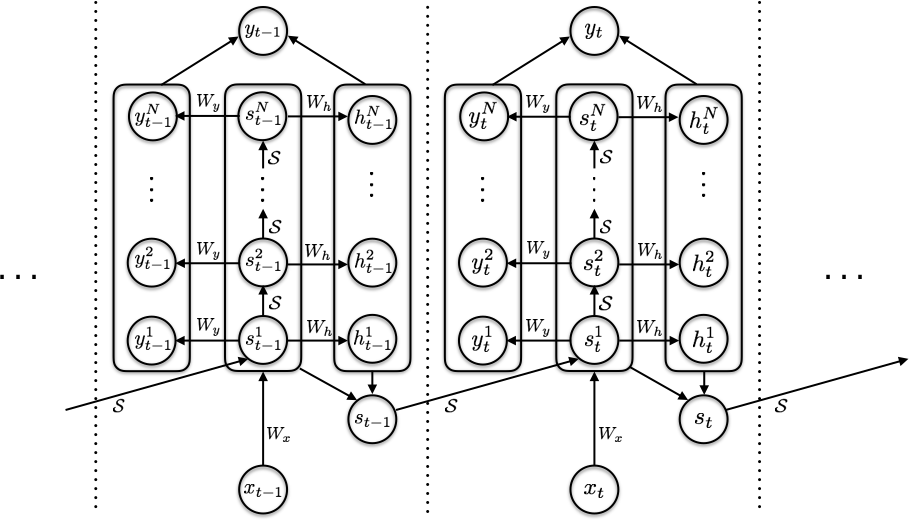
Universal Transformer(UT)(Dehghani ほか 2019年) は ACT を Transformer に持ち込んだ最初の主要論文である。標準 Transformer の各層を weight-tied で時間方向に複数回適用 し、各位置で halting probability を出して「位置ごとに違う深さ」で停止する。本書の系譜における depth recurrence(vertical recurrence)の祖 に当たり、HRM 論文は UT を直接参照している。
UT の重要な観察は、Transformer の表現力を語るときに「層数」と「同じ層を何回通すか」を分離できる点にある。深さは固定である必要がなく、入力依存に展開してよい。これが HRM の \(NT\) 回 unroll、Geiping recurrent depth の test-time looping、Looped Transformer の universality 証明に共通する前提となる。本書の文脈では、UT は単独で読むよりも「Transformer 版の ACT」と位置付けるのが最も自然である。
Iterative Amortized Inference: 推論を反復的最適化と捉える (2018)
Marino らの Iterative Amortized Inference (Marino ほか 2018年) は、Variational Autoencoder(VAE)の inference network を 「勾配を反復的にエンコードする optimizer」 として実装した。標準的な VAE では encoder \(q_\phi(z \mid x)\) が 1 回の forward で近似事後分布を返すが、ここでは encoder に「現在の Evidence Lower BOund(ELBO)の勾配を入力として与え、その方向に近似事後を一歩進める」という再帰構造を持たせる。
この論文が系譜に与えた影響は二つある。一つは「inference は 1-shot ではなく iterative optimization である」という 変分的視点 であり、これは後年の DEQ の固定点定式化や GRAM の amortized variational inference にまで通底する。もう一つは「同じニューラルネットを使って状態を逐次改善する」という設計を、reasoning の中核モチーフとして変分の文脈に持ち込んだことである。
ALBERT: 重み共有を「節約」として正当化する (2019)
ALBERT (Lan ほか 2020年) は系譜の中ではやや別系統に見えるが、cross-layer parameter sharing で「同じ重みを 12 回適用しても Bidirectional Encoder Representations from Transformers(BERT)に匹敵する」 ことを大規模に示した点で外せない。BERT-Large(334M)の層ごとに独立な重みを共有化して 18M まで縮めても、いくつかの GLUE タスクで同等以上の性能を出した。
ALBERT の貢献を単純化して言えば、「Transformer の層を時間方向に解釈してよい」 という発見を経験的に裏付けたことにある。Universal Transformer が表現力の観点から weight tying を導入したのに対し、ALBERT は「パラメータ節約」の観点から同じ構造に到達した。この二系統の合流が、後の Looped Transformer 系列で「weight-tied がむしろ標準である」という前提を確立する。HRM/TRM が「数 M パラメータで大規模モデルと張り合う」と語るときの前提条件は、ここで一度示されていたのである。
DEQ: Weight-tied の極限を固定点として扱う (2019)
Deep Equilibrium Model(DEQ)(Bai ほか 2019年) は weight-tied ニューラルネットを無限に重ねた極限 を fixed point \(z^* = f_\theta(z^*, x)\) として扱い、Implicit Function Theorem(IFT)を使って \(O(1)\) メモリで勾配を計算する手法である。通常の Backpropagation Through Time(BPTT)が展開ステップ数に比例するメモリを要するのに対し、DEQ は固定点だけ保存しておけば逆伝播が \(1\) ステップで済む。
DEQ が HRM に与えた直接の影響は、「1-step gradient approximation の数学的根拠」 である。HRM は全 \(NT\) ステップを BPTT せず、最終ステップだけで勾配を取る近似を用いるが、その正当化は DEQ の IFT による implicit differentiation から借りている。\(f_\theta\) が contraction であれば 1-step linearization が良い近似になるという議論は、DEQ の文献にそのまま乗っている。後述するように、TRM はこの「contraction だから 1-step で良い」という議論を ablation で否定し、full BPTT に戻して性能を上げた。HRM の理論的支柱の一つが系譜の中でどこから来たかを押さえておくと、TRM の否定が何を否定しているかが明確になる。
PonderNet: Halting を Bernoulli 過程として書き直す (2021)
PonderNet (Banino ほか 2021年) は ACT の halting を Bernoulli 過程として確率的に再定式化 し、KL 正則化で安定化した。ACT の元の定式化は halting probability を累積和で扱うためバイアスが入りやすく、訓練が不安定になりがちだった。PonderNet は「各ステップで止まるか続けるかの Bernoulli sampling」を明示し、目標分布(geometric prior 等)との KL 距離をペナルティとして加えることで、計算量と精度のトレードオフを温度パラメータで制御できる枠組みに整えた。
HRM の Q-learning ベースの halting は、形式的には PonderNet の系譜に位置する。「止まる」「続ける」の二択を強化学習のアクションに置き換え、解けたかどうかを reward に使うが、根本のアイデア(halting を確率的決定として扱い、外部から正則化する)は PonderNet で確立されている。系譜の上では、ACT → PonderNet → HRM Q-head の流れが一本通っている。
Looped Transformers as Programmable Computers: 13 層で万能機を作る (2023)
Giannou らの Looped Transformers as Programmable Computers (Giannou ほか 2023年) は、13 層の Transformer を loop すれば universal computer を構成できる ことを構成的に証明した。論文では One Instruction Set Computer(OISC)の各命令を Transformer block で実装し、レジスタを位置 embedding で表現することで、loop 回数を制御するだけで任意の計算が実現できることを示す。
この論文の意義は 「Transformer の表現力は層数ではなく loop 回数で測るべき」 という主張に理論的根拠を与えた点にある。HRM/TRM が「8 層を 16 回 loop すれば 128 層相当」と語るとき、その背後にはこの Turing 完全性証明がある。Looped Transformers as Programmable Computers は、後続の経験的研究(次節)の土台でもある。
Looped Transformers Are Better at Learning Learning Algorithms (2024)
Yang らによる ICLR 2024 論文 (Yang ほか 2024年) は、In-Context Learning(ICL)で loop が標準 Transformer を上回る ことを実験的に示した。線形回帰・スパース回帰・決定木学習などの ICL タスクで、同じパラメータ数の標準 Transformer よりも loop した小さい Transformer の方が高い精度に到達し、より複雑な「学習アルゴリズム」を ICL で表現できる。
この結果は 「実用領域で loop が効く」初の経験的証拠 であり、Looped Transformers as Programmable Computers の理論を「単なる存在証明」から「実用候補」へと格上げした。HRM/TRM 系列の「小規模 weight-tied ニューラルネットを test-time に深く回す」という戦略は、この経験的観察の延長線にある。
Looped Transformers for Length Generalization (2025)
Fan らの ICLR 2025 論文 (Fan ほか 2025年) は、推論時の loop 数を訓練時より増やすことで length generalization が改善する ことを示した。算術タスク(加算・乗算・Floor Operation: fop)で、訓練長より長い入力に対しても loop 数を入力長に比例して増やせば精度を維持できる。
これは HRM が主張する 「訓練時より多く loop することで test-time scaling が効く」 の直接の根拠となる結果である。Fan らの実験は「アルゴリズム的タスクなら recurrent depth が generalize する」ことを示しており、HRM/TRM が ARC-AGI や Sudoku のような構造化タスクで recursion depth を test-time に伸ばす戦略の正当化に使える。系譜の上では、Looped Transformers as Programmable Computers (2023) → Looped TF for Learning Algorithms (2024) → Looped TF for Length Generalization (2025) → HRM (2025) という太い流れが見える。
Geiping Recurrent Depth: 3.5B LLM 版の depth recurrence (2025)
Geiping らの Scaling up Test-Time Compute with Latent Reasoning (Geiping ほか 2025年) は、3.5B parameters の言語モデルが recurrent block を test-time に好きなだけ展開できる 事前学習プロトコルを提示した。事前学習段階で「ランダムな depth で展開する」訓練を行うことで、推論時に loop 数を変えるだけで thinking budget を連続的に制御できるモデルが得られる。
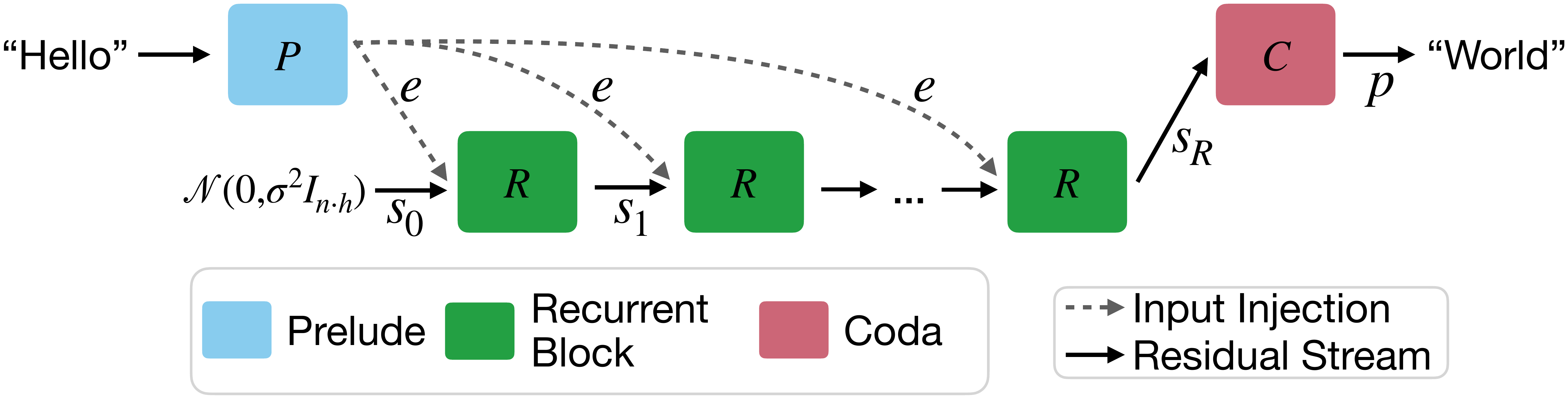
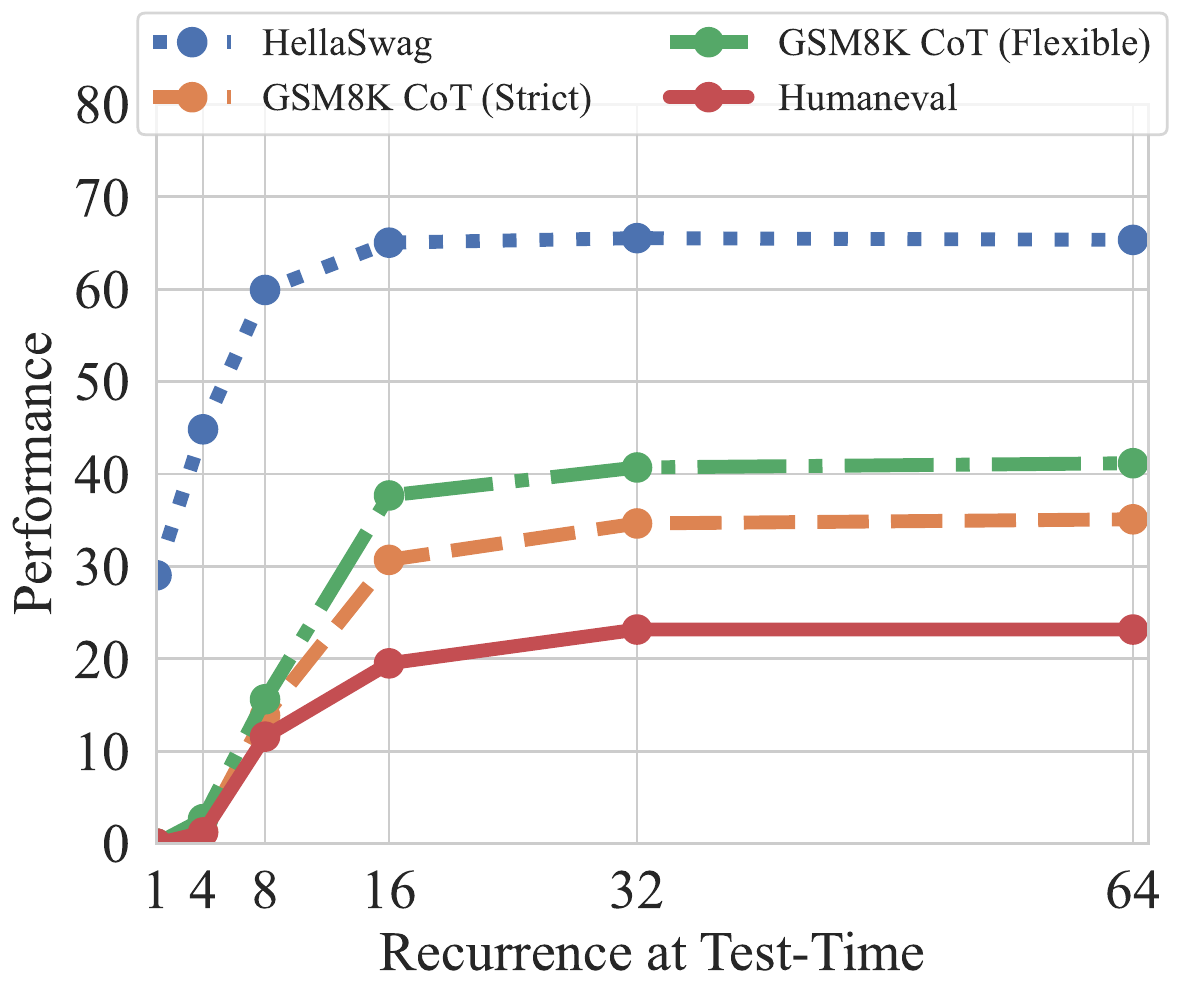
この論文の重要性は二つある。第一に、「Chain-of-Thought(CoT)特化データを使わずに test-time scaling の性質が出る」 ことを LLM 規模で示した点。第二に、HRM/TRM が「言語モデルを経由しない」のに対し、Geiping は「言語モデルの中で同じことをやる」 という位置取りで、recursive reasoning の枠組みが LLM コミュニティと地続きであることを示した点である。HRM の手法上の革新を相対化するには、ほぼ同時期に LLM 側でも depth recurrence 戦略が独立に試みられていたことを認識する必要がある。
Mixture-of-Recursions: token ごとに深さを変える (2025)
Bae らの Mixture-of-Recursions(MoR)(Bae ほか 2025年) は Geiping recurrent depth の直後に登場した NeurIPS 2025 論文で、共有層を再帰で再利用しつつ、token ごとに異なる再帰深さを軽量ルーターで割り当てる枠組みを提案した。すなわち Universal Transformer の adaptive halting を token level で再構成し、Geiping の「モデル全体を \(r\) 回ループ」よりも細粒度な depth 配分を可能にする。135M から 1.7B の規模で、同一 FLOP 予算下で vanilla Transformer と既存 recursive baseline を Pareto 上回りした。
MoR の意義は二つある。第一に、ACT (Graves 2016年) が 2016 年に提起した「token ごとに異なる深さで止まる」というアイデアを、LM 時代の routing 機構として現代化した点。第二に、HRM/TRM が「task 全体に対する固定 deep supervision」を採るのに対し、MoR は「token 単位の adaptive routing」を採る、recursive depth scaling の細粒度を一段押し下げた点である。本書の主要 5 論文がいずれも固定深さに留まる中、MoR は token-level adaptive depth という相補的な軸を示している。
Sotaku: TRM 系統からの個人実装による派生 (2026)
Cheng Lou による Sotaku (Lou 2026年) は、TRM の系譜から GitHub 上で独立に派生した from-scratch 実装である。4 層 weight-shared Transformer に 2D Rotary Position Embedding(RoPE)を組み合わせた約 800K parameters のニューラルネットで、訓練時に 16 反復、推論時に最大 1024 反復まで展開する extreme test-time scaling により Sudoku-Extreme で 98.9 %(24728/25000) を達成した。Sudoku-agnostic(row/col/box の制約を埋め込まない純粋な 2D grid 仮定)でこの精度に到達した点が際立つ。
Sotaku の系譜上の位置付けは、TRM の 1/10(7M → 800K)のサイズでなおかつ Sudoku-Extreme で 11 ポイント高い精度を独立に出した「TRM の引き算をさらに進めた」例である。論文発表ではなく個人 repo であるため正式な比較対象として議論されることは少ないが、続く LDT は Sotaku のアーキテクチャをほぼそのまま継承して abstract interpretation の lattice projection を追加した形で発展する。HRM/TRM/PTRM/GRAM の系譜と並走する「より symbolic deduction 寄り」の系統の起点として、Sotaku は重要なリンクである。
まとめ: HRM/TRM/GRAM の真の novelty
ここまでで挙げた 10 本の論文を整理すると、HRM の技術部品はすべて 2016 年から 2021 年にかけてほぼ揃っており、Looped Transformer 系列と Geiping recurrent depth が経験的妥当性を実証していたことが分かる。具体的には、
- weight-tied recurrence: ACT (2016)、Universal Transformer (2018)、ALBERT (2019)
- fixed point と 1-step gradient: DEQ (2019)
- adaptive halting: ACT (2016)、PonderNet (2021)
- test-time に深く回す: Looped TF 三部作 (2023–2025)、Geiping (2025)
- iterative inference の変分視点: Marino (2018)
が、HRM 以前にそれぞれ独立に確立されていた。HRM の貢献はこれらを 統合した上で、CoT 訓練データも大規模事前学習もないまま、27M parameters・1000 サンプルで離散 reasoning ベンチを解く ことを示した点にある。TRM はその統合のうち「階層性」「1-step gradient」を ablation で否定し、より単純な full BPTT の 2 層単一ニューラルネットで HRM を上回った。GRAM は TRM の効率を保ったまま decoder を probabilistic に拡張し、depth と width の 2 軸 test-time scaling を獲得した。
つまり、HRM/TRM/GRAM 三世代の 真の novelty は「アーキテクチャ部品」ではなく「depth recurrence 系を CoT・大規模データなしで離散 reasoning ベンチに通用させたというレジーム証明」 にある。逆に言えば、「hierarchy が効く」「1-step gradient が効く」といった部品レベルの主張は、TRM の ablation によってすでに否定されている。本書がこの系譜章を冒頭近くに置くのは、各章を読む読者に「どの主張がアーキテクチャの本質で、どの主張が装飾か」を最初から区別してもらうためである。
2026 年 5 月に登場した PTRM と LDT は、この系譜の最新分岐点として読める。PTRM は TRM checkpoint を再学習せずに test-time に Gaussian noise を加える「学習済モデルへの確率的探索」、LDT は Sotaku のアーキテクチャを継承しつつ abstract interpretation の lattice projection を追加する「sound deduction 系統」で、いずれも HRM/TRM が暗黙に保持していた「単一決定論的軌道」「latent の不透明性」を直接攻撃する設計判断である。
機構解釈の進展: attractor landscape の発見 (2026)
系譜上の部品レベルの新規性が頭打ちになる一方で、recursive depth ネットの内部を機構的に開封する研究が 2025-26 年に進展した。これは「何が動いているか」よりも「何が起きているか」の解像度を上げる方向の前進であり、本書の主要 5 論文を読む際の解釈枠組みを大きく変える。
第一に、Ren & Liu (Ren と Liu 2026年)(本書 HRM 章)が HRM の fixed-point property が実際には満たされていないことを示し、HRM の解き口が「reasoning というより guessing に近い」と機構レベルで指摘した。第二に、Blayney ら (Blayney ほか 2026年) は looped reasoning language model(Geiping 流の recurrent depth LM)を probing し、(i) 各層が iteration ごとに別個の固定点に収束する、(ii) モデルは feedforward 流の推論段階を 1 iteration ごとに繰り返す、と報告した。第三に、Efstathiou & Balwani (Efstathiou と Balwani 2026年)(本書 PTRM 章)は sparse autoencoder で TRM の latent dynamics を分析し、「再帰 reasoning は incremental refinement ではなく attractor landscape 上の adaptive search」と結論する。
Vision side では Jacobs ら (Jacobs ほか 2026年) が標準 ViT が暗黙に \(k \ll L\) 個の異なる block を深さ方向で繰り返す構造を持つことを示し(Raptor: 2 block で DINOv2 の 96 % を回復)、directional convergence into class-dependent angular basins、late-depth での low-rank update、低次元 attractor への収束、という動的解釈プログラムを提唱した。
これらを横断して見えるのは、depth recurrence の正体は単なる「層を繰り返して計算量を稼ぐ」のではなく、入力ごとに特定の attractor basin に収束する動的システムである、という統合的描像である。この描像は HRM/TRM の「深さで refine する」物語、PTRM の「noise で bad basin から escape する」発想、GRAM の「複数 trajectory で attractor を多様化する」発想、LDT の「lattice projection で attractor を sound に制約する」発想を、すべて同じ attractor landscape 上の異なる工学操作として読み直す視座を与える。本書の主要 5 論文を「異なる流派の独立な工夫」と読むだけでなく、「同じ景観上の相補的な探索戦略」として読み直すための足場として、この機構解釈の進展は重要である。
参考文献
Bae, Sangmin, Yujin Kim, Reza Bayat, ほか. 2025年. 「Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation」. arXiv preprint arXiv:2507.10524. https://arxiv.org/abs/2507.10524.
Bai, Shaojie, J. Zico Kolter, と Vladlen Koltun. 2019年. 「Deep Equilibrium Models」. Advances in Neural Information Processing Systems. https://arxiv.org/abs/1909.01377.
Banino, Andrea, Jan Balaguer, と Charles Blundell. 2021年. 「PonderNet: Learning to Ponder」. arXiv preprint arXiv:2107.05407. https://arxiv.org/abs/2107.05407.
Blayney, Hugh, Álvaro Arroyo, Johan Obando-Ceron, ほか. 2026年. 「A Mechanistic Analysis of Looped Reasoning Language Models」. arXiv preprint arXiv:2604.11791. https://arxiv.org/abs/2604.11791.
Dehghani, Mostafa, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, と Lukasz Kaiser. 2019年. 「Universal Transformers」. International Conference on Learning Representations. https://openreview.net/forum?id=HyzdRiR9Y7.
Efstathiou, Andreas, と Aishwarya Balwani. 2026年. 「Recursive Reasoning as Attractor Landscape Search: Mechanistic Dynamics of the Tiny Recursive Model」. Workshop on Latent and Implicit Thinking – Going Beyond CoT Reasoning, ICLR 2026. https://openreview.net/forum?id=kKps9W1K7n.
Fan, Ying, Yilun Du, Kannan Ramchandran, と Kangwook Lee. 2025年. 「Looped Transformers for Length Generalization」. International Conference on Learning Representations. https://arxiv.org/abs/2409.15647.
Geiping, Jonas, Sean McLeish, Neel Jain, ほか. 2025年. 「Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach」. arXiv preprint arXiv:2502.05171. https://arxiv.org/abs/2502.05171.
Giannou, Angeliki, Shashank Rajput, Jy-yong Sohn, Kangwook Lee, Jason D. Lee, と Dimitris Papailiopoulos. 2023年. 「Looped Transformers as Programmable Computers」. arXiv preprint arXiv:2301.13196. https://arxiv.org/abs/2301.13196.
Graves, Alex. 2016年. 「Adaptive Computation Time for Recurrent Neural Networks」. arXiv preprint arXiv:1603.08983. https://arxiv.org/abs/1603.08983.
Jacobs, Mozes, Thomas Fel, Richard Hakim, Alessandra Brondetta, Demba Ba, と T. Andy Keller. 2026年. 「Block-Recurrent Dynamics in Vision Transformers」. arXiv preprint arXiv:2512.19941. https://arxiv.org/abs/2512.19941.
Lan, Zhenzhong, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, と Radu Soricut. 2020年. 「ALBERT: A Lite BERT for Self-supervised Learning of Language Representations」. International Conference on Learning Representations. https://openreview.net/forum?id=H1eA7AEtvS.
Lou, Cheng. 2026年. Sotaku: From-scratch Experiments on Iterative Neural Sudoku Solvers. Software, GitHub repository, commit 9e13341. https://github.com/chenglou/sotaku.
Marino, Joseph, Yisong Yue, と Stephan Mandt. 2018年. 「Iterative Amortized Inference」. International Conference on Machine Learning. https://arxiv.org/abs/1807.09356.
Ren, Zirui, と Ziming Liu. 2026年. 「Are Your Reasoning Models Reasoning or Guessing? A Mechanistic Analysis of Hierarchical Reasoning Models」. arXiv preprint arXiv:2601.10679. https://arxiv.org/abs/2601.10679.
Yang, Liu, Kangwook Lee, Robert Nowak, と Dimitris Papailiopoulos. 2024年. 「Looped Transformers are Better at Learning Learning Algorithms」. International Conference on Learning Representations. https://arxiv.org/abs/2311.12424.