GRAM
GRAM(Generative Recursive reAsoning Models)は、Korea Advanced Institute of Science and Technology(KAIST)、New York University、Mila Québec AI Institute の Baek、Jo、Kim、Ren、Bengio、Ahn による 2026 年 5 月の論文で、Recursive Reasoning Model(RRM)系列に 確率的な多軌道計算 を持ち込んだ枠組みである (Baek ほか 2026年)。ICLR 2026 Workshop on AI with Recursive Self-Improvement(RSI)採択、arXiv:2605.19376、コードは執筆時点で未公開(プロジェクトサイトのみ公開)。本章では HRM と TRM の「決定論的 latent recursion」の限界を整理したうえで、GRAM が Gaussian guidance + amortized variational inference でそれを解く設計を見ていく。
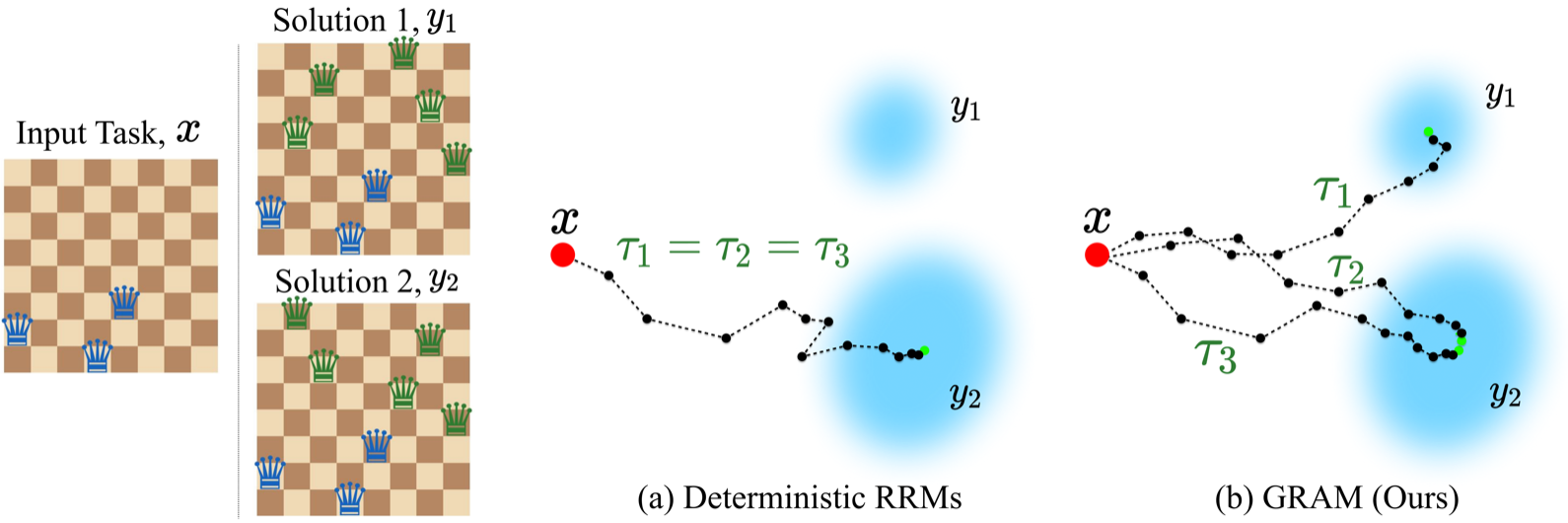
動機: 決定論的 RRM の 4 つの限界
HRM も TRM も、入力 \(x\) と初期状態 \(z_0\) を与えると 常に同じ latent trajectory \(\tau = (z_0 \to z_1 \to \dots \to z_T)\) をたどる。この単純さは、reasoning model として見ると 4 つの制約と表裏一体になる。
- Mode collapse: 複数の妥当解がある Constraint Satisfaction Problem(CSP)で単一の attractor に落ちる。8×8 N-Queens(12 本質解)では coverage が 36 % で頭打ち。
- Single latent trajectory: 同一入力に対する複数 forward は完全重複。test-time compute を「深さ \(K\)」の一軸でしか使えない。
- Unconditional generation 不可: \(z_T = f(x)\) は決定的関数なので \(p(x)\) を定義できず、空盤からの Sudoku 生成のような無条件サンプリングは原理的に不可能。
- Multi-hypothesis reasoning 不可: 不確実性を保持する内部変数を持たないため、「複数仮説を並列に保持する」という System 2 的 reasoning を計算機構として支えられない。
著者らは思想的背景に Kahneman の System 1 / System 2 と Bengio の consciousness prior (Baek ほか 2026年) を置く。「reasoning は単一の決定的経路を伸ばす行為ではなく、複数仮説を確率的に展開する行為である」という主張を RRM のアーキテクチャに直接埋め込むのが GRAM の動機である。
モデル定式化
確率的 latent transition
GRAM は HRM/TRM と同じ階層 latent \(z = (h, l)\) を使い、low-level \(l\) を \(K\) 回 refine してから high-level \(h\) を一度更新するという 1 ステップの再帰構造を保つ。違いは high-level 更新の最後に 学習可能な確率的ガイダンス \(\epsilon_t\) を残差として注入する点である。
\[ \begin{aligned} l_{t,k} &= f_L(h_{t-1}, l_{t,k-1}, e_x; \theta), \quad k=1,\dots,K \\ u_t &= f_H(h_{t-1}, l_t; \theta) \\ \epsilon_t &\sim p_\theta(\epsilon_t \mid u_t) := \mathcal{N}\bigl(\mu_\theta(u_t),\, \sigma^2_\theta(u_t) I\bigr) \\ h_t &= u_t + \epsilon_t \end{aligned} \tag{1}\]
\(\mu_\theta(u_t)\) は「進めるべき reasoning の方向」、\(\sigma^2_\theta(u_t)\) は「探索の幅」を、いずれも現在状態に条件付けて学習する。論文の ablation では、平均をゼロに固定した素のガウシアンノイズだけだと N-Queens で 50 % まで崩れ、平均と分散の両方を学習させて初めて 99 % 台に達する。「stochasticity と structured guidance のどちらも欠かせない」というのが GRAM の核となる経験的主張である。
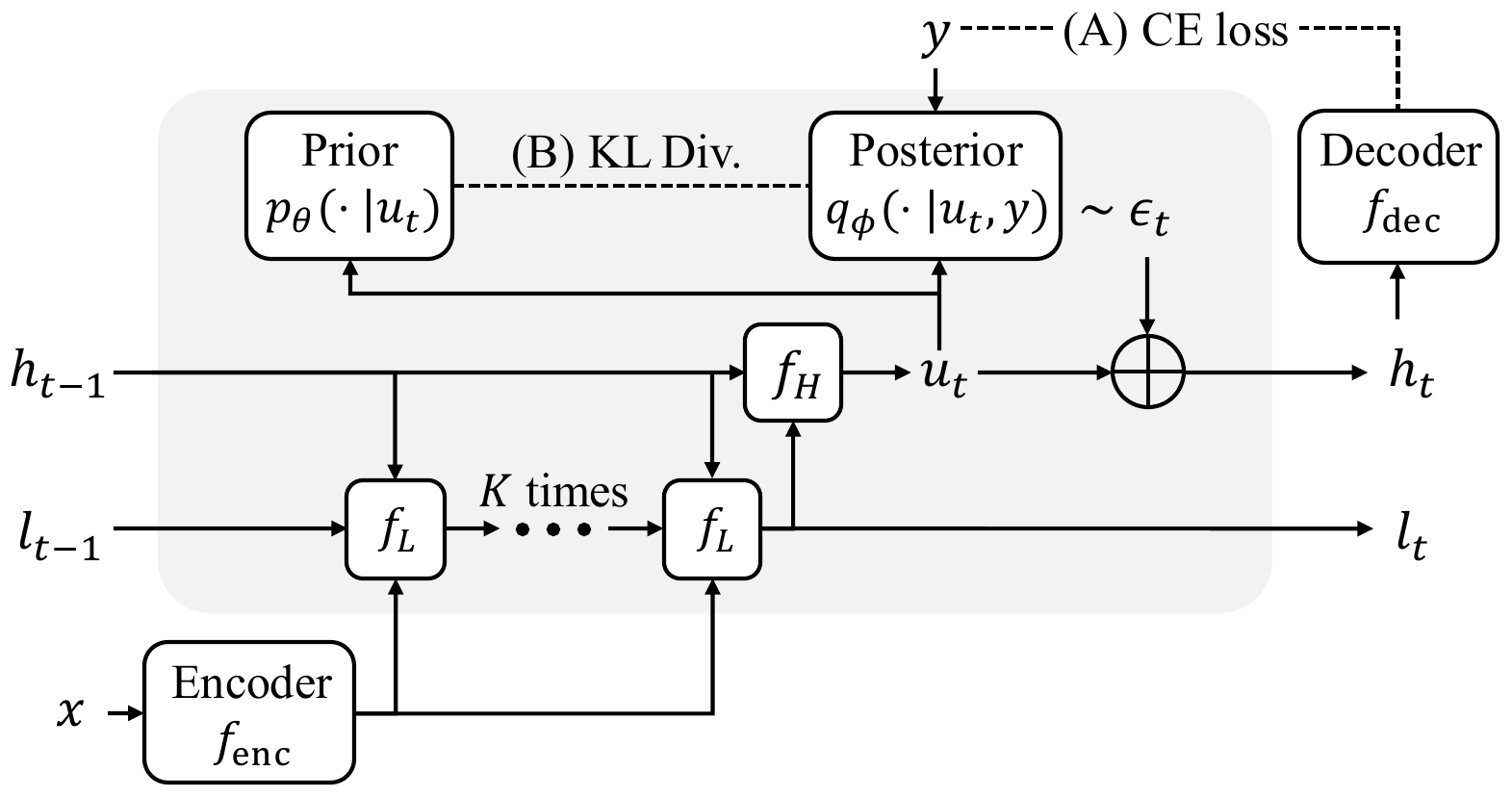
stochasticity を high-level のみに入れるのは設計上の選択で、low-level に入れる ablation では改善が見られなかった。「速い局所計算は決定的に、遅い大域 planning は確率的に」という Kahneman 的役割分担を計算機構に写像した形になっている。
Trajectory 上の生成モデル
1 supervision step が \(T\) 回の transition、全体で \(N_\text{sup}\) supervision step を積むので、trajectory は \(T_\text{total} = T \times N_\text{sup}\) 個の latent からなり、最終 latent から \(\hat y = \arg\max f_\text{dec}(z_{T_\text{total}})\) を取る。これで GRAM は trajectory 上の latent-variable 生成モデル になる:
\[ p_\theta(y \mid x) = \int p_\theta(y \mid \tau, x)\, p_\theta(\tau \mid x)\, d\tau, \qquad p_\theta(\tau \mid x) = p(z_0) \prod_{t=1}^{T_\text{total}} p_\theta(z_t \mid z_{t-1}, x). \tag{2}\]
入力 \(x\) を空の embedding に置き換えれば、同じ機構で \(p_\theta(x)\) を定義できる。すなわち 同一モデルで条件付き reasoning と無条件 generation の両方 を扱える。これは (LCM team ほか 2024年) や (Ye ほか 2024年) が文ベクトル / 拡散 latent 上で目指してきた reasoning を、再帰 transformer 系で実現した形にあたる。
Amortized Variational Inference による訓練
- の \(\tau\) 周辺化は閉形式で解けないため、変分事後 \(q_\phi(\tau \mid x, y)\) を導入して Evidence Lower Bound(ELBO)を最大化する:
\[ \log p_\theta(y \mid x) \ge \mathbb{E}_{q_\phi(\tau \mid x, y)}\bigl[\log p_\theta(y \mid z_{T_\text{total}}, x)\bigr] - \mathrm{KL}\bigl(q_\phi(\tau \mid x, y)\,\|\, p_\theta(\tau \mid x)\bigr). \tag{3}\]
事前と事後はともに Markov 連鎖として因子分解され、確率性は reparameterized Gaussian \(\epsilon_t\) を介してのみ入る。事後 \(q_\phi(\epsilon_t \mid u_t, y)\) は 正解 \(y\) を見ながら ガイダンスを引き、事前 \(p_\theta(\epsilon_t \mid u_t)\) は \(y\) を見ない。推論時は事前から \(\epsilon_t\) をサンプルする。
- を厳密に計算するには \(T_\text{total}\) ステップの backpropagation through time(BPTT)が必要で、メモリが線形に爆発する。GRAM は 各 supervision step の最終 transition \(z_{T-1}^{(n)} \to z_T^{(n)}\) にだけ勾配を流す truncated surrogate を採用する:
\[ \mathcal{L}_\text{GRAM}^{(n)} = \mathbb{E}_{q_\phi}\bigl[\log p_\theta(y \mid z_T^{(n)}, x)\bigr] - \mathrm{KL}\bigl(q_\phi(\epsilon_T^{(n)} \mid u_T^{(n)}, y)\,\|\, p_\theta(\epsilon_T^{(n)} \mid u_T^{(n)})\bigr). \tag{4}\]
これは HRM の 1-step gradient や Deep Equilibrium Model(DEQ)(Bai ほか 2019年) の implicit differentiation と同じ「BPTT を局所化する」発想を、trajectory level の KL に適用したものである。論文付録では、validation 上で full ELBO と surrogate がほぼ同期して単調に下がることが示され、近似の妥当性が裏付けられている。
ELBO を 1 step gradient で更新するアイデアは Iterative Amortized Inference (Marino ほか 2018年) にも先例がある。GRAM はその「事後を recursive に refine する」発想を reasoning trajectory そのものに移植したものと読める。
推論時 scaling: 深さ \(K\) × 並列軌道 \(N\)
GRAM の最も実用的な貢献は、test-time compute を 2 軸に分けて投資できる点である。深さ \(K\) は HRM/TRM と同じ supervision step 反復だが、決定論的 RRM では単一 trajectory が attractor に閉じ込められやすい。並列軌道数 \(N\) は事前 \(p_\theta(\tau \mid x)\) から \(N\) 本を独立サンプルし、各 terminal の候補 \(\hat y^{(i)} = f_\text{dec}(z_T^{(i)})\) を集約する新しい軸である。集約には majority voting か、Latent Process Reward Model(LPRM)による best-of-N を使う。
LPRM は decoder と並列に value head \(v_\psi(z_t)\) を学習し、現在 latent から最終正答率 \(r \in [0,1]\) を回帰する補助損失で訓練する:
\[ \mathcal{L}_\text{LPRM} = \sum_{t=1}^{T}\bigl(v_\psi(z_t) - r\bigr)^2. \tag{5}\]
推論時は \(\arg\max_n v_\psi(z_T^{(n)})\) で軌道を選ぶ。これは言語空間の Process Reward Model(PRM)を latent trajectory 上に移植したもので、「verifier-guided latent search」と呼ぶべき新カテゴリにあたる。
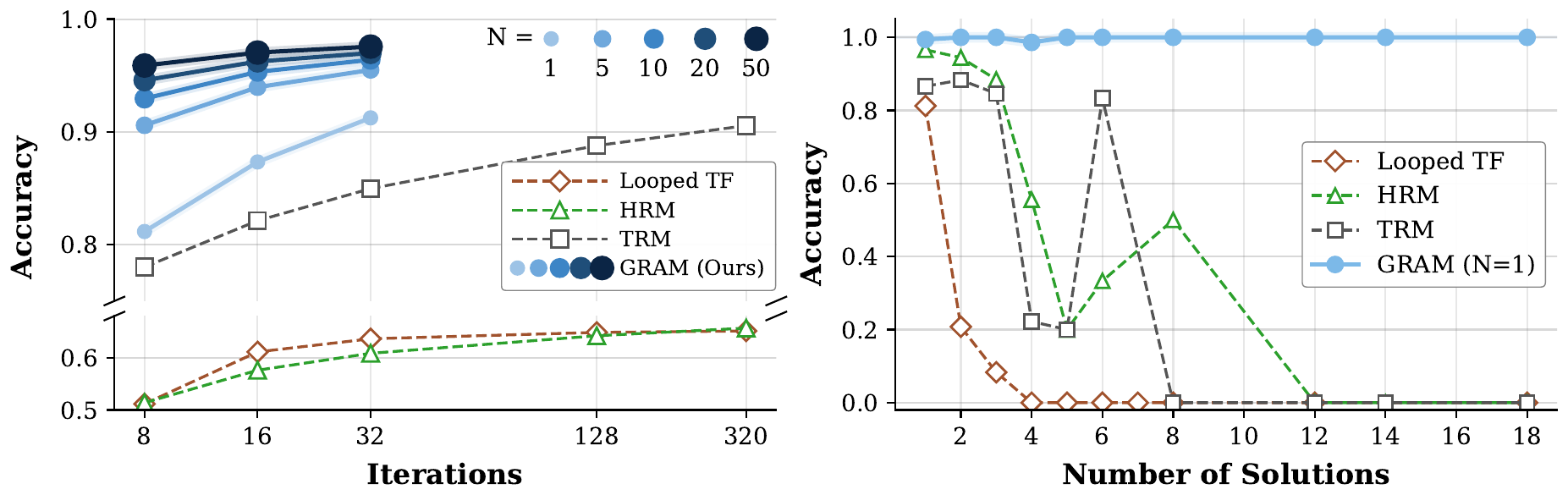
図 3 の左図は 並列軌道数を増やす方が、同じ compute で深さを増やすより効率が良い領域がある ことを示す。\(N=20\), \(K=16\) の GRAM が 97.0 % に達するのに対し、TRM は \(K=320\) まで深めても 90.5 % で頭打ちであり、決定論的 RRM が「単一 trajectory」の構造的制約のせいで深さでは救えない区間が存在することが定量的に確認された。本書の Depth vs Token Scaling に、recursion 側からの実例として接続する観察である。
実験結果
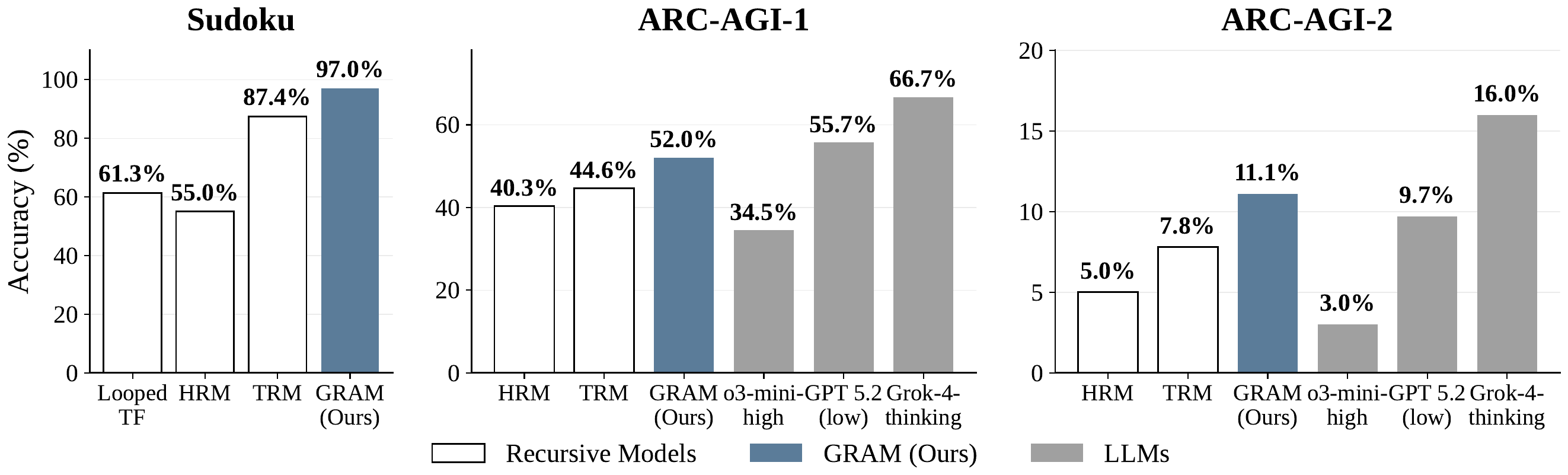
GRAM はあえて Frontier LLM との直接比較を避け、決定論的 recurrent / recursive baseline(Looped Transformer、HRM、TRM)との同条件比較に絞る。論文の主張は「大規模 LLM に勝つ」ではなく「RRM の中で確率化が効く」ことの立証にある。
| Task | Looped TF | HRM | TRM | GRAM |
|---|---|---|---|---|
| Sudoku-Extreme | 47.7 % | 55.0 % | 87.4 % | 97.0 % |
| ARC-AGI-1 | - | 40.3 % | 44.6 % | 52.0 % |
| ARC-AGI-2 | - | 5.0 % | 7.8 % | 11.1 % |
N-Queens や Graph Coloring などの複数解 CSP では、決定論的 RRM の限界が露骨に表れる(図 3 右)。8×8 N-Queens の単一精度は HRM 78.7 %、TRM 66.8 %、AR 96.3 %、Masked Diffusion Language Model(MDLM)96.1 % に対して GRAM 99.7 %、10×10 Graph Coloring の conflict edges(少ないほど良い)は HRM 164.3、TRM 170.7、AR 61.3、MDLM 12.0 に対して GRAM 3.3。AR/MDLM は多様性が高く制約に弱い、決定論的 RRM は制約に強く多様性ゼロ、という二者択一を「再帰精緻化 + 生成的多様性」の同一モデルで解消した形になる。
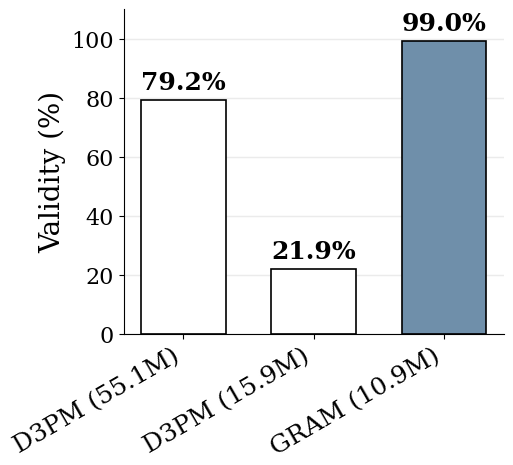
無条件生成では、空盤からの Sudoku 生成で GRAM が 10.9M パラメータ・16 supervision step で validity 99.05 % に達し、Discrete Denoising Diffusion Probabilistic Models(D3PM)の 55.1M パラメータ・1000 denoising step を下回る。
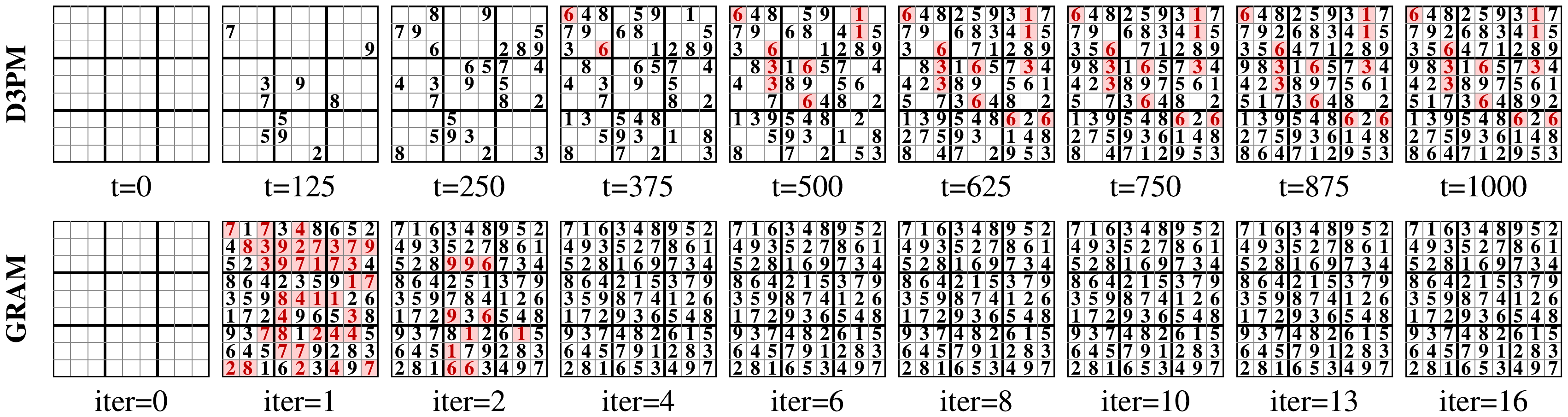
二値化 MNIST では TRM が完全に mode collapse する(Inception Score(IS)1.00 / Fréchet Inception Distance(FID)303.29)のに対し、GRAM は 256 step で IS 2.04 / FID 73.34 と D3PM に匹敵する。学習時 16 step で訓練しても推論時 256 step まで monotonic に改善し、inference-time scaling が generation 側にも持ち越されることが示された。
位置付けと残された課題
著者陣を見ると、Sungjin Ahn(KAIST/NYU) の SCALOR/Genesis 系列の object-centric latent generative model、Yoshua Bengio(Mila) の consciousness prior と GFlowNet、Mengye Ren(NYU) の脳着想アーキテクチャ研究という 3 系統が合流していることが分かる。HRM が脳科学的物語を強調し、TRM がその物語を ablation で剥がしていったのに対し、GRAM は「生成モデルとしての RRM」という別の理論枠組みから RRM を組み立て直す立ち位置にある。
本書の文脈での貢献は 3 点にまとめられる。第一に 2 軸 test-time scaling の実証: 深さ \(K\) × 並列軌道 \(N\) という独立軸が存在し、\(K\) を伸ばすより \(N\) を増やす方が効率的な領域が確かにあることを示した。第二に Latent verifier の登場: LPRM は言語空間 PRM の latent 版にあたり、verifier-guided latent search という新カテゴリを開いた。第三に reasoning model と generative model の橋渡し: \(p_\theta(y \mid x)\) と \(p_\theta(x)\) を同一モデルで扱えるため、両者を分けてきた従来の分類が再考を迫られる。
PTRM との対称性: train-time vs test-time の確率化
GRAM 公開から 2 週間後、Sghaier ら (Sghaier ほか 2026年) は別経路で同じ問題に取り組んだ。PTRM(本書 PTRM 章で扱う)は学習済 TRM checkpoint をそのまま使い、各 deep recursion step で latent に Gaussian noise を加える test-time の確率化 で、Sudoku-Extreme を 87.4 % から 98.75 % に押し上げる。再学習も task-specific augmentation も要しない。GRAM が train-time に確率項を学習し variational に訓練するのに対し、PTRM は推論時にだけ noise を流して TRM の Q head を verifier に再利用する設計で、両者は同じ「TRM の決定論的限界の突破」を表裏から実装している。
興味深いことに、PTRM 論文は「TRM の初期 latent \(z\) に noise を加えるだけ」の単純な ablation を試み、Sudoku で改善が出ないという負の結果を報告している。これは GRAM 論文自身が試した同じ ablation と一致しており、確率性は初期 \(z\) ではなく各 supervision step に注入する必要があるという共通の経験則が両論文で独立に確認された形になっている。GRAM の variational training と PTRM の test-time noise injection は、この共通の診断に対する異なる工学解と読める。
TRM 章末で整理したように、PTRM と GRAM はそれぞれ TRM の最小核に確率性を「推論時に上から流す」「学習時に組み込む」の 2 方向で足し戻す補完研究にあたる。PTRM が既存 TRM checkpoint をそのまま活かす代わりに generation 能力は得ないのに対し、GRAM は新規 model class を提案するコストを払う代わりに unconditional generation を獲得する。実用上は「TRM checkpoint が既にある」場合は PTRM、「最初から確率モデルを訓練する」なら GRAM という使い分けになる。
残された課題
論文自身が認める残された課題は、deep supervision の sequential 性が訓練効率の bottleneck となり、foundation model 規模へのスケールを妨げる点である。CoT が token sequence の並列性で大規模に伸びたのに対し、recursive な supervision step を並列化する方法はまだ確立していない。GRAM は HRM・TRM と同じく「小規模で構造的タスクに強い」レジームに留まっており、open-domain への汎化は今後の課題として残る。
また、PTRM/GRAM の確率化路線とは独立に、Davis らの Lattice Deduction Transformers (Davis ほか 2026年)(本書 LDT 章)は確率性ではなく abstract interpretation 由来の lattice projection を加えることで、解を返すか abstain するかの empirical soundness を獲得した。HRM → TRM 以降の小規模 recursive reasoning model 系列は、PTRM (test-time stochastic) / GRAM (train-time stochastic) / LDT (sound deduction) という 3 つの直交した拡張軸に分岐したとまとめられる。