HRM
Hierarchical Reasoning Model(HRM)(Wang ほか 2025年) は、Sapient Intelligence(Singapore)と Tsinghua University の Sen Song グループが 2025 年 6 月に arXiv に投稿し、同年 8 月に v3 まで改訂された論文で提案された再帰型 reasoning model である。第一著者は Guan Wang、コードは github.com/sapientinc/HRM で公開されている。論文公開直後に X 上で大きな話題となり、その後 ARC Prize Foundation による独立検証 (Ge ほか 2025年) と機構解析 (Ren と Liu 2026年) が公開され、主張と実証の乖離が広く議論された。本章では提案手法とその論拠、実験結果、そして批判の三層を切り分けて整理する。
問題設定: CoT を「外在化された松葉杖」と呼ぶ動機
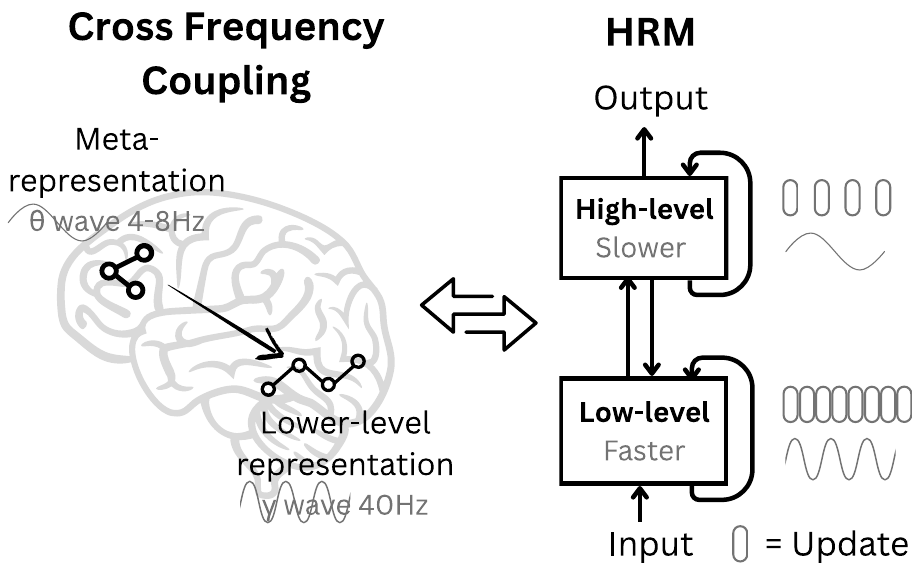
固定深さの Transformer は計算複雑性の意味で AC⁰ / TC⁰ 近傍に閉じ込められ、多項式時間の planning や symbolic manipulation を end-to-end には実行できない。論文はこの構造的限界を出発点に置き、Chain-of-Thought(CoT)はその限界を外部の token tape に逃がすための「外在化された松葉杖」だと述べる。CoT には (i) ステップ分解が手作りで脆い、(ii) 大量の demonstration が必要、(iii) decoding 遅延が線形に効く、という三重苦があり、これを latent space 内の反復計算 で解くべきだという立場を取る。動機の修辞は脳科学に強く依拠しており、(a) 皮質階層が空間的・時間的に異なるスケールで処理する、(b) θ 波(4–8 Hz)と γ 波(30–100 Hz)の周波数分離が安定な高レベル制御を可能にする、(c) recurrent connectivity による反復精錬が深い credit assignment 問題を回避する、の三点が繰り返し強調される。
アーキテクチャ: 4 部品と二重再帰
HRM は 4 つの学習可能部品から成る。入力ニューラルネット \(f_I\)、低レベル再帰モジュール \(f_L\)、高レベル再帰モジュール \(f_H\)、出力ヘッド \(f_O\) である。1 回の forward は \(N\) 個の高レベルサイクル × \(T\) 個の低レベルステップ=合計 \(NT\) timestep を unroll する。timestep を \(i = 1, \ldots, NT\) で indexing し、入力 \(x\) をまず作業表現 \(\tilde x = f_I(x; \theta_I)\) に射影する。各 timestep の更新規則は次の通りで、L は毎ステップ更新する一方、H はサイクル境界(\(T\) の倍数の timestep)でのみ更新する:
\[ z_L^i = f_L(z_L^{i-1}, z_H^{i-1}, \tilde x; \theta_L) \tag{1}\]
\[ z_H^i = \begin{cases} f_H(z_H^{i-1}, z_L^{i-1}; \theta_H) & \text{if } i \equiv 0 \pmod T \\ z_H^{i-1} & \text{otherwise} \end{cases} \tag{2}\]
\(N\) サイクル完了後、最終的な予測は \(\hat y = f_O(z_H^{NT}; \theta_O)\) で得る。\(f_L, f_H\) はいずれも encoder-only Transformer block(hidden 512、8 heads、4 層、SwiGLU、RMSNorm、Rotary Positional Encoding、Post-Norm)で、入力は要素和で合成される。
Hierarchical convergence: 計算の枯渇を防ぐ仕掛け
通常の Recurrent Neural Network は固定点に早期収束した時点で更新量が消え、それ以降のステップが事実上死ぬ。HRM はこれを hierarchical convergence と名付けた仕掛けで回避すると主張する。L が \(T\) ステップで局所均衡に達した時点で H が 1 度だけ更新され、新しい \(z_H\) を L に注入することで L の軌道を周期的にリセットする。結果として \(NT\) ステップ全体の forward residual(連続する hidden state の差分ノルム)は、サイクル境界ごとに周期的なスパイクを持つ。通常 RNN・深い Transformer・HRM の三者を比較した次の図は、HRM だけが計算活動を維持し続けることを示している。
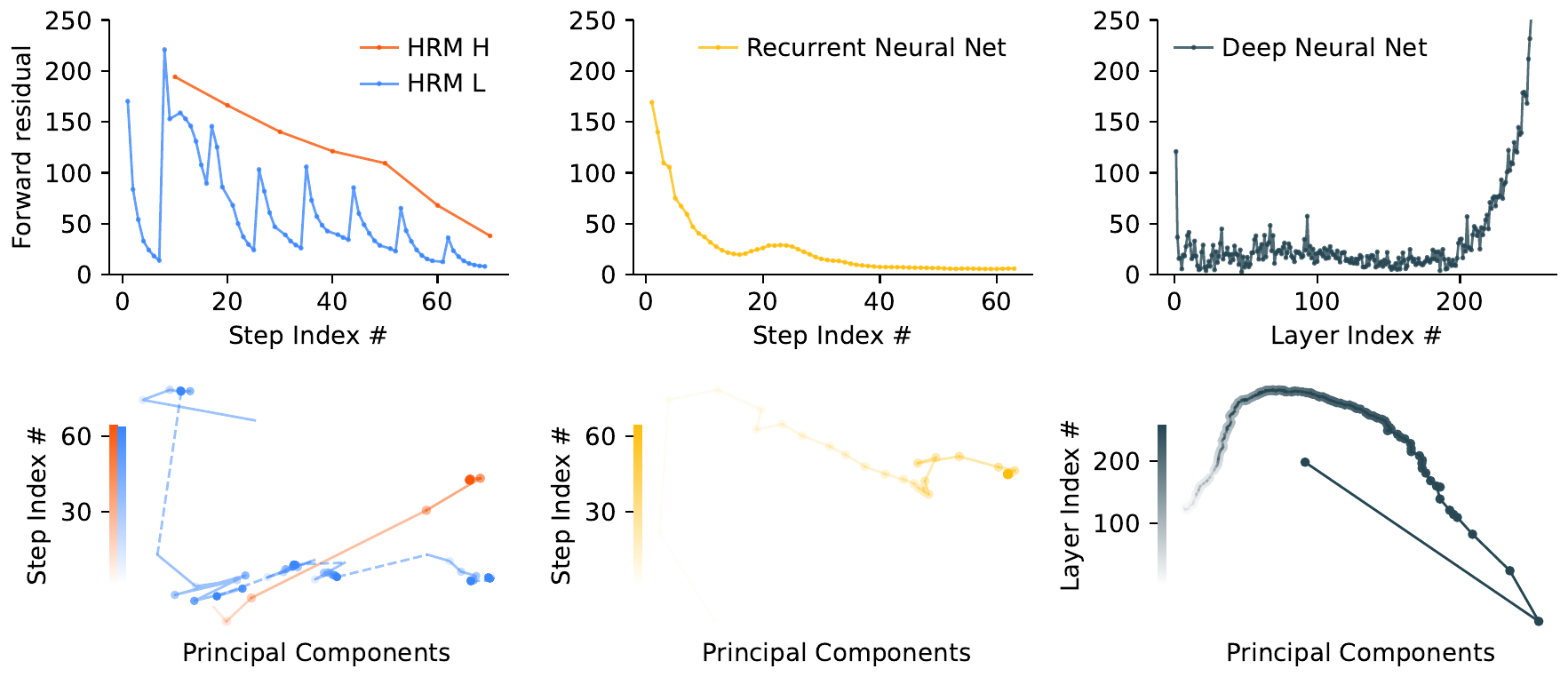
論文は同サイズの recurrent Transformer に対して任意の計算深さで HRM が優れることを示し、hierarchical convergence こそが effective depth を伸ばす本質だと主張する。この主張は後述の批判節で再検討する。
1-step gradient approximation: DEQ 由来の局所バックプロップ
Backpropagation Through Time(BPTT)は \(T\) ステップ分の hidden state を保持する必要があり、メモリが \(O(T)\) になる。HRM はこれを Deep Equilibrium Model(DEQ)(Bai ほか 2019年) と同じ枠組みで回避する。L が固定点 \(z_L^\star = f_L(z_L^\star, z_H^{k-1}, \tilde x; \theta_L)\) に収束したと理想化し、H の固定点 \(z_H^\star = \mathcal F(z_H^\star; \tilde x, \theta)\) を考えると、Implicit Function Theorem(IFT)から正確な勾配は次の式で書ける:
\[ \frac{\partial z_H^\star}{\partial \theta} = (I - J_{\mathcal F}\big|_{z_H^\star})^{-1} \frac{\partial \mathcal F}{\partial \theta}\bigg|_{z_H^\star} \tag{3}\]
ここで \(J_{\mathcal F} = \partial \mathcal F / \partial z_H\) は H 側更新のヤコビアンである。逆行列計算が高価なため、HRM は Neumann 展開 \((I - J_{\mathcal F})^{-1} = I + J_{\mathcal F} + J_{\mathcal F}^2 + \cdots\) の 1 次項のみ を採用し \((I - J_{\mathcal F})^{-1} \approx I\) と近似する。これにより勾配パスは「出力ヘッド → 最終 H 状態 → 最終 L 状態 → 入力埋め込み」の 3 ステップ局所バックプロップに縮約され、メモリは \(O(1)\) になる。論文は「短距離・時間的局所のシナプス信用割当」と生物学的に正当化し、Equilibrium Propagation や Eligibility Propagation の系譜と接続する。
この近似が成立するのは L が固定点に収束し、かつ \(I - J_{\mathcal F}\) が正則な場合に限る。HRM の実装では \(N = T = 2\) しか回さないため、\(z_H\) の residual はそもそも 0 に収束していない。次章で扱う Tiny Recursive Model(TRM)(Jolicoeur-Martineau 2025年) はこの前提崩壊を指摘し、1-step gradient を捨てて full BPTT に置き換えるだけで Sudoku 精度が 30 ポイント以上改善すると示した。HRM の理論的中核を構成する近似が、実証的には最大のボトルネックだったという結果である。
Deep supervision と Adaptive Computation Time
HRM は 1 回の forward を segment と呼び、各 segment の終端で hidden state を detach して次 segment の入力に渡す deep supervision を導入する。最大 \(M\) segments まで反復し、segment ごとに損失を取って勾配更新する。この detach により segment 間の勾配伝播は止まり、再帰的 deep supervision 全体としても 1-step approximation になっている。
加えて Daniel Kahneman の System 1 / System 2 を引いて Q-head を導入し、segment ごとに halt / continue を判定する Adaptive Computation Time(ACT)(Graves 2016年) を実装する。Q-head は最終 H 状態から行動価値を予測する:
\[ \hat Q^m = \sigma(\theta_Q^\top z_H^{mNT}) \in \mathbb R^2 \tag{4}\]
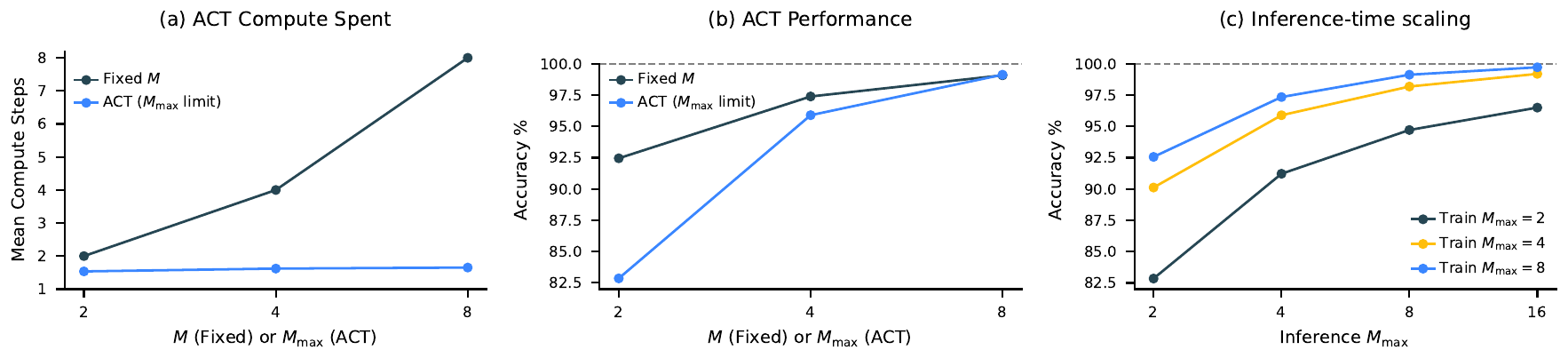
ここで \(\hat Q^m = (\hat Q^m_\text{halt}, \hat Q^m_\text{continue})\) である。halt 報酬は予測正答性 \(\mathbf 1\{\hat y^m = y\}\)、continue 報酬は 0、bootstrap 先は次 segment の最大 Q 値、という標準的 Q-learning で訓練される。replay buffer も target network も使わないが、Post-Norm + RMSNorm + AdamW の組み合わせが \(L^\infty\) 制約付き最適化に等価で、それが安定化に寄与すると論文は主張する。テスト時は \(M_{\max}\) を訓練時より大きく設定するだけで inference-time scaling が得られる。
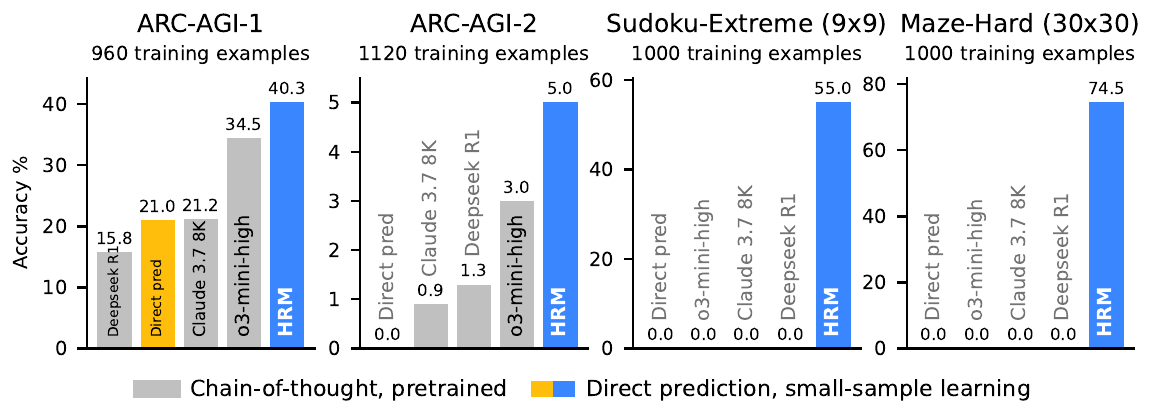
実験: 1000 サンプル・スクラッチ訓練で大規模 LLM を上回ったという主張
HRM の主実験は次の三つのベンチマークで行われ、いずれも 約 1000 訓練サンプル、pretraining なし、CoT ラベルなし、スクラッチ訓練 という設定である。
- ARC-AGI-1 / ARC-AGI-2: グリッドベースの帰納推論パズル
- Sudoku-Extreme: 平均 22 backtracks を要する難 Sudoku
- Maze-Hard 30×30: 最短経路探索(path length 110 以上のみ採用)
| Benchmark | HRM (27M) | Direct pred (同サイズ Transformer) | CoT 比較 |
|---|---|---|---|
| ARC-AGI-1 (~960) | 40.3 % | 15.8 % | o3-mini-high 34.5 %, Claude 3.7 8K 21.2 % |
| ARC-AGI-2 (1120) | 5.0 % | 0 % | Claude 3.7 0.9 %, DeepSeek-R1 1.3 %, o3-mini-high 3.0 % |
| Sudoku-Extreme (1000) | 55.0 % | 0 % | DeepSeek-R1 (DeepSeek-AI ほか 2025年) を含む全 CoT モデル 0 % |
| Maze-Hard 30×30 | 74.5 % | 0 % | 全 CoT モデル 0 % |
ARC-AGI の評価では、入力に回転・反転・色置換による augmentation を 1000 通り適用し、タスクごとに学習可能な puzzle 識別トークンを先頭に付ける。テスト時は 1000 回の augmented 推論から多数決上位 2 つを最終回答とする。この設定は ARC-AGI の “2 attempts” ルールに合わせたものだが、後述するように puzzle 識別トークンへの依存が汎化の議論で大きな論点となる。
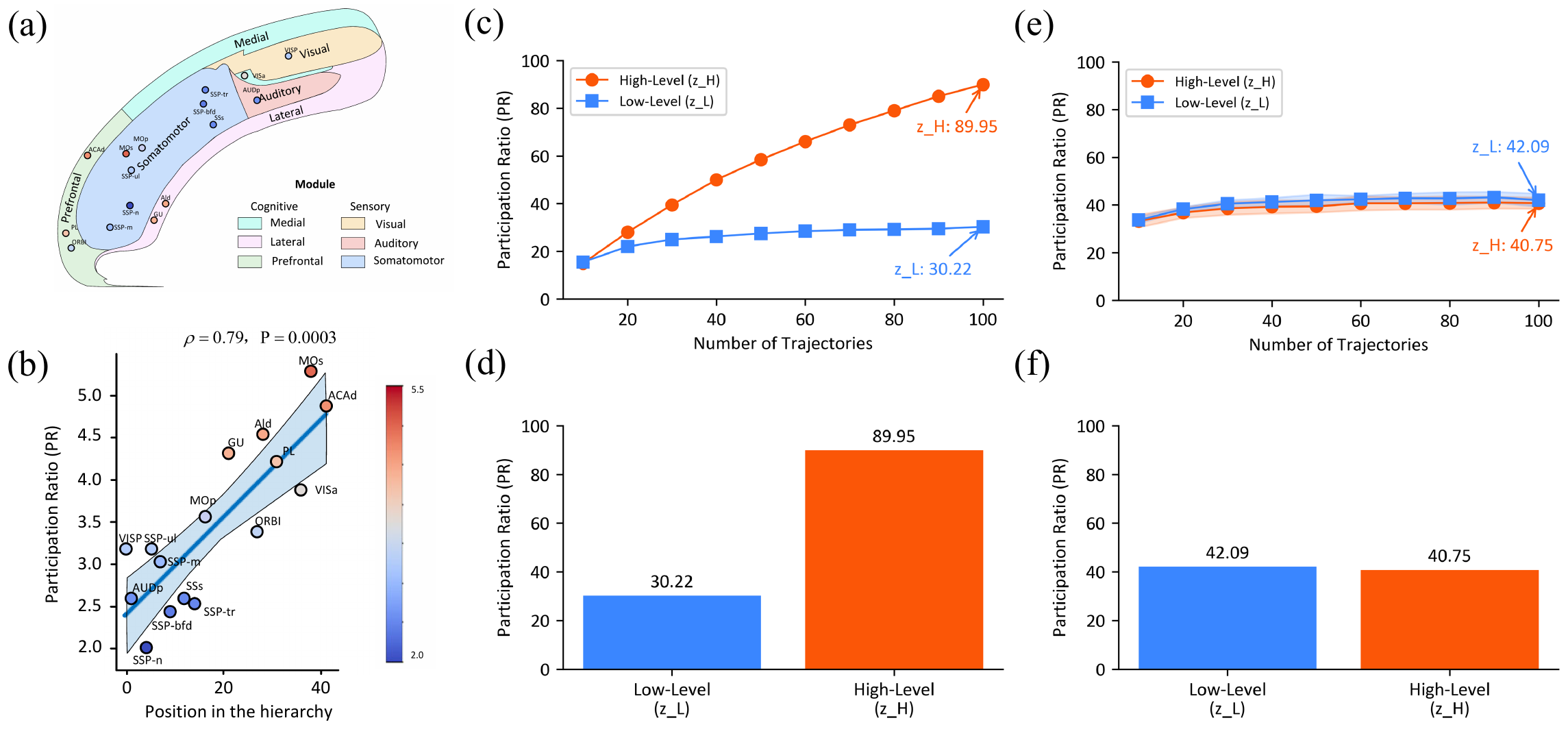
Brain Correspondence: Participation Ratio の階層性
論文の終盤章は HRM の内部表現がマウス皮質と同種の dimensionality hierarchy を示すと主張する。各モジュールの hidden state の共分散行列の固有値 \(\{\lambda_i\}\) から Participation Ratio(PR)を計算する:
\[ \text{PR} = \frac{(\sum_i \lambda_i)^2}{\sum_i \lambda_i^2} \tag{5}\]
訓練済 HRM の PR は \(z_L = 30.22\)、\(z_H = 89.95\) で、比 \(z_H / z_L \approx 2.98\) がマウス皮質階層の \(\approx 2.25\) と類似していると報告される。同じアーキテクチャを未訓練のまま測ると PR はそれぞれ 42.09 と 40.75 で階層差が消えるため、PR の階層性は 訓練を通じた emergent な性質 だと論文は結論する。一方で著者自身も、この証拠は causal ではなく correlational であり、H モジュールの dimensionality を介入的に制約する実験は訓練過程全体に交絡を与えるため評価が難しい、と注釈している。
独立検証: 主張の大半が剥がれた
HRM 公開から約 1 ヶ月後の 2025 年 8 月、ARC Prize Foundation が系統的 ablation の独立検証結果を公開した(arcprize.org/blog/hrm-analysis)。その後 Tomaso Poggio らによる perspectives 論文 (Ge ほか 2025年) と機構解析論文 (Ren と Liu 2026年) が続き、HRM の物語と実証の乖離が広く議論された。主な指摘は次の通りである。
- Semi-private set でのスコア低下: 公開評価セットで 40.3 % を出した HRM は、semi-private set で 32 % まで下がる(-9 pp)。ARC-AGI-2 は 2 % 程度に留まる。
- アーキテクチャ ablation: 同サイズの vanilla Transformer に置換しても ~5 pp しか下がらない。H/L 階層は主要因ではない。
- 本当のドライバは outer loop: deep supervision の反復 (outer-loop refinement) を 1 回 → 2 回で +13 pp、1 回 → 8 回でほぼ倍。論文中で目立たない部品が性能の大半を支えている。
- Augmentation の飽和: 主張の 1000 augmentations は不要で、300 で飽和する。
- Puzzle 識別トークン依存: 訓練時に見た
puzzle_id埋め込みが必須で、新規パズルへの汎化は構造的に不可能。評価 400 タスクだけで訓練しても 31 % pass@2 で、実態は「未知タスクへの汎化」ではなく訓練テンプレートの認識と refinement に近い。
機構解析論文 (Ren と Liu 2026年) はさらに踏み込み、HRM が fixed-point property を実際には満たしておらず、1 セルだけ不明な最易 Sudoku でも失敗するケースを示した。論文タイトルの “Are Your Reasoning Models Reasoning or Guessing?” が挑発的なのは、HRM の解き口が実態として refinement というより guessing に近いという主張の表れである。François Chollet 自身も「HRM のアーキテクチャは重要ではない。outer loop が本体」とまとめている。
位置付け: 真の novelty はレジーム証明である
HRM の技術部品はすべて先行研究に存在する。Adaptive Computation Time は Graves 2016 (Graves 2016年)、weight-tied な depth recurrence は Universal Transformer (Dehghani ほか 2019年)、IFT 経由の implicit gradient は DEQ (Bai ほか 2019年)、確率的 halting は PonderNet (Banino ほか 2021年) にそれぞれ起源があり、近年では Geiping らの recurrent depth approach (Geiping ほか 2025年) が大規模 LLM 文脈で同種のアイデアを再導入している。HRM が真に novel だったのは、これらの既存要素を統合し、CoT データも pretraining も使わずに、27M parameters・1000 サンプルで離散 reasoning ベンチに通用する ことをスクラッチで示した点である。「hierarchy が効く」「1-step gradient が効く」「脳との対応が機構の正当化になる」という装飾的主張は、TRM の ablation (Jolicoeur-Martineau 2025年) と ARC Prize Foundation の検証 (Ge ほか 2025年; Ren と Liu 2026年) によってその後すべて崩された。残った本質は 「depth recurrence 系を CoT・大規模データなしで離散 reasoning に通用させたレジーム証明」 にある。
この帰結は次章以降で繰り返し参照される。TRM は HRM の装飾を引き算して核を取り出した「引き算の研究」であり、GRAM は引き算された最小核に確率性を足し戻して generative model 化した「足し算の研究」である。HRM をこの三世代の出発点として読むときは、論文の修辞を一旦保留し、何が実証的に load-bearing で何が装飾かを TRM の ablation 表(次章で扱う)と突き合わせる読み方が最も生産的になる。