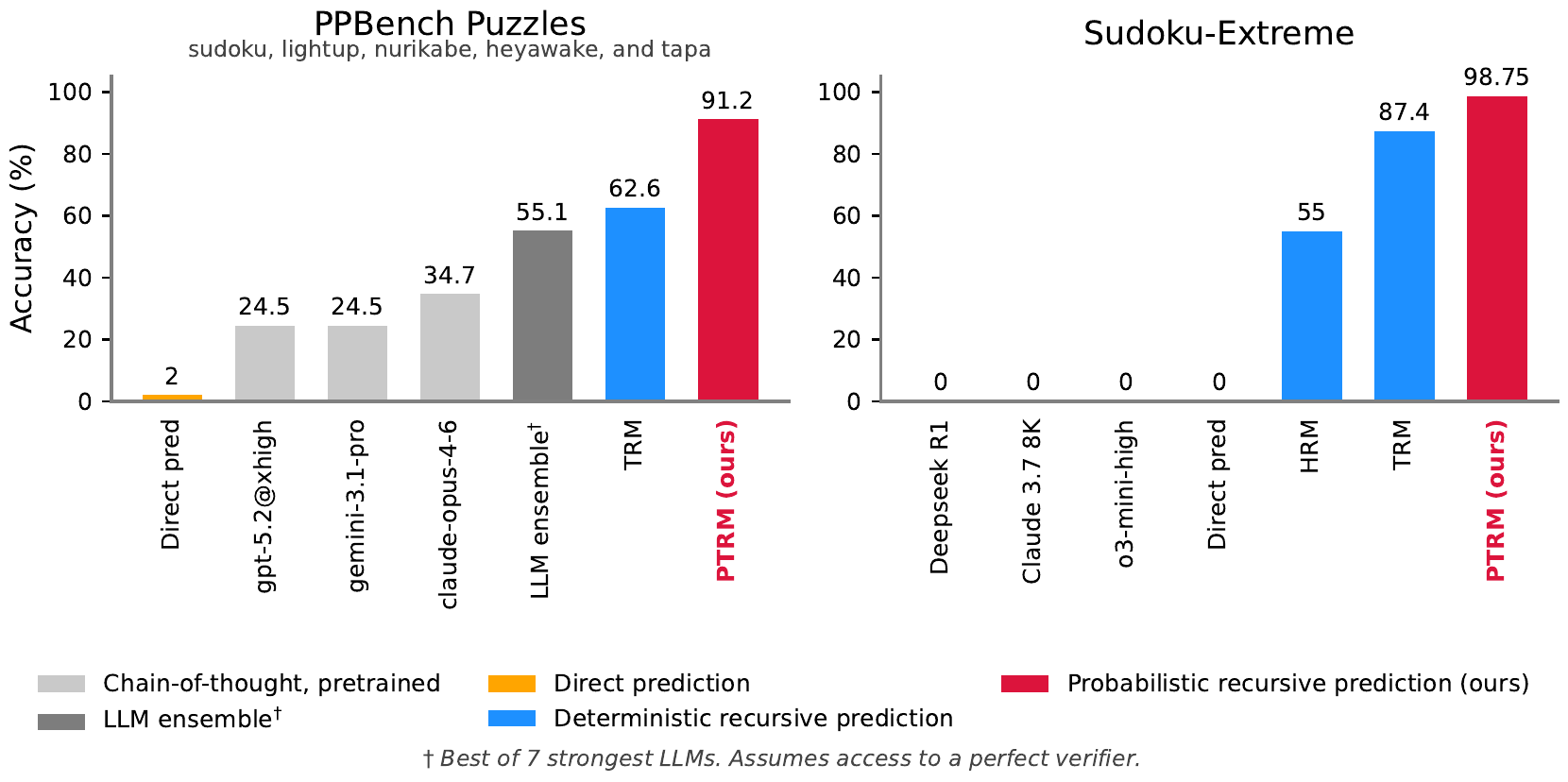
PTRM
Probabilistic Tiny Recursive Model(PTRM)は、Mila Québec AI Institute / École de Technologie Supérieure(ETS)の Sghaier と Parviz、および Tiny Recursive Model(TRM)原著者の Jolicoeur-Martineau が 2026 年 5 月に公開した test-time scaling フレームワークである (Sghaier ほか 2026年)。一行で要約すれば、TRM の決定論的再帰が陥る bad latent basin からの脱出を、各 deep recursion step で latent にスケール \(\sigma\) の Gaussian noise(ガウシアンノイズ)を加えた \(K\) 並列軌道として実現し、TRM が adaptive halting 用に既に学習済の Q head を verifier として再利用 することで最良軌道を選ぶ。再学習不要・タスク固有 augmentation 不要で、TRM の Sudoku-Extreme 87.4 % → 98.75 %、Pencil Puzzle Bench(PPBench)62.6 % → 91.2 % まで引き上げる。同時期に ICLR 2026 Workshop on Latent and Implicit Thinking で公開された Efstathiou & Balwani の機構解析論文 (Efstathiou と Balwani 2026年) が独立に同じ attractor 仮説に到達しており、本章ではこの 2 論文を一組として扱う。ARC Prize 2025 Paper Award を受賞した TRM の test-time 拡張として、本書では「学習済モデルをそのまま活かす第 3 の戦略」に位置付ける。
TRM の失敗モード: bad basin への trap
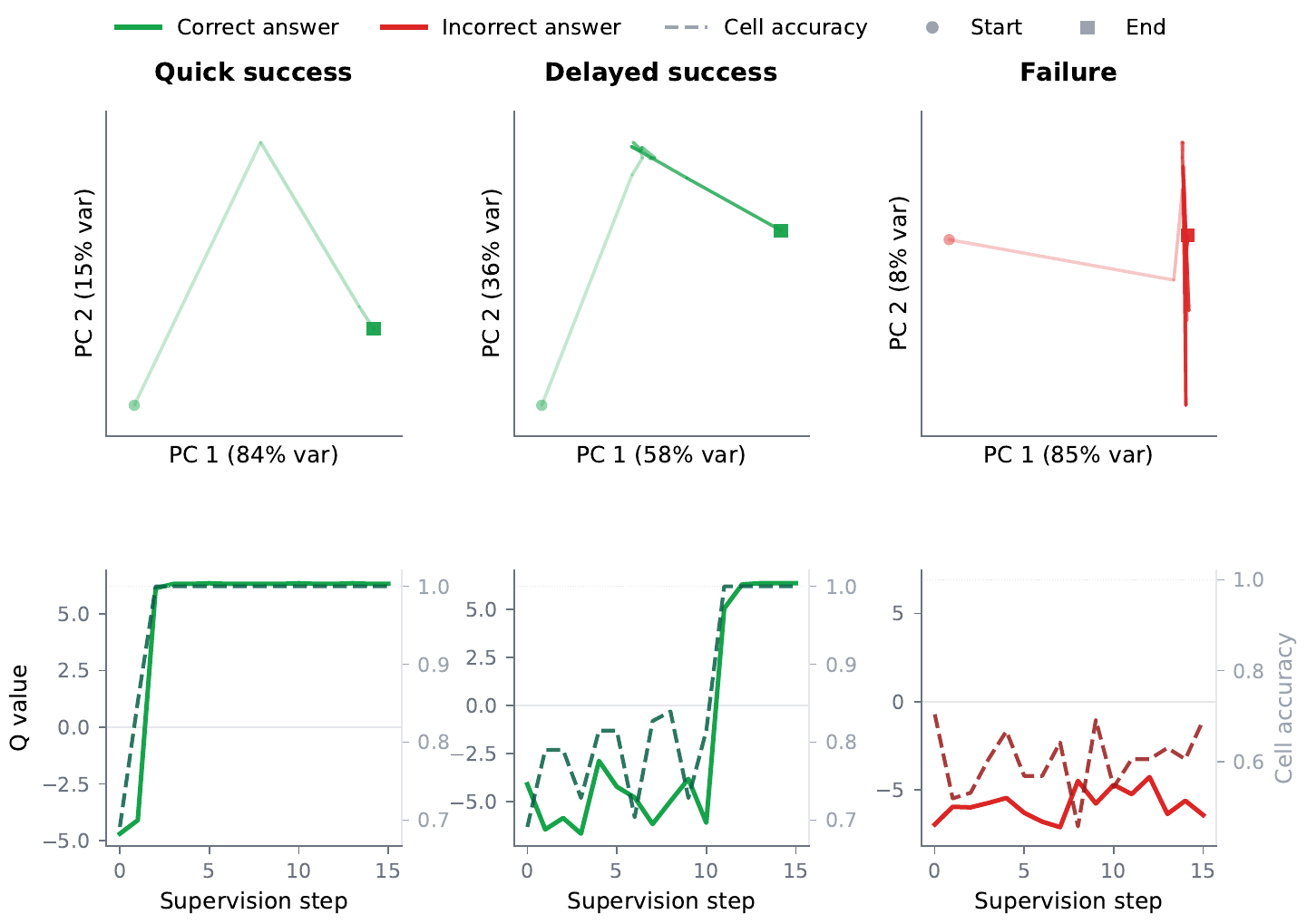
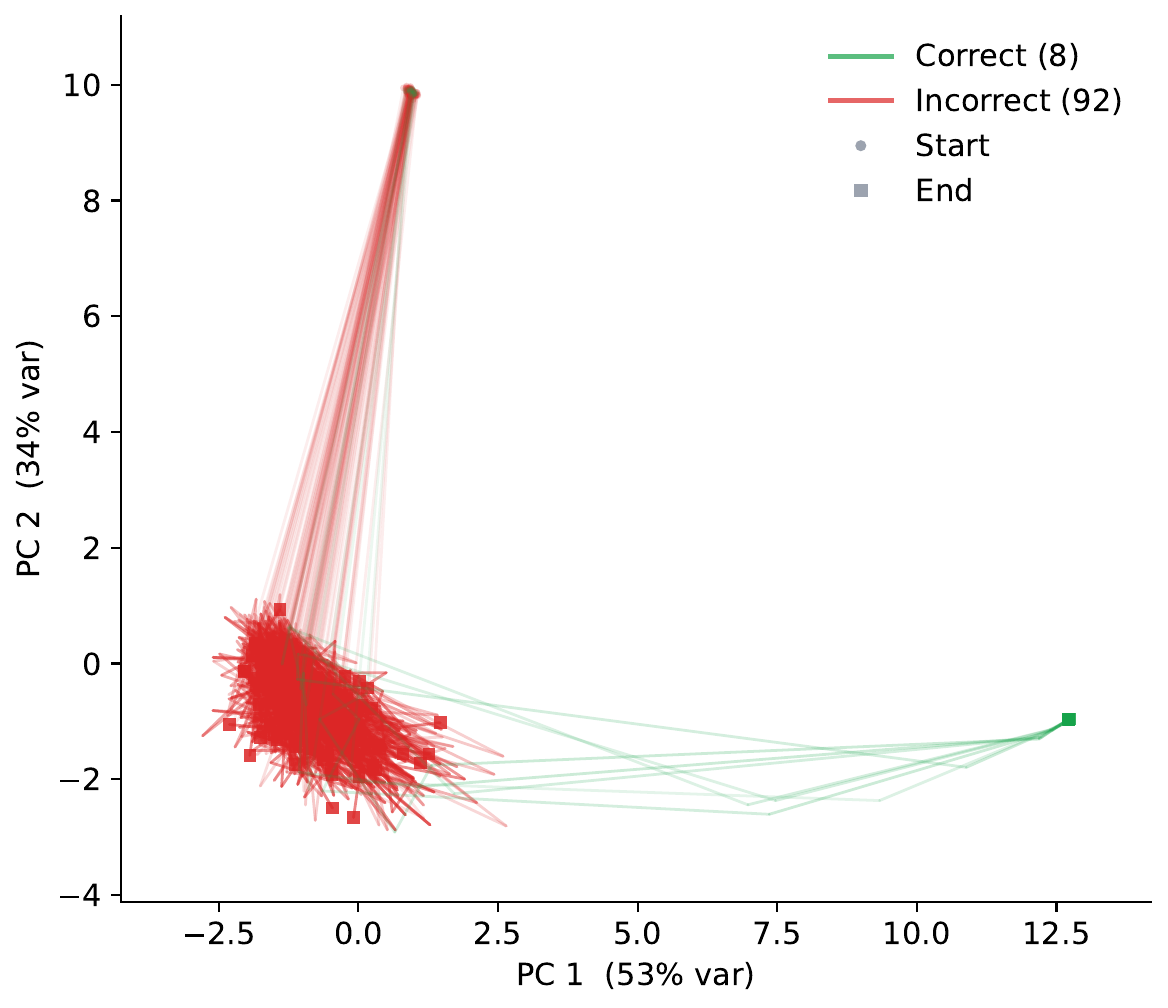
PTRM 論文 Section 3 の機構解析が出発点である。著者らは PPBench 上で 100 puzzle ごとに TRM の latent 軌道を supervision step 単位で記録し、主成分分析(Principal Component Analysis, PCA)で principal plane に射影した。その結果、軌道が 3 つの定性的なモードに分かれることが明らかになった。
- Quick success: 数 step で収束領域に遷移し、そこで停滞する。Q 値(halting logit)と cell accuracy(予測のうち正解セルの割合)が同期して上昇し、同じ supervision step で saturate する。
- Delayed success: bounded region で何 step も振動したのち、ある step で急に別領域に escape して収束する。escape 瞬間に Q 値と cell accuracy が同時にスパイクする。
- Failure: bounded region で振動し続け、Q 値は最後まで負(sigmoid 後 0.5 未満)で、cell accuracy は 100 % に届かない。
著者らはこの観察から good basin / bad basin という語彙を導入する。良基底は cell accuracy が高いまま留まる latent 領域、悪基底はそうでない領域である。重要な発見は、failure と delayed success は前半まったく同じ挙動を示す点にある。両者は同じ bad basin に捕まっているが、後者だけが何らかの確率的揺らぎで basin を抜け出し正解に到達する。「失敗は能力の欠如ではなく escape 機構の欠如である」というのが PTRM の診断である。
Q head は trajectory quality を追跡する
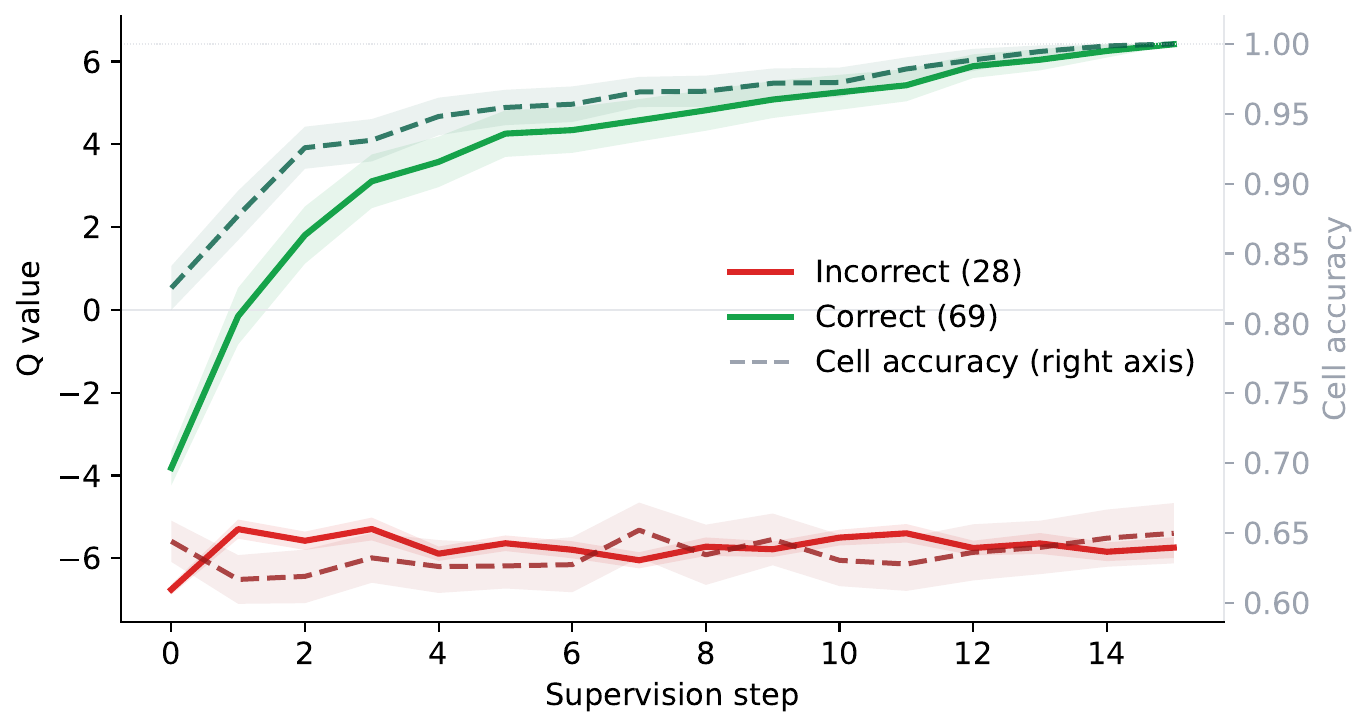
PTRM 設計の鍵となる第二の発見が Section 3.2 にある。TRM の Q head は本来 Adaptive Computation Time(ACT)(Graves 2016年) の halting 信号として、「予測が正解と一致したか」の二値交差エントロピーで訓練されたものである。著者らが 100 PPBench validation puzzle で集計したところ、この Q head の logit \(\hat q\) は supervision step ごとの cell accuracy をほぼ完全に追跡していた。
収束時点では正解軌道で \(\hat q \approx +6\)(sigmoid 約 1)、不正解軌道で \(\hat q \approx -6\)(sigmoid 約 0)と、2 群が鋭く分離する。「TRM は ACT 用の補助損失として、事実上の 学習済 verifier を内部に持っていた」というのが PTRM の核となる解釈である。後段の test-time procedure では、この Q head を別途学習することなくそのまま rollout 選択器として再利用する。
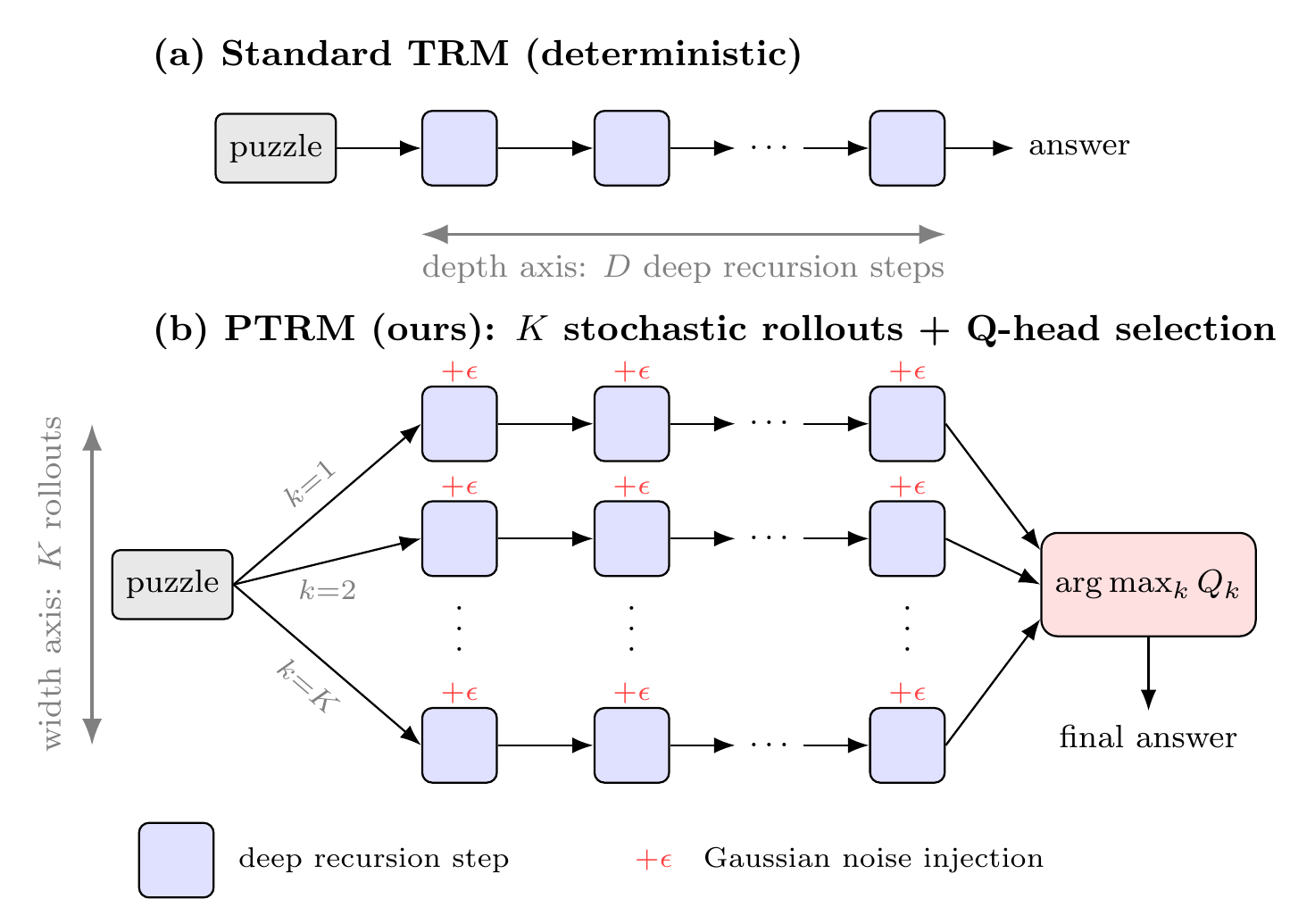
PTRM の手法
PTRM は前節の 2 発見を 1 つの inference-time procedure に組み立てる。各 deep recursion step で latent \(z\) にスケール \(\sigma\) の Gaussian noise を加える。これを \(K\) 本並列に走らせ、各 rollout の終端 Q 値で最良 trajectory を選ぶ。TRM のアーキテクチャは無変更で、checkpoint もそのまま使う。学習済 model に対する test-time のみの介入である。
アルゴリズム
論文 Algorithm 1 を再掲する。rec は TRM の deep recursion step(latent recursion 1 回分)、\(f_O\) は出力ヘッド、\(f_Q\) は Q head。\(D\) は supervision step 数。
def ptrm_inference(x, K, D, sigma, z0, y0):
candidates = []
for k in range(K): # K parallel rollouts
z, y = z0, y0
for t in range(D): # D deep recursion steps
eps = sigma * randn_like(z) # Gaussian noise
z = z + eps
z, y = rec(x, z, y) # standard TRM step
y_hat = argmax(f_O(y))
q_hat = f_Q(y)
candidates.append((y_hat, q_hat))
k_star = argmax([q for _, q in candidates])
return candidates[k_star][0]注意すべきは、ノイズ注入が rollout の最初 1 回だけでなく毎 supervision step に入る 点である。後述するように、これは GRAM (Baek ほか 2026年) が報告した「初期 \(z\) のみへのノイズは効かない」という ablation 結果と整合的で、軌道の各 step で独立な確率性が必要であることを示している。
Bad basin escape の実証
Section 4.1 では、図 2 の failure puzzle 1 個を取り出して \(K=100\) の rollout を試している。100 本のうち 92 本は同じ bad basin に留まり、8 本だけが distinct region に escape して正解に到達した。\(K=5\) では escape 0 本、\(K=25\) では 1 本、\(K=100\) で 8 本と、escape 回数は \(K\) に対して単調に増える。Gaussian noise が per-rollout の escape 確率 を生み出していることが定量的に確認された。
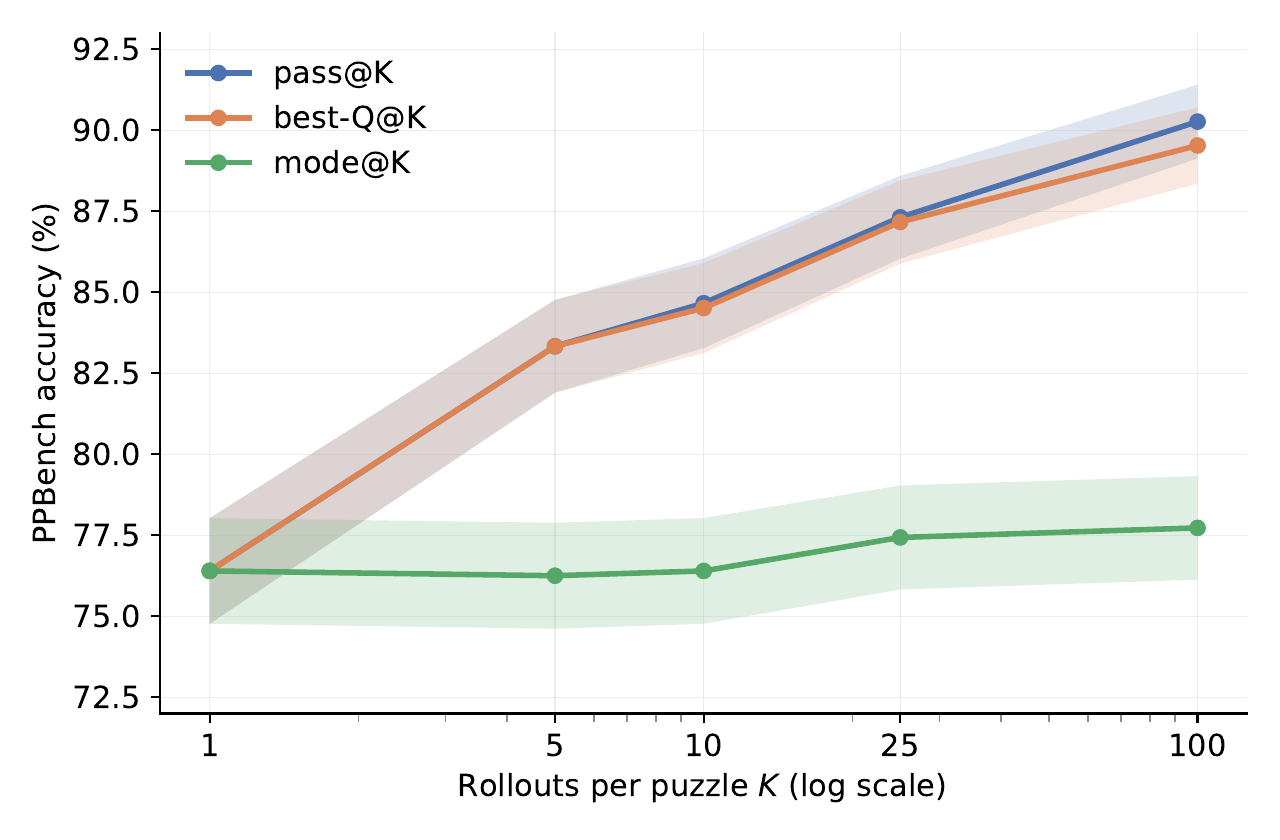
Width scaling と Q head の verifier 性能
Section 4.2 は PTRM の最も実用的な貢献を整理する。著者らは 3 つの集約指標を区別する。
- pass@\(K\): \(K\) rollout のいずれか 1 本が正解する確率(oracle 上界)
- best-Q@\(K\): 最高 Q 値の rollout が正解する確率(実用指標)
- mode@\(K\): 最頻答えが正解する確率(voting)
PPBench validation 上で \(K=1 \to 100\) にすると、pass@\(K\) と best-Q@\(K\) はともに 76.4 % → 89.5 % へ上昇し、両者の gap は 1 pp 未満で推移した。Q head が verifier としてほぼ oracle 並に機能していることを意味する。一方 mode@\(K\) は +1.3 pp しか上がらない。width scaling の gain は voting ではなく Q head selection から来ている。
深さ軸との比較も Section 4.2 にある。\(K=1\) で depth \(D=16 \to 48\) に増やすと PPBench validation は 76.4 % → 79.5 %(+3.1 pp)にしか上がらない。一方 \(D=16\) 固定で \(K=1 \to 100\) にすると +13 pp 上がる。「rollout は独立で並列化可能、深さは sequential」という計算特性も合わせれば、width が主要な test-time scaling 軸となる。
主結果
論文 Section 5 は 3 種の benchmark で PTRM を評価する。共通の方針は「TRM 公開 checkpoint をそのまま使い、\((K, D, \sigma)\) の inference 設定のみ変更」である。
PPBench
PPBench (Waugh 2026年) は 62,231 puzzle / 94 puzzle type の constraint satisfaction puzzle 集で、PTRM の主実験 benchmark。著者らは 6 種(sudoku, lightup, nurikabe, shakashaka, heyawake, tapa)に絞り、Waugh らが定義した 300 puzzle の golden set で per-puzzle 精度を測る。決定論的 TRM が 100 % 解く shakashaka を除く 5 種で集計する。
主結果は PTRM (\(K=100, D=48, \sigma=0.2\)) が aggregate 91.2 %、内訳は sudoku 97.8 %、lightup 100 %、nurikabe 88.9 %、heyawake 85.7 %、tapa 80.0 %。決定論的 TRM (\(K=1, D=16\)) の 62.6 % から +28.6 pp。深さだけ伸ばした TRM (\(K=1, D=48\)) は 66.0 % で +3.4 pp に留まることから、gain の大半が width 由来であることが裏付けられる。
Frontier LLM との比較も同じ golden set で取られている。direct 戦略では gemini-3.1-pro 24.5 %、gpt-5.2@xhigh 24.5 %、claude-opus-4-6@thinking 34.7 %。多段 agentic(perfect verifier 仮定)を許した上位 7 LLM の アンサンブル でも 55.1 %。PTRM はこれを 91.2 % で 36 pp 上回り、コストは puzzle 1 個あたり $0.001 で LLM ensemble の $2.66 と比べて 3 桁安い。
Sudoku-Extreme, Maze-Hard, ARC-AGI-2
Section 5.3 では TRM 原論文と同じ 3 benchmark で PTRM を評価する。Sudoku-Extreme で TRM 87.28 % → PTRM 98.75 %(\(K=100, D=64, \sigma=0.3\)、state-of-the-art)、Maze-Hard で 83.80 % → 86.73 %(\(K=100, D=16, \sigma=1.0\))、ARC-AGI-2 で pass@1 が 7.36 % → 8.47 %、pass@100 が 14.31 % → 15.97 %(\(K=25, D=16, \sigma=0.2\)、pass@2 は 9.72 % で同等)。
Sudoku-Extreme は決定論的 TRM の弱点だった basin trap を最も劇的に解消した benchmark で、PTRM が state-of-the-art に到達した。一方 ARC-AGI-2 では Grok-4 系の大規模 LLM には届かず、Maze-Hard では best-Q@\(K\) が pass@\(K\) から大きく離れる(後述 ablation を参照)。「Q head の verifier 性能が天井になる task」が存在することが、論文自身の指摘する PTRM の限界の一つである。
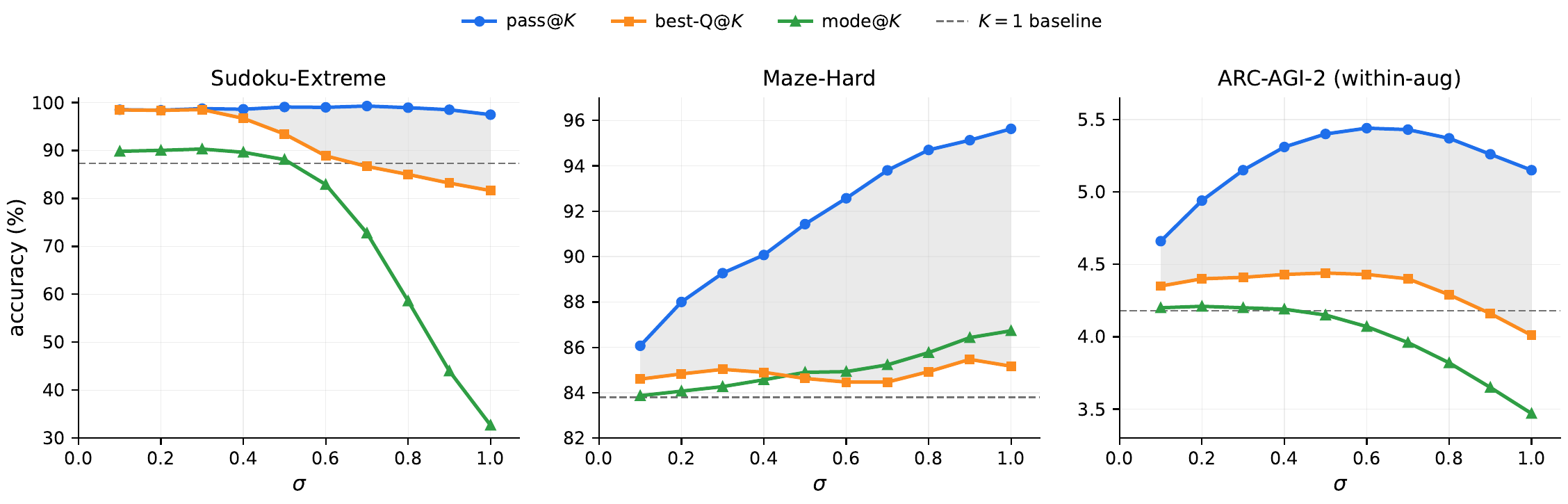
Noise ablation
Section 5.4 と Appendix B は σ の sweep を 3 benchmark で取る。最適 σ は task 依存である。
- Sudoku-Extreme: σ ≈ 0.1 で天井に到達し、σ = 1.0 までほぼフラット。best-Q@\(K\) は 98.5 % で pass@\(K\) の 99.3 % と 1 pp 以内。
- Maze-Hard: σ ≈ 1.0 で pass@\(K\) が 83.8 % → 約 96 %。best-Q@\(K\) は 86 % 付近に留まり、両者の gap が約 10 pp 開く。verifier headroom が大きく残る。
- ARC-AGI-2: σ ≈ 0.6 でピーク。best-Q@\(K\) と pass@\(K\) の gap も無視できない大きさ。
Maze-Hard と ARC-AGI-2 で gap が広いことは、PTRM の制約が「探索能力」ではなく「verifier 能力」にあることを示す。より強力な verifier を学習・接続できれば、現在の Q head で取り損ねている rollout も拾える という方向が、論文 Future Work の中心である。
Appendix C で著者らは Q head の勾配を使って latent を high-Q 領域に誘導する Langevin dynamics、\(z \leftarrow z - \eta \nabla_z E(z) + \sqrt{2\eta}\, \xi\)(\(E(z) = -\log \mathrm{sigmoid}(f_Q(z))\)、\(\xi \sim \mathcal{N}(0, I)\))を試している。PCA 上では \(\nabla_z f_Q\) が確かに good basin 方向を指していたため有望に見えたが、勾配項をゼロにした noise-only ablation と精度が一致した。gain はすべてノイズ項由来で、勾配誘導は何も加えていなかった。著者らはこの結果から、Langevin 版を捨てて simpler な PTRM に収斂した。学習済モデルに対する test-time gradient guidance は、少なくとも TRM の Q head 経由では機能しなかった、という方法論的な発見である。
関連研究と本書での位置付け
PTRM の Section 6 と本書の議論軸を交差させて 5 つの観点で整理する。
GRAM との関係: train-time vs test-time 確率化
GRAM (Baek ほか 2026年) は同じ「決定論的 RRM の単一解問題」を 学習段階 で解いた。高レベル latent に学習可能な Gaussian guidance を残差として加え、amortized variational inference で訓練する。一方 PTRM は学習済 TRM checkpoint をそのまま使い、test-time のみ介入する。PTRM 論文は GRAM が初期 \(z\) にだけノイズを足す ablation で負の結果を報告した事実を引用し、「各 supervision step ごとにノイズを入れる」設計の必要性を主張する。GRAM は再学習を要し、PTRM は再学習不要。両者は test-time scaling の二系統として相補的に並ぶ。
Efstathiou & Balwani: 独立に到達した attractor 仮説
Efstathiou & Balwani (Efstathiou と Balwani 2026年) は同じ ICLR 2026 LIT workshop で同時期に発表された機構解析論文で、PTRM と独立に同じ診断にたどり着いている。著者らは sparse autoencoder で TRM の latent dynamics を分析し、(i) モデルは早期に仮説を形成し、その後 feature activation は周期パターンに stabilize する(incremental refinement ではない)、(ii) 軌道は初期化に応じて早期に分岐し局所最小に陥る、(iii) 失敗 run は高損失の安定 attractor で plateau する、と報告した。結論は「再帰 reasoning は段階的洗練ではなく attractor landscape 上の adaptive search である」。
PTRM が production-ready な解(test-time stochastic intervention)を提供したのに対し、Efstathiou & Balwani は理論的説明(attractor 仮説)を提供している。同じ問題に同じ向きの解を独立に到達した 2 論文として並読する ことで、TRM 系列の真の dynamics 像が立体化する。Ren & Liu (Ren と Liu 2026年) の HRM 機構解析(本書 HRM 章)の延長線上にもこれは位置付けられる。
Hakimi RSM: 訓練効率という別軸
Hakimi の Recursive Stem Model(RSM)(Hakimi 2026年) は TRM 訓練を 20 倍加速する手法で、hidden state detach、終端のみの損失、stochastic depth による訓練効率改善を狙う。PTRM が「学習済 TRM の inference 時探索性を上げる」のに対し、RSM は「TRM の訓練時計算量を下げる」。TRM 後継の二方向として並置できる。
Deep Thinking 系譜
「学習済再帰モデルを test-time に深く回す」発想自体には先史がある。Schwarzschild ら (Schwarzschild ほか 2021年) の「easy から hard へ汎化する recurrent network」、Bansal ら (Bansal ほか 2022年) の recall + progressive training、Bear ら (Bear ほか 2024年) の Lipschitz 制約による安定化が代表である。特に Bear らは「unique fixed point への収束を保証する」方向に進んだが、これは PTRM や Efstathiou & Balwani の「収束しすぎることが bad basin trap を生む」観察と直接対立する視座であり、Deep Thinking 系譜内部の方向性の分岐として読める。
同時期の test-time stochastic exploration
You ら (You ほか 2025年) は 2025 年 10 月に Monte Carlo Dropout + Additive Gaussian Noise + Latent Reward Model(LRM)の組み合わせで latent reasoning model の parallel test-time scaling を試している。PTRM の貢献は、TRM の Q head を verifier として再利用することで LRM を別途学習する必要を消した 点にある。Wang ら (Wang ほか 2026年) の Gaussian Thought Sampler(GTS)は逆方向で、noise distribution を policy optimization で学習することで sampler を高度化する。PTRM (training-free) と GTS (learned) は test-time noise injection の training-free / learned 軸として対比できる。
機構解釈の系譜では Blayney ら (Blayney ほか 2026年) が looped language model の各 iteration が個別の fixed point に収束することを probe で確認しており、PTRM の trajectory mode 分析の言語モデル版として並行する。Bae ら (Bae ほか 2025年) の Mixture of Recursions(MoR)も recursive depth 制御の隣接系として位置付く。
限界と本書での貢献
PTRM 論文 Section 7 / Conclusion が認める限界は 3 つ。第一に、主に格子型 puzzle のみで検証されており、ARC-AGI-2 と Heyawake では gain が小さい。第二に、Q head の verification 能力が天井で、Maze-Hard では best-Q@\(K\) と pass@\(K\) の gap が大きく残る。第三に、より強力な verifier の開発は future work として残されている。
本書の文脈での PTRM の貢献は次の 3 点に整理できる。
第一に、「TRM の決定論的限界」を機構レベルで診断した こと。PCA 上の 3 trajectory mode と bad / good basin の語彙は、TRM 系列の振る舞いを語る共通言語になる。Efstathiou & Balwani の attractor 仮説と合わせて、HRM/TRM のような小規模 recursive model の dynamics 解釈は新しい段階に入った。
第二に、width scaling という test-time compute 軸を確立した こと。深さは sequential で並列化が利かず、ある point から overfitting コストが効いてくる(TRM の Table 4 が示した「深いほど良いは成立しない」と整合的)。width はその性質を持たず、rollout 数を増やすだけで線形に gain が出る。「test-time の計算を何に投資するか」という設計選択の 1 つの解として確立された。
第三に、学習済 Q head が verifier として再利用できる という発見は、recursive reasoning model 全般に再利用可能な観察である。adaptive halting 用の補助損失で訓練した head が、実は trajectory selector としても機能する。今後の RRM 設計で halting 信号を「verifier として使う」前提を組み込むと、test-time scaling の効率を上げやすい。
本書では TRM の「引き算」(HRM 物語を ablation で剥がす)の延長として、PTRM は 「学習済 TRM をそのまま test-time で活かす」最小介入 を提示する。続く GRAM(学習段階で確率項を導入する「足し算」)、LDT(lattice projection で sound 化)と並べると、TRM core に対する介入規模が段階的に大きくなる 3 系統として整理できる。PTRM はそのうちの最も軽い介入で、checkpoint そのままで test-time procedure だけを変える設計が、後続の重い変更と比べて何を得て何を失うのかを最初に提示する位置に立っている。