flowchart LR
A1["<b>HRM 主張 1</b><br/>Fixed-point 近似による<br/>1-step gradient"] --> B1["TRM: full BPTT に置換<br/>+30.9 pp"]
A2["<b>HRM 主張 2</b><br/>ACT/Q-head<br/>(2 forward passes)"] --> B2["TRM: continue loss 削除<br/>1 forward, ほぼ同等"]
A3["<b>HRM 主張 3</b><br/>階層性 (f_L/f_H 分離)<br/>+ 脳との対応"] --> B3["TRM: 単一ニューラルネットに統合<br/>+5.0 pp"]
B1 --> C["<b>結論</b><br/>HRM 物語の核は<br/>性能の説明にならない"]
B2 --> C
B3 --> C
TRM
Tiny Recursive Model(TRM)は、Samsung SAIL Montréal の Alexia Jolicoeur-Martineau が 2025 年 10 月に単著で公開した recursive reasoning model である (Jolicoeur-Martineau 2025年)。Hierarchical Reasoning Model(HRM)が 2025 年 6 月に提示した「脳の階層性 + Deep Equilibrium Model(DEQ)由来の 1-step gradient + Adaptive Computation Time(ACT)」という三本柱の物語を、ablation で順次否定しつつ HRM の性能を上回ることを示した点で、本書が扱う三世代のうち最も鋭い「引き算の研究」である。2 層・約 7M parameters の単一ニューラルネットだけで Sudoku-Extreme 87.4 %、ARC-AGI-1 公開評価 44.6 %、ARC-AGI-2 公開評価 7.8 % を達成し、ARC Prize 2025 Paper Award 1 位を受賞した。GitHub には公式実装が公開されている。
本章は、論文が掲げる「Less is more」の含意を、(1) HRM 物語への critique、(2) TRM の構成、(3) 主結果、(4) ablation、(5) コミュニティ追試と批判、の順で整理する。HRM 側の主張と数値は本書の HRM 章に詳しいので、対比したい読者はそちらと併読してほしい。
HRM 物語への 3 つの critique
論文は HRM の主要構成要素を 3 点で問題視している。これらは TRM のアーキテクチャ決定を直接動機付けるとともに、後段の ablation で実証的に検証される。
Fixed-point theorem の不適用
HRM は 6 回の関数評価のうち最後の 2 回だけで勾配を流す。これは Implicit Function Theorem(IFT)と 1-step gradient approximation (Bai ほか 2019年) による正当化で、「再帰が固定点 \(z^* = f(z^*)\) に収束しているなら、平衡点で 1 ステップだけ back-propagate すれば十分」という DEQ の議論に乗っている。
しかし TRM 論文は、HRM の実際のセットアップではこの前提が成立しないと指摘する。
- HRM の全実験で \(n=2, T=2\) が使われ、内ループの \(f_L\) 評価は計 4 回、\(f_H\) 評価は 1 回にすぎない
- HRM 論文 Figure 3 は \(n=7, T=7\) の設定で forward residual が時間とともに減衰する様子を示しているが、それでも \(z_H\) の residual は明確に 0 から離れたまま推移する
- 実験設定の \(n=2, T=2\) では、\(z_L\) が「1 回の \(f_L\) 評価で固定点に到達した」と仮定して 1-step gradient を適用するが、収束には程遠い
論文は、これらの観察から「IFT を持ち出す動機はあるが、定理が要求する条件は実際には満たされていない」と結論する。後述するように、この理論的中核を捨てるだけで Sudoku-Extreme で +30.9 pp の性能改善が得られる、というのが TRM の最大の発見である。
ACT/Q-head の非効率
HRM は Q-learning で halt/continue 判定を学習し、ACT (Graves 2016年; Banino ほか 2021年) と呼ぶ。halting loss と continue loss から成るが、論文中では言及されないものの公式実装上、continue loss は 追加の forward pass を要求する。すなわち最適化ステップごとに TRM の HRM 部品 forward が 2 回回ることになり、見かけ上はサンプル効率が良くとも計算コストは事実上倍増する。
TRM はこの continue loss を捨て、「現在の予測が正解と一致したか」だけを Binary Cross Entropy で学習する halting head に簡素化する。これにより forward は 1 回に戻り、Sudoku-Extreme で 86.1 → 87.4 % とむしろわずかに改善する。
生物学的解釈の overclaim
HRM の slow \(f_H\) / fast \(f_L\) 二重再帰の解釈は、脳の異なる時間周波数階層と類比される。論文 4 章ではマウス皮質の Participation Ratio 比較まで持ち出されている。TRM 論文はこれを「人工ニューラルネットワークから遠く離れた説明で、何が実際に効いているのかをむしろ不透明にする」と批判する。HRM 論文に系統的な ablation 表が無いことも併せ、論文の構成要素のどれが load-bearing でどれが装飾かを切り分ける作業が必要だ、というのが TRM の問題意識である。
TRM のアーキテクチャ
論文は Algorithm 2(本節末尾の callout に再掲)に全実装を要約する。HRM との対比でいえば、(i) 4 部品 \(\{f_I, f_L, f_H, f_O\}\) を 2 層 Transformer 1 本に統合、(ii) \(z_L, z_H\) という階層的な 2 変数を「現在の解 \(y\)」「潜在 reasoning 特徴 \(z\)」という意味付きの 2 変数に再解釈、(iii) 1-step gradient ではなく内側再帰すべてに full Backpropagation Through Time(BPTT)を流す、の 3 点が本質的変更である。
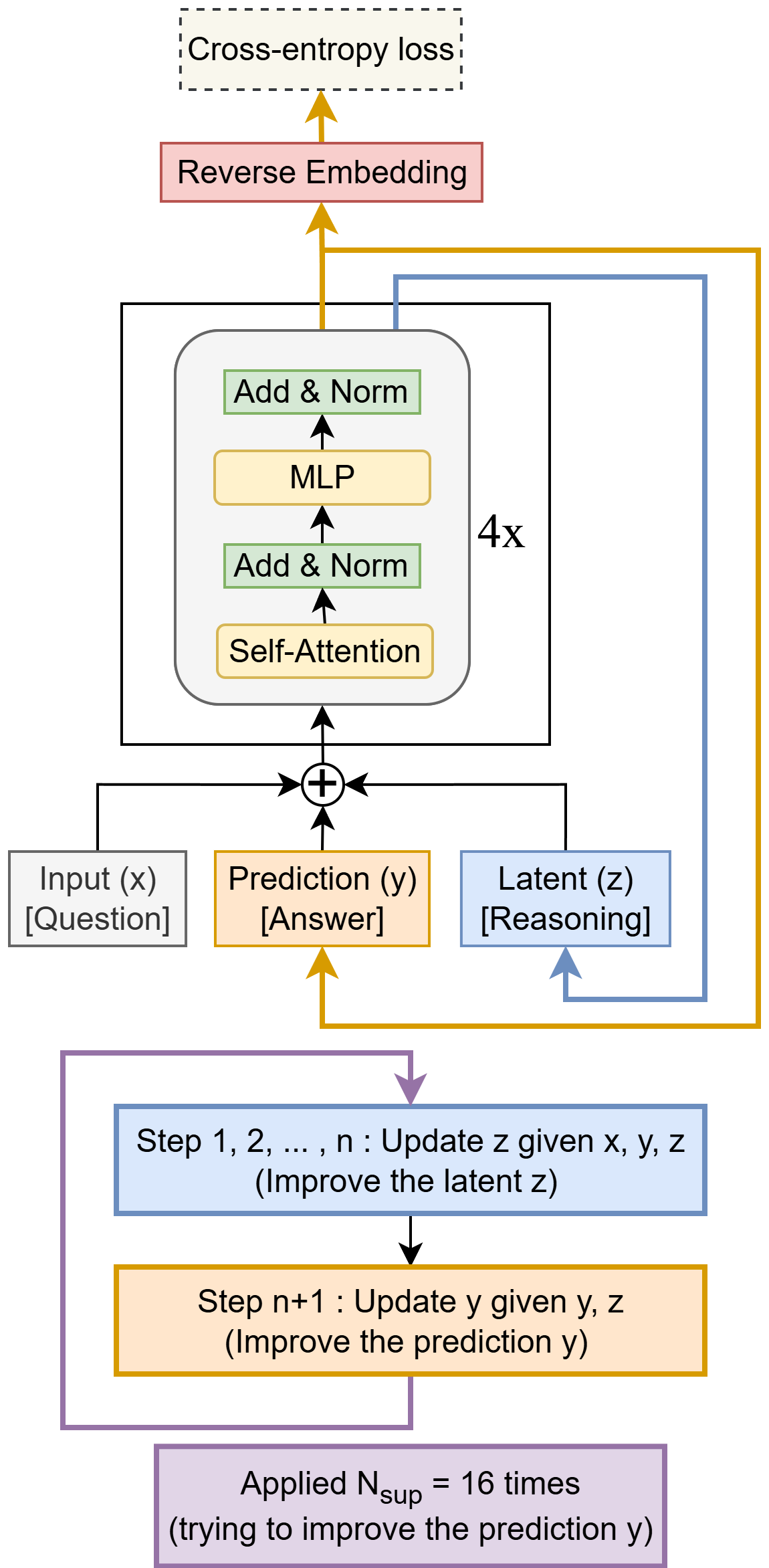
状態と再帰
3 変数を保持する。
- \(x\): 埋め込まれた入力問題(Sudoku なら 9×9 グリッド、ARC なら最大 30×30)
- \(y\): 現在の予測解。出力ヘッドと argmax で離散トークンに復号される
- \(z\): 潜在 reasoning 特徴。\(y\) に直接対応しない中間表現で、\(f_H\) を通すことで \(y\) に反映される
内側ループは \(n\) 回の latent reasoning と 1 回の answer refinement から成る:
\[ \begin{aligned} z &\leftarrow \text{net}(x, y, z) \quad (\text{$n$ 回繰り返し}) \\ y &\leftarrow \text{net}(y, z) \end{aligned} \]
この \(n+1\) 回の評価を 1 つの「full recursion process」と呼ぶ。外側では deep supervision として、\(T-1\) 回は no-grad で recursion を回して \((y, z)\) を改善し、最後の 1 回だけ勾配を流す:
def deep_recursion(x, y, z, n=6, T=3):
with torch.no_grad():
for j in range(T - 1):
y, z = latent_recursion(x, y, z, n)
y, z = latent_recursion(x, y, z, n) # gradients on full recursion
return (y.detach(), z.detach()), output_head(y), Q_head(y)この外側更新を N_supervision 回まで重ね、各ステップで \((y, z)\) を detach する。標準設定は \(n=6, T=3\)、最大 \(N_\text{sup} = 16\)。
効果的深さの計算
1 つの supervision step あたりの効果的深さは \(n_\text{layers} \times (n+1) \times T\) で評価される。HRM (\(n_\text{layers}=4, n=2, T=2\)) では \(4 \times 3 \times 2 = 24\)、TRM (\(n_\text{layers}=2, n=6, T=3\)) では \(2 \times 7 \times 3 = 42\) となり、TRM の方がパラメータを半減させながら効果的深さは増えている。論文 Table 4 はこの depth 軸を揃えた比較を示し、同じ depth でも TRM の方が常に HRM を上回ることを報告している。
「なぜ 2 つの変数か」への新解釈
HRM は「階層性」を理由に \(z_L, z_H\) の 2 変数を用いたが、TRM はもっと素朴な説明を与える。
- \(z_H\)(= TRM の \(y\))は実際には「現在の解」そのものであり、出力ヘッドと argmax で復号できる
- \(z_L\)(= TRM の \(z\))は復号しても意味を持たない潜在特徴で、\(f_H\) を通して初めて解に反映される
論文 Figure 5 では、訓練済 HRM の \(z_L\) と \(z_H\) をそれぞれ argmax 復号した Sudoku の例が示され、\(z_H\) は正解格子と一致するが \(z_L\) は無意味な数字列でしかない、という事実が視覚的に裏付けられる。この観点に立てば、「\(y\) が 1 個と \(z\) が 1 個」という構成は階層論ではなく 「現在の答えと、その答えに至るための作業領域を別々に持つ」 という単純な分業として理解できる。
論文はさらに ablation で \(z\) を \(n+1\) 個に分割する multi-scale 版(77.6 %)と、\(z\) を捨てて単一特徴に縮約する版(71.9 %)を試し、いずれも 2 変数構成(87.4 %)を下回ることを確認している。
flowchart TB
subgraph HRM["<b>HRM</b> (27M params, depth/sup=24)"]
direction LR
H1["f_I<br/>(input enc)"] --> H2["f_L<br/>4-layer TF<br/>(low-level)"]
H2 -.->|n times no-grad| H2
H2 --> H3["f_H<br/>4-layer TF<br/>(high-level)"]
H3 --> H4["f_O<br/>(output head)"]
H5["1-step gradient<br/>(only last f_L, f_H)"]
end
subgraph TRM["<b>TRM</b> (7M params, depth/sup=42)"]
direction LR
T1["embed(x)"] --> T2["net<br/>2-layer TF<br/>(shared)"]
T2 -->|update z<br/>n times| T2
T2 --> T3["net<br/>refine y"]
T3 --> T4["output head"]
T5["full BPTT<br/>(entire n+1 recursions)"]
end
ノートPseudocode の対照
TRM の擬似コードは下記の通り。HRM の擬似コードと比べると、(i) \(f_L, f_H\) が net 1 つに統一されている、(ii) with torch.no_grad() ブロックの外で full recursion が回り 1-step gradient が消えている、(iii) ACT の continue loss が消え halting head が 1 つの BCE に簡素化されている、の 3 点が見て取れる。
def latent_recursion(x, y, z, n=6):
for i in range(n):
z = net(x, y, z) # latent reasoning update
y = net(y, z) # refine output answer
return y, z
def deep_recursion(x, y, z, n=6, T=3):
with torch.no_grad():
for j in range(T - 1):
y, z = latent_recursion(x, y, z, n)
y, z = latent_recursion(x, y, z, n)
return (y.detach(), z.detach()), output_head(y), Q_head(y)
for x_input, y_true in train_dataloader:
y, z = y_init, z_init
for step in range(N_supervision):
x = input_embedding(x_input)
(y, z), y_hat, q_hat = deep_recursion(x, y, z)
loss = softmax_cross_entropy(y_hat, y_true)
loss += binary_cross_entropy(q_hat, (y_hat == y_true))
loss.backward(); opt.step(); opt.zero_grad()
if q_hat > 0:
break訓練の細部
訓練は AdamW(\(\beta_1=0.9, \beta_2=0.95\))で行い、batch size 768、hidden 512、\(N_\text{sup}=16\)。EMA は 0.999 を採用し、論文中 ablation の通り EMA なしでは 79.9 % まで落ちる(後述)。Sudoku-Extreme と Maze-Hard は 60K epoch、ARC-AGI は 100K epoch を訓練する。データ拡張は HRM と同じ条件で、Sudoku は shuffling を 1000 通り、ARC は color permutation + dihedral + translation を 1000 通り適用する。ARC では入力 puzzle ごとに専用の embedding を持ち、テスト時には 1000 augmentation のうち最頻の予測を採用する transductive な構成である点は HRM を踏襲している。
ハードウェアは Sudoku-Extreme なら L40S 1 枚で 36 時間未満、ARC-AGI で H100 4 枚 × 3 日程度と、Frontier LLM の訓練コストと比べて桁違いに軽量である。
主結果
論文の主表 2 つを再掲する。表 1 は格子状の構造化 puzzle、表 2 は ARC-AGI 公開評価セット(2 attempts)の結果である。HRM の数値は HRM 論文から引用、LLM の数値も同じ出典による。
| 手法 | パラメータ | Sudoku-Extreme | Maze-Hard |
|---|---|---|---|
| DeepSeek R1 (CoT) | 671B | 0.0 % | 0.0 % |
| Claude 3.7 8K (CoT) | ? | 0.0 % | 0.0 % |
| o3-mini-high (CoT) | ? | 0.0 % | 0.0 % |
| Direct prediction | 27M | 0.0 % | 0.0 % |
| HRM | 27M | 55.0 % | 74.5 % |
| TRM-Att | 7M | 74.7 % | 85.3 % |
| TRM-MLP | 5M / 19M | 87.4 % | 0.0 % |
| 手法 | パラメータ | ARC-AGI-1 | ARC-AGI-2 |
|---|---|---|---|
| DeepSeek R1 (DeepSeek-AI ほか 2025年) | 671B | 15.8 % | 1.3 % |
| Claude 3.7 16K | ? | 28.6 % | 0.7 % |
| o3-mini-high | ? | 34.5 % | 3.0 % |
| Gemini 2.5 Pro 32K | ? | 37.0 % | 4.9 % |
| Grok-4-thinking | 1.7T | 66.7 % | 16.0 % |
| Bespoke (Grok-4) | 1.7T | 79.6 % | 29.4 % |
| Direct prediction | 27M | 21.0 % | 0.0 % |
| HRM | 27M | 40.3 % | 5.0 % |
| TRM-Att | 7M | 44.6 % | 7.8 % |
| TRM-MLP | 19M | 29.6 % | 2.4 % |
注目すべきは、Sudoku-Extreme と Maze-Hard では DeepSeek R1 / Claude 3.7 / o3-mini-high の全 CoT 系 Frontier LLM が 0 % であるという事実である。これは Frontier LLM の reasoning が弱いという話ではなく、「1000 example で訓練された 7M のニューラルネットが解ける問題」と「数兆 token の事前学習 + RL で訓練された 671B モデルが解ける問題」は重ならないことがあるという、test-time compute 配分の性質を端的に示している。一方で ARC-AGI では Grok-4-thinking の 66.7 % / 16.0 % に TRM は到達せず、「scale + RL post-training は別軸として効く」ことも同時に確認される。
ablation の含意
論文 Table 1 が示す Sudoku-Extreme での系統的 ablation は、本書全体の論点(HRM 物語の「剥がれ」を実証する)に直接関わるため、表 3 に再掲する。baseline は TRM (\(T=3, n=6\), 2 層, EMA 0.999, MLP-Mixer 型) の 87.4 %。
| 設定 | 精度 (%) | Δ (pp) | パラメータ | NFP |
|---|---|---|---|---|
| TRM (\(T=3, n=6\), MLP, baseline) | 87.4 | - | 5M | 1 |
| w/ ACT (continue loss を戻す) | 86.1 | \(-1.3\) | 5M | 2 |
| w/ separate \(f_H, f_L\) (HRM 流) | 82.4 | \(-5.0\) | 10M | 1 |
| no EMA | 79.9 | \(-7.5\) | 5M | 1 |
| w/ 4 層, \(n=3\) | 79.5 | \(-7.9\) | 10M | 1 |
| w/ self-attention (MLP→Attn) | 74.7 | \(-12.7\) | 7M | 1 |
| w/ \(T=2, n=2\) (HRM 相当) | 73.7 | \(-13.7\) | 5M | 1 |
| w/ 1-step gradient (HRM 方式) | 56.5 | \(-30.9\) | 5M | 1 |
| HRM (比較) | 55.0 | - | 27M | 2 |
この表が示す最大の事実は、1-step gradient approximation を捨てて full BPTT に置き換えるだけで +30.9 pp の改善が得られることである。HRM の理論的中核は、HRM 自身の baseline (55.0 %)と 1-step gradient を残した TRM の数値(56.5 %)がほぼ同水準であることからも、性能の説明としては機能していない。論文は付録「Ideas that failed」で、TorchDEQ (Bai ほか 2019年) により実際に fixed-point iteration まで回した版も訓練を遅らせ汎化を悪化させたと報告しており、「固定点に到達させること」自体が本質ではないことを補強している。
他の項目も HRM 物語との対応で読むと示唆的である。階層分離 (\(f_H, f_L\) separate) は -5.0 pp で確かに不要、\(T=2, n=2\) への戻しは -13.7 pp で HRM のハイパーパラメータ選択がそもそも浅すぎたことを示し、self-attention → MLP-Mixer の差 (-12.7 pp) は「9×9 のような短く固定された context では attention の inductive bias がむしろ害になる」という、HRM の Transformer 一辺倒な選択を疑う結果である。
EMA なしで -7.5 pp 落ちる点は、TRM が overfitting ぎりぎりの領域で動いていることを示す。論文は GAN / diffusion で標準化された EMA (Bai ほか 2019年 の文脈とは独立) を持ち込み、weight decay 1.0 と組み合わせて崩壊を抑え込んでいる。
警告「深いほど良い」は成立しない
TRM の重要な経験則として、論文 Table 4 は深さを増やしすぎると性能が落ちることを示す。\(k=T=n=6\)(effective depth 156, OOM 限界近く)に到達する手前で、\(k=T=n=4\) では 84.2 % まで落ち、\(k=3, T=6\) では 85.8 %、\(k=6, T=3\) は OOM で測定不能となる。「Less is more」の含意は「scale を捨てよ」ではなく、「1000 example 規模の supervised 環境では、深さは overfitting コストの源になる」という限定的な主張である。論文 Conclusion でも「なぜ recursion がここまで効くのか、overfitting と関連すると疑っているが理論はない」と保留されている。
コミュニティ追試と批判
TRM は arXiv 公開直後から非公式実装 (lucidrains/tiny-recursive-model 等) が現れ、ARC Prize 2025 公式評価でも独立にスコアが取られている。
ARC Prize Foundation の独立検証
ARC Prize 2025 のリーダーボード上では、TRM の semi-private 評価が ARC-AGI-1 で約 40 %($1.76/task)、ARC-AGI-2 で約 6.2 %($2.10/task)と報告されている。論文値(44.6 %, 7.8 %)よりわずかに低いが、HRM が ARC Prize の独立 ablation で大きく値を落とした経緯(HRM 章を参照)と比べれば、TRM の数値は概ね追試できる範囲に収まっている。論文単体としての Paper Award 1 位受賞は、HRM 物語を ablation で丁寧に解体した方法論的貢献を評価したものである。
ARC Prize 2025 本戦では、TRM-based components を使った NVARC(NVIDIA KGMoN チームの Sorokin & Puget)が ARC-AGI-2 で 24 % ($0.20/task) を達成し、Paper 部門とは別の効率性 SOTA を取った (Chollet ほか 2026年)。TRM のアーキテクチャは「単独で reasoning を解く」よりも「合成データ生成 + test-time training と組み合わせて使う」軌道で実用化が進んでいる、というのが 2026 年中盤時点での見立てである。
関連 critique 論文
TRM への直接的な批判としては、Roye-Azar らの 2025 年論文 (Roye-Azar ほか 2026年) が ARC-AGI-1 に絞って TRM の inductive bias, identity conditioning, test-time compute を機構解析し、puzzle augmentation への依存と「テストで使う task を含めて訓練する」transductive 性が性能の主要因であると指摘する。HRM 系全体に対する Ge ら (Ge ほか 2025年) の解析や、HRM の「reasoning か guessing か」を機構的に切り分けた Ren & Liu (Ren と Liu 2026年) と合わせて読むと、TRM もまた「HRM の物語を否定したが、ARC 系ベンチマークの特殊性に依存する」という同じ批判の対象に立っていることが見えてくる。
機構的批判はさらに 2026 年に深化した。Efstathiou & Balwani (Efstathiou と Balwani 2026年) は sparse autoencoder で TRM の latent dynamics を probe し、(i) モデルは早期に仮説形成し feature activation は周期パターンに収束する(refine ではなく stabilize する)、(ii) 軌道は初期化に応じて局所最小に分岐する、(iii) 失敗 run は高損失の安定 attractor で plateau する、と報告する。「再帰 reasoning は incremental refinement ではなく attractor landscape 上の adaptive search である」という結論は、TRM 自身の「深さで refine する」物語を機構レベルで否定する位置にある。同時期の Sghaier ら (Sghaier ほか 2026年)(本書 PTRM 章で扱う)は独立にほぼ同じ観察に到達し、対処法として test-time の確率的探索を提案した。
TRM の直接派生研究
論文公開後 7 ヶ月で、TRM を起点とした派生研究が複数の方向に並走している。本書がそれぞれを章として扱う 2 本(PTRM と Lattice Deduction Transformers)に加え、(i) 訓練効率、(ii) ARC Prize 2025 での実装的工夫、(iii) アーキテクチャの operator 入れ替え、の 3 軸でも進展がある。
- 訓練効率: Hakimi の Recursive Stem Model (Hakimi 2026年) は hidden state 履歴の detach・終端ステップのみの損失・外側再帰での stochastic depth により TRM 訓練を 20 倍以上加速し、Sudoku-Extreme で 97.5 %、Maze-Hard で約 80 % を達成する。PTRM が「推論時の探索性」を改善するのに対し、RSM は「訓練効率」を改善する直交軸として読める。
- ARC Prize 2025 実装: McGovern の Test-Time Adaptation of Tiny Recursive Models (McGovern 2025年) は 7M parameters の TRM を public 1,280 タスクで 48 時間訓練したのち、コンペ予算下で 12,500 ステップの test-time fine-tuning を施す独立追試で、public eval で約 10 %、semi-private で 6.67 % を報告した。NVARC(ARC-AGI と小規模モデル 章で扱う)が TRM components をより大規模なアンサンブルに統合したのに対し、これは「素の TRM の天井」を示す参照点となる。
- Operator 入れ替え: Wang & Reid (Wang と Reid 2026年) は再帰 operator 内の Transformer block を Mamba-2 SSM に置換する Tiny Recursive Reasoning with Mamba-2 Hybrid を提案。ARC-AGI-1 の top-1 は同等ながら pass@100 が +4.75 pp 改善するという結果は、「TRM は単に小さな Transformer でなく、operator の設計空間が trajectory の多様性を左右する」ことを示唆する。
- Sound deduction 系統への分岐: Cheng Lou の Sotaku (Lou 2026年) は TRM の 1/10 サイズ(800K parameters)で Sudoku-Extreme 98.9 % を独立達成し、Lattice Deduction Transformers (Davis ほか 2026年)(本書 LDT 章で扱う)は Sotaku のアーキテクチャを継承しつつ abstract interpretation の lattice projection を追加して empirical soundness を獲得する。HRM → TRM → Sotaku → LDT の流れは、HRM/TRM/PTRM/GRAM の「approximate refinement」系統とは独立した、より「symbolic deduction 寄り」の系譜として並走している。
論文 Conclusion 自身も「TRM は単一の決定論的解を返す supervised learner にすぎず、複数解が許される設定では使えない。TRM を生成モデルに拡張するのが今後の課題」と述べており、これは 2026 年 5 月の PTRM (Sghaier ほか 2026年)(本書 PTRM 章)と GRAM (Baek ほか 2026年)(本書 GRAM 章)に直接引き取られることになる。前者は学習済 TRM checkpoint をそのまま test-time に noise injection で確率化する一方、後者は学習段階で latent を確率化し再学習を要する補完関係にあり、TRM の決定論的限界を test-time と train-time の双方向から崩した形である。
ノート著者インタビューでの retrospective
ARC Prize 2025 公式 YouTube インタビュー (ARC Prize 2025年) で、Jolicoeur-Martineau 氏は論文では触れられていない実装事情と future direction を語っている。以下は本書筆者が動画の自動生成英語トランスクリプトから直接確認した発言の要約で、論文の主張ではなく口頭発言として扱う。
- 計算リソースで ablation が制約された: 「I was very limited in compute. So it was one run and it was this run, right? I didn’t [do] ablation.」と率直に認めており、論文 Table 1 の各行が単一 run の結果である点を補強する。harder example(ARC など)で深さを変える ablation も「the computer がなかったので試せなかった」と明言。
- training を伸ばすと ARC-AGI-2 が 15 % に届く独立検証: ある replication チームが TRM を約 2 倍の epoch で訓練し直したところ ARC-AGI-2 public で 15 % に達したと著者が紹介している(論文値 7.8 %)。論文値は天井ではなく compute で抑えられていることの直接的な傍証。
- puzzle_id embedding は将来捨てたい: 「right now it’s a bit weird with the one embedding per per data point, like maybe you’d want some kind of in context learning so that you don’t need to retrain」。本書 HRM 章と 未解決問題 章で批判する puzzle_id 依存を、著者本人も今後の改善対象として明示的に認識している。
- ARC-AGI-2 のボトルネックはコンテキスト長: 「RKGI 2 has this multiple example that can cause some issue. It makes the context length very big and you need some strategy.」ARC-AGI-2 で TRM が伸び悩む構造的要因として、著者本人は per-task example 数によるコンテキスト長爆発を挙げている。
位置付け
本書全体の文脈で TRM が果たす役割は、HRM 系統の「物語の剥がれ」を最も鮮明に示した一次資料 という点にある。
- 技術的には、HRM の 3 つの装飾(fixed-point / ACT 2 forward / 階層性)を順次外しても性能が下がらず、むしろ最大の柱(1-step gradient)を外すと +30.9 pp 改善する、というデータを ablation 表 1 枚で示した
- 受賞・実装・コミュニティ追試のいずれの面でも、HRM のように物語が大きく剥がれることなく着地している(数値の再現性、コードの公開、Paper Award)
- 一方で「7M の小規模モデルが Frontier LLM を上回る」というナラティブは Sudoku/Maze の閉じた条件でのみ成立し、ARC-AGI では Grok-4 系には届かない。puzzle-specialized なソルバーであり、open-domain LLM の代替ではないという点は論文自身も明示している
TRM の決定論的最小核に何を足し戻すかによって、研究プログラムは複数の方向に分岐した。PTRM は学習済 TRM checkpoint をそのまま使い、test-time に確率項を加えて bad basin から escape する最小介入である。GRAM は学習段階で Gaussian な確率項を加え、unconditional generation と multi-hypothesis reasoning を獲得するより大きな変更を採る。LDT は TRM の系譜から分岐し(HRM → TRM → Sotaku → LDT)、確率性ではなく abstract interpretation の lattice projection を足して empirical soundness を獲得する。HRM → TRM の引き算ののちにこの 3 系統が並走している現状を、本書では主要 5 論文として 5 章で扱う。
参考文献
ARC Prize. 2025年. Interview with Alexia Jolicoeur-Martineau: ARC Prize 2025 Paper Award Winner. YouTube video interview. https://www.youtube.com/watch?v=P9zzUM0PrBM.
Baek, Junyeob, Mingyu Jo, Minsu Kim, Mengye Ren, Yoshua Bengio, と Sungjin Ahn. 2026年. 「Generative Recursive Reasoning」. arXiv preprint arXiv:2605.19376. https://arxiv.org/abs/2605.19376.
Bai, Shaojie, J. Zico Kolter, と Vladlen Koltun. 2019年. 「Deep Equilibrium Models」. Advances in Neural Information Processing Systems. https://arxiv.org/abs/1909.01377.
Banino, Andrea, Jan Balaguer, と Charles Blundell. 2021年. 「PonderNet: Learning to Ponder」. arXiv preprint arXiv:2107.05407. https://arxiv.org/abs/2107.05407.
Chollet, François, Mike Knoop, Gregory Kamradt, と Bryan Landers. 2026年. 「ARC Prize 2025: Technical Report」. arXiv preprint arXiv:2601.10904. https://arxiv.org/abs/2601.10904.
Davis, Liam, Leopold Haller, Alberto Alfarano, と Mark Santolucito. 2026年. 「Lattice Deduction Transformers」. arXiv preprint arXiv:2605.08605. https://arxiv.org/abs/2605.08605.
DeepSeek-AI, Daya Guo, Dejian Yang, ほか. 2025年. 「DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning」. Nature 645: 633–38. https://arxiv.org/abs/2501.12948.
Efstathiou, Andreas, と Aishwarya Balwani. 2026年. 「Recursive Reasoning as Attractor Landscape Search: Mechanistic Dynamics of the Tiny Recursive Model」. Workshop on Latent and Implicit Thinking – Going Beyond CoT Reasoning, ICLR 2026. https://openreview.net/forum?id=kKps9W1K7n.
Ge, Renee, Qianli Liao, と Tomaso Poggio. 2025年. 「Hierarchical Reasoning Models: Perspectives and Misconceptions」. arXiv preprint arXiv:2510.00355. https://arxiv.org/abs/2510.00355.
Graves, Alex. 2016年. 「Adaptive Computation Time for Recurrent Neural Networks」. arXiv preprint arXiv:1603.08983. https://arxiv.org/abs/1603.08983.
Hakimi, Navid. 2026年. 「Form Follows Function: Recursive Stem Model」. arXiv preprint arXiv:2603.15641. https://arxiv.org/abs/2603.15641.
Jolicoeur-Martineau, Alexia. 2025年. 「Less is More: Recursive Reasoning with Tiny Networks」. arXiv preprint arXiv:2510.04871. https://arxiv.org/abs/2510.04871.
Lou, Cheng. 2026年. Sotaku: From-scratch Experiments on Iterative Neural Sudoku Solvers. Software, GitHub repository, commit 9e13341. https://github.com/chenglou/sotaku.
McGovern, Ronan Killian. 2025年. 「Test-time Adaptation of Tiny Recursive Models」. arXiv preprint arXiv:2511.02886. https://arxiv.org/abs/2511.02886.
Ren, Zirui, と Ziming Liu. 2026年. 「Are Your Reasoning Models Reasoning or Guessing? A Mechanistic Analysis of Hierarchical Reasoning Models」. arXiv preprint arXiv:2601.10679. https://arxiv.org/abs/2601.10679.
Roye-Azar, Antonio, Santiago Vargas-Naranjo, Dhruv Ghai, Nithin Balamurugan, と Rayan Amir. 2026年. 「Tiny Recursive Models on ARC-AGI-1: Inductive Biases, Identity Conditioning, and Test-Time Compute」. arXiv preprint arXiv:2512.11847. https://arxiv.org/abs/2512.11847.
Sghaier, Amin, Ali Parviz, と Alexia Jolicoeur-Martineau. 2026年. 「Probabilistic Tiny Recursive Model」. arXiv preprint arXiv:2605.19943. https://arxiv.org/abs/2605.19943.
Wang, Wenlong, と Fergal Reid. 2026年. 「Tiny Recursive Reasoning with Mamba-2 Attention Hybrid」. arXiv preprint arXiv:2602.12078. https://arxiv.org/abs/2602.12078.