Confidence と Uncertainty
大規模言語モデル(Large Language Model, LLM)が出したreasoning traceに対し、「モデル自身は答えが正しいと思っているか」を ground truth なしに推定したい。この問いは selective prediction、abstention、Best-of-N 重み付け、conformal prediction といった下流応用すべての入口に位置する。本章ではまず estimator の主要 3 経路を整理し、次に 2026 年に独立な複数のグループから報告された「強化学習(Reinforcement Learning, RL)後の系統的な miscalibration」を扱い、そのうえで sampling-based 信号の最新動向と下流タスクとの接続を見る。
3 つの推定経路
confidence estimator は入力に何を使うかで 3 系統に分かれる。logit-based は token の対数尤度や entropy を使い、verbalized はモデルに直接「自信度」を問い、sampling-based は複数サンプル間の同意度や分散を測る。それぞれの代表的な手法を 表 1 にまとめる。
| 経路 | 入力 | white/black box | 代表手法 | 強み | 弱み |
|---|---|---|---|---|---|
| logit-based | token logprob, predictive entropy | white-box | EAS (Zhu ほか 2025年), Think Just Enough (Sharma と Chopra 2025年) | 単一生成で取れて軽量 | logit にアクセスできない API では使えない |
| verbalized | モデルへの自己申告質問 | black-box | “Are you sure?” 系, DINCO (V. Wang と Stengel-Eskin 2025年) | API でも取れる | RL/RLHF 後に強い over-confidence |
| sampling-based | 多サンプル間の同意度・分散 | black-box | semantic entropy, CISC (Taubenfeld ほか 2025年), DiverseAgentEntropy (Feng ほか 2024年) | logit 不要、答えに対して直接的 | N 回サンプリングのコスト |
ICLR 2026 採択の TokUR (Zhang ほか 2025年) は低ランクなランダム重み摂動を decoding 時に注入して aleatoric と epistemic を分離する white-box 手法で、3 経路の中間に位置する変則例である。token-level の perturbation を集約することで「LLM が自分の reasoning 出力の信頼性を自己評価」する枠組みを与える。
RL 後の miscalibration
2026 年の最も大きな経験的発見は、「reasoning model 化のための post-training は confidence の calibration を深刻に劣化させる」というものである。同様の主張が独立に複数のグループから出ている。
Reinforcement Learning with Verifiable Rewards(RLVR)または Reinforcement Learning from Human Feedback(RLHF)で訓練された reasoning model は、正答にも誤答にも極端に高い確率を割り当てる severe miscalibration を起こす。Expected Calibration Error(ECE)が base model 比で大幅に悪化し、verbalized 自信度は 85% 以上に飽和する。
Decoupling Reasoning and Confidence (Ma ほか 2026年) は、Group Relative Policy Optimization(GRPO)等で訓練した reasoning model が severe calibration degeneration を起こすことを示し、原因を「accuracy 最大化と calibration error 最小化の gradient conflict」と分析した。著者らは reasoning 目的と calibration 目的を分離する DCPO(Decoupled Calibration Policy Optimization)損失を提案し、accuracy を保ったまま ECE を改善する。
Reasoning about Uncertainty (Mei ほか 2025年) は o1、o3-mini、DeepSeek-R1、Claude 3.7 Sonnet 等に verbalized confidence を出させると、誤答にも 85% 以上の自信を割り当てる極端な over-confidence が観察されると報告した。さらに反直感的な depth paradox を示している: thinking budget を増やすほど calibration が悪化する。introspection prompt の効果はモデル依存で、o3-mini では改善するが Claude 3.7 では悪化する。
Taming Overconfidence in LLMs (Leng ほか 2024年) は RLHF 後の verbalized over-confidence の根本原因が、報酬モデルが高 confidence 表現にバイアスして高 reward を返すことだと特定した。PPO-M(reward model 訓練に confidence score を統合)と PPO-C(PPO 中に reward を historical 平均で再調整)を提案し、Llama3-8B / Mistral-7B / 6 データセットで calibration を改善した。RLHF 前後の confidence 分布の変化は 図 1 にはっきり現れる。SFT 段階では 0.7〜0.9 帯に幅広く分布していた confidence が、RLHF 後にはほぼ 1.0 近傍に集中してしまう。
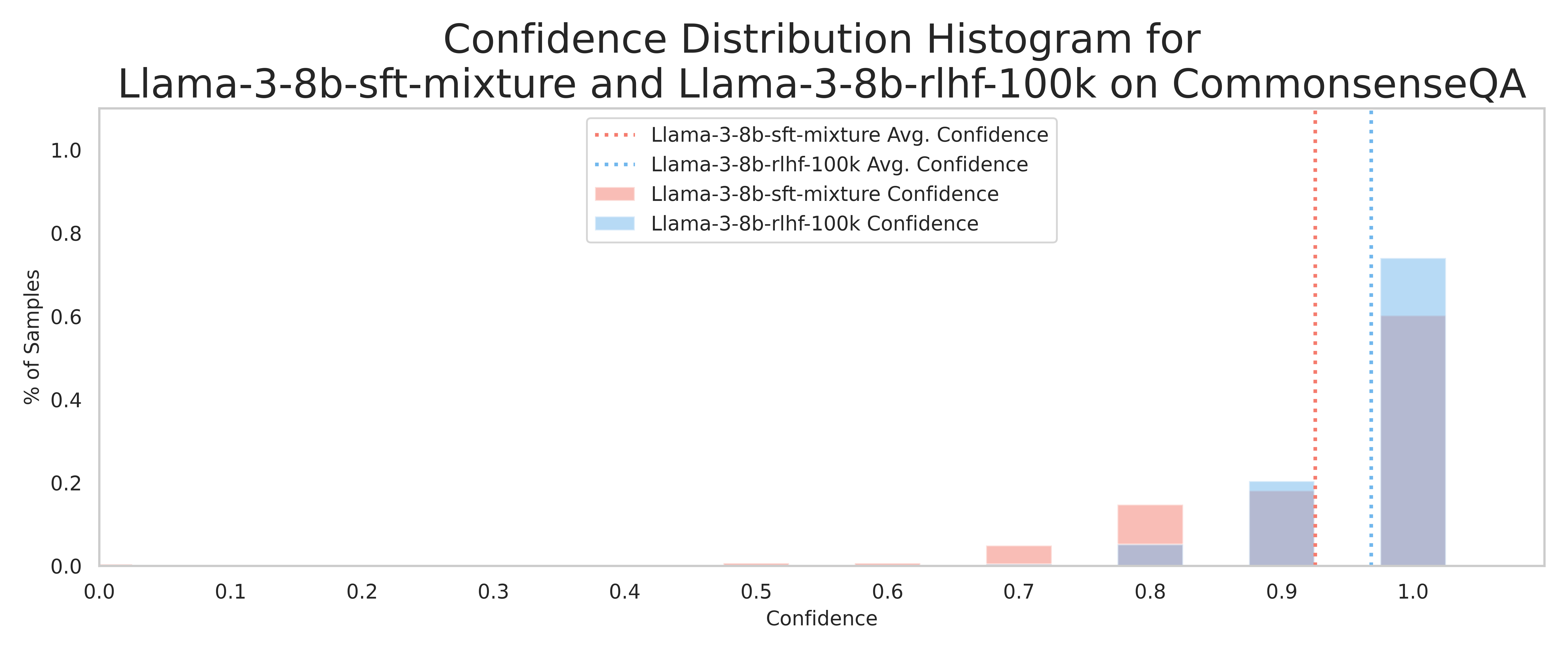
これらは「sampling-based black-box 信号」が現代の reasoning model で必要な理由を新たに正当化する。logit-based / verbalized が壊れている前提で post-hoc な外側測定に投資する動機になる。
Verbalized confidence の崩壊
verbalized confidence については 2026 年に内部回路レベル、decision-theoretic な観点、calibration 直接比較の 3 方面で否定的な証拠が積み上がった。
Wired for Overconfidence (T. Zhao ほか 2026年) は過信を生む内部回路を mechanistic interpretability で同定した。中後層の MLP block と attention head の compact なセットが最終トークン位置で confidence を inflate しており、ここに targeted intervention を入れると calibration が改善する。verbalized 信号が「構造的に inflate されている」ことの内部回路レベルでの裏付けである。
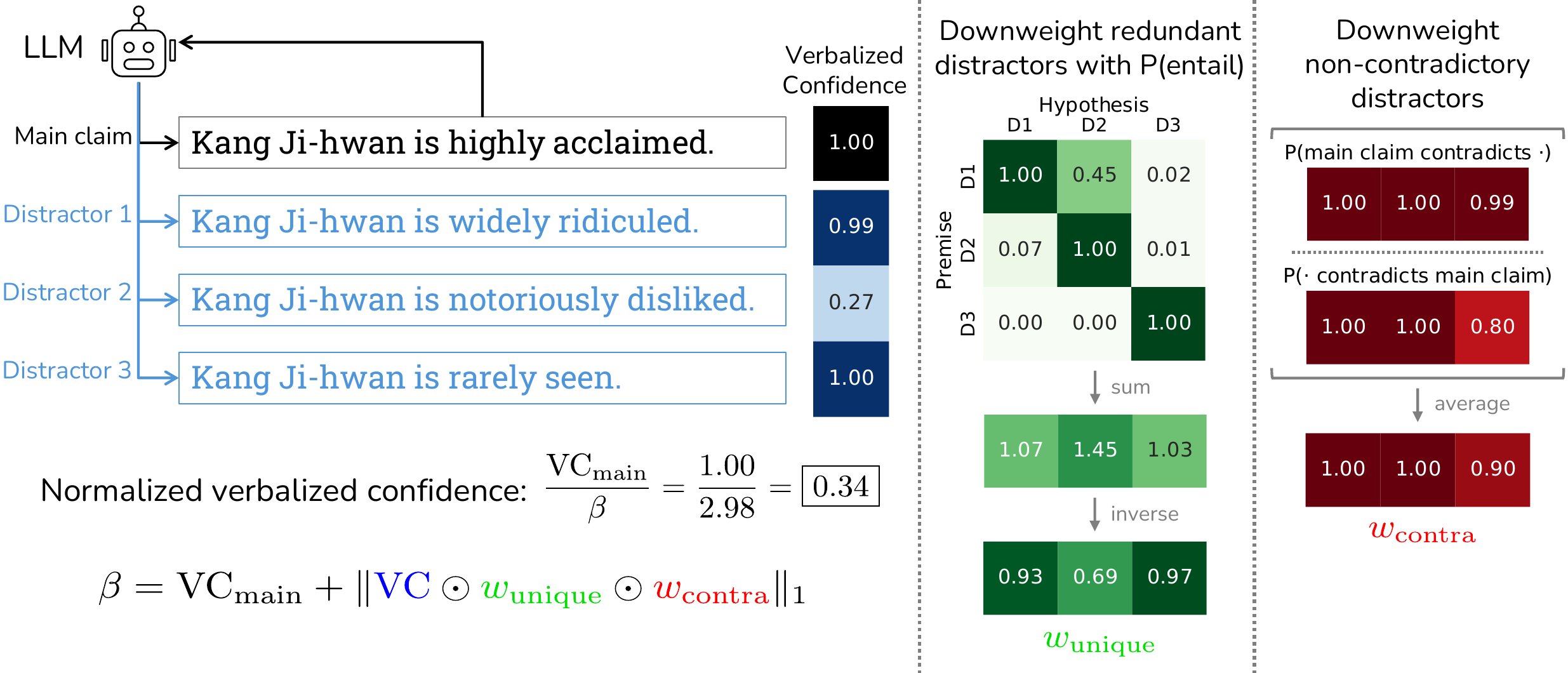
DINCO(V. Wang と Stengel-Eskin 2025年) は「verbalized confidence は提示された claim への suggestibility が出るため過信になる」と診断し、モデル自身に複数の alternative claim を distractor として生成させ、各 claim に独立に verbalized confidence を出して合計で正規化する手法を提案した。10 generations の DINCO が 100 generations の self-consistency を上回るほど効率的に動作する。手法の構造は 図 2 のとおりで、main claim とその distractor の verbalized confidence 合計で正規化し、さらに entailment と contradiction で重み付けすることで「suggestibility による持ち上げ」を抑える。
Are LLM Decisions Faithful to Verbal Confidence? (J. Wang ほか 2026年) は RiskEval というベンチマークで、誤答に高い penalty を与える設定下でも、モデルは verbalized で低 confidence を出しても abstain しない「utility collapse」を発見した。verbalized confidence は数字としては出るが、decision-making に faithful ではない。これは calibration metric だけでは trustworthy 性に不十分という強い主張である。
Sampling-based estimator の最新動向
sampling-based 信号は N 個の reasoning trace を引いて、その agreement や entropy を見る系統である。古典的には self-consistency が基本道具で、2025–2026 年は「効率」と「diversity」を軸に拡張が続いている。詳細は Self-Consistency と重み付き多数決 を参照のこと。
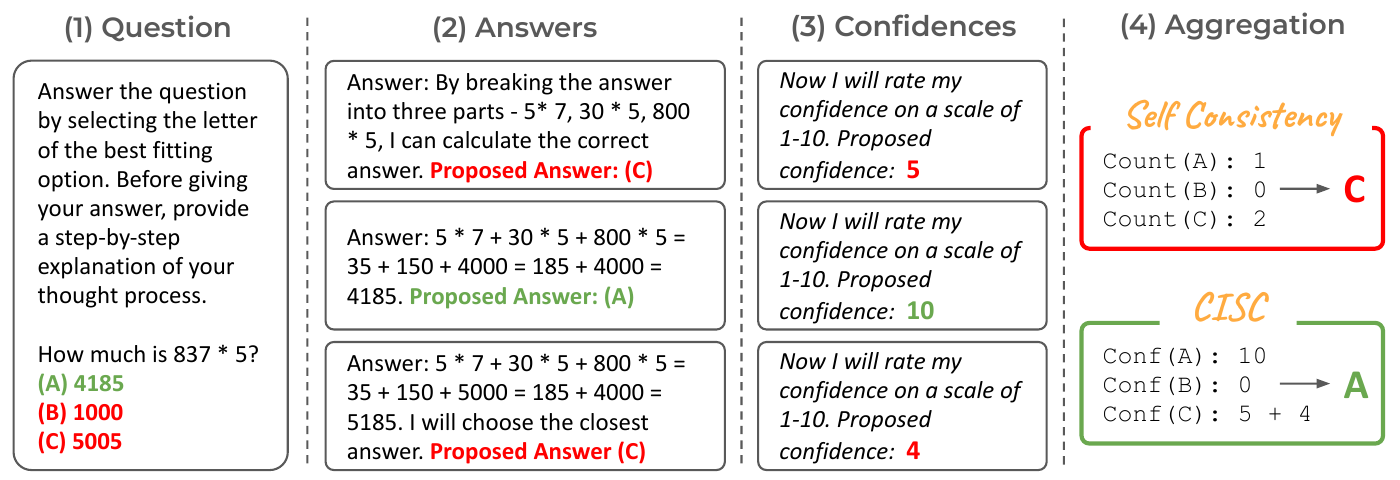
CISC (Taubenfeld ほか 2025年) はモデル自身に各 reasoning path の self-assessment score を出させ、weighted majority vote する手法で、9 モデル 4 データセットで必要 path 数を 40 パーセント以上削減した。図 3 に self-consistency との対比を示す。同じ問題に対して 3 つの reasoning path を引き、self-consistency は単純な多数決で間違った答え C を選ぶのに対し、CISC は path ごとの自己評価 confidence で重み付けし、最も自信のあった path の答え A を採用する。重要な発見として、「最も calibrated な confidence 法が CISC で最も効果が低い」というケースが報告されている。ECE ベースの calibration metric が実用 discrimination と乖離する場面があるという論点である。
VecCISC (Petullo ほか 2026年) は CISC の critic LLM への multi-call が高コストである問題に対し、reasoning trace を semantic similarity でクラスタリングして redundant / degenerate / hallucinated trace を事前にフィルタする。CISC と同等以上の精度で token 使用を 47 パーセント削減する。
DiverseAgentEntropy (Feng ほか 2024年) は「同じ知識を異なる query 表現で問う」multi-agent 設定で entropy を計算する。通常の self-consistency は同じ質問への consistency しか見ないため context bias で同じ誤答を繰り返すケースに弱い。表面的な一致ではなく genuine な知識的 uncertainty を捕捉でき、hallucination 検出で state-of-the-art を達成した。
Unsupervised Confidence Calibration from a Single Generation (Zollo ほか 2026年) は N 回サンプリングの代わりとして、オフラインに unlabeled data 上で self-consistency-based 信号を作り、軽量 predictor に蒸留して deployment 時には 1 回生成のみで confidence を出すパイプラインを提案した。5 つの数学および QA タスク、9 reasoning model でベースラインを大きく上回り、分布シフトにも robust である。
Zollo ほか (2026年) は 2026 年に明確になった重要な方向性: 高品質な sampling-based 信号を訓練データ生成器として使い、それを 1 回生成で再現する軽量 predictor に蒸留する。推論 (inference) 時のコストを N 分の 1 にできるため、selective generation のような low-latency 応用と相性がよい。
Entropy trajectory と step-wise informativeness
logit-based 信号のうち、token 単位の entropy を「軌跡」として扱う系統が 2025 後半から急速に整理されてきた。
Entropy Trajectory Shape (X. Zhao 2026年) は reasoning ステップ間で per-step answer-distribution entropy を測り、その形状が最終正答率を予測することを発見した。monotone に減少する trajectory を持つ chain は non-monotone な chain より有意に正答率が高い。スカラ entropy ではなく trajectory shape が、安価かつ黒箱に近い形で取れる正答性指標として機能する。
Stepwise Informativeness Assumption (Català ほか 2026年) は、CoT の「entropy が下がるほど答えが正しい」という経験則を理論化する。Stepwise Informativeness Assumption (SIA) は「autoregressive モデルは answer-informative prefix を介して情報を蓄積する」という仮定で、最尤訓練と RL によってさらに強化される。Gemma-2、LLaMA-3.2、Qwen-2.5、DeepSeek、Olmo といった幅広いモデルで GSM8K、ARC、SVAMP 等にわたって実証された。
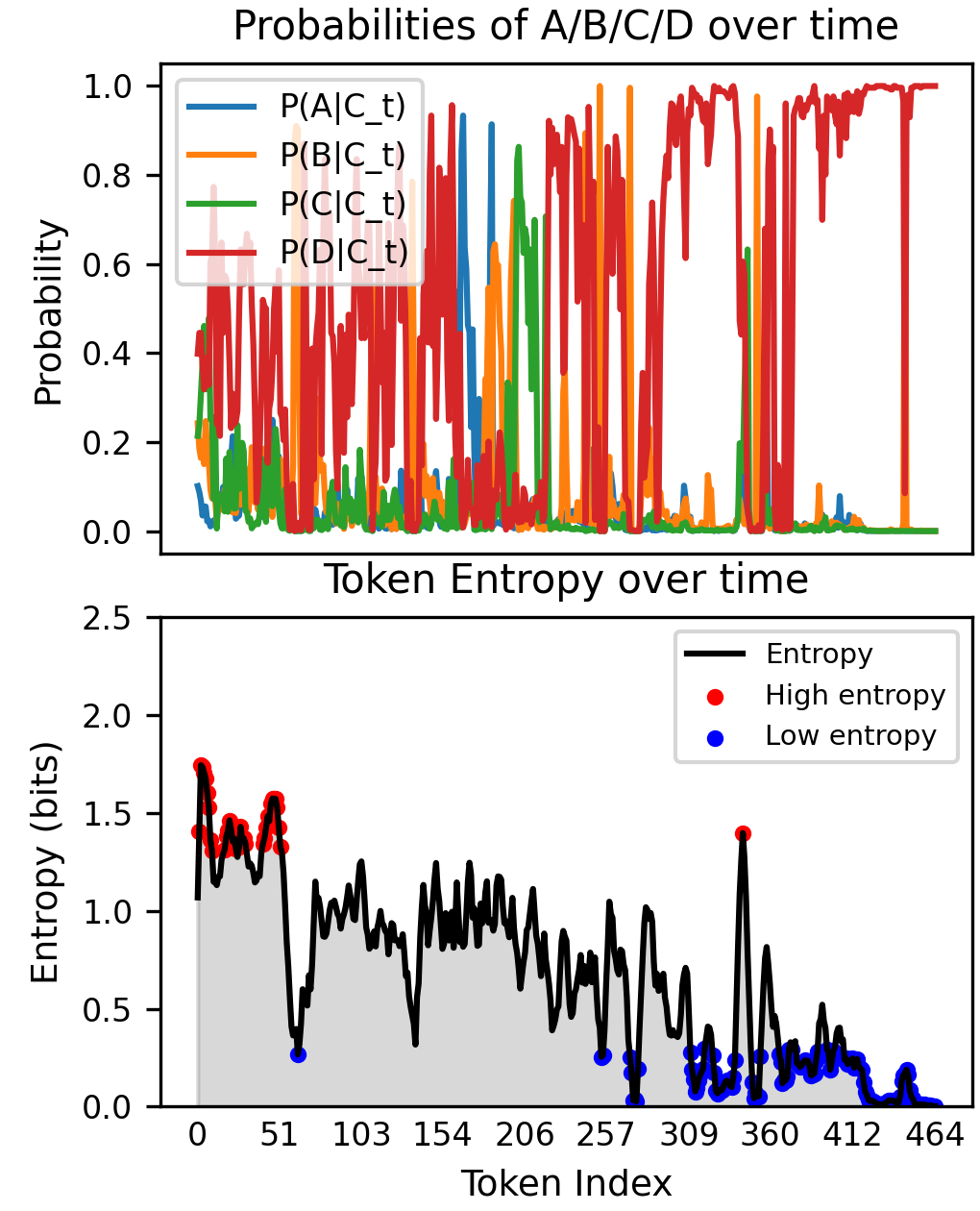
Entropy Area Score (EAS) (Zhu ほか 2025年) は生成中の token-level predictive entropy を積分してスカラに落とす。外部モデルも再サンプリングも不要で、ベンチマーク上で answer entropy と高相関を示す。さらに training data selection にも有効で、pass-rate ベース選別を上回る。図 4 は EAS が捕える信号の典型例である。上段の answer 確率は reasoning の前半で激しく振動し、後半に向けて 1 つの選択肢に収束していく。下段の token-level entropy はそれに対応して、前半で 1.5 bit 以上のピークが連続するのに対し、reasoning が固まる後半では一貫して 0.5 bit 未満に収まる。EAS はこの曲線の下面積を 1 スカラとして取り出す。
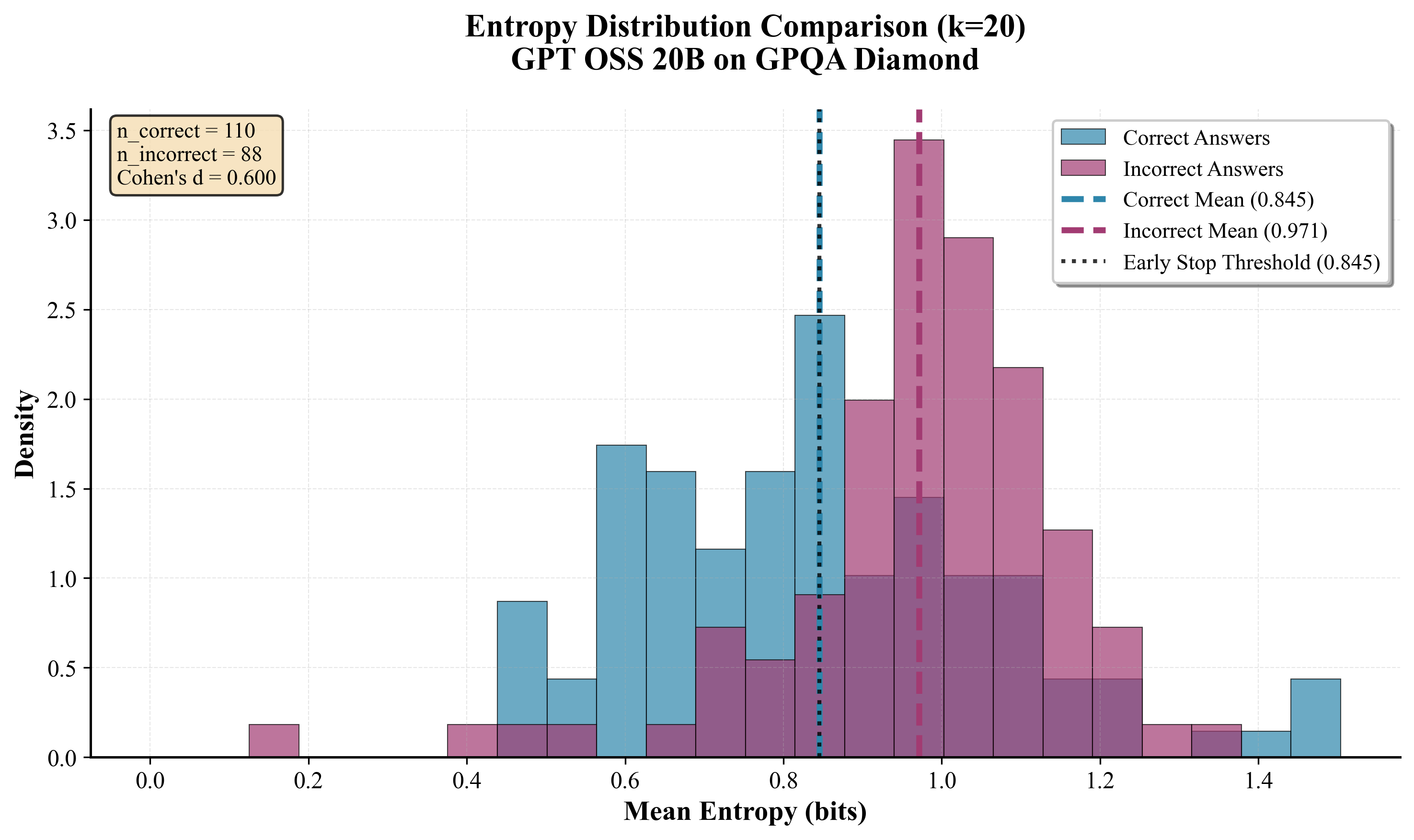
Think Just Enough (Sharma と Chopra 2025年) は token-level logprob から計算した Shannon entropy を early-stopping 信号として用い、reasoning model で 25–50 パーセントの token 削減を達成した。重要な観察として、この entropy-based emergent confidence は post-trained reasoning model(DeepSeek-R1 系)には現れるが、standard instruction-tuned や pre-trained model(Llama 3.3 70B)には現れない、と報告している。図 5 は GPT-OSS 20B / GPQA Diamond 上で正答と誤答の sequence-level entropy 分布が分離する様子を示す。誤答の方が一貫して entropy が高く(平均 0.97 bit vs 0.85 bit、Cohen’s d = 0.6)、早期停止 threshold として 0.845 bit を置くと正誤を実用的に弁別できる。
下流応用
confidence 信号をどう使うかが本章の最後の論点である。代表的な下流タスクは abstention、selective generation、conformal prediction の 3 つに整理できる。
Abstention と selective generation
Knowing When to Quit (Davidov ほか 2026年) は生成途中で abstain を「明示的な action」として RL の中に組み込み、value function が abstention reward を下回ったら止める原理的枠組みを提案した。数学 reasoningと toxicity avoidance の両方で selective accuracy が改善し、一般条件下で「value < reward なら abstain が他のいかなる baseline より strictly 良い」と理論保証を与える。confidence 信号を abstention の入力として plug-in する応用の自然な土台になる。
Conformal prediction
conformal prediction は「真の答えを含む確率が少なくとも 1−α」という被覆保証付きで予測集合を返す枠組みである。LLM 向けには 2 つの ICLR 2026 採択論文が決定的に整備された。
Paraphrase-Robust Conformal Prediction (Xin ほか 2026年) は prompt の表記揺れに robust かつ conformal な被覆保証を保つ枠組みである。入力を paraphrase で展開し、補助モデルで predictive distribution を強化、複数 paraphrase の結果を集約する。Qwen2.5-7B、Llama-3.1-8B、Phi-3-small で nominal coverage を保ちつつ compact な prediction set を出した。
Online Reasoning Calibration (ORCA) (Zhou ほか 2026年) は conformal prediction を test-time training で動的に行う meta-learning 枠組みである。入力ごとに dynamic な calibration を行うことで、分布シフト下でも conformal risk の theoretical guarantee を保ちながら、in-distribution で 47.5 パーセント、out-of-distribution の MATH-500 で 67 パーセントの効率改善を達成した。
Training-time の対極: confidence を学習する
post-hoc に外から測る経路の対極として、confidence 表現を訓練中に内在化させるアプローチがある。Rewarding Doubt (Bani-Harouni ほか 2025年) は生成過程に confidence 表現を seamless に織り込む RL 訓練を提案した。報酬は proper scoring rule の対数版で、over confidence と under confidence の双方を罰する。学習したモデルは未学習タスクにも汎化する。Leng ほか (2024年) の PPO-M / PPO-C と同じく、「inference-time signal を整える」のではなく「training-time に校正性を組み込む」軸の代表である。
章のまとめ
- confidence estimator は logit-based、verbalized、sampling-based の 3 経路に大別され、現代の reasoning model では logit と verbalized の信頼性に系統的な疑義が出ている
- 2026 年に独立な複数のグループ(Ma ほか (2026年)、Mei ほか (2025年)、Leng ほか (2024年))が「RL post-training が calibration を壊す」ことを確認した。これは sampling-based 黒箱信号への移行を正当化する
- verbalized confidence については内部回路(T. Zhao ほか (2026年))、decision-theoretic(J. Wang ほか (2026年))、直接比較(V. Wang と Stengel-Eskin (2025年))の 3 方面で否定的証拠が揃った
- sampling-based 系は efficiency と diversity の両軸で進化中で、特に Zollo ほか (2026年) の「N 回信号を 1 回蒸留する」流れと Feng ほか (2024年) の paraphrase 軸が中心である
- entropy trajectory(X. Zhao (2026年)、Català ほか (2026年)、Zhu ほか (2025年)、Sharma と Chopra (2025年))は logit-based 系を「スカラ」から「軌跡」へ拡張し、SIA で理論化された
- 下流応用としては abstention(Davidov ほか (2026年))、selective generation、conformal prediction(Xin ほか (2026年)、Zhou ほか (2026年))が主軸で、training-time 側の校正(Bani-Harouni ほか (2025年))と補完関係にある