RLVR の理論と限界
DeepSeek-R1 を発端に検証可能報酬による強化学習(Reinforcement Learning with Verifiable Rewards, RLVR)が事実上の標準となった一方で、それが LLM に 何をしているのか という基本的な問いは 2025–2026 年に大きな論争となった。Yue らの「RLVR は base 分布の外には出ない」という観察 (Yue ほか 2025年a) を契機に、評価指標・最適化動力学・回路レベルの介入実験など複数の角度から反論と精緻化が並走している。本章ではこの論争を 3 軸 — 拡張派と再重み付け派の対立、評価指標の選び方、再重み付けが何を変えているのかというメカニズム — に整理し、近接する系統である「base モデルそのものの再評価」もあわせて俯瞰する。
論争の構図
- 拡張派: RLVR は base モデルには無かった reasoning trace を真に獲得させる
- 再重み付け派: RLVR は base 分布内に既に存在する解法経路の確率質量を再配分しているにすぎず、新規能力は獲得しない
- 指標依存: 両派の結論は pass@K の K の取り方や、最終回答だけを見るか CoT も評価するかで容易に反転する
この対立は単なる解釈の違いではない。test-time compute の投資先(より長い CoT か、より多い独立サンプリングか)、PRM など下流 verifier の設計、RL recipe の選択といった実務判断のすべてに直結する。再重み付け派が正しければ、base モデル単体での inference 工夫が見直されるべきであるし、拡張派が正しければ、RL 訓練を続けることで真に新しい解法スキルが手に入ることになる。
出発点: 拡張か再重み付けか
論争の口火を切ったのは NeurIPS 2025 Oral の Yue らによる pass@K 解析 (Yue ほか 2025年a) である。RLVR で fine-tune したモデルと base モデルの両方から K 個ずつ独立サンプリングし、少なくとも 1 つ正解するかで定義される pass@K を K について系統的にスイープすると、小さい K では RL モデルが base を上回るが、K を十分大きくすると base モデルが RL モデルを逆転する という現象を観測した。さらに、RL モデルの生成 trace は perplexity の意味でほぼすべて base 分布の高確率領域に含まれており、新規な reasoning path はほとんど見られない。この観察から「RLVR は base 分布内のサンプリング効率を上げる再重み付けである」という枠組みが提示された。
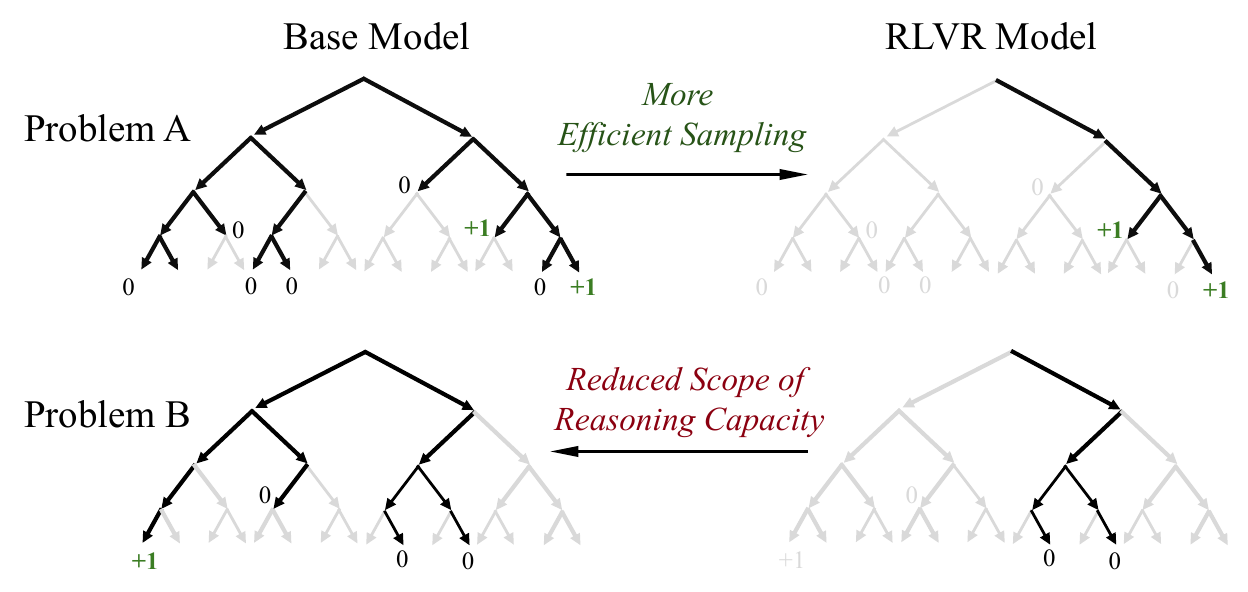
図 2 は同論文の中心的なエビデンスで、4 つの base モデルと 4 つのベンチマークにわたって、十分大きな K で base が RL を逆転する pattern が安定して再現することを示している。
この見方に正面から反論したのが Wen らの CoT-Pass@K 研究 (Wen ほか 2026年) である。pass@K は最終回答だけが正しければ credit を与えるため、間違った reasoning trace から偶然正解にたどり着いた経路と、正しい reasoning trace を含む経路とを区別できない。両者を区別するよう CoT 全体と最終回答の両方が正しい時にのみ credit を与える CoT-Pass@K で再評価すると、Yue らが見た crossover は消え、RLVR は K の全範囲で base を上回る。同じデータを別の指標で測ると逆の結論が出るという事実そのものが、論争の中心が「メカニズム」よりも「測り方」にあることを示している。
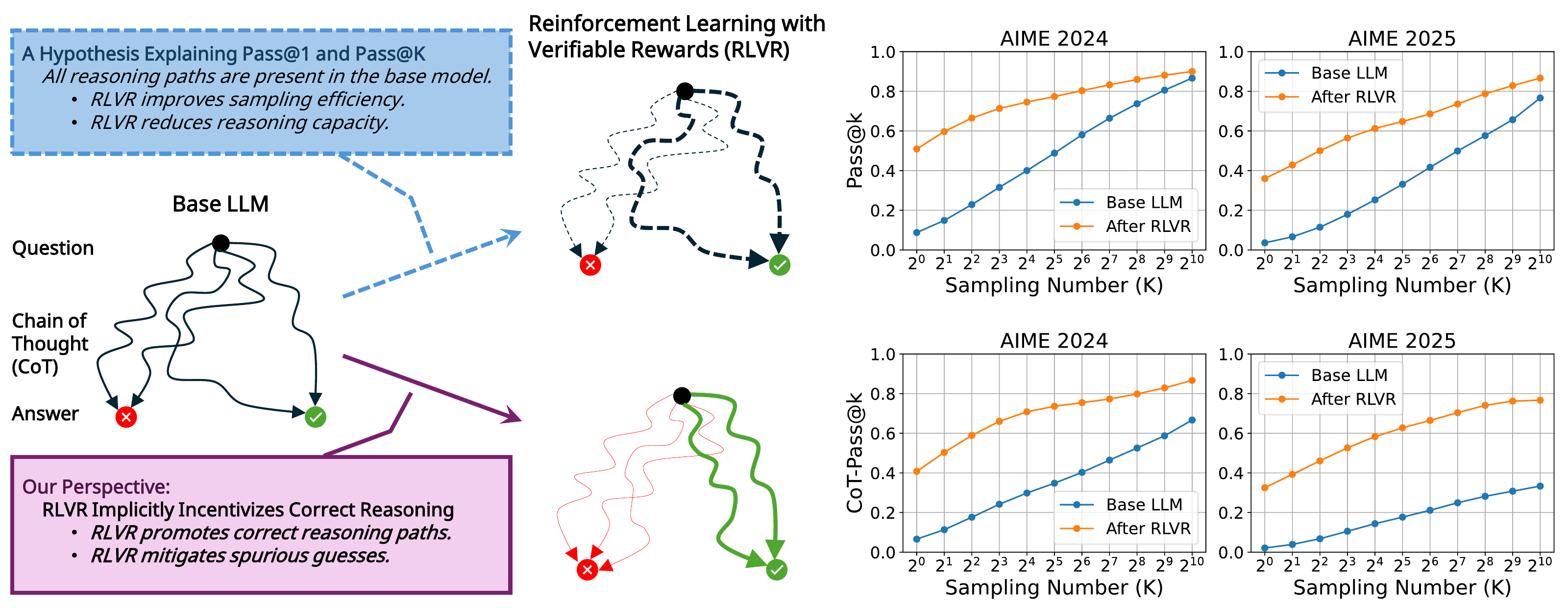
その後、両者を架橋する見方として Two-Stage Dynamic View (Yue ほか 2025年b) が提案された。RLVR の挙動は訓練ステップ数に対する 2 段階の動態として記述できる。
- exploitation 段階(初期): 高確率 token が更に強化され、capability boundary は 縮小 する
- exploration 段階(後期): 訓練を長く回すと境界は真に 拡大 する
短期訓練だけを見た実験は shrinkage に、長期訓練を見た実験は expansion に到達するため、両派の主張は同じ動態の異なる切断面を見ていたことになる。同様に Path Not Taken (Hanqing ほか 2025年) は、訓練動態の幾何学的な特徴付けとして RLVR の weight 更新が pretrained model の principal direction の 外側 に集中することを Three-Gate Theory(KL Anchor / Model Geometry / Precision)で証明し、再重み付け説の理論的裏付けを与えている。
評価指標の選び方
論争のもう一つの軸は「pass@K で reasoning capability を測ること自体が妥当か」という問いである。
pass@K の限界
Pass@k as Diagnostic (Yu ほか 2025年) は、pass@K を 直接最適化 する RL 目的関数を勾配分解し、それが本質的には pass@1 の per-example positive reweighting に過ぎないことを示した。さらに、探索が最も必要な低成功率の領域では学習信号が消失する。著者らはこれを根拠に、pass@K は inference-time の診断指標として残しつつ、訓練目的は別途設計すべきと主張する。
Breadth-Depth metric (De ほか 2025年) はさらに踏み込み、離散答え空間の数学タスクで K を大きくとった pass@K は「単に試行回数が多い」という効果と本来測りたい reasoning boundary を混同させてしまうと指摘する。代替として Cover@τ(少なくとも τ 割の completion が正解になる問題の割合)を提案し、Cover@τ で測ると pass@K で見えた RLVR vs base の crossover とは異なる絵が浮かび上がる。
表 1 に主要な指標の特性を整理する。
| 指標 | 何を測るか | RLVR vs base での挙動 |
|---|---|---|
| pass@1 | 単発正答率 | RL が一貫して優位 |
| pass@K(小 K) | K 本中 1 本正解する確率 | RL が優位 |
| pass@K(大 K) | 多数試行での到達可能性 | base が逆転 (Yue ほか 2025年a) |
| CoT-Pass@K | trace 全体が正しい確率 | RL が全範囲で優位 (Wen ほか 2026年) |
| Cover@τ | 再現性のある正解の比率 | 指標固有の絵 (De ほか 2025年) |
「測り方を変えると結論が反転する」という事実を真剣に受け止めると、RLVR の効果を一つの数値で総括する試みは原理的に不毛である。Self-Consistency と重み付き多数決 で扱う self-consistency と重み付き多数決の研究もまた、同じ理由から「正答率と再現性をどう束ねるか」という問題意識を共有している。
メカニズムの解明
「RLVR は再重み付けである」と言ったとき、何が何に対して再重み付けされているのか。2025–2026 年に複数の系統が独立にメカニズムへ踏み込んだ。
Principal direction とスパースな更新
Path Not Taken (Hanqing ほか 2025年) は前述のとおり、RLVR の重み更新が事前学習モデルの principal direction の外側にある 低曲率部分空間 に集中することを示した。データセットや RL recipe を変えてもこの bias は不変である。同方向の token-level な観察として Sparse but Critical (Meng ほか 2026年) は、RLVR fine-tune 後の policy と base の間で意味のある divergence を示す token 位置がごく少数にしか存在しないことを示し、それらの critical 位置でだけ policy を交換する cross-sampling intervention だけで性能の大半が再現できることを実証した。RLVR は sparse and targeted refinement だという見方である。
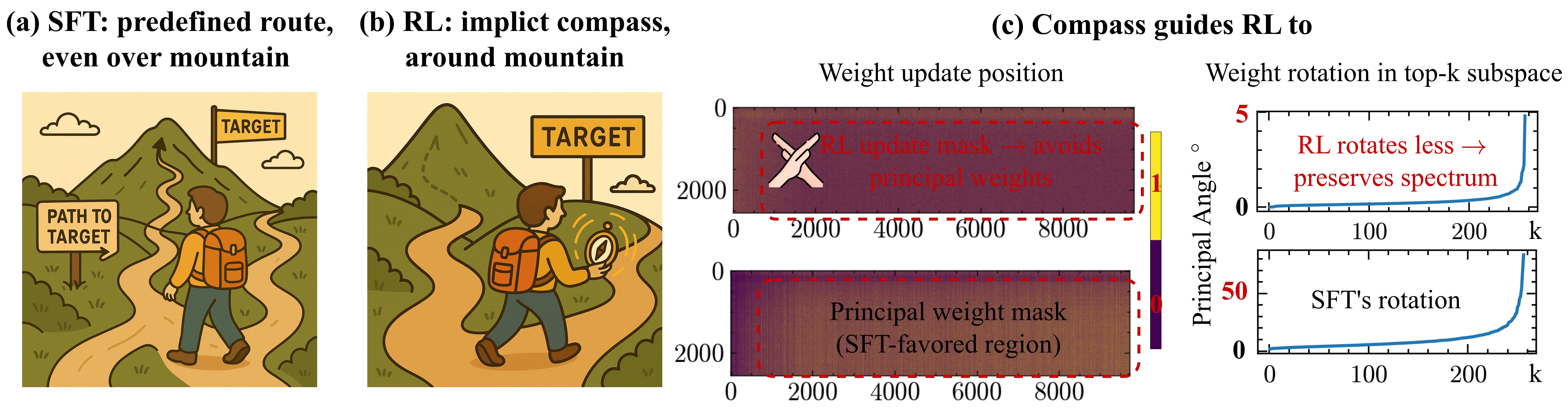
Small Vectors, Big Effects (Sinii ほか 2025年) は介入を更に軽量化し、base モデルの residual stream に per-layer の steering vector を挿入して RL 目的で訓練するだけで、フル fine-tuning による性能向上の大部分が再現できることを示した。最終層の steering vector は最初の生成 token を “To” や “Step” にバイアスする token 置換として働き、penultimate 層は process word と structure symbol を up-weight する。これらは同じ family の別モデルにも転移する。
Primitive と pattern selection
「では何が再重み付けされているのか」に対する答えの一つは 既存 primitive の sharpening である。New Skills or Sharper Primitives (Wang ほか 2026年) は Algebrarium と呼ぶ合成タスク(single-step だけ訓練して multi-step を評価)で、RLVR が atomic step の確率を sharpen することにより、composite task で指数的に蓄積する失敗確率を抑え込むことを示した。新規スキルではなく、既に存在する原子操作の鋭利化が compositional reasoning を支えているという描像である。
Reshaping Reasoning (Chen ほか 2025年) は質問・reasoning・回答の単純化モデル上で RLVR の収束を理論解析し、RLVR が新しい reasoning pattern を作るのではなく 既存 pattern の中から成功率最高のものを選び出す pattern selector として働く ことを示した。初期能力が強いモデルは急速に収束し、弱いモデルは遅く収束する 2 つの regime が導出される。On the Learning Dynamics of RLVR at the Edge of Competence (Huang ほか 2026年) は同じ問題を Transformer 上の compositional reasoning で扱い、難易度混合データでは “easy から hard へ” 自然な curriculum が発生する relay regime と、難易度に discontinuity がある場合に現れる grokking 様の phase transition を理論化している。
Memorization shortcut のリスク
メカニズム研究の中でも特に強い反例として浮上したのが Spurious Rewards Paradox (Yan ほか 2026年) である。Qwen2.5 などのモデルではランダム報酬や誤り報酬を用いた RL でさえも下流タスクの性能が顕著に向上することがある。著者らは path patching と logit lens でこの謎を解析し、中間層 L18–20 の Functional Anchor が pretraining 由来の memorized solution を呼び出し、L21+ の Structural Adapter がそれを表面化させるという Anchor-Adapter 回路を発見した。RLVR の性能向上の一部は、本物の reasoning 強化ではなく、汚染データ由来の memorization shortcut を活性化させていた可能性がある。
これと整合する観察として Post-Training as Reweighting (Bu ほか 2025年) は、RLVR / outcome reward model / process reward model がいずれも tree-like な reasoning path 集合を 拡張せず、既存の path を再重み付けするだけであるという見方を Multi-task Tree-structured Markov Chain で形式化した。事前学習が tree を expand し、post-training は CoT を reweight する、という分業として整理される。
表 2 に主要なメカニズム仮説を並べる。
| 仮説 | 中心的観察 | 代表論文 |
|---|---|---|
| Off-principal な微小更新 | 重みは pretrained の principal direction の外側で動く | (Hanqing ほか 2025年) |
| Sparse token-level 介入 | 少数の critical 位置でだけ policy が変わる | (Meng ほか 2026年) |
| Steering bias | 軽量な per-layer vector で性能を再現 | (Sinii ほか 2025年) |
| Primitive sharpening | atomic step 確率の鋭利化 | (Wang ほか 2026年) |
| Pattern selection | 既存 pattern の最良を選ぶ | (Chen ほか 2025年) |
| Memorization shortcut | 中間層回路が memorized solution を呼ぶ | (Yan ほか 2026年) |
これらの仮説は互いに排他ではなく、異なる解像度で同じ現象を見ている可能性が高い。Functional Anchor のような中間層回路は principal-direction の外側で更新される重みの一部であり、それが下流の token 分布で見ると数個の critical 位置に集中する、という連結を考えると一貫した像が得られる。
base モデルに戻る系統
RLVR が再重み付けにすぎないなら、base モデル自身を inference で操作するだけで同等の効果が得られるはずである、という発想で動く研究が並走している。
Reasoning with Sampling (Karan と Du 2025年) は訓練・検証器・データセットすべて不要の inference-only な power sampling(Metropolis-Hastings ベースで base モデルの likelihood を sharpen する)だけで、MATH500・HumanEval・GPQA で RLVR と同等以上の reasoning 性能を達成することを示した。さらに RL post-training に頻出する diversity 崩壊が起きないという付随利得もある。
Can GRPO Transcend (Ni ほか 2025年) は GRPO の out-of-distribution(OOD)汎化が一貫しない現象 — 数学では効くが医学では効かない — を理論的に説明し、GRPO は base 分布に bound された保守的な再重み付けスキームであって novel solution を発見できないことを証明した。同論文は GRPO を「普遍的な reasoning enhancer」ではなく「pretraining bias の sharpener」と再定義する。
RL vs Distillation (Kim ほか 2025年) は RLVR と distillation の精緻な比較を提供する。RLVR は accuracy(pass@1)を上げるが capability(pass@K)を上げない一方、distillation は新規知識が入る場合に限り capability を上げる。pattern だけ distill した場合は RLVR と同じ trade-off に陥る、という観察は「base モデル + inference 工夫」と「RLVR」と「distillation」の三者の住み分けを整理する手がかりになる。
その他の関連論文
表 3 に本章で本文中に大きく取り上げなかった、しかし論争を理解する上で押さえておくべき論文を整理する。
| 論文 | 角度 |
|---|---|
| Gradient Gap (Suk と Duan 2025年) | RLVR の最適化動力学を trajectory と token の両レベルで解析し、ステップサイズの収束閾値を導出 |
| Edge of Competence (Huang ほか 2026年) | Transformer 上での compositional reasoning に発生する implicit curriculum と phase transition の理論化 |
| Two-Stage Dynamic View (Yue ほか 2025年b) | 訓練ステップに対する exploitation → exploration の 2 段階で shrinkage と expansion を統一説明 |
| Inverse Tree Freezing (Hu ほか 2025年) | 2 段階学習曲線・V 字応答長・catastrophic forgetting を semantic complex network の自己組織化で説明 |
| Interplay of PT/MT/RL (Zhang ほか 2025年) | 合成タスクで pre-training・mid-training・RL の寄与を分離し、RL が真の capability gain を生む条件を抽出 |
特に Interplay (Zhang ほか 2025年) が示した「RL が真の gain を生むのは pre-training が十分な headroom を残し、RL データが edge of competence を狙うときに限る」という条件は、Edge of Competence (Huang ほか 2026年) の implicit curriculum と整合し、二段階動態 (Yue ほか 2025年b) とも結びつく。これらをまとめて言い換えれば、再重み付け派と拡張派の対立は 訓練ステージと問題の難易度分布の関数として動的に切り替わる という結論に近づきつつある。
章のまとめ
RLVR は何をしているのか、という問いに対する 2025–2026 年の到達点は次の 4 点に集約できる。
- 再重み付けが主流見解になりつつある。Yue らの観察 (Yue ほか 2025年a) を起点に、Path Not Taken (Hanqing ほか 2025年)・Sparse but Critical (Meng ほか 2026年)・Pattern Selection (Chen ほか 2025年)・GRPO Transcend (Ni ほか 2025年)・Consistency (Bu ほか 2025年) が独立に「base 分布内の確率質量再配分」という結論に到達した
- 評価指標の選択が結論を支配する。pass@K と CoT-Pass@K (Wen ほか 2026年)、Cover@τ (De ほか 2025年) は同じデータから異なる結論を引き出し、「単一指標で総括できない」ことを示した
- 動的な見方が和解の鍵。Two-Stage Dynamic View (Yue ほか 2025年b) と Interplay (Zhang ほか 2025年) は、RL の効きが訓練ステージと問題難易度の関数であることを示し、拡張派と再重み付け派の主張が同じ動態の異なる切断面である可能性を示唆した
- base モデルの再評価が並走している。Reasoning with Sampling (Karan と Du 2025年) は inference-only 操作だけで RLVR 同等性能に到達し、RL を経由しない経路の余地を残した
これらは続く章で扱う 訓練側の他の信号(GRPO と reward 設計、PRM)および 推論 (inference) 側の信号(self-consistency、confidence、test-time compute scaling)と密接に絡む。例えば PRM の限界に関する近年の指摘は本章で見た「再重み付けの解像度」とちょうど呼応するし、self-consistency と prefix-based な再評価系の隆盛もまた、base 分布内の正しい path をどう取り出すかという同じ問いに端を発している。