Reasoning 構造の分析
Chain-of-Thought(CoT)の品質を推論 (inference) 時に評価しようとするとき、もっとも手軽な信号は「長さ」と「single token の confidence」である。だが、これらが正答率の予測因子として弱いことは Self-Consistency と重み付き多数決 や Confidence と Uncertainty で繰り返し触れてきた通りである。
ではどこを見ればよいか。2025–2026 年に独立に登場した 4 本の論文が、いずれも「CoT を 構造 として読む」という共通方針を採用した。reasoning trace の各 step が回答に及ぼす因果的影響、放棄された分岐の割合、内部回路の attribution graph、認知行動パターンの分類——切り口は異なるが、すべて「単一の長さや confidence では捉えられない構造的特徴に予測信号がある」という直観に立脚している。
本章ではこの 4 本を統合フレームの中で位置づける。共通モチーフは「reasoning の構造を inference-time に測る」であり、Self-Consistency と重み付き多数決 で扱った集約系(Self-Consistency 系・DeepConf 系・prefix を活用する系)と相補的に機能する。集約系が「複数 trace の合意」から信号を取り出すのに対し、本章の手法群は「1 つの trace の構造そのもの」から信号を取り出す。
なぜ「構造」を見るのか
CoT の品質予測について、これまで以下の信号が試されてきた。
- 長さ: 「長い CoT ほど慎重な reasoning」という仮説。だが Feng らの大規模実験 (Feng ほか 2025年) では、同一問題内では 短い CoT のほうが正答率が高い
- Verbalized confidence: モデル自身に「0–10 で確信度を答えろ」と尋ねる。DINCO (Wang と Stengel-Eskin 2025年) や Wired for Overconfidence (T. Zhao ほか 2026年) が示したように、Reinforcement Learning with Verifiable Rewards(RLVR)後のモデルでは深刻に miscalibrated
- Token-level entropy: Self-Certainty (Kang ほか 2025年)、Inverse-Entropy Voting(IEW)(Sharma と Chopra 2025年) などが採用するが、これも内部信号の calibration に依存する
これらの限界は、いずれも CoT を「均質な token 列」として扱っている点に由来する。本章で扱う 4 本は、CoT を 構造化された対象(時間的勾配を持つ列、分岐と放棄を含むグラフ、内部回路、認知行動の集合)として捉え直すことで、より強い予測信号を取り出す。
Self-Consistency と重み付き多数決 で扱った prefix 系手法群(PoLR、Path-Consistency、Prefix-Confidence Scaling、ST-BoN、Beyond the Last Answer、Prefix Consistency)は、CoT を どこで切るか(切断位置)と 何を測るか(confidence・出現頻度・再生成一致など)の 2 軸で構造化されている。本章で扱う構造系研究は、この 2 軸に対して外側から答えを与える位置に立つ。具体的には、Reasoning Horizon は「切断位置をどこに置くべきか」に物理的根拠を与え、Failed-Step Fraction(FSF)は「trace の何が正答性を予測するのか」を構造的に言い直す。
Reasoning Horizon: trace の終盤は因果的に空である
Ye らの Reasoning Horizon (Ye ほか 2026年) は、CoT の各 step が最終回答に及ぼす 因果的影響 を直接介入で測った。手法はシンプルである。CoT の特定 step を意図的に破壊(corruption)し、最終回答の logit 分布がどれだけ変化するかを観測する。
破壊操作はタスクごとに設計されている。
- Dyck-nn(括弧対応): スタック追跡の深さエラーを挿入
- PrOntoQA(論理 reasoning): 論理規則中のエンティティを置換
- GSM8K(算術 reasoning): 計算結果に誤りを挿入
破壊の効果は Normalized Logit Difference Decay(NLDD)で定量化される。正の NLDD は破壊が正解確信度を下げる(= step が因果的に効いている)、負の NLDD は破壊しても正解確信度が下がらない(= step は因果的に冗長)ことを意味する。
70–85% の臨界点
実験結果は明快だった。CoT の前半~中盤では NLDD が高く、ある地点を境に急減して 0 付近に落ちる。この臨界点を著者らは Reasoning Horizon \(k^*\) と名付けた。タスクとモデルを通じて、\(k^*\) は CoT 全体の 70–85% の範囲に収まる。
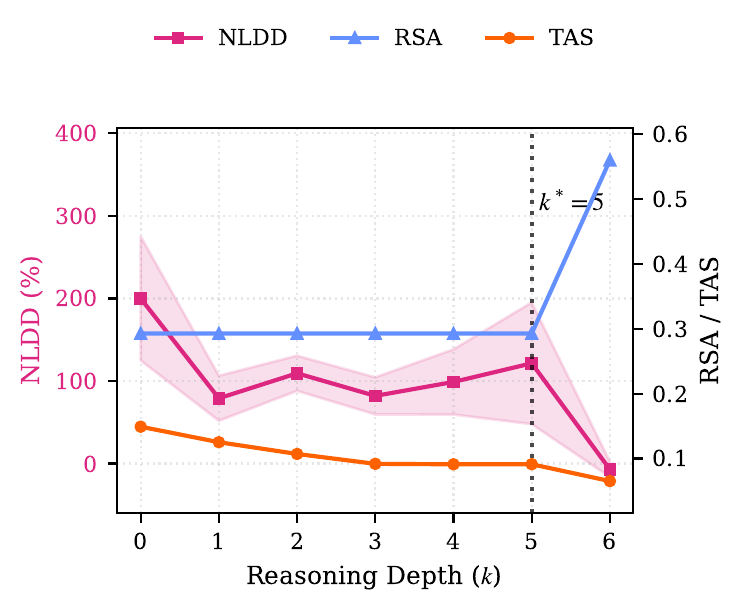
図 1 が示す具体的な内訳は次の通りである。
- GSM8K: 8 step 中 5–6 step 目(約 85%)
- Dyck-nn: 12 step 中 9–11 step 目(約 80%)
- PrOntoQA: 16 step 中 11–16 step 目(約 70–100%)
検証モデルは DeepSeek-Coder-6.7B-Instruct、Llama-3.1-8B-Instruct、Gemma-2-9B-Instruct の 3 系統で、アーキテクチャが異なるにもかかわらず同じパターンが観測された。
Faithful レジームと Anti-Faithful レジーム
すべてのモデルが CoT に誠実に依存しているわけではない。Ye らは 2 種類のレジームを区別した。
- Faithful: Llama と DeepSeek は高い正の NLDD を示す。CoT の前半 step に因果的に依存しており、破壊で回答が崩れる
- Anti-Faithful: Gemma は論理 reasoning で 99% の精度を達成しながら、NLDD が −52.5% を示す。CoT を破壊するとむしろ正解確信度が上がる。表出された CoT と内部表現が因果的に切断されている状態
精度だけでは reasoning メカニズムを判断できないという観察は、Lanham et al. (2023) の CoT faithfulness 議論の延長に位置する。
Prefix 系手法への含意
Reasoning Horizon の発見は、Self-Consistency と重み付き多数決 の prefix 系手法群(PoLR、Path-Consistency、Prefix-Confidence Scaling、ST-BoN、Beyond the Last Answer、Prefix Consistency)が共有する「どこで切るか」の問題に物理的な含意を与える。
これらの手法は CoT の prefix を起点に後続を集約するが、切断位置を経験的に決めてきた。Reasoning Horizon の知見を借りれば、\(k^* / L\)(\(L\) は CoT 全長、\(k^*\) は本章で見た 70–85% の臨界点)よりも手前で切ることで、因果的に重要な前半を保持したまま、回答に効かない後半のみを再生成・再集約のシードに使える、という指針が得られる。
逆に言えば、\(k^*\) 以降のトークンは「回答の生成にとって載っているだけ」の冗長 trace であり、prefix 系手法が信頼度推定や confidence 集約に使うべきでない領域である。
Failed-Step Fraction: CoT をグラフとして読む
Feng らの Failed-Step Fraction (Feng ほか 2025年) は、CoT を「テキスト列」ではなく「reasoning graph」として構造分析する。Claude 3.7 Sonnet で各 CoT を Graphviz 形式に変換し(100% のコンパイル成功率)、ノード = 個別の reasoning step、エッジ = step 間の情報の流れ、として有向グラフを構築する。各ノードには Success Step(青)か Failed Attempt(赤)かのラベルが付く。
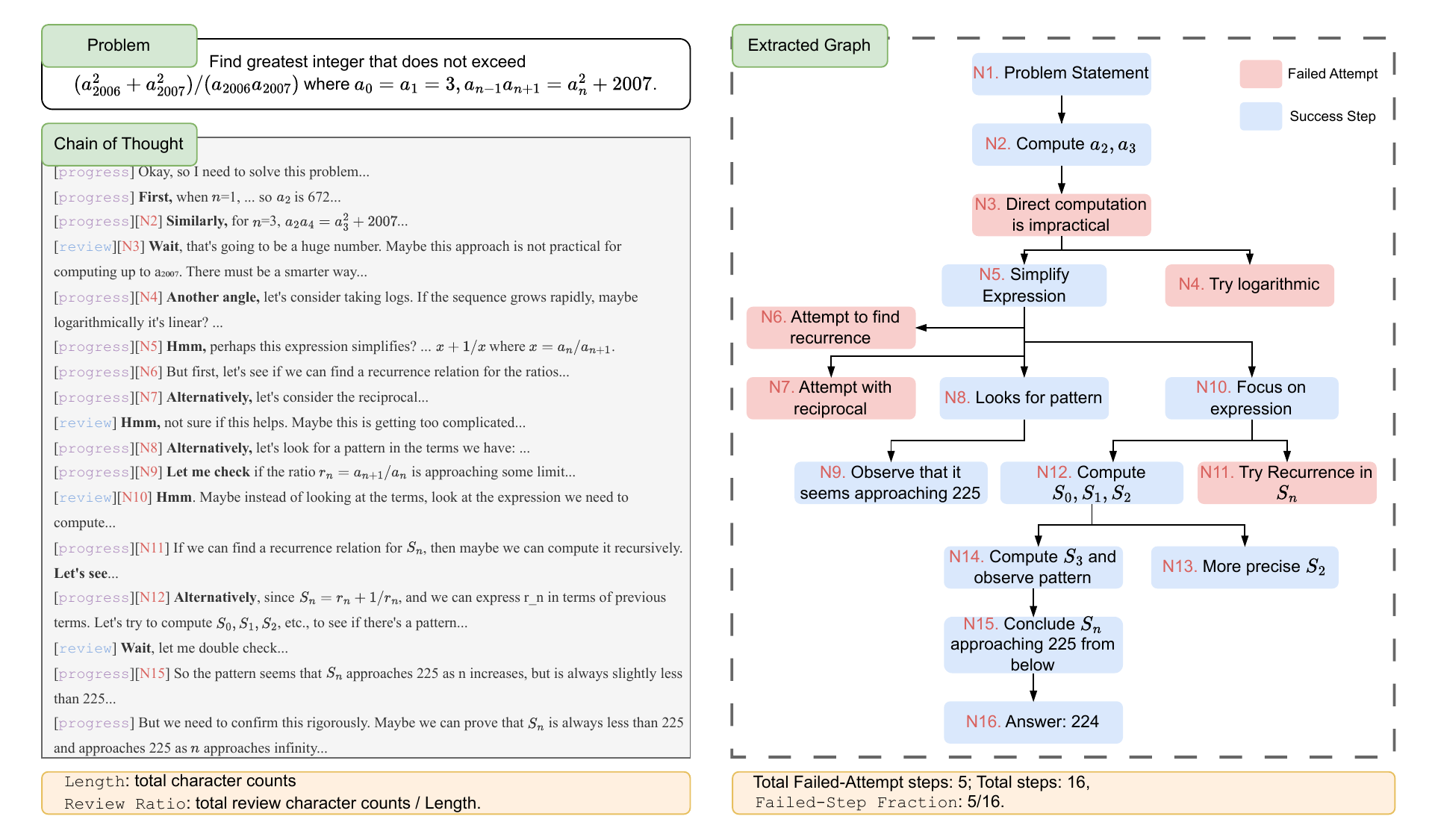
FSF の定義
このグラフから FSF が定義される。
\[ \text{FSF} = \frac{|\text{failed nodes}|}{|\text{total nodes}|} \tag{1}\]
FSF は「reasoning 過程で試みられたが放棄された分岐の割合」を表す。重要なのは、これが trace ごとにローカルに計算される構造指標であり、ground truth の正解ラベルを必要としない点である。
FSF は長さや Review Ratio より強い予測因子
Feng らは約 4,800 の数学 trace と 3,200 の科学 trace を 10 モデルにわたって分析した。条件付き相関分析の結果は直感に反する部分を含む。
- 長さ: 同一問題内では 短い CoT のほうが正答率が高い
- Review Ratio(見直し行動の割合): 見直しが 少ない ほうが正答率が高い
- FSF: 放棄分岐が 少ない ほうが正答率が高く、全モデル・全タスクで一貫して有意
「長い trace = 慎重な思考」「review が多い = 自己検証している」という直観は、データの上では成立しない。長さや review の増加は、行き止まりに何度もぶつかった痕跡である可能性が高く、それを直接捉えるのが FSF である。
Test-time selection としての FSF
FSF を test-time の trace 選別に使う実験も行われた。同一問題に対して複数 trace を生成し、最小 FSF の trace を選ぶ。
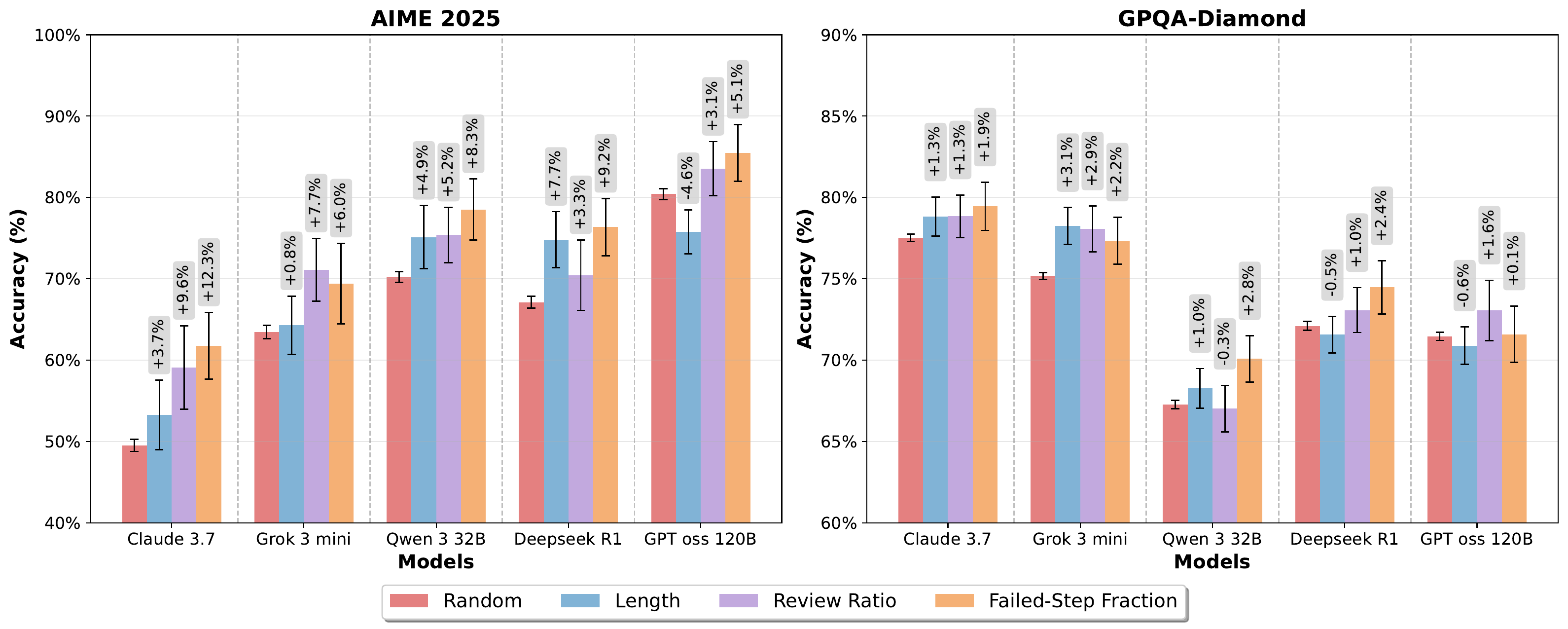
図 3 の AIME 2025 では FSF 基準の選別が Random 比で平均 5–13% の精度向上を達成し、Length 基準や Review Ratio 基準を上回る。GPQA-Diamond でも FSF が概ね最良で、構造的指標が単純指標を支配することを示している。
放棄分岐の除去実験
FSF が単なる相関ではなく 因果的 に重要であることを示すため、放棄された分岐を CoT から物理的に除去する介入実験が行われた。
- DeepSeek R1: 20.89% → 29.42%
- GPT oss 120B: 28.05% → 36.41%
放棄された分岐は単なる無駄ではなく、その後の reasoning にバイアスを与えていた。モデルは過去の失敗を完全には「忘れる」ことができず、放棄した試行の残響が後続の reasoning を歪める。この結果は、CoT の構造を test-time に 書き換える ことで精度を改善できる可能性を示唆している。
再生成系手法との関係
FSF は CoT を外部 LLM でグラフ化して構造特徴を読む手法だが、同じ「trace の安定性」をブラックボックスで近似する候補として、Self-Consistency と重み付き多数決 の Beyond the Last Answer (Hammoud ほか 2025年) や Prefix Consistency (Iwase ほか 2026年) のような再生成系手法が考えられる。再生成系手法は trace の prefix から後続を再生成して結果の一致度を測るが、FSF が高い(分岐と放棄が多い)trace は再生成で同じ分岐パターンを辿りにくく、一致度が低くなる傾向が期待される。両者を統合した経験的比較は未公表で、open question である。
CRV: 内部回路から構造を読む
ここまでの 2 本(Reasoning Horizon、FSF)は CoT の 外部観測(テキスト、介入後の logit、抽出グラフ)を信号源としていた。Zhao らの Circuit-based Reasoning Verification(CRV)(Z. Zhao ほか 2025年) はこれを反転させ、モデル内部の計算グラフ(attribution graph)から構造特徴を抽出する。機械的解釈可能性(Mechanistic Interpretability)の手法を reasoning 検証に応用した初の試みである。
CRV の 4 段階パイプライン
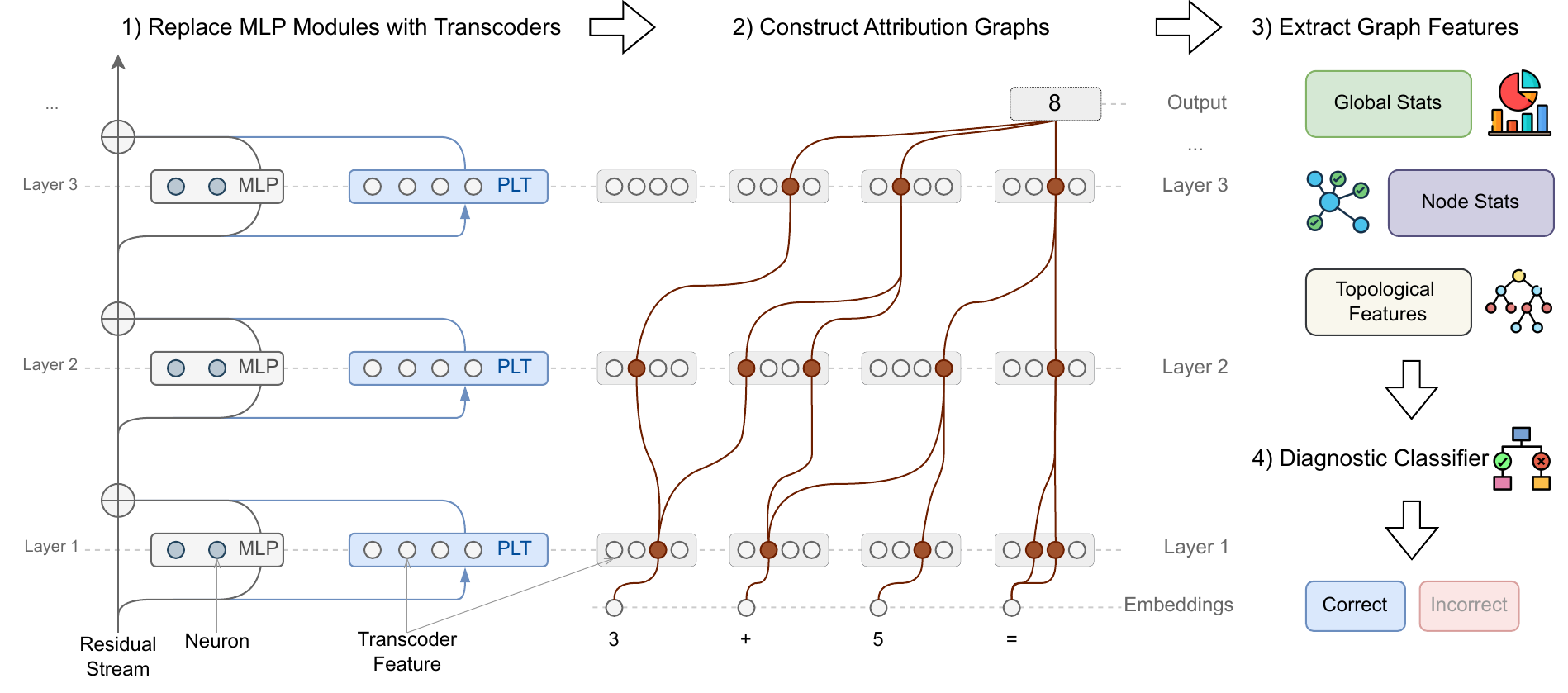
図 4 に示す CRV のパイプラインは次の通り。
- MLP の解釈可能化: Llama 3.1 8B Instruct の各 MLP モジュールを per-layer transcoder(PLT)に置換。PLT は MLP の入出力関数を疎な解釈可能特徴で近似するスパースオートエンコーダの一種
- Attribution graph の構築: 各reasoning step について、入力 token・活性化 PLT 特徴・出力 logit をノード、それらの間の高帰属因果経路をエッジとする有向重み付きグラフを構築
- 構造特徴の抽出: 刈り込んだグラフから 3 種類の特徴を抽出
- Global stats: 活性ノード数、最終 logit 確率、エントロピー
- Node stats: ノード活性化値や影響度スコアの平均・最大・標準偏差、層ごとの活性特徴ヒストグラム
- Topological features: グラフ密度、中心性指標(次数、媒介)、接続性メトリクス
- 診断分類器: 上記特徴ベクトルを入力に、gradient boosting 分類器が step の正誤を予測
ブラックボックス手法を大きく上回る AUROC
CRV は全データセット・全メトリクスで既存のブラックボックスおよびグレーボックス手法を上回った。
| データセット | CRV (AUROC) | 最強ベースライン (AUROC) | 差分 |
|---|---|---|---|
| Synthetic Arithmetic | 92.47 | 76.45 (Energy) | +16.02 |
| Synthetic Boolean | 75.87 | 58.81 (MaxProb) | +17.06 |
| GSM8K | 70.17 | 62.55 (Energy) | +7.62 |
特に Synthetic Arithmetic では、構造化された reasoning が均質な計算 trace を生成するため、エラーの構造的シグネチャが検出しやすい。GSM8K のような自然言語数学では trace の多様性が増し、AUROC は 70.17 まで下がるが、それでもベースラインを 7.62 ポイント上回る。
エラーシグネチャのドメイン特異性
重要な発見の 1 つは、エラーの構造的パターンがドメインに強く依存する ことである。算術タスクで訓練した CRV を GSM8K に適用すると、AUROC は 57.04 まで低下し、ベースラインの Energy(62.55)すら下回る。
論理 reasoning・算術計算・自然言語 reasoning など異なるタスクにおける reasoning エラーは、モデル内部で異なる計算パターンとして発現している。「汎用的な internal verifier」を作る方向には大きな障壁があり、ドメインごとの再訓練が必要になる。
因果介入によるエラー修正
CRV のもっとも注目すべき成果は、検出したエラーの 因果的修正 に成功した点である。
算術式 \(7 \times ((5+9)+7)\) の計算で、モデルは \(7 \times 14 = 98\) と誤計算した(正解は \(14+7=21\)、\(7 \times 21 = 147\))。CRV がこの step を不正確と判定した後、特徴重要度分析により、後層の PLT 特徴(乗算に関連する ID 91814)が異常に高く活性化していることが判明——早まった乗算の発火である。
この特徴の活性を 0 にクランプする forward hook を入れたところ、モデルは正しく \(14+7=21\) を生成し、最終的に正解に到達した。逆に活性不足の特徴を増幅する介入でもエラー修正が可能であることが示された。
つまり CRV が捉える構造的シグネチャはreasoning エラーに 因果的に関与 しており、単なる相関ではない。
限界
CRV は研究ツールとしての価値が高い反面、実用的な検証器としては重い。
- 計算コスト: PLT の訓練、attribution graph の構築、特徴抽出が各 step ごとに必要で、ドロップイン検証器としては high cost
- ドメイン特異性: 上記の通り再訓練が必要
- 対象の限定: 標準的な instruction-tuned モデルの自己回帰 CoT が対象で、探索やバックトラックを伴う高度な reasoning モデルには未対応
外部信号と内部信号の補完関係
CRV と、外部観測ベースのブラックボックス手法(DeepConf 系の logit、Self-Consistency 系の trace 間 agreement、FSF の reasoning graph、prefix 再生成系の一致率など)は、対立するというより 補完的 な関係にある。
- CRV は「正しい reasoning と誤った reasoning はモデル内部で異なる計算パターンを持つ」ことを内部から実証する
- 外部観測手法はその差異を別の信号源で間接的に捉える
CRV の知見は「なぜ外部信号が機能しうるか」のメカニズム的な背景を与える。正しい reasoning は内部的に安定した計算パターンを持ちうるため、外部観測(trace 間の合意、logit、再生成の一致など)にもその痕跡が現れることが期待される。
実用面では、API アクセスのみで動く外部信号系(Self-Consistency と重み付き多数決 参照)が現実的な選択肢であり、CRV はその背後にある内部メカニズムを照らす研究ツールとして位置づけられる。
FSF (Feng ほか 2025年) の reasoning graph と CRV (Z. Zhao ほか 2025年) の attribution graph は、どちらも「グラフ」と呼ばれるが抽象度が根本的に異なる。
- FSF の reasoning graph: CoT テキストを外部 LLM でパースし、reasoning step 間の論理的依存関係をグラフ化したもの。テキストレベルの構造
- CRV の attribution graph: モデル内部のニューロン活性化と情報伝搬経路を可視化したもの。計算レベルの構造
前者は「モデルが何を言ったか」の構造、後者は「モデルがどう計算したか」の構造である。両者を組み合わせることで higher-order な aggregator を作る方向の研究余地は大きい。
Four Habits of Highly Effective STaRs: trace の「形」を分類する
ここまでの 3 本は構造を 連続値の指標(NLDD、FSF、AUROC)で測ってきた。Gandhi らの “Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs” (Gandhi ほか 2025年) はこれを質的に補う研究である。trace の「形」を 4 つの認知パターンで分類し、自己改善する reasoning モデルがどのパターンを備えているかを調べる。
Qwen と Llama の対照
研究の出発点は単純な観察だった。Countdown ゲーム(与えられた数字と四則演算で目標数を作る課題)において、同一の Reinforcement Learning(RL)訓練条件下で Qwen-2.5-3B が Llama-3.2-3B を大幅に上回る。
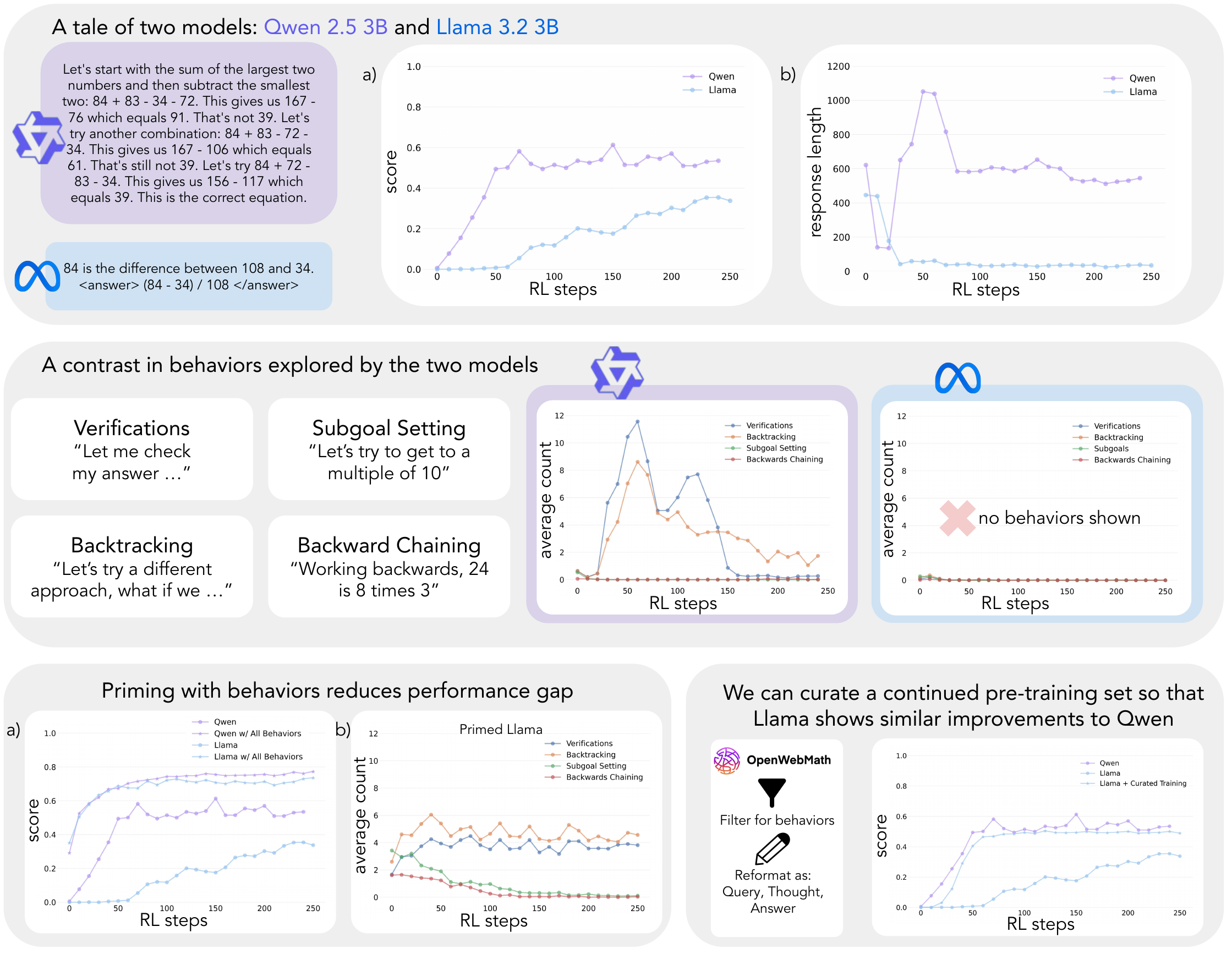
図 5 の上段が示すように、Qwen は score が 0.6 付近まで急上昇するのに対し、Llama は同じ RL を回しても 0.3 付近で頭打ちになる。response length も対照的で、Qwen は trace を伸ばしながら改善を続けるが、Llama は短い trace に留まる。
4 つの認知パターン
中段の “A contrast in behaviors” がこの差の原因を示す。Qwen の trace には 4 つの認知パターンが頻出する。
- Verification: 中間結果が正しいかを確認する自己チェック(例: “Let me check my answer…”)
- Backtracking: 行き詰まったときに前 step に戻り別アプローチを試みる(例: “Let’s try a different approach, what if we …”)
- Subgoal setting: 大きな問題を小さな部分問題に分解する(例: “Let’s try to get to a multiple of 10”)
- Backward chaining: 目標から逆算して必要な中間結果を特定する(例: “Working backwards, 24 is 8 times 3”)
Llama にはこの 4 つがほぼ存在しない。中段右の plot で Llama 側のすべての behavior count が 0 付近に張り付いている。
reasoning 行動は「正解そのもの」よりも重要
研究のもっとも驚くべき発見は、reasoning 行動の存在が正解の有無よりも重要 という点だった。4 つの認知パターンを含むが最終回答が 不正解 であるデータで訓練されたモデルは、正しい認知パターンを含まない 正解データ で訓練されたモデルと同等以上の性能を示した。
つまりモデルが自己改善する能力は、正解を暗記することではなく、「効果的な reasoning の やり方 を獲得すること」に依存する。
行動 priming で gap が縮まる
図 5 の下段は priming 実験の結果である。4 つの認知パターンを含む例で Llama を事前学習すると(“Llama w/ All Behaviors”)、Qwen に近い軌道で自己改善を始める。さらに認知パターンを強調した OpenWebMath サブセットで継続事前学習すれば(右下の “Llama + Curated Training”)、score gap は大きく縮む。
この結果は、4 つの認知行動が 学習可能 であり、かつ RL による自己改善の 前提条件 であることを示している。base モデルが備える認知パターンの差が、その後の RL post-training の天井を決めてしまう。
集約系手法との関係
trace の「形」を質的に分類する Four Habits は、Reasoning Horizon / FSF / CRV の定量的指標に対して、それらが 何を測っているか の認知的解釈を与える位置にある。Gandhi らの 4 行動(Verification、Backtracking、Subgoal setting、Backward chaining)は trace の内側に内在化された認知パターンとして現れるが、Self-Consistency と重み付き多数決 で扱った集約系手法は、これらが外部観測可能な信号として trace の表面に漏れ出てくる程度を測っているとも読める。たとえば backtracking が頻発する trace は FSF が高く、prefix を起点とした再生成の挙動も不安定になる方向に動きうる。
4 つの視点の統合
本章で扱った 4 本は、いずれも「reasoning の構造を inference-time に測る」という共通モチーフを別の切り口で具体化している。表 2 に整理する。
| 研究 | 分析対象 | 核心的知見 | 集約系への示唆 |
|---|---|---|---|
| Reasoning Horizon (Ye ほか 2026年) | Causal influence decay | \(k^*\) 以降のトークンは因果的に空 | prefix 系手法の切断位置に物理的根拠 |
| FSF (Feng ほか 2025年) | Text-level reasoning graph | 放棄分岐の割合が長さ・review より強い予測因子 | 再生成系手法のブラックボックス近似候補 |
| CRV (Z. Zhao ほか 2025年) | Internal attribution graph | 正/誤の step は内部回路が異なる(AUROC 92.47) | 外部信号が機能するメカニズム的背景 |
| Four Habits (Gandhi ほか 2025年) | Cognitive behavior patterns | 4 行動の存在が正解の有無より重要 | 集約系信号の認知的解釈 |
集約系との相補性
本章の手法群は Self-Consistency と重み付き多数決 で扱った集約系と 直交 している。集約系は「複数 trace の合意」を信号源にするのに対し、本章の手法は「1 つの trace の構造」を信号源にする。原理的には組み合わせ可能で、たとえば次のレシピが成立する。
- 構造的選別 + 集約: 各 trace の FSF を計算し、FSF が閾値以下の trace のみで加重多数決を行う
- 構造的早期停止: Reasoning Horizon に従って \(k^*\) で打ち切り、その時点までの prefix で Self-Consistency を実行
- 内部 + 外部 + 認知: CRV の internal signal、prefix-based 系の external signal、Four Habits の cognitive pattern を入力とする meta-aggregator を学習
このように、構造的指標と集約的指標は higher-order の信号統合の余地を残している。
残された問い
4 本の研究はそれぞれに open question を抱えている。
- Reasoning Horizon: Anti-Faithful レジーム(Gemma)でも \(k^*\) という概念が同じ意味を持つのか。CoT と内部表現が因果的に切断されているなら、表出された CoT 上の \(k^*\) は何を測っているのか
- FSF: 外部 LLM(Claude 3.7 Sonnet)でのグラフ抽出に依存している点。グラフ抽出器の精度・一貫性が FSF の上限を決めている。Self-hosted な light-weight 抽出器の研究が必要
- CRV: 計算コストとドメイン特異性。研究ツールとしての価値は確立されたが、実用検証器としての位置づけは未定
- Four Habits: 認知パターンの定義は heuristic に依存する。4 つで足りるのか、より粗いか細かい分類があり得るのか、ドメインを跨ぐ普遍性はあるのか
inference-time に reasoning を「読む」ということ
集約系(Self-Consistency と重み付き多数決)、信頼度推定(Confidence と Uncertainty)、test-time compute scaling(Test-Time Compute Scaling)と並んで、本章で扱った構造的アプローチは inference-time に reasoning trace から信号を取り出す系統の 4 番目の柱を形成しつつある。
- 集約系: 複数 trace の 合意 を測る
- 信頼度系: 単一 trace の token 分布 を測る
- compute scaling 系: trace 本数や長さの 予算配分 を決める
- 構造系(本章): 1 trace の 形 を測る
4 系統が独立に同じ問題——「ground truth なしに reasoning の正しさをどう推定するか」——に異なる角度から取り組んでいる点が、現代の reliable reasoning 研究の特徴である。本章の構造的アプローチは、CoT を均質な token 列としてではなく、因果勾配・分岐構造・内部回路・認知パターンを持つ 構造化された対象 として扱うことで、長さや confidence では捉えられない新しい信号軸を開いた。