Tree Search と MCTS
Chain-of-Thought(CoT)を一本のシーケンスではなく木構造として扱い、各ノードで複数の continuation を展開・選別する。Monte Carlo Tree Search(MCTS)、Tree-of-Thoughts(ToT)、beam search といった古典探索アルゴリズムを大規模言語モデル(Large Language Model, LLM)に持ち込む研究は AlphaGo 以来の系譜を引き継ぎつつ、2025–2026 年に再び大きな更新を迎えた。
本章では、2025–2026 年に登場した木探索系手法を 7 つの軸で整理する。
- MCTS の代表手法: AlphaMath / rStar-Math の系譜
- wider vs deeper の動的選択: AB-MCTS が拓いた branching 制御
- 検証粒度の制御: VG-Search が示した beam search と Best-of-N の連続的接続
- uncertainty-based 分岐: 価値関数の点推定から分布推定、policy entropy への移行
- verifier-free / lightweight verifier 系統: PRM への依存を減らす自己評価アプローチ
- faithfulness 警鐘: 「深い trace」と「実際の意思決定」の乖離
- 効率系: 計算予算を意識した実装最適化
最後に、tree search を probabilistic inference として捉え直す動きにも触れる。
CoT を木として扱う
LLM の reasoning を木として扱う動機は単純である。サンプリング温度を上げて単一 chain を多く引いても、誤った前提に乗ったまま冗長な reasoning を続ける trace は救えない。木構造ならば、誤りに気づいた時点で別の枝に切り替えられる。
LLM の木探索アルゴリズムは概ね 3 つの要素で記述できる (Wei ほか 2025年)。
- Search Mechanism: どのノードを展開するか(MCTS の UCB、beam search の top-k、A* のヒューリスティック等)
- Reward Formulation: 各ノードや trajectory にどう価値を割り当てるか(PRM、自己評価、consistency 等)
- Transition Function: ノードから次ノードへの遷移単位(token、step、思考タイプ等)
サーベイ (Wei ほか 2025年) はこの 3 軸で既存手法を分類し、test-time scaling と self-improvement を統一的に扱う概念地図を提供する。
ノードの意味は論文ごとに違う
上の callout で挙げた 3 軸のうち、Transition Function 軸 (= ノードから次ノードへの遷移単位) は、実は LLM tree search 論文を横断する際の最大の混乱源である。同じ「tree」「node」を使っていても、ノードが何を表すかは論文ごとに大きく分かれる。本書で扱う主要手法を整理すると、ノードの意味は次の 7 系統に分かれる。
| 系統 | ノードが表すもの | 境界の決め方 | 代表例 |
|---|---|---|---|
| (α) Reasoning step | 1 つの推論ステップ (1 文 or 1 段落) | 改行 / step splitter | ToT (Yao ほか 2023年), MITS (J. Li ほか 2025年) |
| (β) Semantic marker | 次の transition marker までのチャンク | “Wait” / “Therefore” 等の語彙 | Beyond the Last Answer (Hammoud ほか 2025年) |
| (γ) Fixed-length window | \(L\) token 分のチャンク or 比率 \(\tau\) | 固定長または比率 | Path-Consistency (Zhu ほか 2024年), PoLR (Jindal ほか 2026年), Prefix Consistency (Iwase ほか 2026年) |
| (δ) MDP state | 問題空間の状態 | domain-specific encoder | Reasoning via Planning (RAP) など planning 系 |
| (ε) 完全候補解 | 1 つの full reasoning trace or code candidate | ノード = whole solution | AB-MCTS (Inoue ほか 2025年) (Code Contest 等) |
| (ζ) Aggregator node | 子集合の統計量を集約する仮想ノード | non-leaf 自体が意味を持つ | AB-MCTS (Inoue ほか 2025年) の GEN ノード |
| (η) Question / sub-problem | 問題の reformulation や sub-question | LLM が出す sub-question | Decomposed Prompting 系 |
ノードの意味が違うと、(i) 同じ “branching factor” や “depth” の比較不能、(ii) verifier が要求する粒度の違い、(iii) compute budget の単位 (LLM call 回数 vs token 回数) の変化、という形で fair comparison を難しくする。本章で扱う各手法を読む際は「ノード = 何」を意識すると見通しが利く。特に Self-Consistency と重み付き多数決 の prefix-based 手法 (γ 系統) と、本章の (α) Reasoning step 系の手法を比較する際、両者の “node” が指す対象が異なる点に注意する。
ToT と探索アルゴリズムの選択
LLM tree search の foundational 論文は Tree of Thoughts (ToT) (Yao ほか 2023年) で、後続研究の多くがこの枠組みを継承する。ToT は次の 4 部品で記述される。
- Thought decomposition: 問題を「1 思考 = 1 中間ステップ」の単位に分割する設計
- Thought generator \(G(p_\theta, s, k)\): 状態 \(s\) から \(k\) 個の候補思考を sampling
- State evaluator \(V(p_\theta, S)\): LLM 自身に「この state は有望か」を聞いて scalar を返す
- Search algorithm: BFS / DFS / Beam Search のいずれかで木を探索
すなわち ToT は「LLM = policy + value function」を兼ねる self-evaluation 構造で、explicit な LLM evaluator が探索を駆動する。original 論文では実験タスクごとに探索アルゴリズムを使い分けている。
| タスク | 採用 search algorithm | 設定 |
|---|---|---|
| Game of 24 | BFS with top-\(b\) keep | \(b = 5\) (実質 Beam Search) |
| Creative Writing | BFS | \(b = 1\) (ほぼ greedy) |
| 5×5 Mini Crosswords | DFS | backtracking 付き |
つまり ToT は 枠組みであって単一アルゴリズムではない。後続論文では search algorithm を明示するために ToT-BS (Beam Search), ToT-DFS, ToT-BFS のような合成名が使われる。文献を読む際、単に「ToT」とだけ書かれていても、実際にどの探索アルゴリズムが採用されているかは実験設定を見て確認する必要がある。
MCTS と ToT の違い
ToT は MCTS ではない。両者は別の探索アルゴリズム系統で、本章で扱う手法群も大きくこの 2 系統に分かれる。MCTS は古典的に 4 段階 cycle を回す。
- Selection: 既存ノードから UCB / Thompson sampling 等で子を選び降下
- Expansion: leaf に到達したら新しい子を追加
- Simulation (rollout): 新しい子から最終 outcome まで random rollout
- Backpropagation: rollout の結果を root まで遡って全祖先の統計量を更新
ToT には rollout も backpropagation も無い。各 node で LLM evaluator を 1 回呼んで scalar を取り、BFS / DFS / Beam で score の高い枝に進む。両者の差を一表にすると次のようになる。
| 項目 | MCTS | ToT |
|---|---|---|
| Selection 規則 | UCB / Thompson sampling (統計的) | LLM evaluator の scalar (heuristic) |
| Rollout | あり (random simulation で leaf まで降りる) | なし (1 ノード = 1 LLM 評価) |
| Backpropagation | あり (rollout 結果を全祖先に伝搬) | なし (各 node 独立) |
| Value 更新 | \(N(v), W(v)\) 等の統計量を逐次更新 | 1 回の LLM 評価のみ |
本章で扱う LLM tree search 論文はこの 2 系統に大別できる。
- MCTS 系: AlphaMath (G. Chen ほか 2024年)、rStar-Math (Guan ほか 2025年)、AB-MCTS (Inoue ほか 2025年)、SC-MCTS* (Gao ほか 2024年)
- non-MCTS heuristic 系: ToT 系 (Yao ほか 2023年)、Reasoning via Planning (RAP)、MITS (J. Li ほか 2025年) (PMI で beam search)、CMCTS (Lin ほか 2025年) (名前に MCTS と入っていても rollout を伴う古典 MCTS とは限らない点に注意)
後述する VG-Search (H. M. Chen ほか 2025年) や UATS (Song ほか 2026年) / UVM (Yu ほか 2025年) の議論を読む際は、対象手法がどちらの系統に属するかを意識すると整理が利く。
Reward の与え方が tree search の性能を支配することは、後述する PRM への懐疑 (Cinquin ほか 2025年) や verifier-free 系の台頭 (M. Wu ほか 2025年; Rakhsha ほか 2025年) でますます鮮明になっている。
MCTS の代表手法
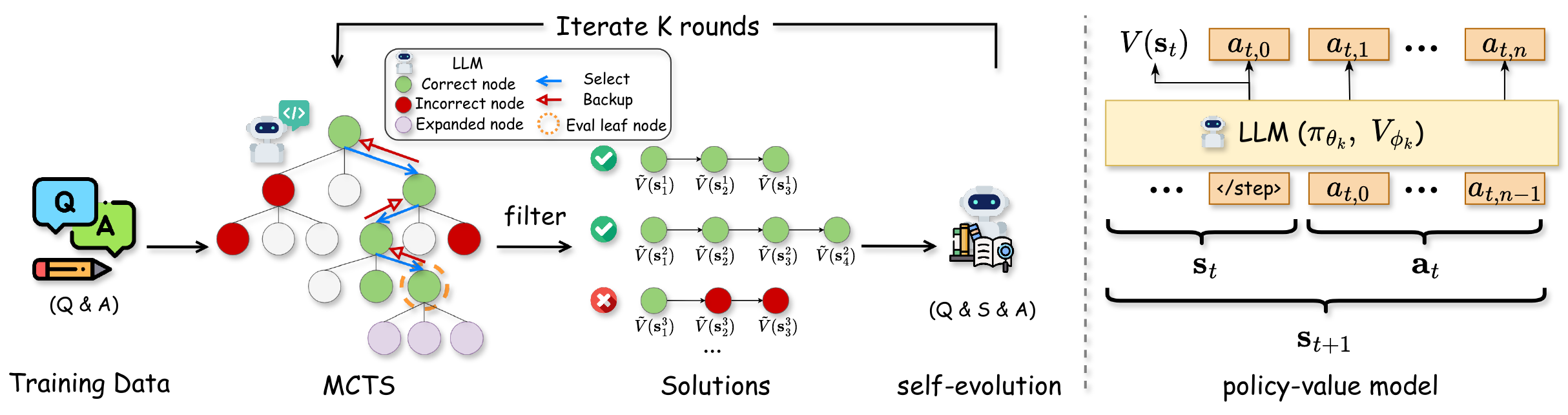
LLM × MCTS の系譜の起点として広く参照されるのが AlphaMath (G. Chen ほか 2024年) である。MCTS rollout の ground-truth 一致率を value としてアノテーション不要の Process Reward Model(PRM)を学習し、policy と value を交互に改善する。AlphaGo 風の self-play 構造を数学問題に持ち込んだ点で、後続の MCTS-for-reasoning 研究の参照点になっている。図 1 に全体パイプラインを示す。
rStar-Math (Guan ほか 2025年) はこの系譜を 7B 規模の small language model(SLM)でさらに推し進め、AIME 2024 で 53.3%(8/15 問正解、o1-preview を上回る)を達成した。図 2 に method overview を示す。
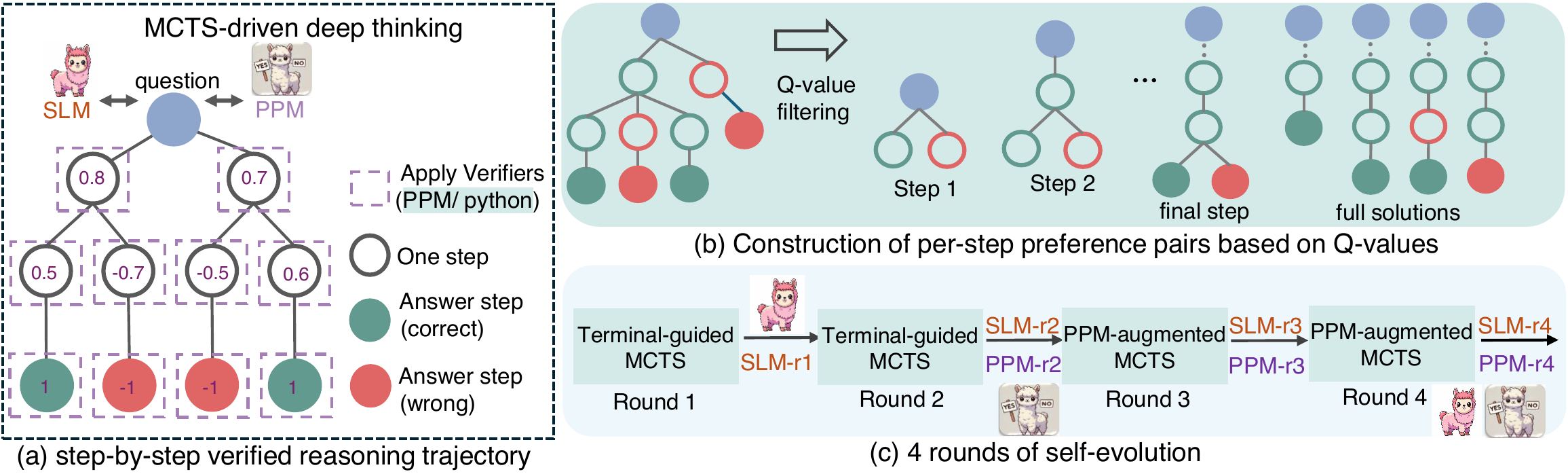
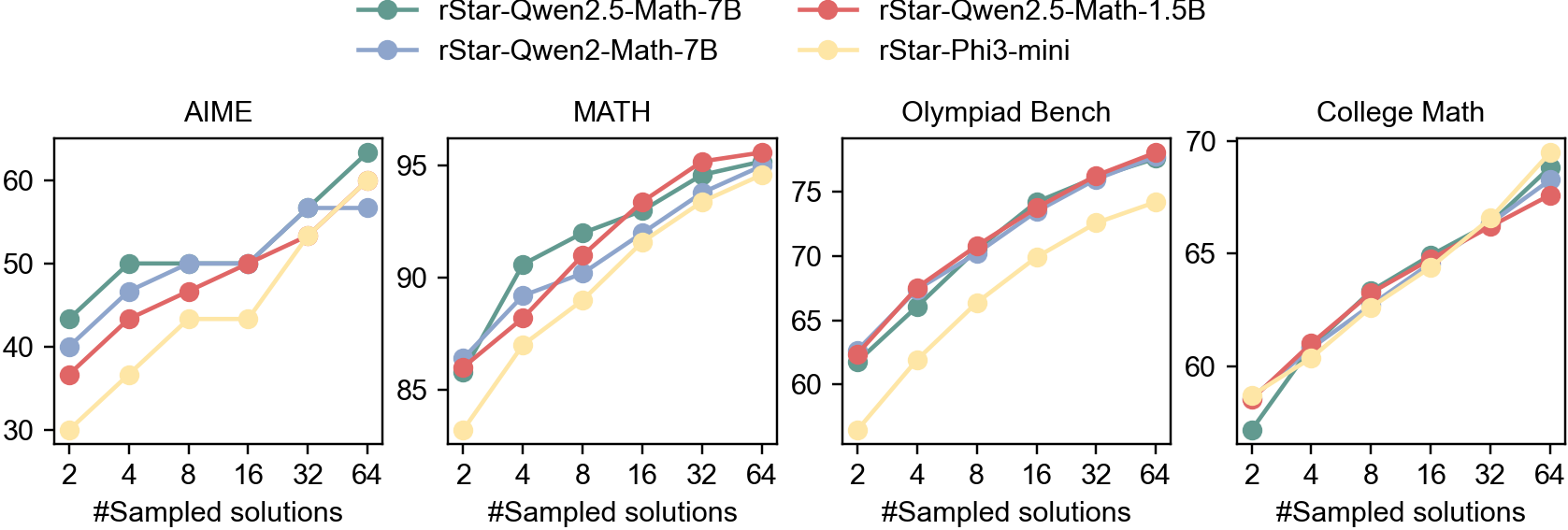
図 2 の self-evolution は AlphaMath(図 1)の policy-value 交互更新を MCTS と PPM 双方に拡張したものと読める。MCTS sampling 数を増やしたときの pass@K 性能を 図 3 に示す。Sampling 数の増加に伴い AIME / MATH / Olympiad / College Math すべてで対数的にスケールし、64 サンプルで AIME 60% 超に到達する。
rStar-Math の貢献は 3 点ある。
- Code-augmented CoT data 合成: MCTS rollout で得た trajectory を Python 実行で検証し、訓練データとして使う
- Score annotation 不要の Process Preference Model(PPM)学習: 数値スコアではなく rollout の Q 値の相対順序からペアワイズで PPM を訓練
- Policy と PPM の自己進化(self-evolution): 4 ラウンドの iterative training で性能を引き上げる
7B SLM が o1-preview を上回ったという結果は、データ生成パイプラインに MCTS を組み込むことで verifier 不要に近い形で深層 reasoningが学習できることを示し、後続の DeepSearch (F. Wu ほか 2025年) などに直接影響した。
SC-MCTS* (Gao ほか 2024年) は contrastive decoding の原理に基づく解釈可能な reward model と speculative decoding による高速化を組み合わせ、Blocksworld の planning タスクで Llama-3.1-70B + SC-MCTS* が o1-mini を平均 +17.4% 上回ったと報告する。MCTS の 3 要素のうち reward と inference 速度を同時に改良した例である。
Wider vs Deeper の動的選択
MCTS の branching factor をどう決めるかは古典的に難しい問題で、LLM 文脈では「同じノードからもう一度サンプリングする(wider)か、子ノードを進める(deeper)か」を online で決める必要がある。
AB-MCTS(Adaptive Branching MCTS) (Inoue ほか 2025年) はこの問いに Thompson sampling で答える。各ノードに対し新しい子を生成する「展開腕」と既存の子を選ぶ「継続腕」をベルヌーイ・ガウス混合の Bayesian 事後で扱い、ノードごとに最適な branching を自動決定する。NeurIPS 2025 Spotlight。図 4 に既存手法との対比を示す。
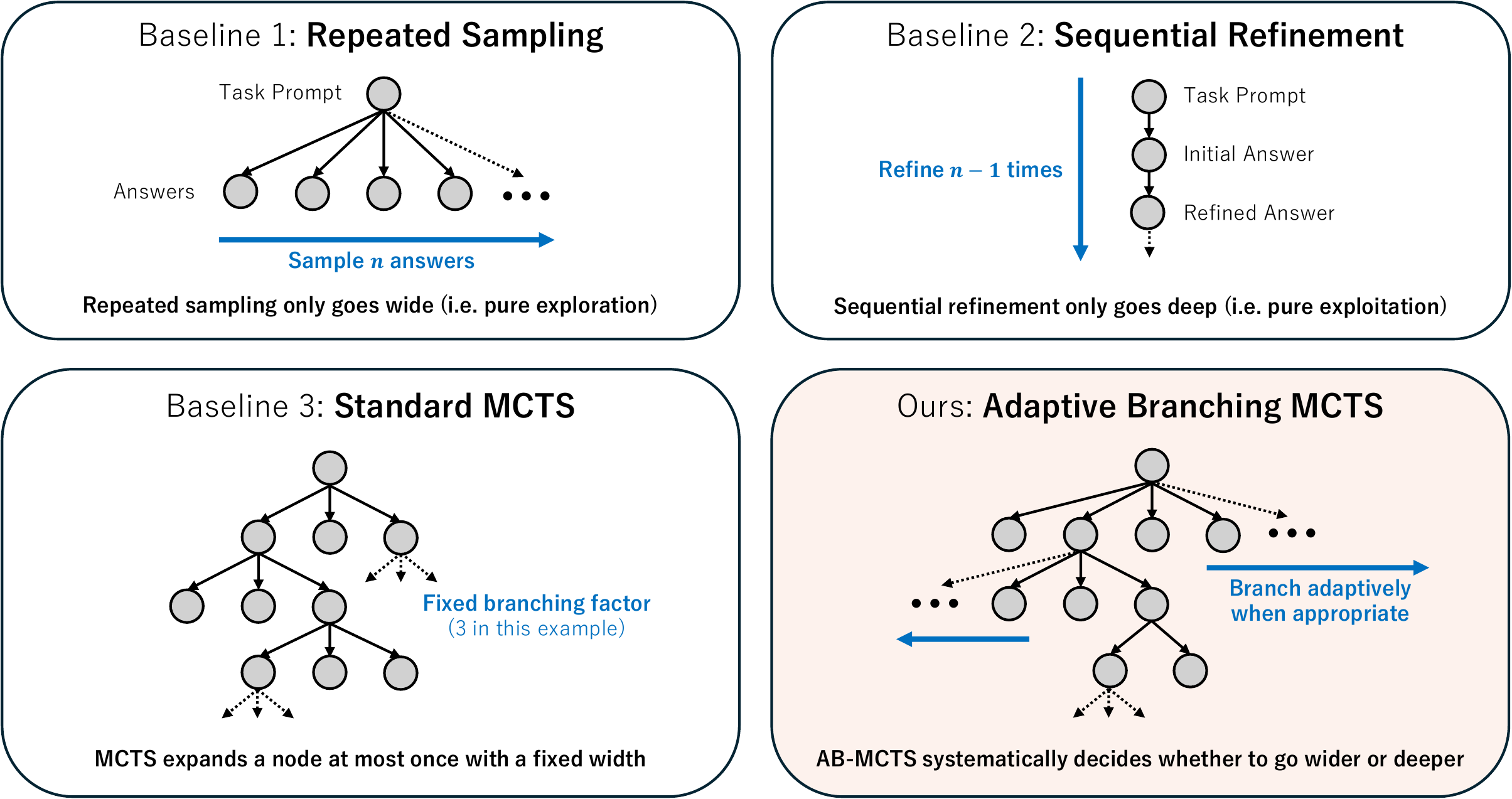
図 4 の右下が示すように、AB-MCTS では「同じノードから追加で子を生む」操作と「既存の子を深掘りする」操作を Bayesian 事後の Thompson sampling で per-node に切り替える。
AB-MCTS の wider vs deeper 制御は「どこに次のサンプルを置くか」を不確実性で決める枠組みである。後述する UATS (Song ほか 2026年) や UVM (Yu ほか 2025年) は、この発想を value 関数側の不確実性に持ち込んで一般化したと解釈できる。
検証粒度の制御
Wider vs deeper が「どこにサンプルを置くか」の問題なら、検証粒度(verification granularity)は「どの頻度で verifier を呼ぶか」の問題である。Beam search は step ごと、Best-of-N は終端のみで検証する。両者は別アルゴリズムとして扱われてきたが、実は 連続スペクトラムの両端 に過ぎない。
VG-Search (H. M. Chen ほか 2025年) は粒度パラメータ \(g\) を導入し、\(g\) ステップごとに PRM で候補を選別する一般形を定義する。\(g=1\) で beam search、\(g=L\)(reasoning path 全長)で Best-of-N、\(1<g<L\) がその中間である。図 5 に概観を示す。
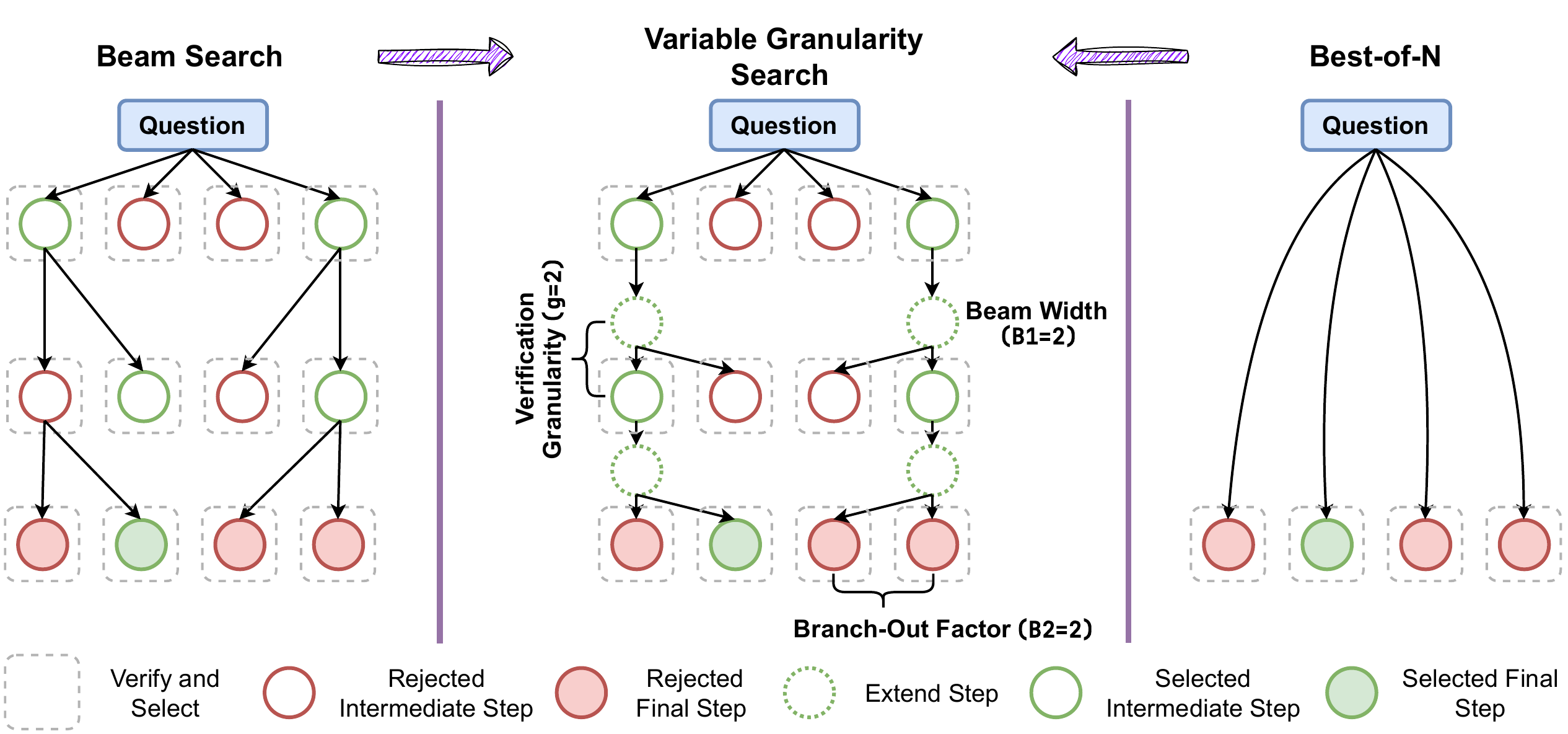
VG-Search の核心的発見は 最適な \(g\) がタスク・計算予算・モデル能力で変わる ことである。
- 難しい問題ほど密な検証(小さい \(g\))が必要。各 step で誤る確率が高く早期軌道修正が要る
- 計算予算が大きい ほど粗い検証(大きい \(g\))で十分。検証器呼び出しを抑えても精度は出る
- 強い生成器 には粗い検証が適する。安定した step を出せる生成器なら頻繁な PRM 呼び出しは無駄
MATH-500(Qwen2.5-Math-7B + Skywork-o1-1.5B verifier)では、適応的 \(g\) 選択が beam search に対し最大 +3.1%、Best-of-N に対し +3.6% の精度向上を達成し、同時に FLOPs を 52% 以上削減した。例えば \(g=3\) で約 \(2^{13}\) FLOPs / 約 88% 精度に達するのに対し、\(g=1\)(beam)は約 \(2^{15}\) FLOPs を要して精度約 87.5% に留まる。検証頻度を下げた方が精度も効率も改善される 領域が存在する。
Uncertainty-based 分岐
PRM の点推定(一つの数値スコア)を value 関数の不確実性分布に置き換える流れが 2025–2026 年に強まった。
UATS(Adaptive Uncertainty-Aware Tree Search) (Song ほか 2026年) は PRM の epistemic uncertainty を Monte Carlo Dropout で推定し、強化学習(Reinforcement Learning, RL)コントローラで計算予算をノードごとに動的配分する。理論的には標準的な search が linear regret なのに対し、uncertainty-aware search は sublinear regret を達成可能と示している。OOD(Out-Of-Distribution)reasoning paths での PRM 暴走を緩和する効果が報告されている。図 6 が UATS の motivation を端的に表す。
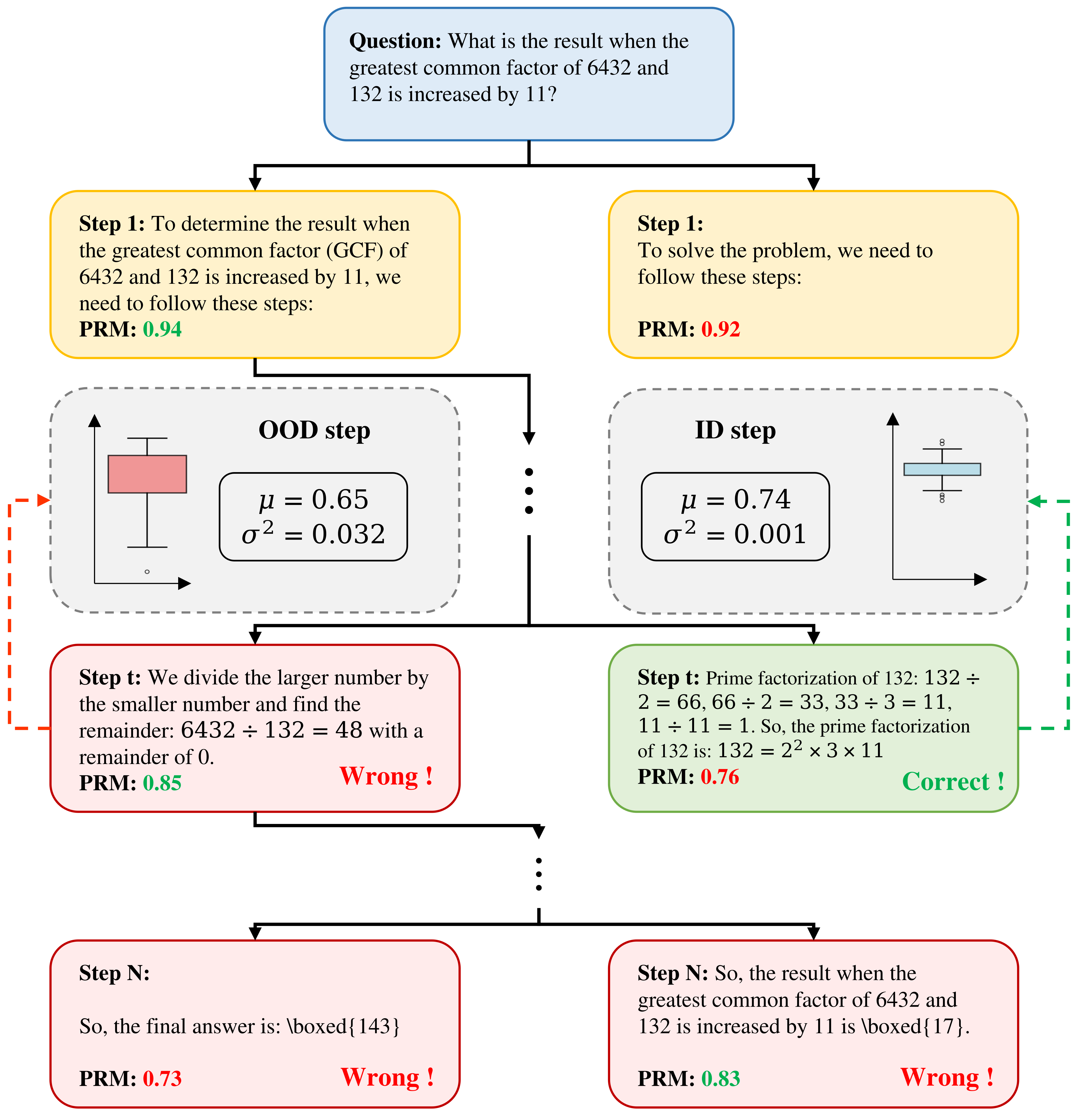
図 6 左側の OOD step では PRM のスコア平均は 0.85 と高いものの分散 \(\sigma^2=0.032\) が大きく、結果として誤った枝(Wrong)に進んでしまう。右側の ID step は逆にスコア 0.76 と低めでも \(\sigma^2=0.001\) と確信を持って正しい枝(Correct)を選べる。点推定の PRM がノードの「真の価値」と乖離する典型例である。
Robust Search with Uncertainty-aware Value Models (Yu ほか 2025年) は、単点の value estimate を value distribution に置き換えた Uncertainty-aware Value Model(UVM)と、その分布から最適候補を選ぶ Group Thompson Sampling を提案する。GSM8K と MATH の in-distribution 評価に加え、AIME25 と Minerva という OOD 設定で verifier failure を大幅に緩和した。
MITS (J. Li ほか 2025年) は entropy ベースの dynamic sampling で「不確実な step に計算を集中する」設計を採用し、pointwise mutual information(PMI)を step-wise スコアに使うことで expensive な look-ahead simulation を回避する。final prediction は PMI と consensus の重み付き多数決。
同じく entropy を分岐 gate に使う Entropy-Gated Branching (X. Li ほか 2025年) は、value 関数ではなく 次トークン予測分布の entropy を直接の分岐シグナルにする。Entropy が閾値を超えた step でのみ複数 continuation を生成し、それ以外は単一パスで進めるという「迷っているところだけ広げる」設計である。図 7 に Normal decoding / Beam search / Entropy-Gated Branching の対比を示す。
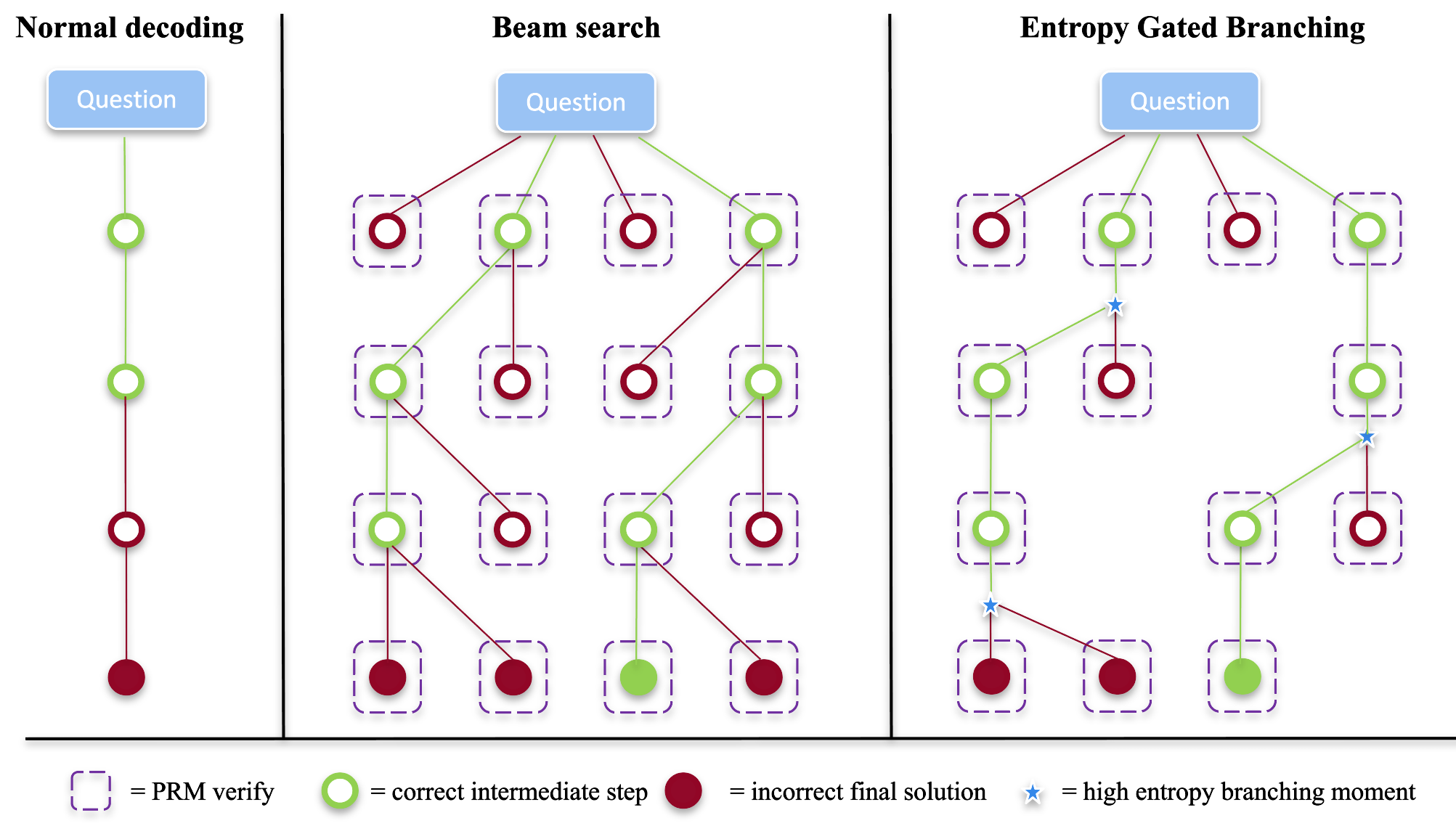
数学 reasoning ベンチマークで標準 decoding に対し +22.6% の精度向上、uniform beam search に対し 31〜75% の高速化を報告する。計算資源を「不確実な step」に集中させる発想は MITS の entropy + PMI と同じ思想で、value 側ではなく policy 側の分布から不確実性を取り出している点が異なる。
価値関数の不確実性ベース分岐の代表的アプローチを 表 4 にまとめる。
| 手法 | 不確実性の表現 | 制御先 |
|---|---|---|
| AB-MCTS (Inoue ほか 2025年) | branching 腕の Bayesian 事後 | wider vs deeper |
| UATS (Song ほか 2026年) | MC Dropout による PRM の epistemic uncertainty | ノード予算配分(RL) |
| UVM (Yu ほか 2025年) | Value distribution + Group Thompson | 候補選択 |
| MITS (J. Li ほか 2025年) | Step entropy + PMI | サンプル数 |
| Entropy-Gated (X. Li ほか 2025年) | 次トークン予測分布の entropy | 分岐するか否か(gate) |
Verifier-free / Lightweight verifier 系統
PRM-guided search の限界 (Cinquin ほか 2025年) が認識されるにつれ、外部 reward model なしに探索を制御する手法が増えている。
SELT(Self-Evaluation Tree Search) (M. Wu ほか 2025年) は外部 reward model を使わず、LLM の内在的 self-evaluation で UCB を再定義した MCTS である。各ノードを atomic subtask に分解し semantic clustering を適用する。MMLU や Seal-Tools で robustness 向上と幻覚抑制を報告。
W2S-AlignTree (D. Zhang ほか 2026年) は弱モデルの step-level signal を強モデルの MCTS guidance として使う weak-to-strong inference-time alignment を提案する。Entropy-Aware PUCT という UCB 改良で trajectory diversity を確保し、Llama3-8B summarization で 1.89 から 2.19(+15.9%)まで品質を引き上げた。AAAI 2026 Oral。
Majority of the Bests(MoB) (Rakhsha ほか 2025年) は reward model が不完全でも「最頻 mode は信頼できる」という観察に立脚する。Best-of-N(BoN)の候補集合から bootstrap subset を作り、各 subset の argmax を取って majority voting する。5 ベンチマーク × 3 LLM × 2 RM のうち 25/30 設定で改善。NeurIPS 2025 Poster。
MoB の「reward は信頼できなくても最頻 mode は信頼できる」は、Self-Consistency と重み付き多数決 の self-consistency (X. Wang ほか 2023年) とほぼ同じ哲学である。木探索の reward design においても「個別のスコアではなく集合的な mode」を信号源にする発想は、verifier-free 化の主軸として広がっている。
CMCTS (Lin ほか 2025年) は action space を understanding / planning / reflection / coding / summary の disjoint 5 種に制約し、PRM と部分順序ルールで non-sensical な遷移を防ぐ。Zero-shot で 7B モデルが 72B baseline を平均 +4.8% 上回ったと報告。verifier そのものを軽量化するのではなく、search 空間を絞ることで PRM への依存度を下げるアプローチである。
PRM-guided 探索の限界
Limits of PRM-Guided Tree Search (Cinquin ほか 2025年) は Qwen2.5-Math-7B-Instruct と純正 PRM を 23 問の数学問題で精査し、PRM-guided な MCTS / beam search / A* / BoN は計算量が増えるのに統計的に BoN を有意に上回らないことを示した。原因は次の 2 点である。
- PRM は state value の悪い近似: 深さに従って信頼性が劣化する
- PRM は OOD に弱い: 分布外問題で系統的に誤評価する
このネガティブ結果は、tree search 自体を否定するというより、PRM への盲信を改める契機となった。本章で扱う verifier-free 系 (M. Wu ほか 2025年; Rakhsha ほか 2025年) や uncertainty-aware 系 (Song ほか 2026年; Yu ほか 2025年) はいずれも、この限界への解として位置付けられる。
詳細は Process Reward Models も参照されたい。
Probabilistic inference framing
Tree search を「探索」ではなく「確率的推論 (probabilistic inference)」として捉え直す動きが COLM 2025 で表面化した。
Particle-based Monte Carlo (Puri ほか 2025年) は inference-time scaling を state-space model の typical set サンプリングと見なし、particle filter(Sequential Monte Carlo, SMC)で実装する。Reward hacking を避ける副次効果があり、Qwen2.5-Math-1.5B が 4 rollout で GPT-4o 超え、7B が 32 rollout で o1 級と報告。図 8 が SMC の各 step を可視化する。
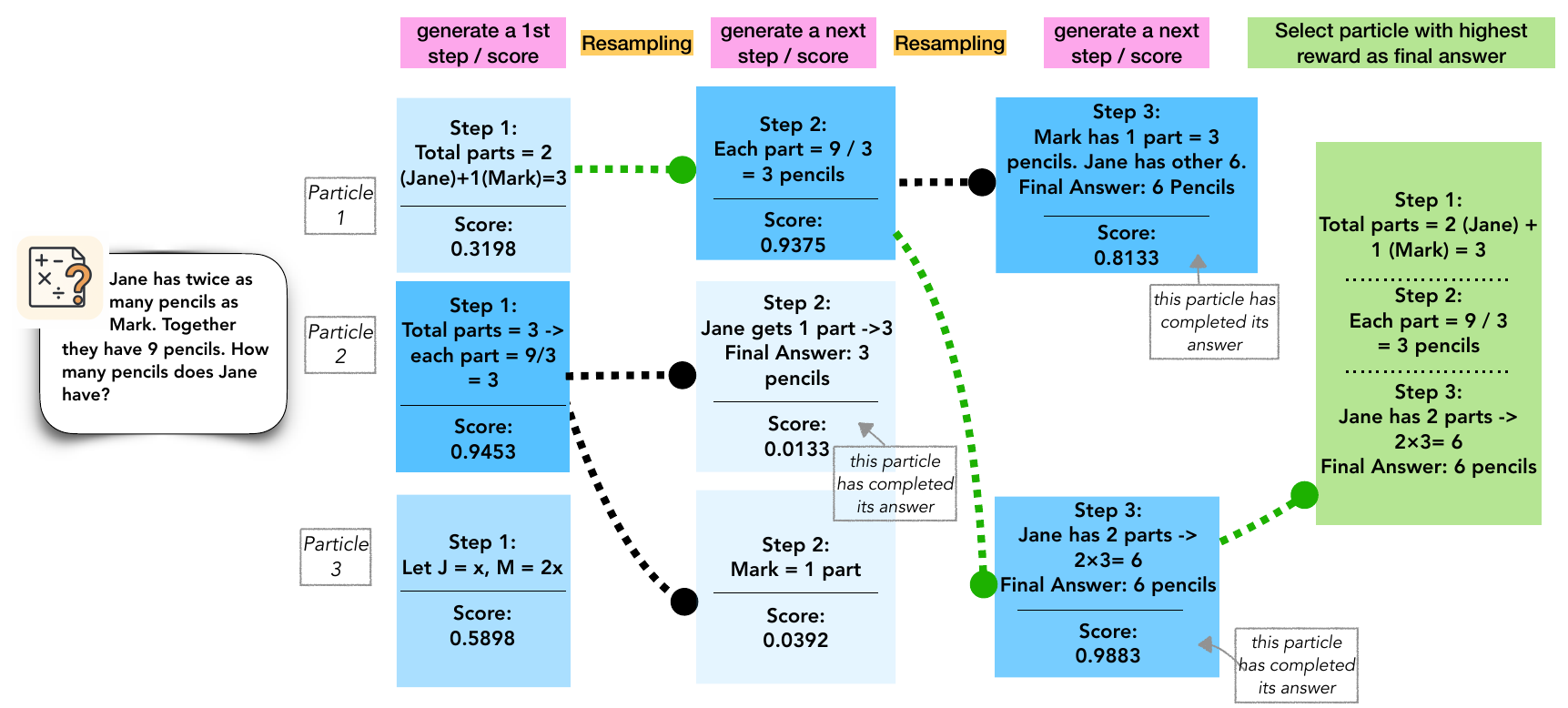
PRM-guided GFlowNets (Younsi ほか 2025年) は MCTS で PRM を自動学習し、GFlowNet で reward に比例した多様サンプリングを実現する。MCTS の greedy 性を補完し、reward 比例サンプリングで経路被覆を上げる。MATH Level 5 で +2.59%、SAT MATH で +9.4% の汎化性能を報告。
Particle-based MC の見方では、MCTS の「rollout して reward で resample する」操作は SMC の proposal-likelihood-resample に対応する。木探索を inference algorithm として再記述できると、Bayesian 文脈の道具(importance sampling、posterior approximation、reward-likelihood の混同問題)が直接適用できるようになる。
Faithfulness 警鐘
木探索で得られる reasoning trace が「実際に深い計算」を反映しているのかという問いに、警告音が鳴り始めている。
Four-in-a-row ゲームで LLM の reasoning trace から search tree を抽出した分析論文。発見は 3 点。
- LLM の探索は人間より浅い
- 性能は depth ではなく breadth で予測される
- 重要: trace 上は深いノードを展開していても、実際の手選択は深いノードを無視する myopic model で説明できる
つまり「深い search を装って実際には浅く決定している」可能性が定量的に示された。chain-of-thought の faithfulness 議論 (Lanham ほか 2023年) の延長線上にある重要な観察である。
図 9 は trace から特定の depth の branch を削除して再度プレイヤに渡すアブレーション実験を示す。
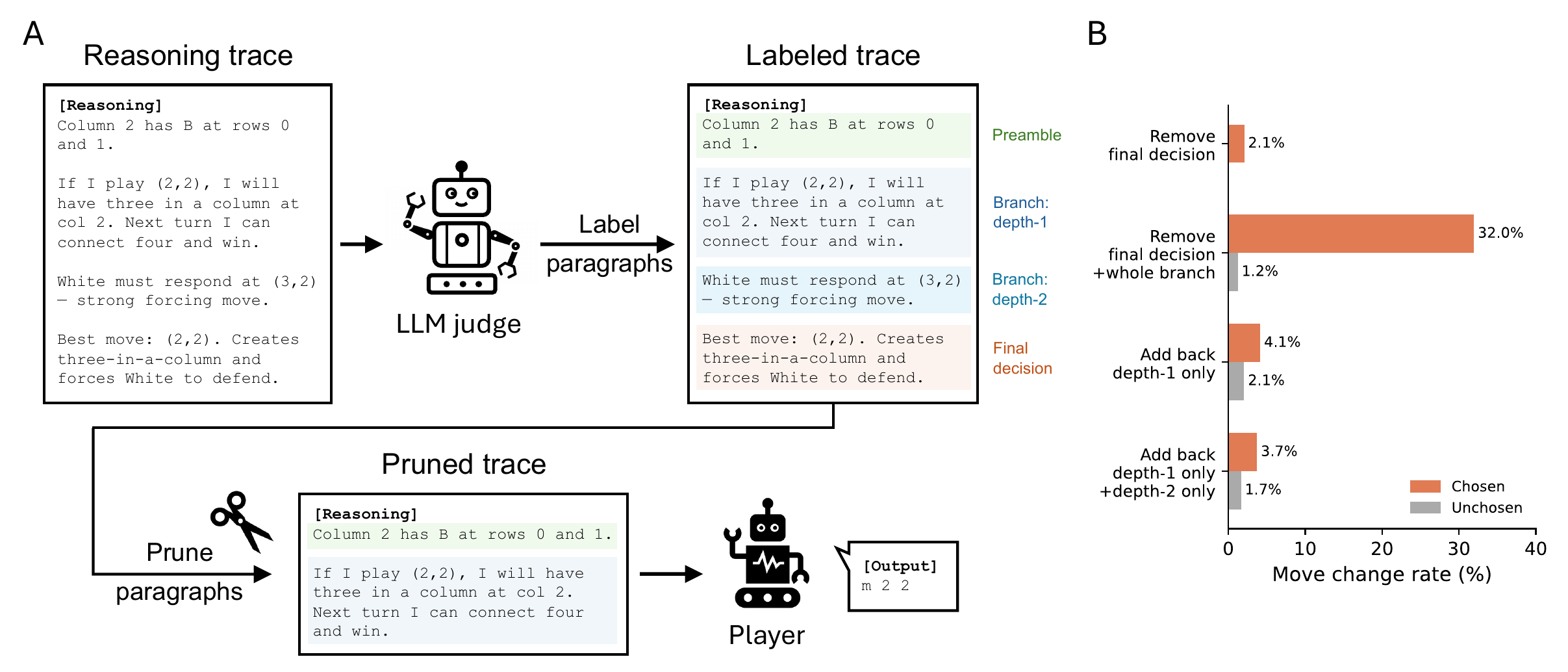
図 9 の右パネルが定量的な証拠である。Final decision とそれに紐づく whole branch を削除した場合は 32% の手が変わるのに対し、depth-1 のみ残して depth-2 を全削除しても move change rate は chosen branch 側で 3.7% に留まる。つまり LLM は深いノードを展開していても、実際には浅い情報だけで手を選んでいる。
この発見は木探索の見せかけの深さに依存した評価設計(trace の長さや展開ノード数を「思考量」と等価視する設計)を再考すべきことを意味する。「rollout 数が多いほど良い」という素朴な scaling 観も、実際には浅い決定の上に積み重ねた無効な計算かもしれない。
Tree-of-Thoughts と Graph-of-Thoughts の系譜
純粋な MCTS の外側に、ToT の RL post-training や graph 拡張、さらに 既存の長い CoT を事後的に木として解析する 方向も登場している。
LCoT2Tree (Jiang ほか 2025年) は long CoT を自動的に階層的なツリーに変換し、Graph Neural Network(GNN)で構造パターンを抽出するフレームワークである。図 10 に変換パイプラインを示す。Sketch 抽出 → step 分割 → step を sketch ノードへ割り当て → 各 step の機能(exploration / verification / backtrack / continuation)をラベル付け → 木を構築する 5 段階で、ノード特徴(深さ・出次数・兄弟数)とエッジ特徴(4 種の機能)を持つ reasoning tree が得られる。
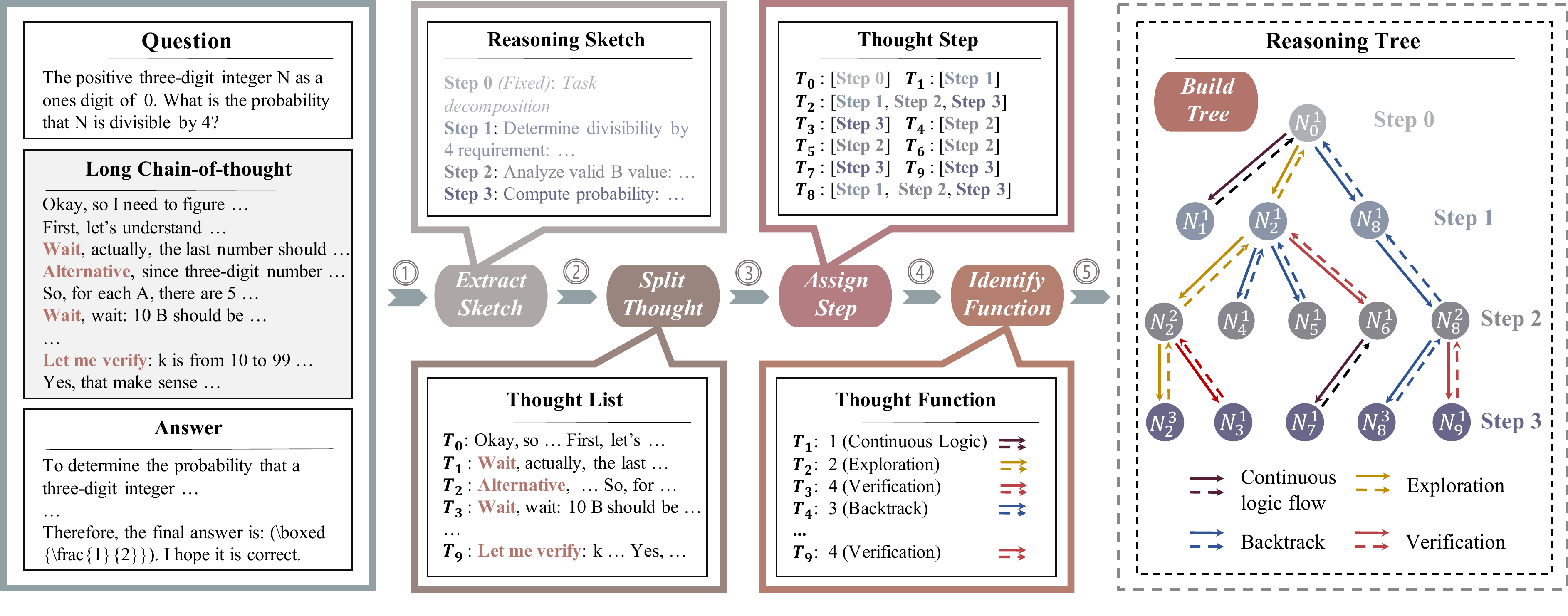
GNN による分析の結果、(1) 探索回数・バックトラック回数・検証回数が正答率と強く相関する、(2) 単純なトークン長より木構造特徴量の方が予測精度が高い、(3) over-branching(過度な分岐)が代表的な失敗パターンとして特定される、という観察が得られた。「分岐は多いほど良い」という素朴な scaling 観への警告であり、本章で扱った AB-MCTS (Inoue ほか 2025年) や Entropy-Gated (X. Li ほか 2025年) の「迷っているところだけ広げる」設計の経験的な裏付けとも読める。
ToTRL (H. Wu ほか 2025年) は「長い CoT は冗長な内省と trial-and-error になりがち」という観察に基づき、ToT 戦略を on-policy RL で puzzle game から学習させる。ToTQwen3-8B が複雑 reasoningで精度と効率の両面で向上したと報告する。
Adaptive Graph of Thoughts(AGoT) (Pandey ほか 2025年) は複雑クエリを再帰的に subproblem に分解し、必要な部分だけ展開する dynamic directed acyclic graph(DAG)を test-time に構築する。CoT / ToT / GoT の長所を統合し、GPQA で +46.2% を training-free で達成。
Forest-of-Thought (Bi ほか 2024年) は複数の独立 ToT を ensemble する forest 構造を取り、sparse activation で関連 path を選択、dynamic self-correction、consensus-guided decision を組み合わせる。Tree レベルでの多様性と consensus voting を両立する設計である。
Policy Guided Tree Search(PGTS) (Y. Li 2025年) は学習済み policy が expand / branch / backtrack / terminate を動的に選択する RL ベース tree search である。math / logic / planning で state-of-the-art を出しつつコストを大幅削減。
効率系
本章で扱った tree search 系手法および前章の Self-Consistency 系を実運用に乗せるには、計算予算と効率化が決定的になる。
FETCH (A. Wang ほか 2025年) は tree search の失敗を 2 つの pitfall に分解する。
- Over-exploration: 意味同等の state が冗長に展開される
- Under-exploration: verifier scoring の高分散で trajectory が頻繁に切り替わる
対策として SimCSE 埋め込みの agglomerative clustering で同等 state を merge、TD(λ) と verifier ensemble で分散を抑える。GSM8K / GSM-Plus / MATH で複数の tree search アルゴリズムを同時に改善した(ACL 2025 long)。
DPTS(Dynamic Parallel Tree Search) (Ding ほか 2025年) は ToT の遅さを「reasoning focus の頻繁な切替」と「冗長な suboptimal 探索」に分解し、Parallelism Streamline と Search-and-Transition Mechanism で 2–4 倍の高速化を達成。Qwen-2.5 / Llama-3 で MATH500 / GSM8K の精度を保ったままスループットを改善する。
A*-Decoding (Chatziveroglou 2025年) は言語モデル生成を partial solution の state-space 上の構造探索とみなし A* を適用する。BoN や particle filtering と同等性能を 1/3 のトークン・30% 少ない PRM パスで達成し、Llama-3.2-1B が 70 倍大きい Llama-3.1-70B に MATH500 / AIME24 で追従する例を示した。
PRM-BAS(PRM-guided Beam Annealing Search) (Hu ほか 2025年) は探索深度に応じて beam width を縮小する annealing schedule に PRM dense reward を組み合わせる。MathVista / MathVision / ChartQA で改善し、大きい固定 beam と同等品質を半分の計算で達成する。
AdaSearch / AdaBeam (Quamar ほか 2025年) は「初期トークンが alignment にとって決定的」という仮説に基づき、計算予算を decaying schedule で前段に集中する block-wise search を提案。Harmlessness +10%、sentiment +33%、math reasoning +24%(対 BoN)を報告。
CATS(Cost-Augmented MCTS) (Z. Zhang ほか 2025年) は予算制約下の planning に explicit cost-awareness を MCTS に組み込み、DFS / BFS / MCTS / bidirectional を統一比較する。GPT-4.1 の baseline が tight budget で失敗するのに対し CATS は精度とコストを両立。
効率系の主要設計を 表 5 にまとめる。
| 手法 | 主な工夫 | 効果 |
|---|---|---|
| FETCH (A. Wang ほか 2025年) | Semantic clustering で over-exploration を抑制 | 複数 tree search 同時改善 |
| DPTS (Ding ほか 2025年) | Parallel KV と transition mechanism | 2–4 倍高速化 |
| A*-Decoding (Chatziveroglou 2025年) | A* ヒューリスティック | トークン 1/3、PRM 30% 減 |
| PRM-BAS (Hu ほか 2025年) | Beam width の annealing | 半分の計算で同等品質 |
| AdaSearch (Quamar ほか 2025年) | 初期 block に予算集中 | 大幅改善(math +24%) |
| CATS (Z. Zhang ほか 2025年) | Explicit cost-awareness | Tight budget で精度維持 |
Self-improvement への展開
木探索結果を training に還流させる動きも顕著である。DeepSearch (F. Wu ほか 2025年) は RLVR が数千 step で頭打ちになる原因をスパースな rollout exploration と特定し、MCTS を訓練ループに統合する。Global frontier selection、entropy-based supervision、caching 付き replay buffer により平均精度 62.95%、5.7 倍の GPU 時間削減を達成した。
RLVR の理論と限界 で扱う「RLVR は base を超えるか」の論争に対し、DeepSearch は MCTS-augmented RLVR が新たな探索シグナルを供給することで頭打ちを破れる可能性を示している。本章で扱った rStar-Math (Guan ほか 2025年) と並んで、test-time search と training-time exploration の境界を曖昧にする方向性を代表する。
章のまとめ
2025–2026 年の tree search 研究は 5 つの主軸で進んだ。
- PRM への懐疑が verifier-free / uncertainty-aware 系を駆動した: Limits of PRM-Guided (Cinquin ほか 2025年) を起点に、SELT (M. Wu ほか 2025年)、MoB (Rakhsha ほか 2025年)、UATS (Song ほか 2026年)、UVM (Yu ほか 2025年) が独立に「外部 verifier への依存を減らす」設計を提示した
- Wider vs deeper の動的制御が標準化した: AB-MCTS (Inoue ほか 2025年) の Thompson sampling 枠組みが、後続の不確実性ベース手法 (Song ほか 2026年; Yu ほか 2025年) に直接波及している
- 検証粒度が連続スペクトラムとして整理された: VG-Search (H. M. Chen ほか 2025年) は beam search と Best-of-N を粒度 \(g\) で接続し、最適粒度がタスク・予算・モデルで変わることを示した
- Entropy-based 分岐が広がった: Entropy-Gated Branching (X. Li ほか 2025年) と MITS (J. Li ほか 2025年) は「迷っている step だけ広げる」設計を確立し、LCoT2Tree (Jiang ほか 2025年) が GNN 分析で over-branching を失敗パターンとして経験的に裏付けた
- Faithfulness 警鐘が積み上がった: Lanham et al. の Early Answering (Lanham ほか 2023年) から Extracting Search Trees (S. Chen ほか 2026年) まで、「LLM が示す深い trace は myopic decision で説明できる」「CoT の途中切断で答えが大きくは変わらない」という観察が trace の長さや展開数を素朴に「思考量」と読む評価設計に再考を迫る
並行して、tree search を probabilistic inference として捉え直す動き (Puri ほか 2025年)、self-improvement に組み込む動き (Guan ほか 2025年; F. Wu ほか 2025年) も加速している。サーベイ (Wei ほか 2025年) が示す「Search Mechanism × Reward Formulation × Transition Function」の 3 軸は、本章で扱った 30 本近い論文を整合的に俯瞰する枠組みとして引き続き有効である。
PRM 系の議論は Process Reward Models、self-consistency や verifier-free voting は Self-Consistency と重み付き多数決、計算予算配分の話題は Test-Time Compute Scaling を参照されたい。