Test-Time Compute Scaling
本章では LLM の推論 (inference) 時に追加計算を投じて精度を上げる手法群を扱う。OpenAI o1 が公開されて以降、「推論時に計算を投じれば精度が上がる」という事実は研究コミュニティの共通認識になった。問いは「上がるかどうか」から「どこに、どう投資するか」に移っている。本章では Chain-of-Thought(CoT)長を制御する手法、難易度に応じて計算を割り当てる手法、システム側の効率化、そして言語空間を離れた latent reasoning まで、Test-time Compute Scaling(TTS)の主要な流れを整理する。
OpenAI o1 以後の構図
Test-time に投じる計算の使い道は、大きく次の 4 つに分類できる。
- CoT を長くする: thinking token の上限を伸ばす、あるいは Best-of-N の N を増やす
- 複数 path を集約する: Self-Consistency 系の多数決・重み付け(Self-Consistency と重み付き多数決)
- 探索する: tree search や MCTS(Monte Carlo Tree Search)で thought 空間を広げる(Tree Search と MCTS)
- verify する: Process Reward Model(PRM)や verifier で候補を選別する(Process Reward Models)
(Snell ほか 2025年) は ICLR 2025 Oral で、PRM ベースの探索と prompt 適応的な response 分布更新という 2 つの test-time 機構を解析し、難易度に応じた「compute-optimal」戦略を取れば 14 倍小さいモデルが同等以上の性能を出せると報告した。同じ 2024 年に (Brown ほか 2024年) が「サンプル数 N を 4 桁スケールさせれば coverage(少なくとも 1 つが正解する率)は log-linear に伸びる」ことを示し、(Yangzhen Wu ほか 2024年) が greedy / majority voting / tree search の組み合わせから推論コストと model size の trade-off を実測した。
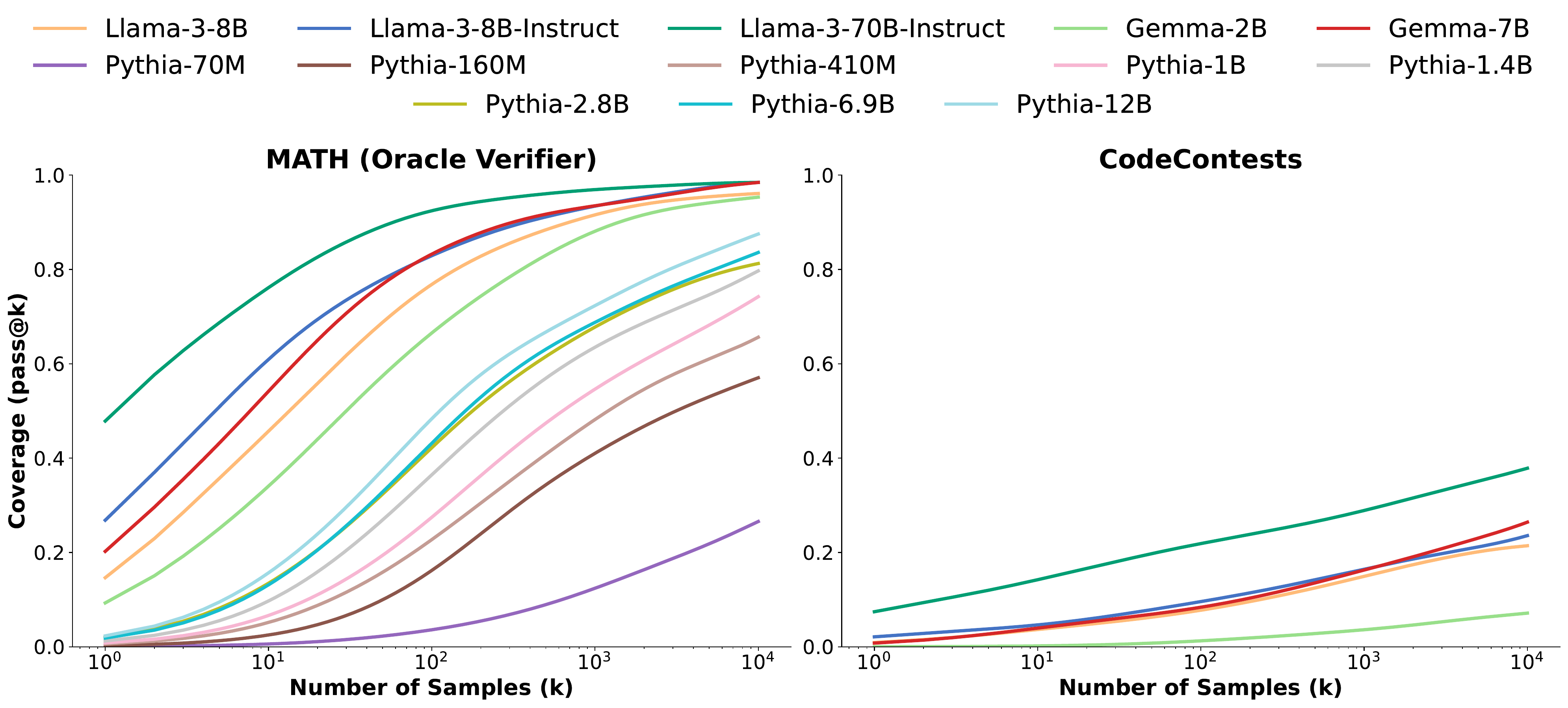
図 1 が示すのは、Best-of-N 的な repeated sampling が「k を増やすほど少なくとも 1 つは当たる確率が log-linear に上がる」という極めて単純な scaling 構造を持つということである。後の節で議論する adaptive allocation 系は、この素朴な scaling を「どこで停めるか」によって効率化する試みと位置付けられる。
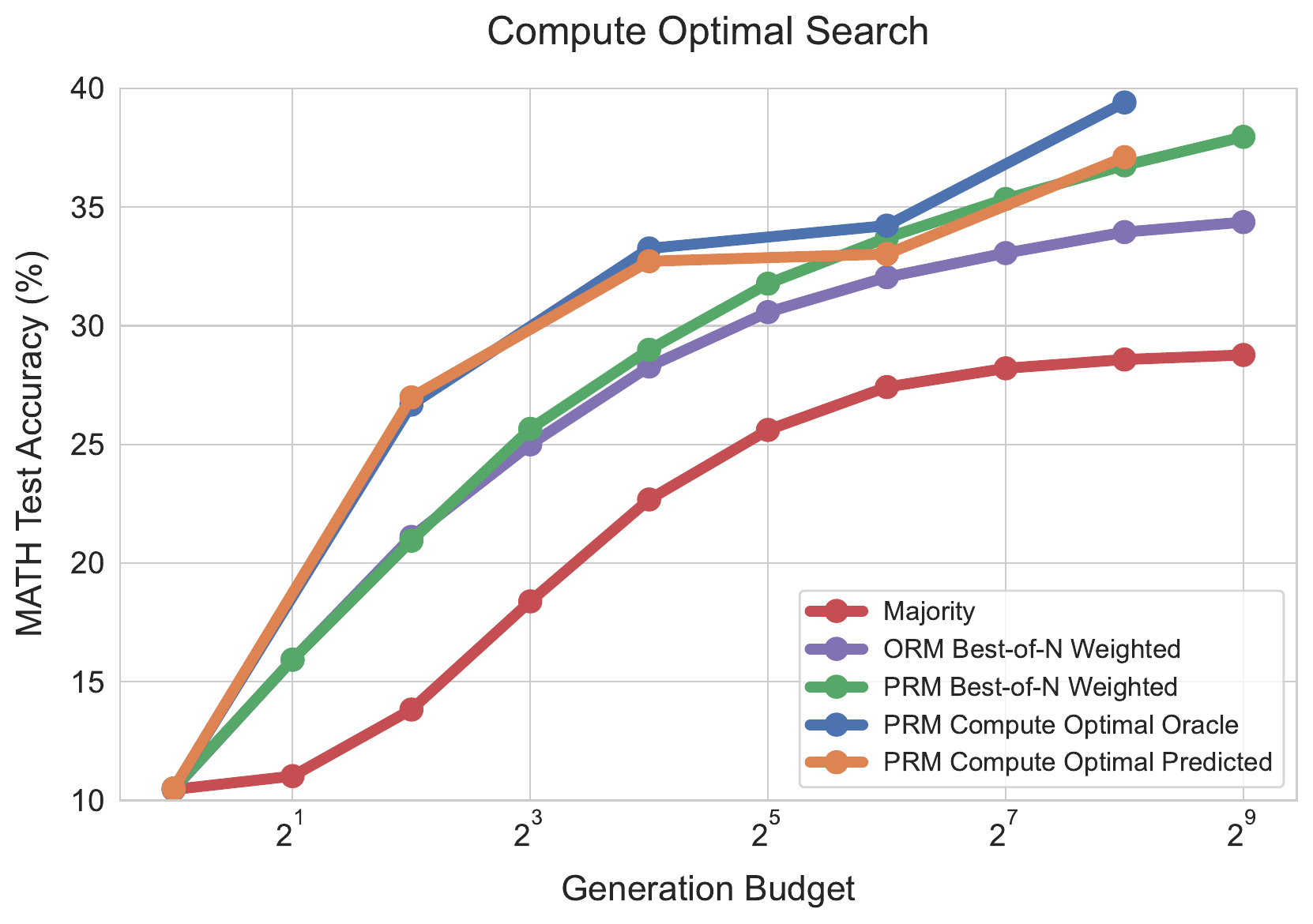
図 2 の主張は「compute をどう投じるか」を問題ごとに最適化する余地がある、ということである。固定戦略(Majority や Best-of-N)の曲線が早期に飽和する一方、難易度に応じて手法を切り替える Compute Optimal は generation budget が増えても伸び続ける。本章後半の adaptive allocation はこの観察の延長線上にある。
これらは「TTS は確かに効く」という empirical な土台を作った。本章ではそのうえで、「どう効かせるか」を扱う 2025–2026 年の研究を見る。
OpenAI o1 Pro 以降、frontier vendor は「同じ reasoning モデルに parallel test-time compute を投じた上位 tier」を製品として並べている (o1 Pro, GPT-5 Pro, GPT-5.5 Pro, xAI Grok 4 Heavy 等)。OpenAI 自身は GPT-5 Pro を “scaled but efficient parallel test-time compute” と表現し、Pro tier が別アーキテクチャではなく 同一モデルの deployment mode であることを明言している。
公式に確認できる範囲では、o1 公開時のベンチで pass@1 と majority vote @ 64 samples の両方が示されており、本章後段で扱う集約 (Self-Consistency と重み付き多数決) と verify (Process Reward Models) の 複合 deployment として読める。生成より検証のほうが安価であるという非対称性を利用した最近の研究 (Zeng ほか 2025年) は、この種の deployment の効率限界を学術側から押している。
aggregation / selection 機構の詳細は公開されていないため、本章では Pro tier の中身そのものではなく、本章で扱う学術手法群が商用 deployment と同じ問題空間を共有している点を指摘するに留める。
Budget forcing と thinking 制御
最も単純で広く使われる TTS は、thinking の長さを陽に制御する手法である。s1(Muennighoff ほか 2025年) が代表で、1,000 例の curated reasoning trace(s1K)で SFT した Qwen2.5-32B-Instruct に対し、生成中に “Wait” を append して thinking を延長したり、指定 token 数で thinking を強制終了したりする「Budget Forcing」を組み合わせる。これだけで o1-preview を MATH で 27% 上回り、OpenAI が示した test-time scaling curve を最小構成で再現した初の論文となった。
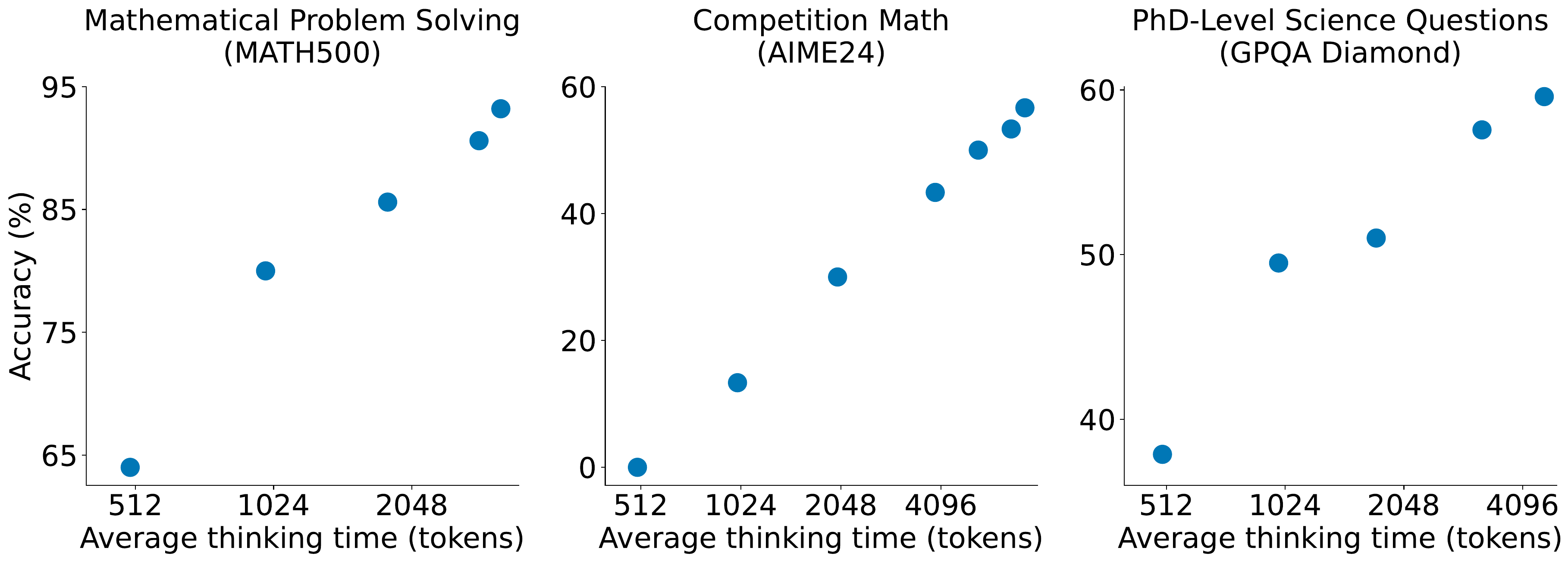
図 3 は、たった 1,000 例の SFT と Budget Forcing という最小構成で、log-scale の thinking budget に対する単調な性能向上が再現できることを示している。本章で扱う多くの手法は、この基本曲線を出発点として「同じ thinking budget でより高い精度」あるいは「同じ精度でより少ない budget」のどちらかを狙う。
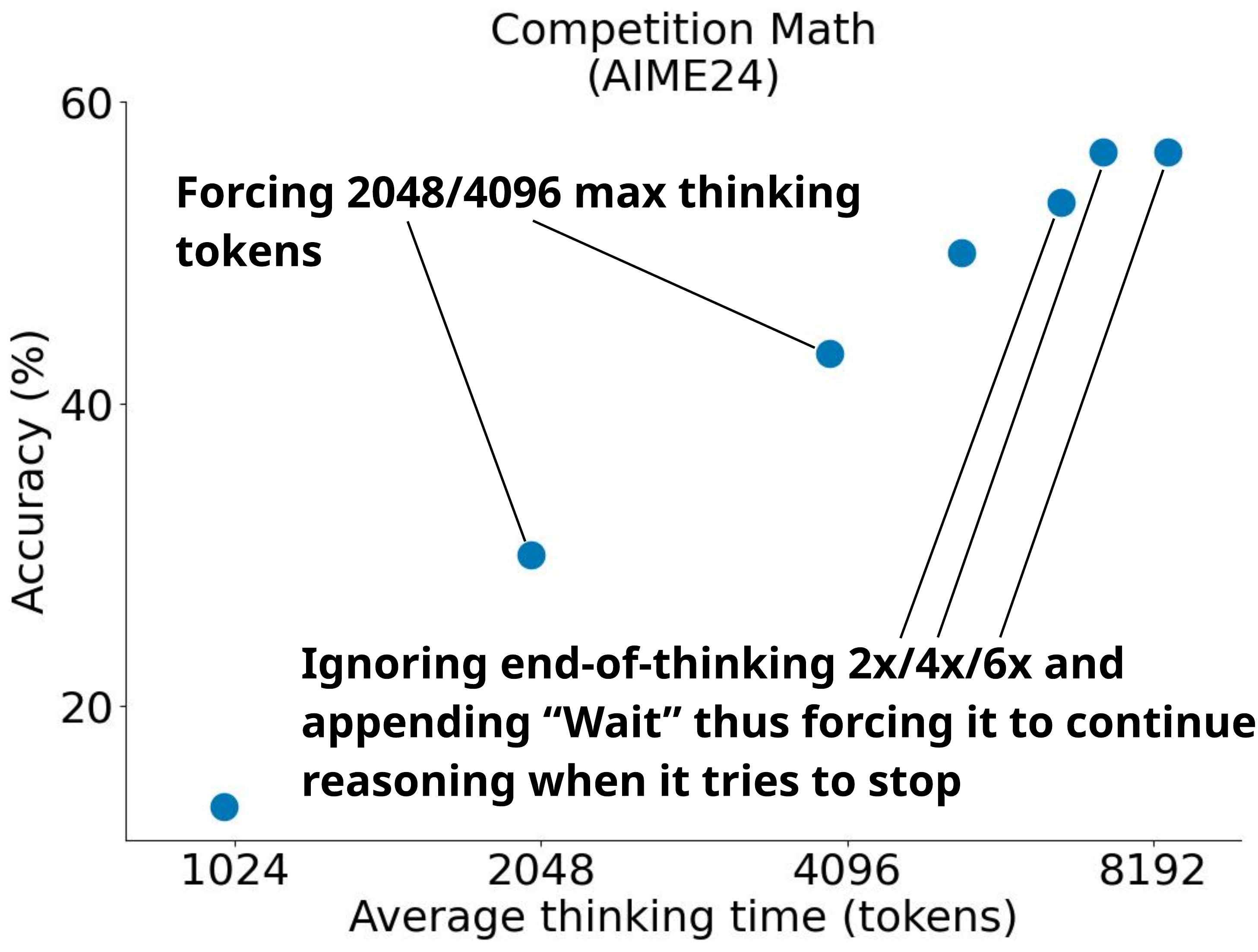
図 4 が示しているのは、外部から「いつ止めるか」「いつ続けるか」を制御するだけで scaling curve 上の動作点を陽に選べるということである。この粒度の制御性が、後の adaptive allocation 系(CaTS, DEER, CGES など)の前提となる。
s1 の Budget Forcing が示したのは、test-time scaling は特別な強化学習や巨大なデータ無しでも実現できるという事実である。重要なのは「いつ止めるか / いつ続けるか」をモデル外部から制御できる粒度に分解することであり、これが本章後半の adaptive allocation の前提になる。
Budget Guidance(Li ほか 2025年) は s1 の hard cut を soft 化した。残り思考長について Gamma 分布を仮定し、next-token 生成を確率的に guide する。fine-tuning 不要で、MATH-500 において tight budget 下で 26% の accuracy gain、フル思考の 63% トークンで同等精度を達成した。
O1-Pruner(Luo ほか 2025年) は逆に「長すぎる thinking」を縮める方向で、length-harmonizing reward の RL-style fine-tuning によって短縮と精度を両立する。Accuracy Efficiency Score(AES)という指標も提案した。
Chain of Draft(Xu ほか 2025年) は極端な短縮を試みる。Think step by step, but only keep a minimum draft for each thinking step, with 5 words at most という単純な prompt で CoT を 7.6% トークンまで圧縮し、GSM8k で 80% のトークン削減・76% の latency 削減を達成しつつ精度は同等以上だった。
これらの手法に共通するのは、CoT の長さ自体を独立した制御変数として扱う姿勢である。
CoT 長と accuracy の非単調な関係
長い CoT が常に良いわけではない。2025 年に独立した複数のグループが、CoT 長と accuracy の関係が単調ではないことを示した。
(Yuyang Wu ほか 2025年) は CoT 長と accuracy が「逆 U 字」であることを controlled 実験と理論モデルの両面から示し、最適長は task 難易度に対しては増加、モデル能力に対しては減少(強いモデルほど “simplicity bias”)すると報告した。(W. Yang ほか 2025年) は domain ごとに最適 length 分布が異なることを実証し、短い正解 response を self-select する thinking-optimal scaling によって Qwen2.5-32B を QwQ-32B-Preview レベルに引き上げた。
CoT が「長すぎても」「短すぎても」精度は下がる。これを 2 方向から指摘する論文が同時期に出ている。
- Overthinking: (Hassid ほか 2025年) は同一問題に対する複数 chain のうち、短い chain ほど 34.5% も正解率が高いと報告し、
short-m@k(k 並列生成して最初に終わった m 個で多数決)で 40% のトークン削減を達成した - Underthinking: (Y. Wang ほか 2025年) は o1 系モデルが promising な思考路を未完了で放棄して別 thought に移る「underthinking」を起こすと指摘し、decoding に “thought switching penalty” を入れて改善した。難問ほど起きやすく、不正解と強相関する
これらの観察は、固定長 / 固定 N の TTS が原理的に最適でないことを意味する。次節の adaptive allocation に直接つながる論点である。
Adaptive compute allocation
問題ごとに計算量を動的に割り当てるという発想は、2025 年後半から ICLR 2026 にかけて主流化した。代表的な系統を表にまとめる。
| 手法 | 制御信号 | 制御対象 | 出典 |
|---|---|---|---|
| CaTS(Self-Calibration) | 自己蒸留した confidence | Best-of-N の早期停止 | (C. Huang ほか 2025年) |
| T1 | external tool(code, retrieval) | small LM の verification | (Kang ほか 2025年) |
| Fractional Reasoning | latent steering vector | reasoning depth(連続) | (S. Liu ほか 2025年) |
| DiffAdapt | token entropy パターン | Easy / Normal / Hard の strategy 切替 | (X. Liu ほか 2025年) |
| DEER | thought-switch detection | thinking の early exit | (C. Yang ほか 2025年) |
| CGES | scalar confidence の Bayesian 更新 | sampling の早期停止 | (Aghazadeh ほか 2025年) |
| Thought Calibration | hidden state probe | plateau 検出による早期停止 | (M. Wu ほか 2025年) |
| Budget-aware | discriminative verifier + SC | 検証コストの最適化 | (Montgomery ほか 2025年) |
| e1 | 連続的 effort parameter | CoT 長の割合制御 | (Kleinman ほか 2025年) |
表 1 を眺めると、複数の系統が「どこで停める / どれだけ深く考える」を別々の観測量で決めようとしていることが分かる。CaTS は Best-of-N の N を、DEER は thinking 自体の長さを、Fractional Reasoning は latent 空間の深さを動的に決める。
CaTS, T1, Fractional Reasoning, ThinKV, DiffAdapt が ICLR 2026 で同時に採択された事実は、「固定 K の self-consistency や固定 token budget の CoT は古いベースラインになりつつある」というコミュニティの空気を象徴している。
特に Fractional Reasoning は離散トークン CoT を超えて、latent steering vector を tunable scaling factor で再注入することで連続的に reasoning depth を制御する。Best-of-N、majority voting、self-reflection を training-free で一様に改善できるという結果は、reasoning depth が線形構造を持つことを示唆する。
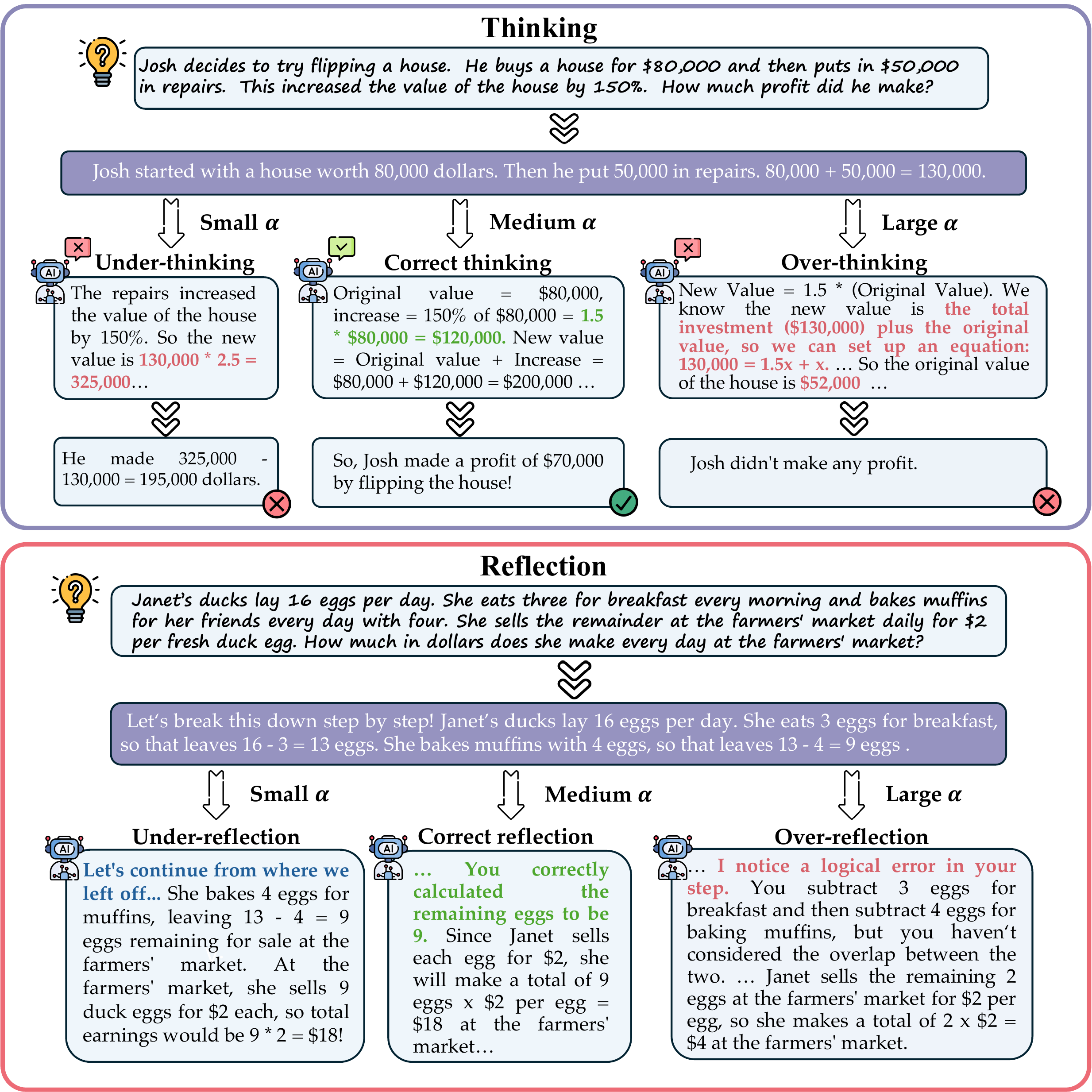
図 5 は、reasoning depth が単一スカラー α で連続的に動かせることを定性的に示している。固定長 CoT や離散的な「もう一回考える / 止める」の二択ではなく、連続値で thinking 深さを指定できるという発想は、Tree Search と MCTS で扱う tree search の depth 制御とも自然に接続する。
System-side optimization
TTS の「重さ」をソフト/ハードウェア側で吸収する系統も急速に立ち上がっている。
KV cache 圧縮
長い CoT は KV cache を爆発させる。ThinKV(Ramachandran ほか 2025年)(ICLR 2026 Oral)は thought ごとの重要度に応じて quantize / evict し、PagedAttention を拡張した kernel で空きスロットを再利用する。元の KV cache の 5% 未満で near-lossless、5.8 倍の throughput を達成した。
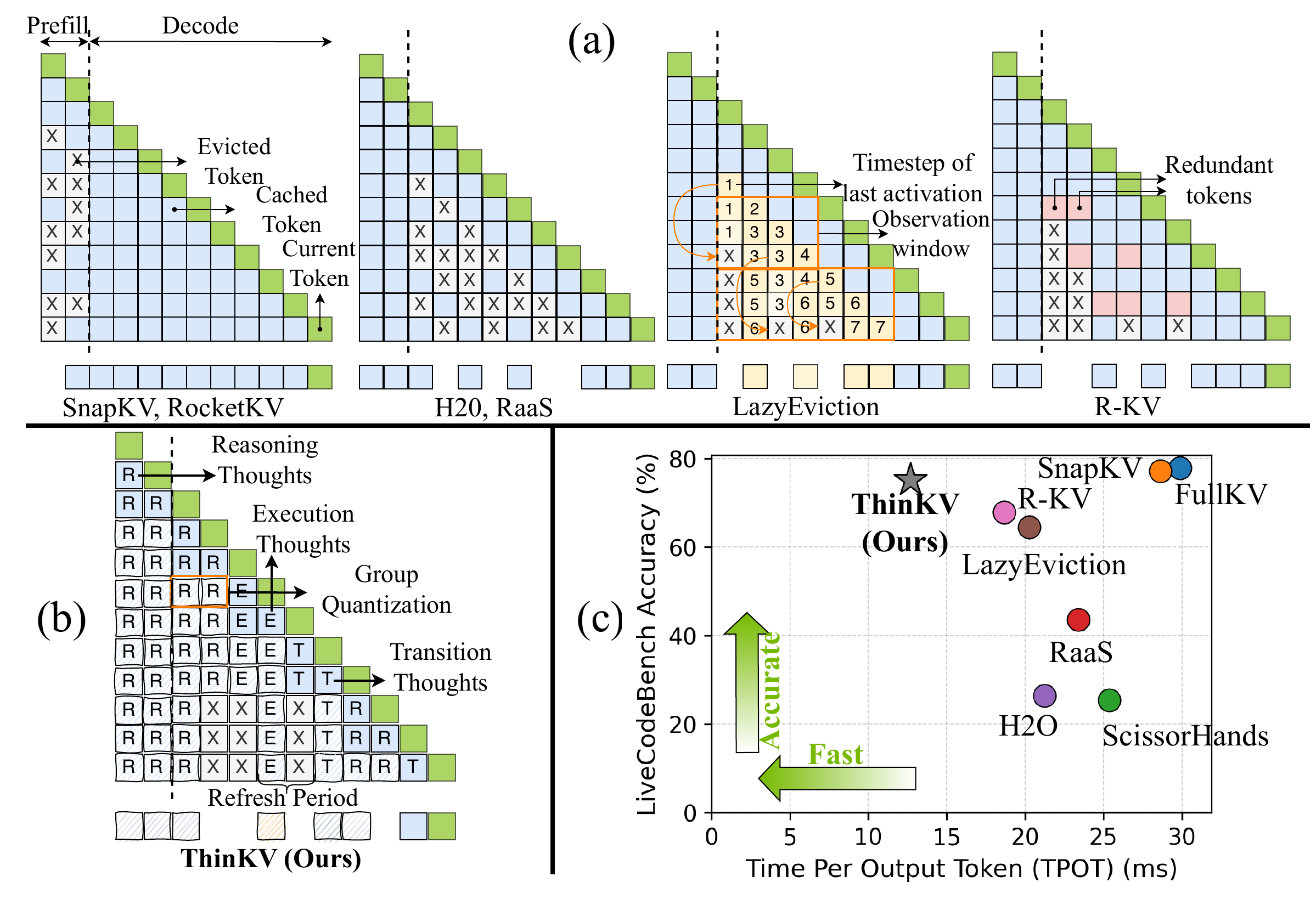
図 6 が示すのは、KV cache 圧縮の粒度を「token」から「thought」に上げると、accuracy をほぼ落とさずに TPOT を大幅に削れるということである。長 CoT 時代の system 側の主戦場が、token 単位の generic な KV 圧縮から reasoning 構造を意識した圧縮に移りつつあることを象徴する結果である。
Speculative reasoning
SpecReason(Pan ほか 2025年) は中間 reasoning step を軽量モデルに任せ、base モデルは verification に専念する設計を提案した。semantic な等価性で判定するため exact token matching に縛られない。1.4–3.0 倍の高速化と 0.4–9.0% の accuracy 改善、speculative decoding 併用で 8.8–58.0% の latency 削減を報告。SCoT(J. Wang ほか 2025年) は小さな draft モデルが thought-level の提案を出し、target モデルが採否 / 修正する設計で math データセットの latency を 48–66% 削減した。
長文脈での speculative decoding 自体も進んでおり、LongSpec(P. Yang ほか 2025年)(ACL 2025)は memory / 訓練-推論ギャップ / tree attention の非効率を解決し、AIME24 の long reasoning で wall-clock を 2.25 倍削減、Flash Attention 比 3.26 倍の高速化を達成した。
Offline への移行
Sleep-time Compute(Lin ほか 2025年) は test-time の負担そのものを「ユーザ問い合わせ前」の idle 時間に押し出す。context について先回り reasoningし、その表現を test-time の prompt に渡すことで、test-time compute を約 5 倍削減しつつ精度を 13–18% 改善する。関連質問群への amortize で 2.5 倍のコスト削減も得られる。
スケーリング則の再考
Kinetics(Sadhukhan ほか 2025年) は既存の test-time scaling 則が memory access ボトルネックを無視しており、小モデルの実効効率を過大評価していると主張した。0.6B–32B の実測から「attention が新たな cost driver」であることを示し、sparse attention によって AIME で 60 ポイント以上のゲインを得た。
TTS は「同じ計算予算なら長く考えた方が良い」という単純な話ではなく、「計算予算 = compute × memory × time」という多次元の trade-off になっている。ThinKV や Kinetics の登場により、TTS のスケーリング曲線は algorithm 側だけでなく system 側からも書き直されつつある。
Latent reasoning
CoT は離散トークン列という束縛を受けている。Coconut(Hao ほか 2024年)(COLM 2025)はこの束縛を外し、最終 hidden state を “continuous thought” として直接 embedding 入力に戻すことで、言語空間に縛られない latent reasoning を可能にした。複数 reasoning path を BFS(Breadth-First Search)的に同時探索でき、論理タスクで離散 CoT を上回る accuracy-efficiency Pareto を示した。
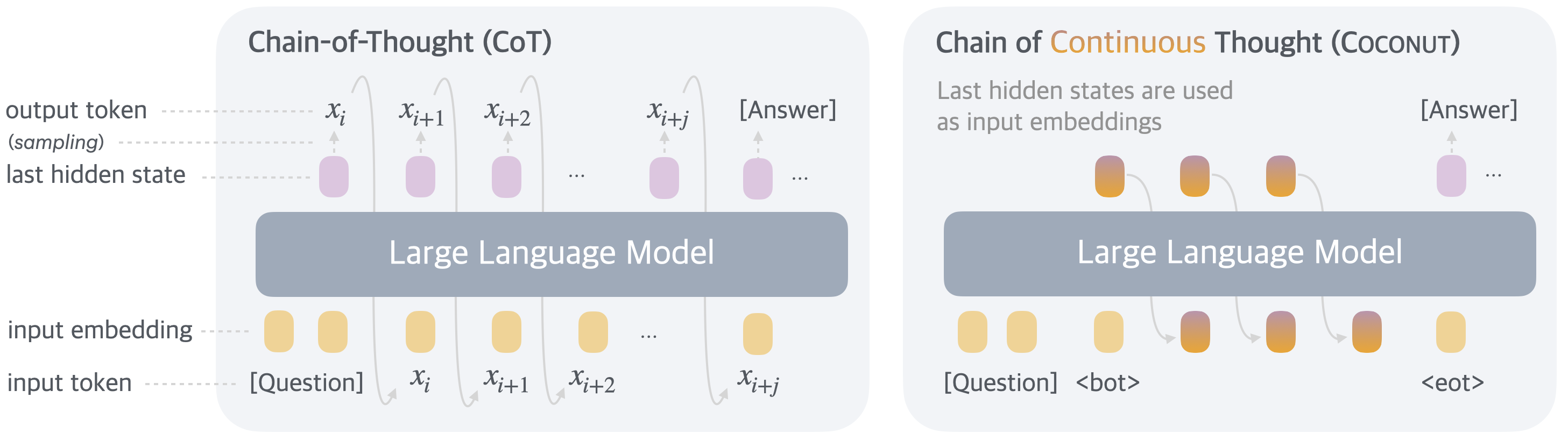
<bot> から <eot> までの区間で言語空間を介さない reasoning を行う。出典: (Hao ほか 2024年)
図 7 が捉えているのは、reasoning における「離散化」の必然性は実は外部観測者のためのものでしかなく、モデル内部の reasoning に限れば連続空間で完結できるという論点である。離散 CoT は人間が読めるという解釈性の利点を持つが、その代償として一語ごとに hidden state を 1 トークンの語彙分布に潰している。Coconut はこの代償を払うかどうかをタスクに応じて選べるようにした。
Coconut の系譜は次の 2 方向に伸びている。
- continuous CoT の表現空間を広げる: thought を vector として扱い、線形演算で操作可能にする方向。Fractional Reasoning(S. Liu ほか 2025年) はその延長と位置付けられる
- compressed CoT: 長い離散 CoT を短い latent 表現に圧縮し、必要なときに decode する方向
Latent reasoning の理論的射程はまだ広がっており、Self-Consistency と重み付き多数決 で扱う prefix consistency や Tree Search と MCTS の探索を latent 空間に持ち込んだ時、何が「同じ thought」と見做されるかという論点が次の自然な拡張になる。
並列・非同期化と Markovian thinking
逐次的な thinking は「Tunnel Vision」と呼ばれる病理、つまり序盤の suboptimal な選択が後段を縛る現象を起こす。ParaThinker(Wen ほか 2025年) は並列で複数 reasoning path を生成して統合する native parallel thinking を提案し、1.5B で 12.3%、7B で 7.5% の精度改善を、追加 latency 7.1% 程度で実現した。Self-Consistency が外側の集約だけを並列化するのに対し、ParaThinker は thinking 自体を native に並列化する。
Markovian Thinker(Aghajohari ほか 2025年) は RL 訓練環境を再設計し、reasoning を固定サイズの chunk に区切って境界で context をリセットする(つまり Markovian 性を強制する)。1.5B モデルが 24K thinking を 8K chunk で実現でき、96K の長さで H100-月数を 27 から 7 に削減しつつ精度を維持した。長 CoT の線形コスト化として注目されている。
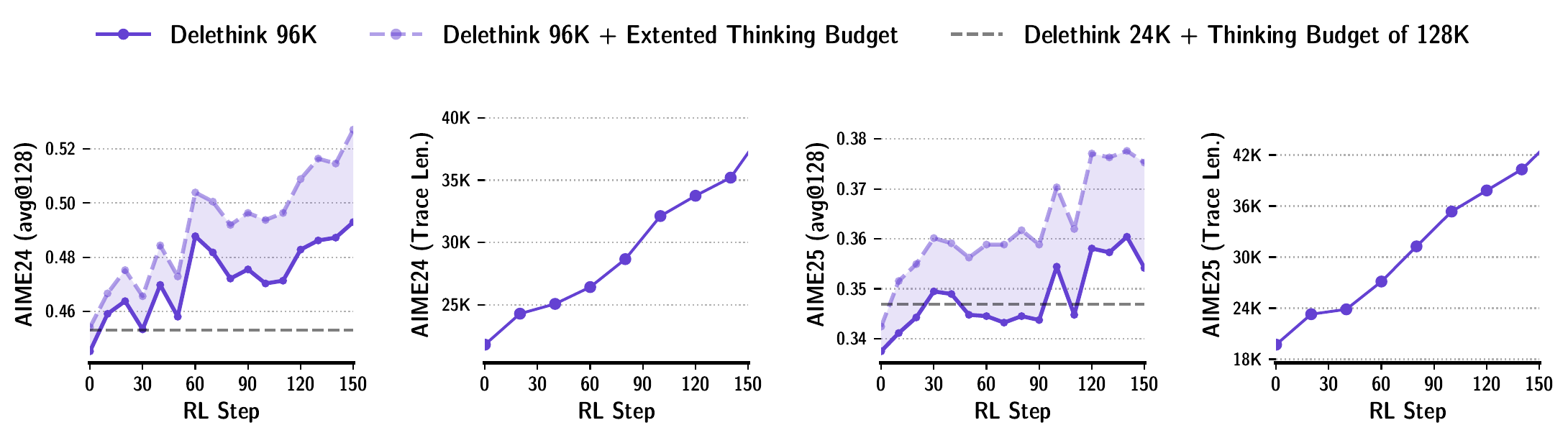
図 8 が示しているのは、chunk 境界での context reset を強制した RL 訓練でも accuracy がきちんと伸び、しかも長さは線形コストで済むということである。長 CoT を伸ばすときに quadratic な attention コストが頭打ち要因になるのを、訓練側から回避するアプローチとして位置付けられる。
ドメイン依存性: 数学から医療へ
ここまでの議論——budget forcing、optimal CoT length、adaptive allocation——は、ほぼ数学タスクを暗黙の前提に組み立てられている。AIME / MATH500 / GSM8k / AMC が本章図表の大半を占めるのは偶然ではなく、test-time compute 研究自体が数学に強く偏っているためである。ドメインを変えたとき、ここでの結論はどこまで生き残るのか。2025 年の医療 reasoning 研究は、これに対し否定的な答えを並べ始めている。
Knowledge と reasoning の分解
(J. Wu ほか 2025年) は thinking trajectory を knowledge と reasoning の 2 成分に分解し、(1) 各 step が使う domain knowledge を抽出して外部 DB と照合する Knowledge Index(KI)と、(2) 各 step が回答への不確実性をどれだけ減らすかを測る Information Gain(InfoGain)を定義した。
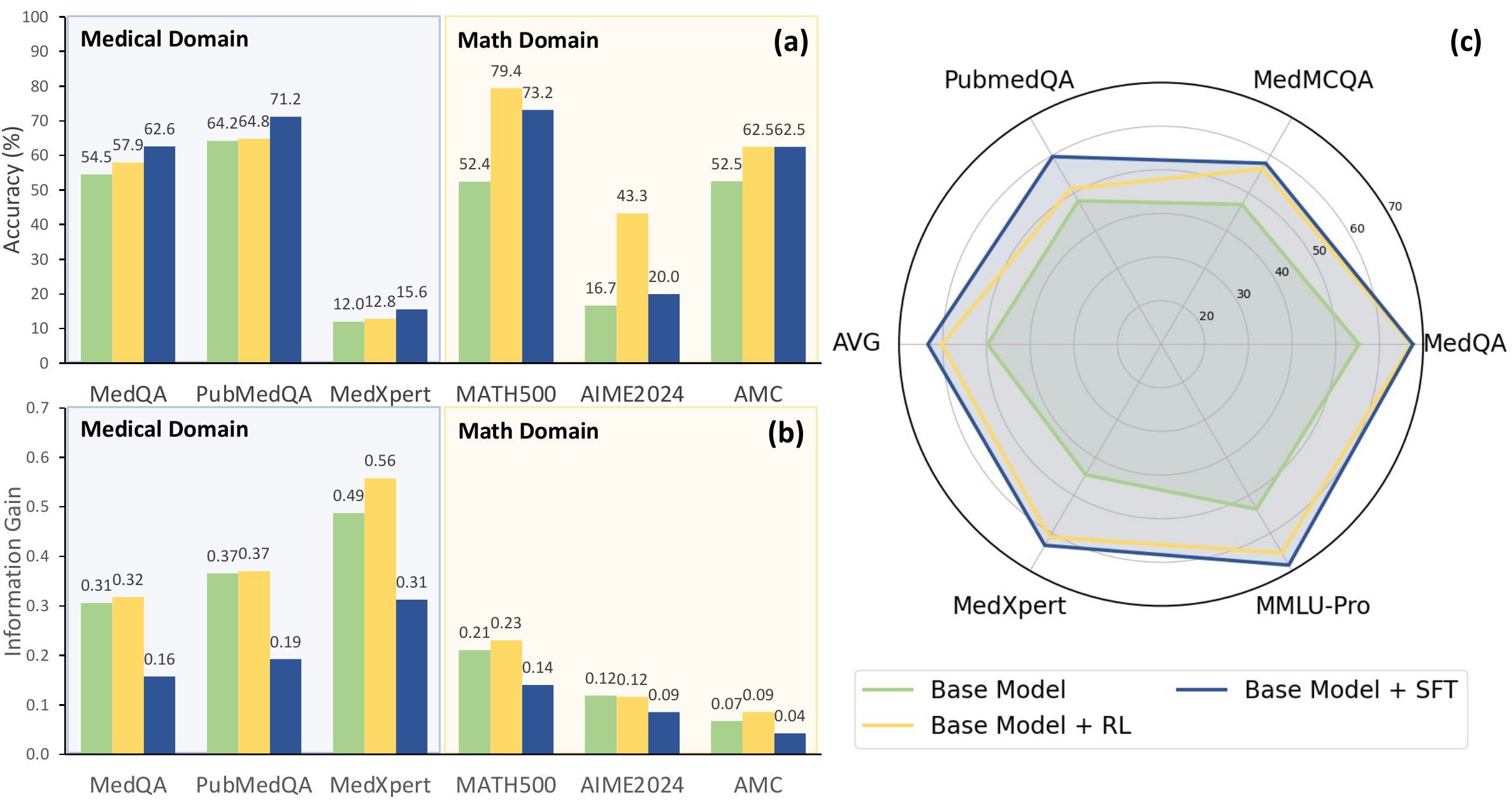
図 9 が示すのは、同じ training 手法でもドメインによって効き方が異なるという事実である。医療 5 ベンチマークのうち 4 つで KI–accuracy の相関が InfoGain–accuracy を上回る。SFT は accuracy を上げる一方で InfoGain を平均 38.9% 下げ(reasoning の冗長化)、医療では KI を平均 6.2 ポイント上げる。RL は医療 KI を平均 12.4 ポイント上げ、不正確な knowledge を含む reasoning 経路を刈り込む。R1 由来の reasoning 蒸留が SFT/RL を後段に挟んでも医療に自動的には転移しないことも報告されている。
医療では thinking budget に上限がある
(X. Huang ほか 2025年) は test-time scaling を医療 reasoning で系統的に調べた。10 種の医療 QA ベンチマークで、accuracy は thinking budget の対数増加とともに伸びるが、約 4K トークン付近で頭打ちになる。
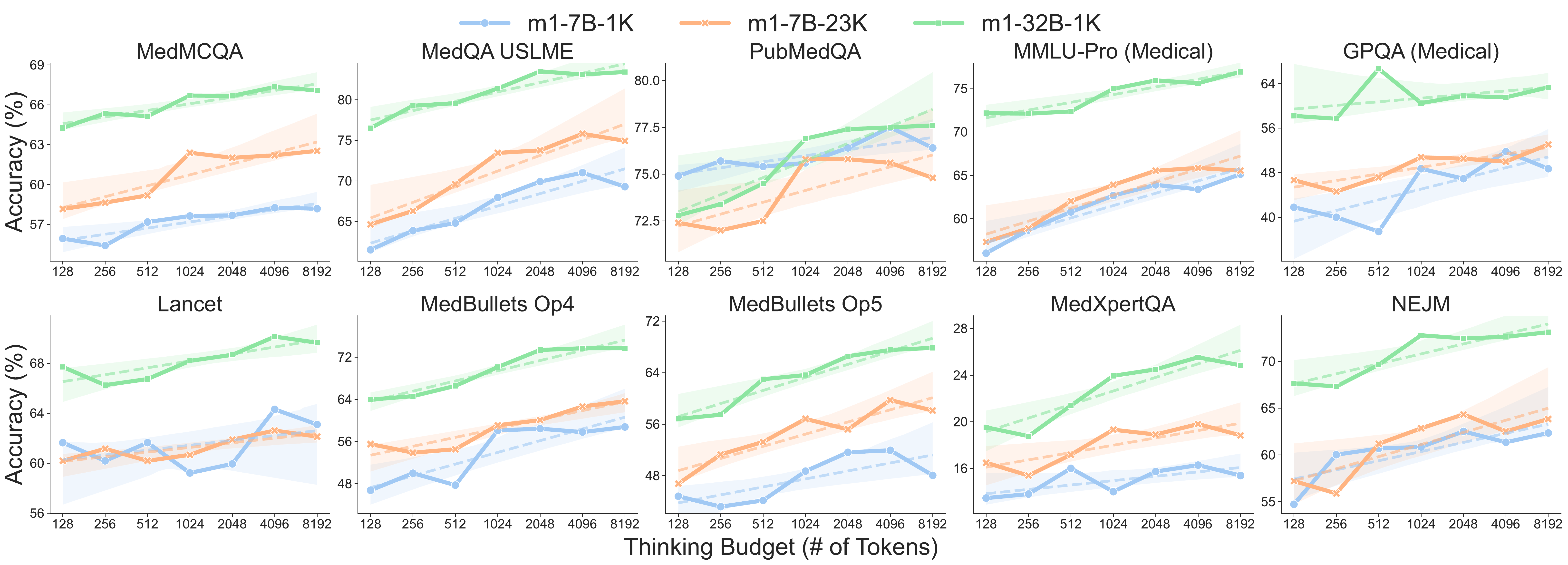
加えて、s1 (Muennighoff ほか 2025年) で導入された “Wait” 挿入による budget forcing は、医療 QA では効果が限定的か、場合によっては元々正しかった回答を覆して誤りに変える。論文の case analysis は、erroneous knowledge を持つモデルが追加 thinking で正しい初期回答を再考し、不正確な結論に到達する例を示す。数学で iterative refinement として機能する操作が、医療では knowledge bottleneck を露呈させる方向に働く。著者らはこの bottleneck の源を「medical knowledge の不足」と帰結し、thinking budget を伸ばす以上にデータ品質とモデル容量の scaling が効くと結論する。
医療誤り訂正という評価軸
数学の inference-time 信号を医療に持ち込むには、医療側に対応する評価が要る。MedRECT (Iwase ほか 2025年) は、臨床テキストに対する error detection / error sentence extraction / error correction の 3 サブタスクに分解した日英 bilingual ベンチマークである(図 11)。MedRECT-ja は日本医師国家試験(JMLE 2024–2025)から自動パイプラインで構築された 663 サンプル、MedRECT-en は MEDEC MS Subset Test に同じ LLM-as-a-Judge screening を適用した 458 サンプルからなり、11 個の LLM(proprietary / open-weight / 医療特化 / reasoning 系)が評価された。

主要な結果は次の 3 点である。第一に、Qwen3-32B の think / no-think 比較で reasoning オンが error detection F1 を +13.5%、sentence extraction accuracy を +51.0% 相対改善する。第二に、汎用 reasoning モデルが医療特化モデルを sentence extraction で上回り(HuatuoGPT-o1-72B が 62.1% に対し小型の Qwen3-32B think は 72.5%)、ドメイン特化訓練よりも reasoning capability の方が支配的という観察が得られる。第三に、LoRA fine-tuning が両言語で正答率を伸ばす(MedRECT-ja で +16.8%、MedRECT-en で +19.6% の相対改善)。MedRECT-ja と MedRECT-en は原資料が異なるため絶対値の直接比較は避けられるが、within-language での model 順位や within-model の en–ja 差を測る枠組みになっている。
小括
数学で確立した inference-time 手法が他ドメインに転移する条件は自明ではない。少なくとも次の 2 点が確認されている。
- ドメインのボトルネックが reasoning ではなく knowledge にある場合、reasoning depth を伸ばす方向の手法は accuracy gain が乏しく、budget forcing は正しい回答を覆す方向に働きうる (X. Huang ほか 2025年)
- 最適 thinking budget はドメイン依存で、数学で見られる log-linear scaling は医療では 4K トークン付近で頭打ちになる (X. Huang ほか 2025年; J. Wu ほか 2025年)
本章で議論した budget forcing / adaptive allocation / KV cache 圧縮等は数学に最適化された動作点に達しているにすぎず、knowledge-intensive ドメインでは別の動作点と評価軸が要請される。
章のまとめ
表 2 に本章で扱った主要手法を、何を最適化しているかという軸で再整理する。
| 軸 | 代表手法 | 効果(おおまかな桁) |
|---|---|---|
| 長さの hard control | s1(Budget Forcing) | o1-preview を MATH +27% |
| 長さの soft control | Budget Guidance | フル思考の 63% トークンで同精度 |
| 短縮優先 | Chain of Draft | 7.6% トークン、80% 削減 |
| 短縮優先(学習) | O1-Pruner | 長さと精度の両立 |
| 長さの逆 U 字 | When More is Less | 最適長は問題依存 |
| Adaptive 早期停止 | CaTS, DEER, CGES, Thought Calibration | thinking token 50–80% 削減 |
| Adaptive depth | Fractional Reasoning | training-free で多手法を一律改善 |
| KV cache 圧縮 | ThinKV | 5% 未満の KV で near-lossless、5.8 倍 throughput |
| Speculative | SpecReason, SCoT, LongSpec | latency 1.4–3.3 倍改善 |
| Offline 化 | Sleep-time Compute | test-time compute 5 倍削減 |
| Latent | Coconut, Fractional Reasoning | 言語空間外の reasoning |
| 並列化 | ParaThinker | 7B で 7.5%、追加 latency 7% |
| Linear scaling | Markovian Thinker | 96K thinking のコストを 4 倍削減 |
横断的に観察できるのは、次の 4 点である。
- 「いつ止めるか」が共通の問い: Budget Forcing の hard cut、Budget Guidance の soft cut、DEER の thought-switch exit、CGES の Bayesian 停止、Thought Calibration の plateau 検出は、いずれも reasoning prefix を切る位置を別の信号で決めている。Self-Consistency と重み付き多数決 で扱う prefix-based aggregation 系と直接接続する論点である
- 長さの非単調性が定説化: 複数の独立した研究が overthinking と underthinking を同時期に報告した。固定長 / 固定 N の TTS は今後ベースラインとして残るが、最適手法は問題依存・能力依存に動的に決める必要がある
- System 側の追い上げ: ThinKV, SpecReason, Sleep-time Compute, Kinetics が「N 倍コスト」批判への反論材料を提供している。algorithm 側だけで TTS の効率を議論するのは妥当でなくなりつつある
- ドメイン依存性が表面化: 医療のような knowledge-intensive ドメインでは、budget forcing が正しい初期回答を覆す方向に働き、thinking budget も ~4K で頭打ちになる (X. Huang ほか 2025年; J. Wu ほか 2025年)。数学に最適化された動作点は他ドメインに自動転移しない
Self-Consistency と重み付き多数決 では、ここで扱った compute allocation を「sample 集合をどう集約するか」の側面から見直す。Self-Consistency の派生として登場した CISC・CER・Path-Consistency・ST-BoN・Prefix Consistency は、本章の adaptive allocation と表裏一体の関係にある。