GRPO と Reward 設計
DeepSeek-R1 (Guo ほか 2025年) の登場以降、Group Relative Policy Optimization(GRPO)(Z. Shao ほか 2024年) は Reinforcement Learning with Verifiable Rewards(RLVR)の de facto 標準アルゴリズムとして急速に普及した。本章では、まず GRPO 本体と 2025–2026 年に出揃った主要派生(DAPO、Dr. GRPO、GSPO、VAPO、REINFORCE++)を整理し、その上で「outcome reward だけで十分か」という問いに対する dense / process reward 系の応答、特にモデル自身の consistency や confidence を reward に流用する系統を扱う。最後に、ランダム reward でも性能が上がってしまう「spurious reward 現象」が突きつける根本的な懐疑論を取り上げる。
GRPO とその派生
GRPO は Proximal Policy Optimization(PPO)から value network(critic)を取り除き、同一プロンプトに対する \(G\) 本のサンプルが互いに baseline となる group relative な advantage を使う。PPO との構造上の差は 図 1 に明瞭で、PPO が policy・reward・reference・value の 4 モデルを保持するのに対し、GRPO は value model を捨て、同一プロンプト \(q\) から得た \(G\) 本のロールアウト \(\{o_1, \dots, o_G\}\) の reward を group computation で正規化して advantage を作る。
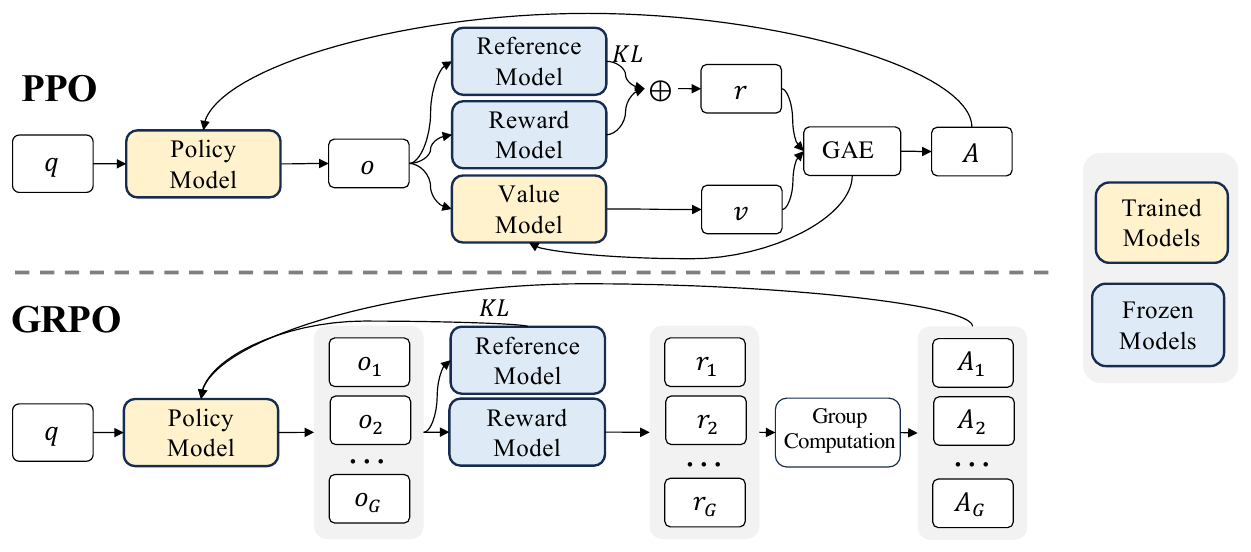
形式的には、プロンプト \(q\) に対するロールアウト \(\{o_1, \dots, o_G\}\) と outcome reward \(\{r_1, \dots, r_G\}\) から、各サンプルの advantage を group 内の正規化として
\[ \hat{A}_i = \frac{r_i - \mathrm{mean}(\{r_j\})}{\mathrm{std}(\{r_j\})} \]
と定義し、これを全 token に共有する。critic を学習しなくてよい点が大規模 LLM では大きな利点となる。
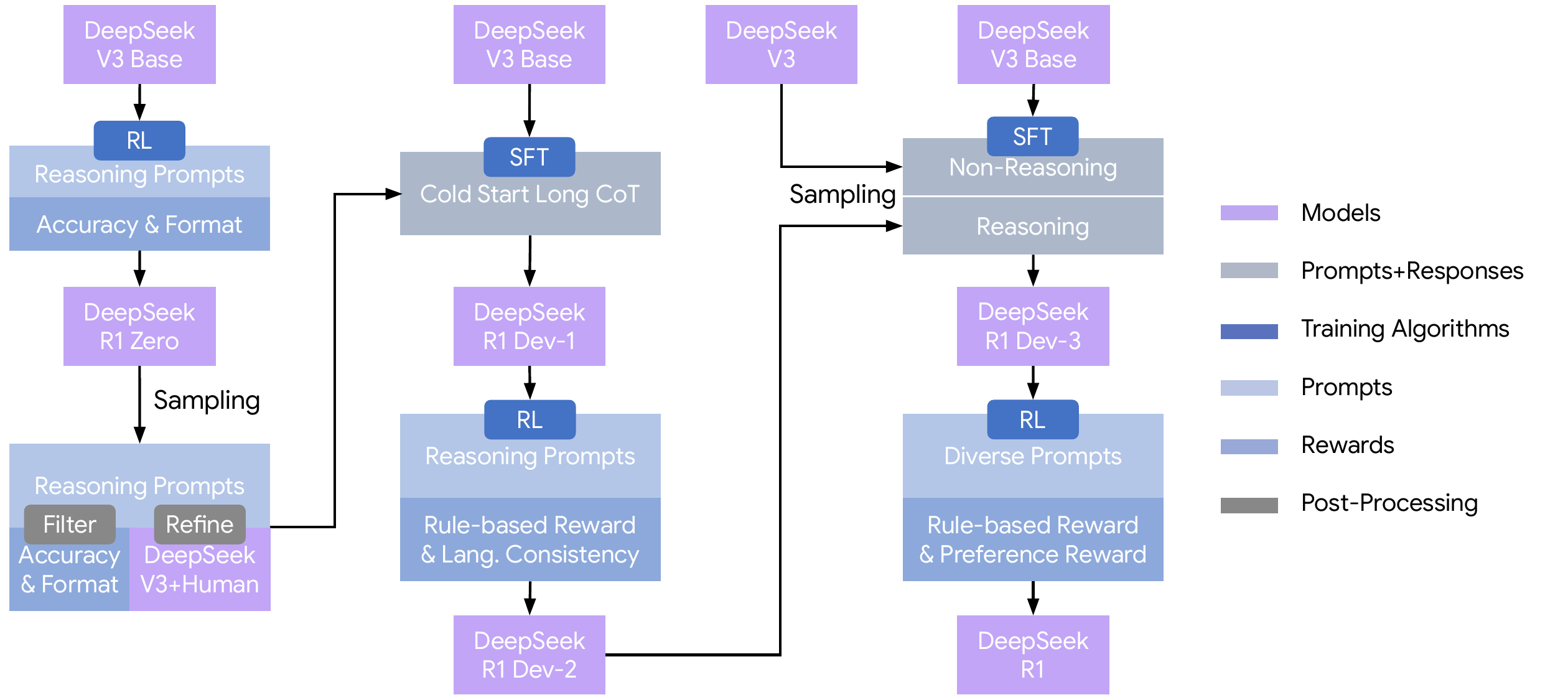
DeepSeek-R1 はこの GRPO を中心とする多段パイプラインで構築された(図 2)。base モデルからまず純粋な RL のみで R1-Zero を作り、そこから cold start CoT を sampling した上で再度 RL を回す。reasoning prompts には accuracy + format reward を、汎用化のための 2 段目では rule-based reward と preference reward を組み合わせる構成で、後続研究の多くはこのパイプラインの一部を改良する形で位置づけられる。
2025 年はこの基本形を巡る派生が一気に出揃った年であった。
- DAPO(Q. Yu ほか 2025年): ByteDance Seed が公開した実運用スケールの GRPO 実装。Clip-Higher による entropy collapse 抑制、Dynamic Sampling による勾配信号枯渇の回避、Token-level Policy Gradient Loss、Overlong Reward Shaping の 4 点を改良。AIME 2024 で DeepSeek-R1-Zero-Qwen-32B を半分のステップで超え、データとコードを完全公開した
- Dr. GRPO(Liu ほか 2025年): GRPO の advantage 計算に潜む 2 つのバイアスを指摘。1 つは sequence-length 正規化に由来する Response Length Bias(誤答が長いほどペナルティが薄れる)、もう 1 つは標準偏差で割ることに由来する Question-Level Difficulty Bias(std が小さい問題が過剰に重み付けされる)。両者を除去する処方箋を提案
- GSPO(Zheng ほか 2025年): token-level の importance ratio を捨て、sequence-level の likelihood 比で clipping/optimization を行う。Mixture-of-Experts(MoE)モデルの RL で顕在化していた不安定性を解消し、Qwen3 の training stack で実利用された
- VAPO(Yu Yue ほか 2025年): GRPO 系の critic-free 路線に対し、PPO 系の value-based 路線を 7 つの修正で改良。Qwen2.5-32B で AIME 2024 = 60.4 を達成し、5000 ステップで複数 run の crash がゼロだった点が特徴
- REINFORCE++(Hu ほか 2025年): GRPO/RLOO の prompt-local な advantage 正規化はバイアスがあると指摘し、グローバルバッチ全体で advantage を正規化する形に変更。critic-free を維持しつつ複雑な reasoning にも対応
これらは「critic を持つか持たないか」「正規化をプロンプト内に閉じるかグローバルにするか」「importance ratio を token 単位か sequence 単位か」という 3 つの軸で位置づけられる。
DAPO は GRPO の vanilla 形を上記 4 つの修正で底上げし、AIME 2024 で DeepSeek-R1-Zero-Qwen-32B を半分の training step で超えるという結果を示した(図 3)。avg@32 / pass@32 / cons@32 の 3 種類の曲線が同時にプロットされており、pass@32 が早期から飽和に近い水準まで上がる一方で avg@32 が後から追従する形になっている点が、reasoning RL の典型的な挙動を端的に表している。
Dr. GRPO はこれとは別方向で、GRPO の advantage 計算式そのものを修正する。図 4 の左側に示されるように、vanilla GRPO は応答長で割る項 \(1/|o_i|\) と問題ごとの \(1/\mathrm{std}(\mathbf{R})\) を advantage に乗じており、これが「誤答が長いほど罰が軽い」「易/難の極端な問題が過大評価される」というバイアスを生む。両者を取り除く Dr. GRPO は、図の右側のとおり同じ training reward に対して出力長が短く保たれ、token efficiency の意味で明確に優位を示す。

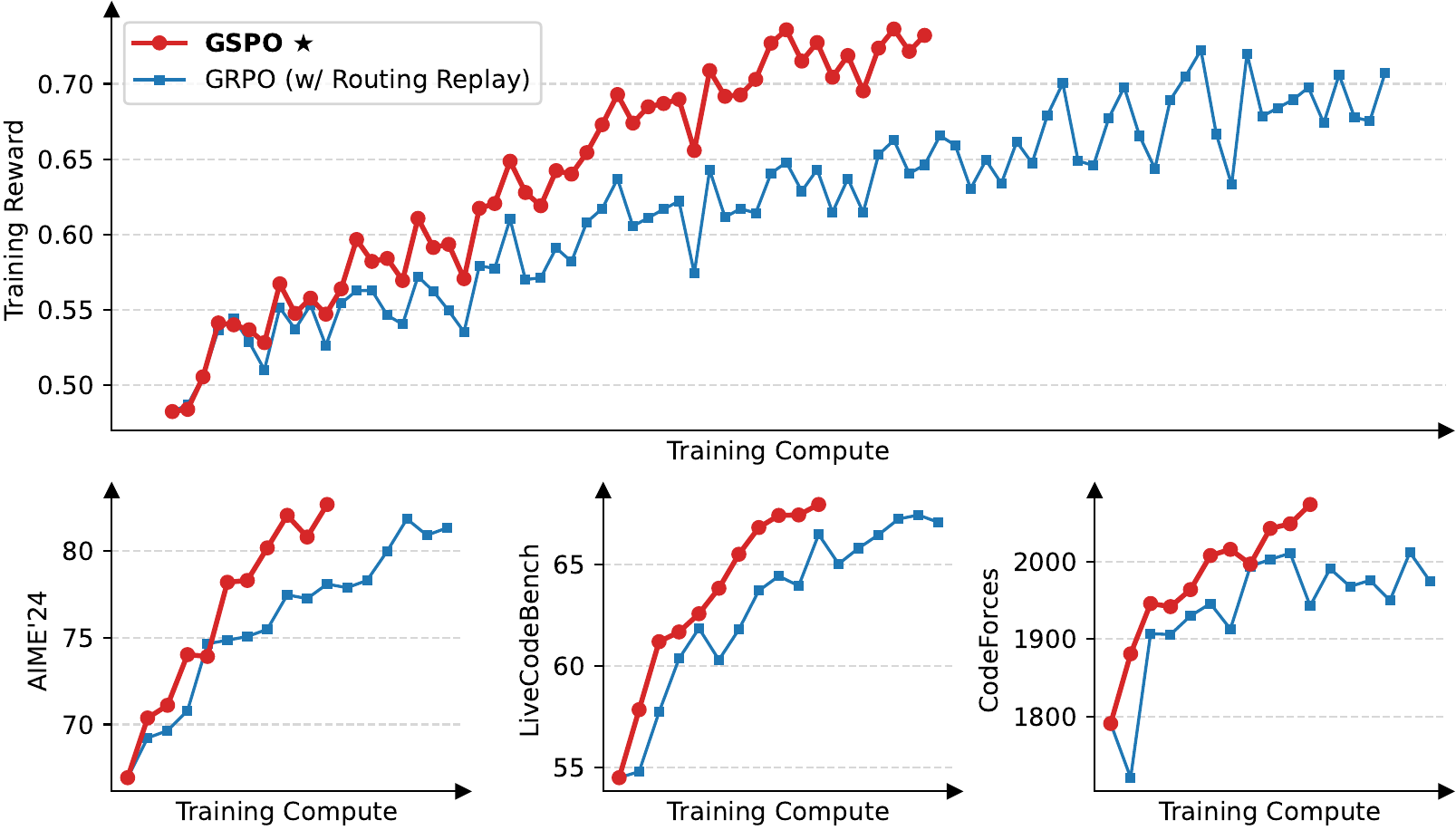
GSPO は importance ratio の単位を token から sequence へ移すことで、特に MoE モデルでの training を安定化する。図 5 に示されるとおり、同じ compute 量に対する training reward の伸びが GSPO のほうが安定して大きく、AIME’24 / LiveCodeBench / CodeForces の 3 ベンチでも一貫して GRPO + routing replay を上回る。
2026 年時点では vanilla GRPO はすでに古いベースラインであり、新規研究では派生の組み合わせを前提とするのが一般的である。
Outcome reward から process reward へ
GRPO 系のアルゴリズム整備と並行して、reward signal 自体の情報量を増やす方向の研究が爆発的に増えた。
- Outcome reward: 最終答えが正解かどうかという二値(あるいはタスク完遂度)だけを reward とする。RLVR の標準形
- Process reward: reasoning の各 step ごとに reward を与える。sparse な outcome reward を補完し、credit assignment が局所化する
Process reward を得るには通常 step-level の人手アノテーションが必要で高コストであった。2025 年の主要トレンドは「人手ラベルなしで process reward をどう作るか」に集中した。
Implicit process reward の発見
PRIME(Cui ほか 2026年) は、policy のロールアウトと outcome label のみから implicit な process reward を online で推定する枠組みである。明示的な step アノテーションを必要とせず、PPO / GRPO / RLOO / REINFORCE のいずれの backbone にも乗る。Qwen2.5-Math-7B-Base + PRIME(= Eurus-2-7B-PRIME)は、わずか 10% のデータで Qwen2.5-Math-7B-Instruct を上回った。
これと表裏一体の理論的発見が GRPO is Secretly a PRM(Sullivan と Koller 2025年) である。彼らは、outcome reward 付きの GRPO が実は Monte Carlo ベースの PRM-aware な RL 目的関数と等価であることを示した。group 内で同一 prefix を共有するロールアウトが存在するとき、outcome reward は自動的に sub-trajectory 単位の process reward に変換される構造が現れる。これは「explicit に process reward を導入する」ことの正当性を理論側から裏付ける結果である。
VinePPO(Kazemnejad ほか 2025年) は PPO の value network が中間 state の値付けに失敗していると指摘し、各中間 state から MC ロールアウトを独立に走らせて value を直接推定する。implicit reward を「prefix から再サンプルした成功率」として読み替える発想は PRIME と機構が近い。
Consistency-based / self-rewarding な reward
「外部 verifier を使わず、policy 自身の振る舞いから reward を取り出す」系統は 2025 年後半から 2026 年にかけて急増した。発想は大きく 2 つに分かれる。
第 1 は token / sample 単位の confidence や entropy を reward とする系である。
- Intuitor(X. Zhao ほか 2026年): 外部 reward を完全に廃し、モデル自身の self-certainty(logit entropy)を唯一の reward signal として GRPO に投入する。教師あり手法に比肩する数学性能と、コード生成への out-of-distribution 汎化を示した
- LaSeR(Yang ほか 2026年): 解の最終トークンに pre-specified token を入れた際の log-prob から、真の reasoning reward を直接推定できることを示す。別 verifier を呼ぶ必要がなく、RLVR の中で self-rewarding スコアを verified reward に align させて co-train する
- Reasoning with Exploration(Cheng ほか 2026年): token-level の entropy が pivotal token(論理的分岐点)、self-verification token、rare action と相関することを利用し、entropy を advantage の shaping term として加える
第 2 は trajectory 間や prefix 間の一致度を reward にする系である。
- TTRL(Zuo ほか 2025年): ラベルなしテストデータに対し、majority voting で pseudo-label を作って GRPO を回す。Qwen-2.5-Math-7B の AIME 2024 pass@1 が +211% 改善。一方、続けると overconfidence によって mode collapse に陥る点が報告されている
- CoVo(Zhang ほか 2025年): 複数の reasoning trajectory が中間状態でどれだけ「最終回答に収束し(consistency)、他候補にぶれないか(volatility)」をベクトル空間で集約し、intrinsic reward に変換する
- SCS(Jiahao Wang ほか 2025年): 入力画像に視覚的摂動を加えた上で reasoning chain を truncation + resampling し、得られた回答の agreement を測る。得られた differentiable な consistency score で policy update の各 trace を down-weight する。multimodal で +7.7pp
- RESTRAIN(Z. Yu ほか 2025年): TTRL が majority voting に過剰依存して spurious votes に騙される問題に対し、モデルの answer 分布全体を見て「自信過剰な rollout」「consistency が低い例」を罰する self-penalization を導入
- COMPASS(Xing ほか 2025年): Dual-Calibration Answer Reward で pseudo-label を作り、Decisive Path Reward で reasoning path そのものの品質を直接 optimize する 2 段構成
これらに共通する哲学は「policy 自身の内部状態を reward source にする」である。外部 verifier の収集コストや domain 依存性を回避できる一方、policy の系統的バイアスがそのまま reward に混ざるリスクを抱える。
Negative group の救出
GRPO は group 内で全員が誤答だと advantage の分散が消え、勾配が 0 になってしまう negative group 問題 を抱える。
LENS(Feng ほか 2025年) はこの問題に対し、reward 関数を「confidence に応じた負の値」へ拡張する。自信過剰な誤答ほど大きく罰する MLE 視点の政策勾配修正であり、誤答群からも informative な学習信号を取り出す。
Prefix-based reward
「途中状態の reasoning quality を model 自身に問う」というアイデアは、prefix を起点とする reward 設計として複数の論文で独立に現れている。
GRPO-VPS(Jingyi Wang ほか 2026年) は、モデルが reasoning を進めるにつれて「正解 answer の条件付き確率」を segment ごとに probe し、その増分を segment-wise の process reward として GRPO の advantage に加える。critic 不要、追加ロールアウト不要(1 forward pass のみ)で、数学タスクで +2.6 acc / -13.7% length を実現した。
PACR(Yoon ほか 2025年) は「well-formed reasoning では正解確率が単調増加するはず」という仮定を inductive bias とし、reasoning 中の正解 answer 確率の昇順性を直接 reward に組み込む。GRPO-VPS と同様に ground-truth answer の存在を前提とするが、reward の形(増分 vs 単調性)が異なる。
VinePPO や PRIME が「prefix から後続を見る」操作を implicit reward の推定手段として扱うのに対し、PPPO(Sun ほか 2025年) はこの操作を MDP の上に正面から載せ直す。prefix そのものを状態と見なし、固定 prefix から \(N\) 回 continuation をサンプリングして得られる正答率の平均を、その prefix の Monte Carlo value として advantage に組み込む。さらに最適化対象とする prefix の長さ \(\eta\)(生成トークンに対する割合)を 15% から 35% まで段階的に拡大する Progressive Prefix Retention を組み合わせ、序盤トークンほど後続を強く拘束するという経験則を訓練アルゴリズム側に明示的に反映させる設計になっている(図 6)。
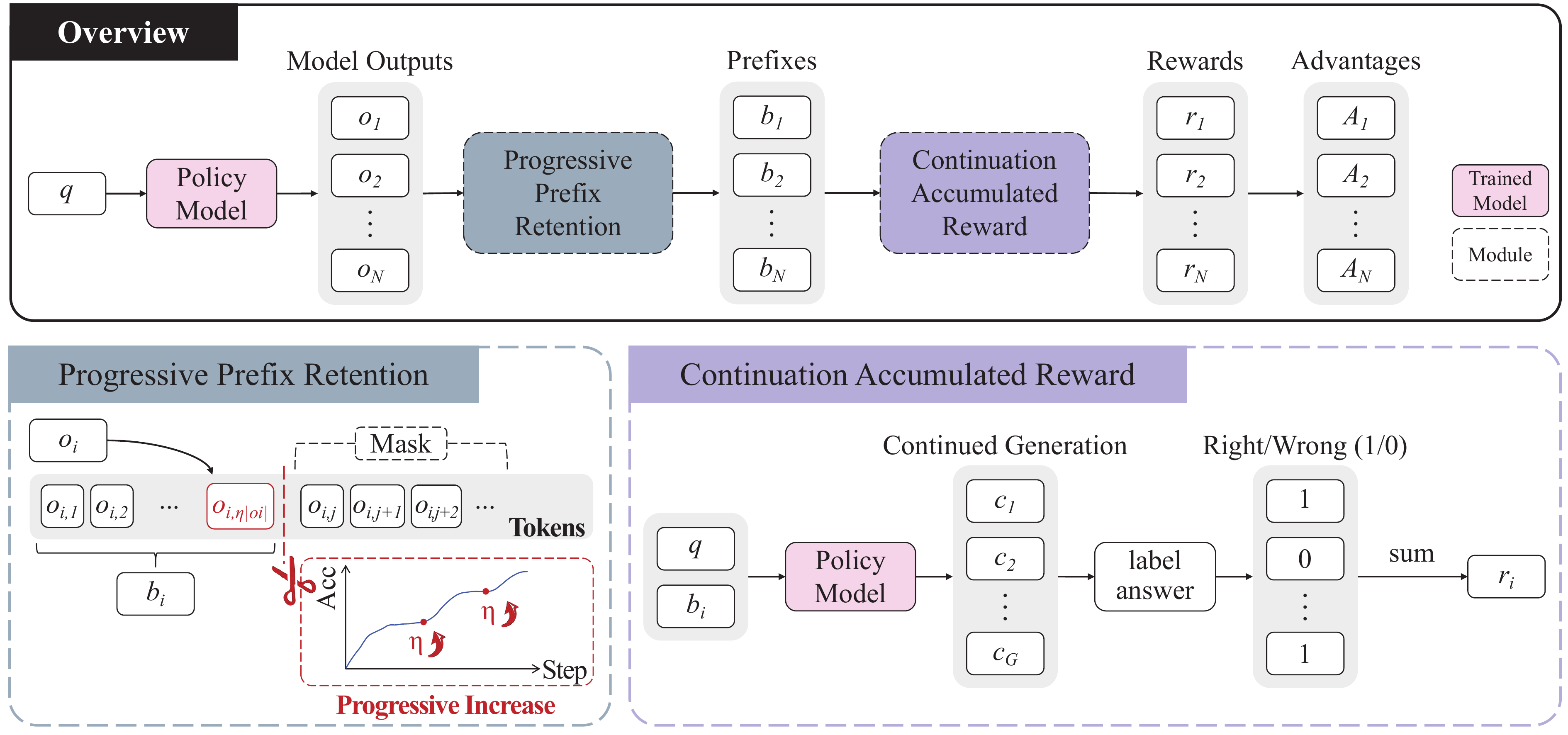
論文では、Qwen3-1.7B/4B/8B で AIME’25 を含む数学ベンチで最大 +18.02pp、平均 +14.64pp の精度向上を、全生成トークンのうち先頭 26.17% にしか勾配を流さない訓練コストで達成している。良い prefix から RL を始めれば残り 65%–85% のトークンは凍結したままでよい、という構図は、prefix-based reward の系譜の中で「prefix こそが RL で動かすべき自由度である」ことを最も極端な形で主張した結果と見ることができる。
これらの prefix-based reward は、Self-Consistency と重み付き多数決 で扱う Prefix-Confidence や Prefix Consistency といった推論 (inference) 側の手法と機構が一致する。GRPO-VPS / PACR の implicit 形から PPPO の explicit な MDP 定式化に至るまで、訓練側と推論側で同じ「prefix から後続を見る」操作が独立に再発明されている ことは、prefix が reasoning の load-bearing な単位であることを強く示唆する。
Reward hacking と spurious reward の落とし穴
dense / consistency-based reward を導入する際には、それが「本物の reasoning quality」を測っているか、policy の単なる癖を増幅しているかを切り分ける必要がある。この問題に正面から取り組んだのが Spurious Rewards(R. Shao ほか 2025年) である。
彼らは、ランダム reward や incorrect label でも GRPO で Qwen2.5-Math-7B の MATH-500 が +21.4pp 改善し、ground-truth 利用時(+29.1pp)に肉薄することを示した(図 7)。これは GRPO の clipping バイアスが、事前学習で獲得済みの behavior(特に code reasoning パターン)を増幅した結果と説明される。重要なのは、この現象が Qwen 専用で Llama3 や OLMo2 では再現しない 点である。図 7 を見ると、同じ random/incorrect reward を Llama3.1-8B-Instruct や Olmo2-7B に適用しても、ground truth 由来の信号がない条件では精度が下がるか伸びがほぼ無くなる。
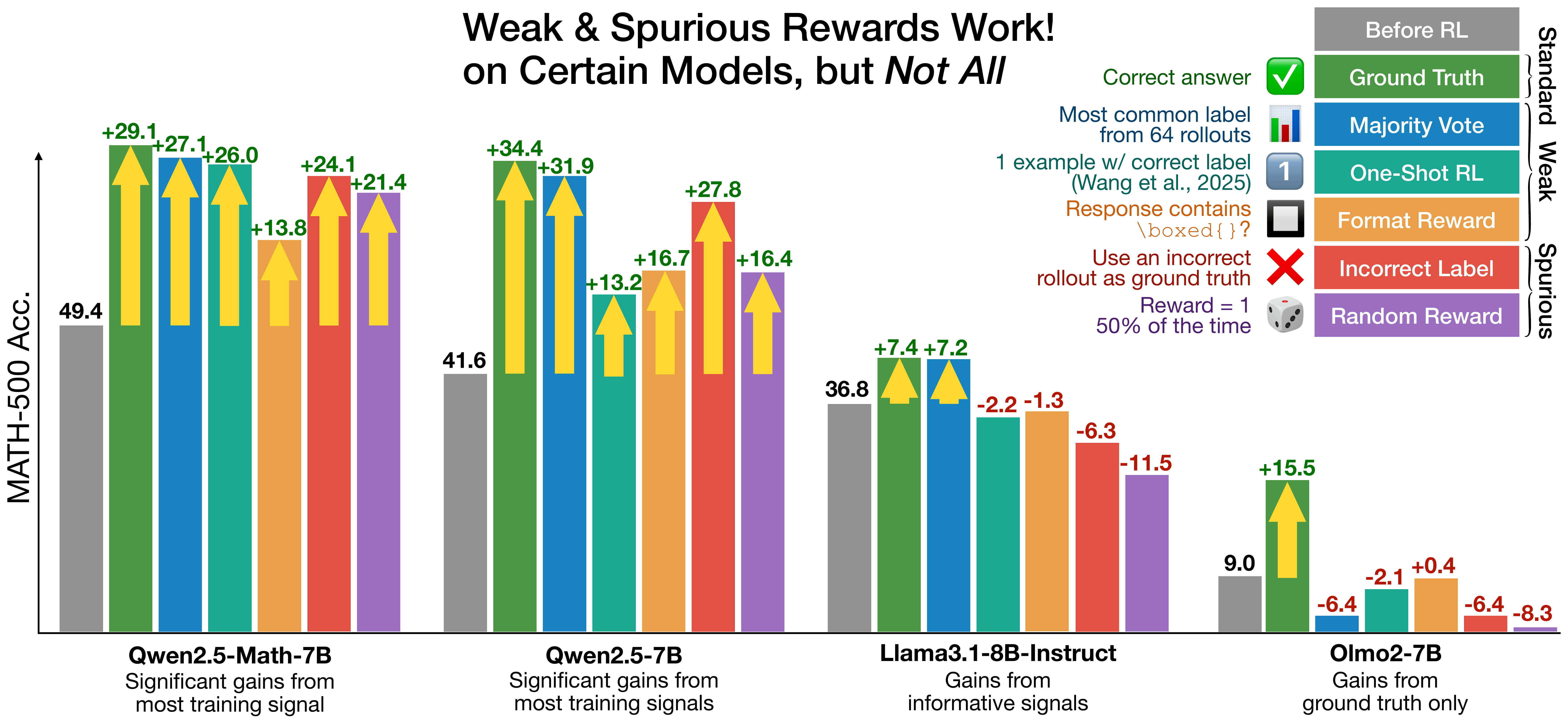
新しい reward signal を提案する研究は、(1) random / spurious reward に対するロバスト性(同じ reward でランダム化したらどうなるか)、(2) base モデルを跨いだ再現性(Qwen 以外でも効くか)、(3) large-K の pass@K への影響(base 分布を狭めていないか)の 3 つを示すことが事実上必須となった。
この cross-model robustness の問題は、RLVR の理論と限界 で扱う「RLVR は base モデルの能力を本当に拡張しているか」という問いと直結する。Does RLVR Really Incentivize Reasoning Beyond Base(Yang Yue ほか 2025年) は、RLVR が pass@1 を上げる一方で large K の pass@K では base モデルに劣ること、つまり RLVR は新規 reasoning パターンを生まず base 分布を狭めているだけと結論づけた。dense reward がこの根本的な頭打ちを緩和できるかは、process reward 系の研究全体に課された課題となっている。
自己教師化された RL: R-Zero と Absolute Zero
外部 reward を完全に排して reasoning モデルを訓練する方向の研究として、2025 年には 2 つの代表的なシステムが登場した。
R-Zero(Huang ほか 2026年) は Challenger-Solver の共進化を採用する。Challenger は Solver の能力境界付近のタスクを生成すると報酬を得て、Solver はそれらの難問を解くと報酬を得る。人手 curation がゼロで Qwen3-4B-Base が +6.49 math / +7.54 general の改善を示した。
Absolute Zero Reasoner (AZR)(A. Zhao ほか 2025年) は単一モデルが自分で学習進捗が最大化されるタスクを propose しつつ自分で解く構成で、code executor を verifier 兼 task validator として活用する。外部データゼロでコード/数学の SOTA を達成した。
これらは consistency-based reward と並ぶ「ground-truth verifier の代替」を探す系譜であり、code executor や self-play による検証可能性を、consistency 系は policy 自身の挙動の安定性を、それぞれ verifier の代替として利用している。
その他の関連論文
本章で逐次取り上げた論文以外で本章のテーマに関わる主要論文を以下に整理する。
章のまとめ
GRPO は 2025 年に RLVR の de facto アルゴリズムとなったが、vanilla 形は既にベースラインの位置に下がり、DAPO / Dr. GRPO / GSPO / VAPO / REINFORCE++ といった派生のいずれかを使う前提で議論が進む段階に入った。reward 設計の側では、outcome reward から process / dense reward への移行が大きな流れとなり、特に「policy 自身の consistency や confidence を reward に流用する」系統(TTRL、CoVo、SCS、RESTRAIN、COMPASS、Intuitor、LaSeR、LENS、GRPO-VPS、PACR、PPPO)が爆発的に増えた。これらの背景には GRPO is Secretly a PRM(Sullivan と Koller 2025年) や PRIME(Cui ほか 2026年) の「outcome reward の中に既に process 情報が埋め込まれている」という理論的・経験的発見がある。
一方で Spurious Rewards(R. Shao ほか 2025年) は、reward signal の “本物さ” を cross-model 実験で検証することが必須であると突きつけた。新規 reward を提案する研究は、それが pre-trained behavior の単なる増幅ではなく真の reasoning quality を測っていることを示す責任を負う。次章(Process Reward Models)では、本章で扱った implicit / consistency-based な reward の対極として、CoT の各 step に明示的なスコアを与える PRM 系の手法を整理する。