Self-Consistency と重み付き多数決
大規模言語モデル(Large Language Model, LLM)に Chain-of-Thought(CoT)で問題を解かせるとき、1 本の reasoning trace だけを信じるのは脆い。確率的 decoding は同じ問題に対して毎回違う中間ステップを出すからである。Self-Consistency (X. Wang ほか 2023年) が提案して以降、N 本の trace を独立にサンプリングして集約するという枠組みが LLM の reasoning における基本道具となった。
2025–2026 年の研究はこの枠組みを大きく 4 方向に拡張している。第 1 は集約時の 重み付け。各サンプルに信頼度を付与し、単純多数決を加重多数決に置き換える。第 2 は prefix の活用。短い prefix を起点として多サンプリングし、合致率や confidence で answer を予測する。第 3 は 理論的支柱。加重多数決が単純多数決を支配する条件と最適性が定式化されつつある。第 4 は adaptive sampling。サンプル数 N を問題依存に動的決定する。本章ではこの 4 軸で関連研究を整理する。
基本道具: Self-Consistency と Universal Self-Consistency
Self-Consistency (X. Wang ほか 2023年) のアイデアは単純である。同じ問題に対して LLM から N 本の reasoning chain を独立にサンプリングし、各 chain の最終答え \(a_i\) を集めて 最頻値を採用する。
\[ \hat{a} = \arg\max_{a} \sum_{i=1}^{N} \mathbf{1}\{a_i = a\} \tag{1}\]
Wang らは、この単純な多数決が greedy decoding よりも GSM8K や MultiArith で大幅に高い精度を達成することを示した。背後の直観は「正答へ至る reasoning path は複数存在するが、誤答へ至る path はばらつきやすい」というものである。
Self-Consistency の素朴な拡張として Universal Self-Consistency(USC)がある。USC は exact match で集約できない自由形式の出力に対して、LLM 自身に「最も意味的に多数派の回答」を選ばせる。これにより summarization や open-ended QA にも多数決が適用できる。
式 1 は二つの強い前提を置いている: (i) 各サンプルが等しい重みを持つ、(ii) 答えの一致は exact match で判定する。2025–2026 年の研究はこの両方を緩める方向に展開した。
重み付け系: 各サンプルに信頼度の weight を付ける
各サンプル \(i\) から confidence 信号 \(s_i\) を取り出し、weighting 関数 \(w(\cdot)\) を通して投票重みに変える weighted majority vote(WMV)は次の形を取る:
\[ \hat{a} = \arg\max_{a} \sum_{i=1}^{N} w(s_i) \cdot \mathbf{1}\{a_i = a\} \tag{2}\]
整理の軸は (1) 信号 \(s_i\) をどこから取るか、(2) weighting 関数 \(w\) をどう設計するか、(3) per-sample(\(a_i\) にのみ重みを置く)か per-candidate(regenerate 等で出現する任意の答えにも重みを置く)か、の 3 点である。本書ではまず信号 \(s_i\) の源で分類して整理する。
Token logprob: trace-level confidence の家族
Deep Think with Confidence(DeepConf)(Fu ほか 2025年) は trace-level confidence 信号の家族である。Meta AI が NeurIPS 2025 Efficient Reasoning Workshop で発表(Spotlight)。原論文は top-20 token log-probability \(\{P_{t,j}\}_{j \leq 20}\) から \(C_t = -\frac{1}{20}\sum_{j=1}^{20}\log P_{t,j}\) を計算し、それを 5 通りの集約で trace スコアにする:
| 名称 | 定義 |
|---|---|
| First-token | 最初の生成トークン位置における top-20 分布と uniform との KL ダイバージェンス |
| Mean | \(\tfrac{1}{|y|}\sum_t C_t\)(全 trace の単純平均) |
| Bottom-10% | \(C_t\) の sliding window 平均(window 1024)の下位 10% の平均 |
| Block-min | double-newline で分割したブロック平均の最小値 |
| Tail | 最後の 2,048 token 上での \(C_t\) 平均 |
集約は \(w(s) = s\)(恒等)の WMV で、\(v_i(a) = s(y_i, \ell_i) \cdot \mathbf{1}\{a_i = a\}\) となる。さらに confidence filtering として、信号の上位 \(\eta\)% の trace だけを残してから投票するバリアントが導入される。
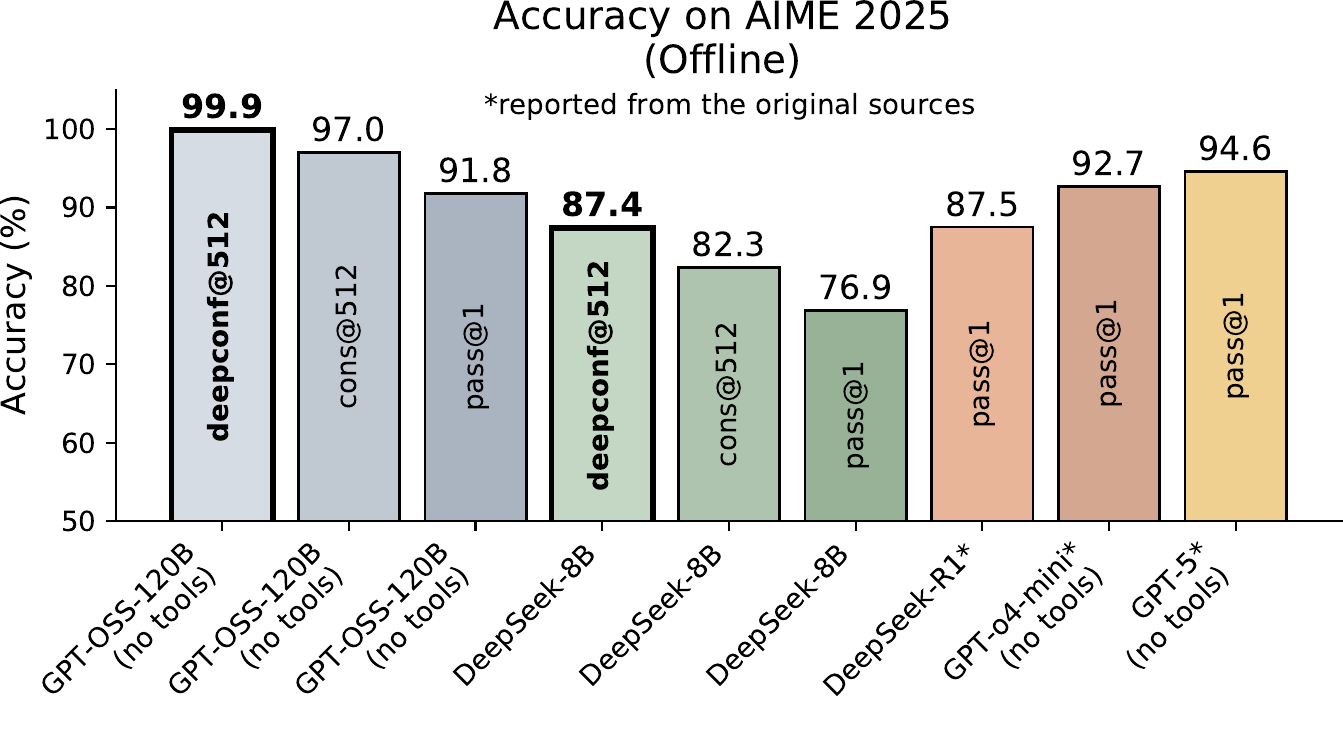
図 1 に概略を示す。原論文の目玉である AIME 2025 + GPT-OSS-120B で DeepConf@512 が 99.9% の精度 に到達し標準多数決 97.0% を上回ったうえで生成トークンを 84.7% 削減したという結果は、bottom-10%/tail の confidence filtering + 早期打ち切り を組み合わせた構成での値で、家族の中の特定のバリアントである点に注意する(図 2)。
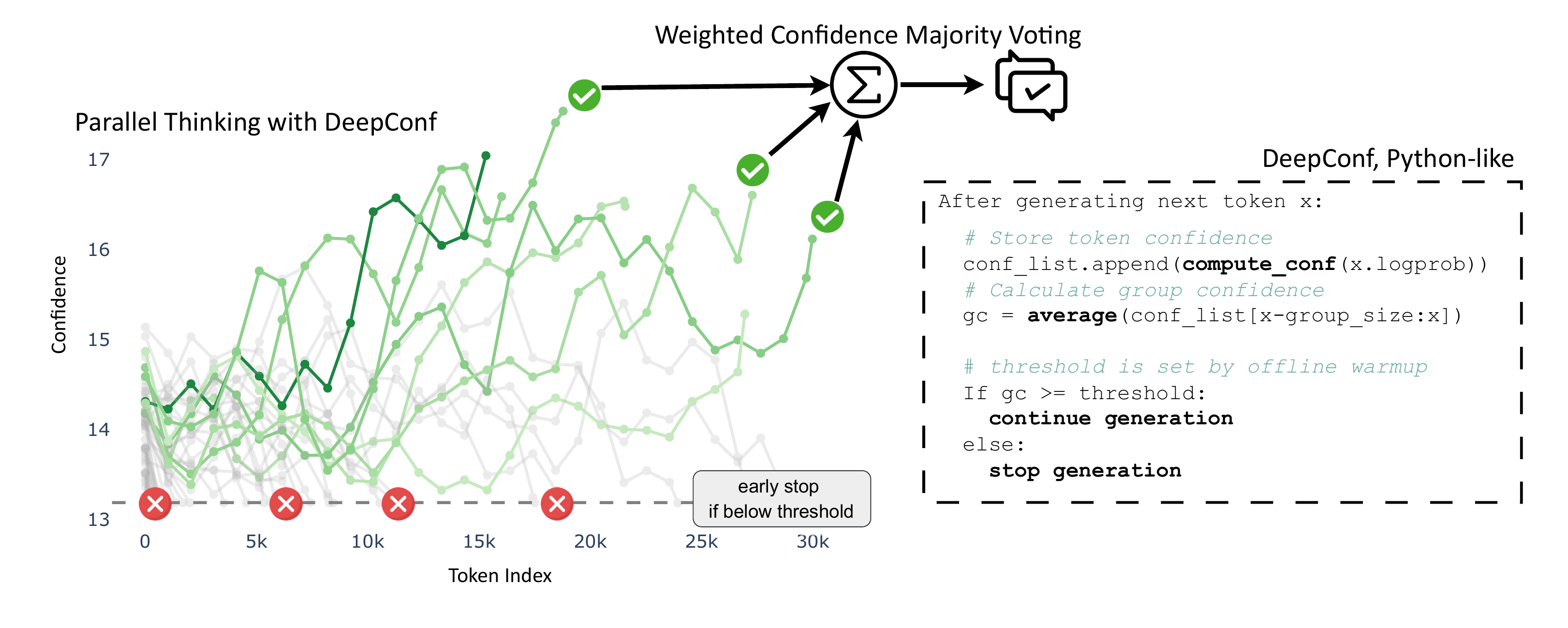
DeepConf は token log-probability にアクセスできる前提(grey-box)に立つため、log-probability を返さない API では使えない。また Pass@1 が低い難問では DeepConf の各バリアントの per-problem signal 分布が正答 trace と誤答 trace でほぼ重なる現象も独立に報告されており (Iwase ほか 2026年)、logit 系信号の頭打ちが「重み付け系の上限」を決めている可能性が示唆されている。
Logit/entropy 系の他の代表: Self-Certainty・CER・IEW
DeepConf 家族の “Mean” は、Self-Certainty (Kang ほか 2025年) の top-20 近似版に相当する。Self-Certainty は語彙全体に対する token 分布と uniform 分布の Kullback–Leibler(KL)ダイバージェンスの全 trace 平均として定義され、reward model なしの Best-of-N 信号として提案された(NeurIPS 2025 採択)。Borda voting と組み合わせて SC を超え、open-ended な生成にも一般化できる点が特徴である。図 3 は SC が誤答に投票する典型的な失敗例を示している。同一問題への 6 本の chain のうち多数派 50 が SC で勝つが、Self-Certainty で測ると正答 64 の chain が高い certainty を示し、Borda voting が正答を選び直す。

CER (Razghandi ほか 2025年) は trace 全体の平均ではなく、reasoning trace 中の critical decision points(数値や固有名詞など)に注目し、その位置の logit から confidence を取る training-free な weighting フレームワークである。数学で最大 7.4%、open-domain で 5.8% の改善を報告した。
IEW(Inverse-Entropy Voting)(Sharma と Chopra 2025年) は trace 全体の token-level Shannon entropy の逆数を重みとする。同一 token 予算下で IEW + 逐次 self-refinement が並列 SC を 95.6% の構成で上回り、AIME-2024/25・GPQA-Diamond で最大 46.7% 改善した。
DeepConf Mean / Self-Certainty / CER / IEW は どの位置の logit を読むか(全 trace 平均か、critical points か、bottom-window か、tail か)と どの統計量を作るか(KL、entropy、log-prob)の組み合わせで分岐しており、その背後には「正答 chain は logit 上で内部的に異なる」という共通仮説が置かれている。
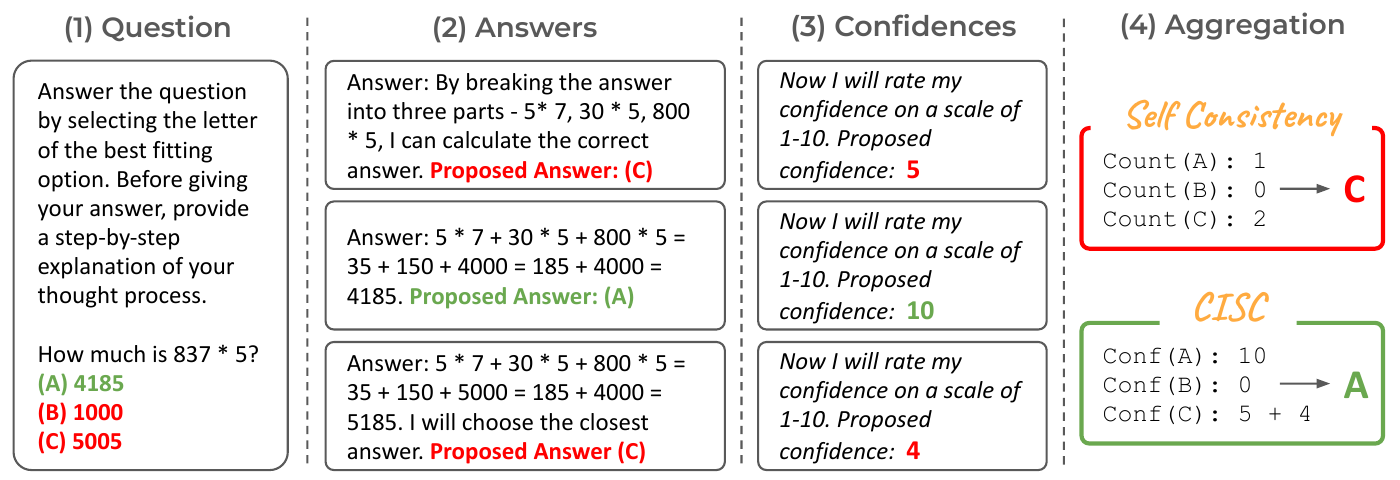
Verbalized・rating call 系と CISC フレームワーク
CISC(Confidence-Informed Self-Consistency)(Taubenfeld ほか 2025年) は単一手法ではなく、既存の per-sample confidence 源を softmax weighting でまとめる フレームワークである。原論文は raw confidence の source として以下 4 つを比較している:
| Source | log-prob 依存 | 説明 |
|---|---|---|
| Response probability (X. Wang ほか 2023年) | あり | trace 全体の length-normalized geometric mean of per-token probabilities。Wang らの SC 原論文で既に weighted variant として提案 |
| Verbal binary (Lin ほか 2022年) | なし | 別 prompt で {0, 1} の自己 rating を聞く |
| Verbal 0–100 (Lin ほか 2022年) | なし | 別 prompt で 0–100 の自己 rating を聞く |
| P(True) (Kadavath ほか 2022年) | あり | rating call 位置で「1」と「0」の logit を読み、\(\exp(\ell_1)/(\exp(\ell_0)+\exp(\ell_1))\) で確率を作る |
CISC の貢献は (a) 信号源を統一的に比較したことと、(b) softmax with temperature \(T\) で sample-soft 重みに変える weighting 設計の二つで、信号源そのものは既存研究に由来する点に注意する。図 4 は CISC の集約手順を SC と並べて示している。
verbalized confidence の calibration が壊れていることは独立に複数の研究で示されている。DINCO (V. Wang と Stengel-Eskin 2025年) は ICLR 2026 で「LLM の verbalized confidence は過信気味」と実証し、self-generated distractor で正規化する手法を提案した。Verbal binary / Verbal 0–100 は CISC framework の中ではしばしば最弱の source として現れ、強い source は P(True) と Response probability に偏ることが報告されている。
外部一貫性ベース: 再生成や同意で信頼度を測る
ここまでは sample \(i\) の中身(logit、verbalized rating)から \(s_i\) を取り出す系統だった。これに対し、サンプル間の関係や再生成挙動から信号を作る系統がある。Prefix Consistency (Iwase ほか 2026年) は CoT を比率 \(\tau\) で切り再生成した後続が元の答えに戻るかを per-candidate に集計して WMV に流す。同じ再生成操作を共有する手法群と並べた整理は次節「Prefix を活用する系」で行う。NAD(Neuron Agreement Decoding)(Chen ほか 2025年) は正答時に活性化するニューロンが少なく複数サンプル間でより強く一致するという発見に基づき、内部 neuron agreement のみで Best-of-N を行う。外部観測(再生成一致)と内部観測(neuron agreement)は、いずれも「正答 chain はサンプル間で構造的に再現される」という同じ仮説を、異なる粒度で計測している。
Prefix を活用する系: 短い prefix から後続を予測する
第二の方向は、reasoning trace の prefix を集約の起点とする系統である。独立した複数のグループがほぼ同時期にこの方向に到達したことが特徴で、prefix が answer を予測するという共通仮説を、weight 設計・cluster 選別・足切り・再生成という別の operation で具体化している。
Prefix clustering: 展開するパスを選ぶ
PoLR(Path of Least Resistance)(Jindal ほか 2026年) は短い prefix を clustering し、最頻 cluster に属するパスのみを完全展開する inference-time 手法である。「early reasoning steps が final correctness を予測する」ことを mutual information と entropy で理論化し、GSM8K・MATH500・AIME24/25・GPQA-Diamond で SC と同等以上の精度を保ちつつトークン最大 60%・wall-clock 50% を削減した。ICLR 2026 採択。
Prefix confidence: 1 本に絞る
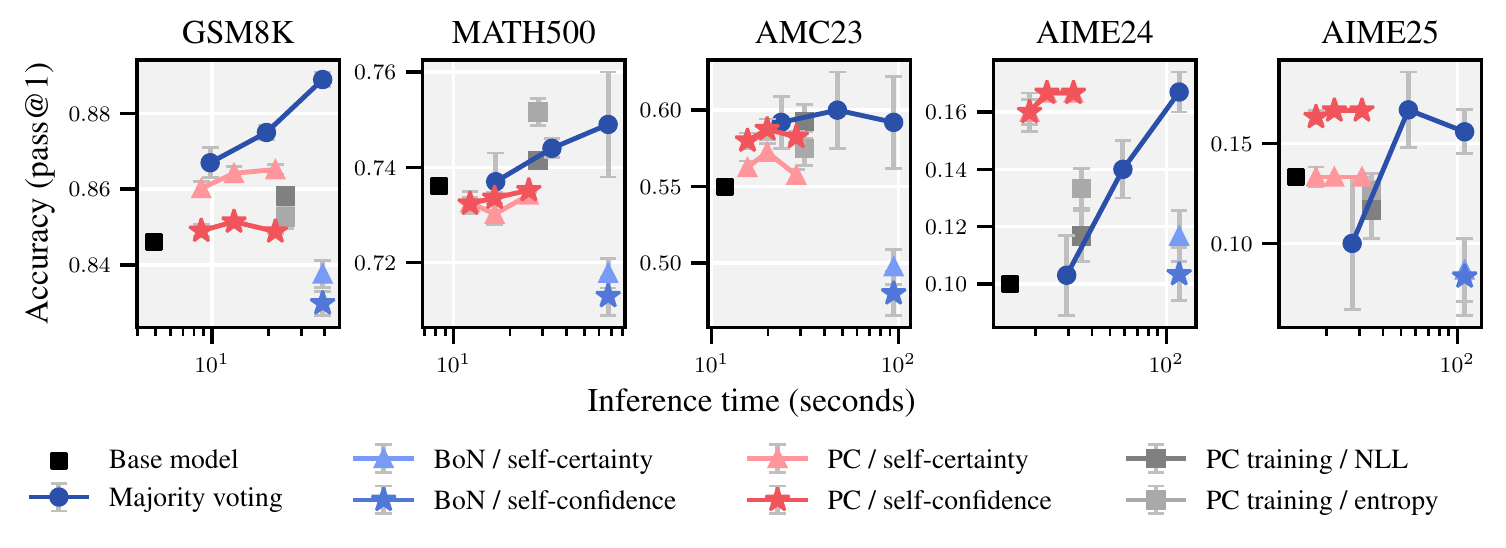
Prefix-Confidence Scaling (Otth ほか 2025年) は 32-token の短い prefix だけを生成して各 candidate の prefix-confidence を測り、最も有望な 1 本のみ続行する。GSM8K・MATH・AMC・AIME のすべてで多数決投票よりも良い accuracy–compute tradeoff を示し、長さバイアスにも頑健であることを報告した。図 5 に 5 つの数学ベンチでの inference time vs accuracy 曲線を示す。各点が異なる予算設定に対応し、prefix-confidence を使う設定(赤系のマーカー)が同等の時間で majority voting(青)を上回るか、より少ない時間で同等精度に到達することが見て取れる。
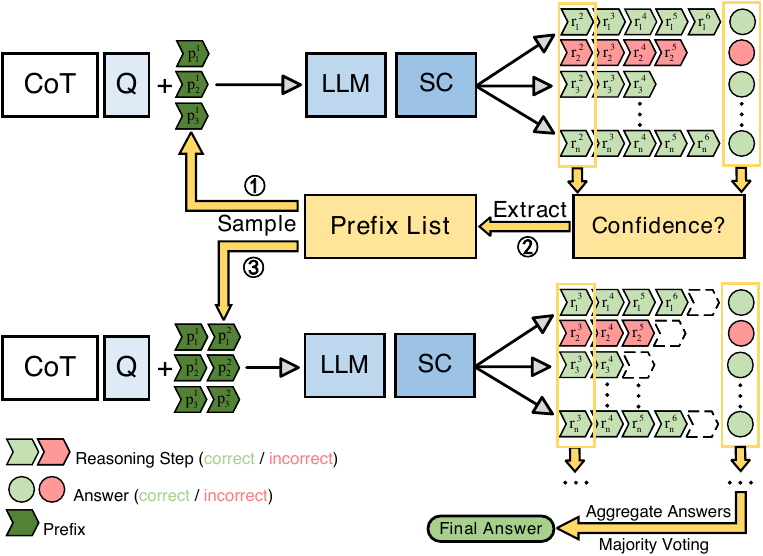
Path-consistency: 頻度で SC を強化
Path-Consistency (Zhu ほか 2024年) は 複数の有望な prefix を Prefix List として並列に保持し、各候補を起点として後続を伸ばす 設計で SC を強化する。図 6 の手順は段階的で、各 window 境界で多数派最終答えが beta 信頼度の閾値を超えた時点で、その答えに到達した optimal paths から共通の level-\(\ell\) prefix を抽出して Prefix List に追加する。各候補は iteration が進むごとに level が 1 段ずつ伸びる。後段では Prefix List 内のいずれかの prefix 以降だけを生成すれば良いので、トークン量を削減しながら SC を実行できる。原論文の定式化では、最終答え分布が Prefix List 上の marginalization
\[ P(a \mid q) \;=\; \sum_{R_{\mathrm{prefix}} \in \mathcal{P}} P(R_{\mathrm{prefix}} \mid q)\, P(a \mid q, R_{\mathrm{prefix}}) \tag{3}\]
として書かれており、Prefix List \(\mathcal{P}\) が 単一 trunk ではなく複数候補 であることがここに露わになる。図 6 で縦に並ぶ \(p_1, p_2, p_3\) はそれぞれが \(\mathcal{P}\) の別エントリで、後段の iteration では各候補が独立に 1 段ずつ伸びる (\(p_i^1 \to p_i^1 + p_i^2\))。
Speculative truncation: 早期に枝刈り
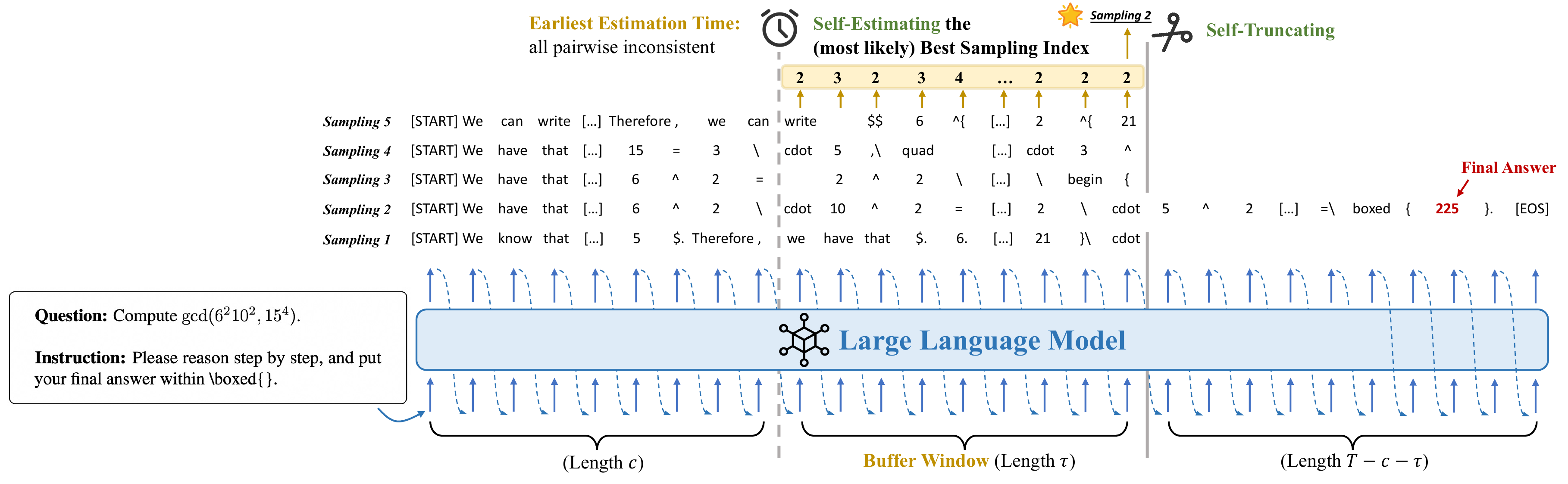
ST-BoN(Self-Truncation Best-of-N)(Y. Wang ほか 2025年) は早期 decoding 段階で「内部 sampling consistency」を測定し、有望でない candidate を truncate する。GPU メモリ 80%・レイテンシ 50%・compute 70–80% の削減を実現した。NeurIPS 2025 Spotlight。図 7 の通り、早期の “earliest estimation time” でサンプル間の内部一致度を見て、もっとも有望なサンプル(図中の sampling 3)以外を打ち切ることで、後続の生成コストを大幅に節約する。
Subthought 分割と再生成: Mode aggregation
Beyond the Last Answer (Hammoud ほか 2025年) は、reasoning trace を言語マーカーで複数の subthought に分割し、各分割点から後続を再生成して 回答の最頻値(mode)を取る手法である。Prefix Consistency (Iwase ほか 2026年) の直接的な先行研究にあたり、prefix からの再生成という操作を共有する。
具体的には、"Wait", "Hmm", "Alternatively", "Actually", "Therefore", "So", "First", "Next" といった反省・代替探索・修正・結論遷移のマーカーで CoT を \(s_1, s_2, \dots, s_n\) に分割し、各接頭辞 \(s_1 \oplus \cdots \oplus s_j\) から continuation を再生成して回答 \(A_j\) を抽出する。最終答えは
\[ A_{\text{mode}} = \arg\max_{A} \sum_{j=1}^{n} \mathbf{1}\{A_j = A\} \tag{4}\]
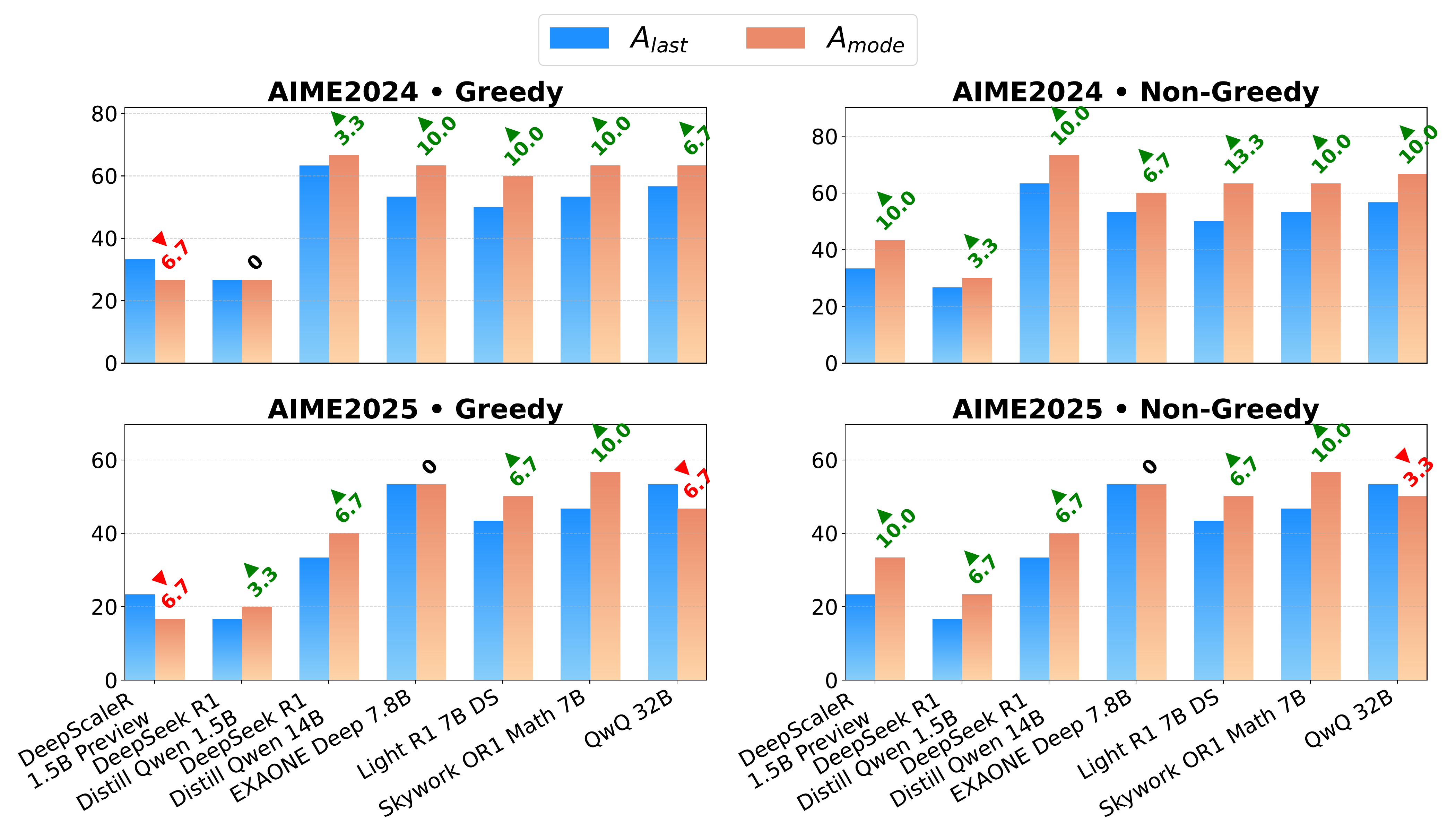
で選ぶ。図 8 は、最終 subthought が誤答 50 を返す一方で、中間 subthought 群から再生成された答えの mode が正答 96 になる典型例を示している。reasoning trace は最終回答以上の情報を持ち、途中段階の再生成を集約することで隠れた多数派を救えるという発見である。

報告された改善は大きく、AIME 2024 で最大 +13%、AIME 2025 で +10% の精度向上を複数の reasoning model にわたって確認した(図 9)。subthought ごとの回答一致パターンが confidence と correctness に相関するという観察も付随する。
Prefix Consistency (Iwase ほか 2026年) は、この再生成操作の集約方法を mode から 元答えに戻る率 に置き換え、WMV の重み源として使う点で differentiate される。後続節でこの点を整理する。
Prefix consistency: 再生成で信頼度を測る
Prefix Consistency (Iwase ほか 2026年) は CoT を比率 \(\tau\) で切り、prefix から後続を再生成して 元の答えに戻る率 を投票重みに使う。重み付け系(式 2)の枠組みに乗りつつ、weight の source として prefix-regeneration consistency を採用する点が特徴である。Beyond the Last Answer (Hammoud ほか 2025年) が mode を最終答えとして採用する training-free aggregator であるのに対し、Prefix Consistency は一致率そのものを連続的な weight として WMV に流す。同じ操作から別の signal を取り出している。
同じ仮説、異なる operation
表 1 に prefix を起点とする手法を並べる。共通仮説は「短い prefix が最終答えの正しさを予測する」であり、各手法はこれを別の operation で具体化している。
| 手法 | prefix の使い方 | 出力 |
|---|---|---|
| PoLR (Jindal ほか 2026年) | clustering して dominant cluster を選別 | 展開するパスの集合 |
| Prefix-Confidence Scaling (Otth ほか 2025年) | confidence で top-1 を選ぶ | 1 本の chain |
| Path-Consistency (Zhu ほか 2024年) | 出現頻度で SC を強化 | 加重多数決 |
| ST-BoN (Y. Wang ほか 2025年) | 早期に枝刈り | 残ったパスの集合 |
| Beyond the Last Answer (Hammoud ほか 2025年) | 言語マーカーで分割し各点から再生成 | 再生成回答の mode |
| Prefix Consistency (Iwase ほか 2026年) | 再生成して元答えに戻る率を測る | 加重多数決 |
「prefix が answer を担う」という観察が複数グループから独立に得られたことは、prefix が reasoning における load-bearing な要素であるという仮説の傍証となる。
PoLR (Jindal ほか 2026年) と Path-Consistency (Zhu ほか 2024年) は 両方とも prefix 集合上の skew で SC を効率化する 同型の peer 関係にある。名称も “Prefix Consensus” (PoLR) / “Path-Consistency” / “Prefix Consistency” (Iwase ほか 2026年) と三重に近接するが、構造的には次のように対称な変種を成す。
| 軸 | Path-Consistency | PoLR |
|---|---|---|
| 信号 | exact prefix の出現頻度 \(\mathrm{count}(p) / N\) | TF-IDF lexical 類似下の cluster サイズ占有率 \(\lvert C^{*} \rvert / N\) |
| 展開戦略 | sequential extract-and-sample (window ごとに iteration) | one-shot (短 prefix を一回 sample → clustering → dominant 展開) |
| 候補抽出の機構 | confidence-gated (beta 信頼度 ≥ threshold) | clustering-based (TF-IDF agglomerative + dominant cluster) |
| 主目的 | latency / token 削減 | token / latency 削減 + Adaptive Consistency (AC) / Early-Stopping SC (ESC) との直交 pre-filter |
| Box 性 | Black-box | Black-box |
| 信号粒度 | prefix exact freq | prefix 集合上の cluster skew |
両者は「prefix 集合の skew を SC 効率化に転用する」枠組みは同じで、measure (exact freq vs lexical cluster) と展開戦略 (sequential vs one-shot) のみ対称的に分かれる。Related Work でこの 2 本は「軸 (5) trajectory agreement 内の双子」として扱える。
理論的支柱: 加重多数決は MAP 最適である
加重多数決が単純多数決を支配することは、近年 ICLR 2026 で理論的にも裏付けられた。
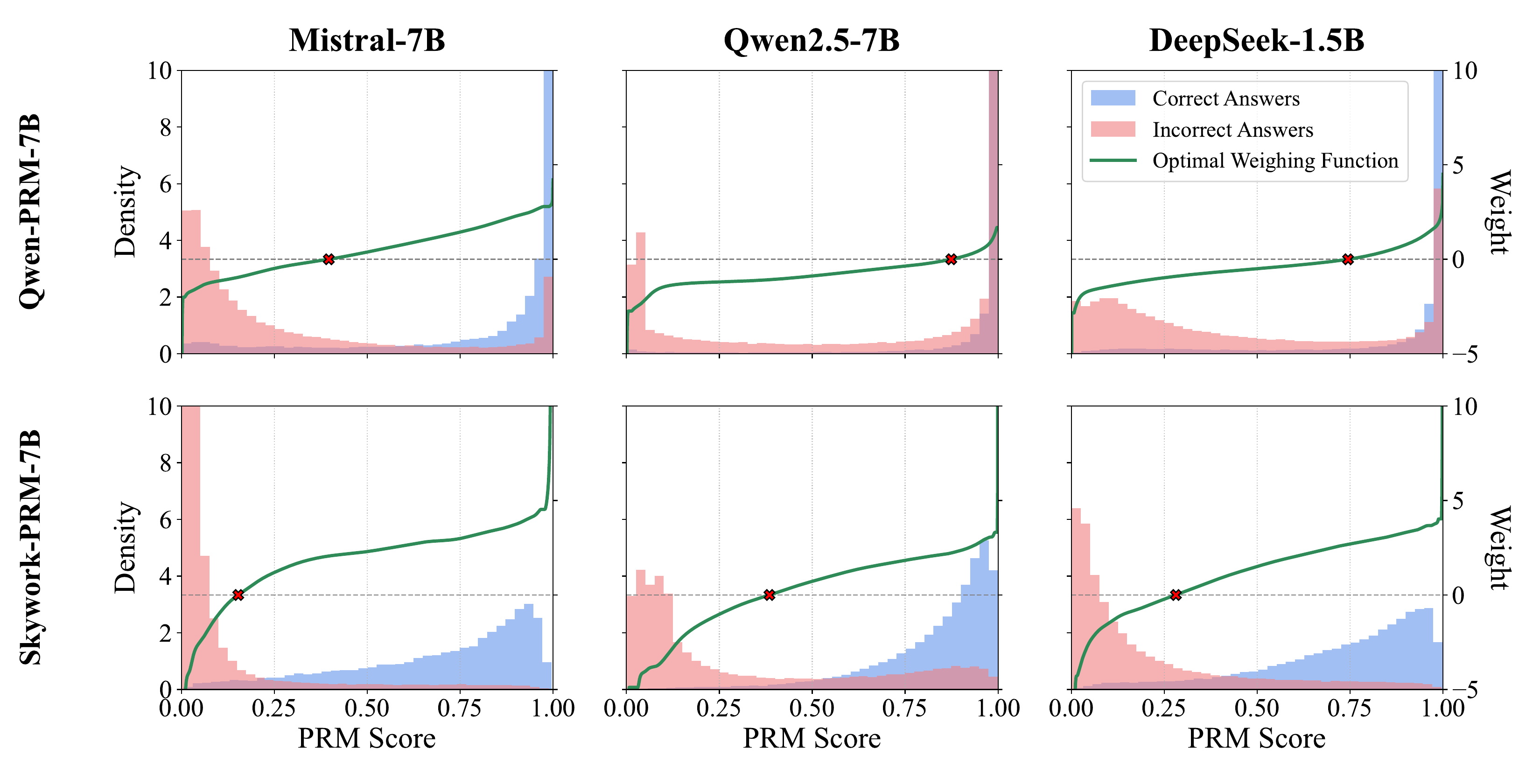
Kuang らの研究 (Kuang ほか 2025年) は LLM signal と Process Reward Model(PRM)signal を最適に結合する MAP 推定 として集約問題を定式化した。結果は単純な best-scoring 選択ではなく calibrated weighted majority vote が最適であることを理論的に示し、test-time compute を 37.1% / 21.3% 削減した。図 10 は導出された最適な重み関数の形状を示している。correct/incorrect の PRM score 分布が異なるとき、最適な重みは PRM スコアに対して単純な線形ではなく非線形に変動し、高スコア側で急激に重みが立ち上がる形になる。
Ai らの研究 (Ai ほか 2025年) は「多数決は zero-order 集約に過ぎず、各モデルの expected accuracy(一次)と回答相関(二次)を活用すべき」と主張し、Optimal Weight(OW)と Inverse Surprising Popularity(ISP)という二つのアルゴリズムを理論解析つきで提案した。UltraFeedback・MMLU・ARMMAN で多数決を 1.16–3.36% 上回る。
Best-of-∞ (Komiyama ほか 2026年) は多数決 Best-of-N の \(N \to \infty\) 極限を分析し、有限予算で同等性能を出すための adaptive 生成方式を提案する。さらに複数 LLM の weighted ensemble に拡張し、最適重みを mixed-integer linear program(MILP)として定式化した。ICLR 2026 採択。
別の方向として AggLM (Zhao ほか 2025年) は「投票関数そのものを RL で学習する」アプローチを取る。複数解候補を入力として正解を合成する aggregator LM を verifiable reward で訓練し、majority voting と reward re-ranking の双方を上回ることを示した。training-free な WMV 系手法に対する upper bound 的位置づけになる。
Adaptive sampling と早期停止: N を動的に決める
固定 N の SC は単純な代わりに無駄が多い。簡単な問題には少ない N で十分、難しい問題ほど多くの N が必要、という直観を定式化する研究が 2025–2026 年に急増した。
Bayesian / SPRT 系
BEACON (Wan ほか 2025年) は Sequential Search with Bayesian Learning に基づき、reward 分布の事後信念を逐次更新して「追加生成の marginal utility がコストを下回ったら停止」する。平均サンプル数を最大 80% 削減。
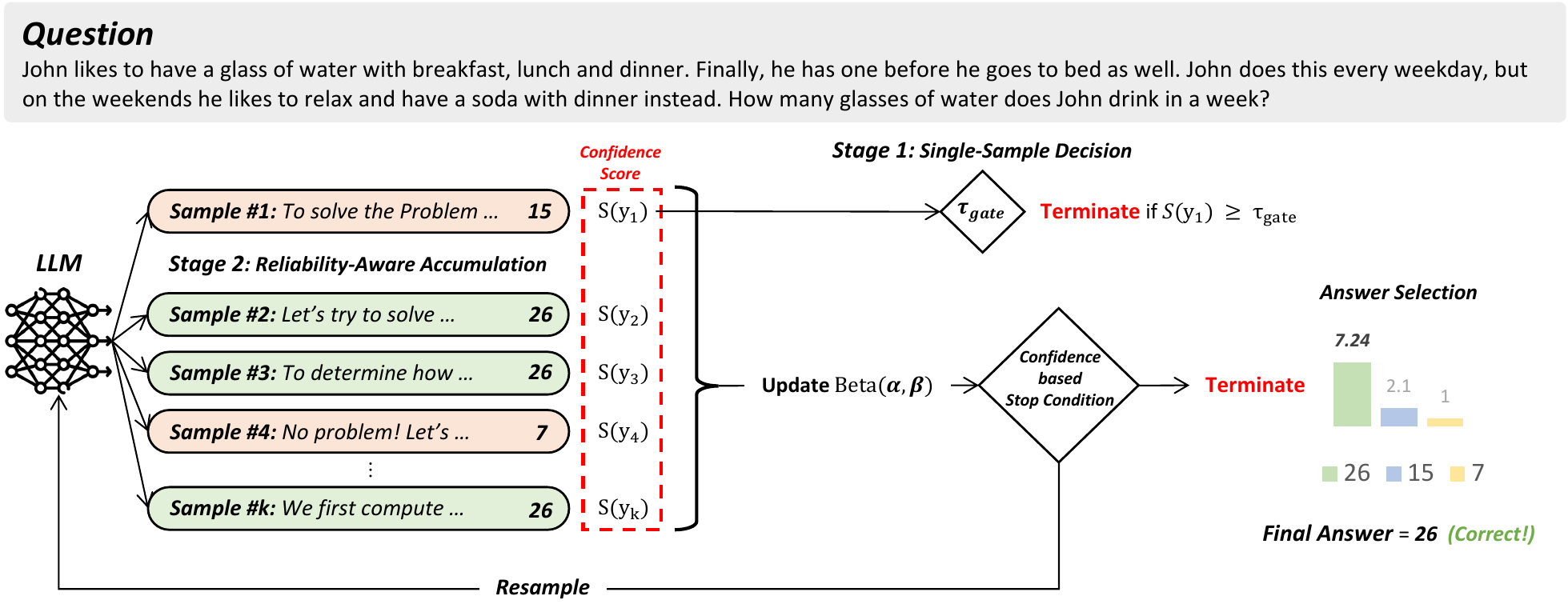
ReASC(Reliability-Aware Adaptive Self-Consistency)(Kim ほか 2026年) は、上位 2 候補の支持率 \(p\) を Beta 分布でモデル化し、各サンプルの信頼度 \(z(y_i)\)(標準化された bottom-10% confidence)を \(\max(1, \exp(\lambda z))\) で「証拠量」に変換して逐次更新する。事後確率 \(P(p_1 > p_2 \mid V)\) が閾値(典型 0.95)を超えたら停止するため、サンプリングコストを問題依存に削減できる。Gemma-3-4B / Qwen-2.5-7B など 5 モデル × GSM8K を含む 4 ベンチで、SC(k=16)と同等精度を保ちつつ 約 70% のコスト削減を報告。図 11 にフレームワーク全体を示す。第 1 段で最初の 1 サンプルの信頼度が閾値 \(\tau_{\text{gate}}\) を超えれば即決し、超えなければ第 2 段で信頼度重み付き Beta 更新を回す二段構成である。
ReASC は Best-of-∞ (Komiyama ほか 2026年) と思想が近い。両者とも「ベイズ的に answer 分布の事後信念を更新し、追加サンプルが marginal にしか効かなくなった時点で止める」という骨格を共有する。Bo∞ は reward model のスカラー報酬を証拠として使うのに対し、ReASC は token logprob 由来の self-confidence を証拠として使う。BEACON / CGES / ReASC / Bo∞ はいずれも 信号源は違うが停止規則は同じ Bayes 更新 という構造に収斂しており、weight 設計と stopping rule の組み合わせ空間が大きく残されていることを示している。
CGES (Aghazadeh ほか 2025年) は token probability または PRM 由来のスカラー信号で各候補回答に事後分布を作り、posterior mass が閾値を超えたら停止する。NeurIPS 2025 Workshop on Efficient Reasoning。
ConSol (Lee ほか 2025年) は古典的な 順序確率比検定(Sequential Probability Ratio Test, SPRT)を LLM 自己一貫性向けに calibration し、十分な一貫性に達した瞬間に止める。
Verbal confidence + 少数サンプル: 取り下げ済みの主張
Two Samples Are Enough: Verbal Confidence Meets Self-Consistency in Reasoning LLMs (Del ほか 2026年) は ICLR 2026 に投稿後に取り下げられた(OpenReview ID: 66D3rZrNjV)。以下は参考情報として記すが、査読を経た確定結果ではない。
主張は単純で、6 種類の verbalized confidence(VC)手法、SC、およびそれらの hybrid (VCSC) を 9 つの科学系ベンチと 3 つの reasoning model で比較した結果、2 サンプル + verbal confidence だけで 16–64 サンプルの SC と同等以上の信頼性評価が得られる、というものである。 これが本当に成立するなら推論サンプル数は桁違いに削減できるが、verbalized confidence は CISC (Taubenfeld ほか 2025年) と DINCO (V. Wang と Stengel-Eskin 2025年) でも指摘される通り calibration がプロンプト・モデル依存で揺れる。reasoning model の calibration 特性は通常 LLM と異なるため、追試と検証が必要な主張として扱うのが妥当である。
Budget allocation 系
SeerSC (Ji ほか 2025年) は System 1 で高速に answer entropy を計算して各問題の「必要サンプル数」を事前推定し、System 2 で並列にその数だけ生成する。逐次的な ASC/ESC と違い並列実行と両立し、トークン 47%・レイテンシ 43% を削減した。
PETS (Liu ほか 2026年) は「無限予算 majority vote との一致率」を self-consistency rate と定義し、限定予算下で trajectory allocation を最適化する。crowdsourcing 理論に基づくオフライン割当と、難易度に応じたオンライン割当アルゴリズムを与え、GPQA で予算を 75% 削減した。
Pruning 系
Token Set Cover (Sultan と Astudillo 2025年) はモデル信頼度と語彙的カバレッジを組み合わせた weighted set cover で、SC 途中の不要な仮説を周期的に刈る。5 つの LLM × 3 つの数学ベンチで 10–35% のトークン削減を報告。
これら adaptive sampling の研究は加重多数決の研究と 直交 している。weight 設計と stopping rule は組み合わせ可能で、BEACON で動的に N を決め、Prefix Consistency や IEW で集約する、という運用が自然な発展形になる。
Universal Self-Consistency と意味的集約
exact match で集約できないタスク(要約、open-ended QA、長文回答)には別の仕掛けが要る。
Latent Self-Consistency(LSC)(Oh と Lee 2025年) は各応答末尾に learnable summary token を付け、その埋め込みの cosine 類似度で意味的多数派を検出する。KV cache 再利用で計算オーバーヘッドは 0.9% 以下。短答・長答どちらにも対応する。
Representation Consistency(RC)(Jiang ほか 2025年) は回答頻度だけでなく、生成中の内部活性化(dense / sparse autoencoder の出力)の一貫性を加味して集約する。最大 4% の精度向上。NeurIPS 2025。
string-match 投票(SC)、埋め込み投票(LSC)、内部活性化投票(RC)という三層が並列に発展している。
内部状態 probing 系: 別系統の信号源
ここまで紹介した手法は基本的に「外部観測(出力 token、再生成、agreement)」を信号とするが、内部状態を直接 probe する系統も並行発展している。
Hidden-state probing (Zhang ほか 2025年) は答え位置の hidden state に binary 分類器を訓練し、中間答えの正誤を予測する。「もうここで止めて良い」判定に使い、トークン 24% を削減した。
ReProbe (Ni ほか 2025年) は 10M 未満のパラメータの transformer probe で frozen LLM の internal state から step-credibility を予測する。最大 810 倍大きい PRM と同等以上の性能を MATH・Plan・QA で達成。ACL 2026 採択。
Calibrated Reasoning (Garg ほか 2025年) は Group Relative Policy Optimization(GRPO)で訓練したペアワイズ Explanatory Verifier が calibrated confidence と自然言語説明を出し、両解が同じ誤りを共有するケースなど majority vote が失敗する状況で勝つ。
これらは外部信号(Self-Consistency や prefix-based 系など)と相補的で、組み合わせて higher-order な aggregator を作る方向の研究余地が大きい。
Agent 設定への拡張
reasoning は単発回答だけでなく multi-step agent にも必要である。
TrACE (Sethi 2026年) は LLM agent の各ステップで小サンプル間の action agreement を測り、agreement が高ければ即決、低ければ追加サンプルを取る訓練不要 controller を提案する。SC-4 相当の精度を GSM8K で 33%、MiniHouse で 39% 少ない呼び出しで達成した。
「rollout 間 agreement を free signal にする」というアプローチは 式 2 の WMV と agent setting を橋渡しする位置にある。
章のまとめ
本章では SC を起点とする集約手法の 4 軸を整理した。
- 重み付け系: token logprob (Fu ほか 2025年)、verbalized (Taubenfeld ほか 2025年)、logit/entropy (Razghandi ほか 2025年; Kang ほか 2025年; Sharma と Chopra 2025年)、外部一貫性 (Iwase ほか 2026年; Chen ほか 2025年) と weight source が分岐
- Prefix を活用する系: PoLR (Jindal ほか 2026年)、Path-Consistency (Zhu ほか 2024年)、Prefix-Confidence Scaling (Otth ほか 2025年)、ST-BoN (Y. Wang ほか 2025年)、Beyond the Last Answer (Hammoud ほか 2025年)、Prefix Consistency (Iwase ほか 2026年) が独立に同じ仮説に到達
- 理論的支柱: 加重多数決が MAP-optimal (Kuang ほか 2025年)、higher-order 情報の活用 (Ai ほか 2025年)、\(N \to \infty\) 極限 (Komiyama ほか 2026年)、学習型集約 (Zhao ほか 2025年)
- Adaptive sampling: Bayesian/SPRT (Wan ほか 2025年; Kim ほか 2026年; Aghazadeh ほか 2025年; Lee ほか 2025年)、budget allocation (Ji ほか 2025年; Liu ほか 2026年)、pruning (Sultan と Astudillo 2025年)、verbal confidence による少数サンプル化 (Del ほか 2026年)
これら 4 軸は 直交 しており、組み合わせて運用できる。たとえば「BEACON で動的に N を決め、prefix から weight を作り、加重多数決で集約する」というレシピは原理的に成立する。実際にどの組み合わせが accuracy–compute Pareto を支配するかは、2026 年現在の open question である。
加えて、外部観測(再生成、agreement)と 内部観測(hidden state probe、neuron agreement、representation consistency)は相補的な信号源として位置づけられ、両者を統合する higher-order aggregator が次のフロンティアになりつつある。Process Reward Model 系の研究(Process Reward Models)と本章の流れは Kuang ほか (2025年) や Zhao ほか (2025年) で交差し始めており、訓練側信号と推論 (inference) 側信号の境界自体が溶けていくのが直近の流れである。