Reasoning in Diffusion LLMs
本章では masked diffusion 系の大規模言語モデル(Diffusion Large Language Model, DLLM)における reasoning を扱う。Autoregressive(AR)モデルが左から右へ一方向に系列を生成するのに対し、DLLM は完全 mask 状態の系列から並列に unmask していくため、生成順序や中間状態の扱いが本質的に異なる(図 1)。本書のこれまでの章で扱ってきた self-consistency や confidence といった「推論 (inference) 側の信号」は、AR モデルを前提として発展してきたが、2025–2026 年にかけて DLLM においても類似の問題意識から派生した手法が独立に複数登場している。
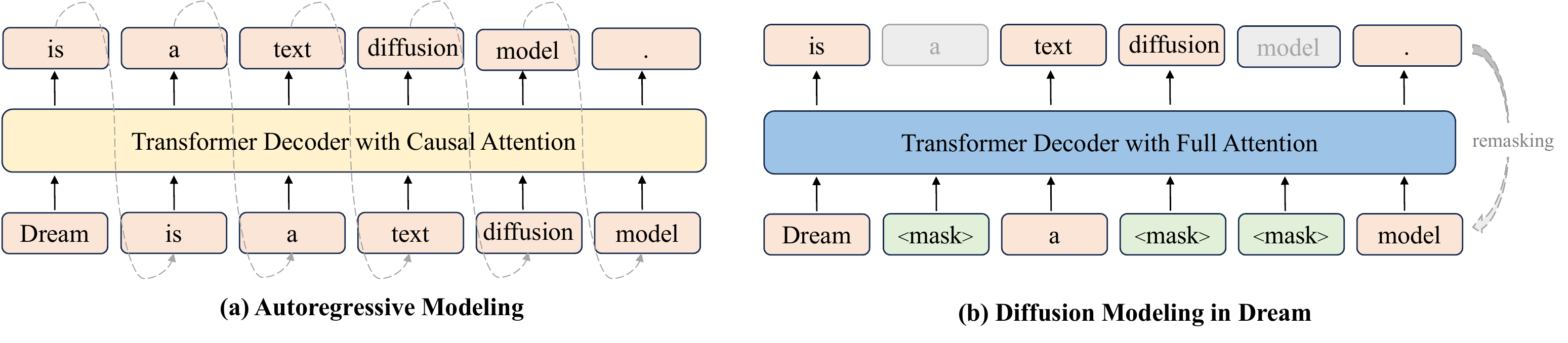
本書では DLLM の reasoning に焦点を絞る。DLLM 全般の理論基盤・訓練手法・派生モデルについては別本 Diffusion Language Models を参照。本章では基盤モデルの説明は最小限にとどめる。
基盤となる DLLM たち
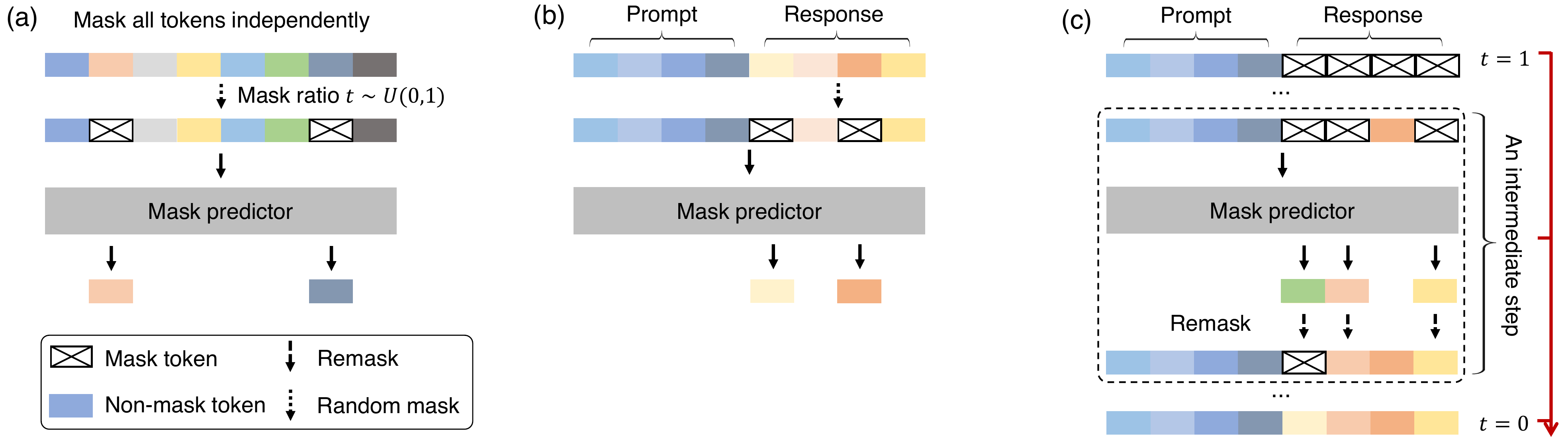
DLLM の出発点は Masked Diffusion Language Model(MDLM)(Sahoo ほか 2024年) による absorbing-state discrete diffusion の整理である。図 2 に LLaDA を例として、masked diffusion LM の (a) forward 過程(mask ratio \(t \sim U(0,1)\) でランダムに mask)、(b) prompt-conditional な mask predictor 訓練、(c) 推論時の denoising trajectory(中間 step で再 mask しながら徐々に答えに近づく)を示す。続いて 7B–8B スケールに到達した DLLM が複数登場し、reasoning 研究の実験基盤となっている。
- LLaDA(Nie ほか 2025年):8B 規模で初めて AR の LLaMA3 8B と互角の in-context learning 性能を達成した DLLM。Token を逐次的に mask する forward 過程と Transformer による reverse denoising という標準的な masked diffusion 設計を採り、open weight で配布されている。後続の DLLM-RL 研究の事実上の base model
- Dream 7B(Ye ほか 2025年):AR LLM 初期化と context-adaptive noise rescheduling で訓練された open DLLM。arbitrary-order generation と infilling、quality-speed の tunability を強調し、math/code と planning で LLaDA を上回る
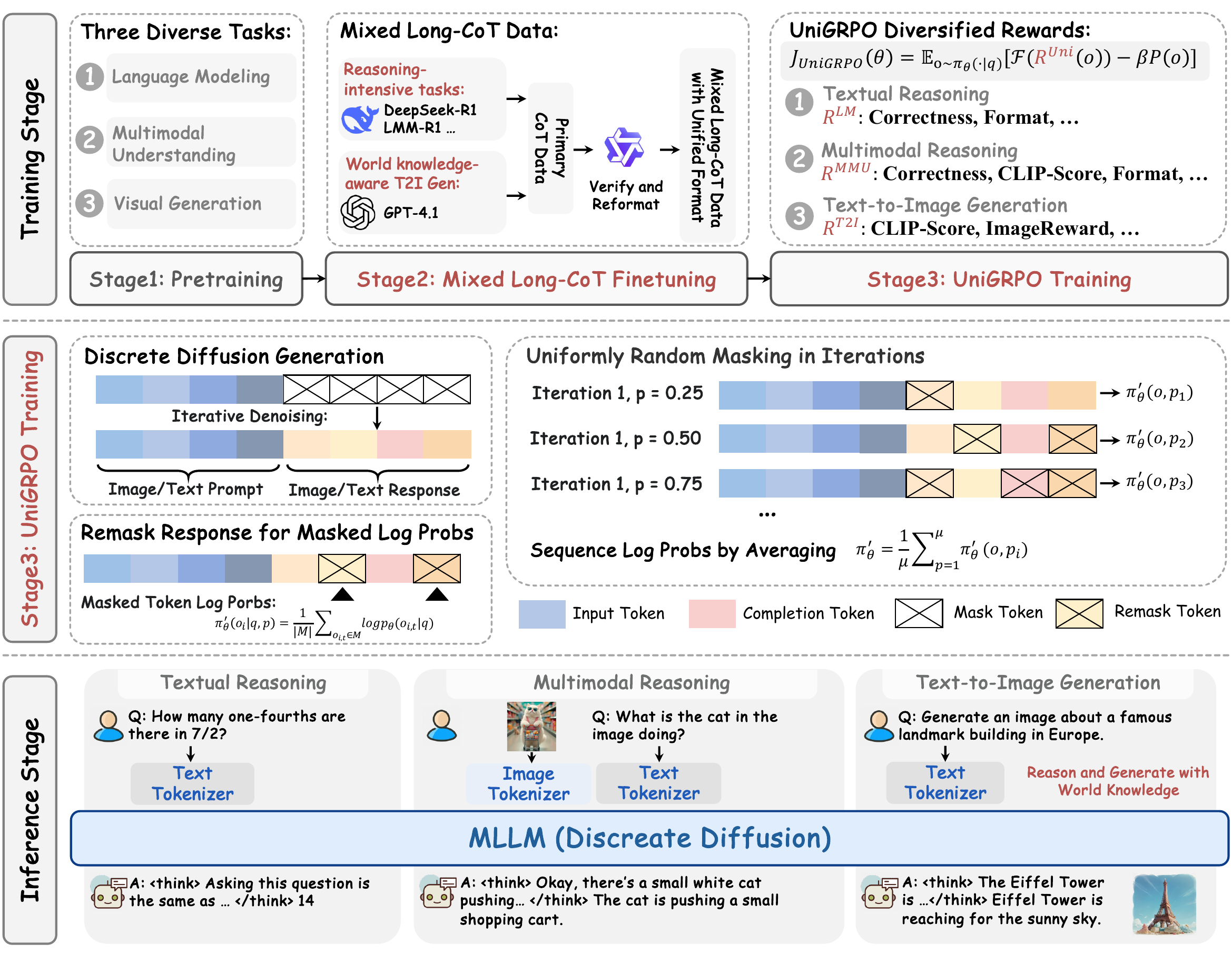
- MMaDA(L. Yang ほか 2025年):textual reasoning、multimodal understanding、text-to-image generation を単一の diffusion foundation model に統合した multimodal DLLM。図 3 のように mixed long-CoT データでの SFT と UniGRPO(modality をまたぐ統一 RL)を組み合わせ、推論時には単一の masked diffusion で text・image を生成する
商用 / 大規模 industry 向けには Mercury(Inception Labs ほか 2025年)(Inception Labs)、Seed Diffusion(ByteDance Seed ほか 2025年)(ByteDance)が登場しており、speed-quality の Pareto frontier 上で AR と競合する位置に到達した。AR と DLLM の中間にあたる block diffusion(Arriola ほか 2025年) は block 内 diffusion・block 間 AR の hybrid 設計で、AR と DLLM を連続的に補間する。
AR モデルが planning に弱い問題に対し、discrete diffusion が「難しい subgoal を AR より上手く学習する」という観察が (Ye, Gao, ほか 2024年) で示された。Countdown で 91.5%、Sudoku で 100%(同条件の AR は 45.8% と 20.7%)という強い結果は、reasoning に diffusion が向きうる構造的理由(並列予測、unmask order の自由度、bidirectional context)があることを示唆する。
DLLM 固有の inference-time 技術
AR の self-consistency や prefix-confidence と類似した「中間状態を集約して answer を予測する」思想が、DLLM の denoising trajectory に対しても独立に提案されている。共通する核心観察は DLLM の denoising trajectory 上で answer は最終 step よりかなり早い時点で内部的に確定する という点である。表 1 にそれぞれの位置づけを整理する。
| 手法 | 操作 | 時間軸 | 集約方法 |
|---|---|---|---|
| Prophet | early-stop して一括 decode | denoising step | 単一 trajectory の top-2 gap 監視 |
| Time-is-a-Feature | 中間 step の予測を集約 | denoising step | 同一 trajectory の step 間 majority vote |
| I-DLM | 単一 forward 内で前 token を再検証 | forward pass 内 | self-verify による rejection sampling |
Trajectory 内で answer が定まる時点の検出
Prophet(Li ほか 2025年) は DLLM の denoising 過程で「最終答が refinement の半分程度の時点で内部的にすでに確定している」現象を GSM8K で 97%、MMLU で 99% の instance について観測した。具体的には top-2 candidate の confidence gap が一定の閾値を超えた時点で残りの mask token を一括 decode する training-free な方式で、3.4 倍の高速化を実現する(図 4)。
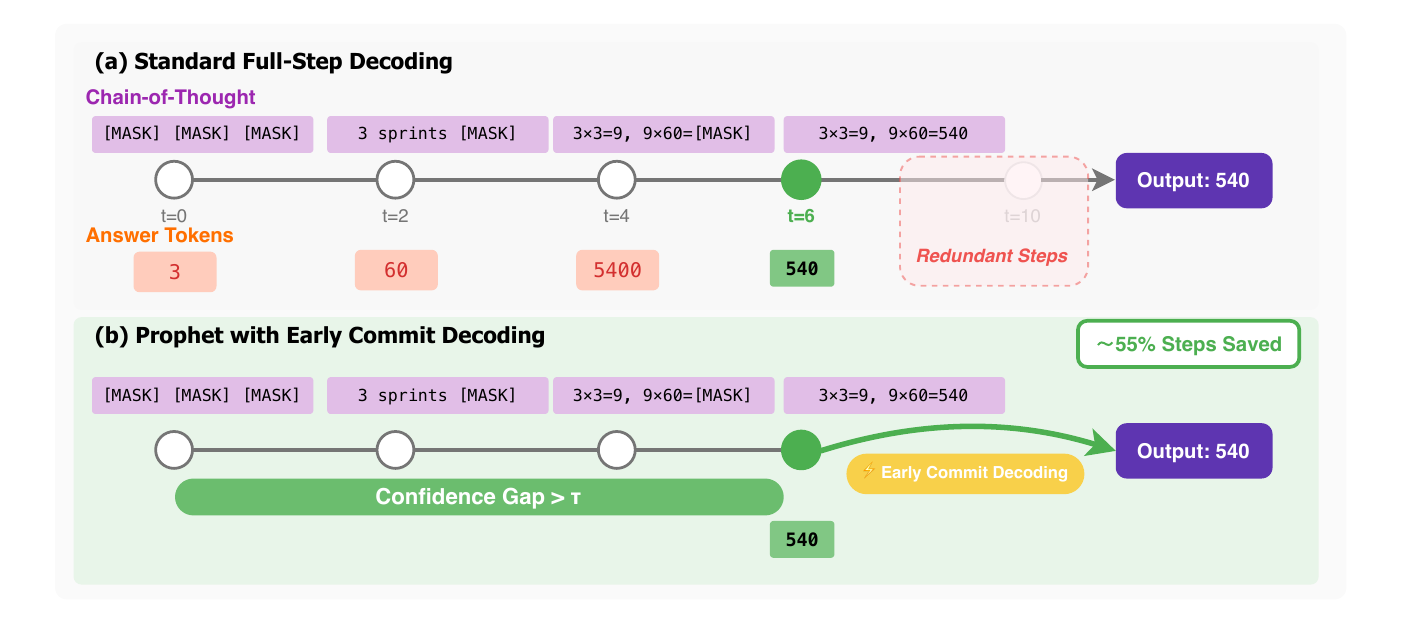
この観察は、AR における prefix-consistency 系の手法(Self-Consistency と重み付き多数決)が「途中で答えが決まっている」という事実を利用するのと完全にパラレルである。AR では prefix の長さが時間軸となるのに対し、DLLM では denoising step 数が時間軸になる。
中間 step の集約による self-consistency
Time-is-a-Feature(W. Wang ほか 2025年) は DLLM の denoising 中に「正答が一度浮かんでから後段で潰される」という temporal oscillation を観測し、中間 step の予測を集約する Temporal Self-Consistency Voting を提案した(図 5)。さらに Temporal Semantic Entropy(TSE)を reward として post-training することで、Countdown +24.7%、GSM8K +2.0%、MATH500 +4.3% の改善を得ている。
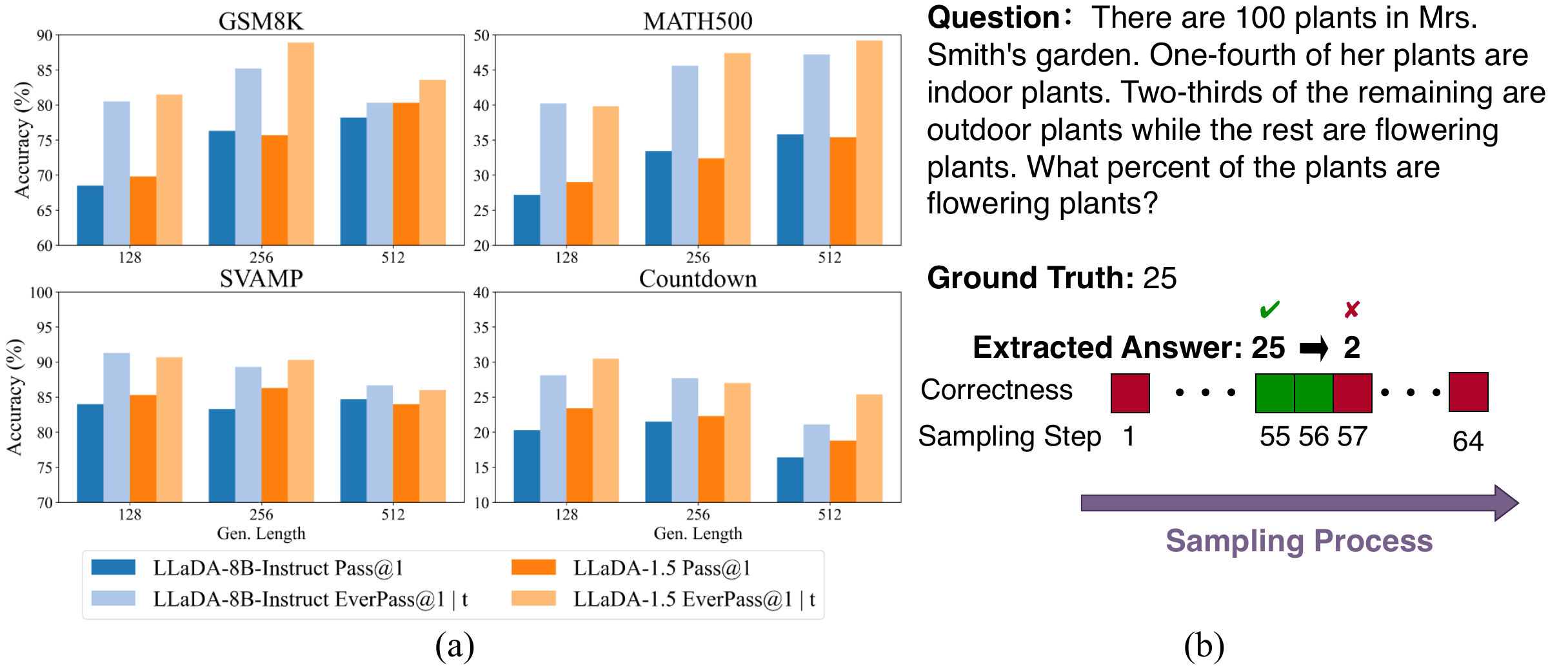
これは AR の self-consistency が複数 sample を独立に並走させて多数決を取るのに対し、同一 trajectory 上の異なる denoising step を sample として扱う という時間軸の取り方の違いと見られる。サンプリングコストは単一の denoising pass のみで済むため、AR の self-consistency に比べて圧倒的に安価になりうる。
単一 forward 内 self-verify
Introspective Diffusion Language Models(I-DLM)(Yu ほか 2026年) は、DLLM が AR 性質(自分の過去生成と整合する)を持たないことが quality gap の主因であると特定し、Introspective Strided Decoding(ISD)を提案した。これは新規 token を進めつつ前の token を同じ forward pass で検証する設計で、 acceptance ルールにより AR distribution との等価性を理論的に保証する。AIME-24 で 69.6、LiveCodeBench で 45.7 を達成し、LLaDA-2.1-mini を大幅に上回りつつ AR 比で 2.9–4.1 倍の高速化を実現する(図 6)。
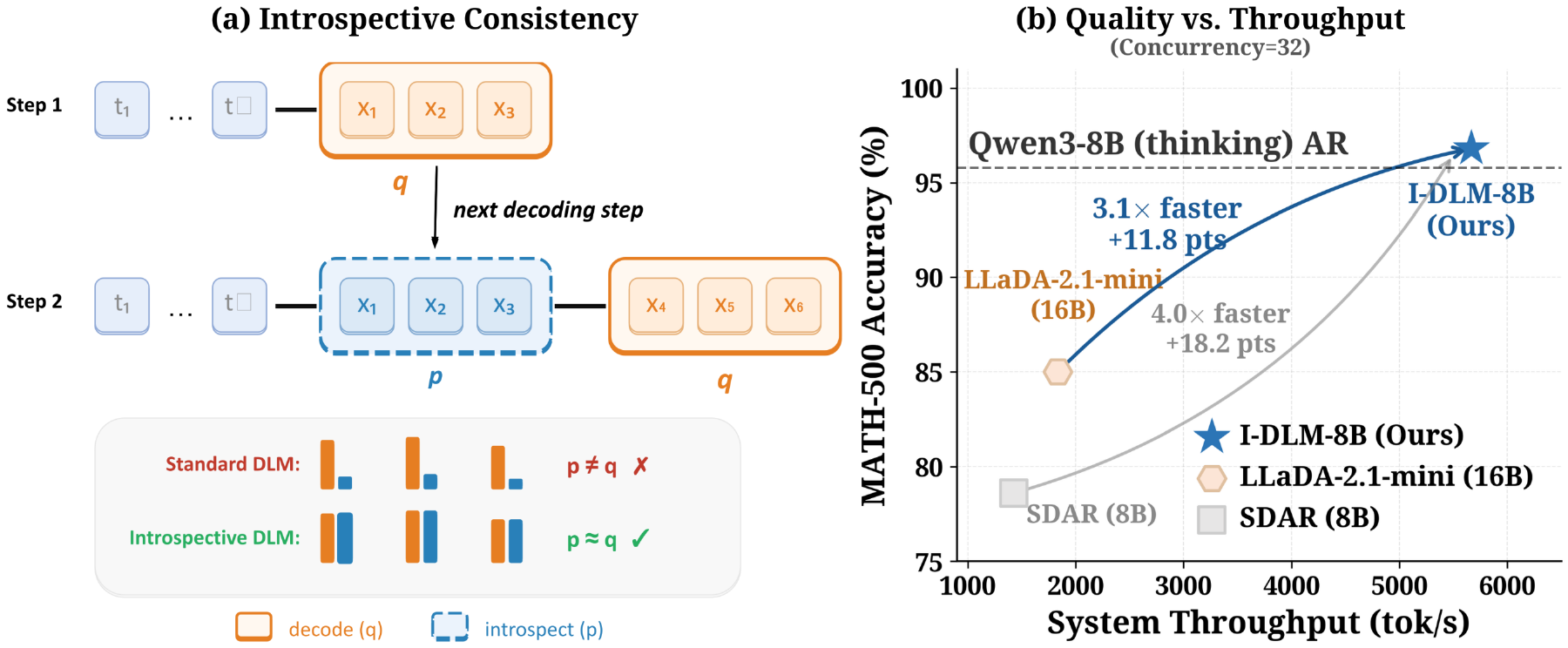
外部に複数 trajectory を持つのではなく、単一 forward 内に self-verification を組み込む 設計は、AR における speculative decoding や self-verification と問題意識が近い。
Unmask order の選び方
DLLM の本質的な自由度は「どの順番で mask を埋めるか」にある。AR が左→右に固定されているのに対し、DLLM は任意順序で unmask 可能であるため、この schedule をどう決めるかが test-time scaling の主要な軸になる。
代表的な選択肢を以下に整理する。
- Confidence-based unmasking: モデルの予測 entropy が低い token から順に unmask する標準的な方式。簡単だが後述する flexibility trap を引き起こす
- Block scheduling: 系列を block に分け、block 単位で進める方式。Block size が AR↔︎ 並列 diffusion を補間する自由度として機能する(Arriola ほか 2025年)
- Wavefront ordering(H. Yang ほか 2025年):すでに確定した token から外向きに広がる “wavefront” に従って unmask。Global denoising の premature EOS と block denoising の semantic unit 分断を回避し、reasoning と code 生成で SOTA を達成
- Tree search による order 探索(Zheng Huang ほか 2025年):unmask trajectory を combinatorial search 空間とみなし、Monte Carlo Tree Search(MCTS)で初期段階の trajectory を information-gain reward で誘導する。後段は heuristic に切替
Schedule の多重性を ensembling に使う
HEX(Lee ほか 2025年) は DLLM が「異なる block schedule に対応する semi-AR expert の mixture」を暗黙に学習していることを示し、固定 schedule に commit すると性能が崩れることを観察した。提案手法は複数 schedule で生成して majority vote する training-free な方式で、math reasoning で 88.10% に到達する。
これは AR の self-consistency が 異なる sampling seed の trajectory 間 majority vote であるのに対し、HEX は 異なる schedule の trajectory 間 majority vote という点で ensembling 軸が直交する。両者を組み合わせれば双方向の test-time scaling になりうる。
Flexibility trap と confusion zones
DLLM の order 自由度は無条件に reasoning を改善するわけではなく、むしろ落とし穴があることが 2025–2026 年に独立に複数報告された。
(Ni ほか 2026年) は反直感的観察として「arbitrary-order generation は reasoning boundary を狭める」ことを示した。MDLM は confidence-based unmasking により、高 entropy トークン(therefore、because、so のような論理 connector)を後回しにする傾向があり、これが branching point の探索を阻害する。AR order に制限すると solution space が広がるという結果は、AR の固定 order が論理 chain 学習に inductive bias として効いていた可能性を示唆する。
関連して Confusion Zones(Chen ほか 2025年) は、DLLM の trajectory 上で entropy spike や confidence margin の急変が起きる “zones of confusion” を発見し、これら少数 step が最終正答率を強く predict することを示した。Adaptive Trajectory Policy Optimization(ATPO)は policy gradient をその step に集中させることで、追加 reward や compute なしに性能を向上させる。
これらの観察は本書の他章とも整合する。
- 高 entropy 位置が分岐点という構造は、Self-Consistency と重み付き多数決 で扱った prefix-consensus 系手法と同じ「重要な意思決定箇所」の局在化現象
- “Early commit を後から覆す” 機能性が必要という指摘は、RemeDi(Huang ほか 2025年) による self-reflective remasking(一度 unmask した token を per-token confidence で re-mask する)で実装され、reasoning 性能が大幅に向上する
DLLM 上の RL: post-training による reasoning 強化
DLLM の reasoning を inference-time 技術だけでなく訓練側から強化する系統も急速に成熟している。半年単位で次の更新が続いている。
- d1(S. Zhao ほか 2025年):事前学習済み masked DLLM に SFT と新規 RL アルゴリズム
diffu-GRPOを適用。Mean-field 近似で sequence likelihood を近似し、ランダム prompt masking で正則化する。GSM8K、MATH500 で LLaDA-8B-Instruct から大幅 boost - DCoLT(Zemin Huang ほか 2025年):各 reverse diffusion step を “thinking action” とみなし、trajectory 全体を outcome-based RL で最適化。Linear/causal な CoT と違い bidirectional な lateral thinking が intermediate step で許される。LLaDA に適用すると GSM8K +9.8%、MATH +5.7%、MBPP +11.4%、HumanEval +19.5%
- d2(G. Wang ほか 2025年):d1 の後継。Trajectory likelihood を 1 model pass で正確に推定する d2-AnyOrder と近似版 d2-StepMerge を提案。Countdown、Sudoku、GSM8K、MATH500 で d1 を SFT 無しで上回り、likelihood 推定の精度が RL 性能を支配することを示す
- DiFFPO(H. Zhao ほか 2025年):DLLM の RL を統一する framework。Off-policy RL で surrogate policy を訓練し、two-stage likelihood approximation と importance sampling correction で精度を上げる。さらに sampler と controller の joint training で prompt ごとに inference threshold を動的決定
RLVR の理論と限界 で扱った AR 用 RLVR の問題意識(base 分布の re-weighting か新たな能力獲得か)は、DLLM においても同じ形で議論可能である。trajectory-level の credit assignment が AR より自然に定義できる点は DLLM の構造的優位だが、likelihood 推定の精度がボトルネックになることが d2 の観察から見て取れる。
AR との比較・接続点
DLLM の reasoning における特性を AR と並べると、表 2 のような対応関係になる。
| 観点 | AR (auto-regressive) | DLLM (masked diffusion) |
|---|---|---|
| 生成順序 | 左→右固定 | unmask order が自由 |
| 中間状態 | prefix(左側の確定 token 列) | partial mask 状態(任意位置の確定 token 集合) |
| 早期信号 | prefix consistency、prefix confidence | answer convergence within trajectory(Prophet) |
| Ensembling 軸 | 独立 sample(Self-Consistency) | denoising step(Time-is-a-Feature)、schedule(HEX) |
| Self-verify | speculative decoding、内部一貫性 | 単一 forward 内 self-verify(I-DLM) |
| 分岐点 | logical connector を含む step | 高 entropy 位置、confusion zone |
| Test-time RL | GRPO / DAPO 系 | diffu-GRPO(d1)、DCoLT、d2、DiFFPO |
両者は構造的に異なるが、本書を貫く「中間状態を集約して answer を予測する」という共通の問題意識を持つ。AR で発展した手法を DLLM の denoising step や schedule に翻訳することで、新しい test-time scaling 軸を得られる可能性がある。実際 block diffusion(Arriola ほか 2025年) のような hybrid 設計は、AR と DLLM の手法を段階的に橋渡しする土台になりうる。
その他の関連論文
Latent CoT 系(COCONUT、LaDiR、latent tokens)は、reasoning を離散 token 列から徐々に剥がす方向であり、DLLM の masked token とも親和性が高い。本章の中心テーマである「何を中間状態とみなすか」を再定義する系統として位置付けられる。
章のまとめ
DLLM の reasoning は AR の reasoning とは異なる構造を持つが、本書を貫く問題意識との対応は明瞭である。
- 早期収束現象の独立発見:Prophet、Time-is-a-Feature、I-DLM はいずれも別チームが「DLLM の途中状態で answer が確定する」現象を観測し、それぞれ inference 効率や品質向上に利用している。AR における prefix-consistency 系手法と同じ「中間状態の信号」を、denoising step という時間軸で取り出している
- Unmask order の自由度が新しい test-time scaling 軸:HEX、MEDAL、WavefrontDiffusion は schedule の多様性を新しい ensembling 軸として活用。AR の sample 軸 ensembling と直交し、組み合わせの余地が大きい
- Arbitrary order の落とし穴:Flexibility Trap と Confusion Zones は、DLLM の order 柔軟性が必ずしも reasoning に有利でないことを示す。AR の固定 order が論理 chain 学習に inductive bias として効いていた可能性があり、「AR 的 prefix 構造」を保つ手法が DLLM 上でも価値を持ちうる
- DLLM 用 RL の急速な成熟:d1 → DCoLT → d2 → DiFFPO → ATPO と半年単位で更新が続き、AR の RLVR と比較可能な水準に達しつつある。Trajectory-level credit assignment が AR より自然に定義できる点は構造的優位だが、likelihood 推定の精度が現状のボトルネックである
DLLM の reasoning は AR 一辺倒だった研究地形に並列軸を加え、本書の各章で扱った手法群を「中間状態をどう定義し、どう集約するか」という統一的視点で見直す機会を与える。Block diffusion のような hybrid 設計が普及すれば、AR と DLLM の手法は実装レベルで連続的に接続される可能性が高い。