Process Reward Models
Process Reward Model(PRM)は Chain-of-Thought(CoT)の各 step に対し正しさ(あるいは正答に到達する確率)を返すモデルである。2024 年までは Best-of-N(BoN)の selection や強化学習(Reinforcement Learning, RL)における中間信号として広く使われてきたが、step ラベルを人手で集めるコストの高さが普及の最大の障壁だった。2025–2026 年の研究はこの障壁を二方向から取り崩している。一つは ラベル無し / 弱教師化 であり、もう一つは 生成型 PRM への移行 である。さらに、PRM そのものの限界を実証するベンチマークと、PRM-guided 探索の有効性を懐疑する研究も同時並行で蓄積している。本章ではこの 4 つの動きを軸に、24 本程度の主要研究を俯瞰する。
PRM の役割
PRM は古典的には次の 3 つの用途で使われてきた。
- BoN 選別: 候補 \(N\) 本の trajectory に対し、各 step スコアを集約して最良応答を選ぶ。Outcome Reward Model(ORM)が「最終答」に対してのみスコアを返すのに比べ、PRM は途中で誤った trajectory を識別できる
- RL 訓練の guide: GRPO(Group Relative Policy Optimization)や DPO(Direct Preference Optimization)の中で、outcome reward だけでなく step-level の信号を advantage に組み込む
- 探索の guide: Monte Carlo Tree Search(MCTS)や beam search で、node のスコアリングや剪定に使う
これらの用途で PRM が機能するには、step ラベルが十分な精度で得られていることが前提となる。だが PRM800K のような人手アノテートは 80 万 step 規模で初めて成立する世界であり、現実の研究現場では合成ラベルか弱教師に頼らざるを得ない。2025–2026 年の主要な技術進展は、この「ラベル供給の細さ」に答える形で起こっている。
図 1 に ProcessBench の典型的なアノテーション例を示す。label: 2 は「最初に誤った step」のインデックスで、PRM 訓練・評価の最小単位がこの粒度であることが分かる。

steps 配列のうち専門家が「最初に誤った step」をインデックスとしてアノテートしている。出典: (Zheng ほか 2024年)
ラベル無し PRM の系統
step ラベル不要化のメカニズムは大きく 4 つに分かれる。MC rollout、policy 自身の log-likelihood ratio、outcome から逆伝播した pseudo label、そして next-token 確率である。
Math-Shepherd 系(MC rollout 由来): Math-Shepherd は各中間 step から \(N\) 本の rollout を生成し、正答に到達する割合を擬似スコアとして step ラベル化する古典的手法である。OmegaPRM は MCTS による rollout 効率化を加え、生成コストを下げた。一方 Qwen2.5-Math-PRM の実務報告 (Zheng ほか 2024年) は「MC rollout 由来の step ラベルは LLM-as-judge より generalization が弱い」ことを示し、consensus filtering とハイブリッド annotation を提案している。
Implicit PRM(log-likelihood ratio 由来): Free Process Rewards (Cui ほか 2026年) の中核アイデアは、outcome reward を policy/reference の log-likelihood ratio で parametrize するだけで、訓練後に step-level reward が「無料で」取り出せるというものである。response-level ラベルしか使わずに PRM を得られるため、step アノテーション収集の bottleneck が解消する。PRIME (Cui ほか 2026年) はこれを online RL に統合し、専用 PRM 訓練フェーズを排して policy rollout と outcome ラベルだけで implicit PRM を更新する。Qwen2.5-Math-7B-Base から平均 15.1% の改善、学習データ 10% で Instruct を超える効率を報告している。
FreePRM 系(outcome → pseudo step label): FreePRM は最終 outcome の正誤から pseudo step label を生成し、Buffer Probability でラベルノイズを緩和する弱教師付き PRM である。ProcessBench で F1=53.0 を達成し、Math-Shepherd ベースの完全教師付き PRM を +24.1 ポイント上回る。「outcome が正しければ全 step を仮に正しいとする」という素朴な pseudo label から始めて、ノイズを統計的に押し出す方向のアプローチである。
uPRM 系(next-token 確率由来): Unsupervised PRM(uPRM, (Gadetsky ほか 2026年))は、LLM の next-token 確率から導出される scoring 関数で、batch 内の trajectory 群に対し「最初の誤 step 候補位置」を joint に評価する。step ラベルも outcome ラベルも一切使わずに完全教師無しで PRM を訓練できる点が新しい。ProcessBench で LLM-as-Judge を最大 15% 上回り、RL policy optimization も改善する。
表 1 に主要なラベル無し PRM を信号源で整理する。
| 手法 | 信号源 | 使うラベル |
|---|---|---|
| Math-Shepherd / OmegaPRM | MC rollout 一致率 | なし(生成のみ) |
| ImplicitPRM / PRIME (Cui ほか 2026年) | \(\log \pi_\theta - \log \pi_\mathrm{ref}\) | outcome のみ |
| FreePRM | outcome → pseudo step + buffer | outcome のみ |
| Athena-PRM (Athena-PRM Team 2025年) | weak/strong completer の一致 | outcome のみ |
| uPRM (Gadetsky ほか 2026年) | next-token 確率の joint scoring | なし |
| SPARK | self-consistency と meta-critique | outcome のみ |
これらに共通するのは「人手 step ラベルを諦める代わりに、別の場所から信号を取り出す」という発想である。MC rollout、log-likelihood ratio、outcome から逆伝播した pseudo label、next-token 確率、completer 間の合意は、いずれも policy の implicit な分布から取り出した代理信号と見ることができる。
生成型 PRM の系統
従来の PRM は scalar head で各 step に確率を返す識別型だった。生成型 PRM はこれを「step ごとに CoT を verbalize して判定する verifier」へ置き換える。識別型と異なり、verifier 側でも test-time compute をスケールできるのが本質的な利点である。
ThinkPRM (Khalifa ほか 2025年) は識別型に対する長 CoT 型 PRM の最初期事例で、PRM800K の 1%(8K step ラベル)の合成データだけで fine-tune し、ProcessBench / MATH-500 / AIME’24 の BoN と reward-guided search で full PRM800K で訓練した識別型 PRM を out-of-domain で 8% / 4.5% 上回る。GenPRM (Zhao ほか 2025年) は explicit CoT に加えて code verification を組み合わせる方向で、独自のラベル付与法 Relative Progress Estimation(RPE)を提案している。GenPRM-7B は同サイズの識別型 PRM を上回り、test-time scaling で Qwen2.5-Math-PRM-72B を超える。
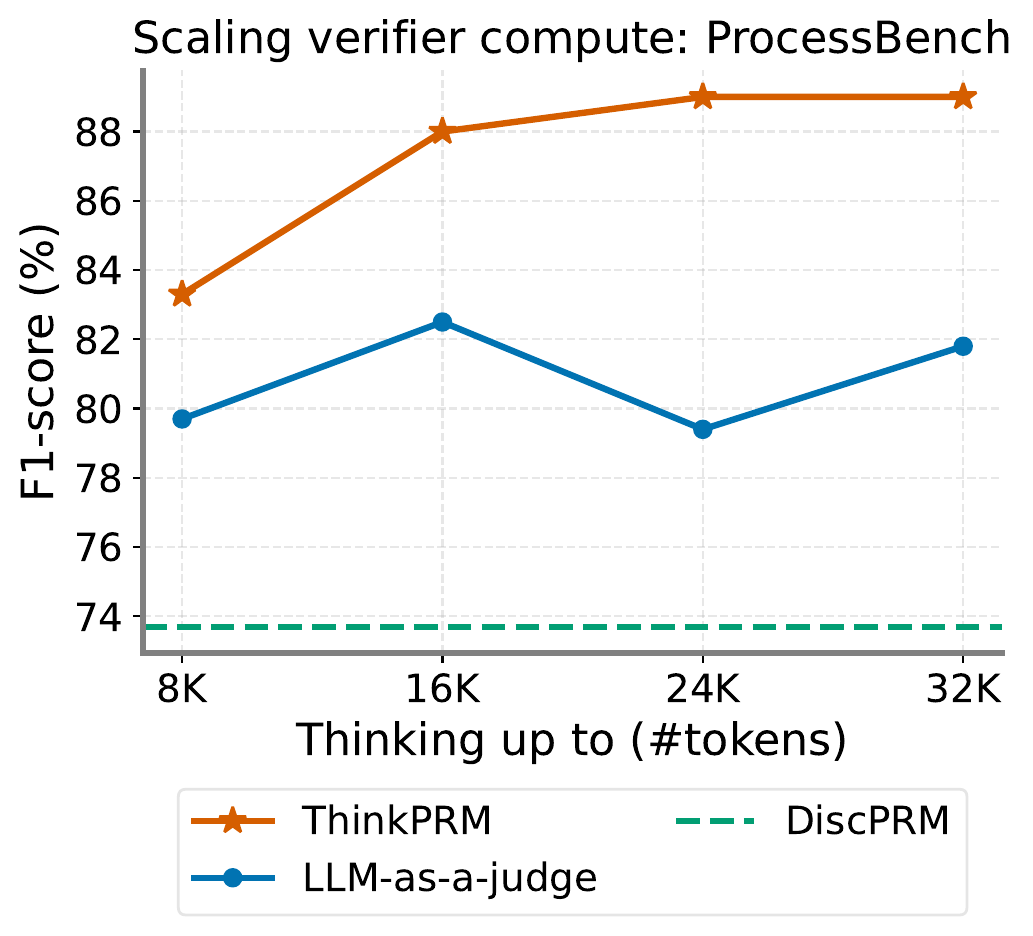
図 2 は ThinkPRM が「verifier 側 scaling law」を実証した代表的なプロットである。思考トークン数を 8K から 32K に増やすと F1 が 83 から 89 まで単調に伸び、識別型 PRM(DiscPRM)の頭打ちを大きく超える。
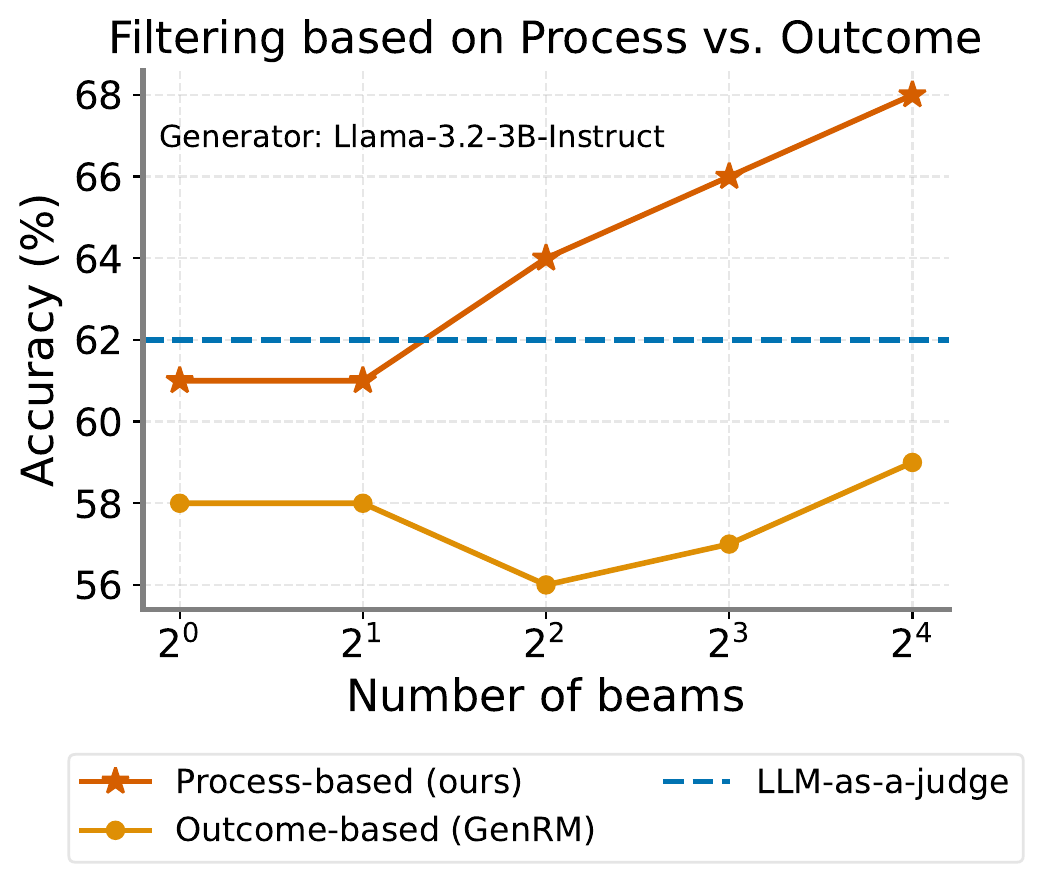
生成型 PRM の利点は filtering でも顕著で、図 3 は ThinkPRM の process-based filtering が outcome-based filtering(GenRM 相当)に対して beam 数を増やすほど優位差が拡大することを示している。「途中段階で誤った trajectory を切り捨てる」という PRM 本来の利点が compute と共にスケールすることを示唆する結果である。
R-PRM は preference optimization で追加アノテーション無しに性能を伸ばす生成型 PRM、Reward Reasoning Model(RRM) は reward を返す前に explicit CoT で deliberate し、ELO/knockout 戦略で test-time compute を可変投入できる。Uncertainty-Aware Step-wise Verification は生成型 PRM の CoT Entropy という新しい不確実性指標を導入し、verifier 自身が不確実な step を検出することで誤フィードバックを減らす。
生成型 PRM の利点は、compute をかけるほど精度が上がる「verifier 側 scaling law」を持つことである。識別型 PRM の精度は学習データ量と表現力に上限が縛られるが、生成型は推論 (inference) 時に reasoning budget を増やせる。一方コストは線形以上に上がるため、いつ生成型を使うかは下流タスクの compute 予算次第になる。
専門ドメインへの拡張
PRM はしばらく数学領域に集中していたが、2025 年後半から急速にドメイン横断化した。
- Multimodal: Athena-PRM (Athena-PRM Team 2025年) は弱い completer と強い completer の予測一致を信頼ラベルの基準にし、5K サンプルで multimodal PRM を訓練。VisualProcessBench で SOTA を +3.9 F1、Qwen2.5-VL-7B を policy にすると WeMath で +10.2、MathVista で +7.1 ポイント改善する。図 4 に Athena の completer 一致による pseudo label の生成例を示す
- 多領域: VersaPRM は MMLU-Pro から synthetic CoT を生成し 70B モデルで auto-label することで、法律・医療・経済等の領域に PRM を拡張した。法律カテゴリの weighted majority voting で +7.9%(Qwen2.5-Math-PRM の +1.3% に対し大きく上回る)
- Long-CoT trajectory: ReasonFlux-PRM は既存 PRM が DeepSeek-R1 / OpenAI-o1 の trajectory-response 構造に適合しない問題に応える。step-level と trajectory-level の両監督を組合せ、10K の高品質 trajectory-response データで Qwen2.5-Math-PRM-72B を data selection 品質で上回る
- 構造化 reasoning(rule-based): VPRM(Verifiable PRM)は neural judge の opacity / bias / reward hacking 脆弱性を避けるため、deterministic な rule-based verifier で各 step を検証する。医療証拠合成の risk-of-bias 評価で SOTA を最大 +20% F1 改善する

これらに共通するのは「ドメイン特有の構造(multimodal の completer 多様性、medical の rule-based 検証可能性、long-CoT の trajectory 構造)を PRM の信号源として取り込む」という方向性である。汎用 PRM を作る代わりにドメイン特化型を作るほうが、限られたラベル予算で実用的な性能が得られやすい。
PRM の限界とベンチマーク
PRM の進歩と並行して、PRM 自体への懐疑も強くなっている。
(Cinquin ほか 2025年) は MCTS の guide としての PRM が、相当の compute をかけても素朴な BoN を一貫して上回るわけではないことを示した。PRM のスコアが MCTS の探索空間を絞る効果は理論上明らかに有用に見えるが、実証的には PRM のノイズが探索を歪めるケースも多い。PRM をどう使うかは、信号の質と探索アルゴリズムの両方に依存する open な問題である。
(Cinquin ほか 2025年) の分析の中で興味深いのは、step スコアを軌道全体に集約する aggregator の選び方で相関が大きく変わることである。図 5 に示す通り、Last / Avg / Min / Prod は中程度の正相関を保つが、Sum や Max は OOD でほぼ無相関にまで劣化する。PRM の信号を下流タスクで使うときは、aggregation の選択そのものが重要な hyperparameter になることを示唆する。
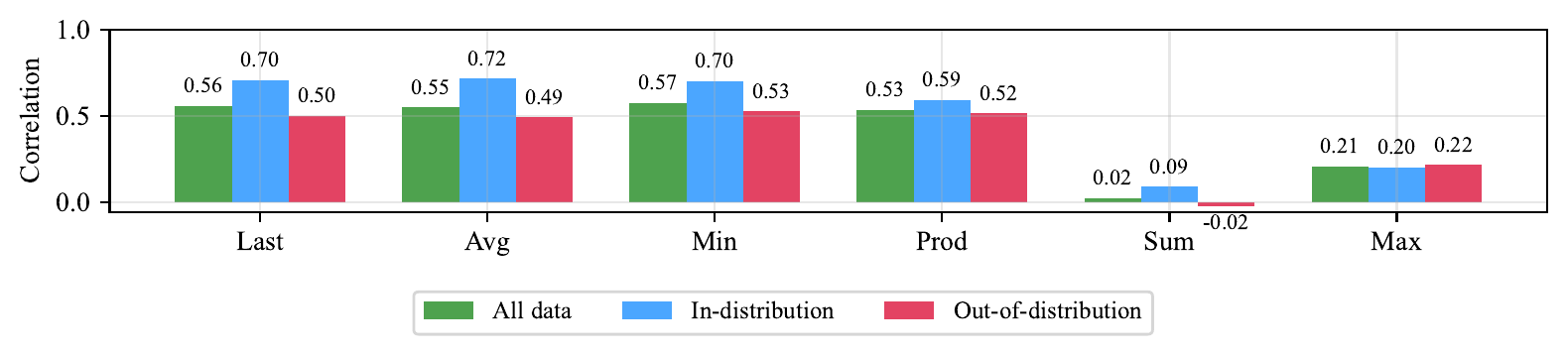
Last/Avg/Min/Prod は安定だが Sum/Max は崩れる。出典: (Cinquin ほか 2025年)
ベンチマーク側では、難易度・粒度が階段状に上がっている。
- ProcessBench (Zheng ほか 2024年): 3,400 件のオリンピアード級数学問題に対し、専門家が「最初に誤る step」をアノテートしたベンチマーク。既存 PRM が GSM8K/MATH の枠を超えると性能が大幅低下することを示した
- PRMBench: 6,216 問題 / 83,456 step ラベル。simplicity / soundness / sensitivity の 3 次元 9 サブカテゴリで PRM の implicit error 検出能力を評価。25 PRM/LLM の評価で、Gemini-2-Thinking が 68.8 で最良(人間は 83.8)
- Hard2Verify (Pandit ほか 2025年): 500 時間超の人手アノテートによる frontier-level math(IMO 2025 等の open-ended proof) の step verification ベンチ。1,860 step / 200 解答。Qwen2.5-Math-PRM-72B が ProcessBench の 78.3 から Hard2Verify では 37.3 に大幅低下し、既存 PRM がフロンティアで使えない実態を明示した
図 6 に Hard2Verify と ProcessBench の同一モデル比較を示す。横軸が ProcessBench、縦軸が Hard2Verify で、専用 PRM である Qwen2.5-Math-PRM-72B は ProcessBench 78 → Hard2Verify 37 と大きく落ちる。Gemini 2.5 Pro や GPT-5-High のような汎用大規模 LLM のみが Hard2Verify で 50% 以上を確保しており、専用 PRM の優位性がフロンティアでは失われていることを端的に示す。
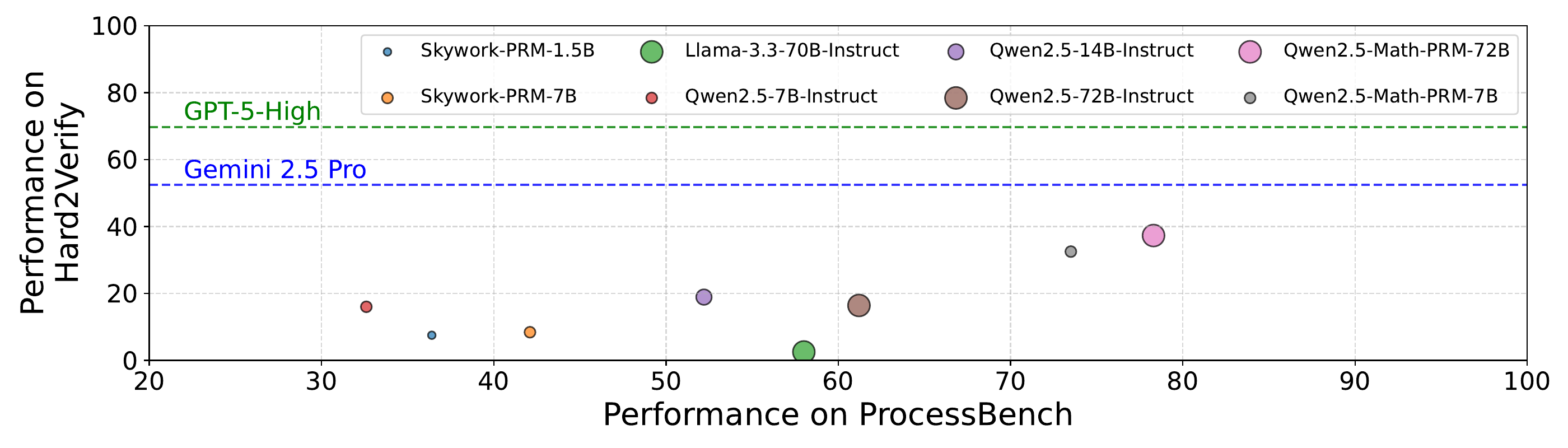
Hard2Verify の結果は「数学領域内ですら PRM の generalization は限定的」という強いメッセージを送っている。
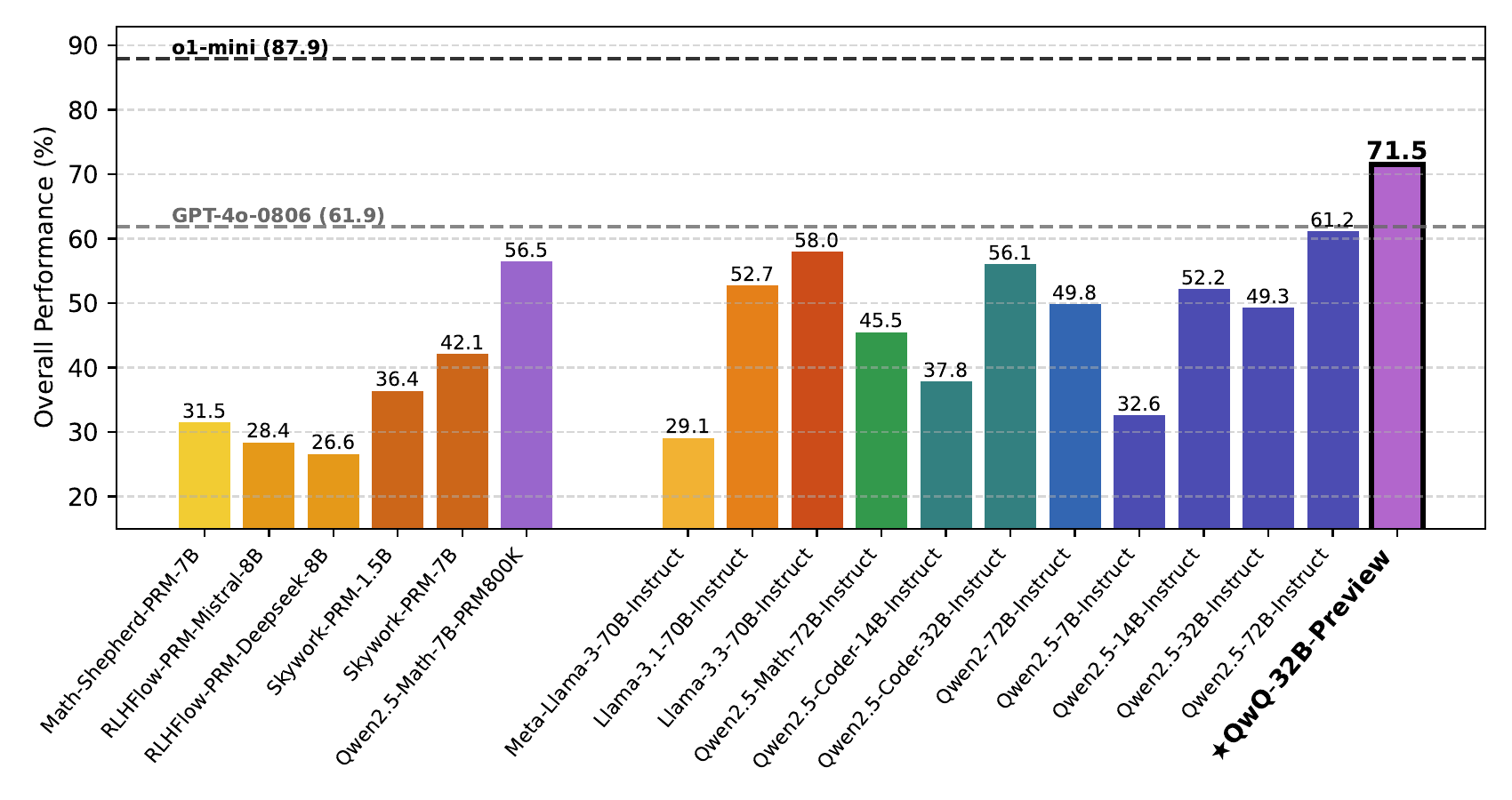
参考までに ProcessBench 上での主要 PRM/LLM の比較を 図 7 に示す。同じ数学領域のベンチマークでも、最良の Qwen2.5-Math-7B-PRM800K (56.5) と Skywork-PRM 系(28-42 程度)の差が大きく、PRM 訓練レシピの違いが極端な性能差を生むことが分かる。Hard2Verify の数値と合わせて見ると、PRM はベンチマーク選択と訓練レシピの両方に強く依存する不安定な信号源であると言える。
キャリブレーション
PRM のスコアは確率として読まれることが多いが、その calibration は深刻に劣化する場合がある。
(Khalifa ほか 2025年) と並行して報告された一連の研究は、PRM が systematically overconfident であることを示した。Know What You Don’t Know は PRM が 90% と予測した部分軌道が実際にはそれより遥かに低い率でしか成功しないことを実証し、quantile regression による PRM 出力のキャリブレーションを提案する。calibrated 推定を Instance-Adaptive Scaling(IAS)に組込むことで、MATH ベンチで calibration error を大幅低減し、計算コスト削減と正答率維持を両立した。
Distributional PRM はこの方向をさらに進め、conditional optimal transport で PRM の miscalibration を補正する。PRM hidden states を条件として success 確率に対する monotonic conditional quantile 関数を学習することで、任意 confidence level での bound 抽出が可能になり、MATH-500 / AIME で uncalibrated PRM と quantile regression を有意に上回る。
calibration の議論は PRM だけでなく、self-consistency や verbalized confidence など他の信号源にも横断的に効く(Confidence と Uncertainty を参照)。
RL との理論的接続
PRM と RL の関係は、近年「等価性」の議論が深まっている。
GRPO is Secretly a PRM は outcome reward 付き GRPO が、identical-prefix を共有する trajectory 部分集合に対しては Monte-Carlo PRM と等価であることを理論的に証明した。実世界の rollout でも identical-prefix 条件はほぼ満たされ、GRPO 内に hidden な step-level reward 構造が存在することを実証する。defect を補正する λ-GRPO は reasoning ベンチで GRPO を上回る。
SPRO は追加 PRM を訓練せず process reward を policy model 自身から intrinsically 導出する方向で、Masked Step Advantage(MSA) によって shared-prompt sampling 群内の step-wise advantage を厳密推定する。vanilla GRPO の 3.4× 訓練効率、17.5% 正答率向上を報告する。
ActPRM は逆方向のアプローチで、forward pass 後の不確実性(aleatoric + epistemic)で最も不確実なサンプルだけを高 capability judge model でラベル化する active learning PRM 訓練を提案する。アノテーションコスト 50% 削減で同等以上の性能、ProcessBench 75.0 / PRMBench 65.5 で SOTA を達成する。
これらの研究は「PRM 訓練と RL 訓練を別フェーズと考える必要は必ずしもなく、RL の中に implicit な PRM 構造が含まれている」という認識を確立しつつある。本書では同じ視点を別の角度から GRPO と Reward 設計 でも扱う。
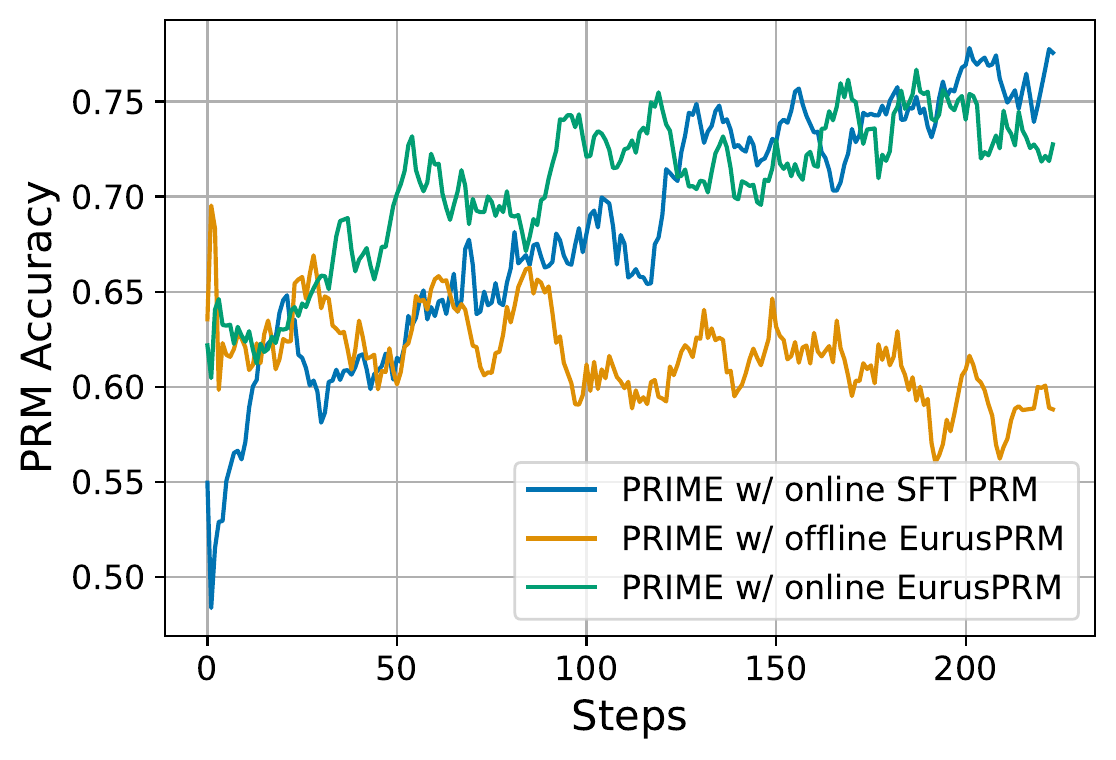
PRIME (Cui ほか 2026年) の online implicit PRM が学習中にどの程度の精度を保つかを 図 8 に示す。offline で固定された EurusPRM は途中で精度が劣化していくのに対し、online で更新される PRM(SFT 版・EurusPRM 版いずれも)は steps を重ねるごとに 75% 程度まで精度が伸びる。implicit PRM は policy と一緒に co-evolve させることで初めて精度を保てるという、PRIME の主張を裏付ける結果である。
その他の関連論文
表 2 に本章で詳述しなかった主要 PRM 関連論文をまとめる。
| 略称 | 一文要約 |
|---|---|
| Qwen2.5-Math-PRM | PRM 訓練の実務知見。MC ラベルは LLM-as-judge より弱いと報告 |
| PRMBench | 9 サブカテゴリでの fine-grained PRM 評価 |
| R-PRM | preference optimization で生成型 PRM の bootstrap |
| RRM | reward 自体が CoT で deliberate する |
| ActPRM | active learning で PRM 訓練を効率化 |
| ReasonFlux-PRM | long-CoT trajectory に適合する PRM |
| VPRM | rule-based verifier による検証可能 PRM |
| VersaPRM | 多領域への synthetic data 拡張 |
| SPARK | self-consistency と meta-critique で reference-free PRM |
| Survey of PRMs | PRM 領域の包括的 survey |
これらの多くは個別の技術的革新を持つが、本章で軸として取り上げた 4 つの動き(ラベル無し化、生成型化、ドメイン拡張、限界の顕在化)の組合せで位置付けられる。
章のまとめ
PRM 領域の 2025–2026 年の動きは、次の 5 点で要約できる。
- 「ラベル無し step reward」の収束: 異なる信号源(MC rollout、log-likelihood ratio、outcome 由来 pseudo label、next-token 確率、completer 一致)から同一目標(step ラベル不要化)が独立に追求されている
- 生成型 PRM への移行: scalar head から CoT-verbalized verifier へ移行し、verifier 側で test-time compute がスケールできるようになった
- GRPO/RL との理論的同一視: PRIME、GRPO-is-secretly-a-PRM、SPRO 等の研究で、RL の中に PRM 構造が implicit に含まれることが示されつつある
- キャリブレーション問題の顕在化: PRM の overconfidence と、それを quantile regression / optimal transport で補正する方向が確立した
- ベンチマークの難化: ProcessBench → PRMBench → Hard2Verify と難易度が拡張され、既存 PRM の限界が露呈している
これらは独立に進んでいるように見えて、根底では「step ラベルの希少性」「verifier の compute 投資先」「下流での信号利用」という 3 つの問いに対する答えである。次章の Self-Consistency と重み付き多数決 では、PRM 不要な軽量 verifier として self-consistency 系の信号を扱う。両系統の境界線は 2026 年に向けて急速に曖昧になりつつある。